📝 Original Info
- Title: Convergence of Outputs When Two Large Language Models Interact in a Multi-Agentic Setup
- ArXiv ID: 2512.06256
- Date: 2025-12-06
- Authors: Aniruddha Maiti, Satya Nimmagadda, Kartha Veerya Jammuladinne, Niladri Sengupta, Ananya Jana
📝 Abstract
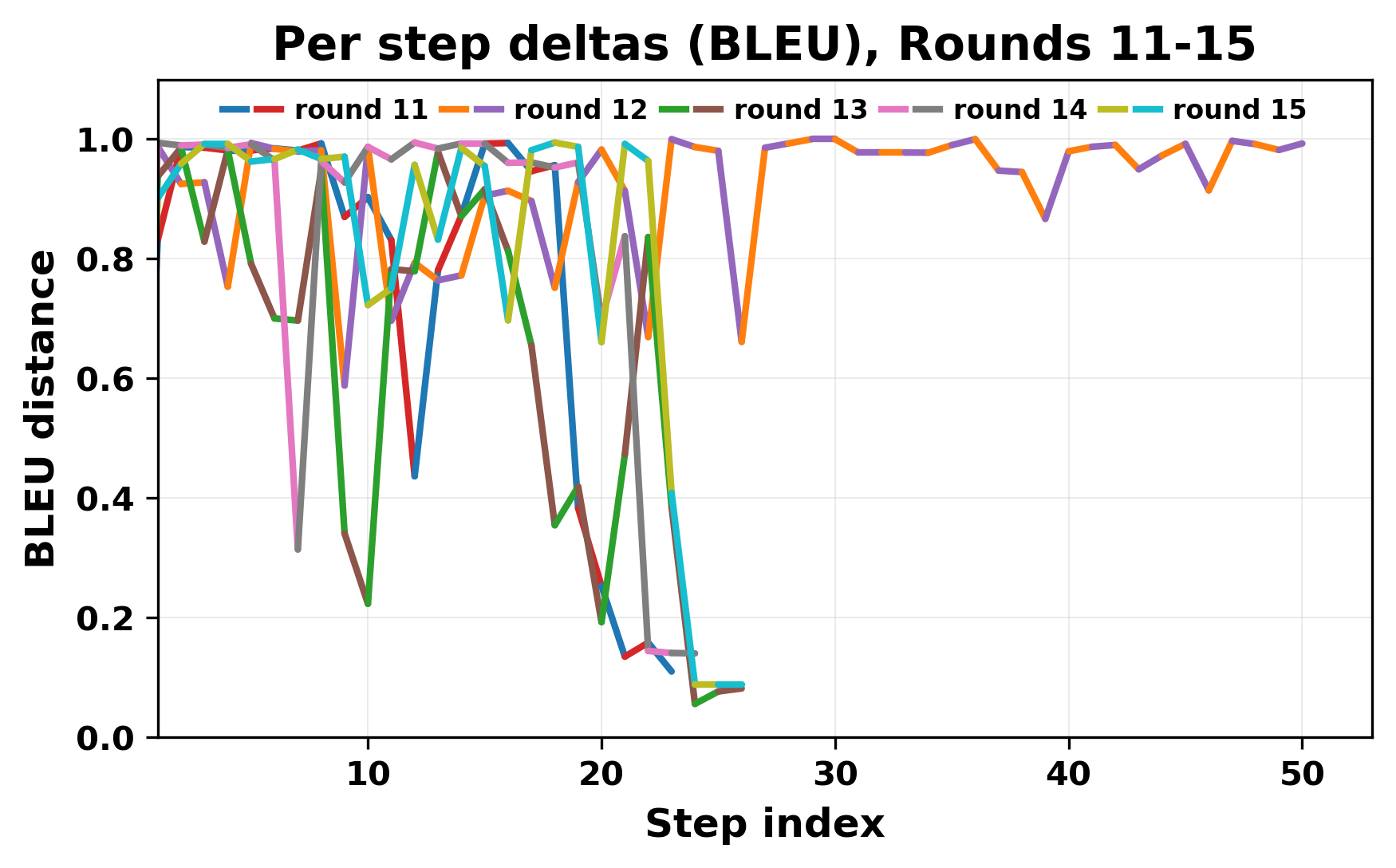
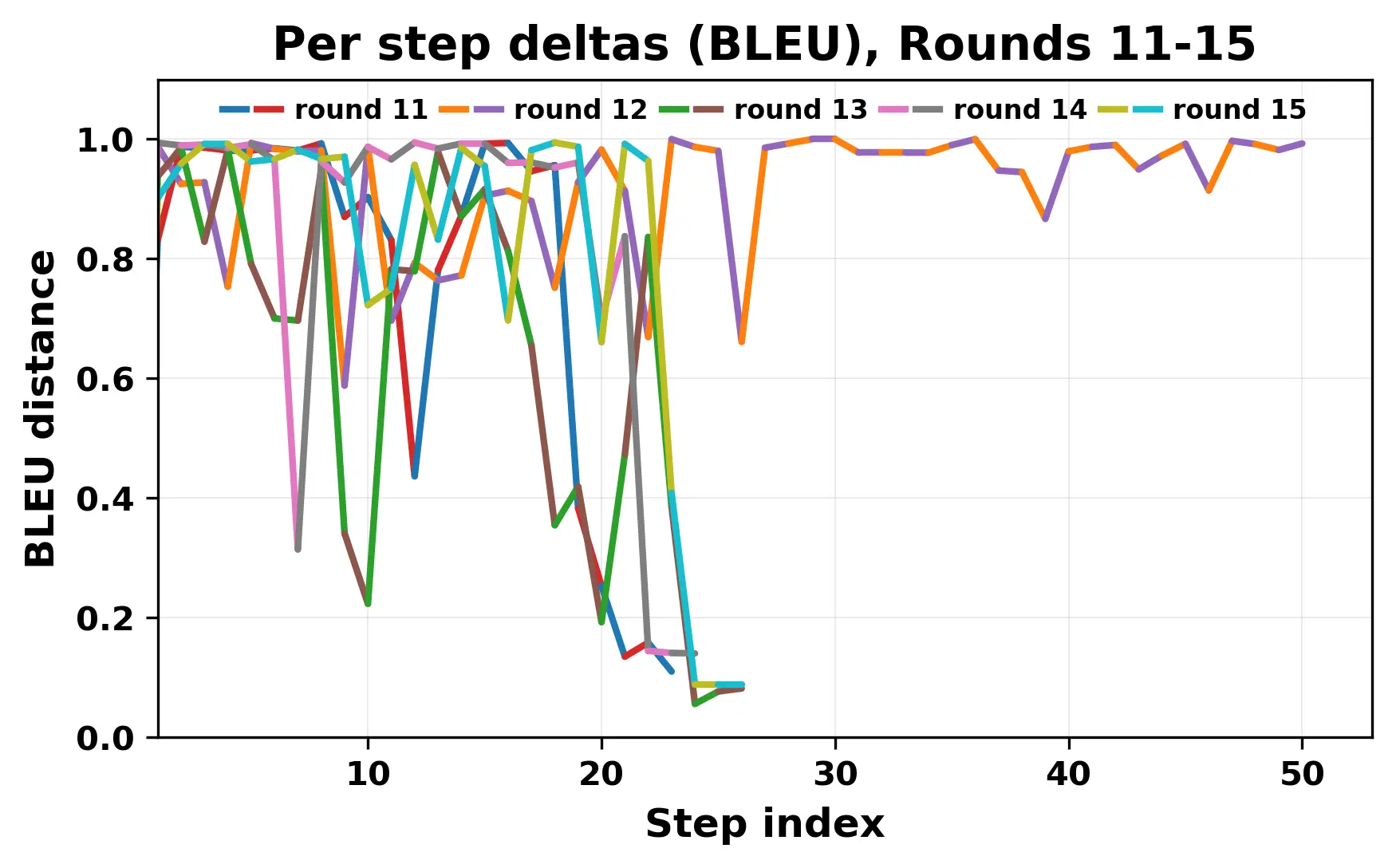
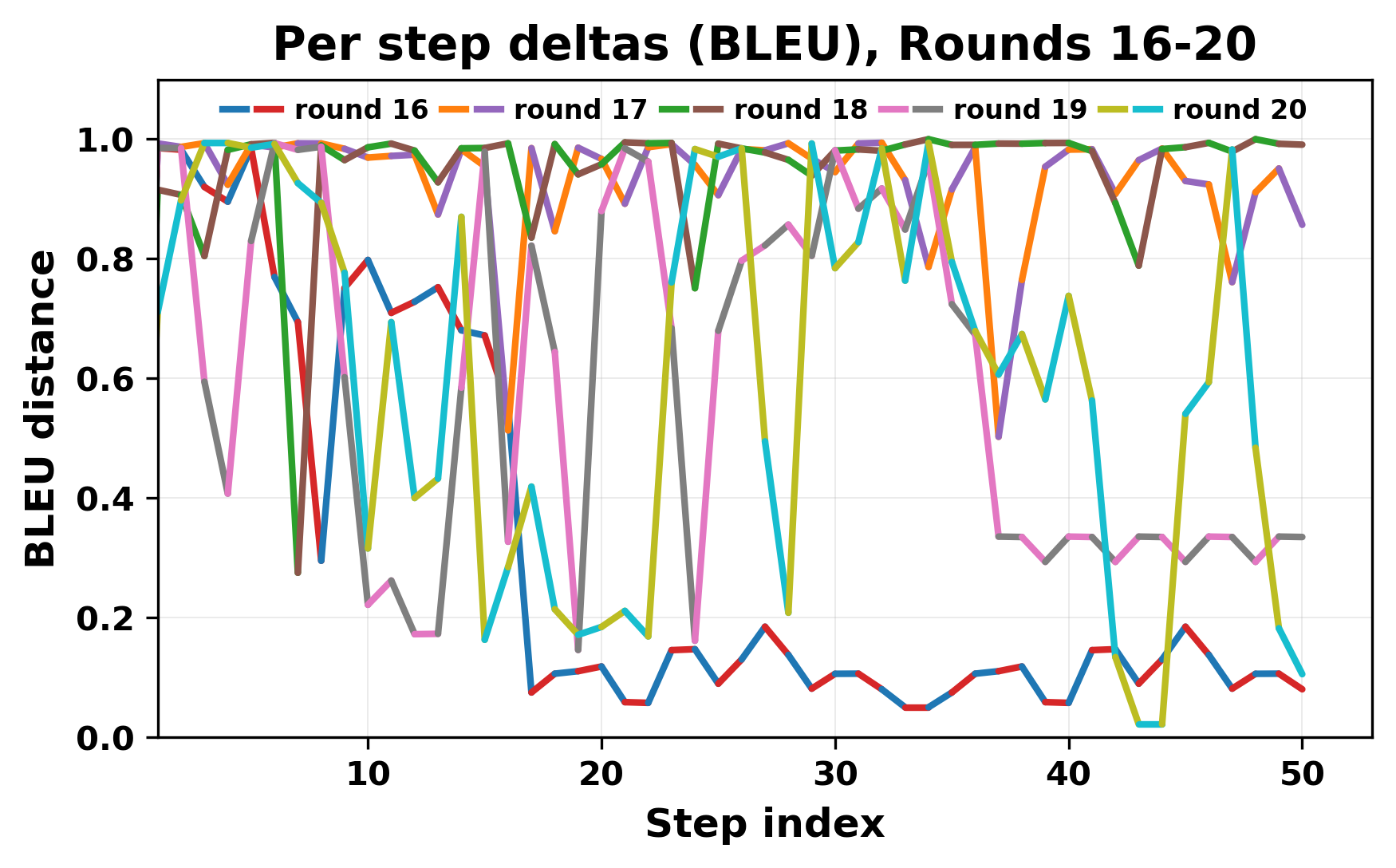
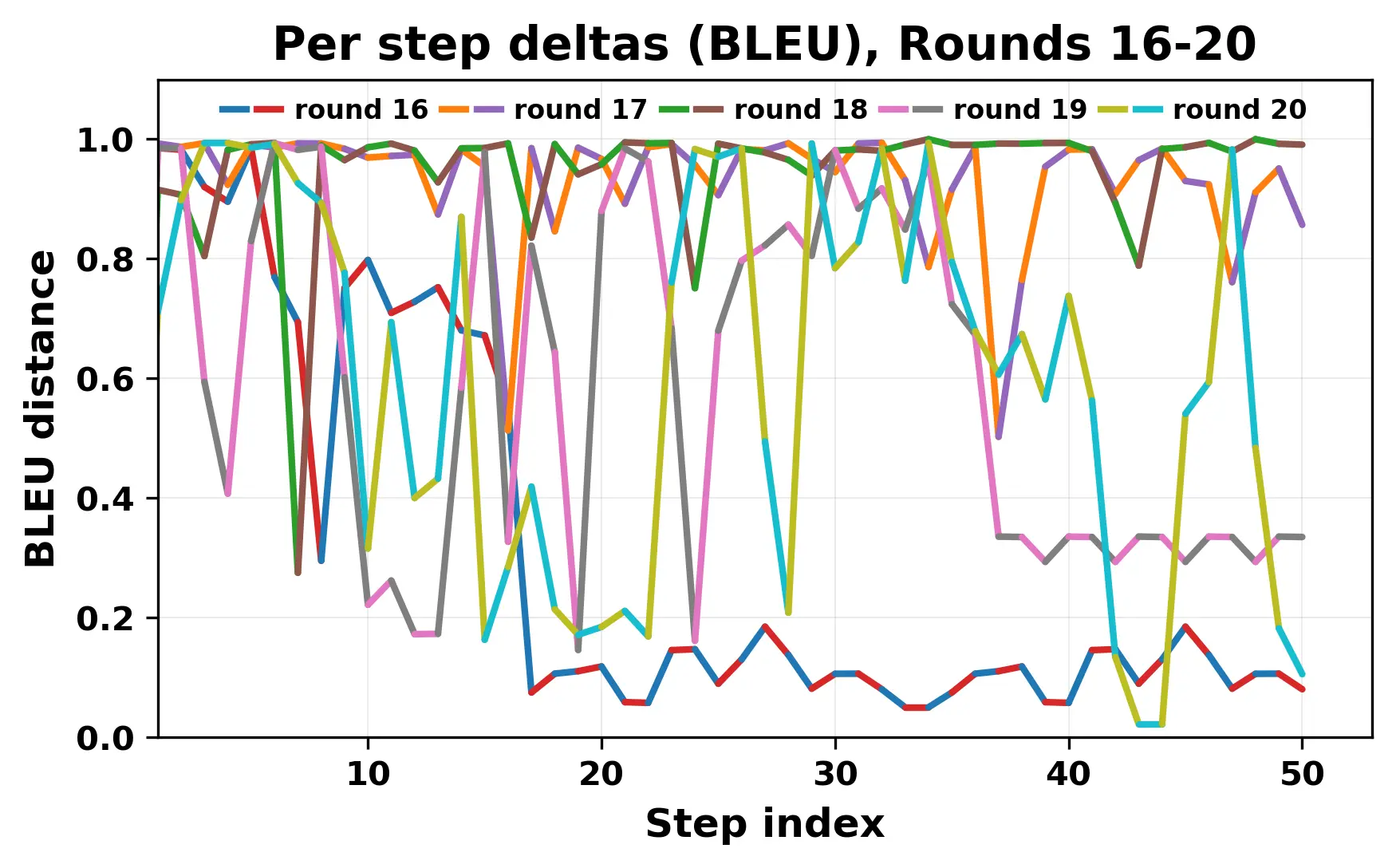
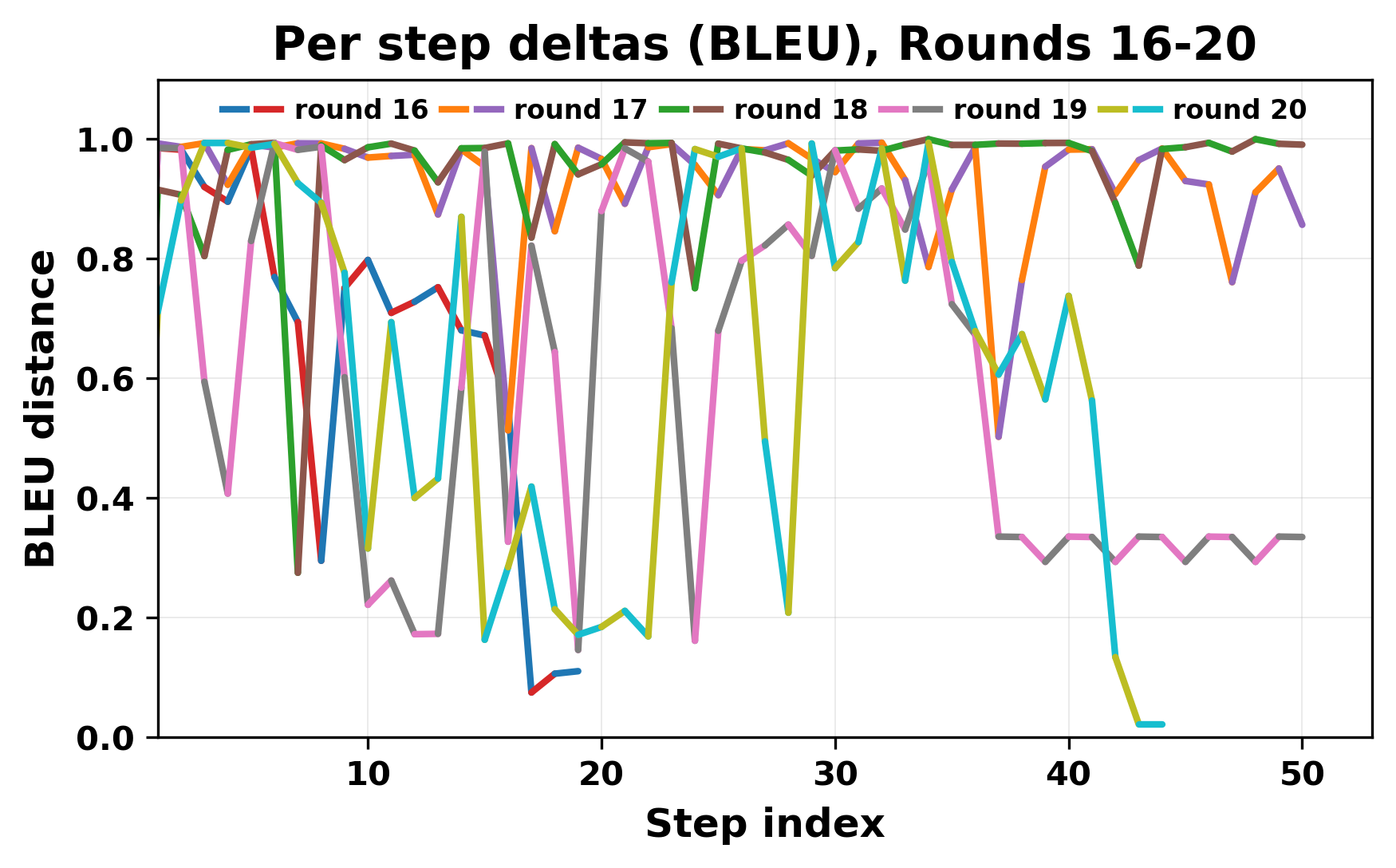
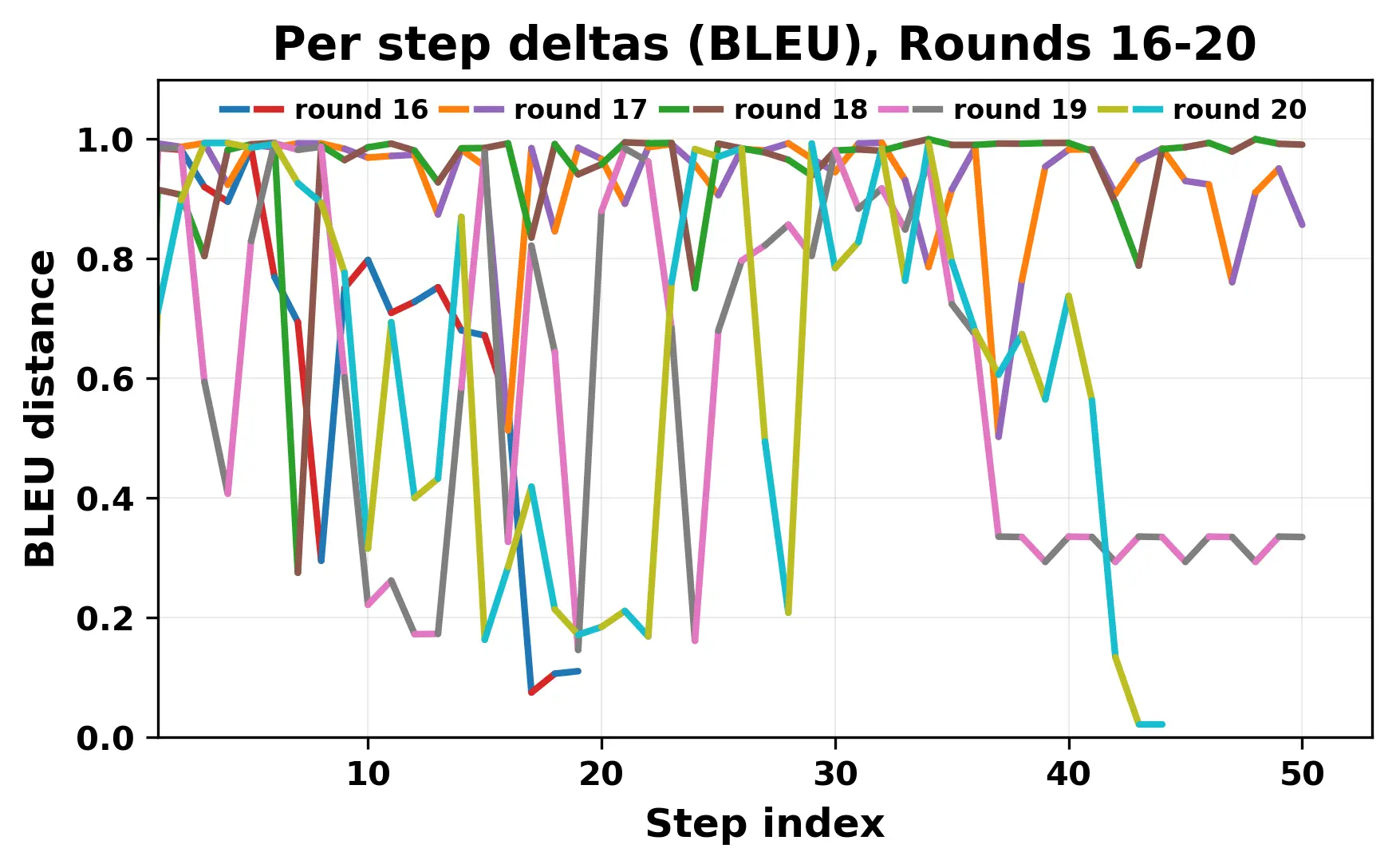
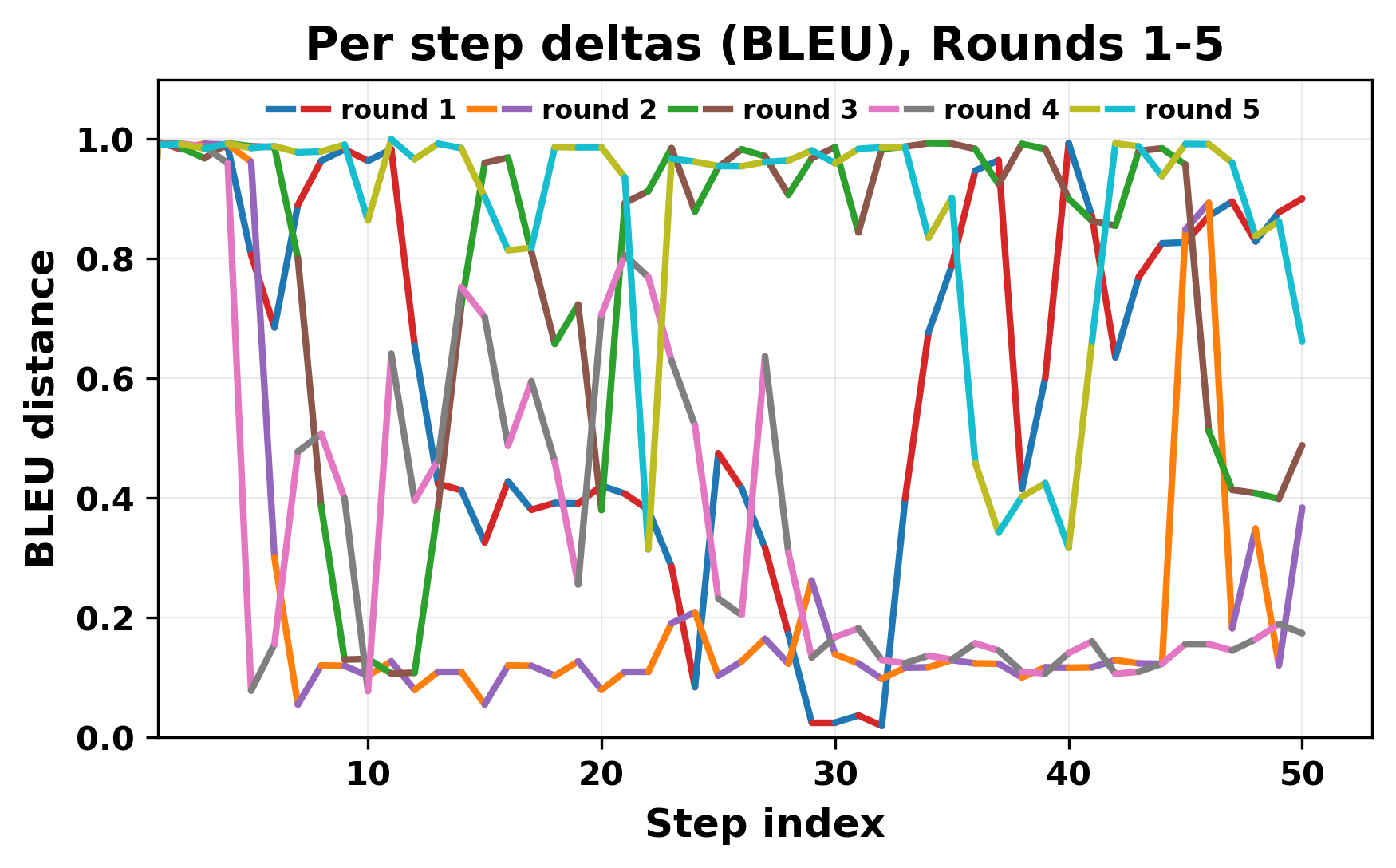
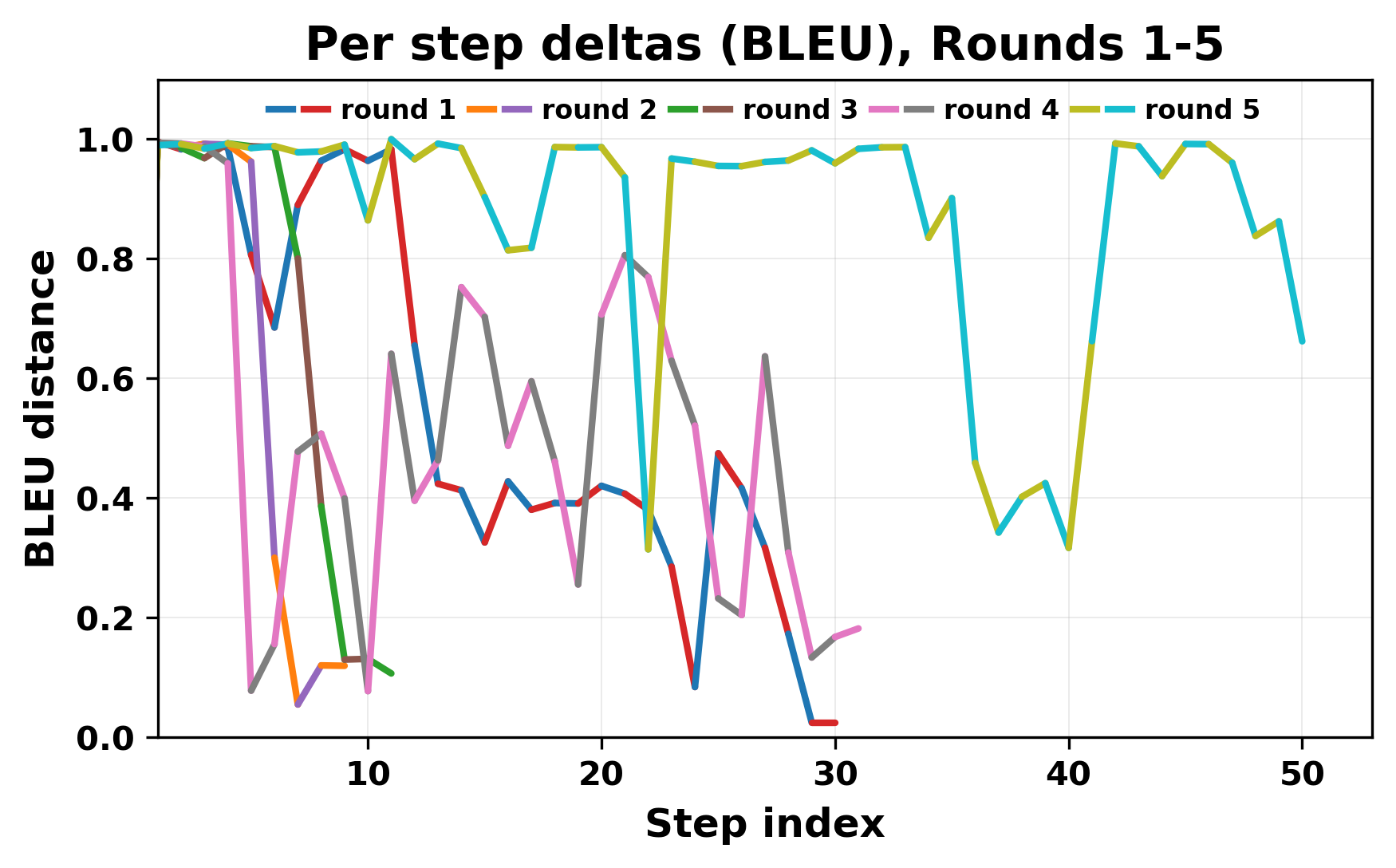
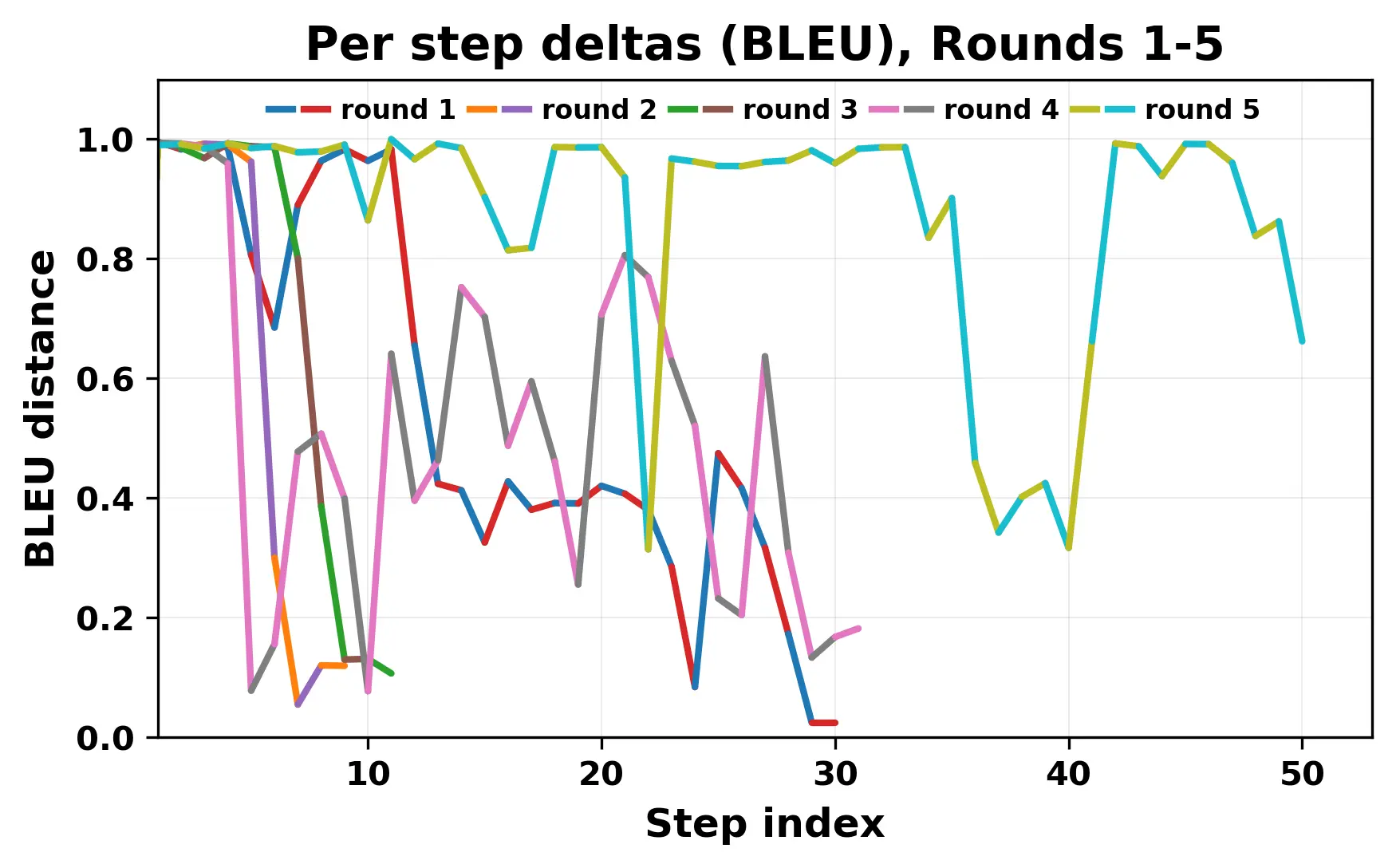
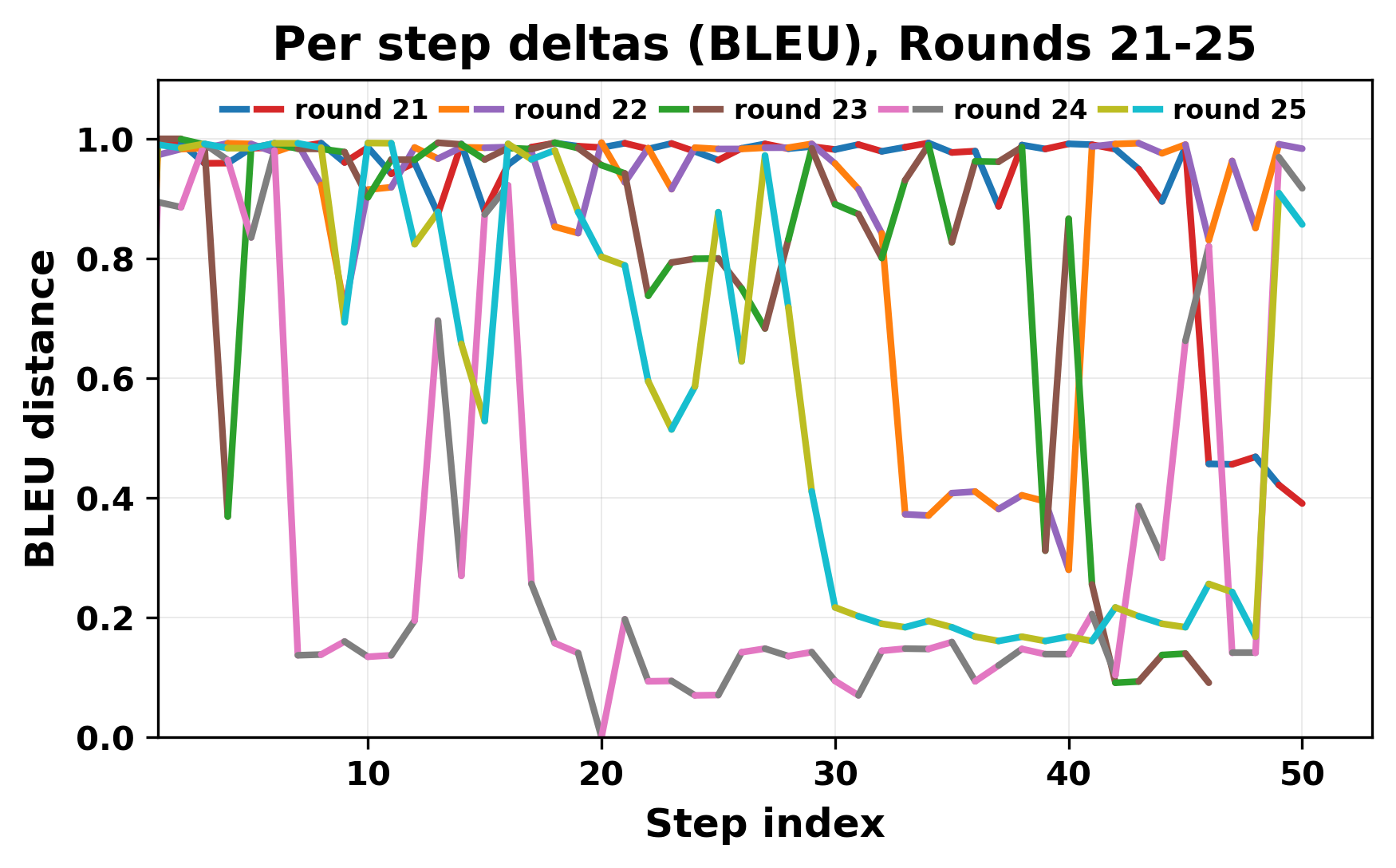
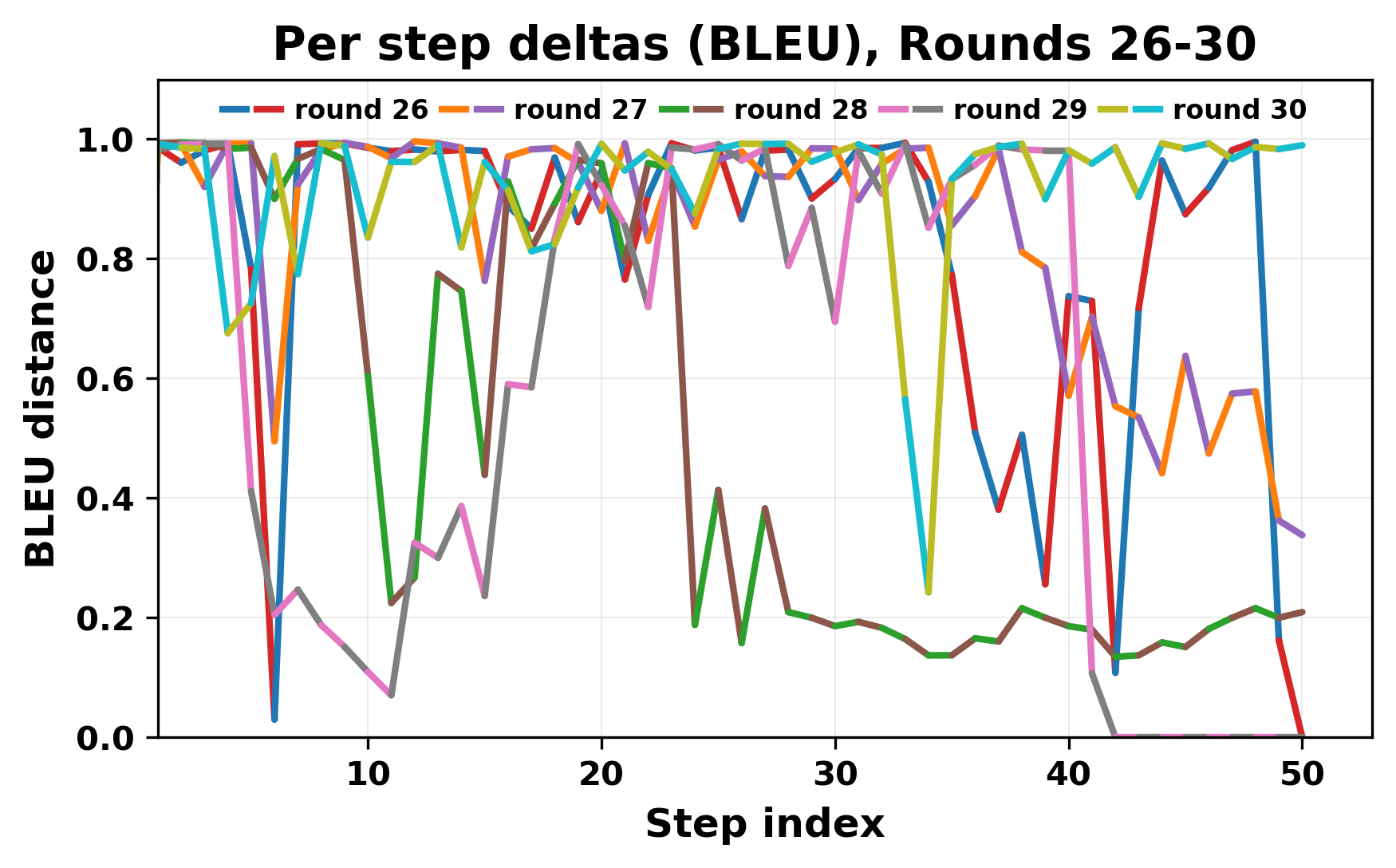
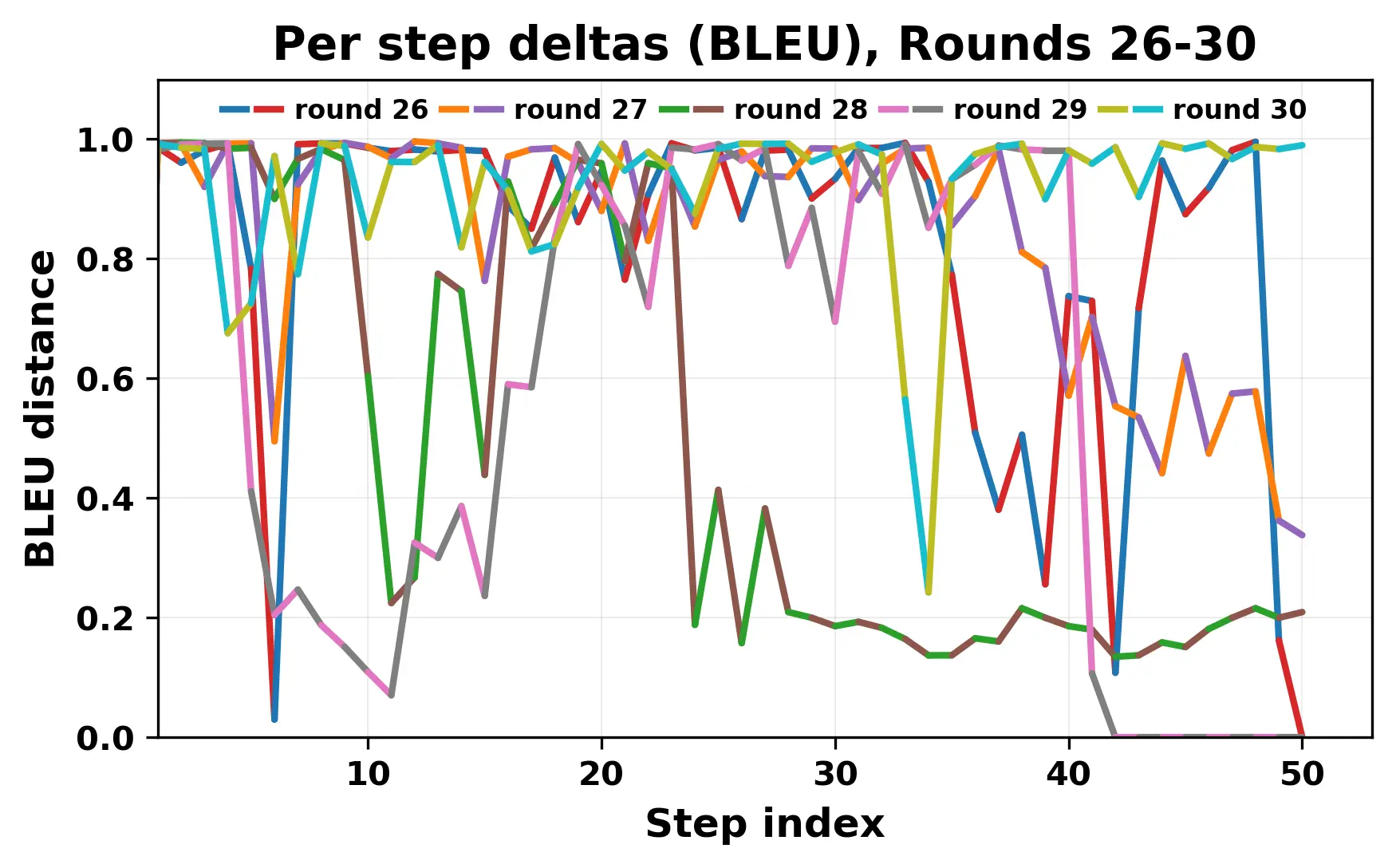
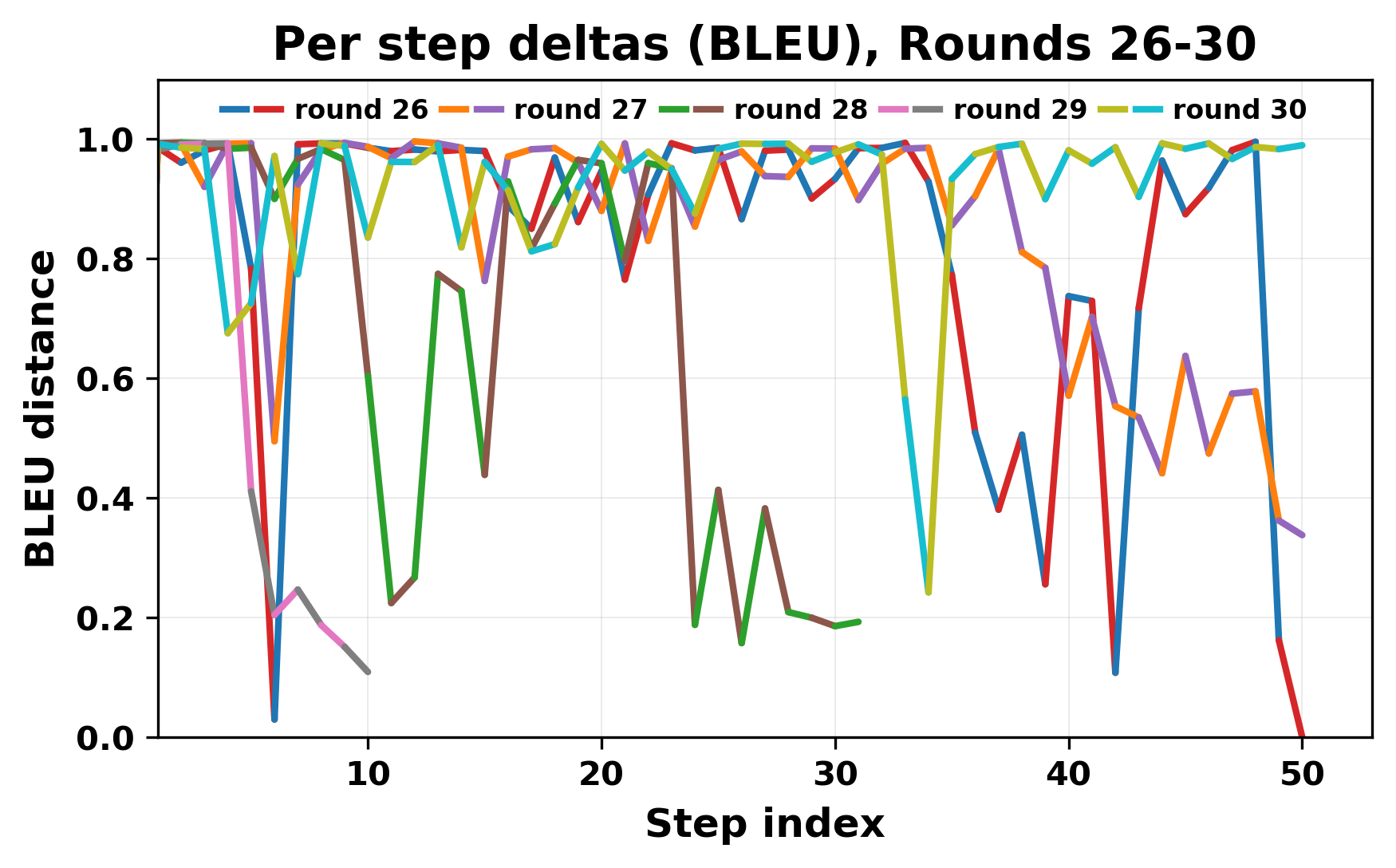
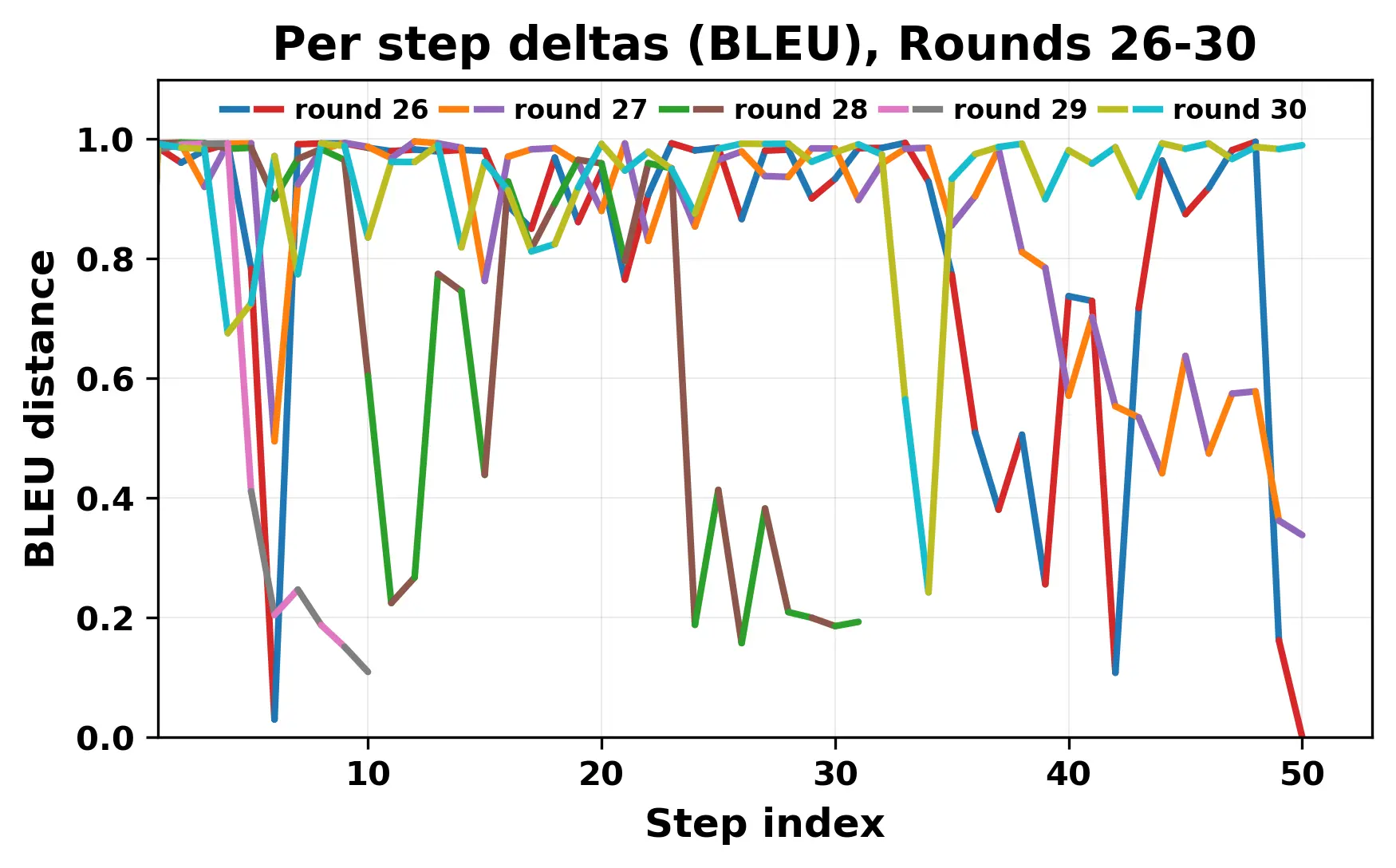
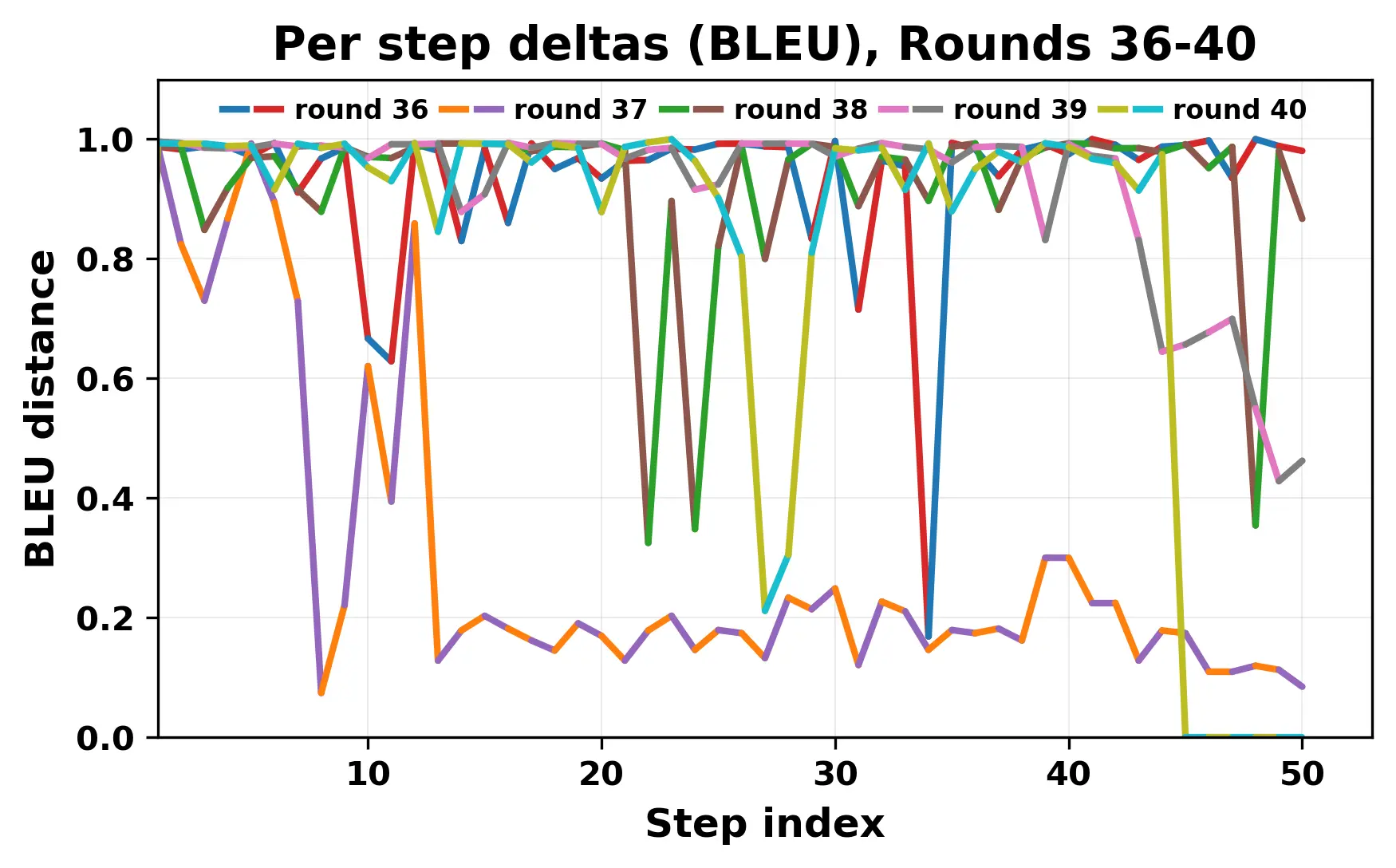
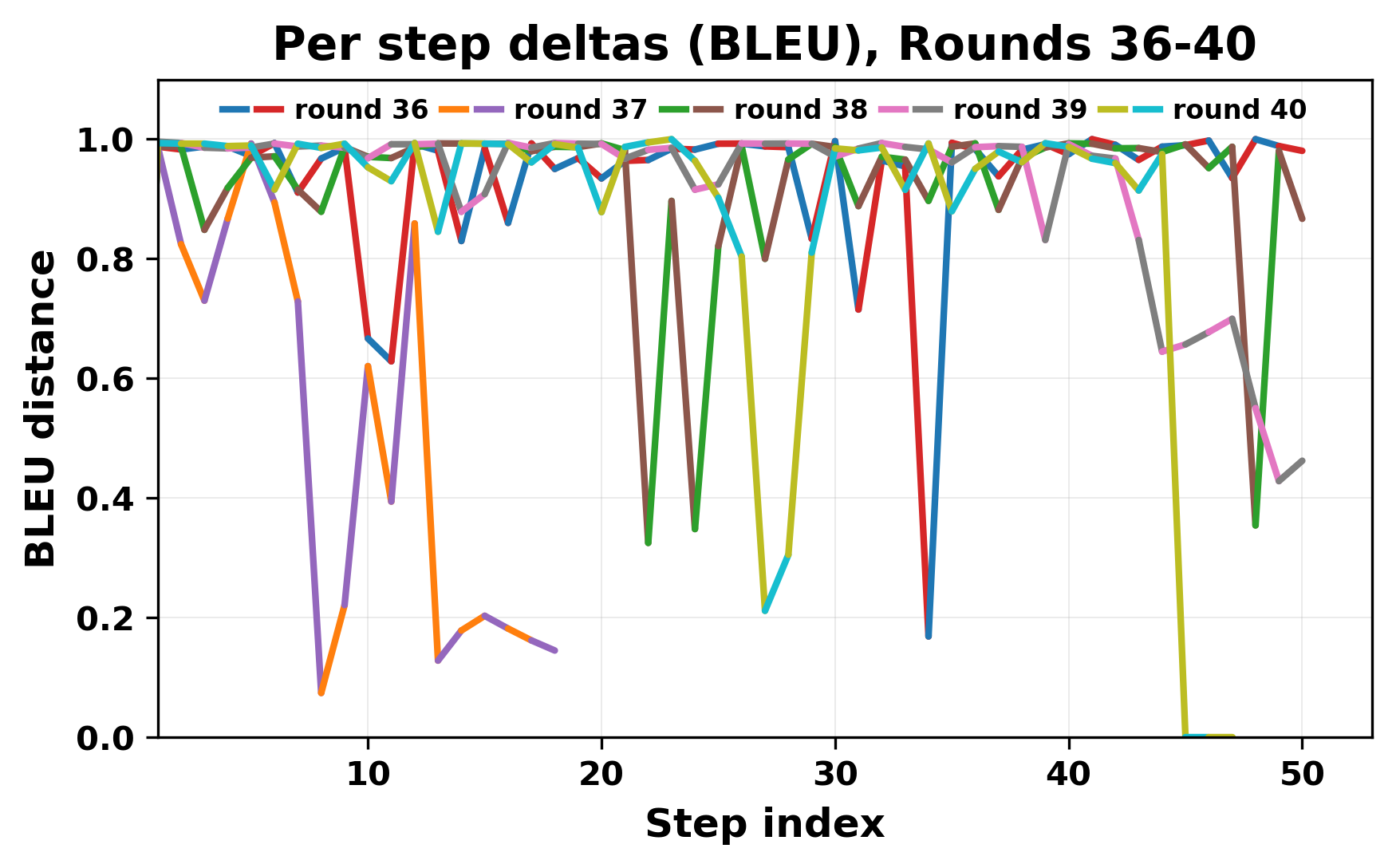
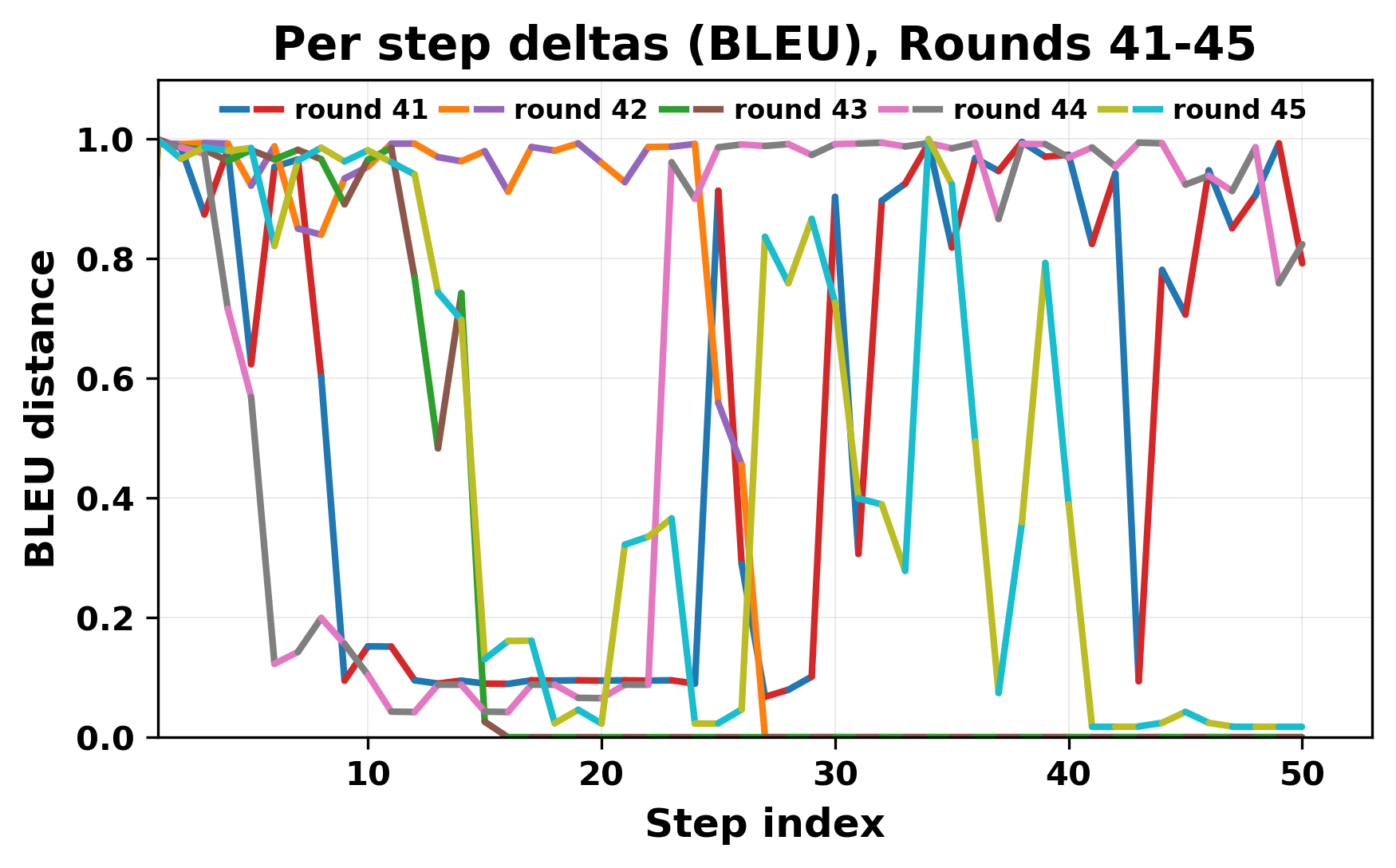
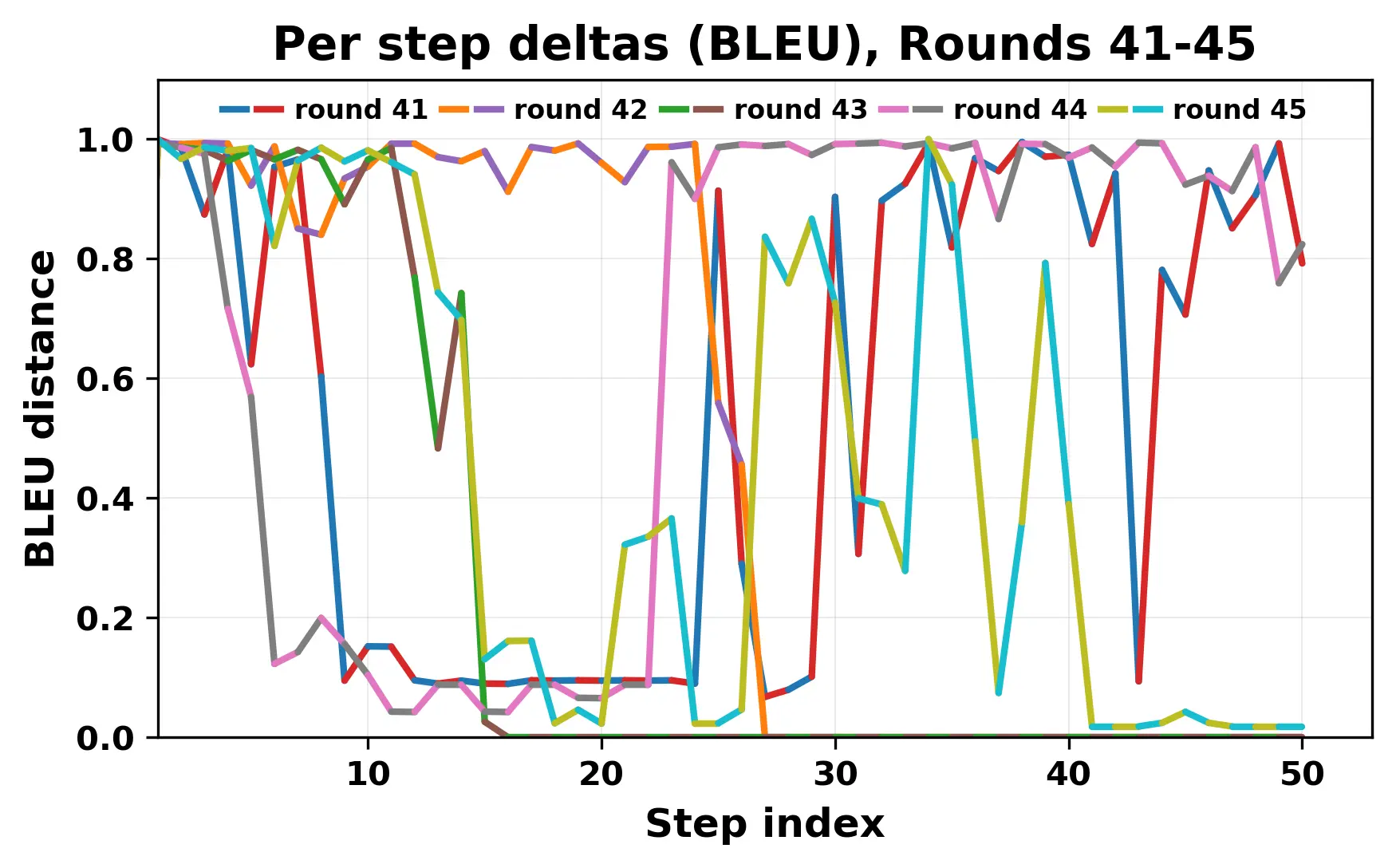
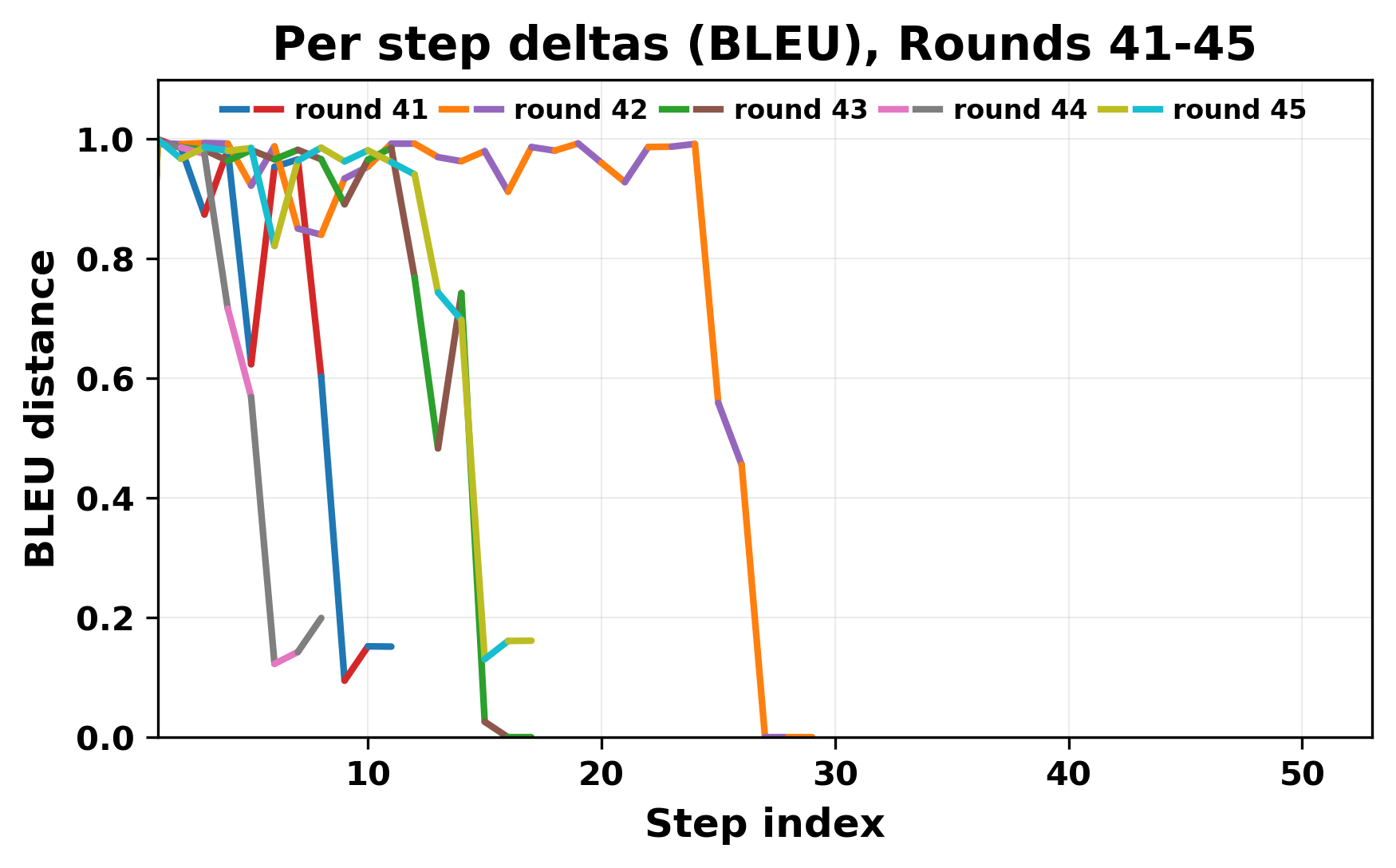
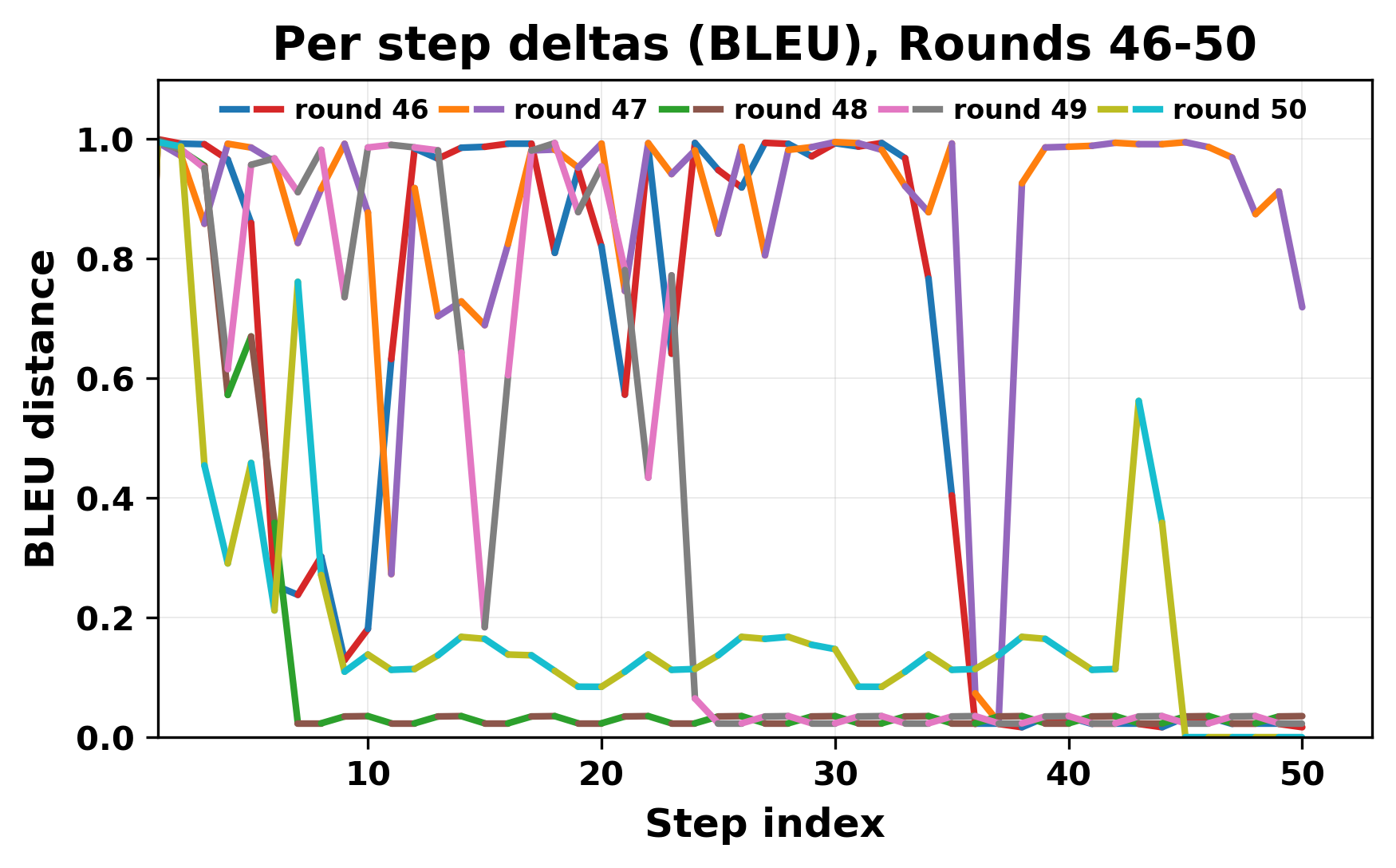
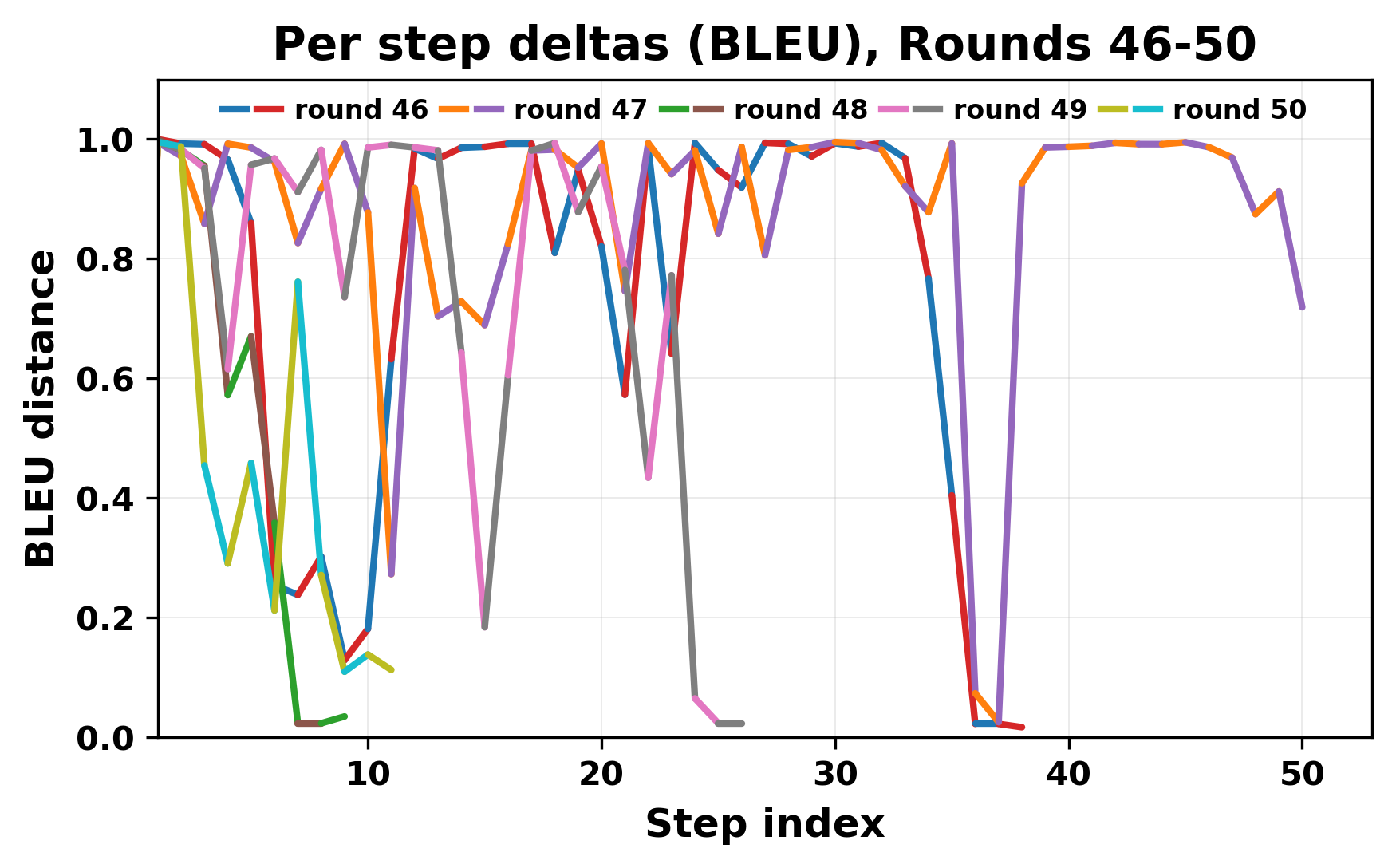
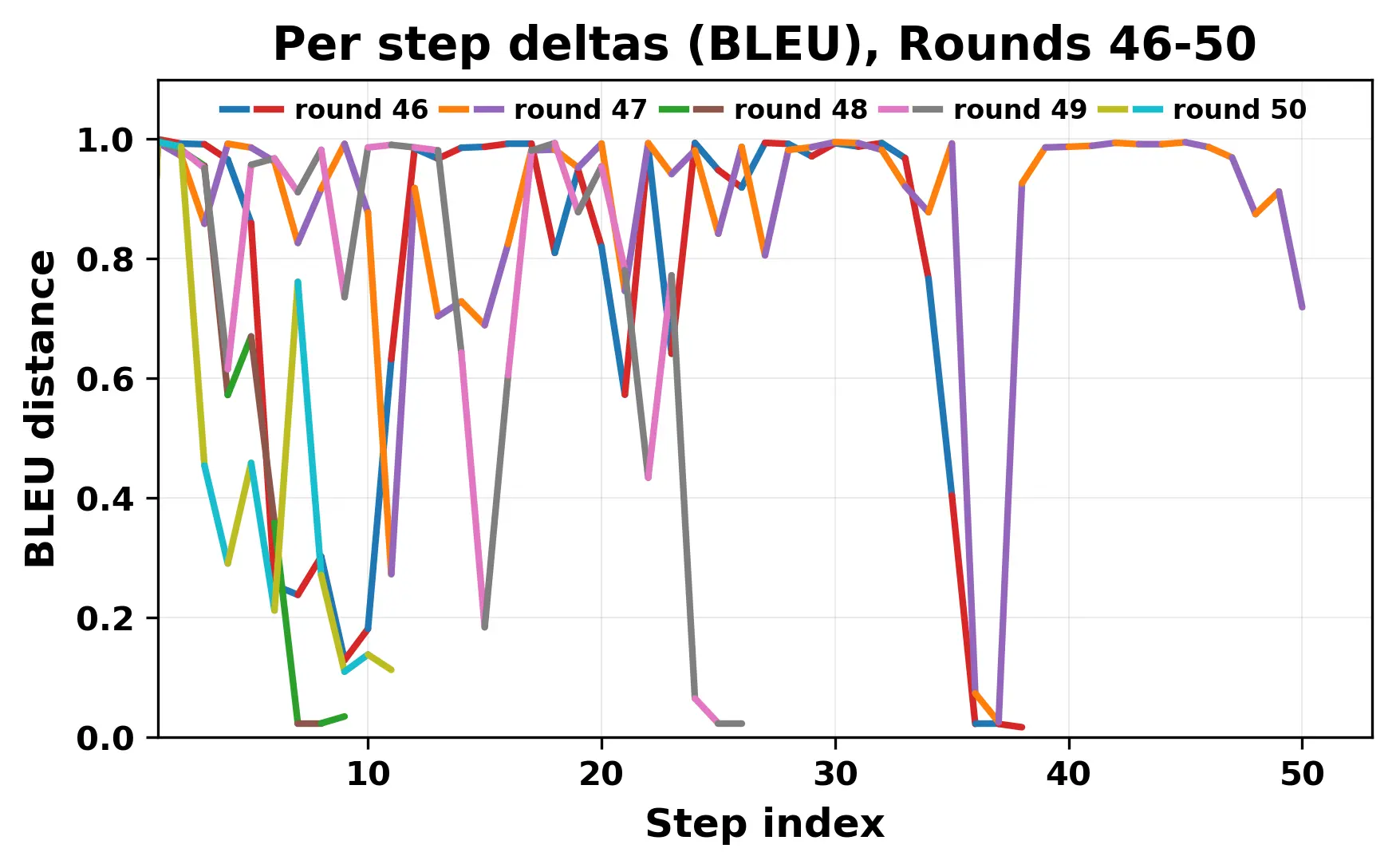
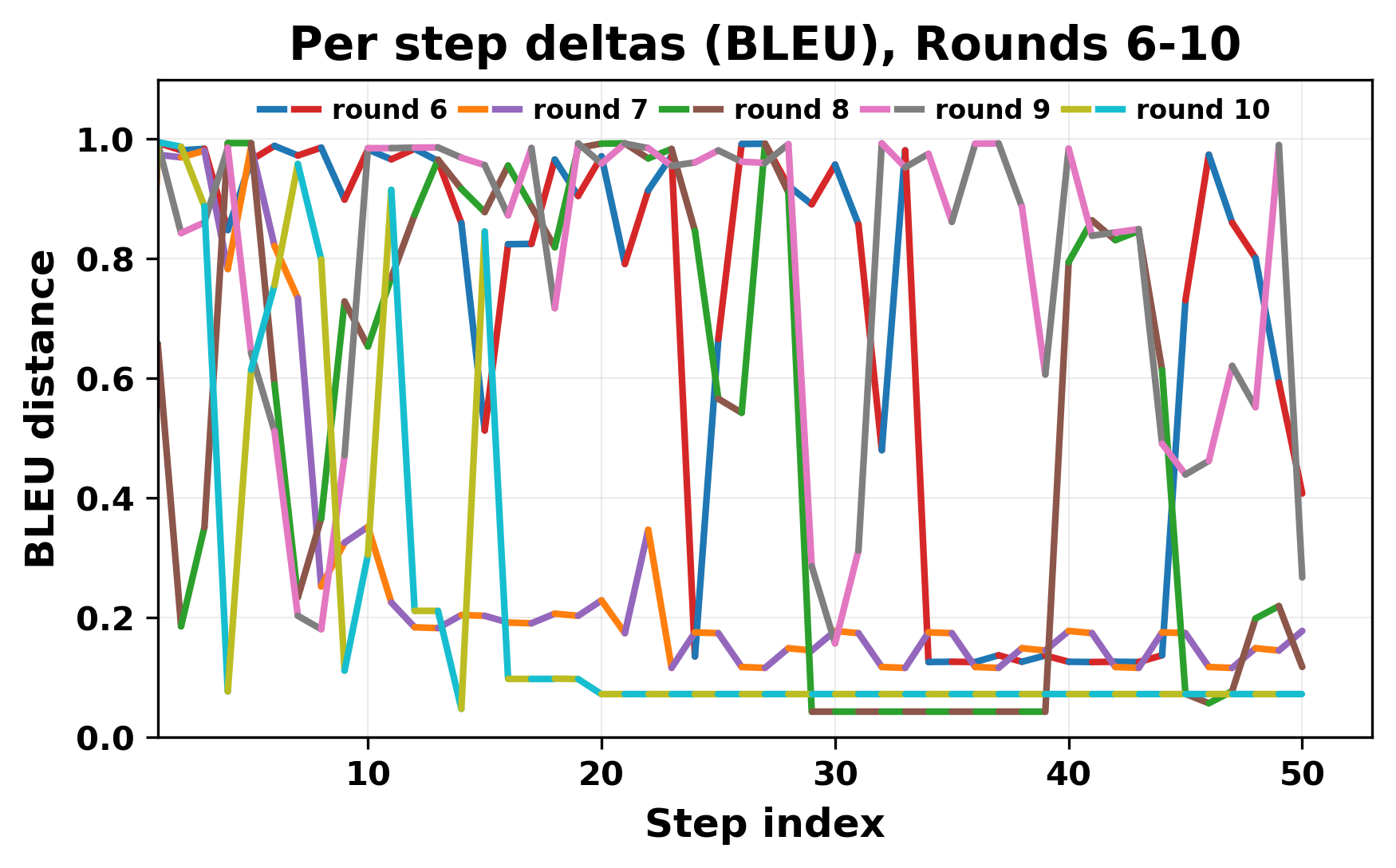
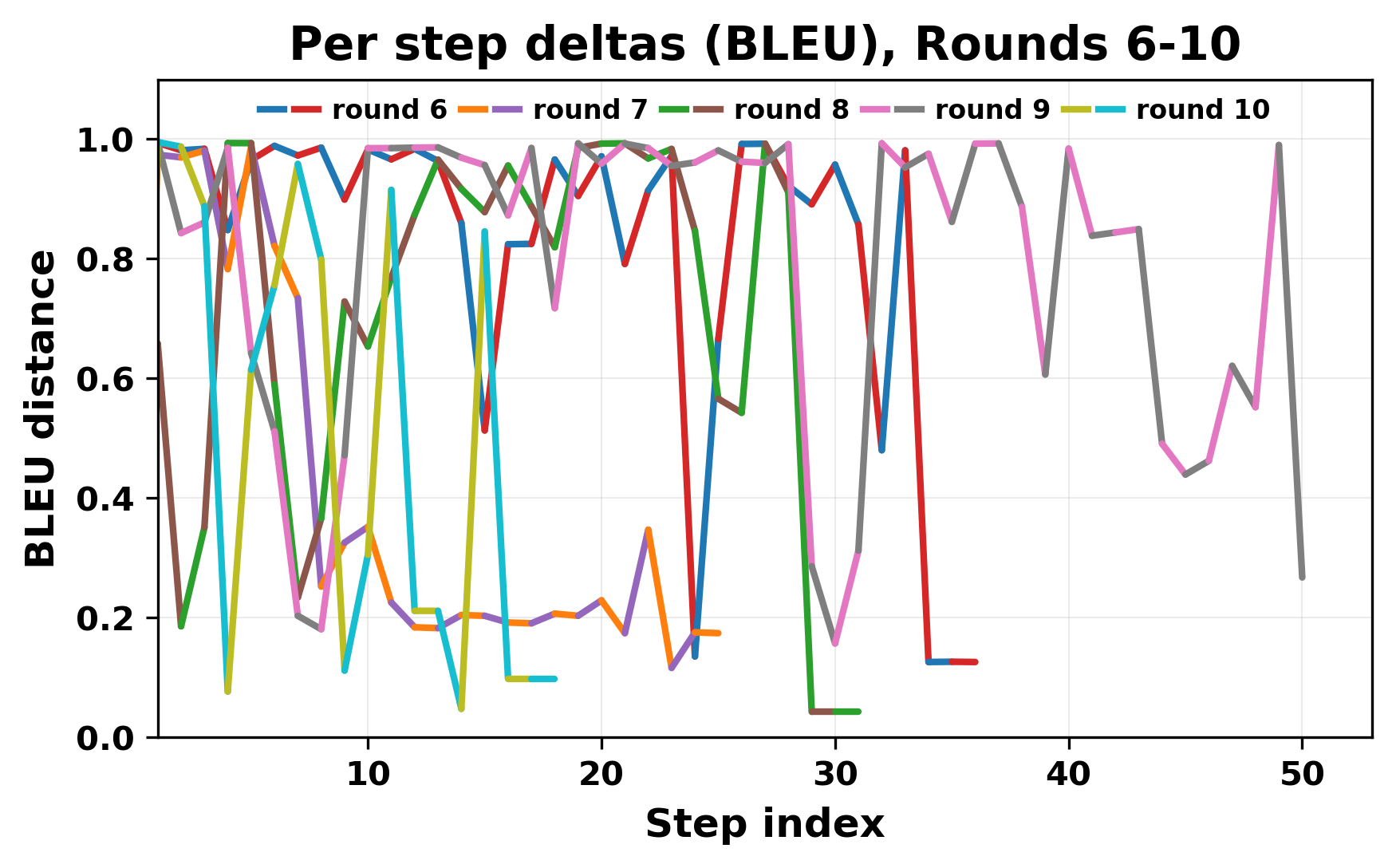
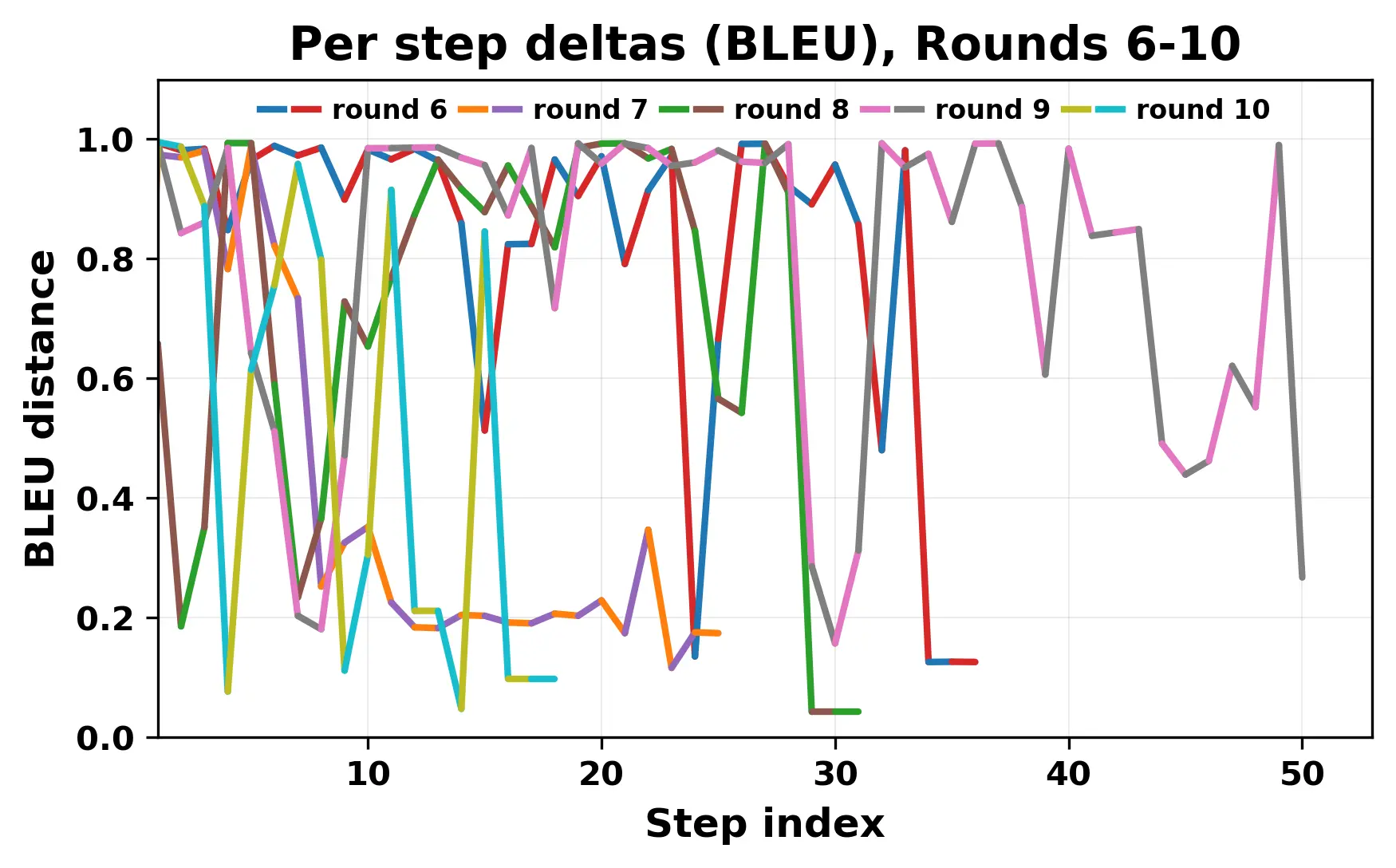
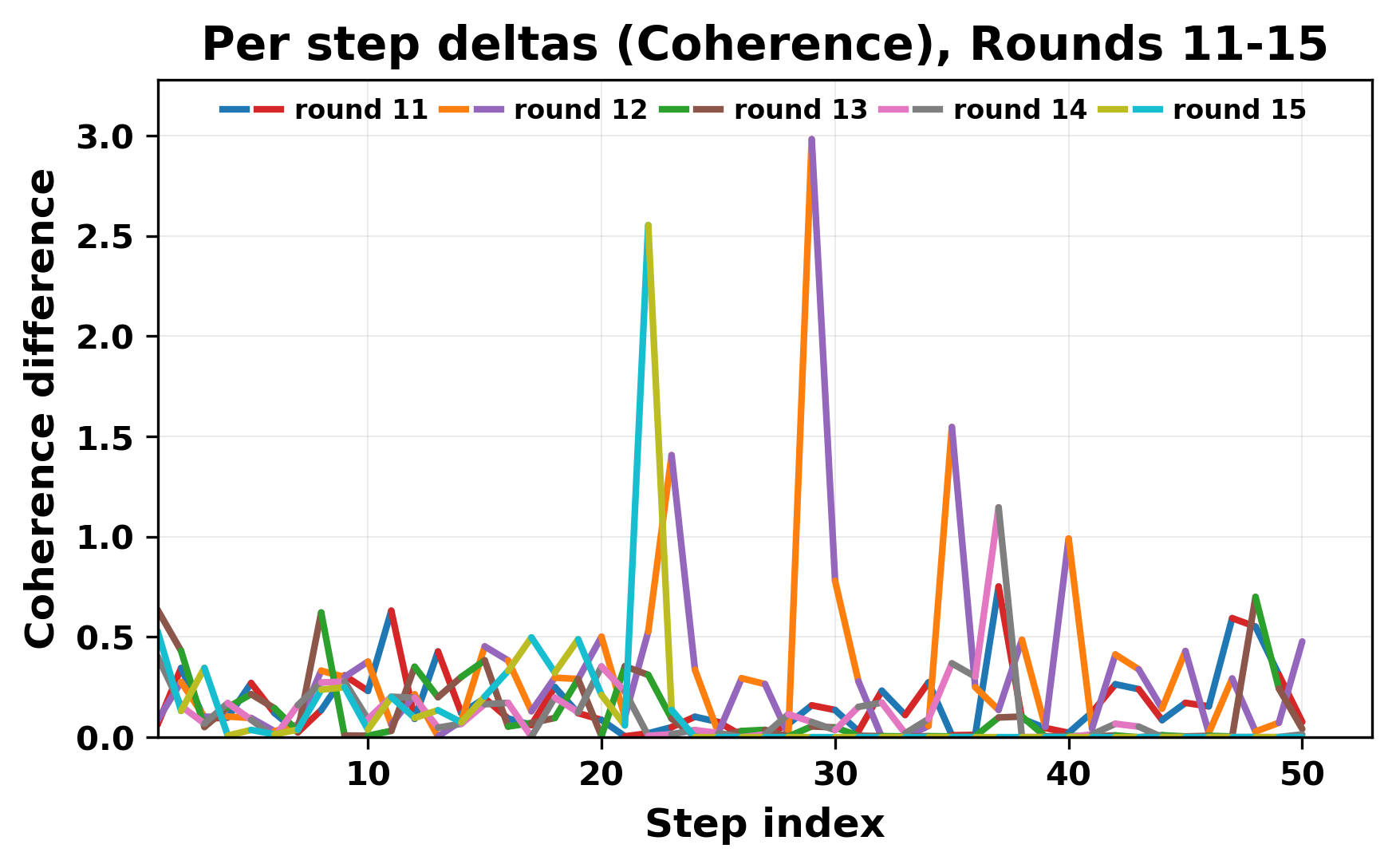
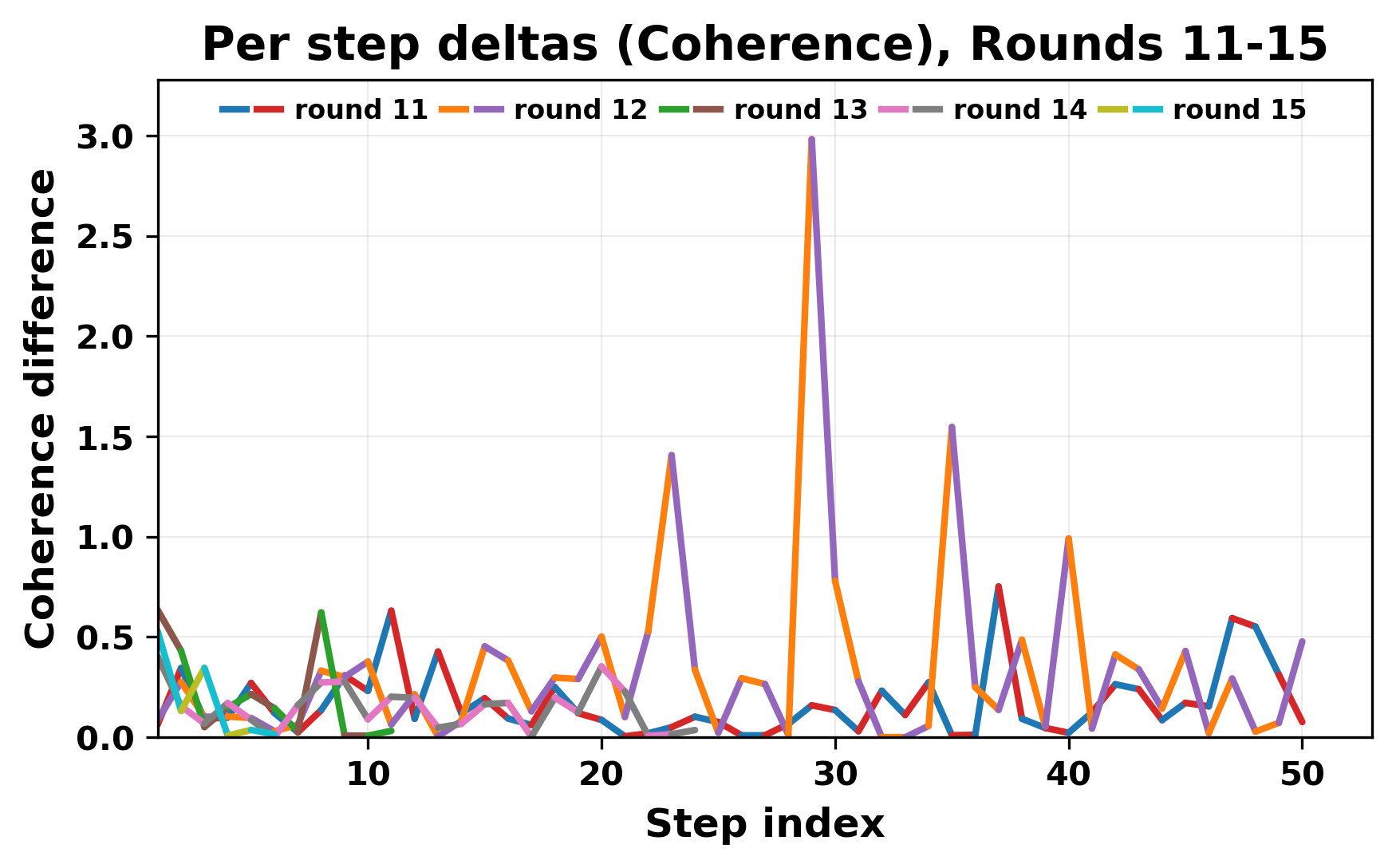
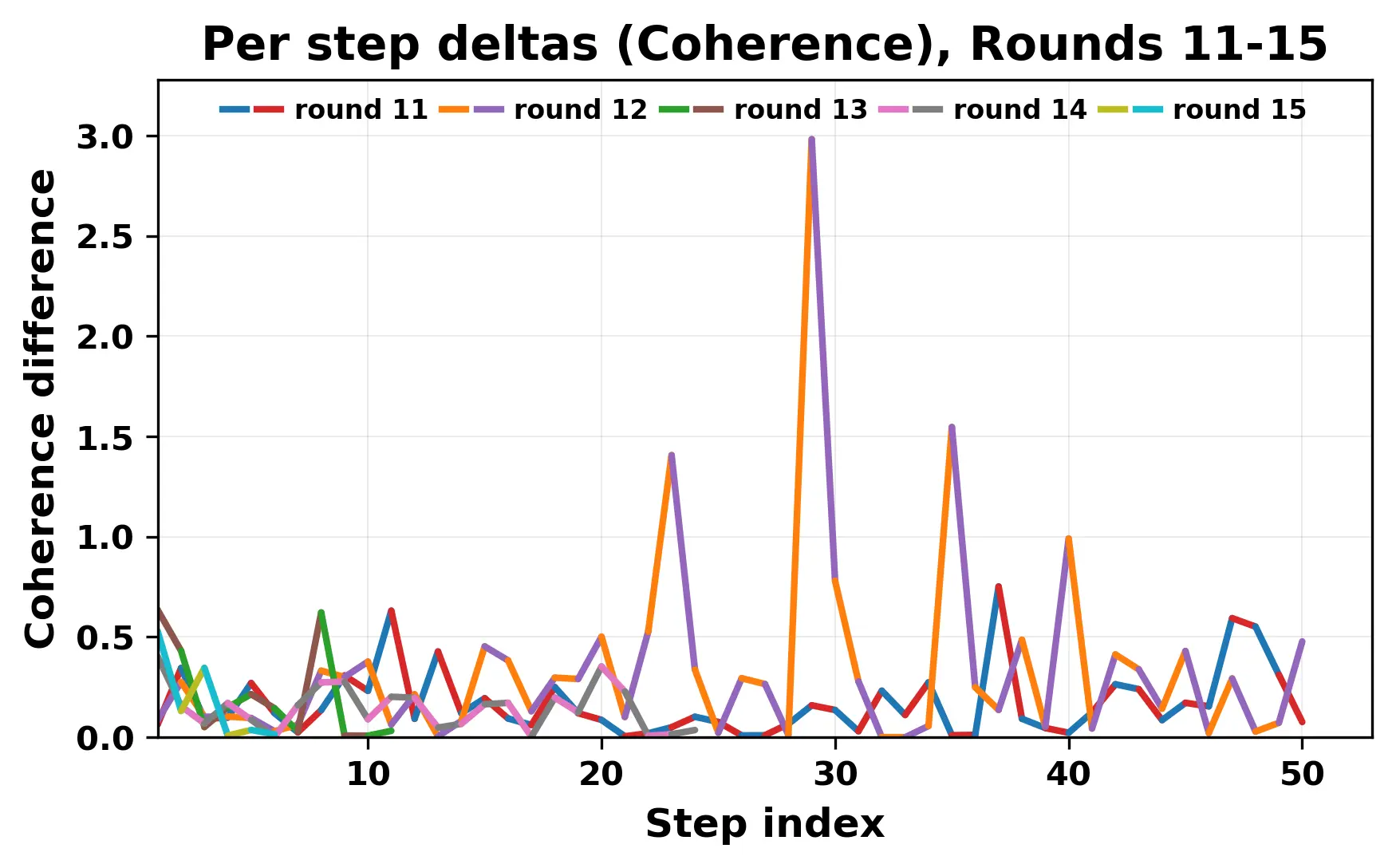
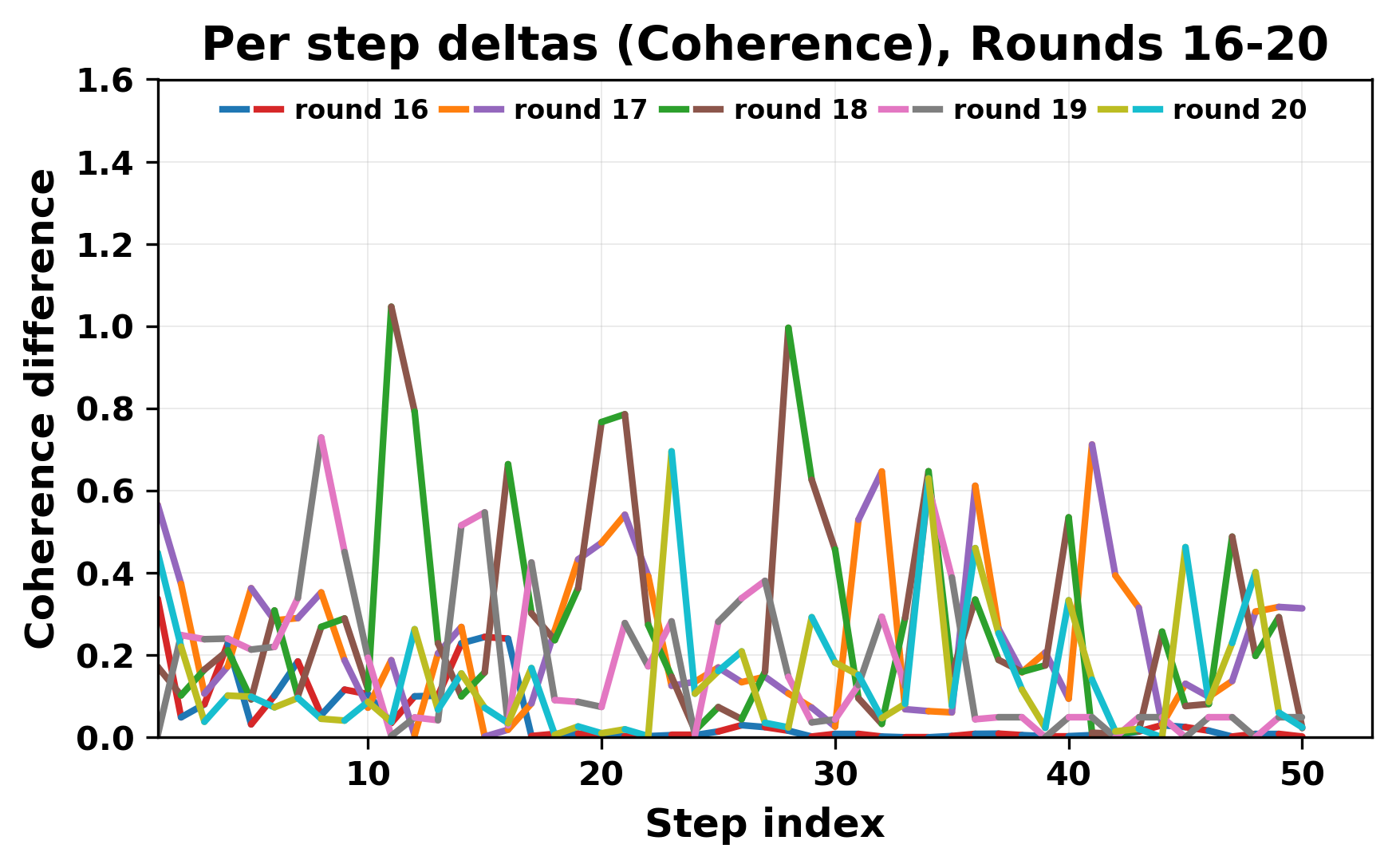
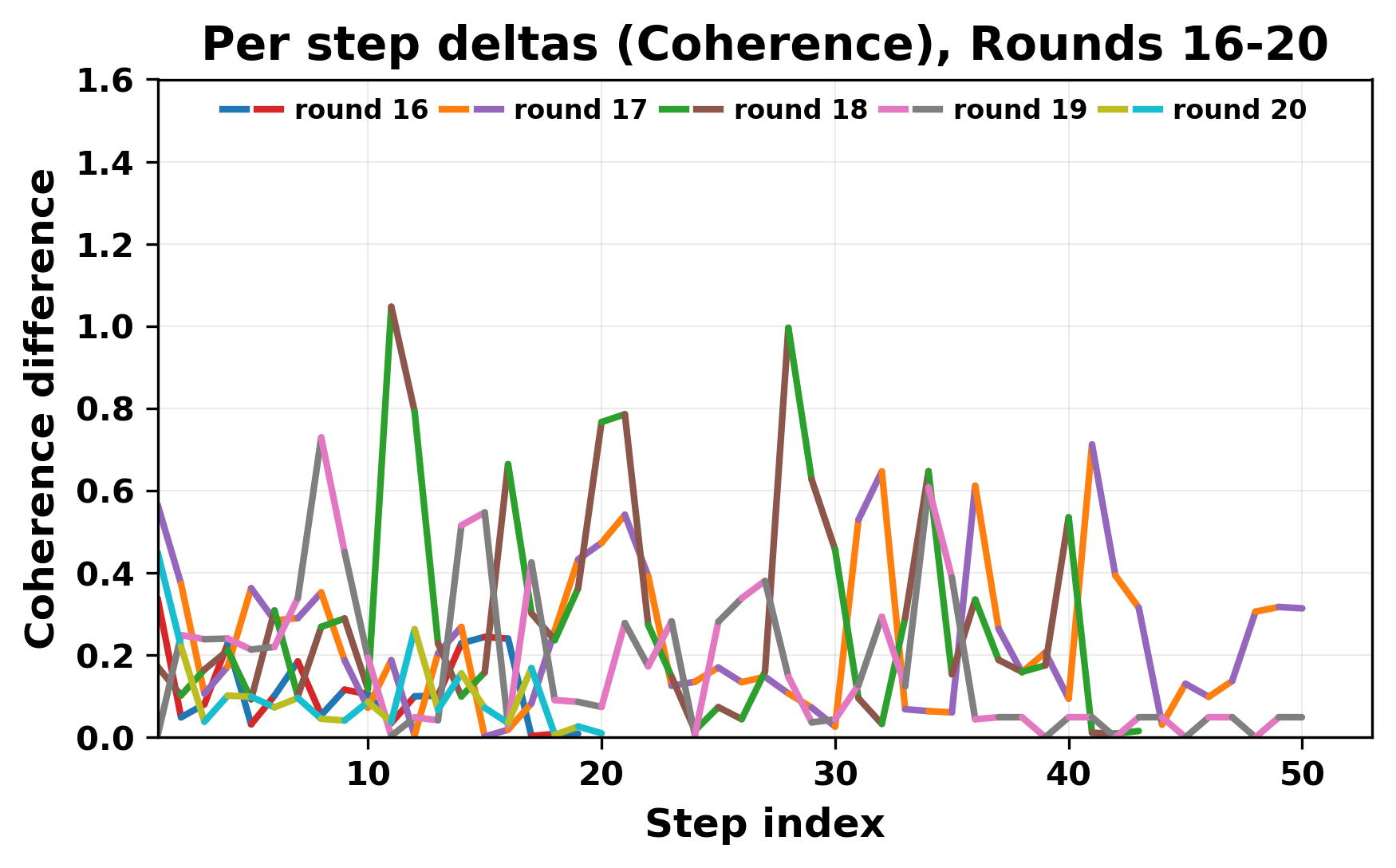
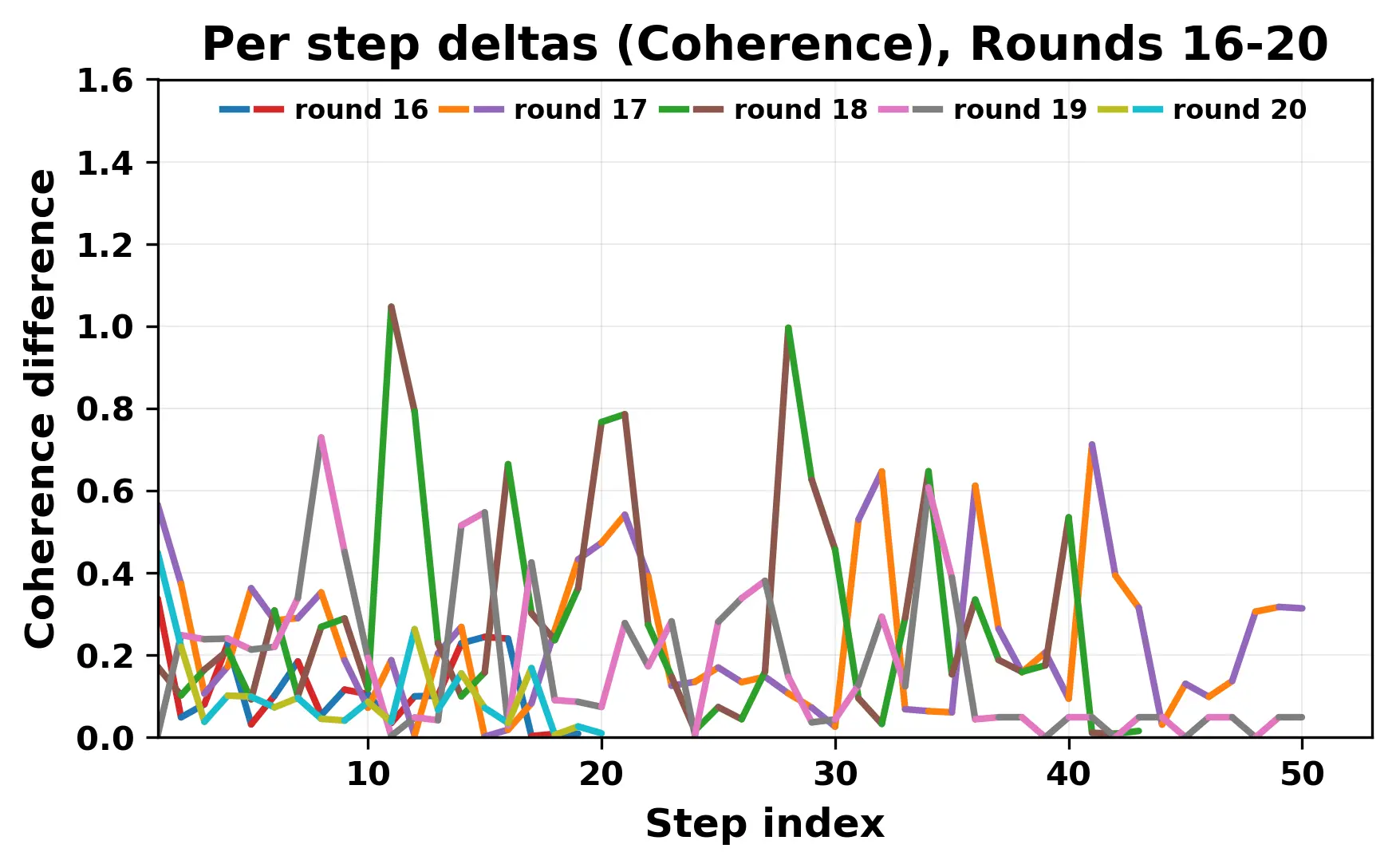
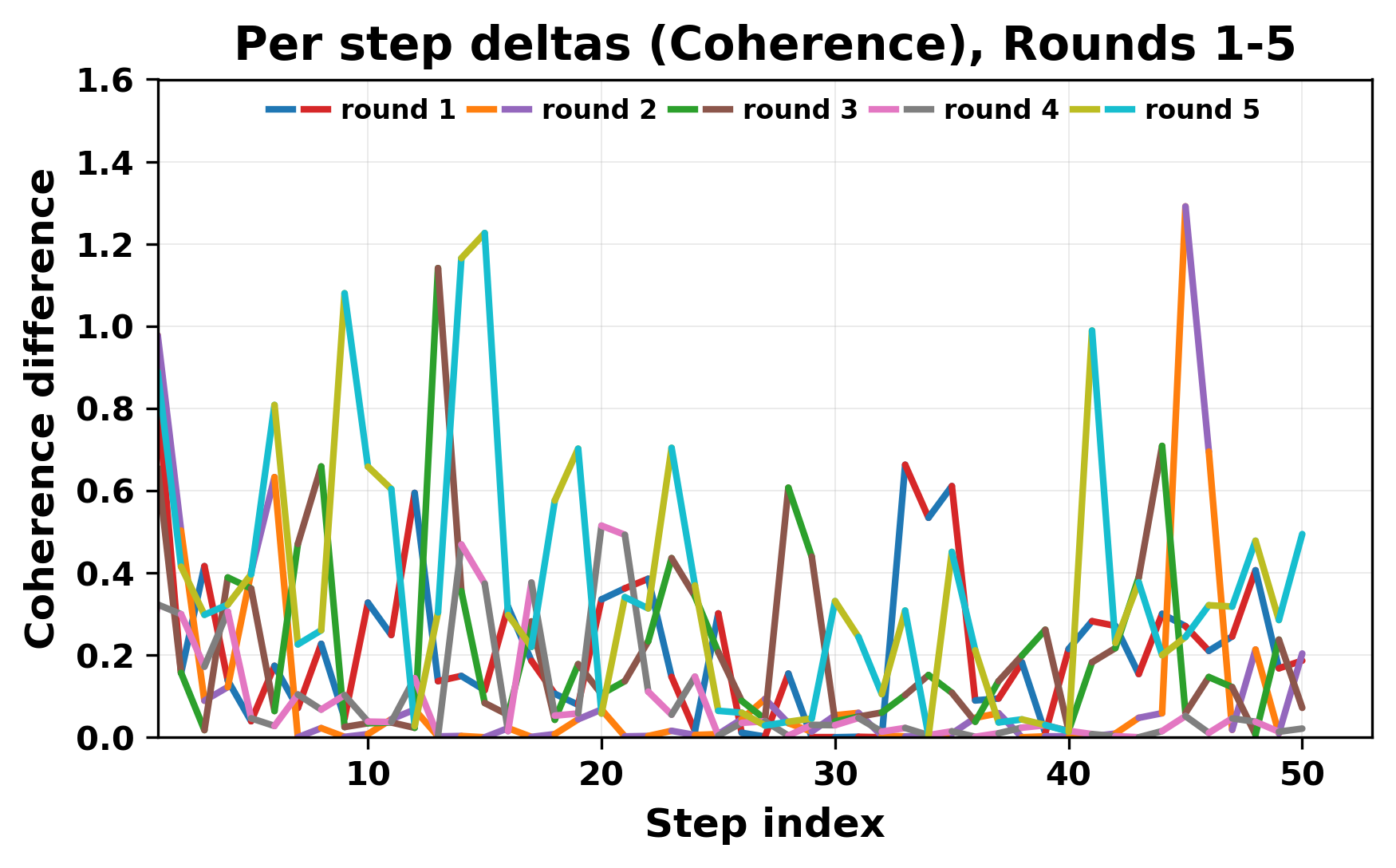
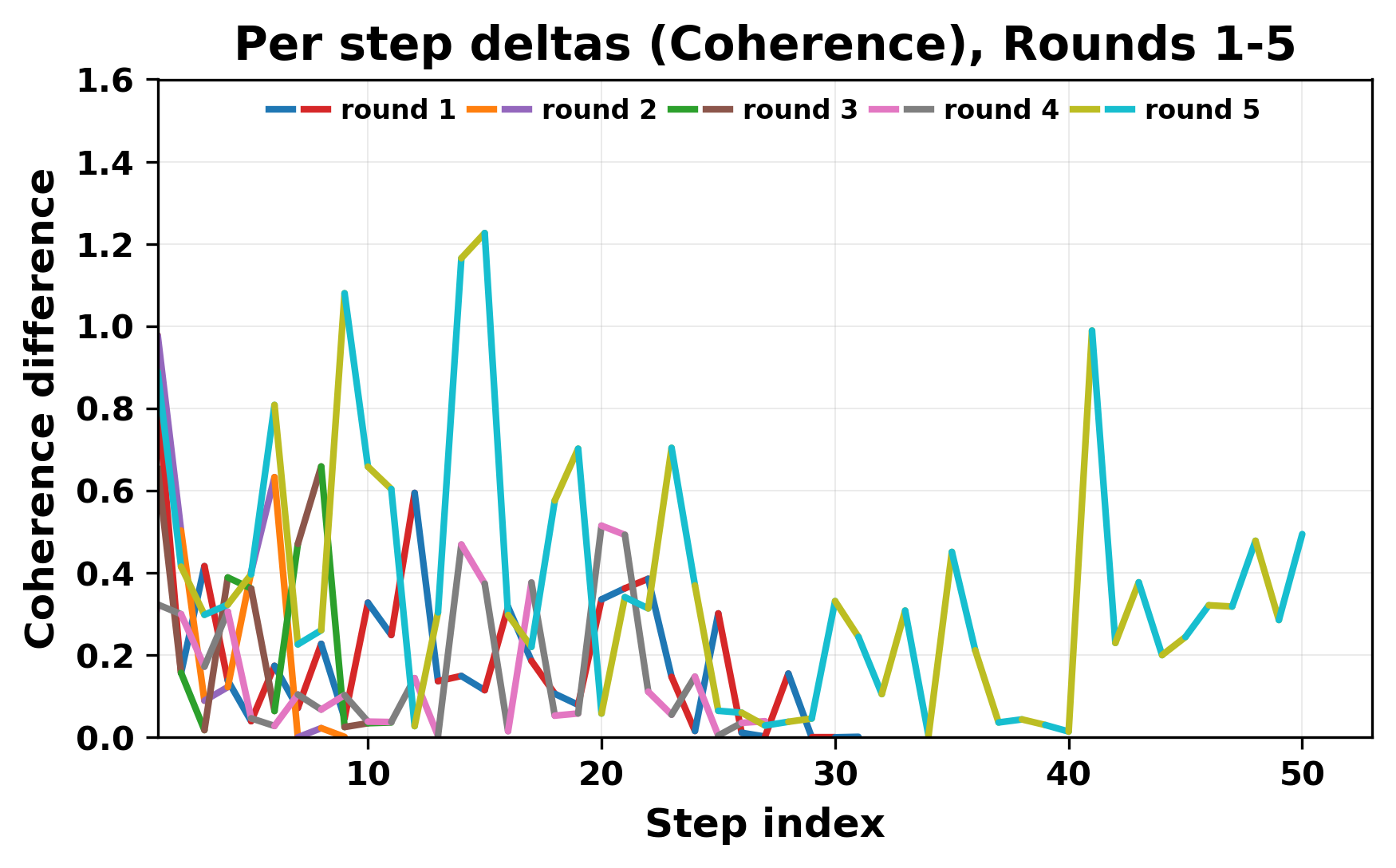
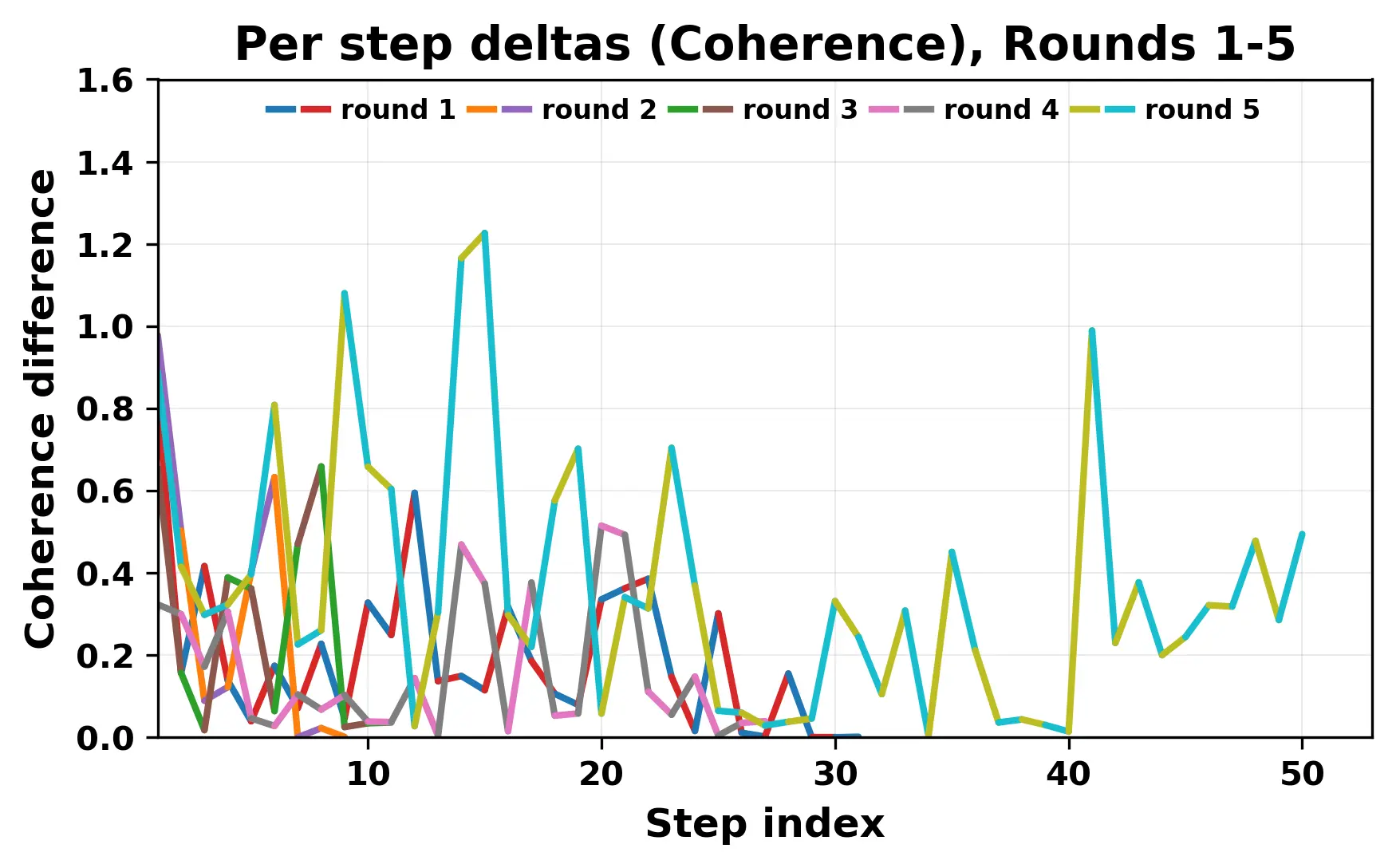
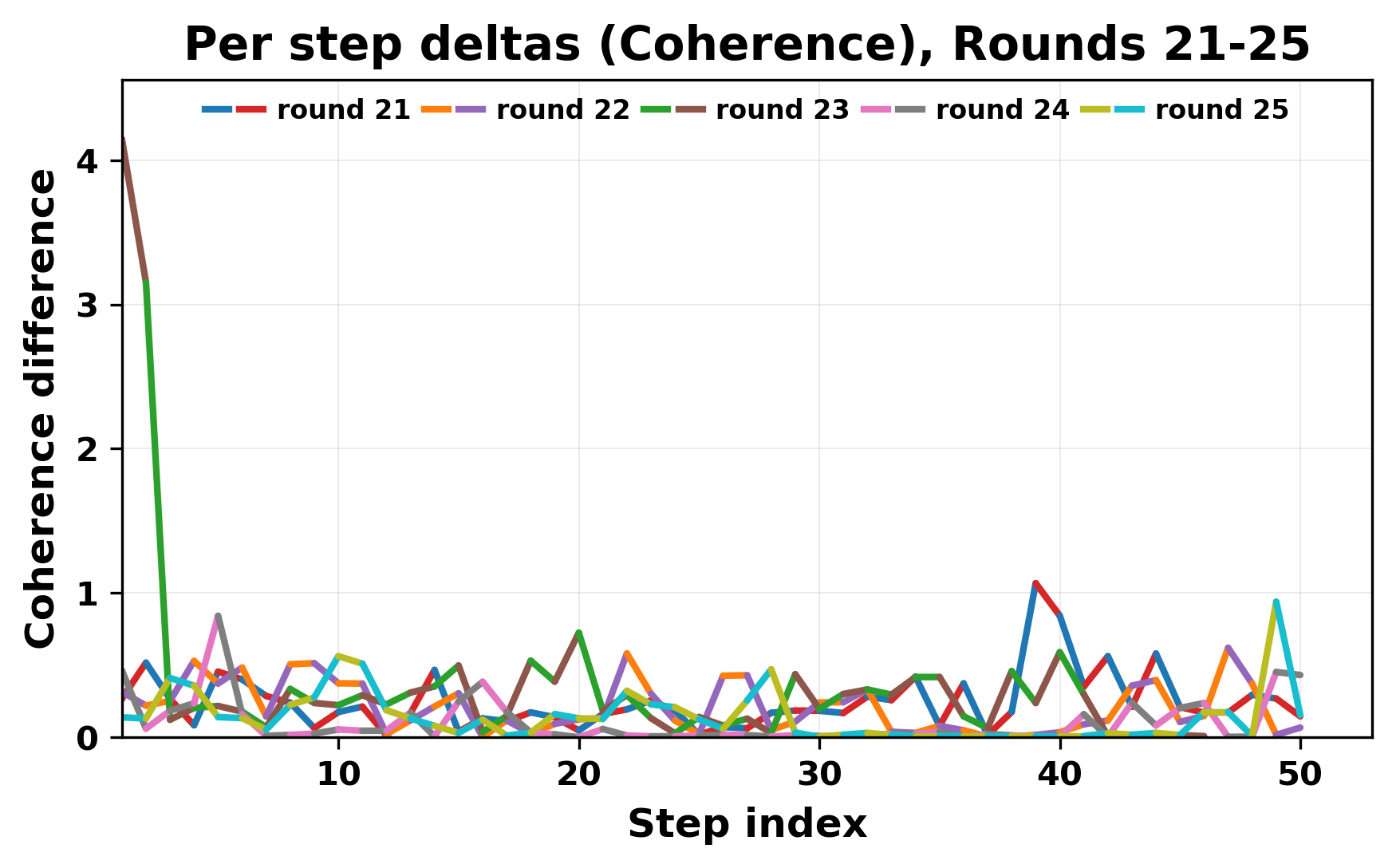
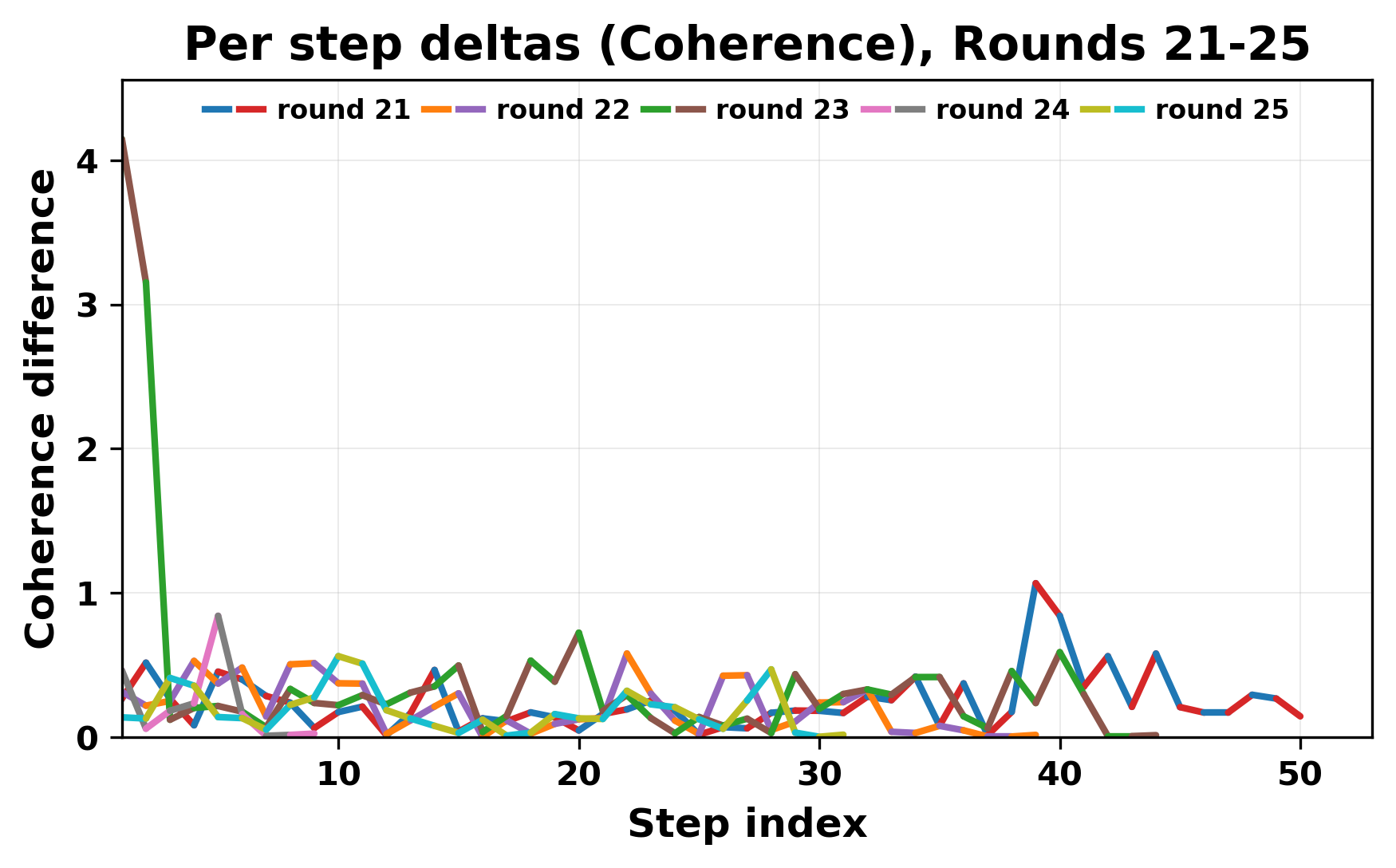
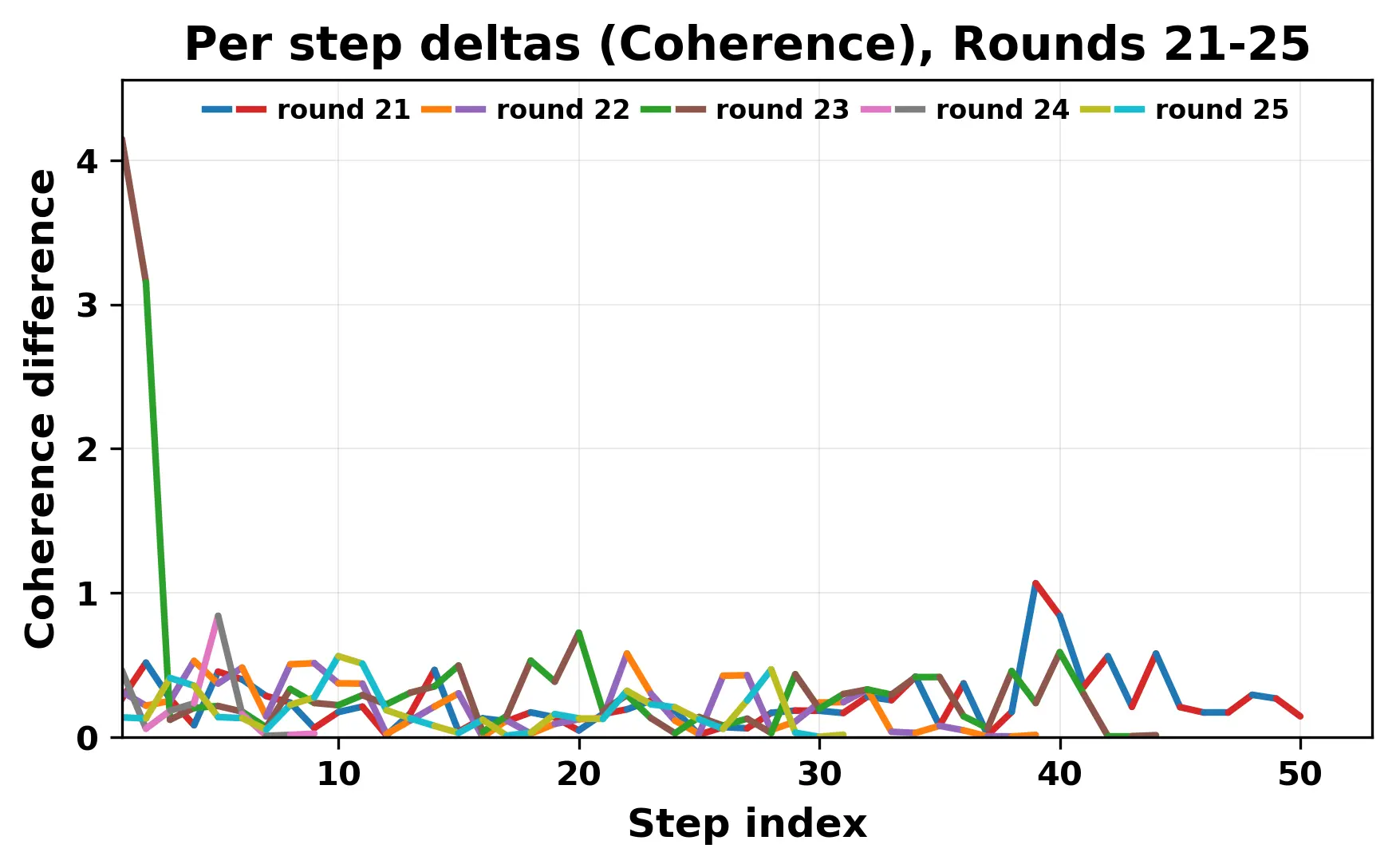
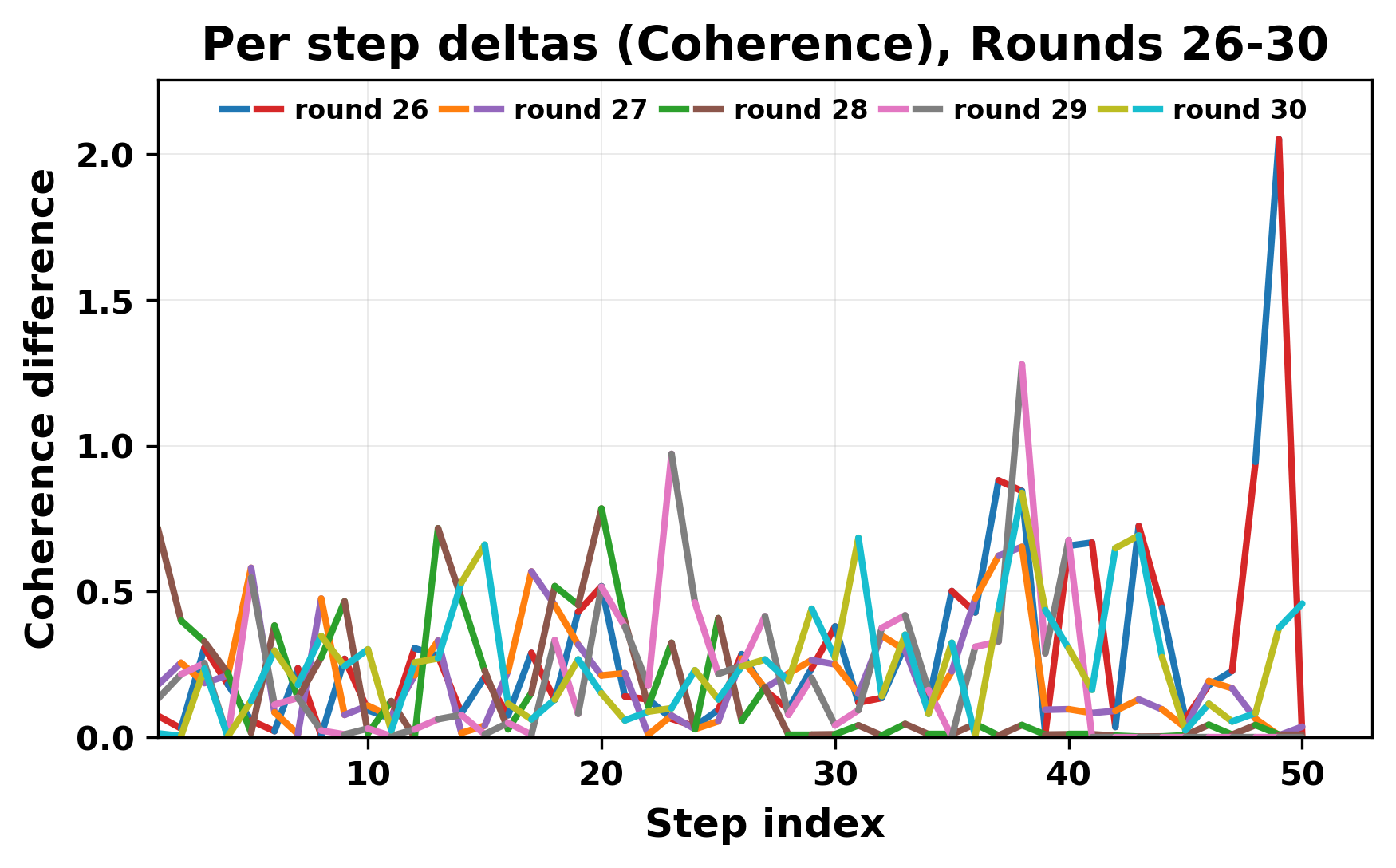
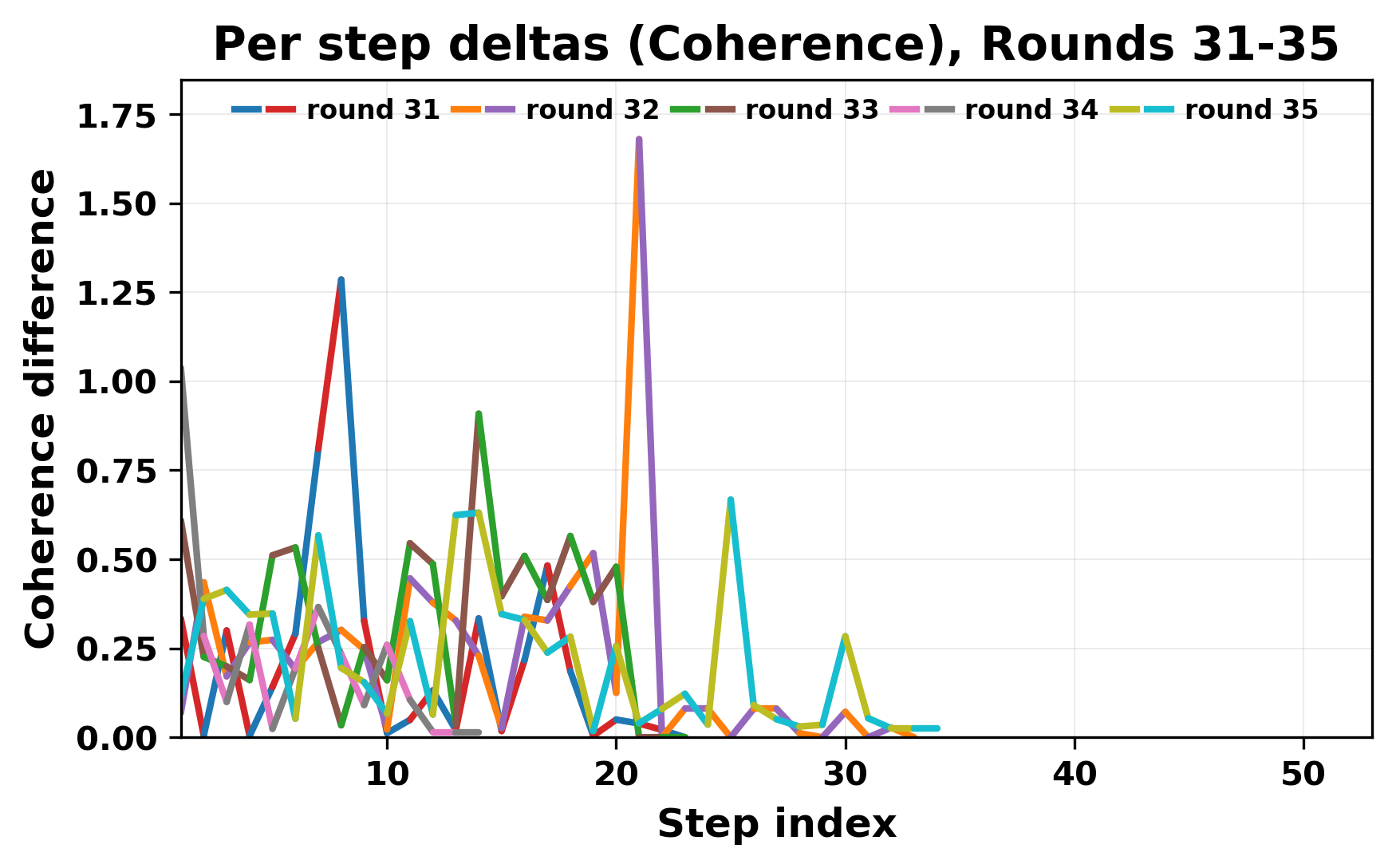
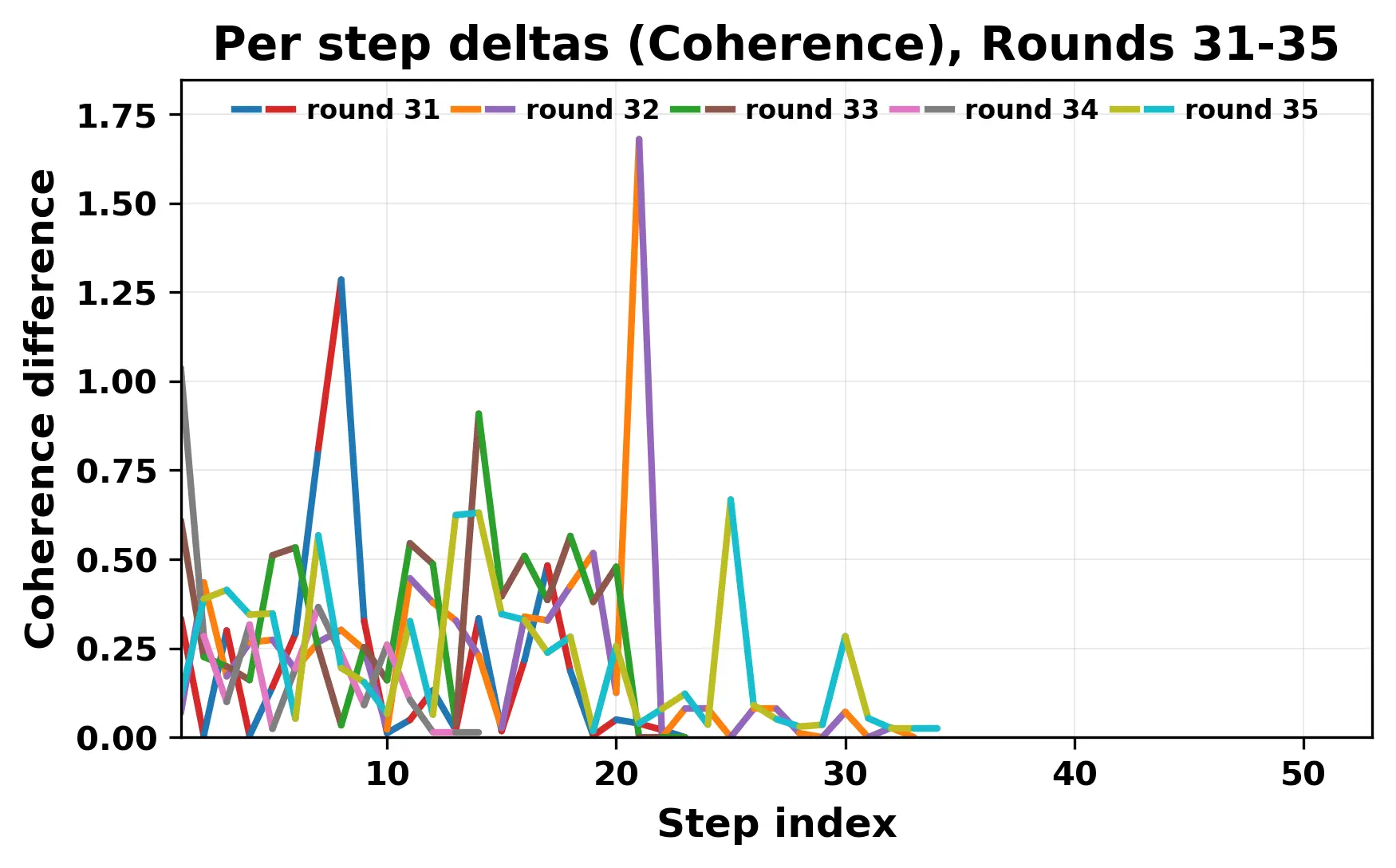
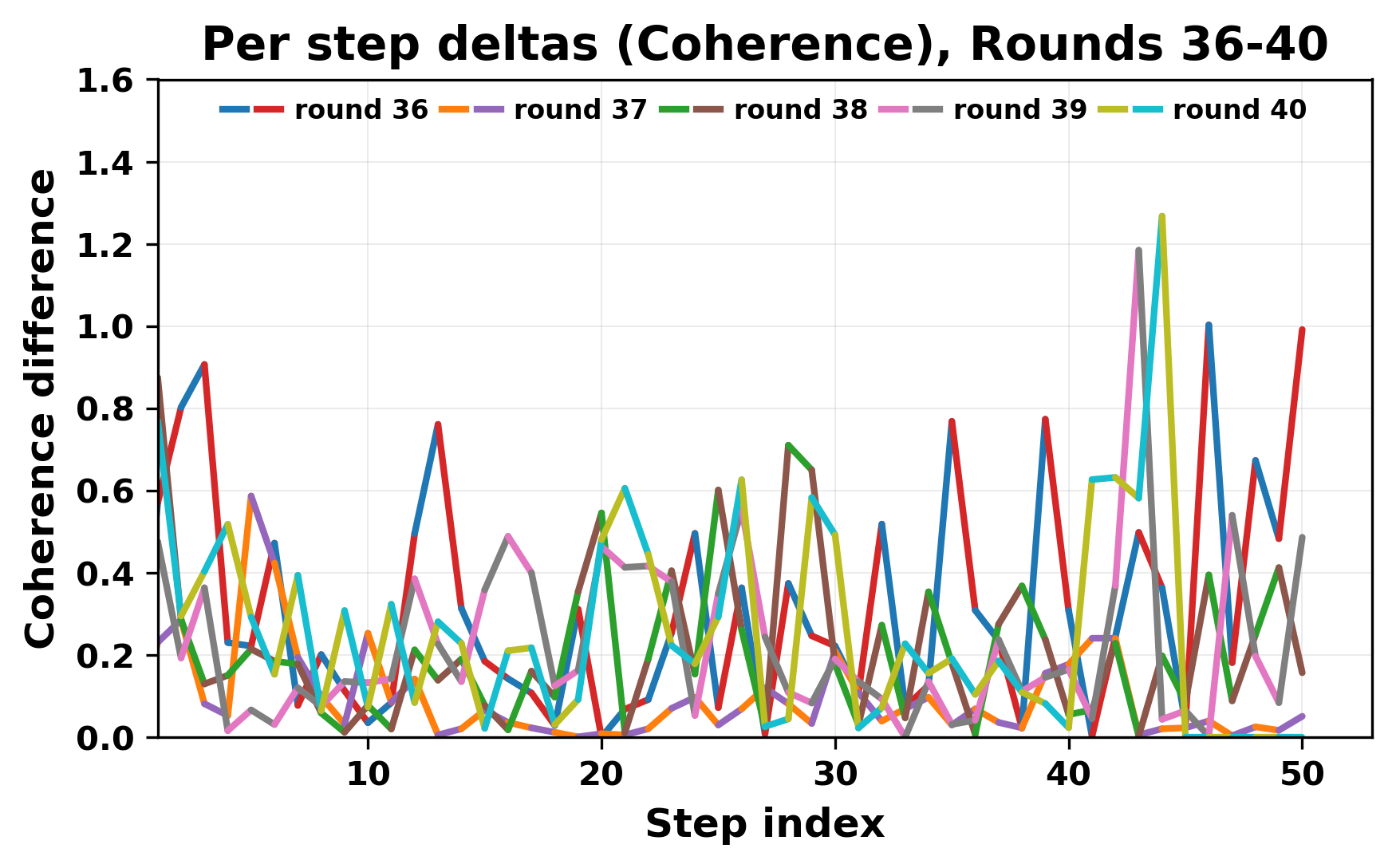
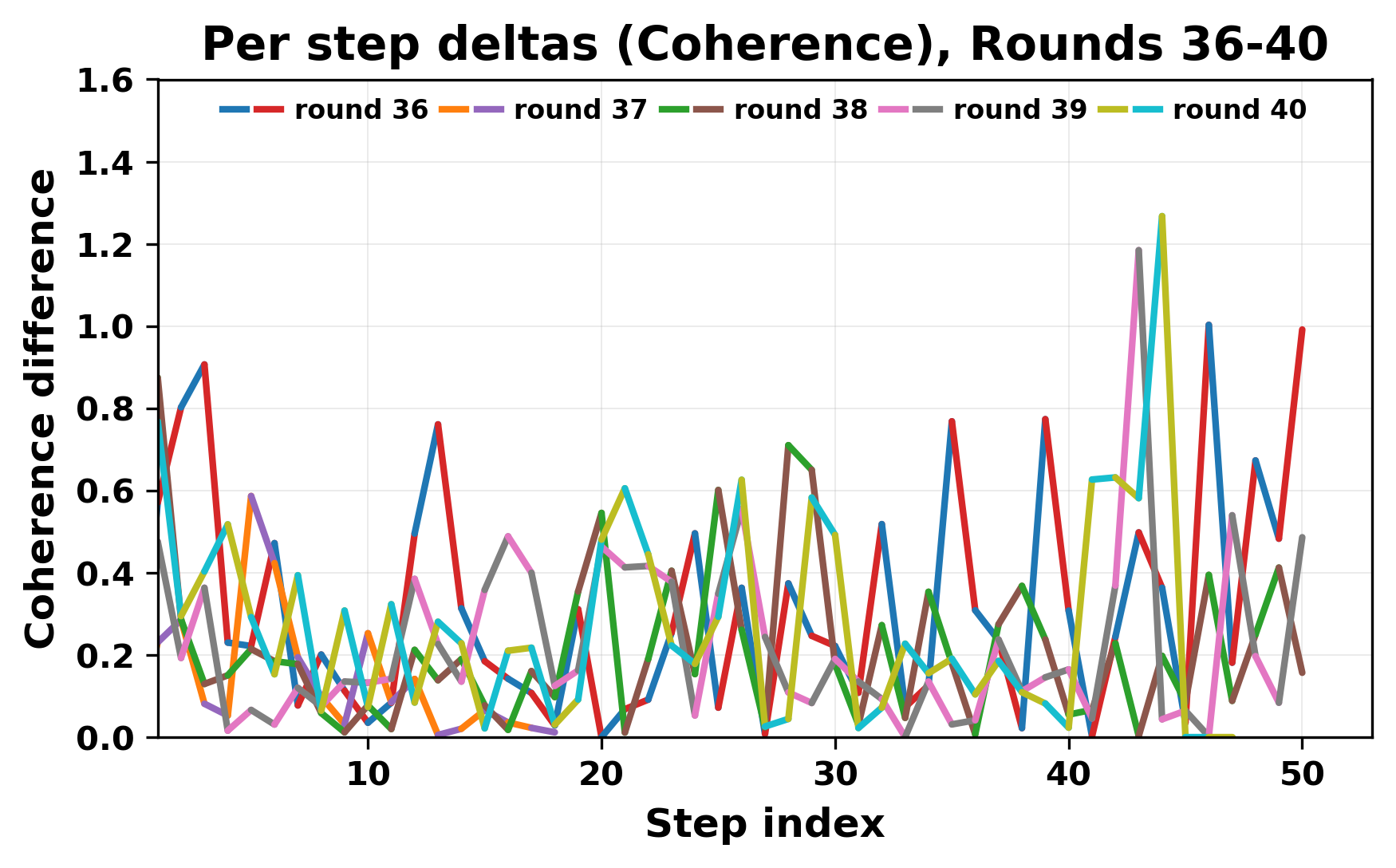
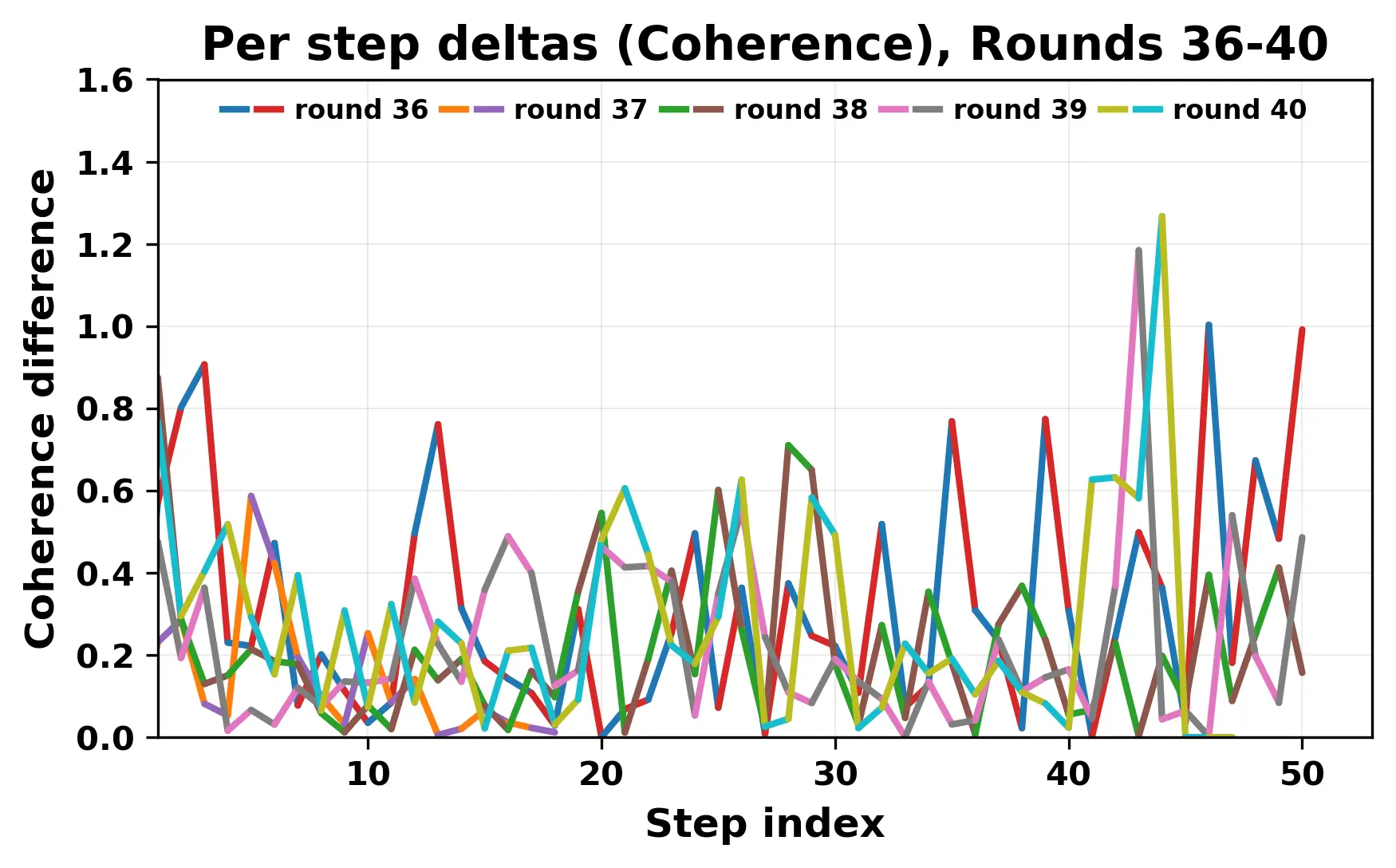
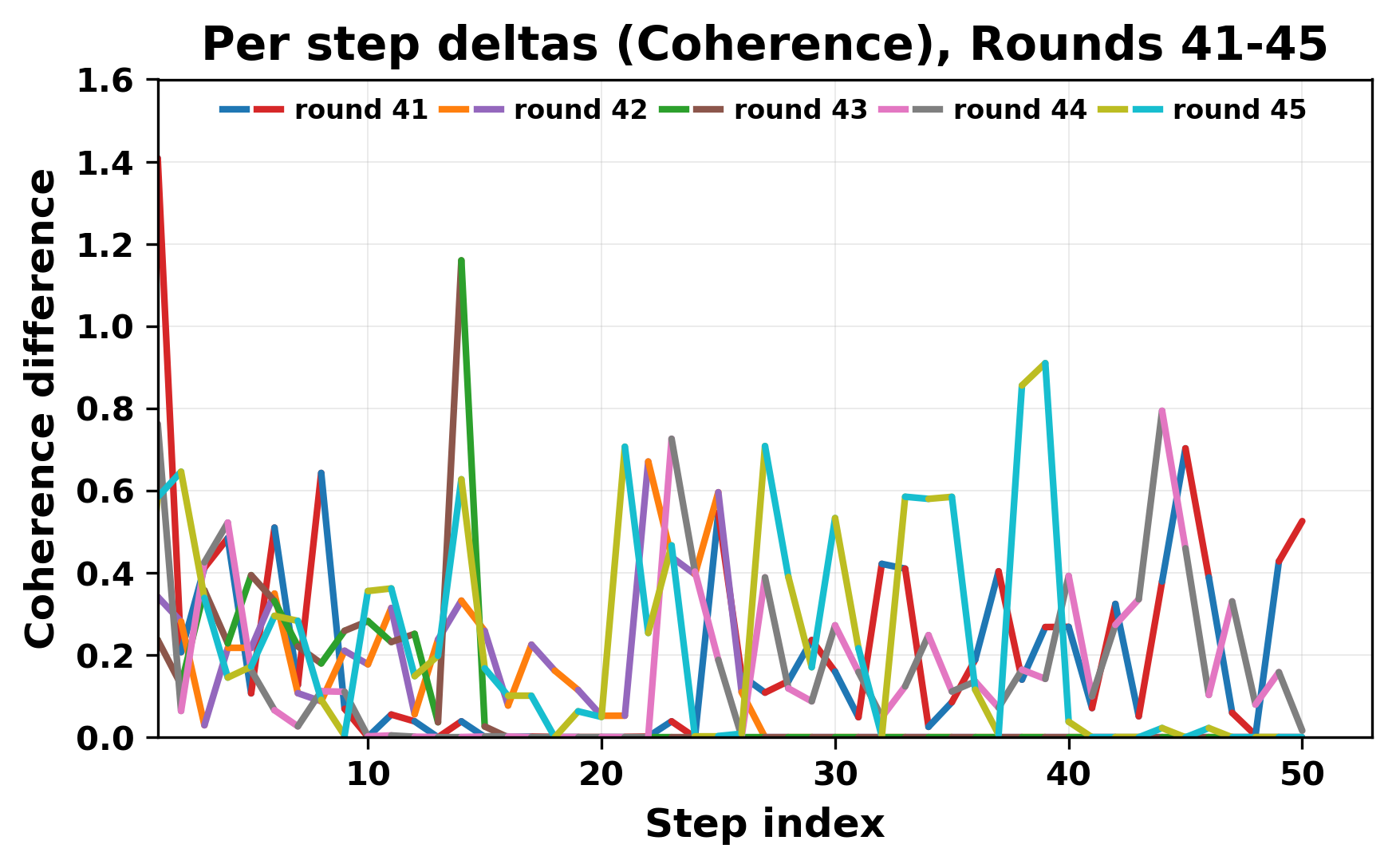
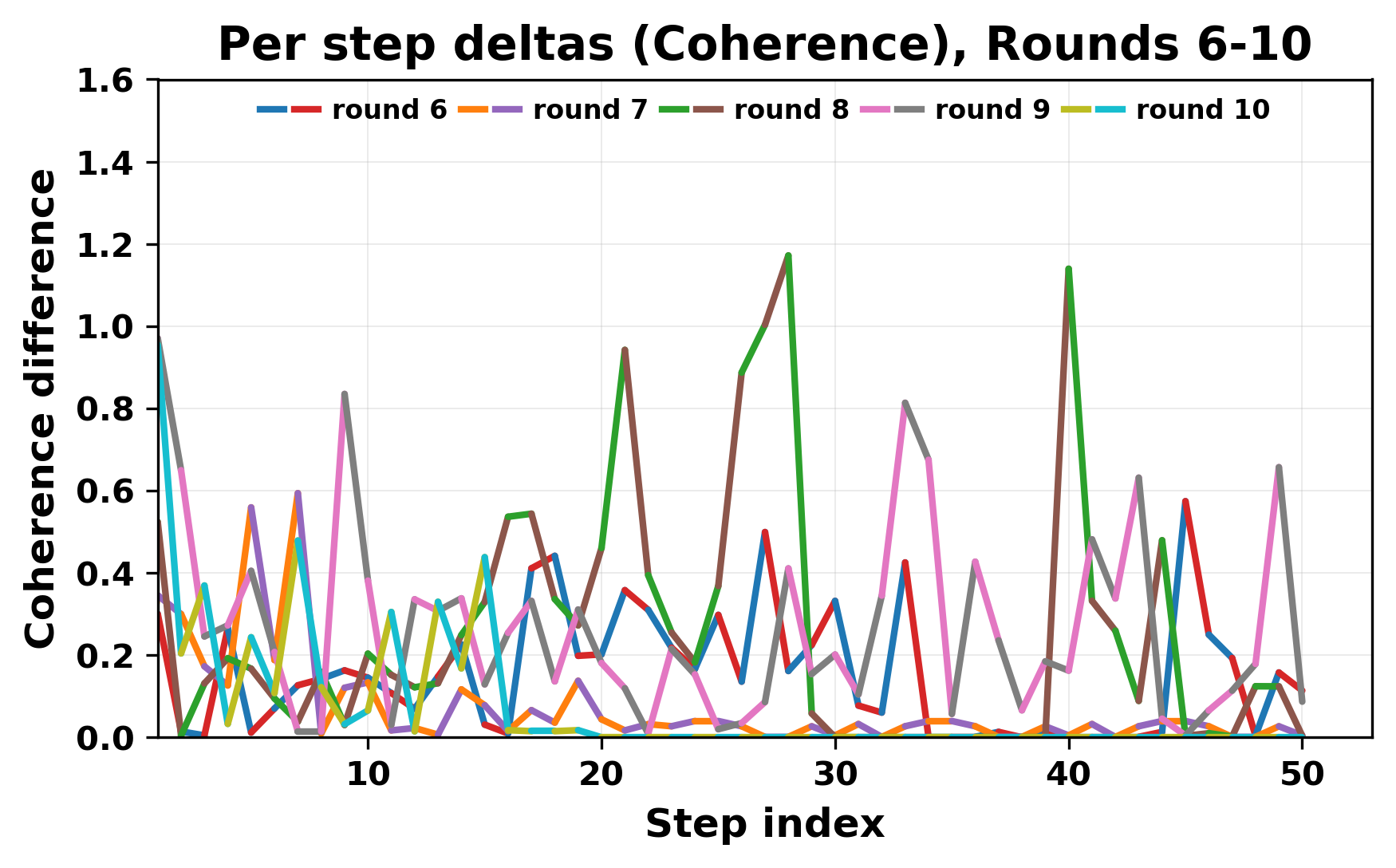
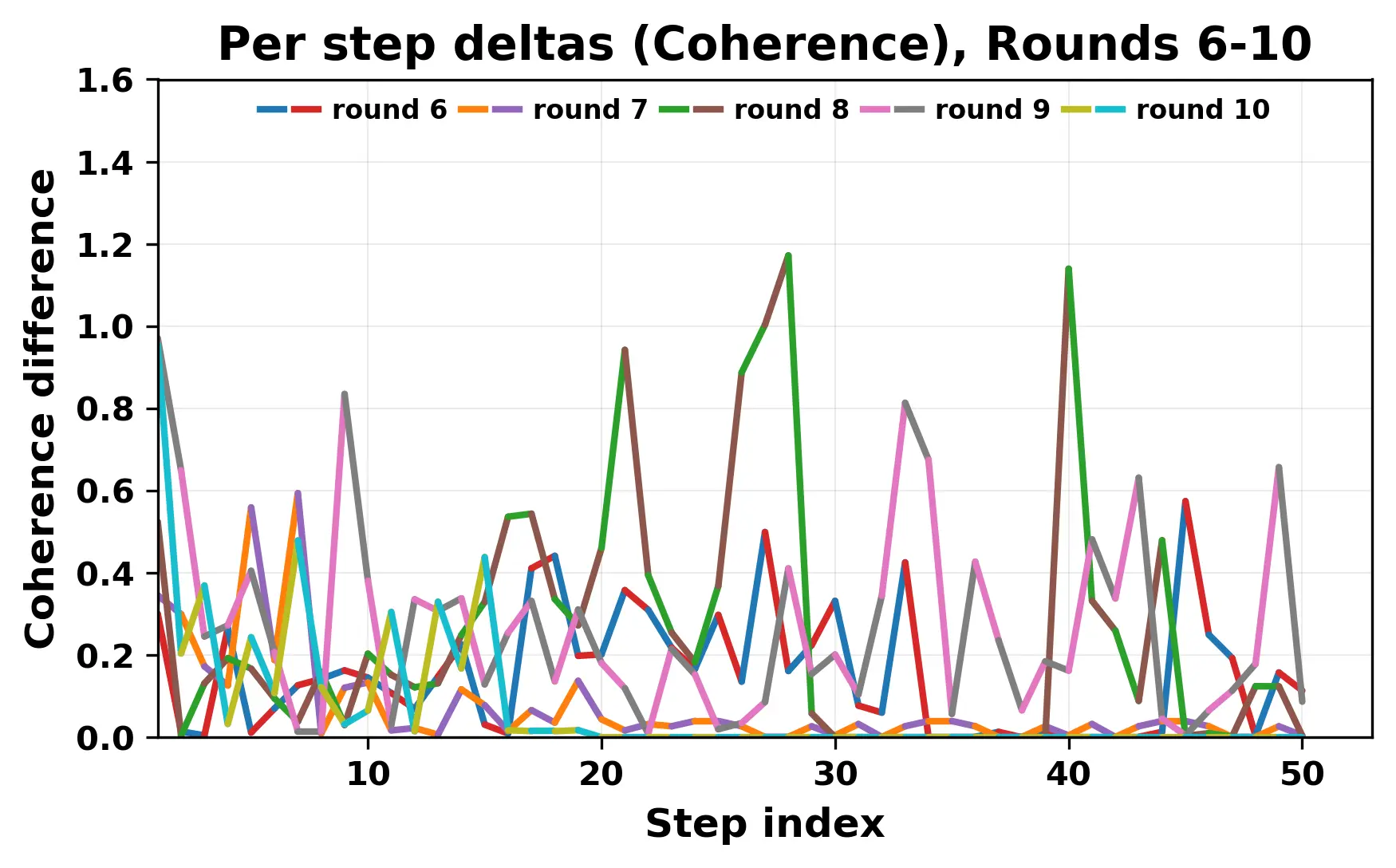
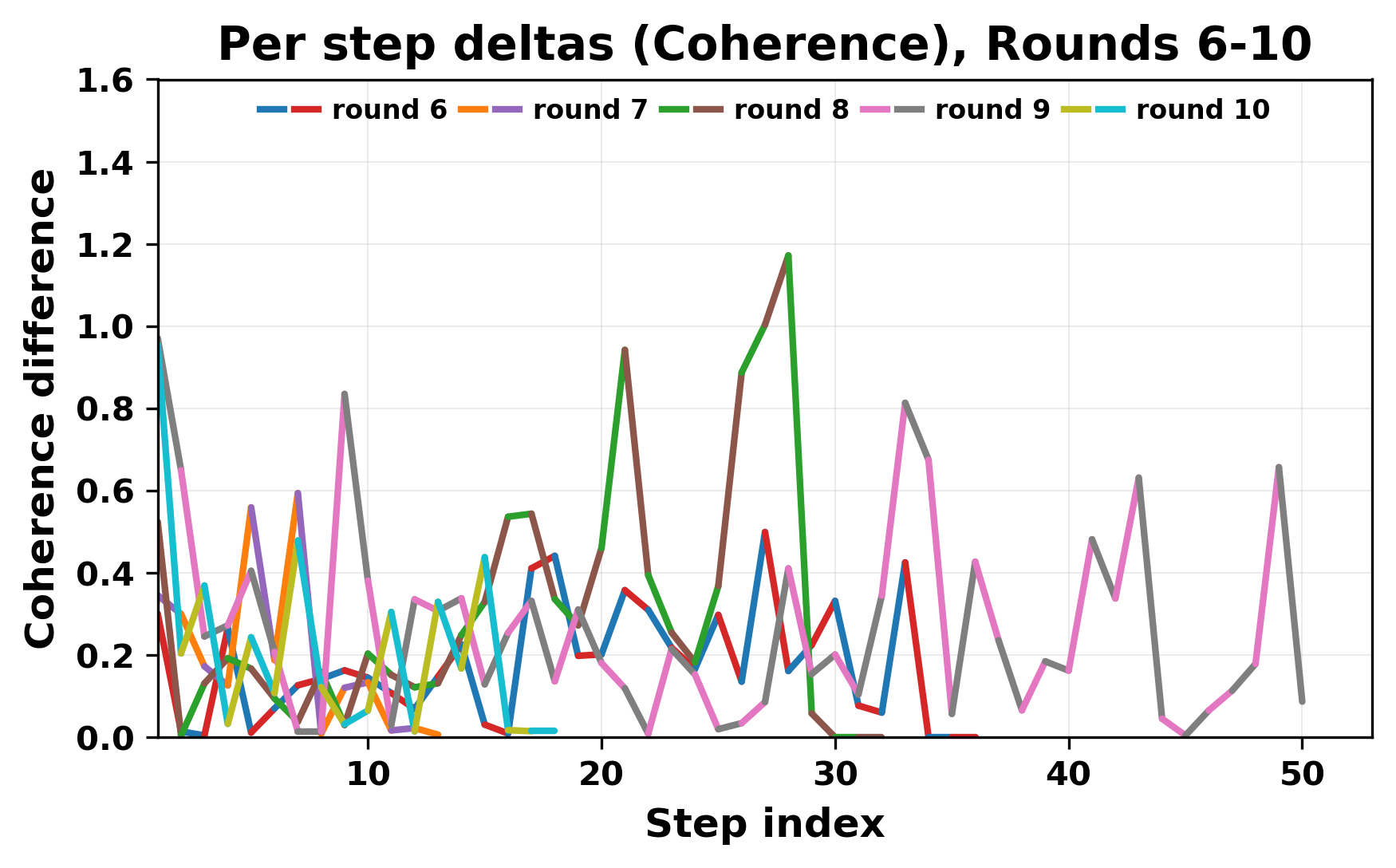
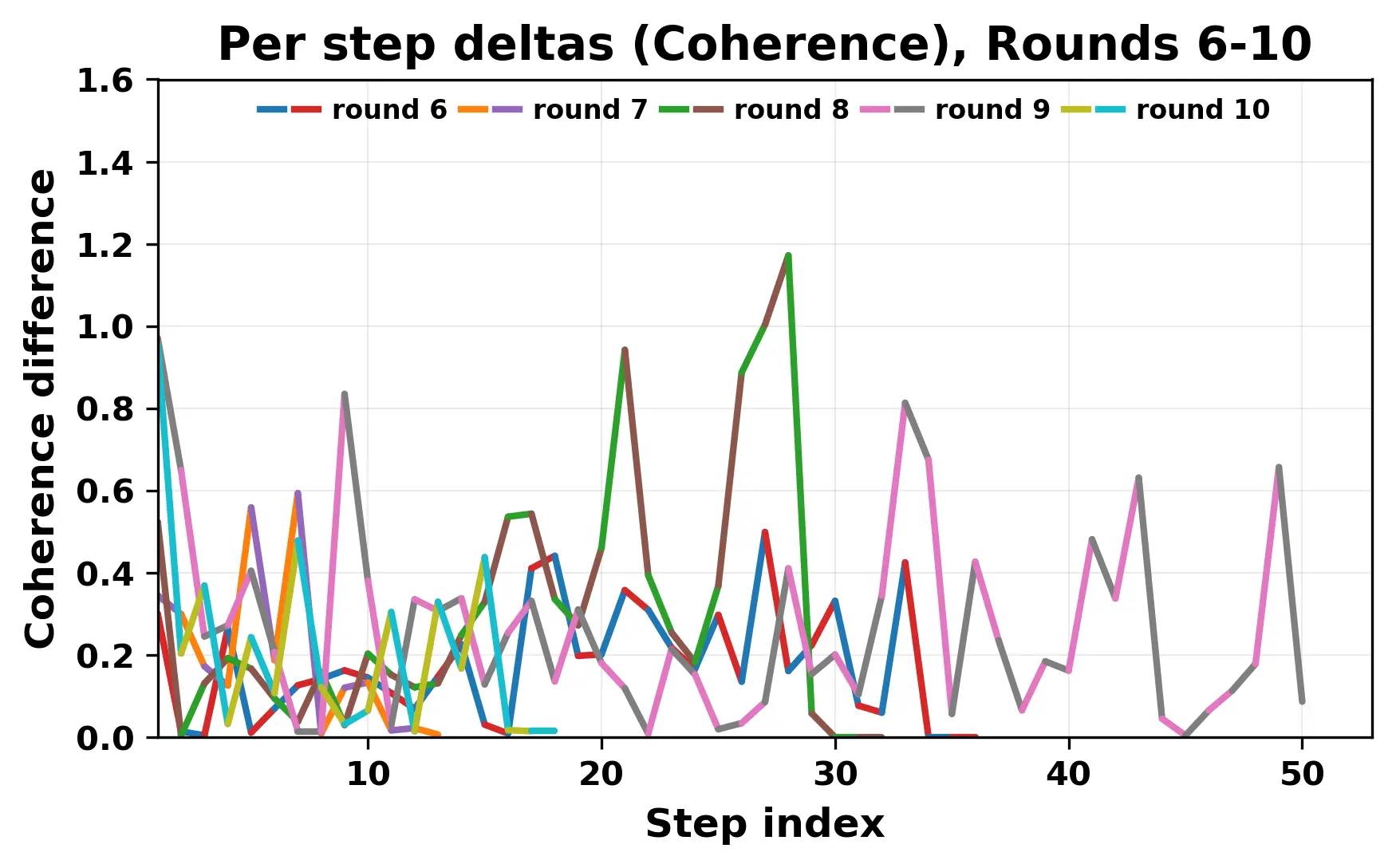
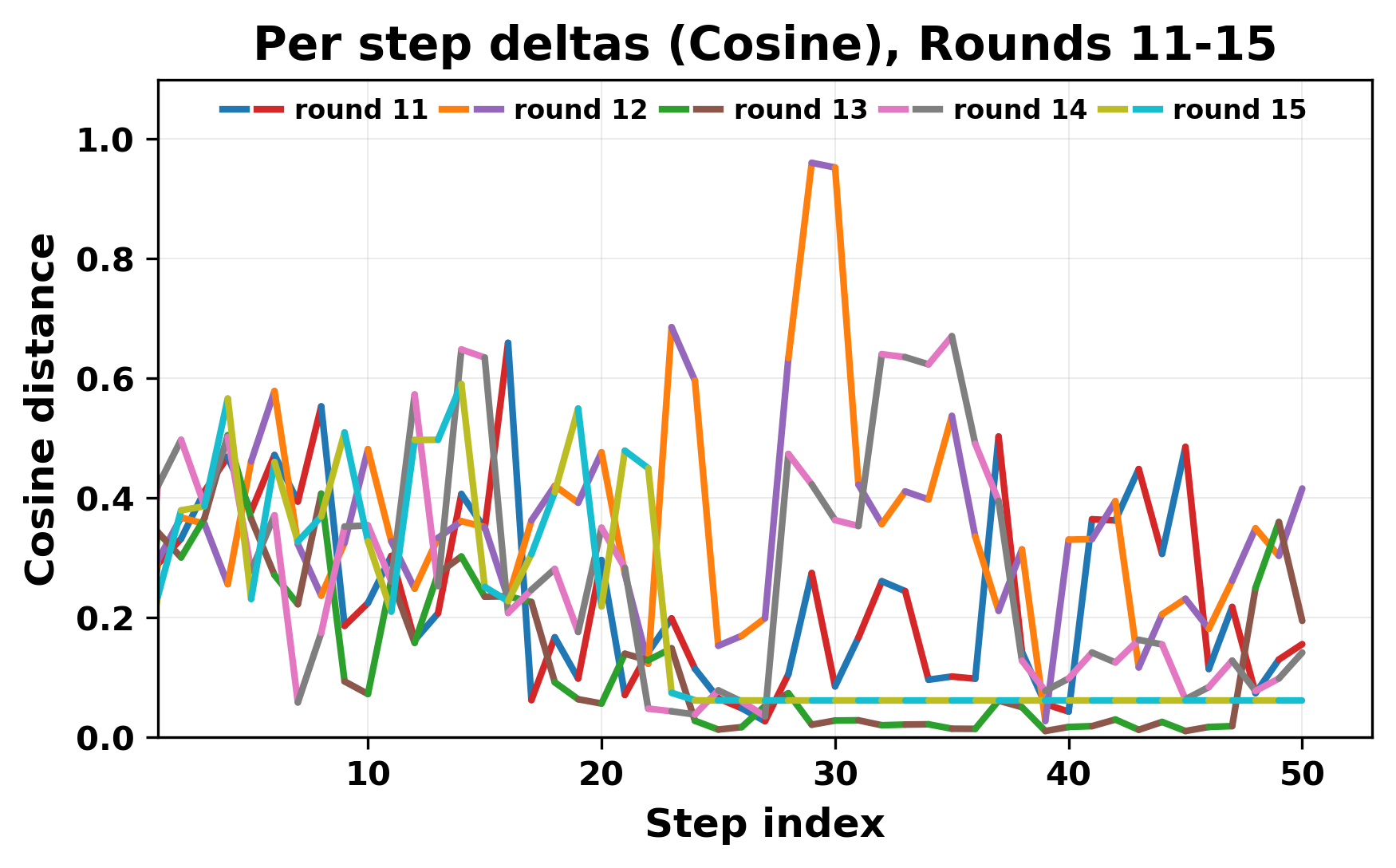
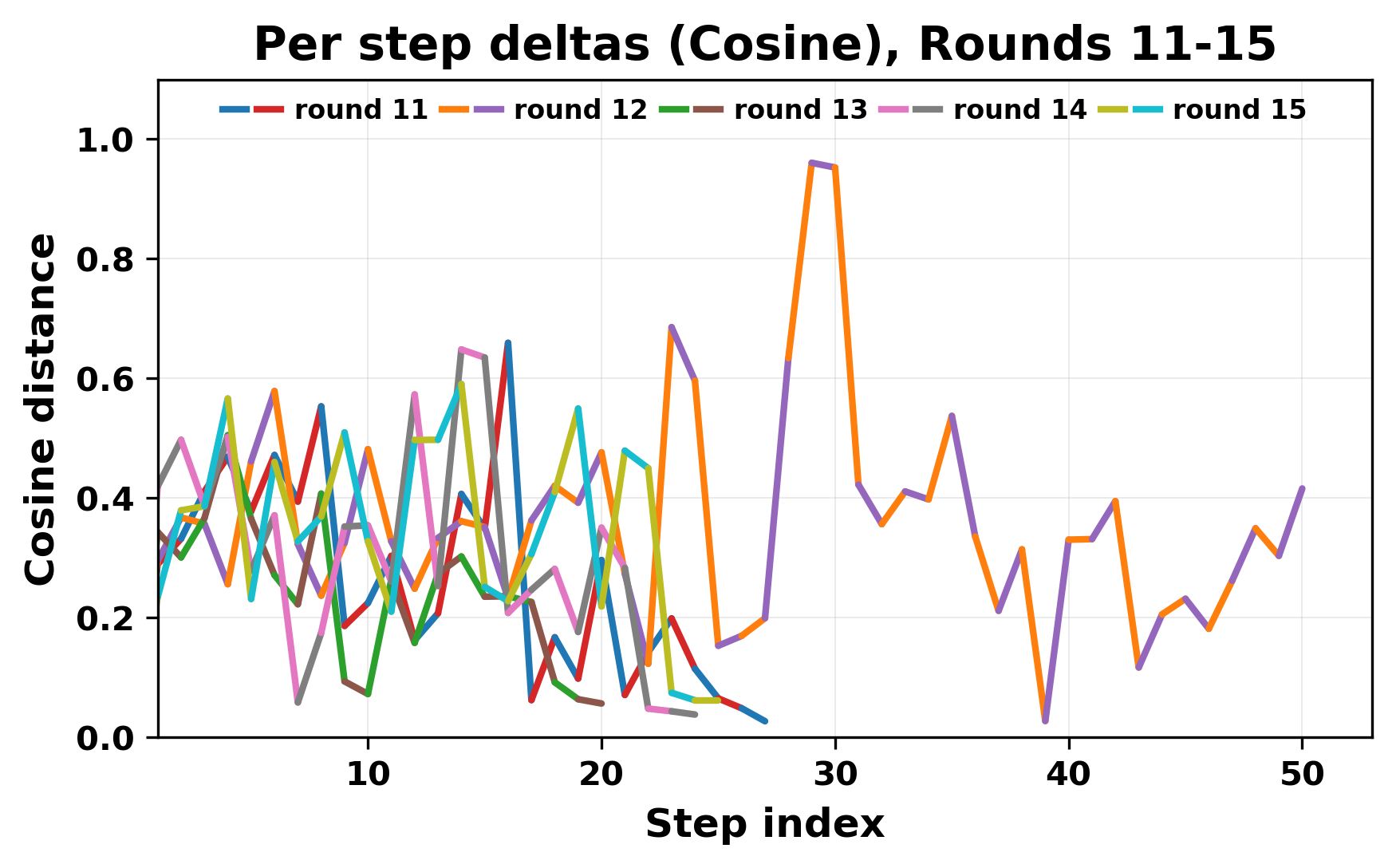
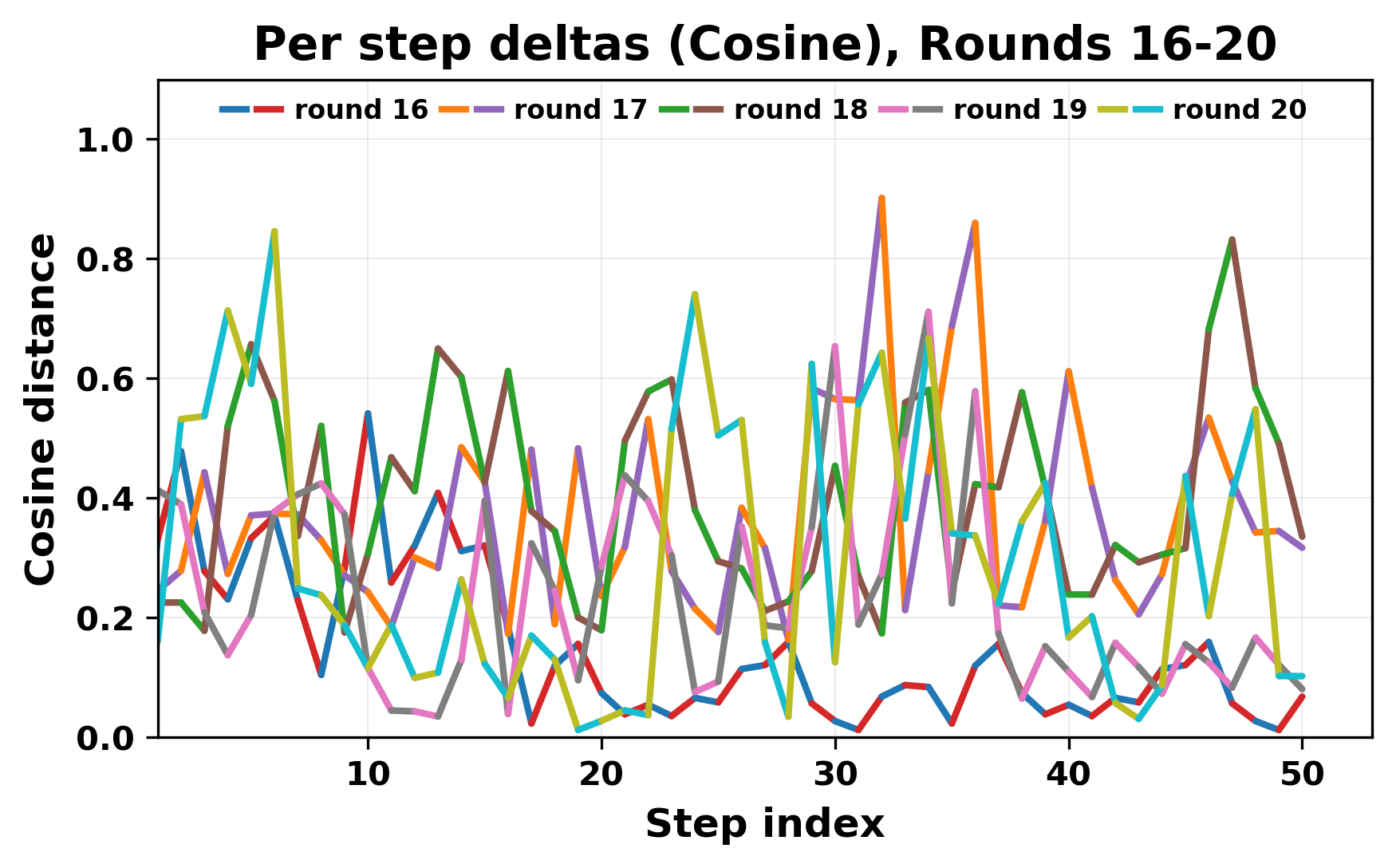
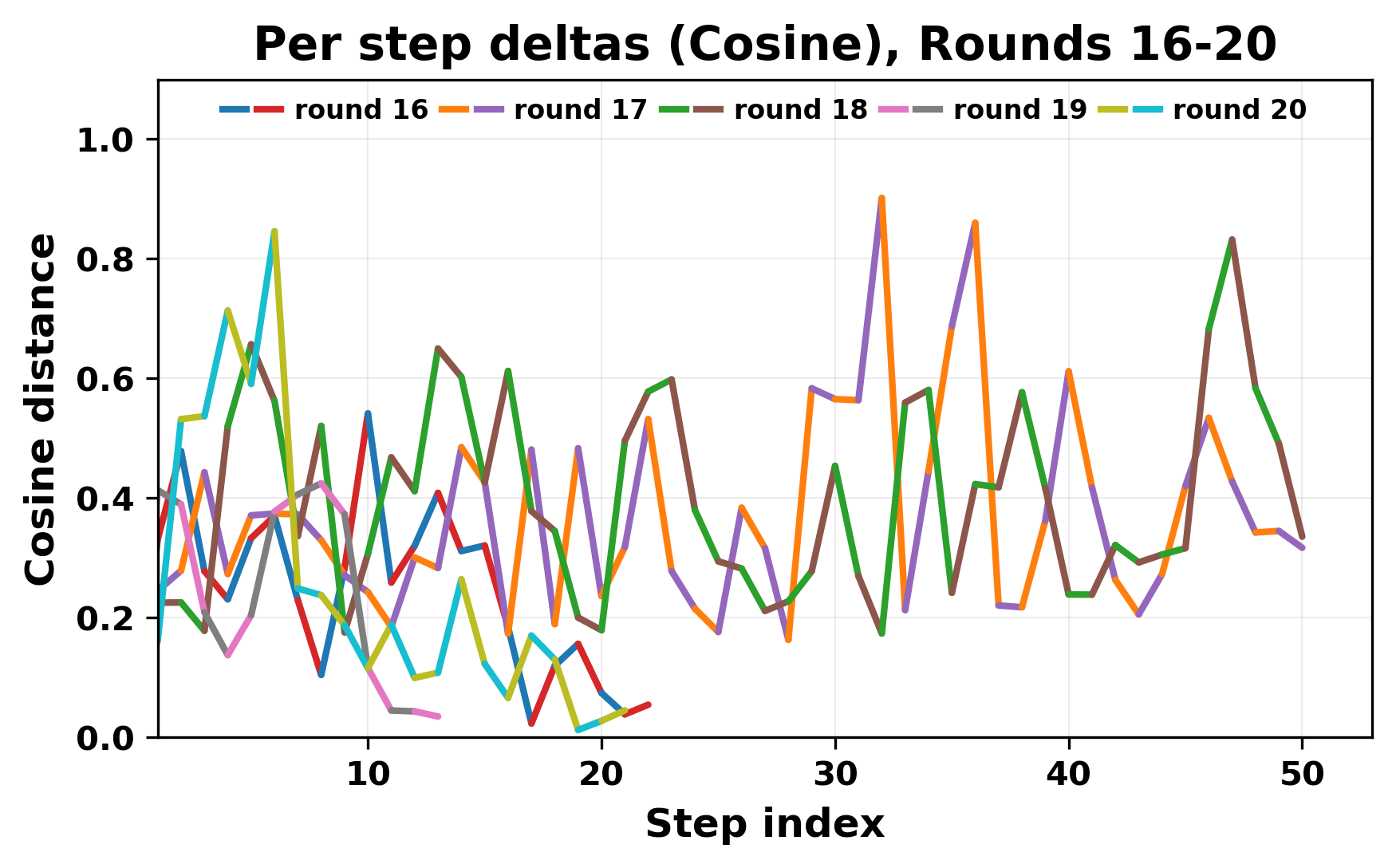
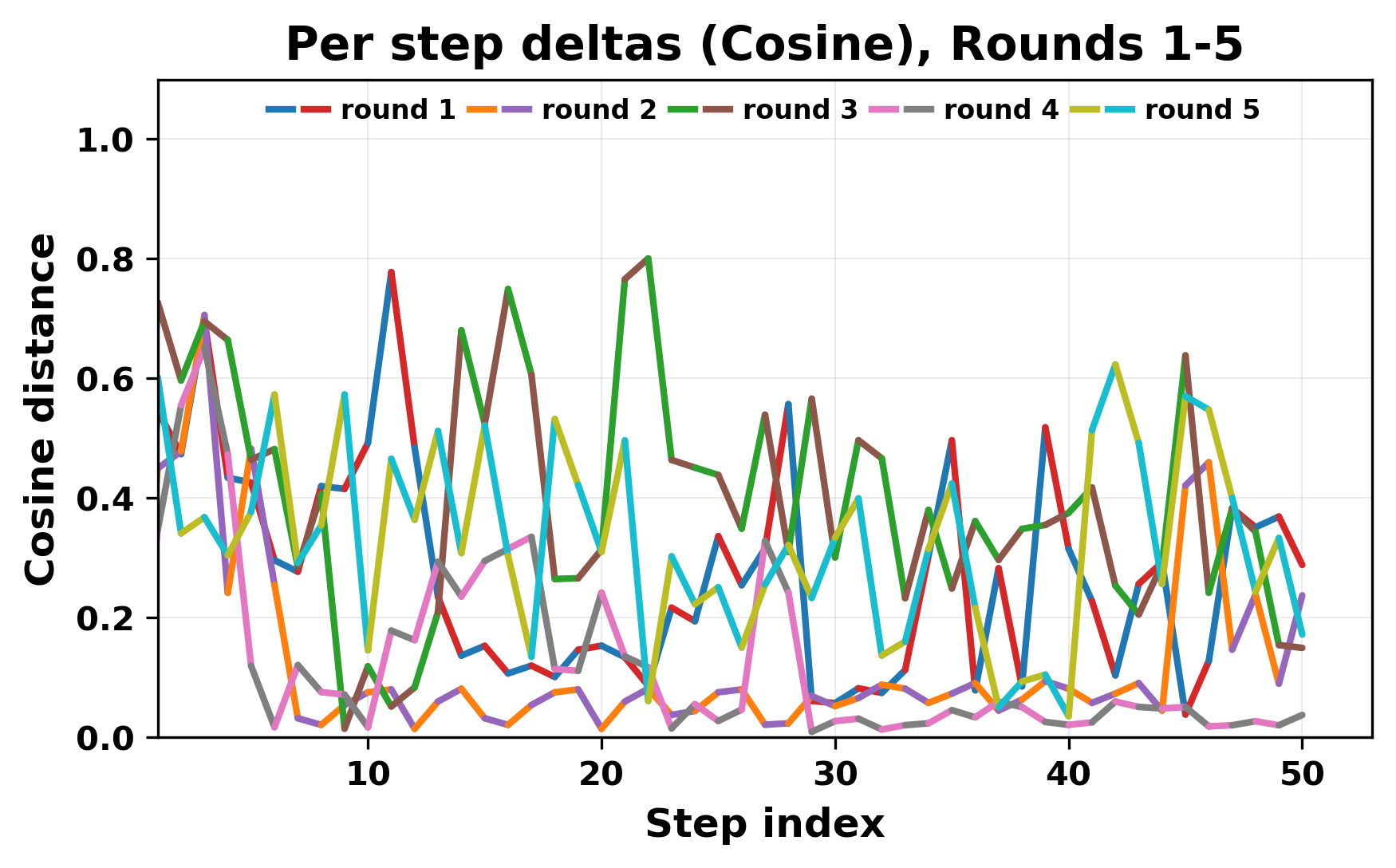
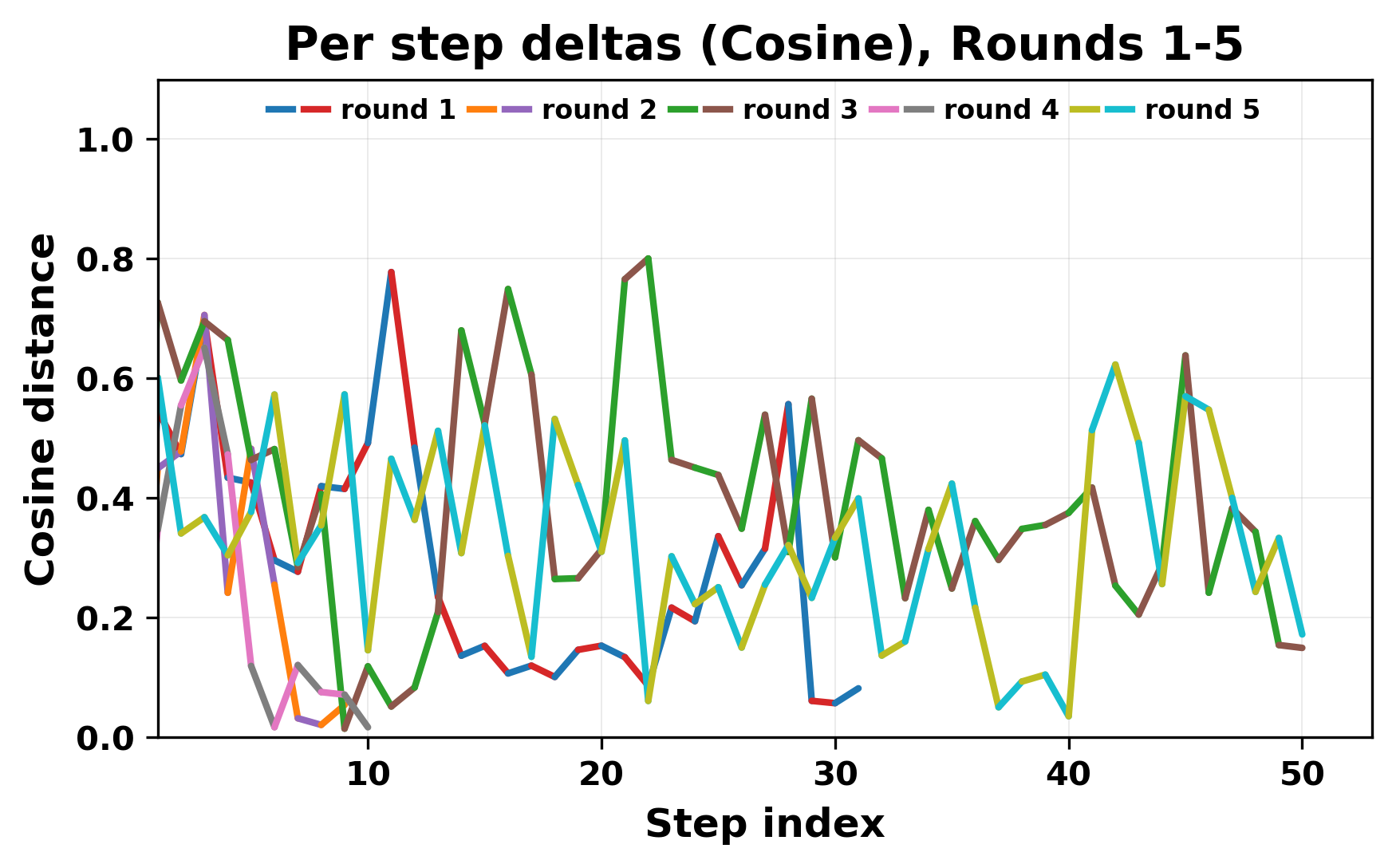
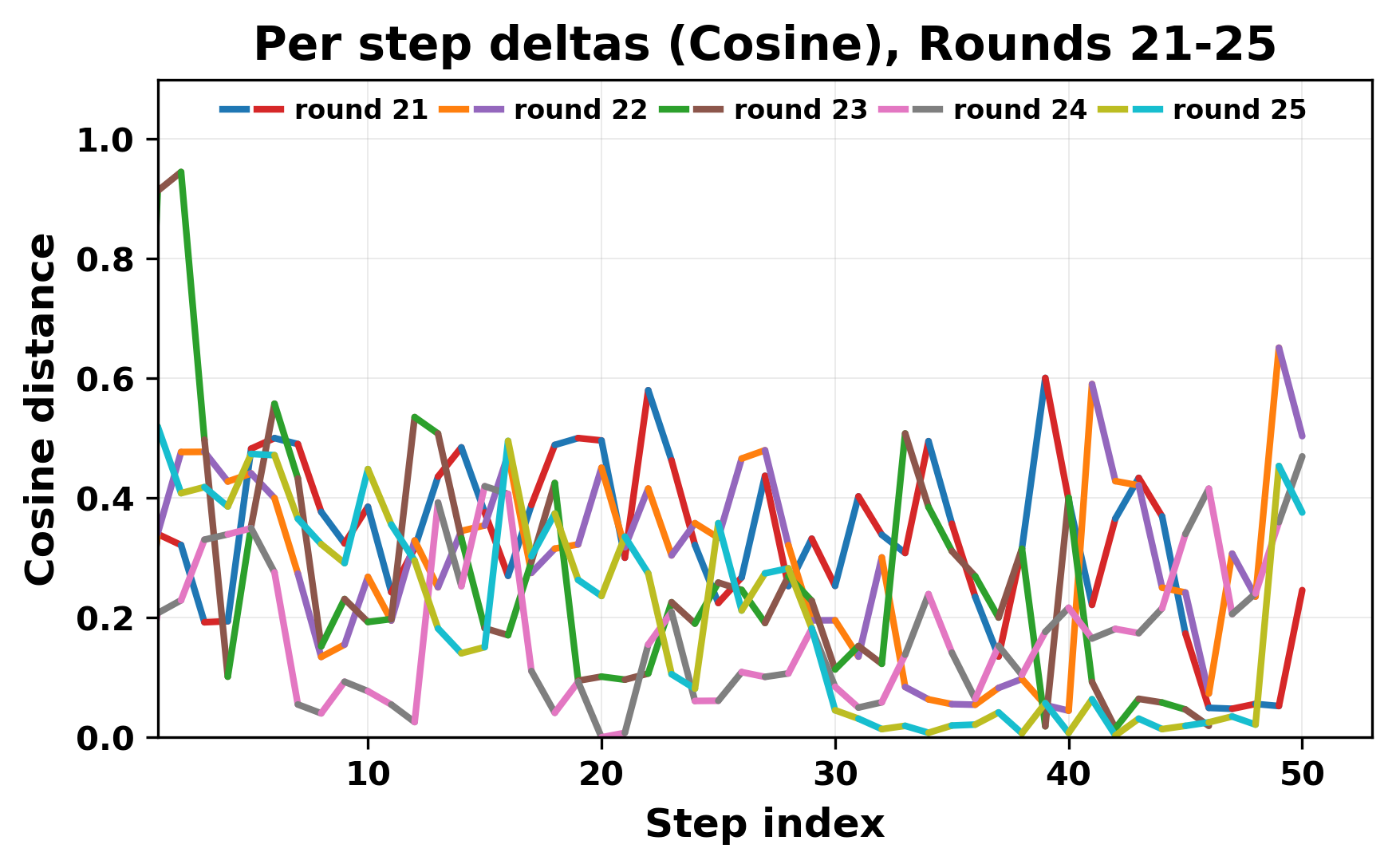
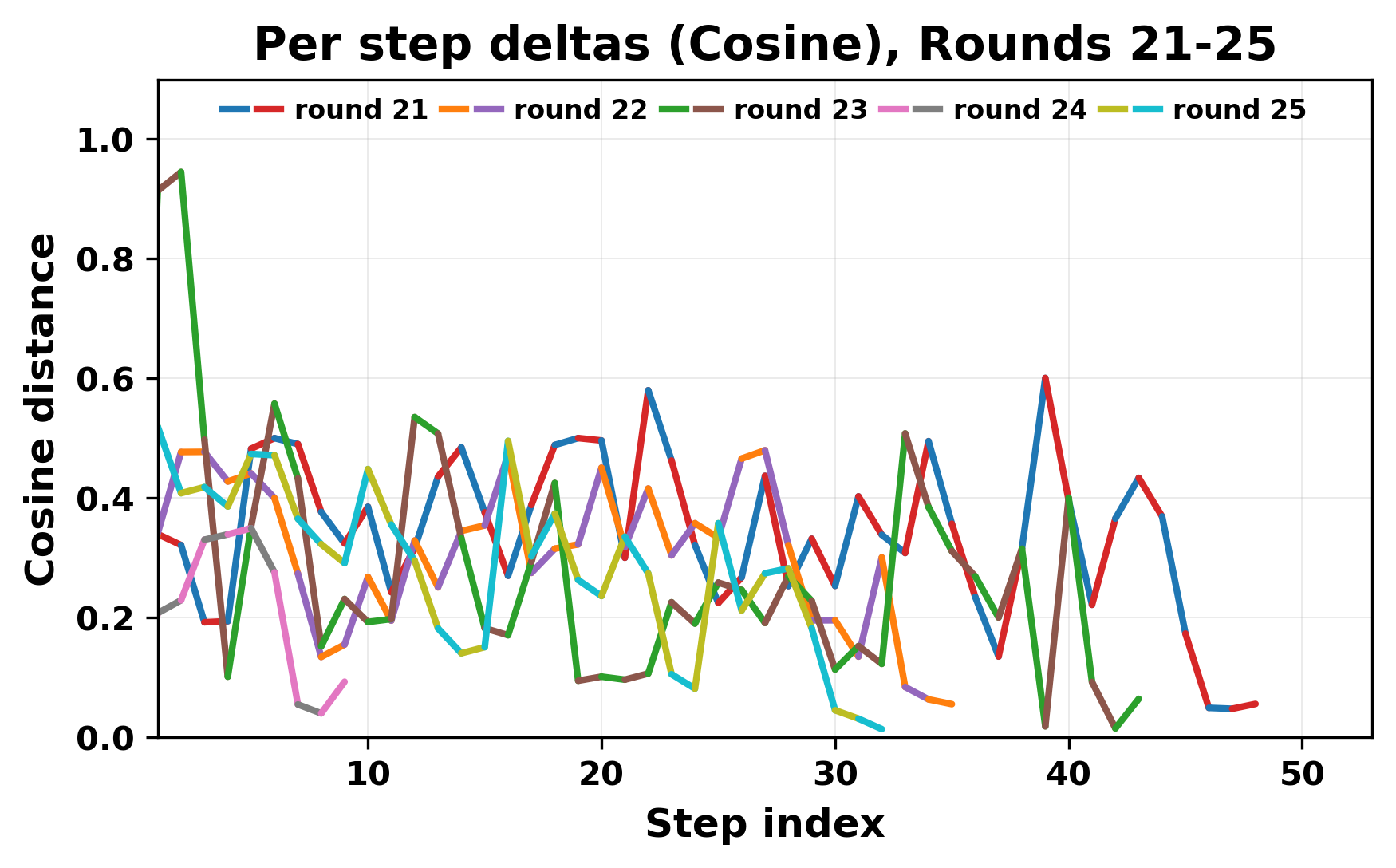
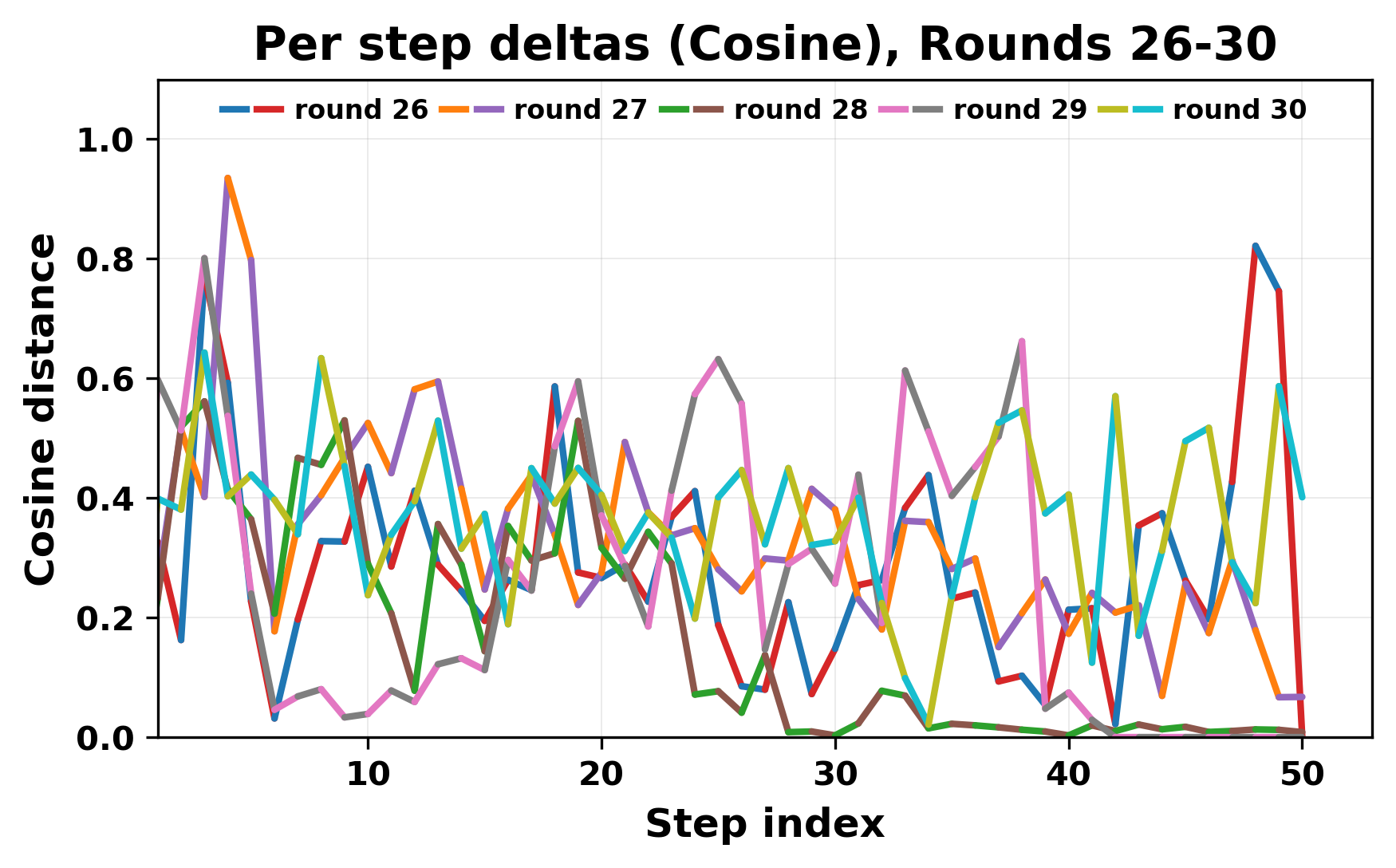
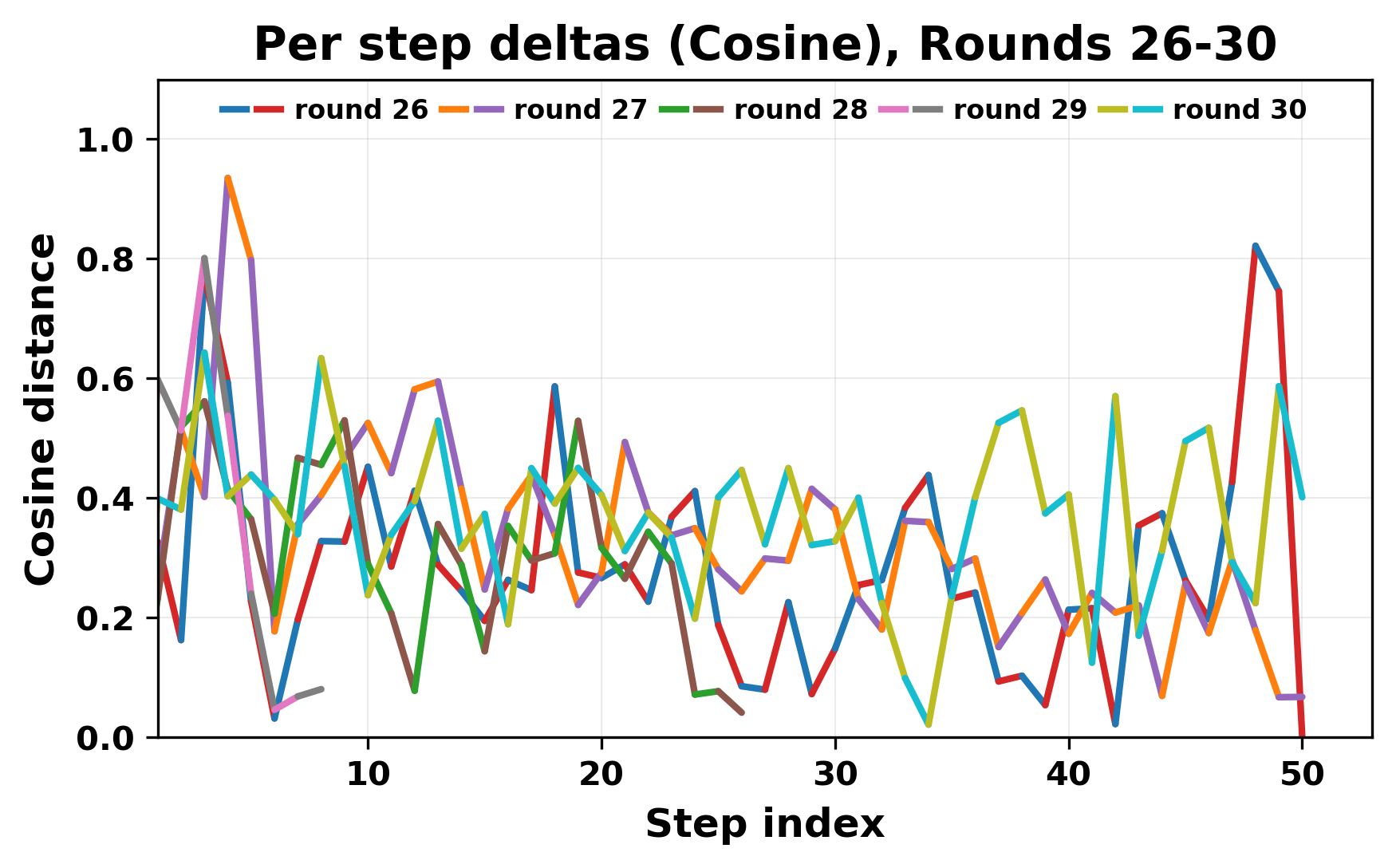
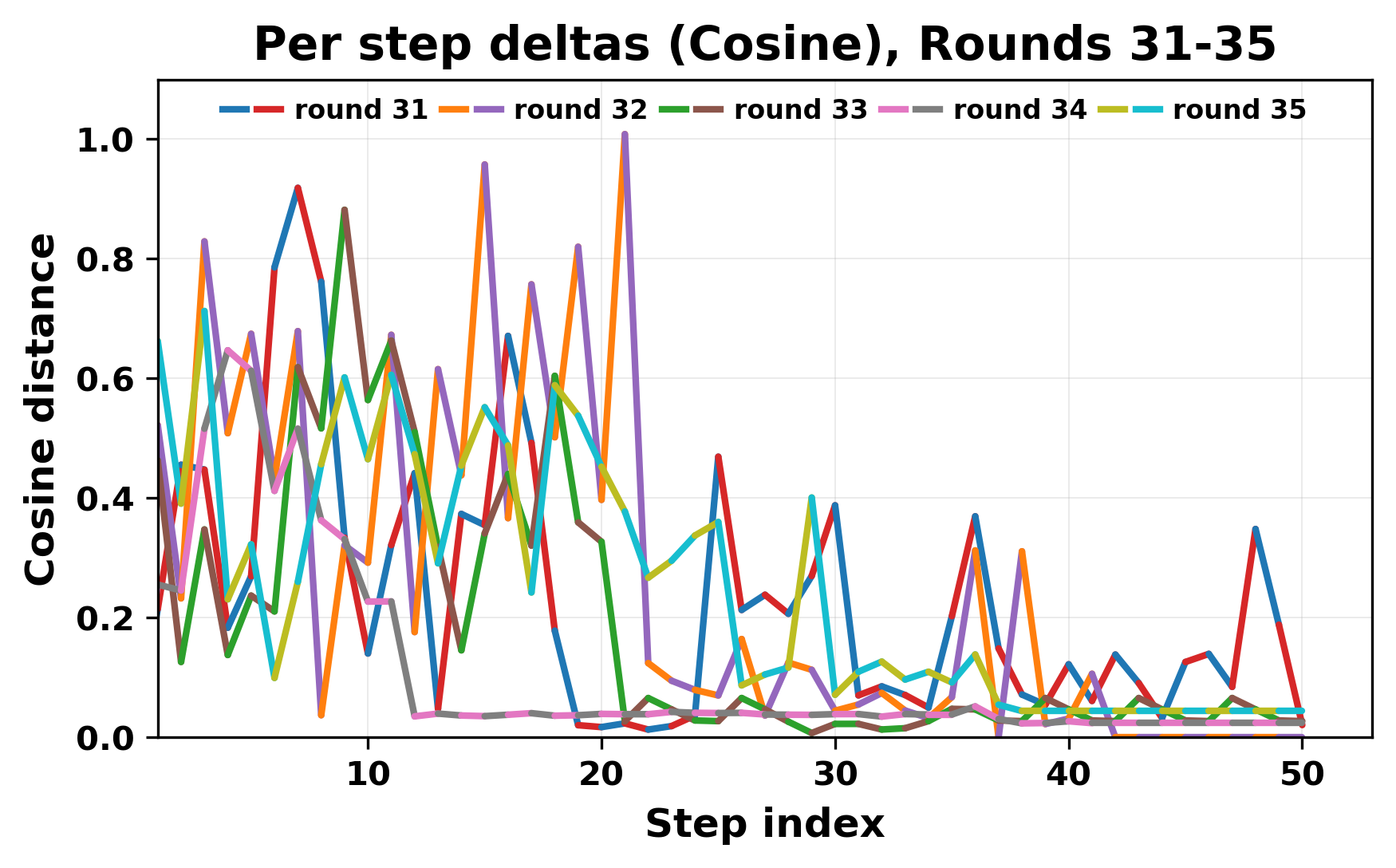
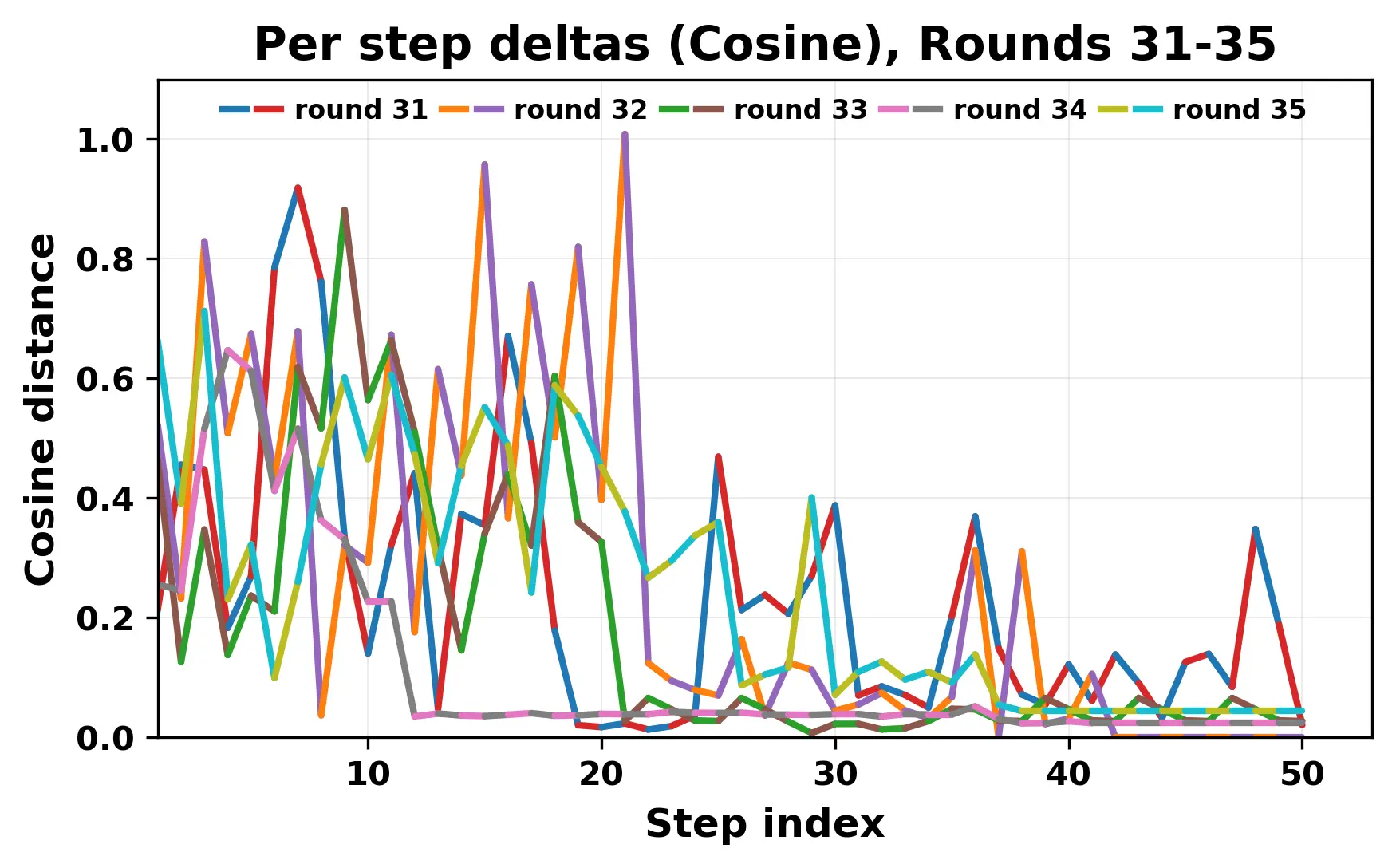
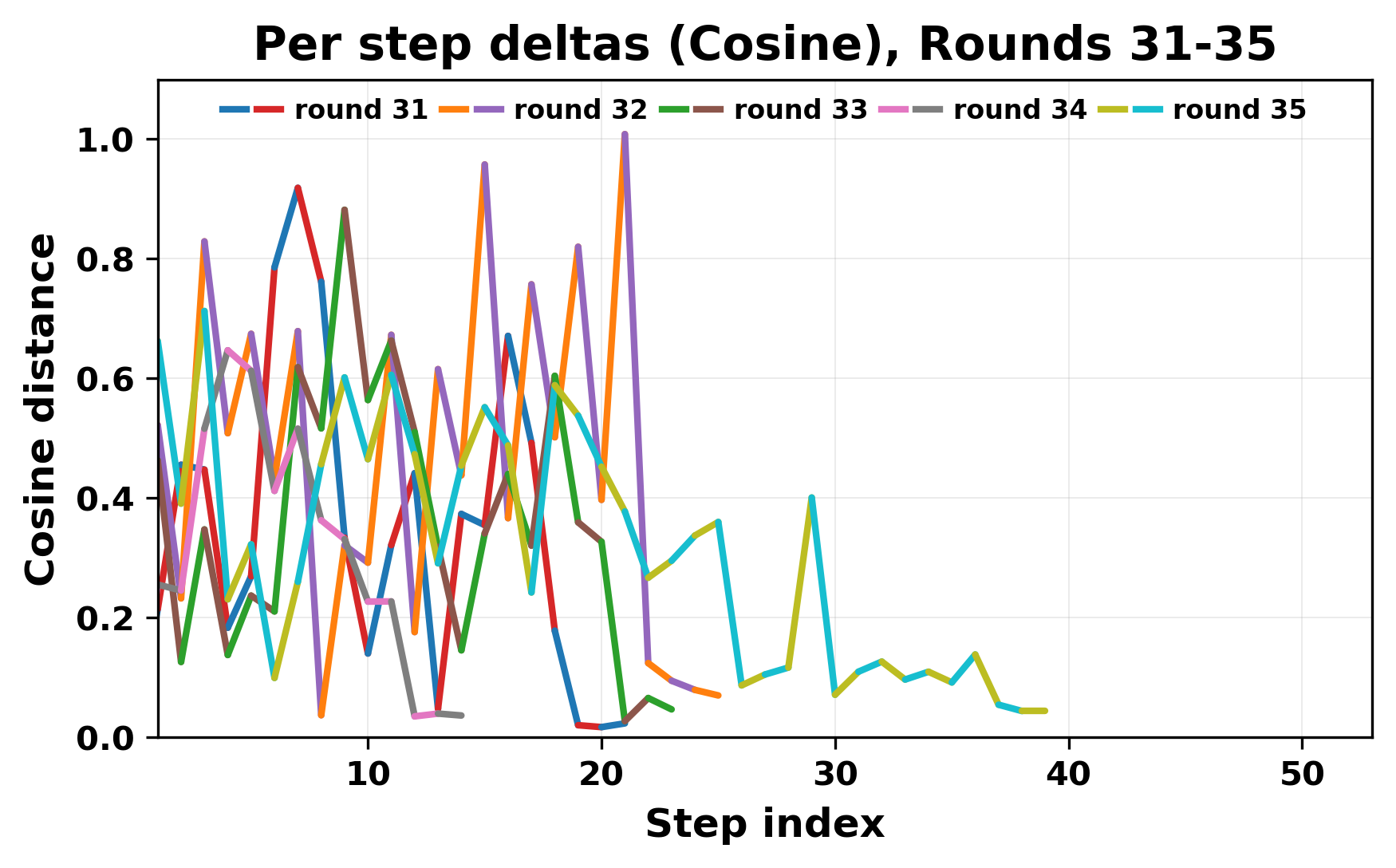
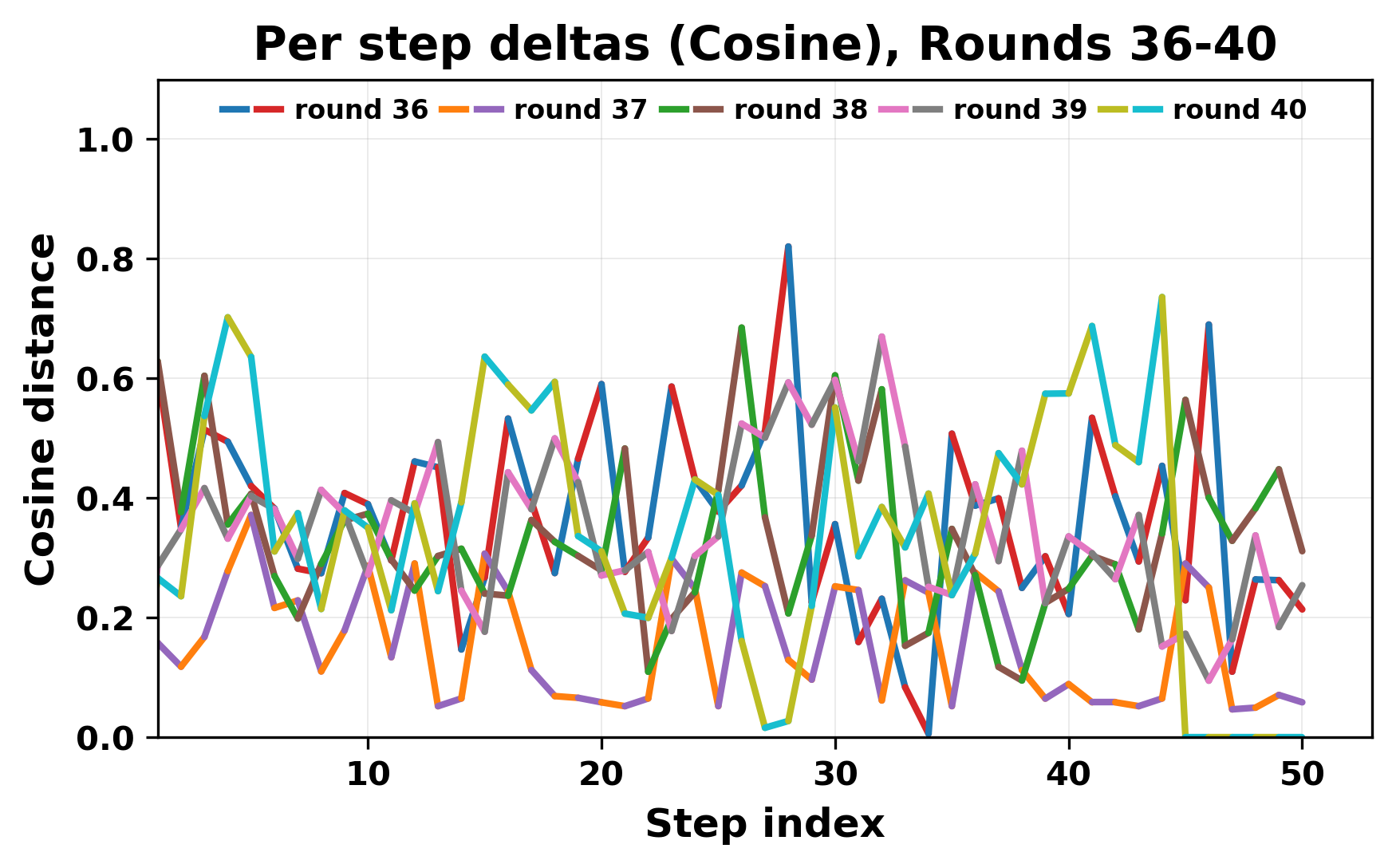
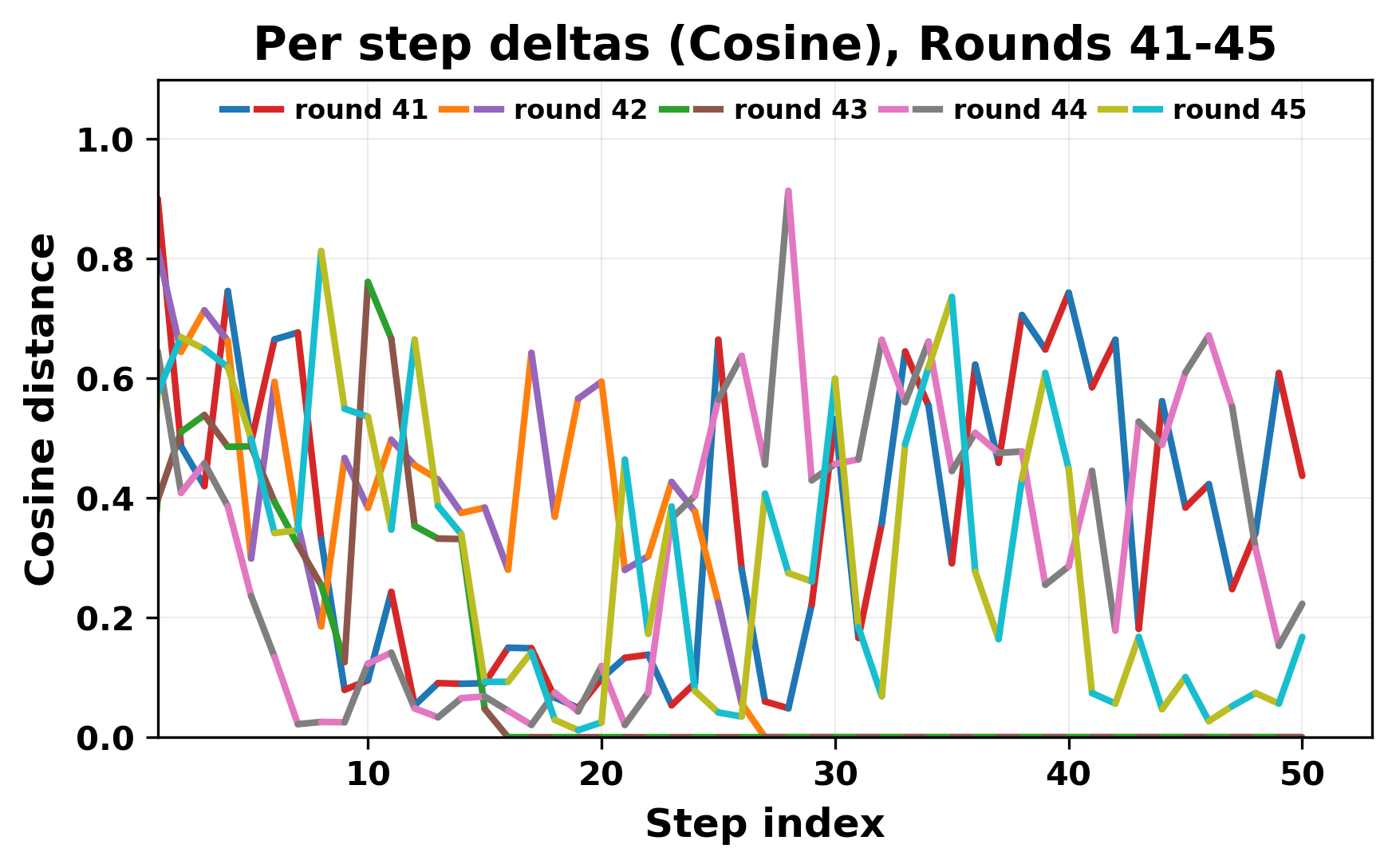
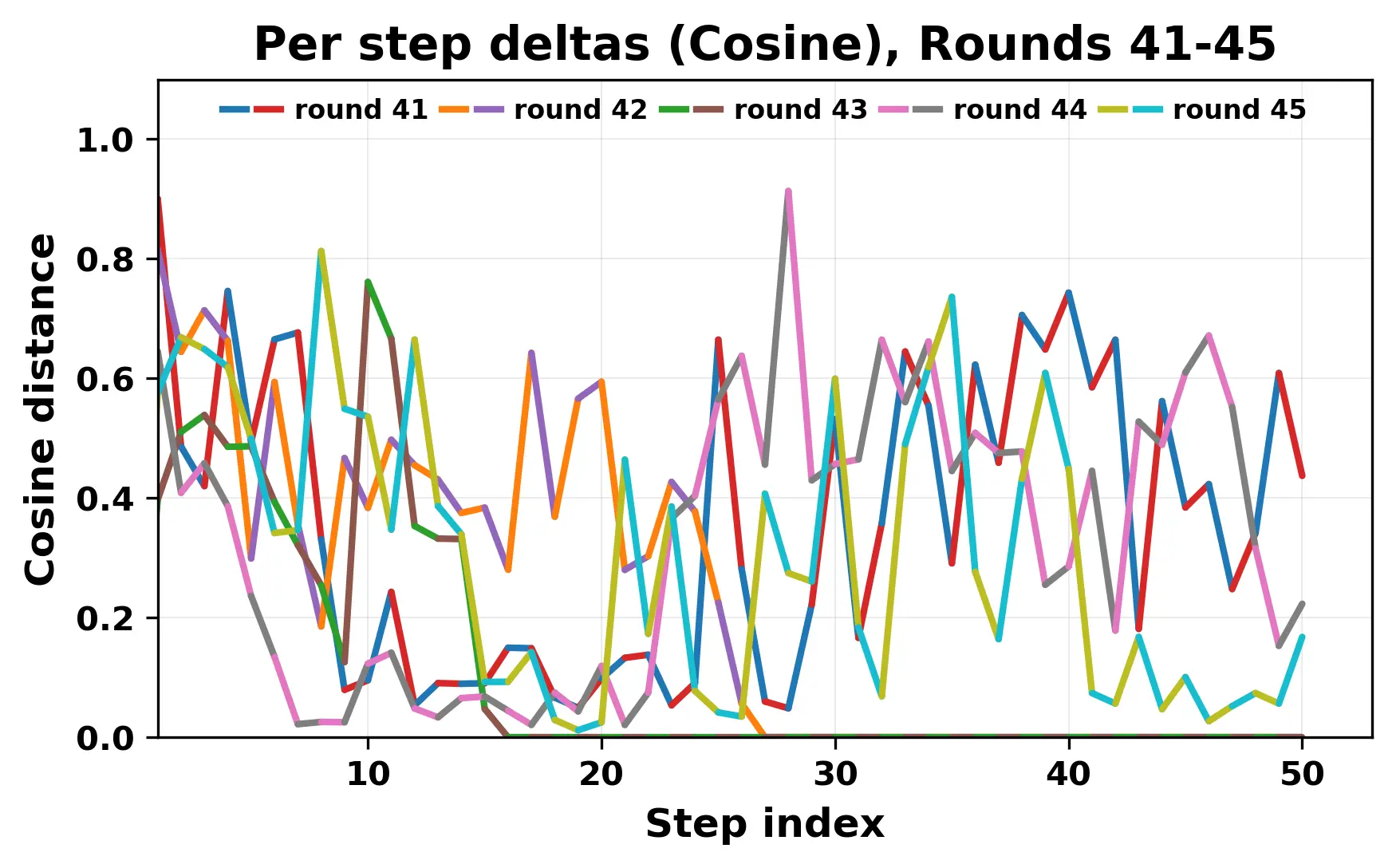
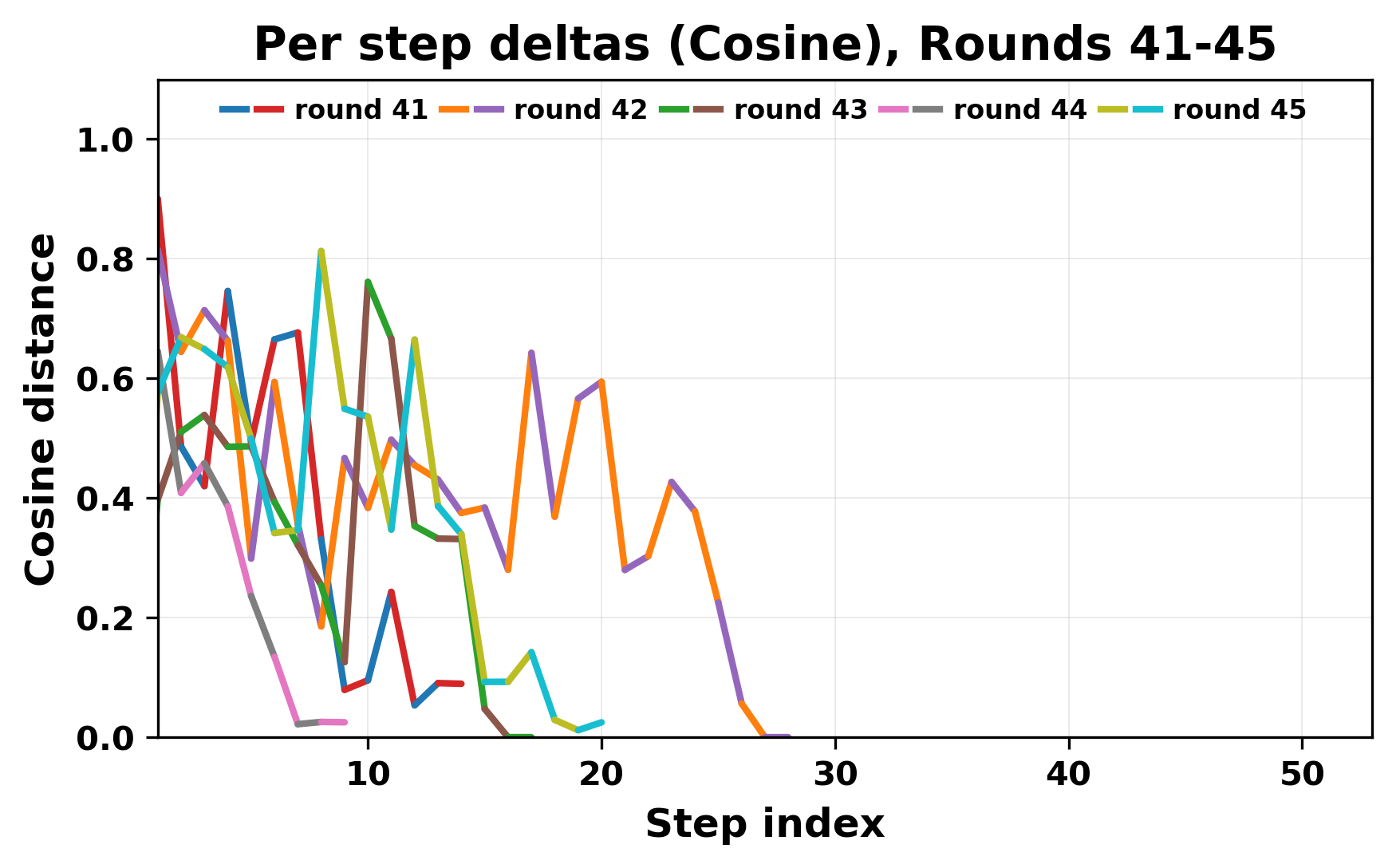
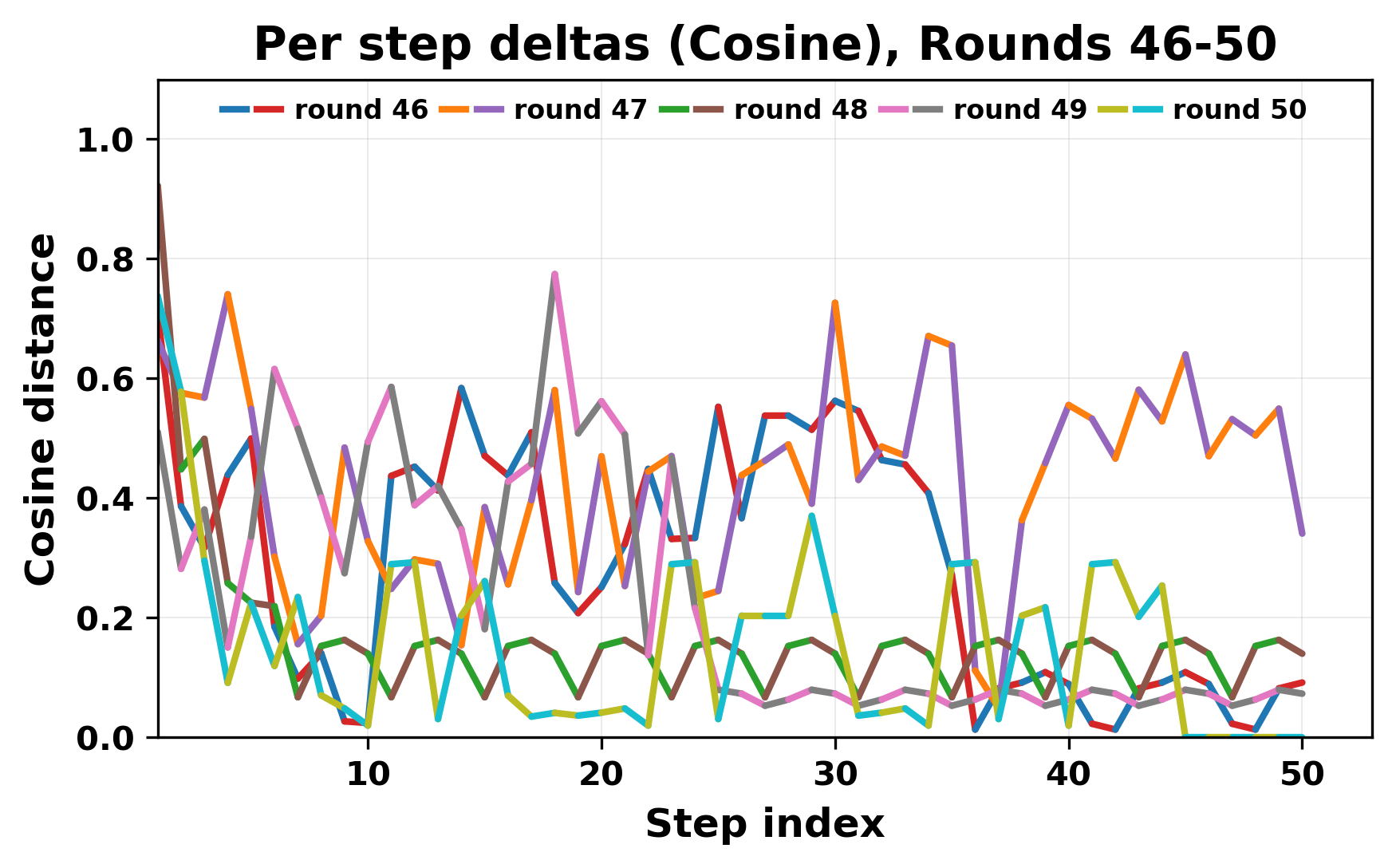
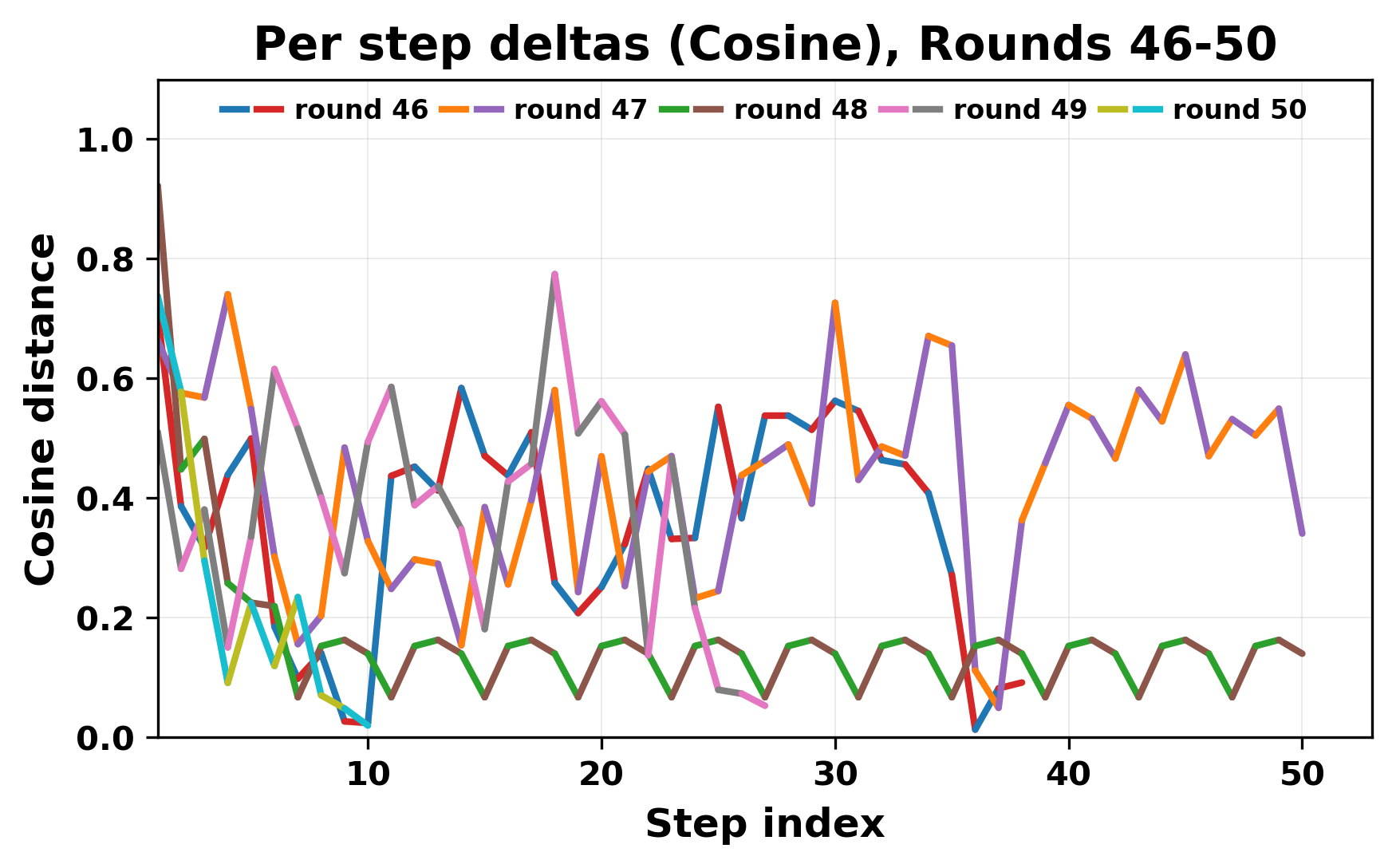
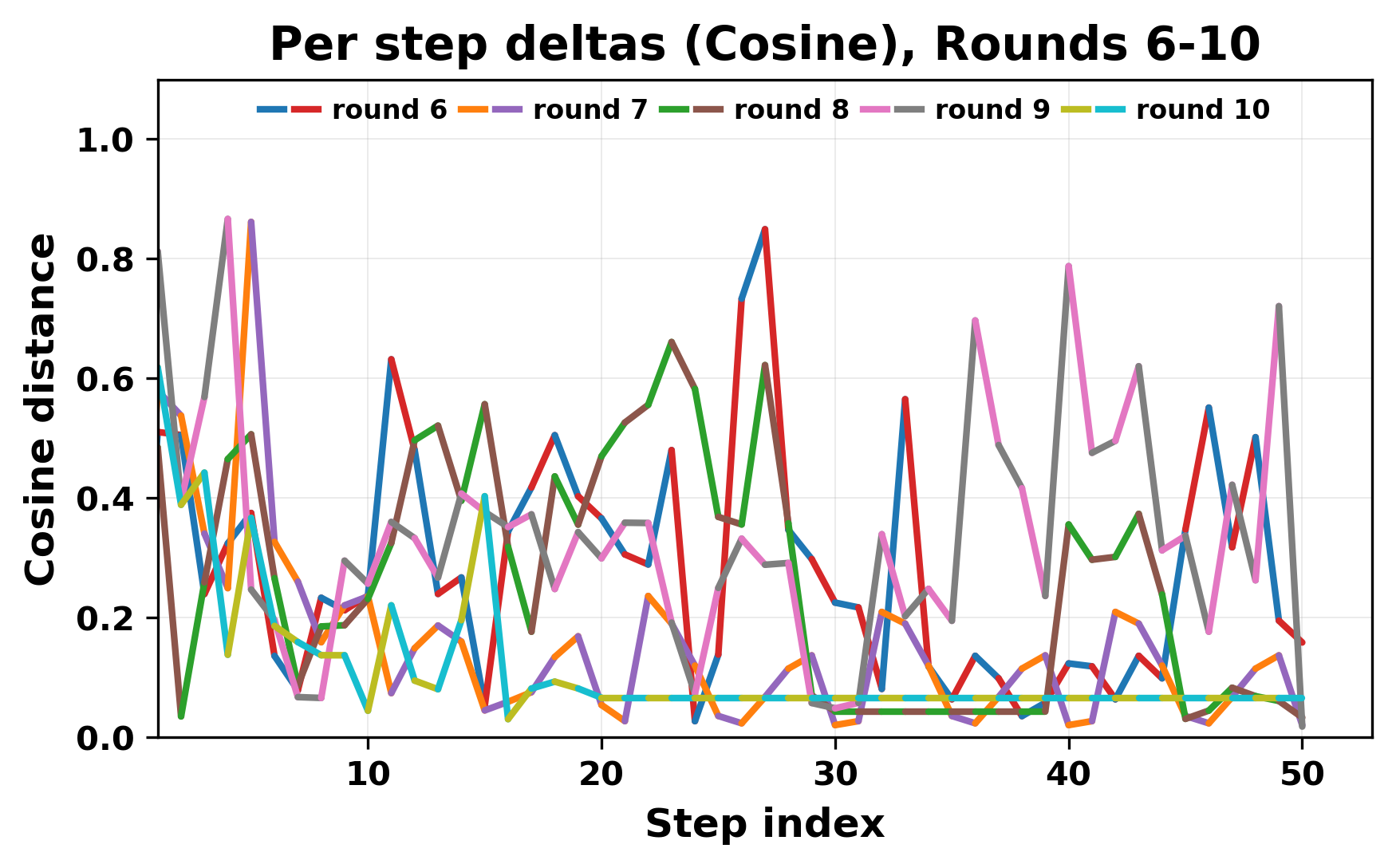
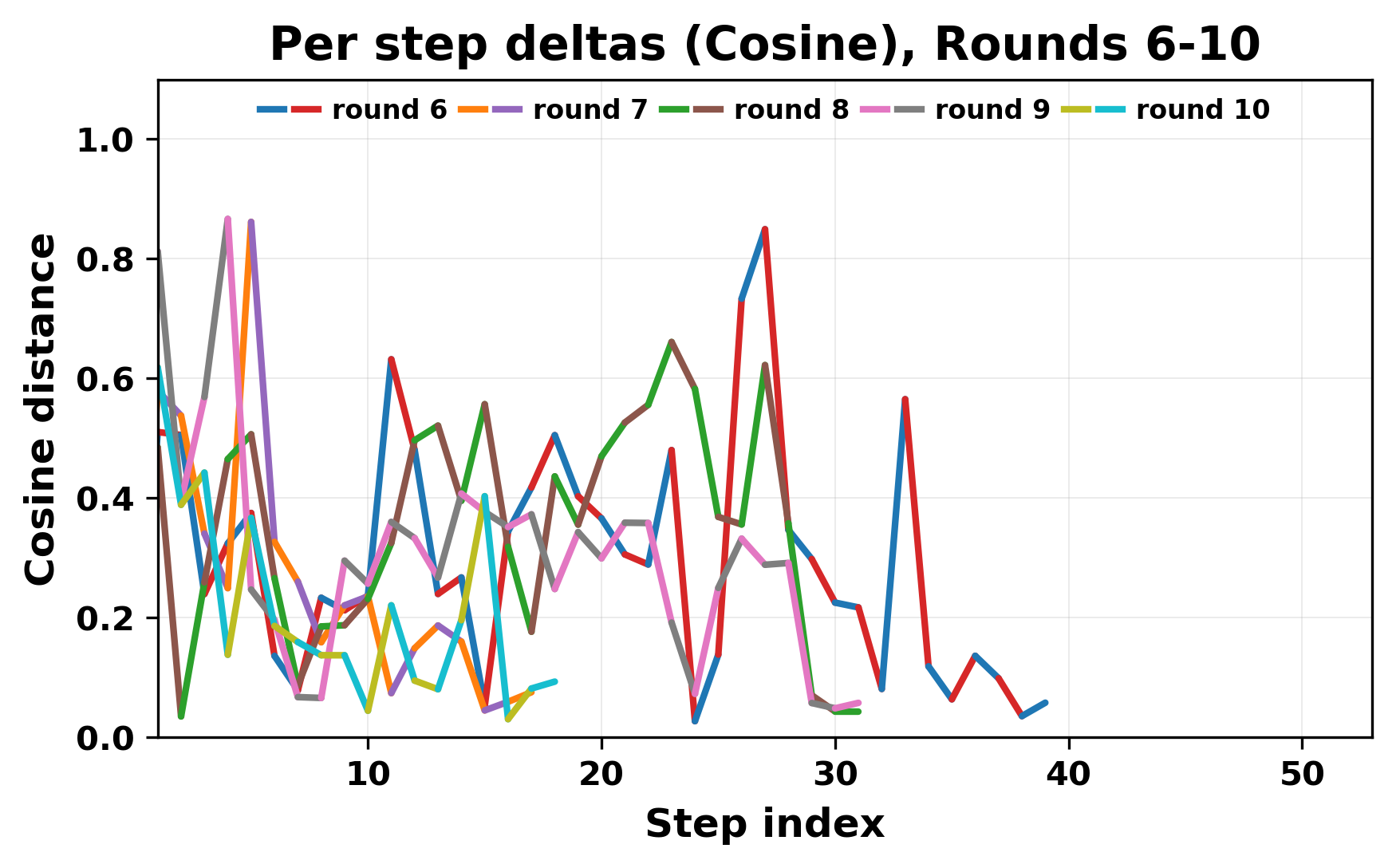
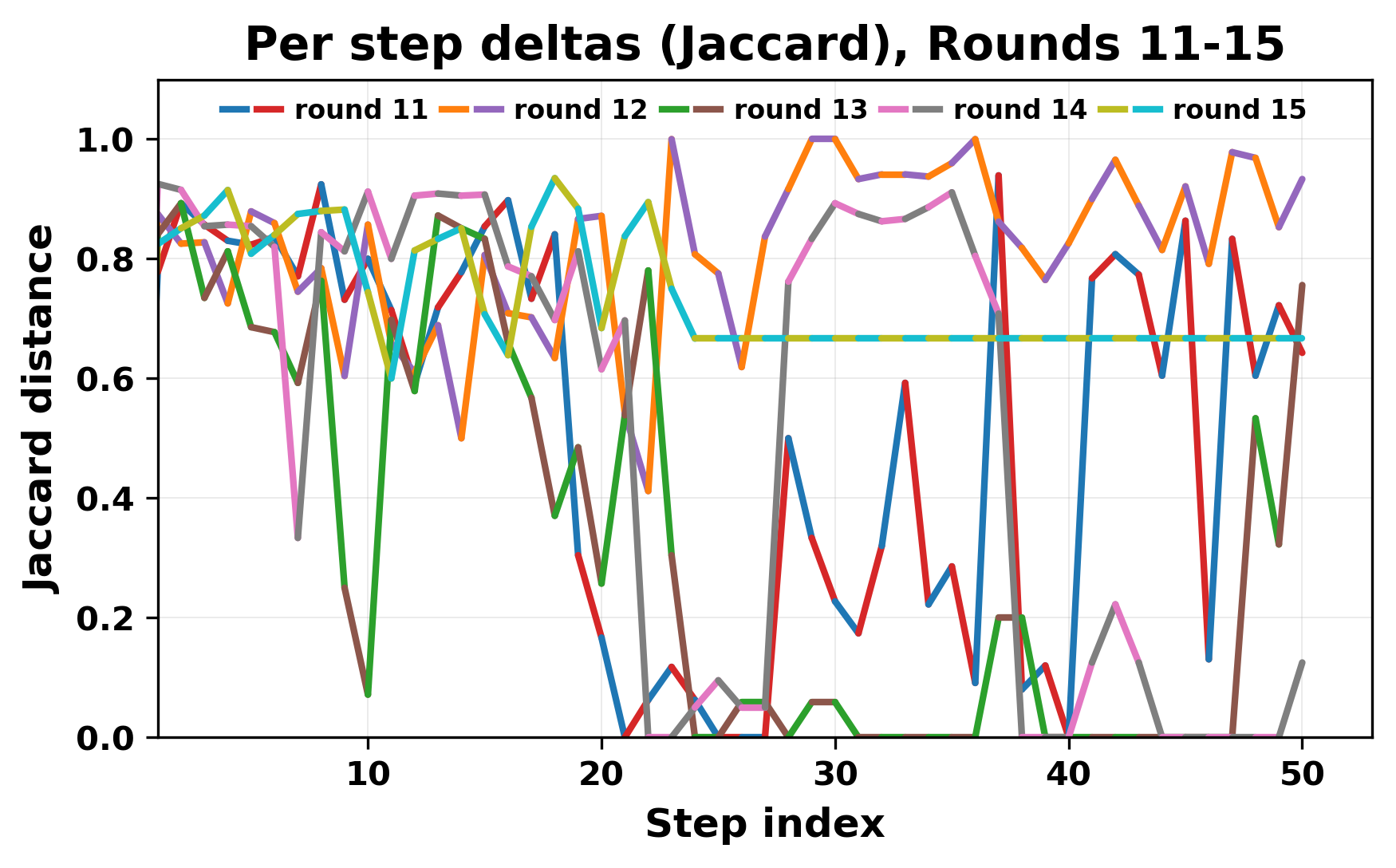
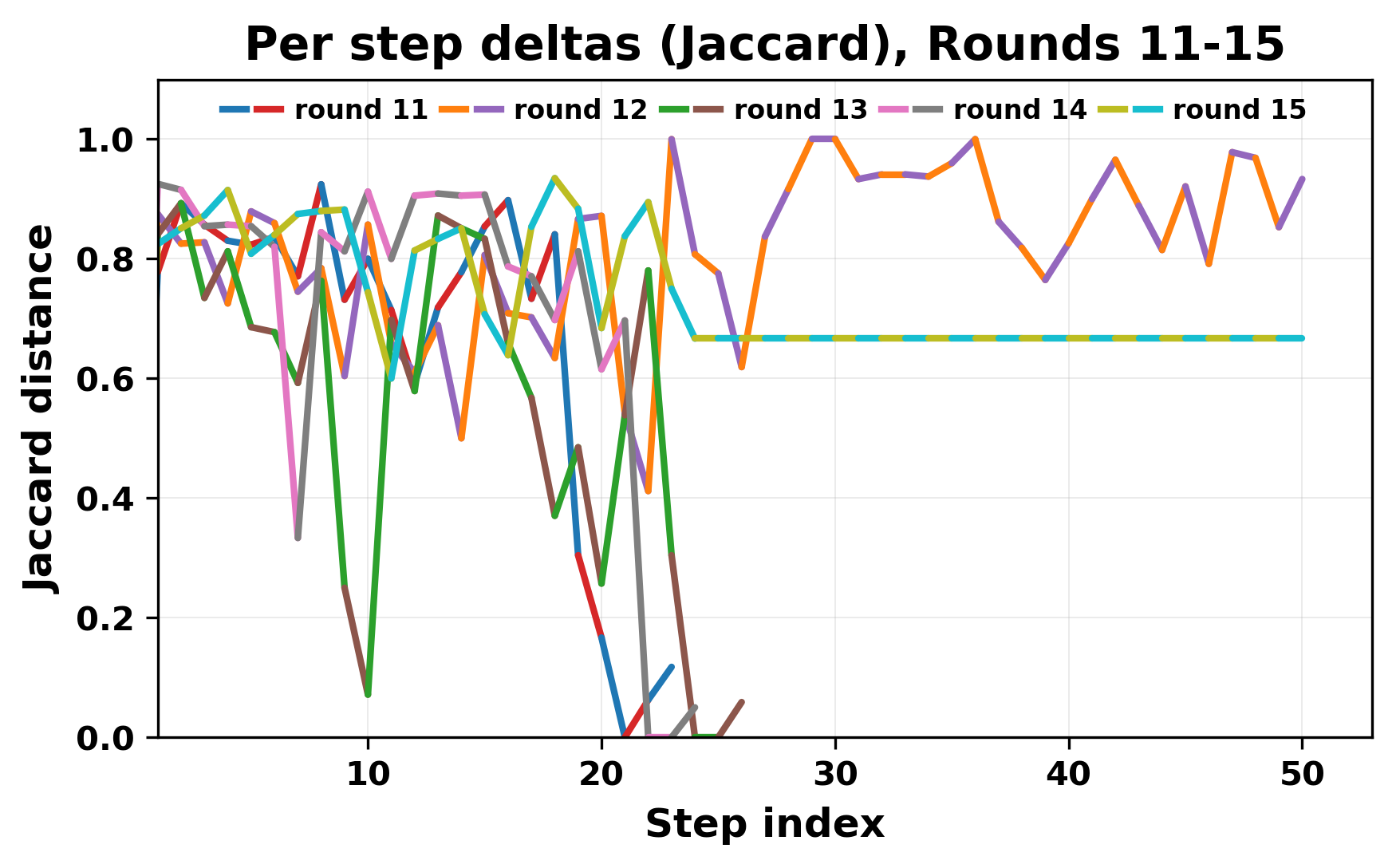
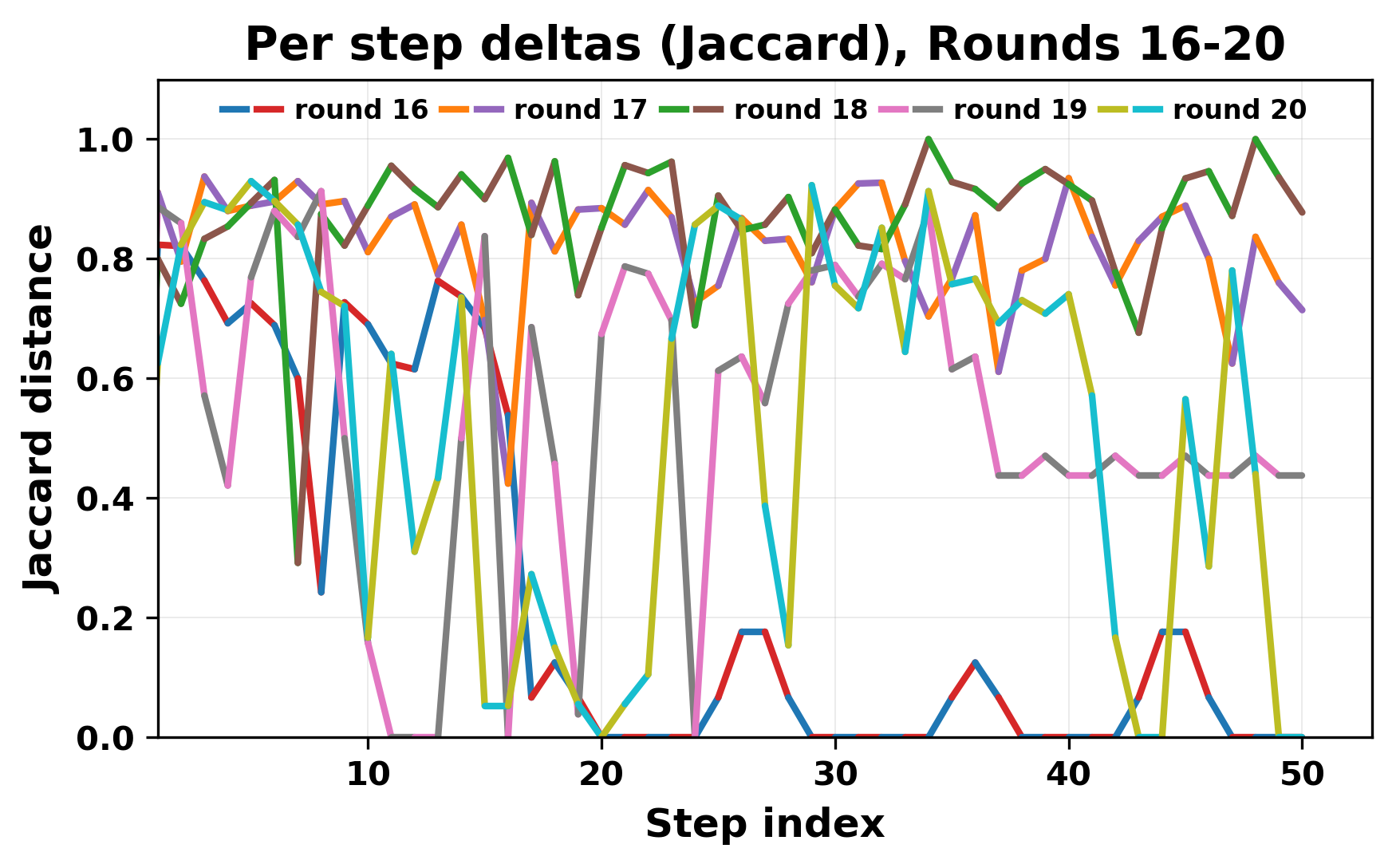
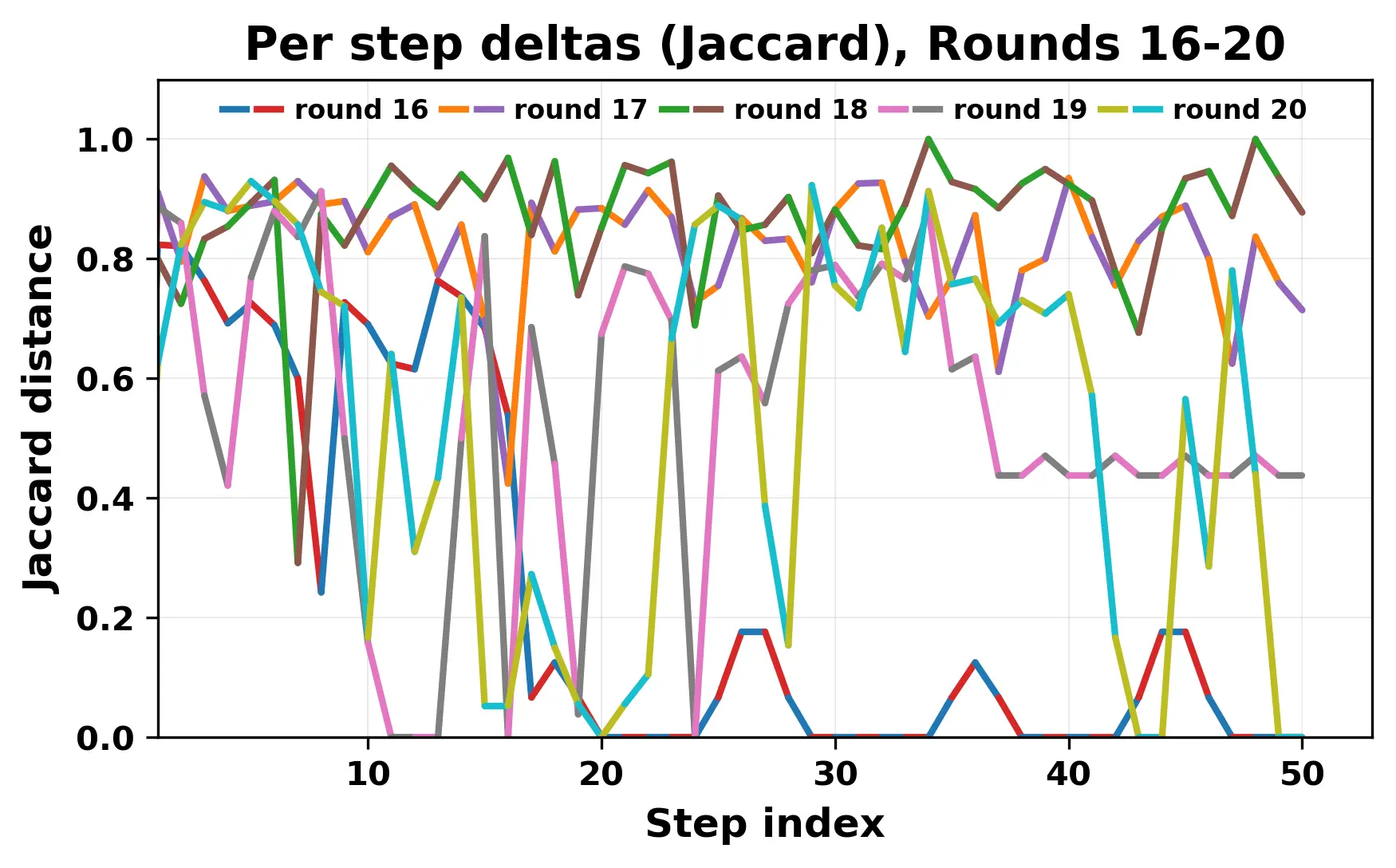
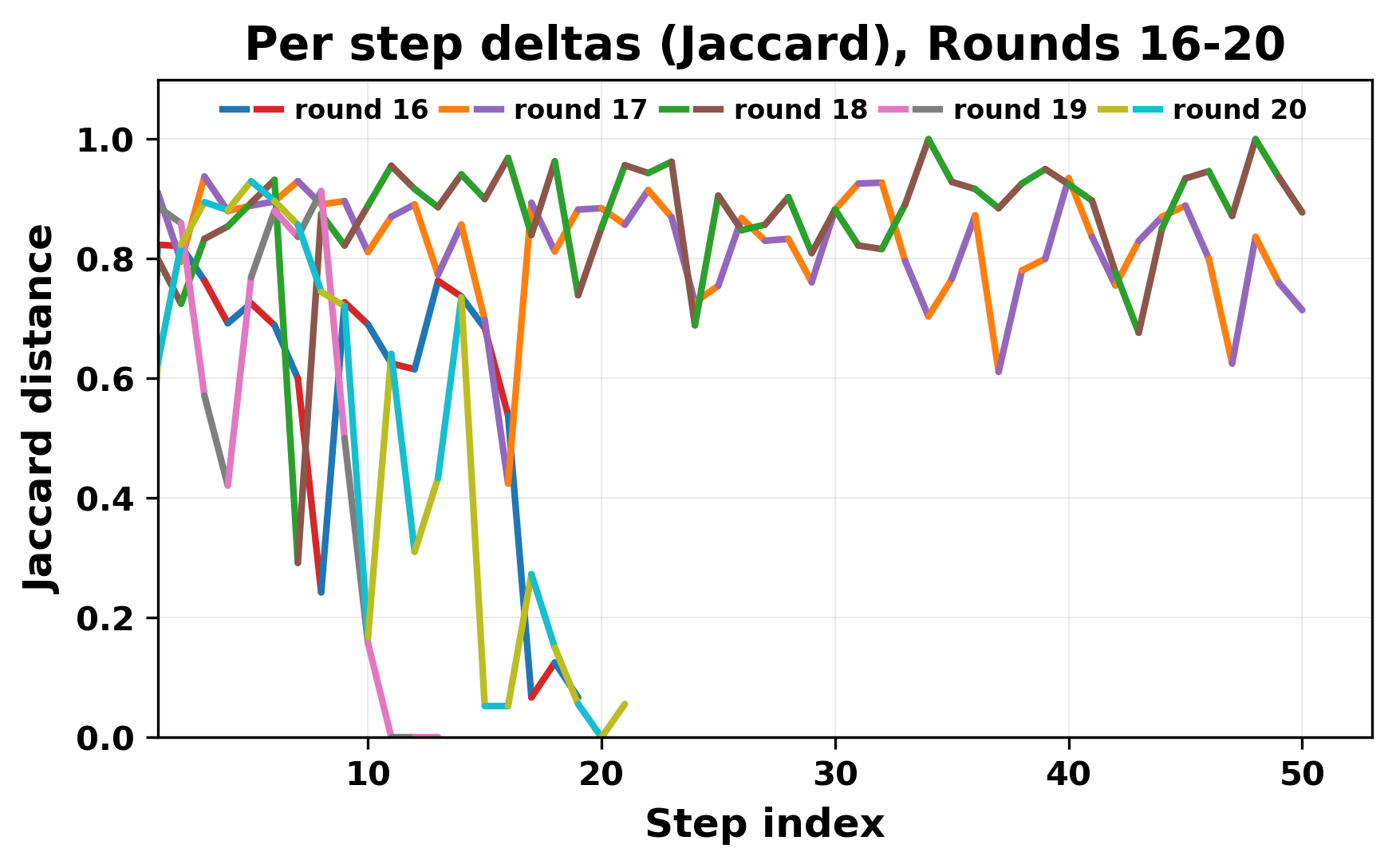
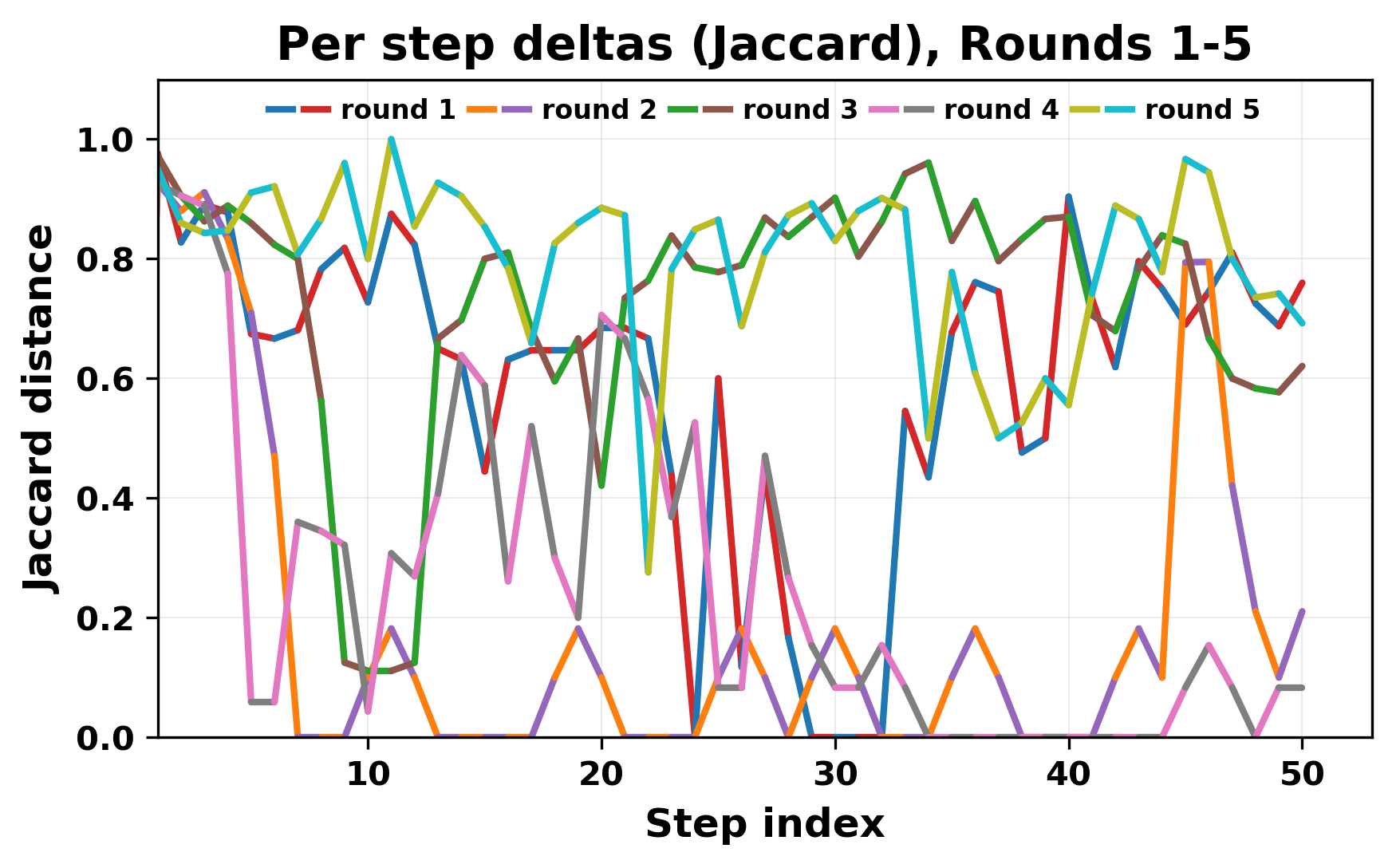
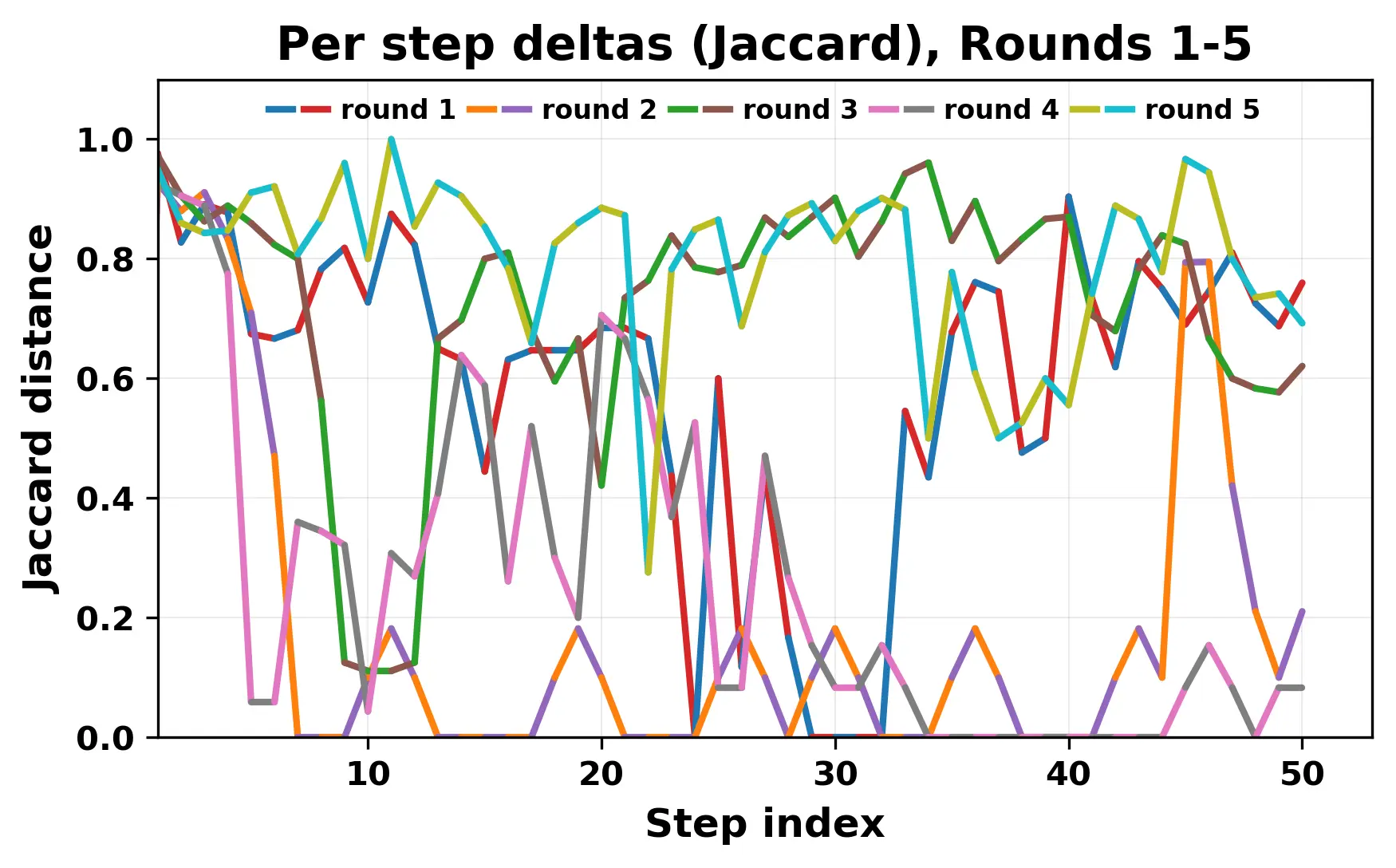
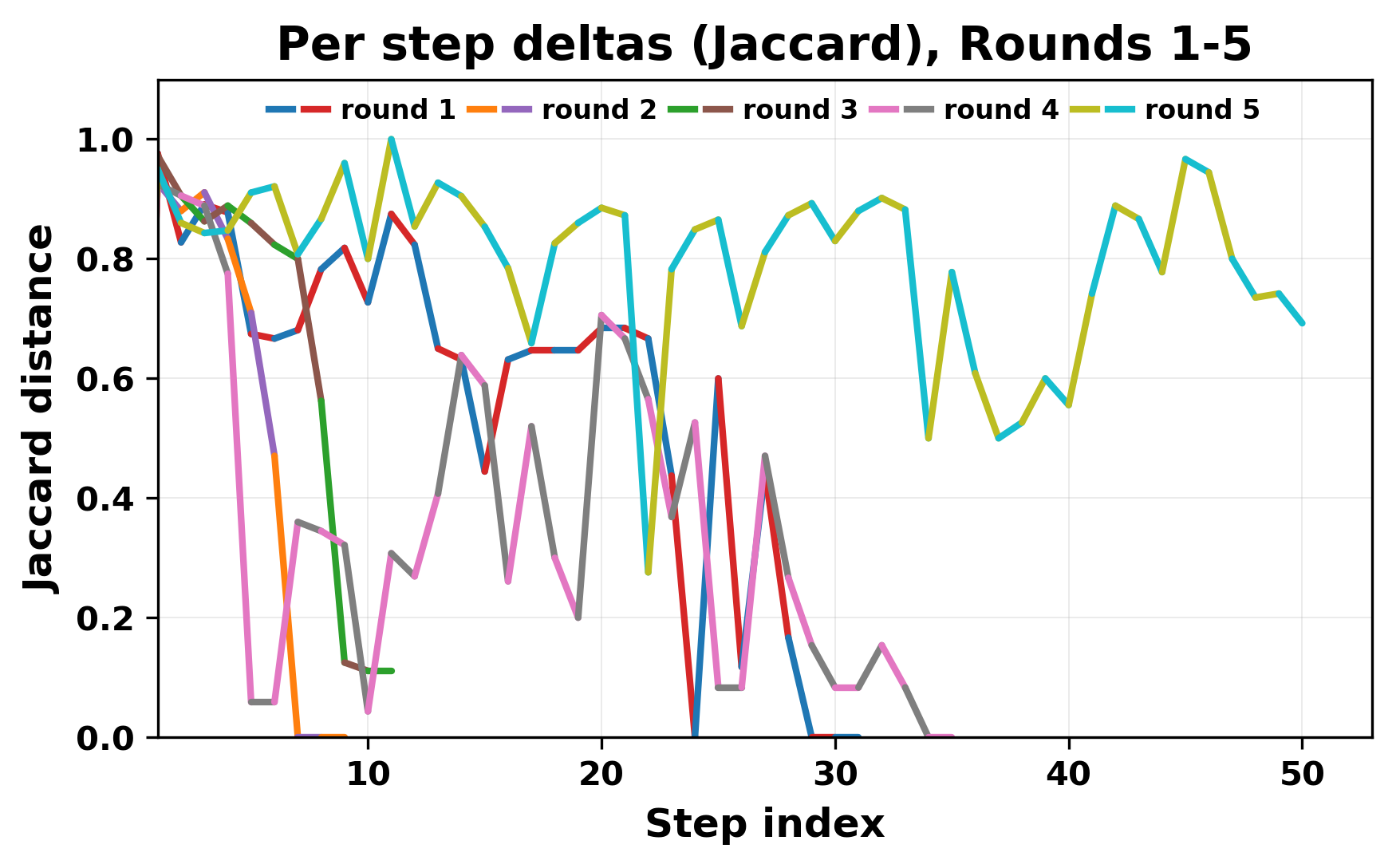
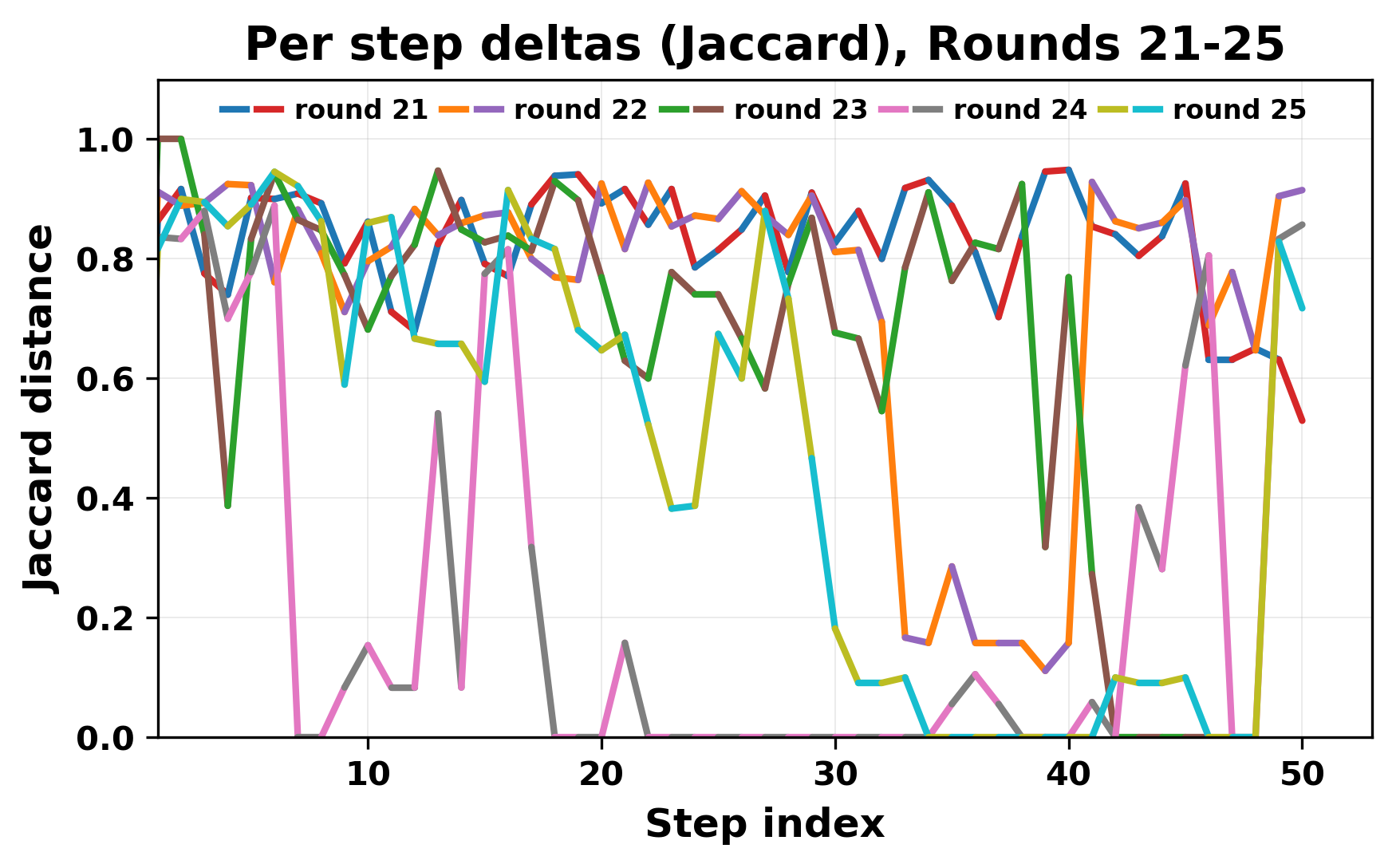
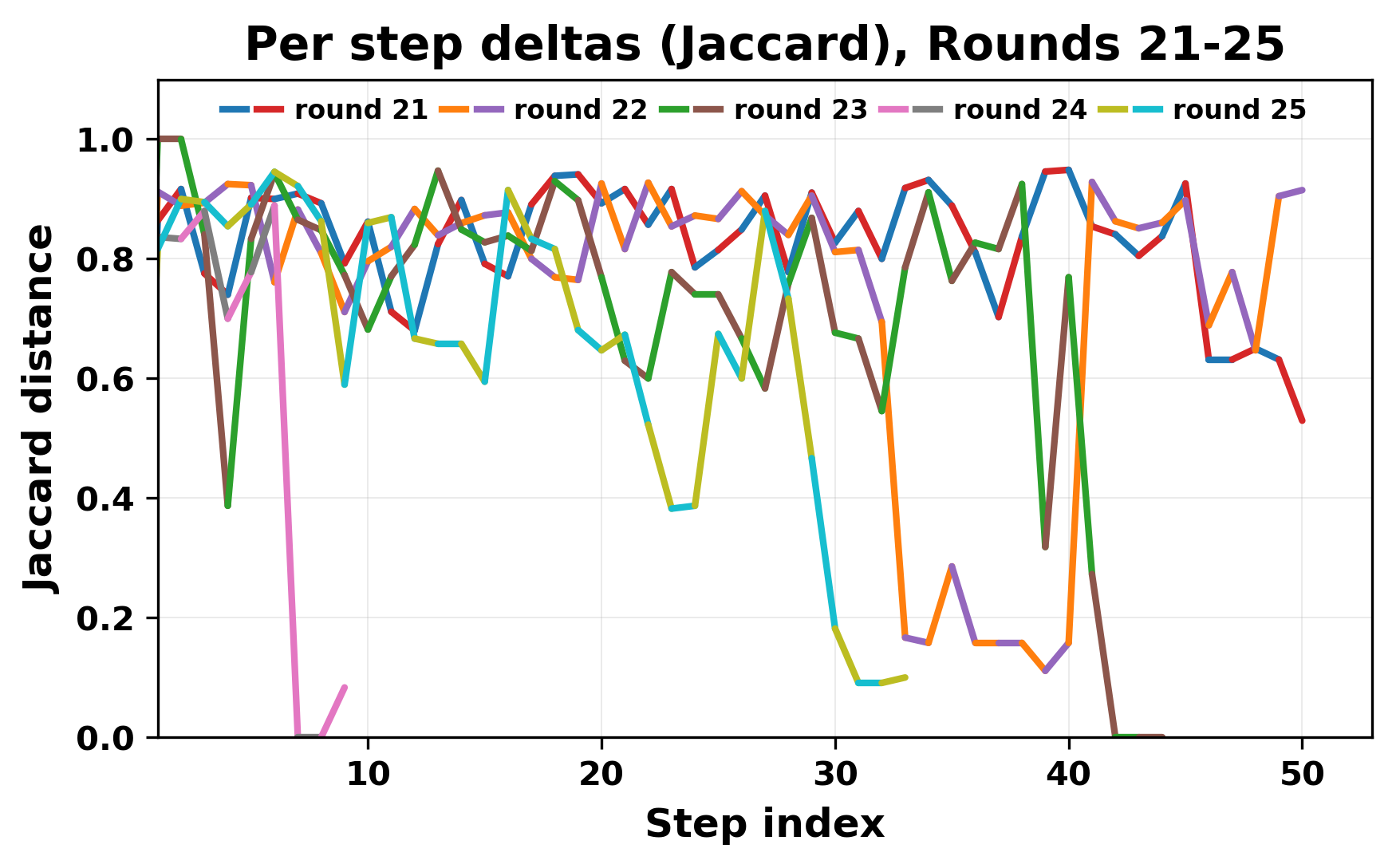
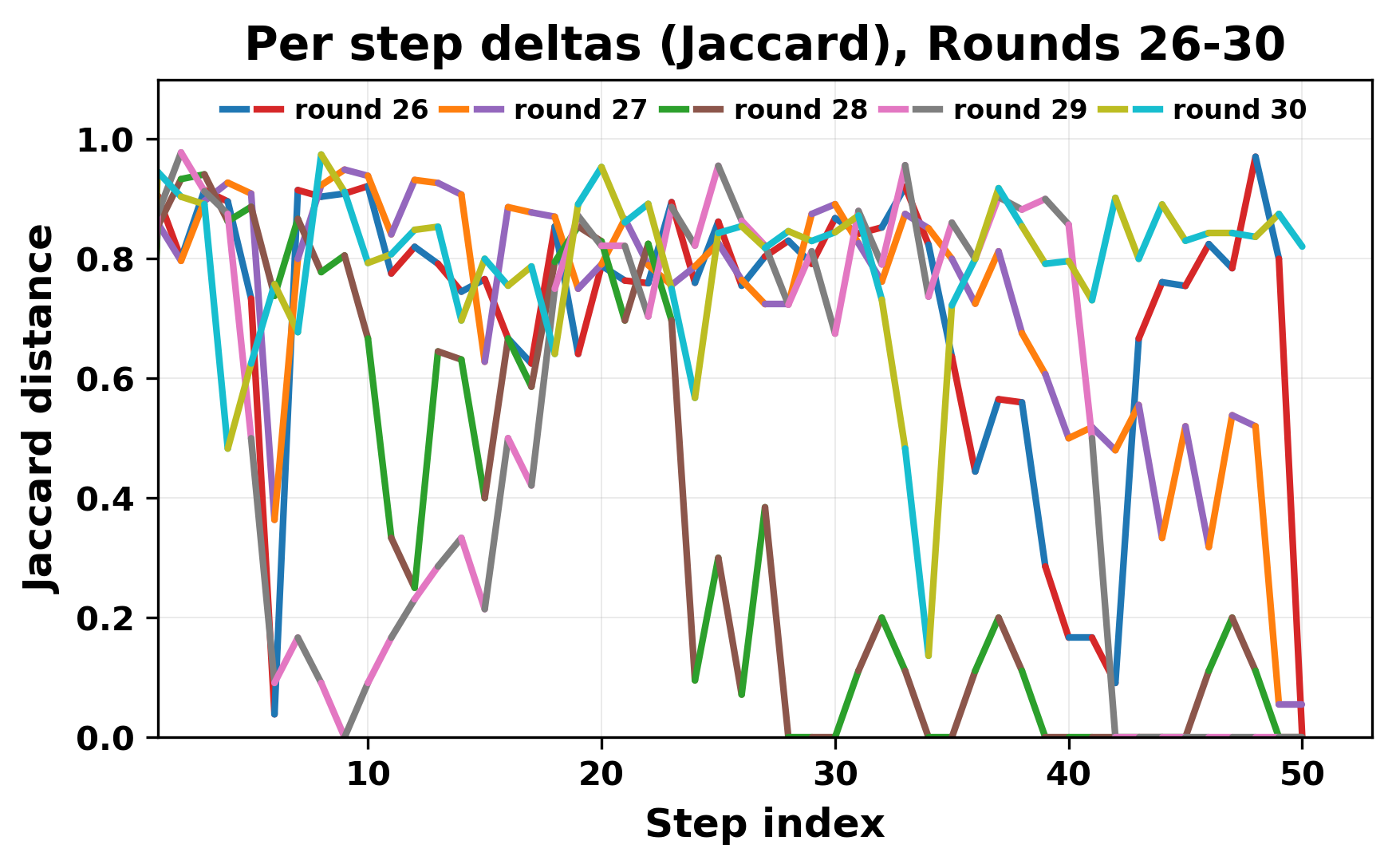
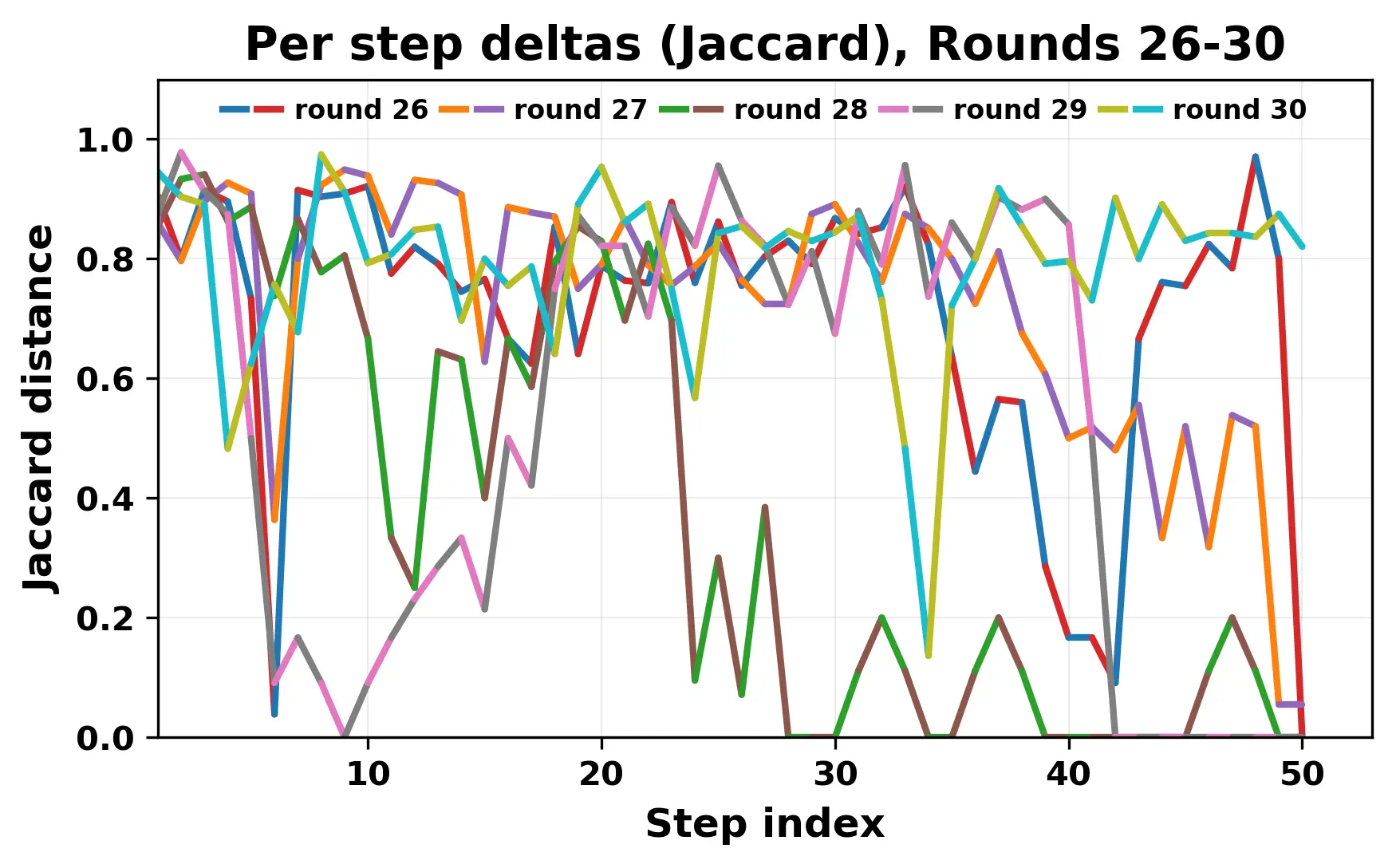
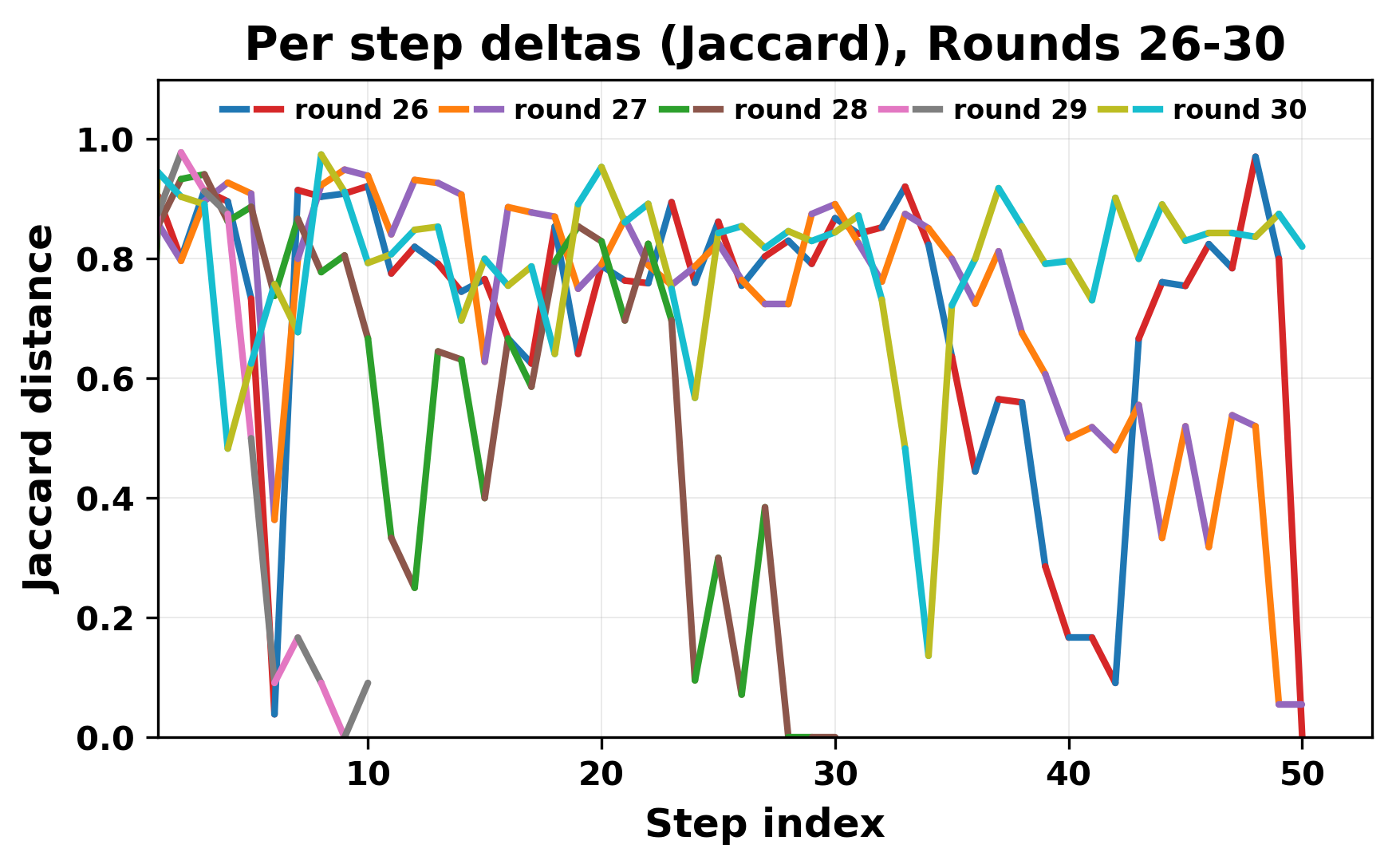
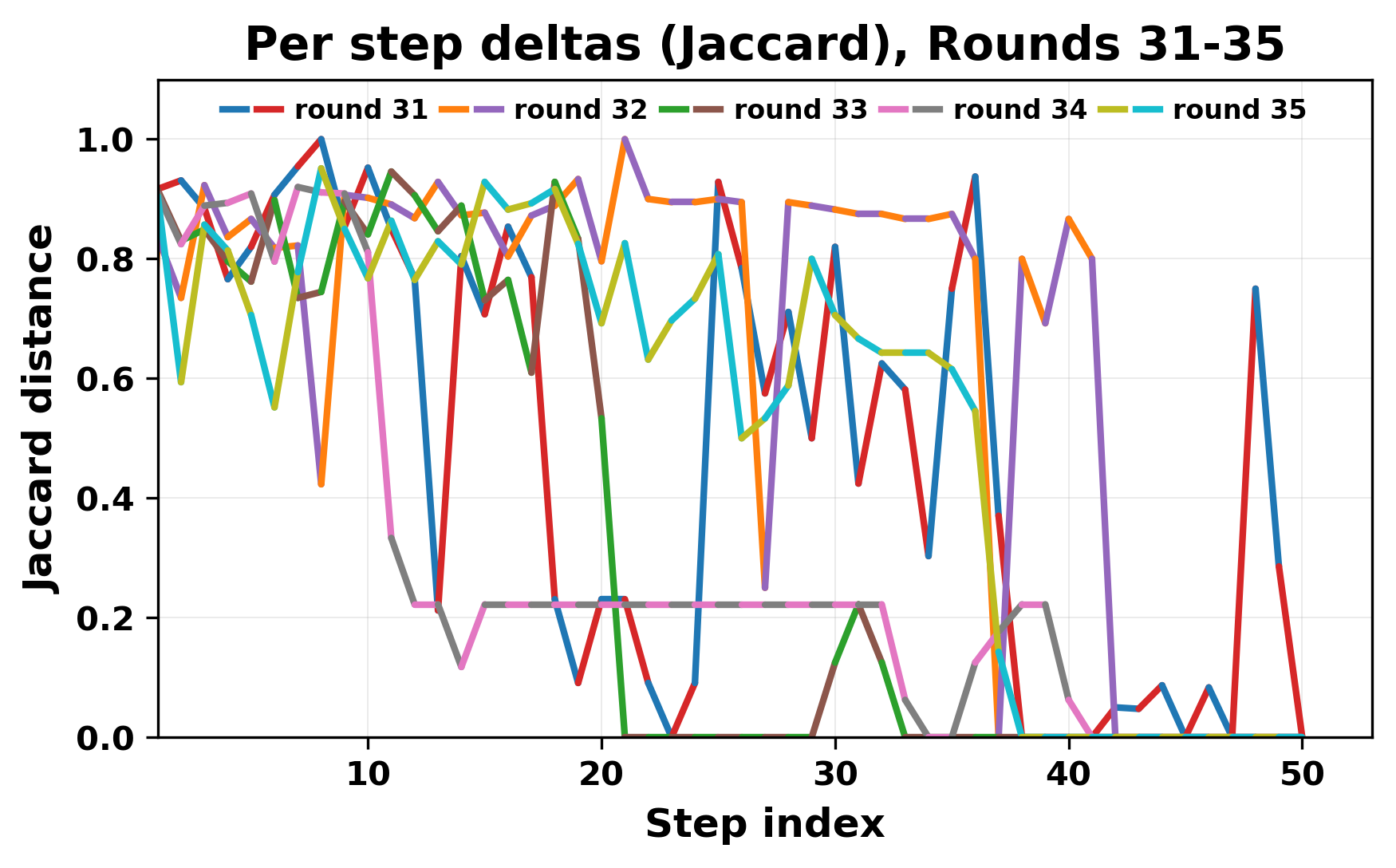
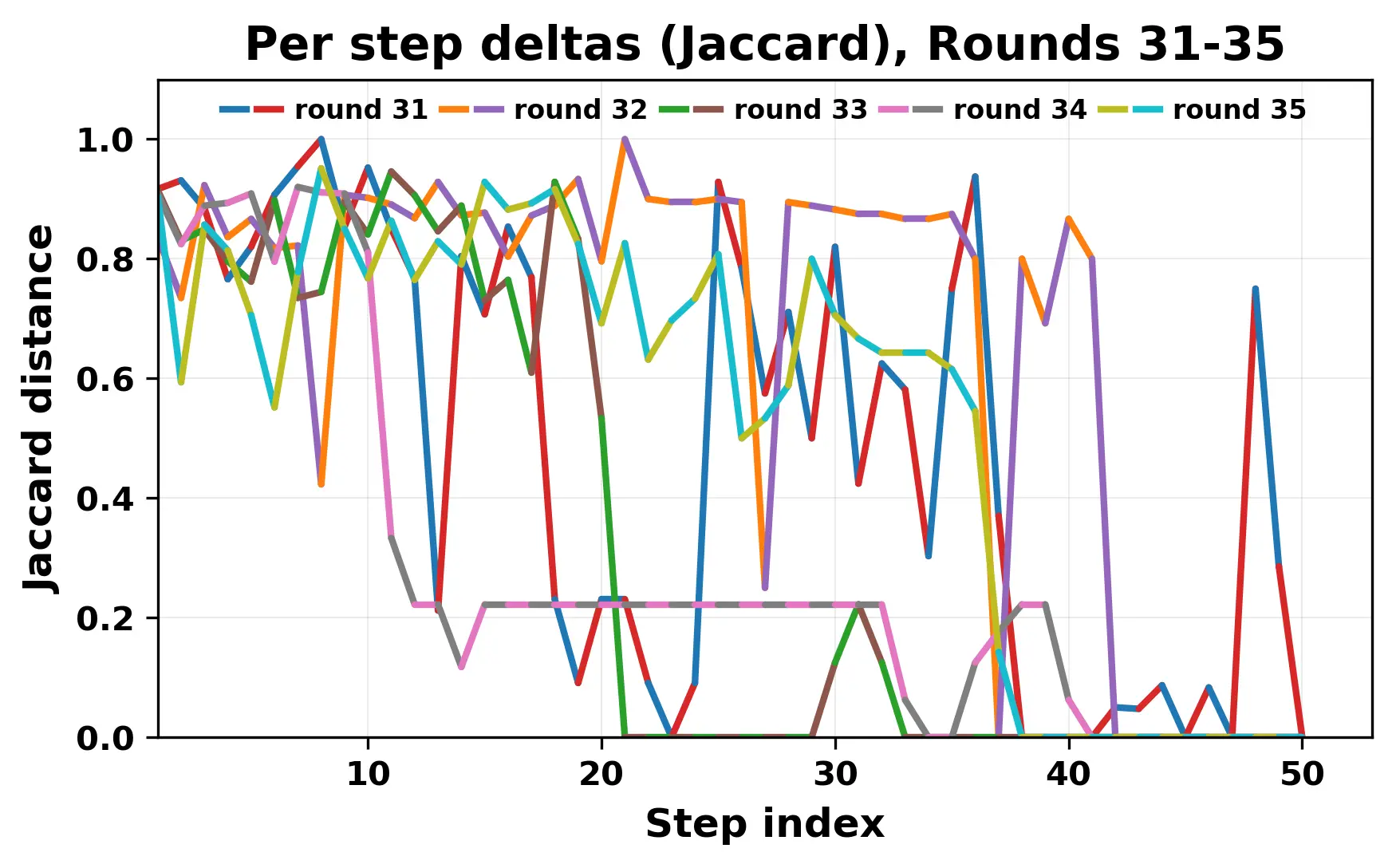
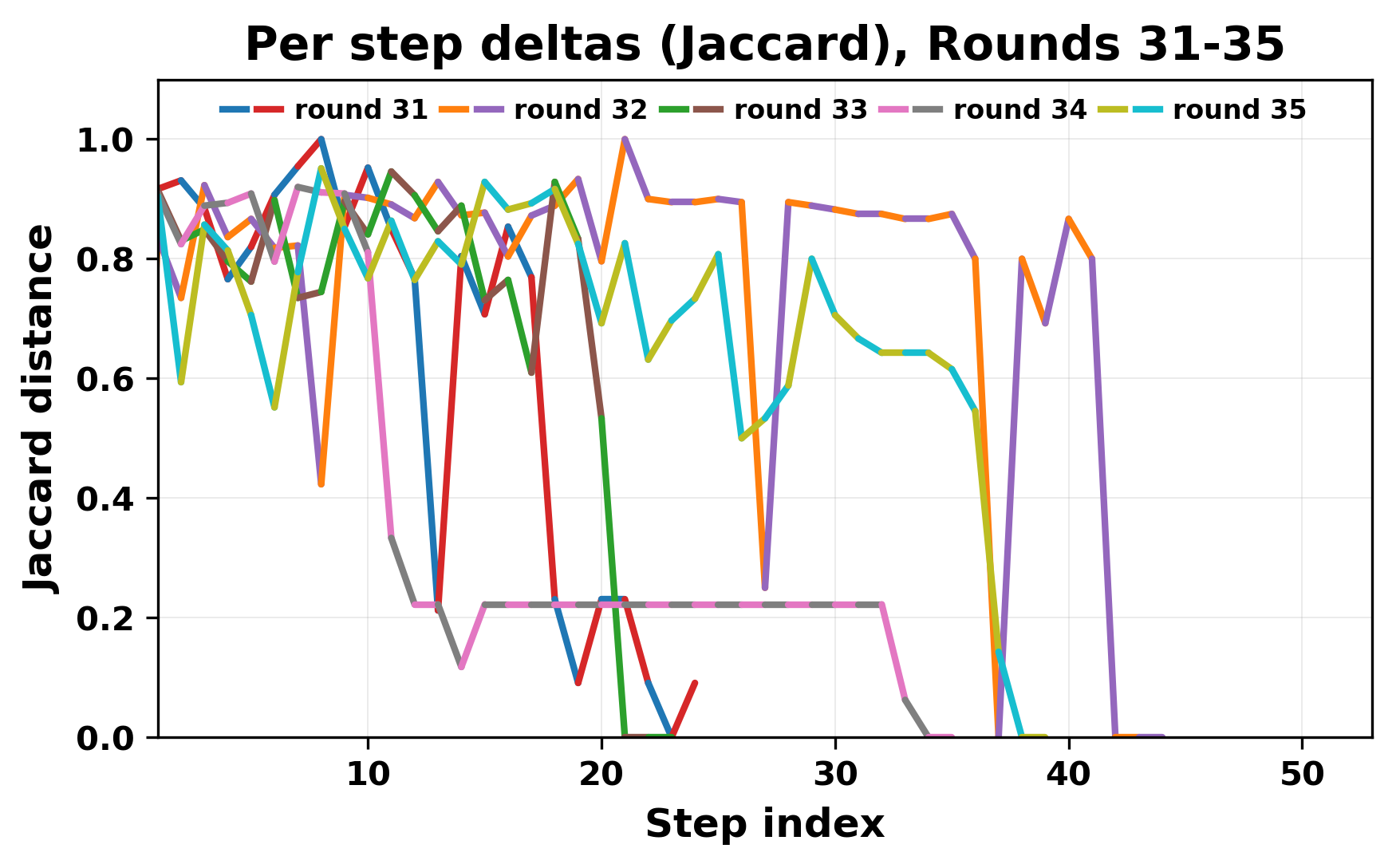
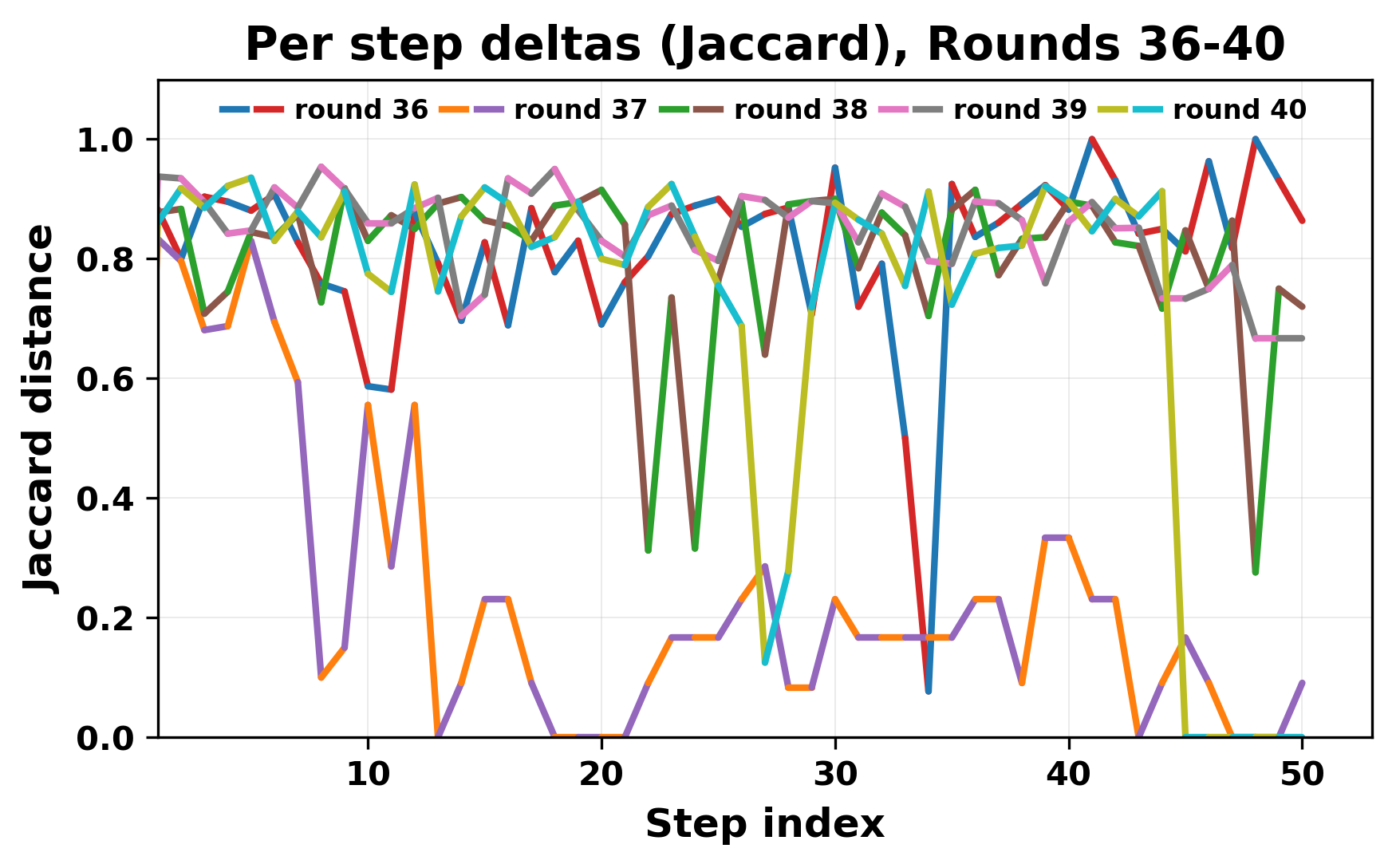
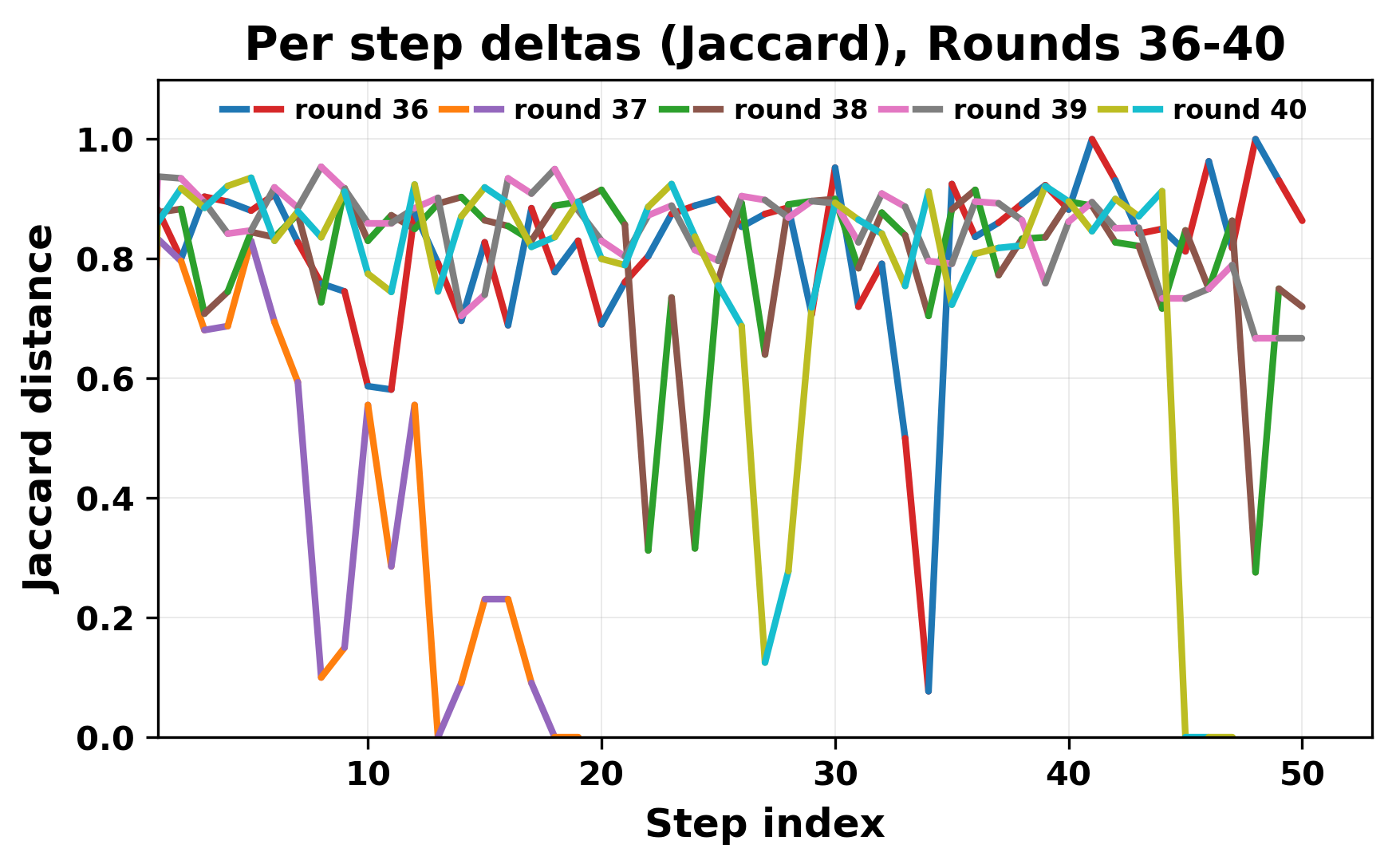
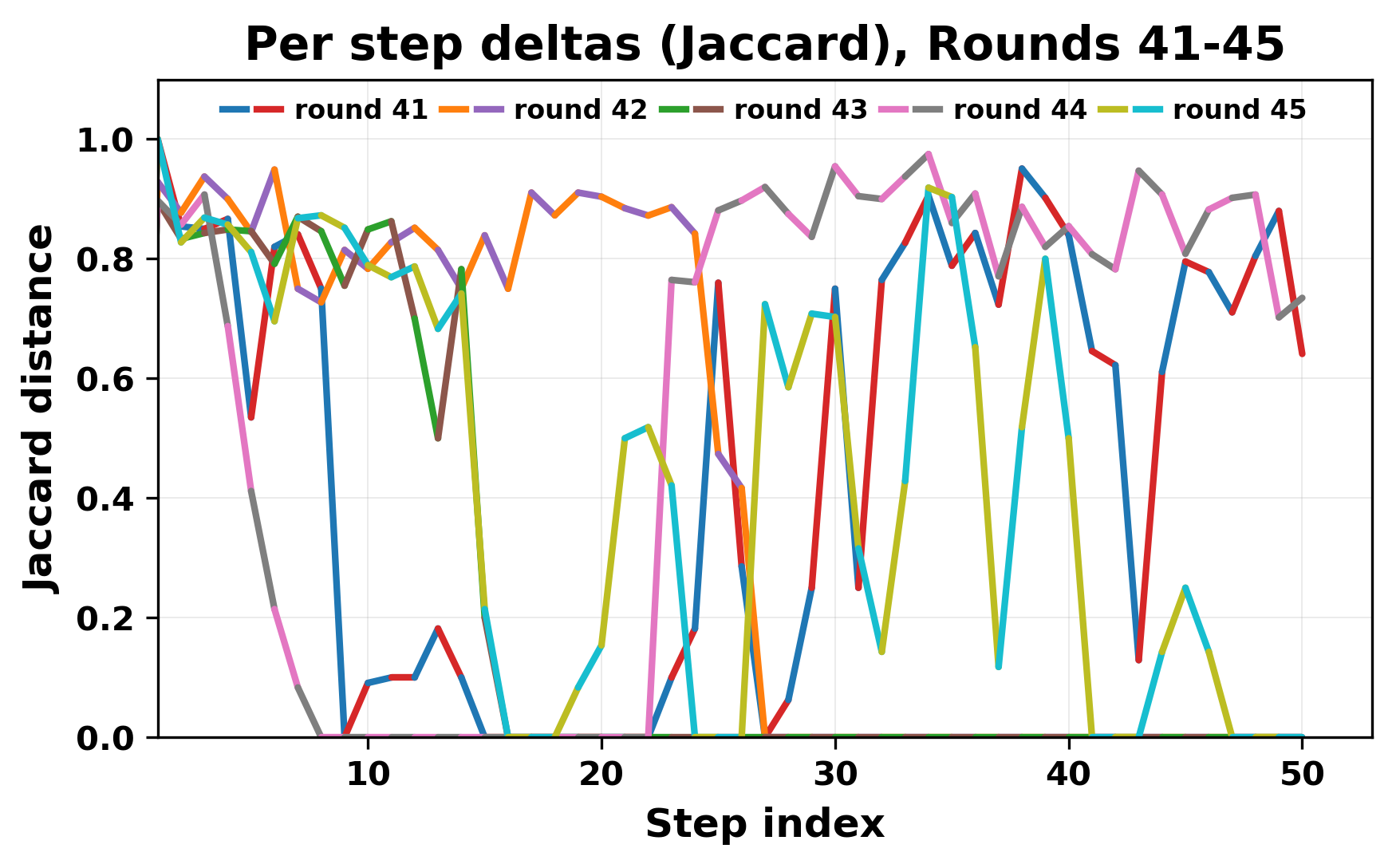
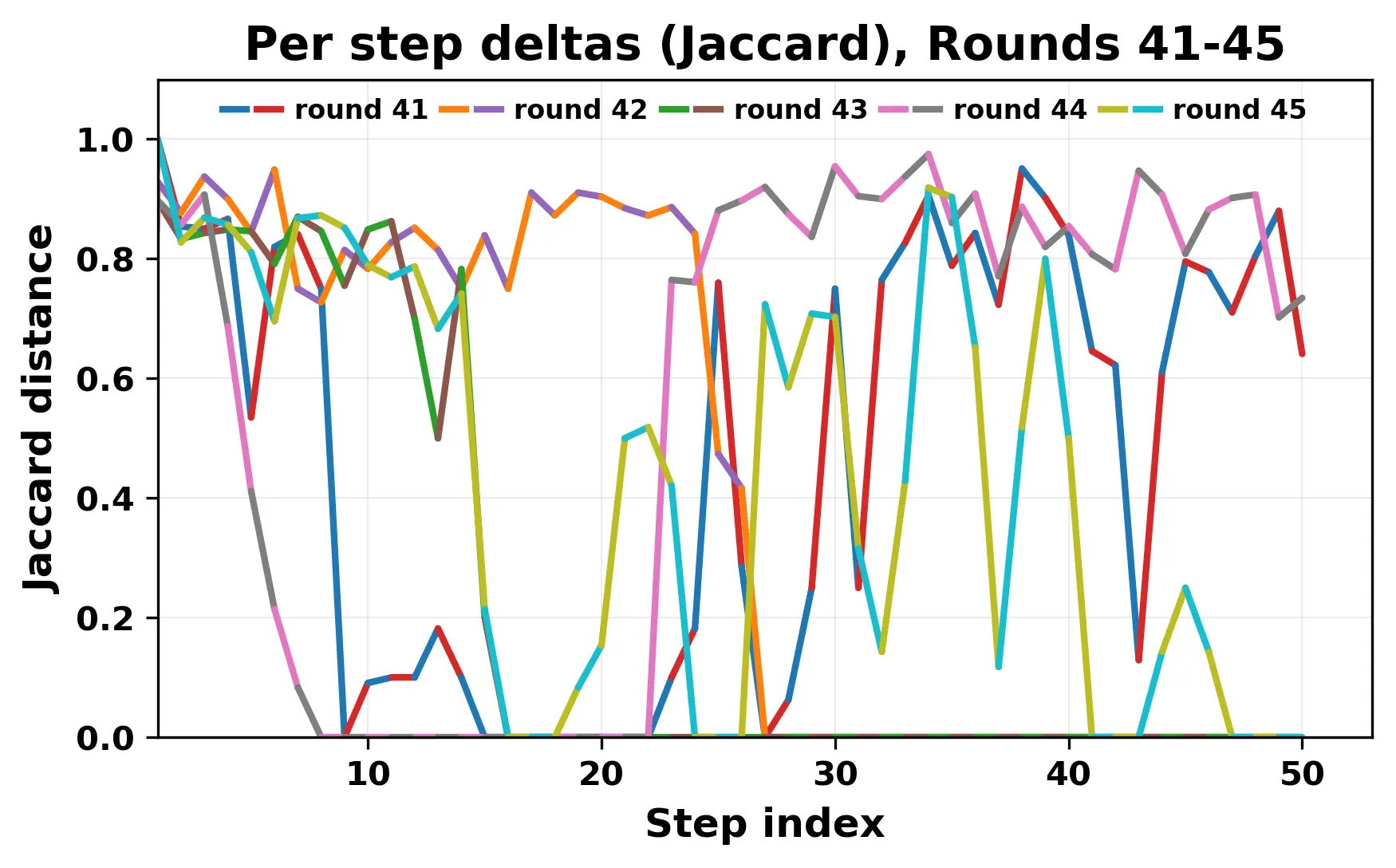
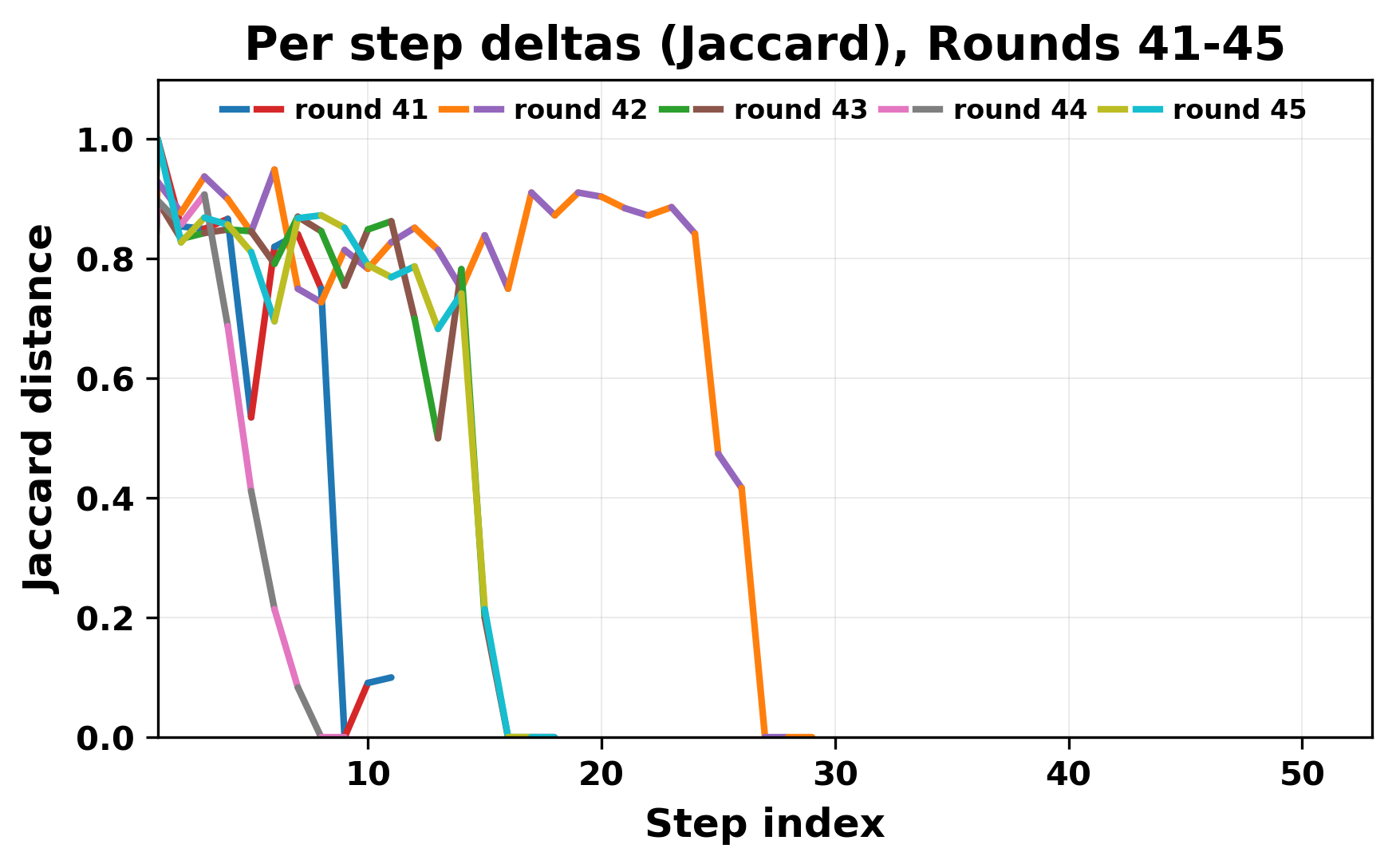
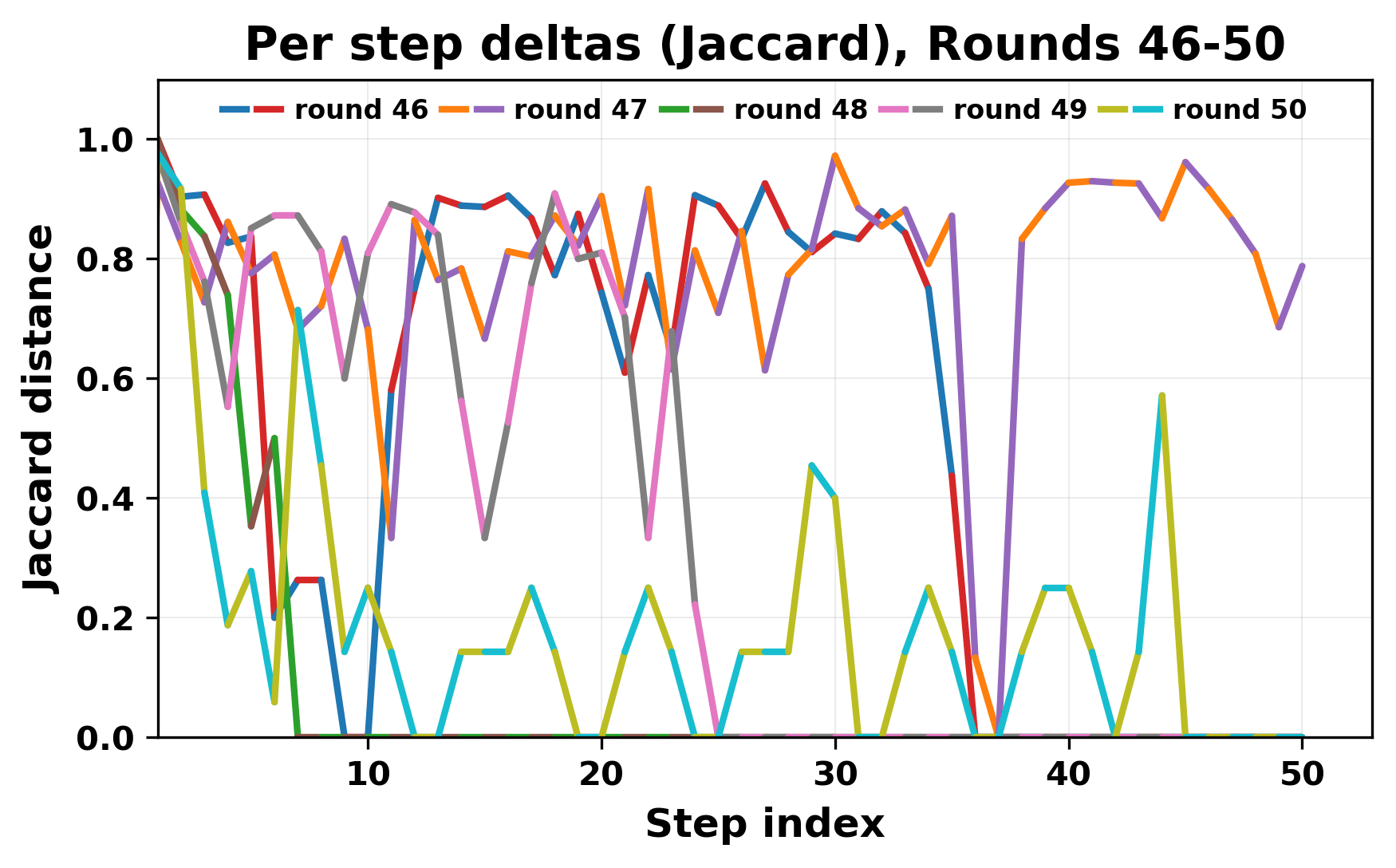
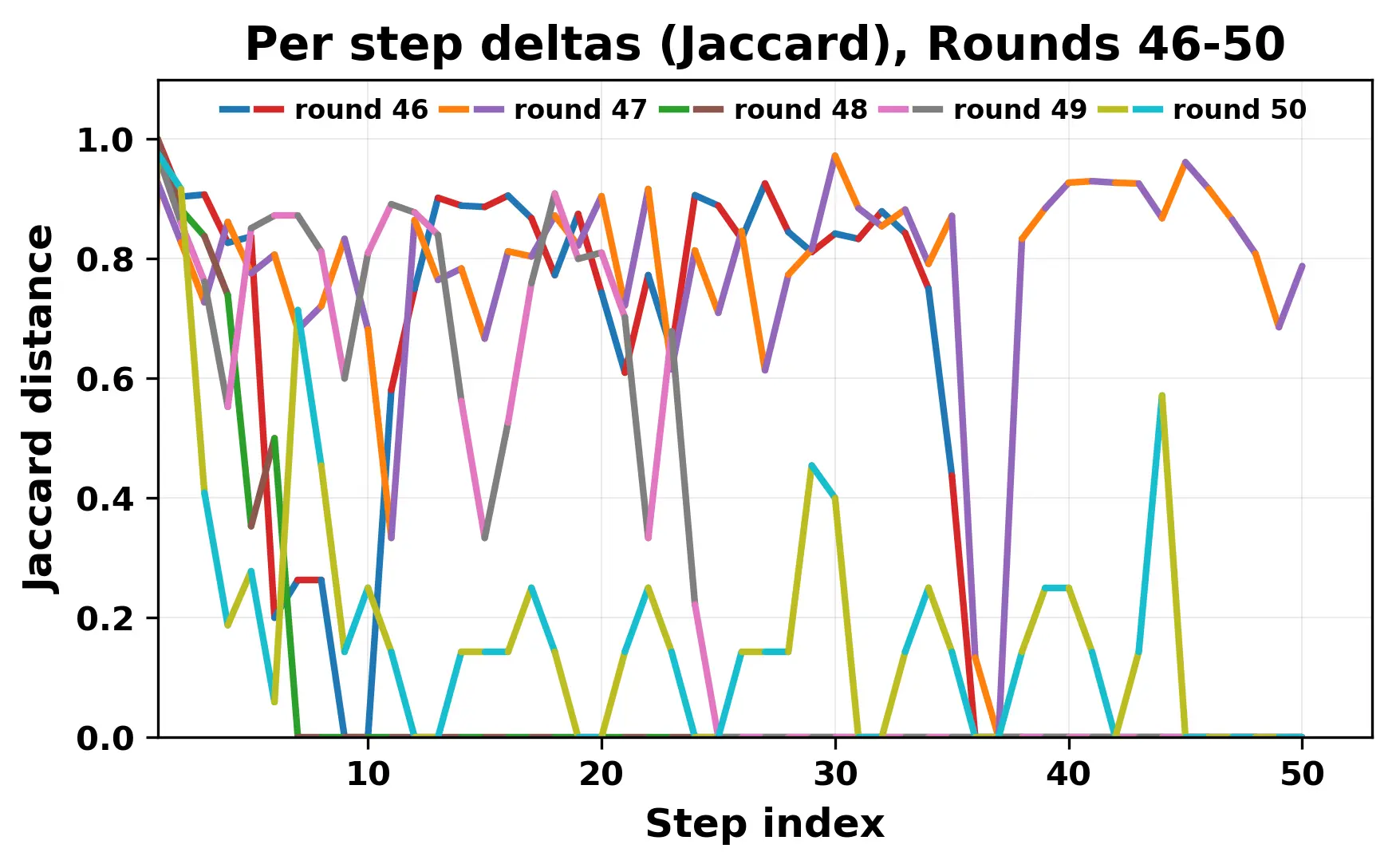
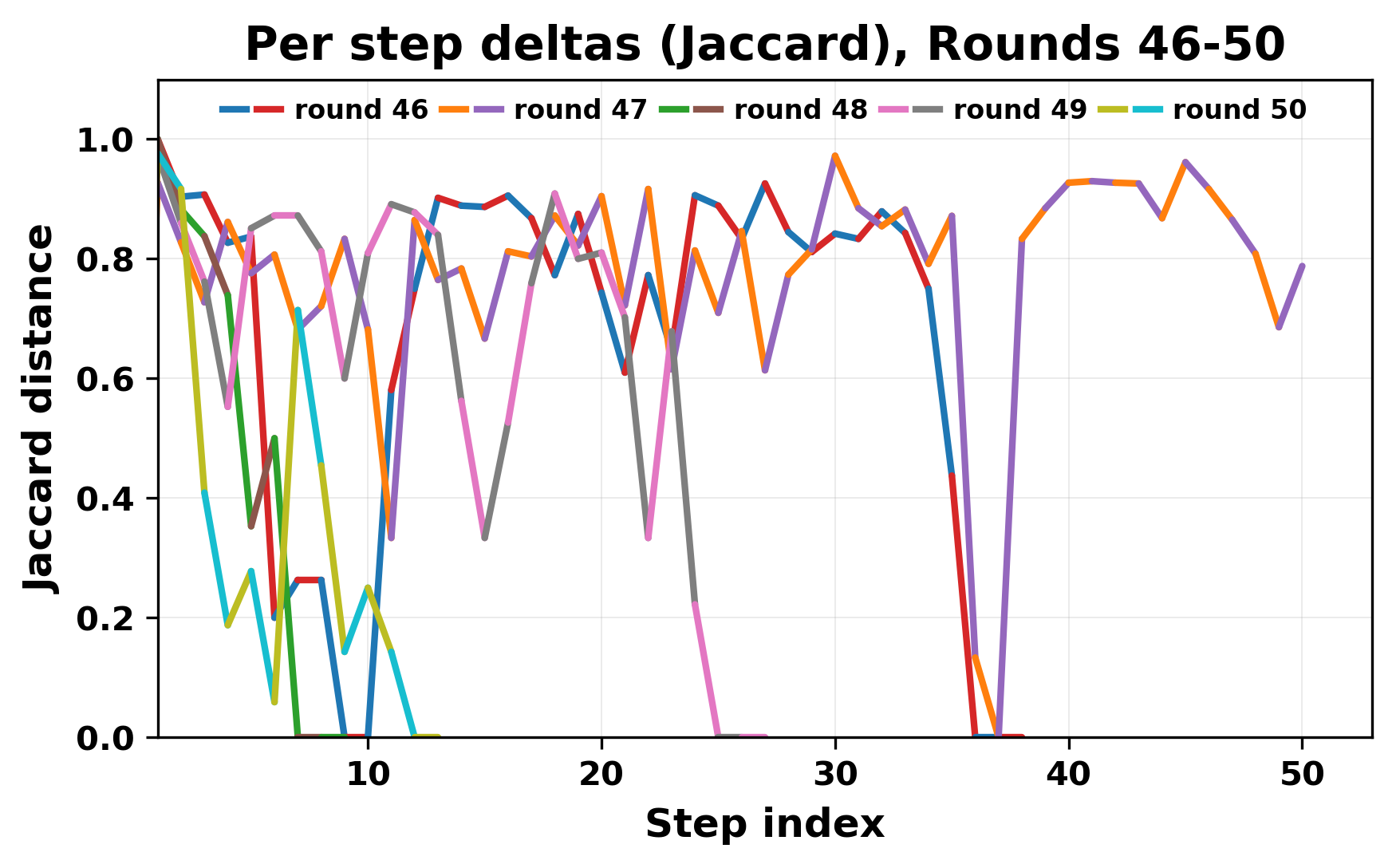
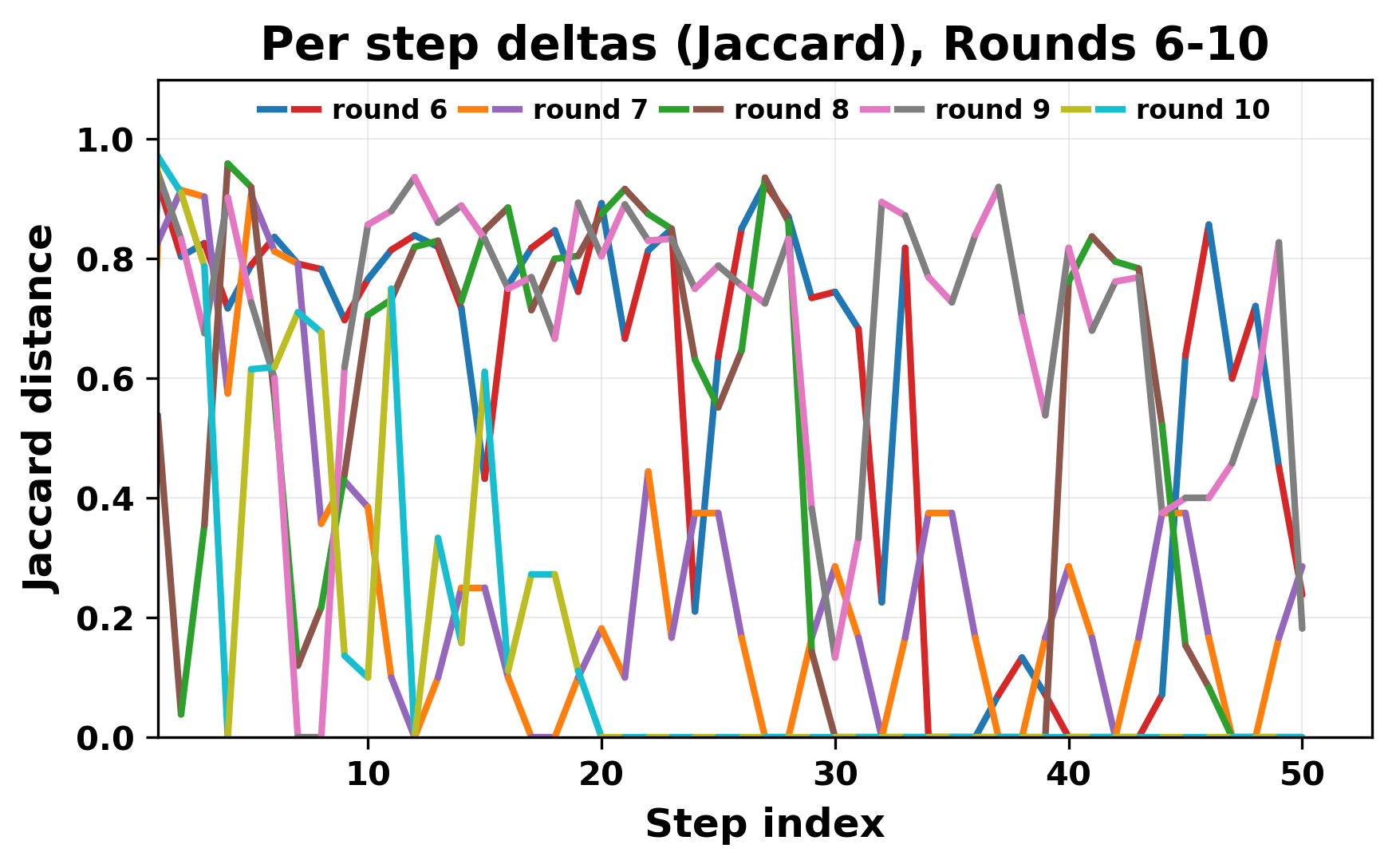
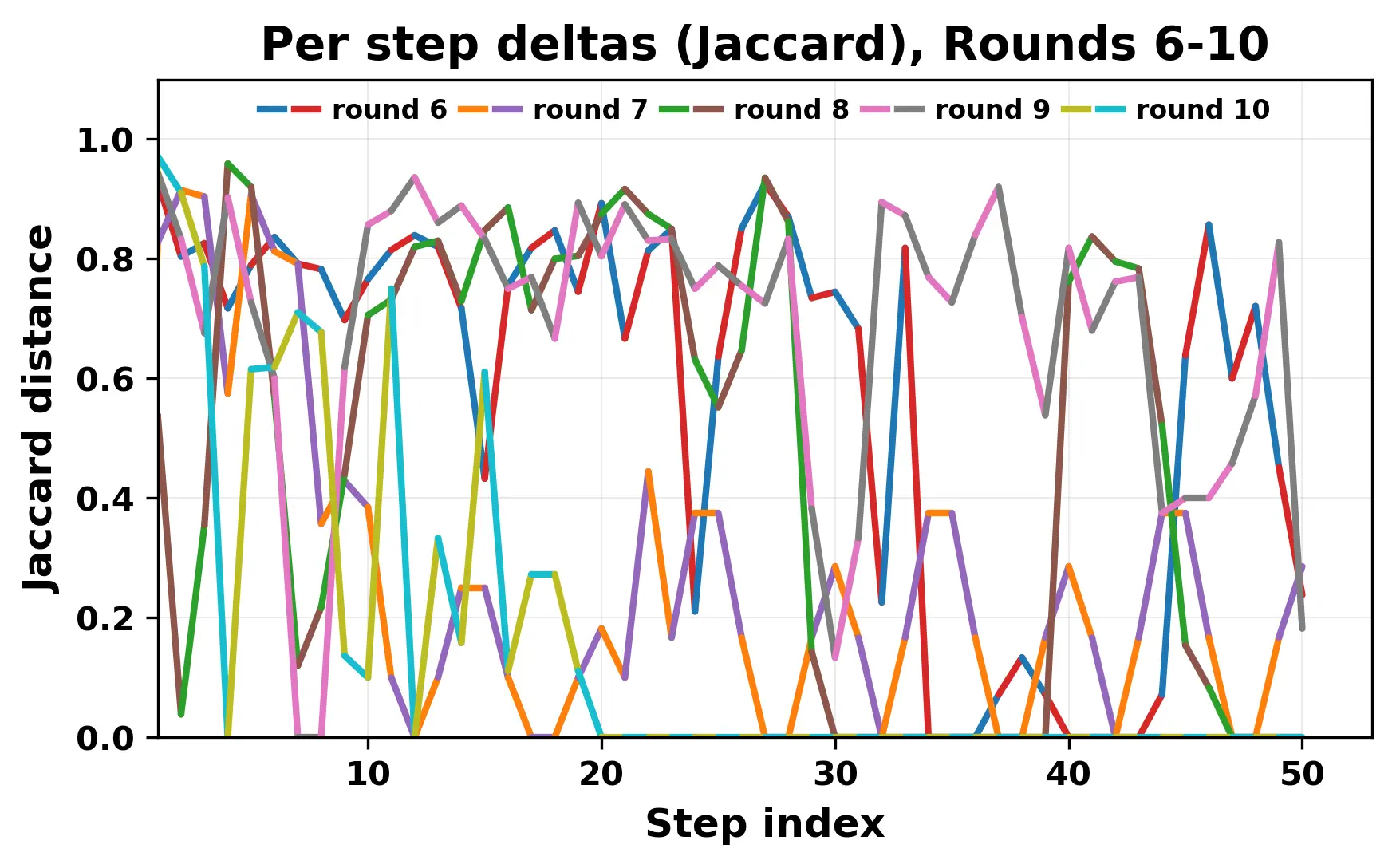
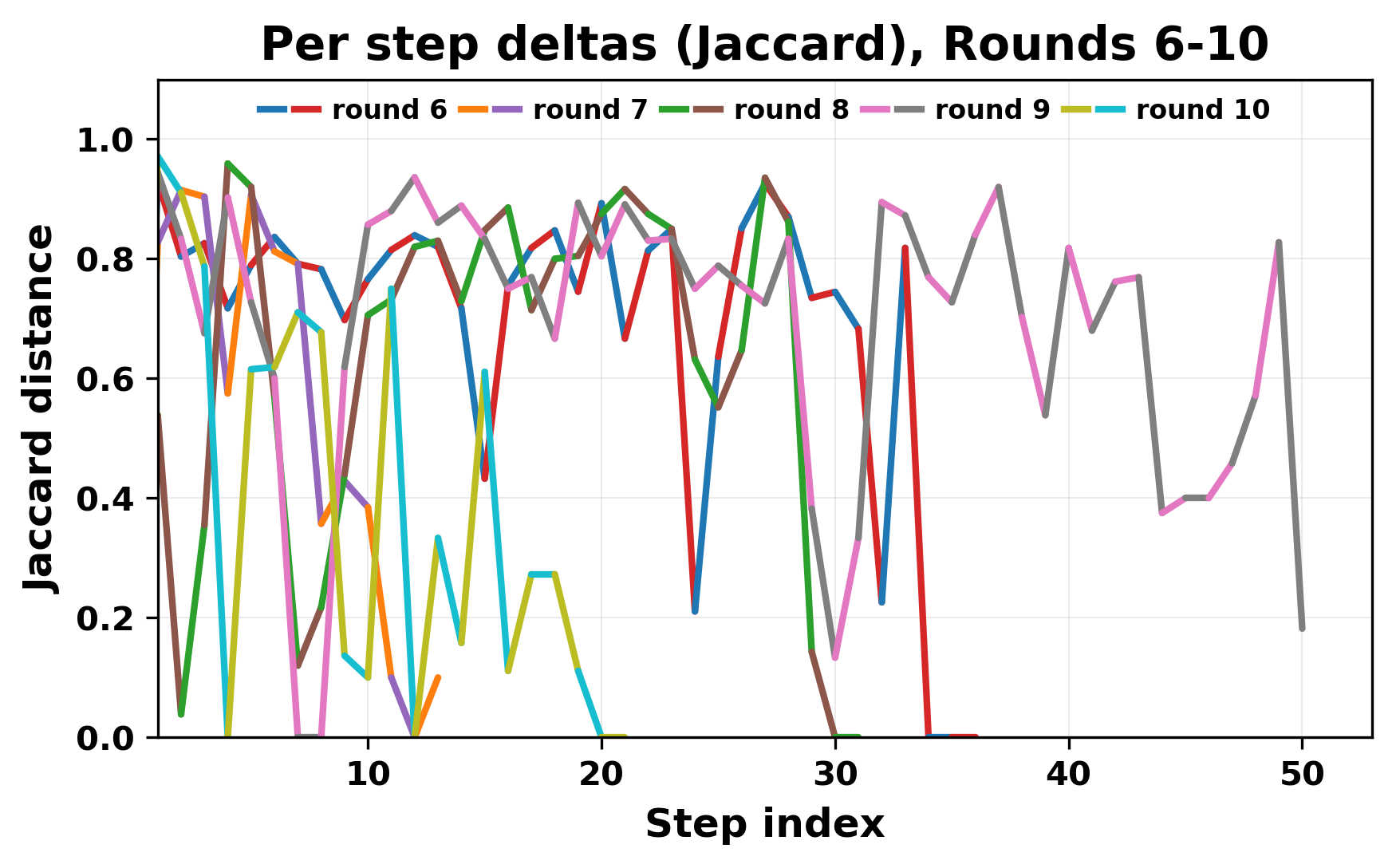
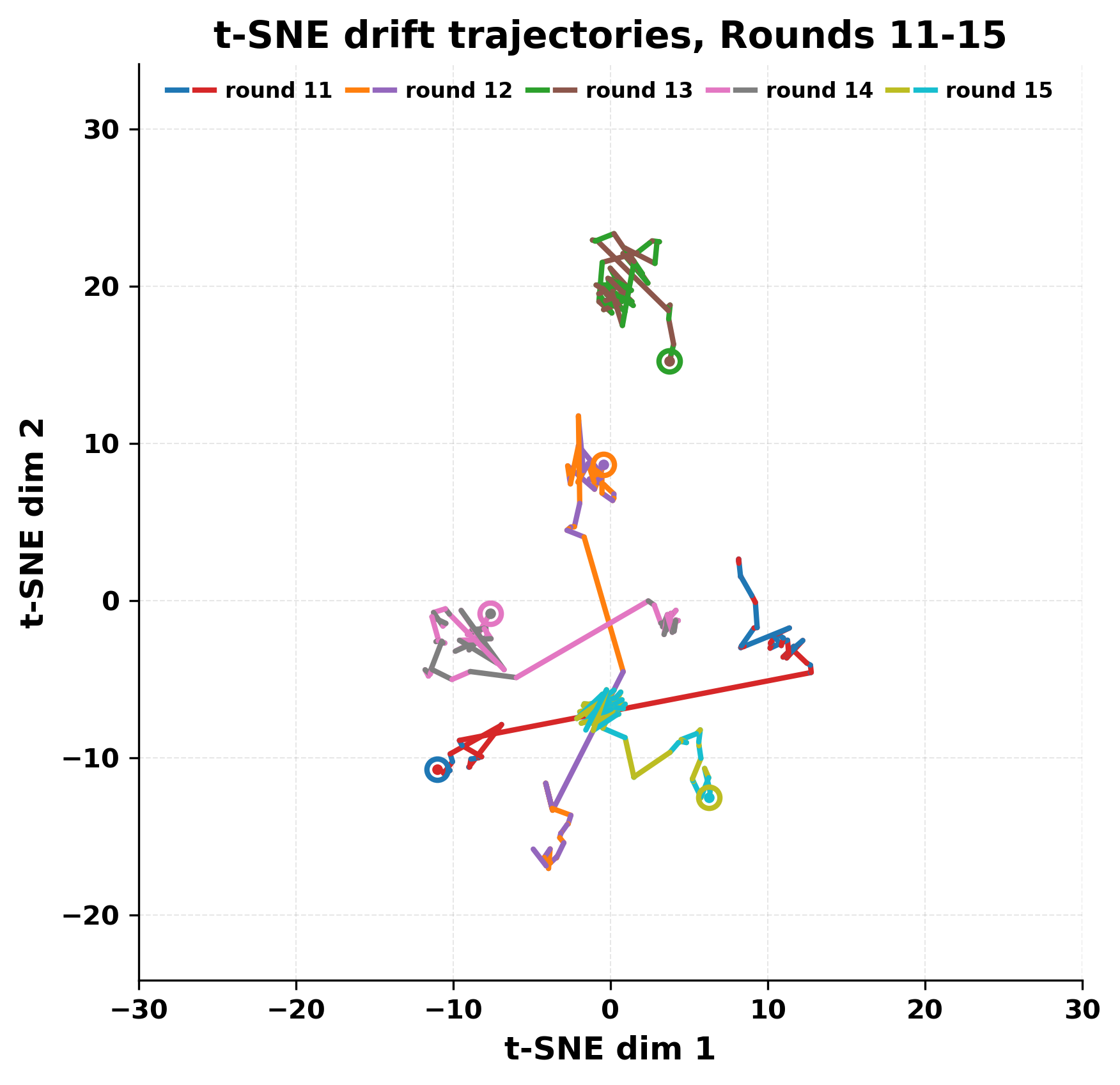
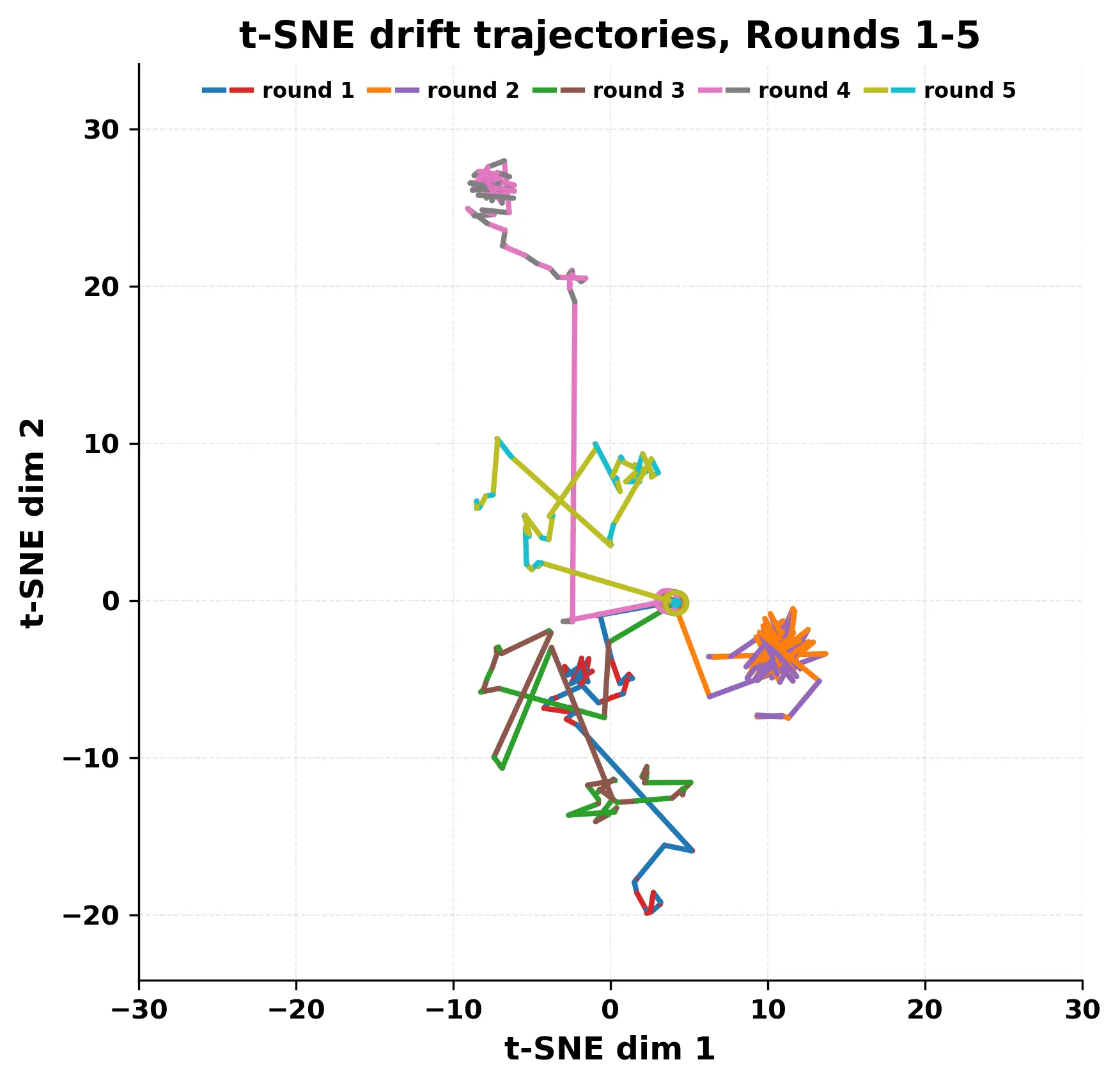
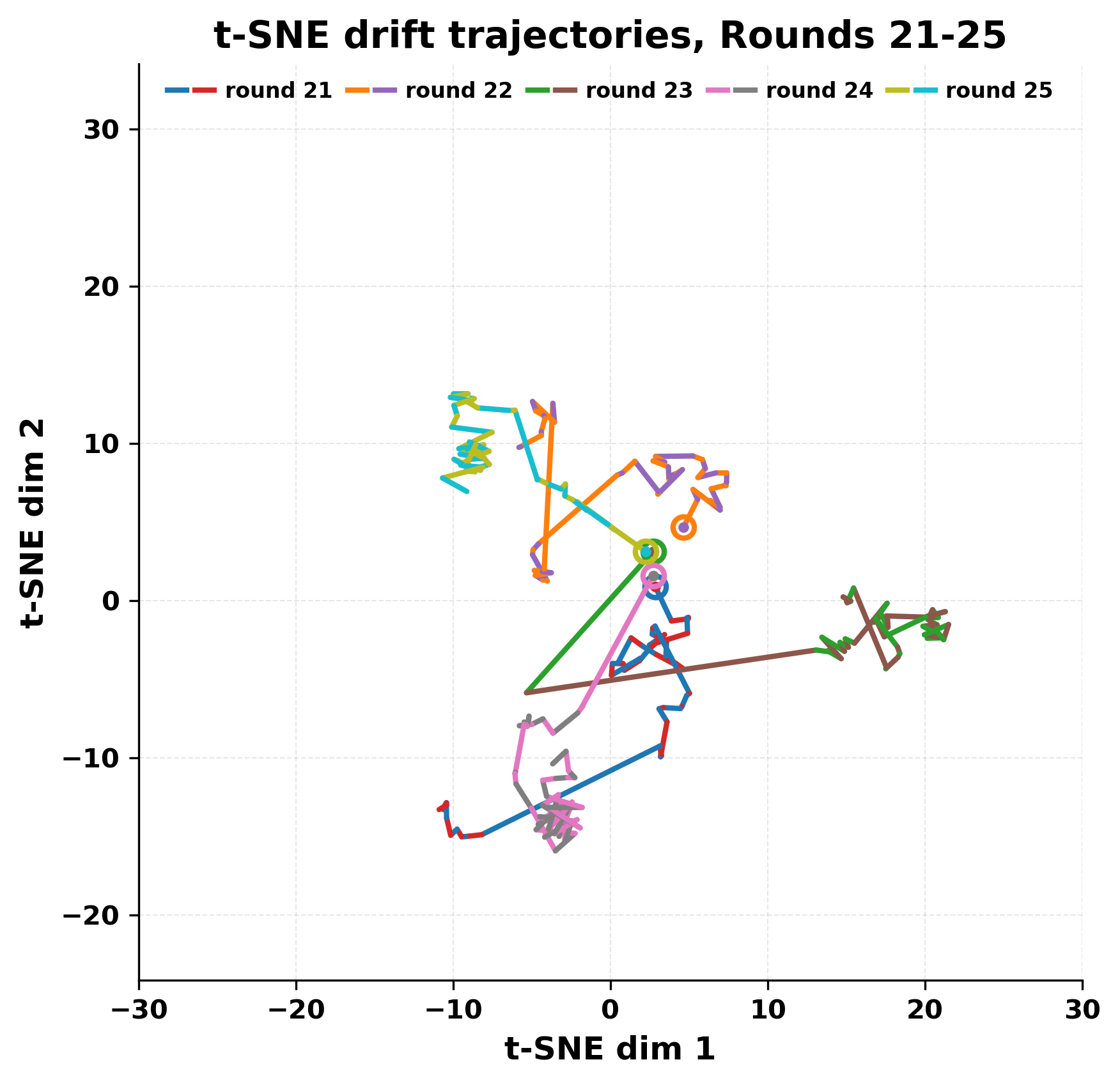
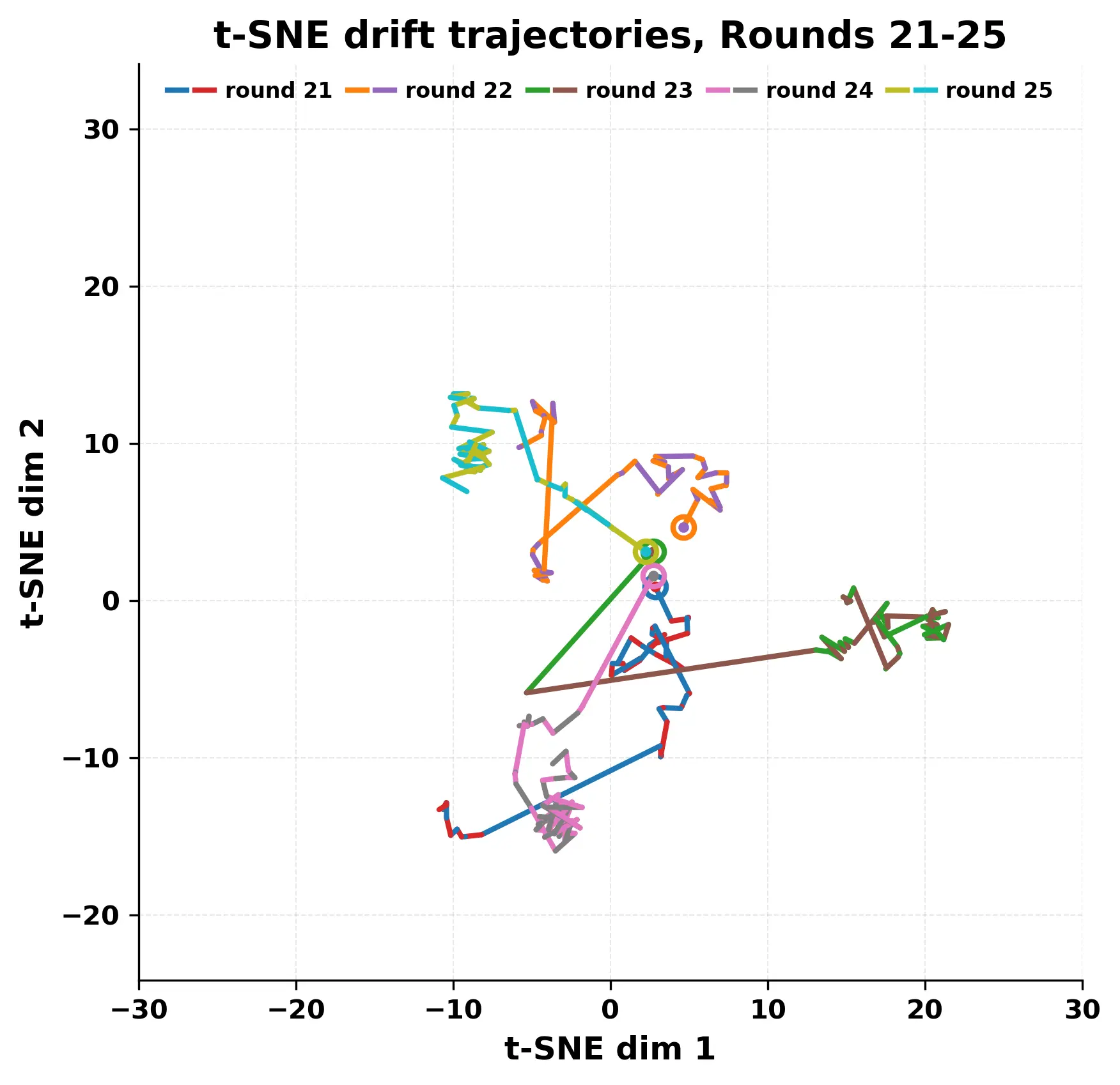
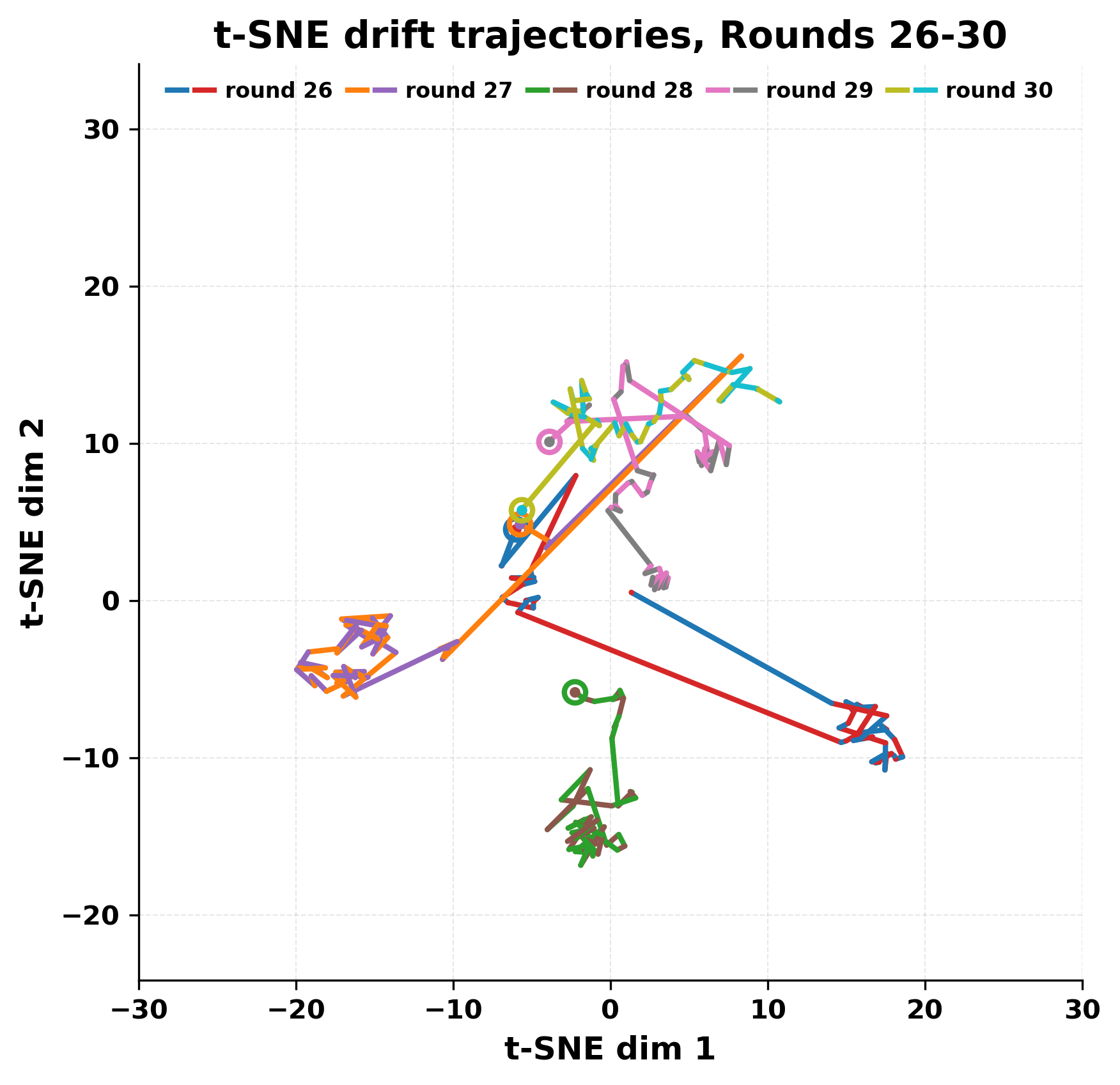
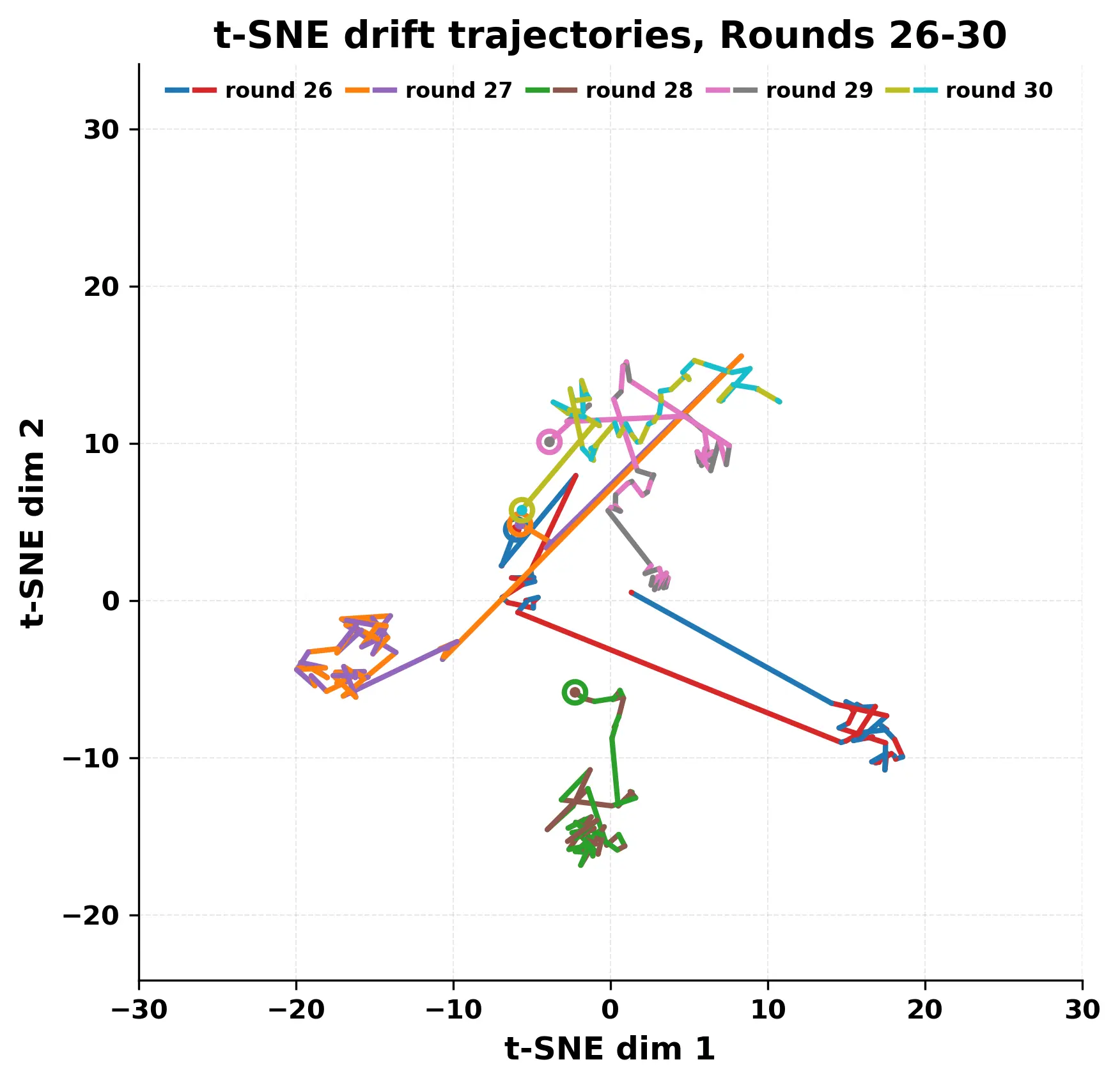
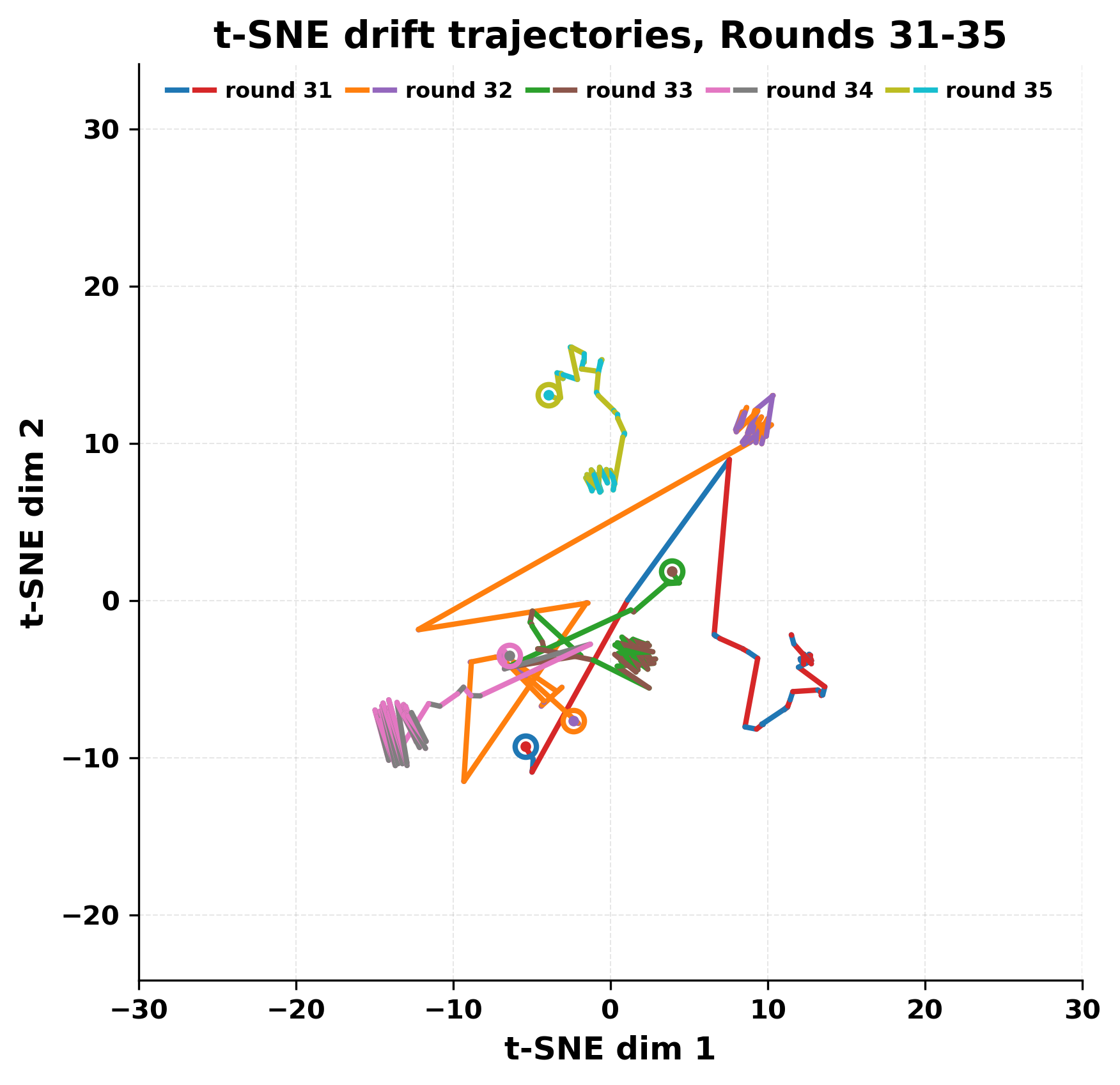
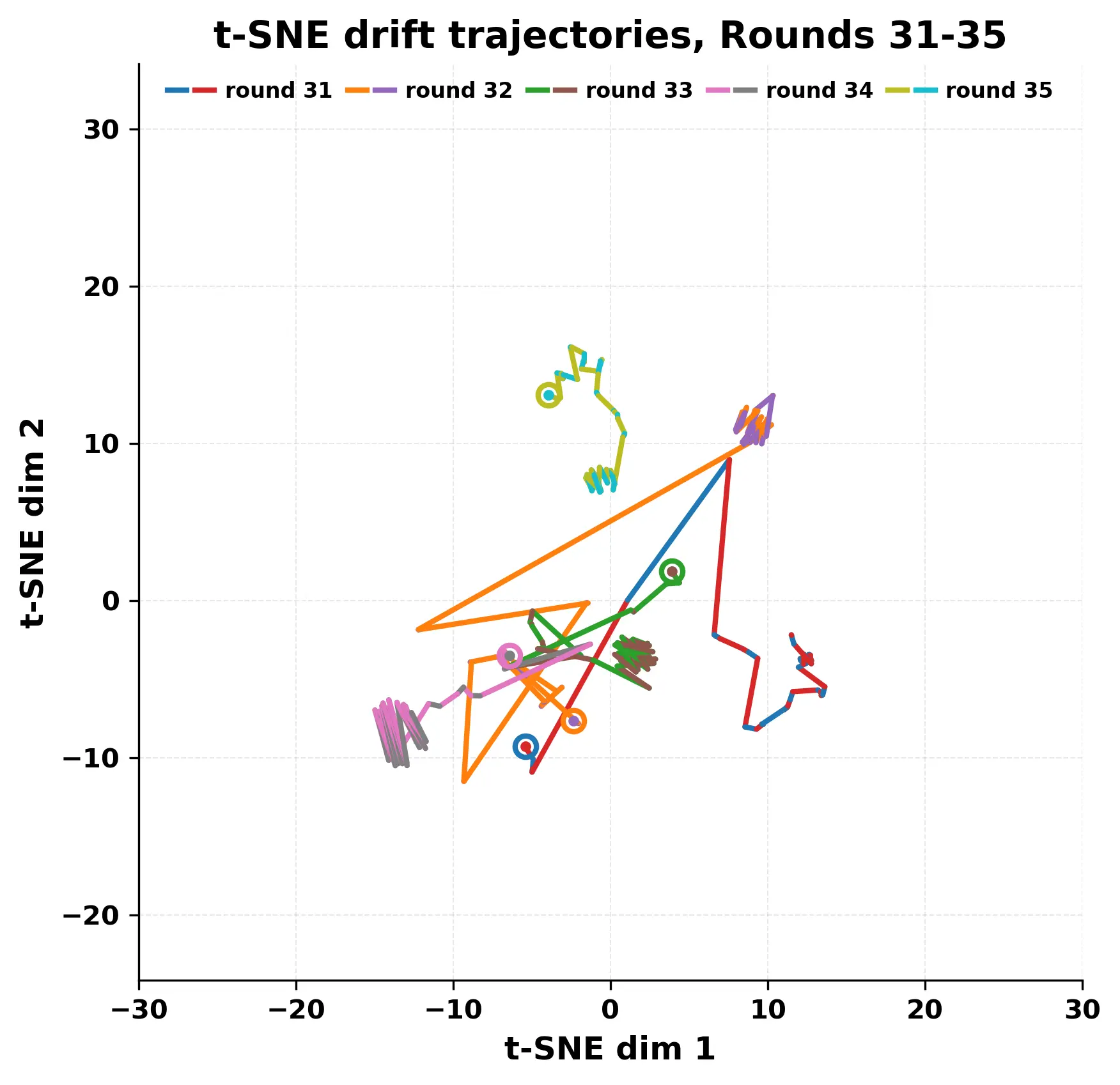
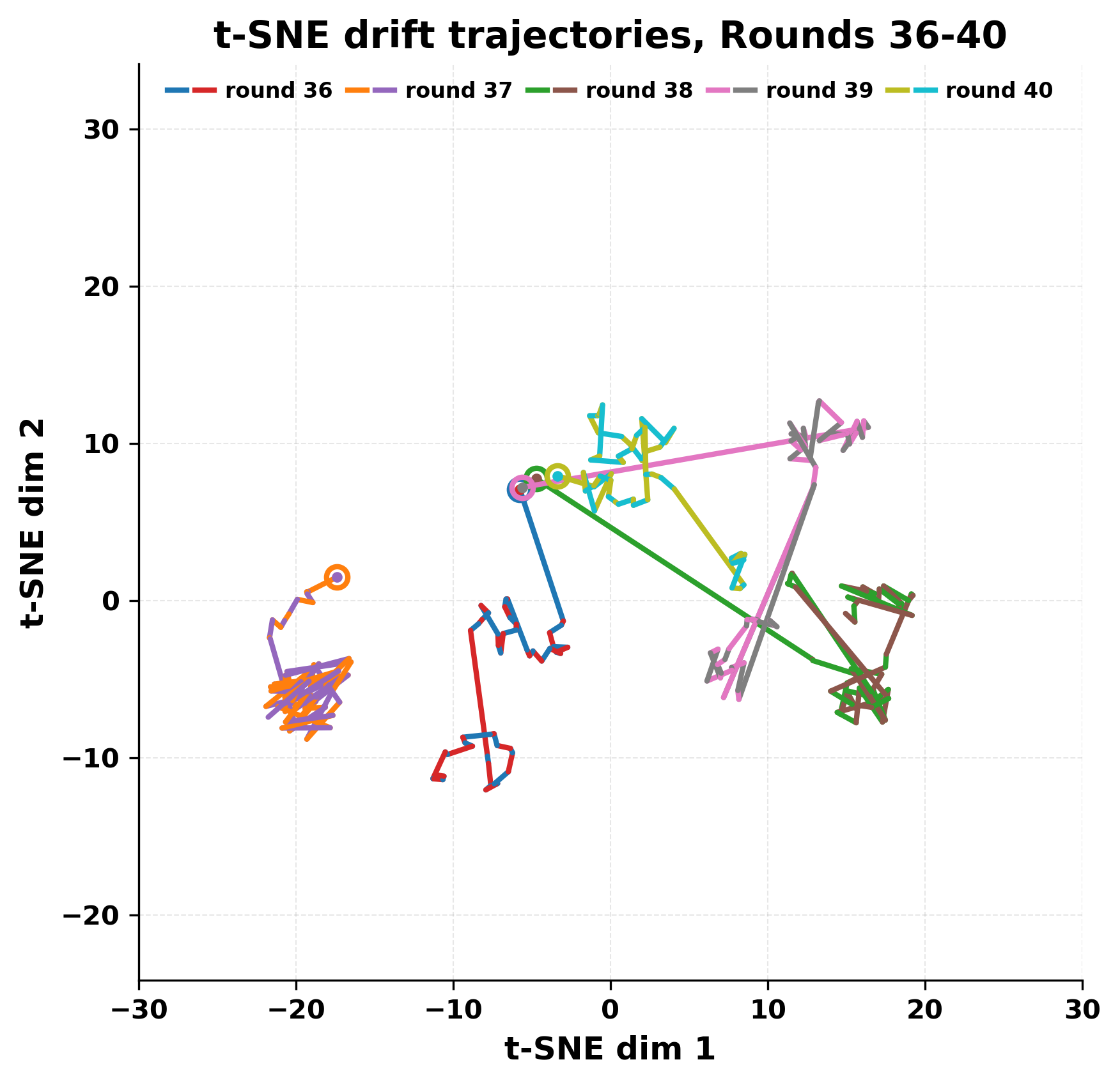
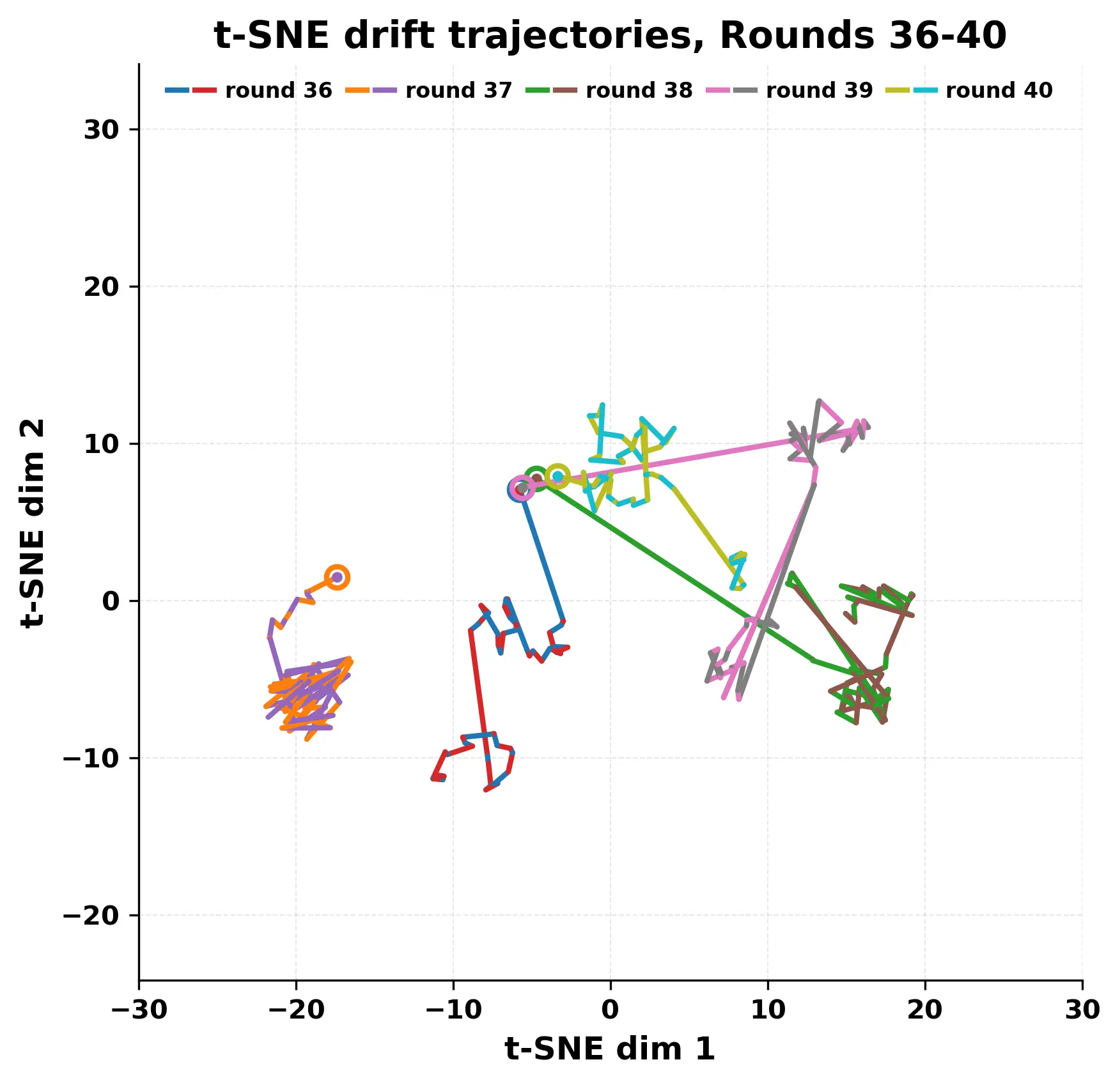
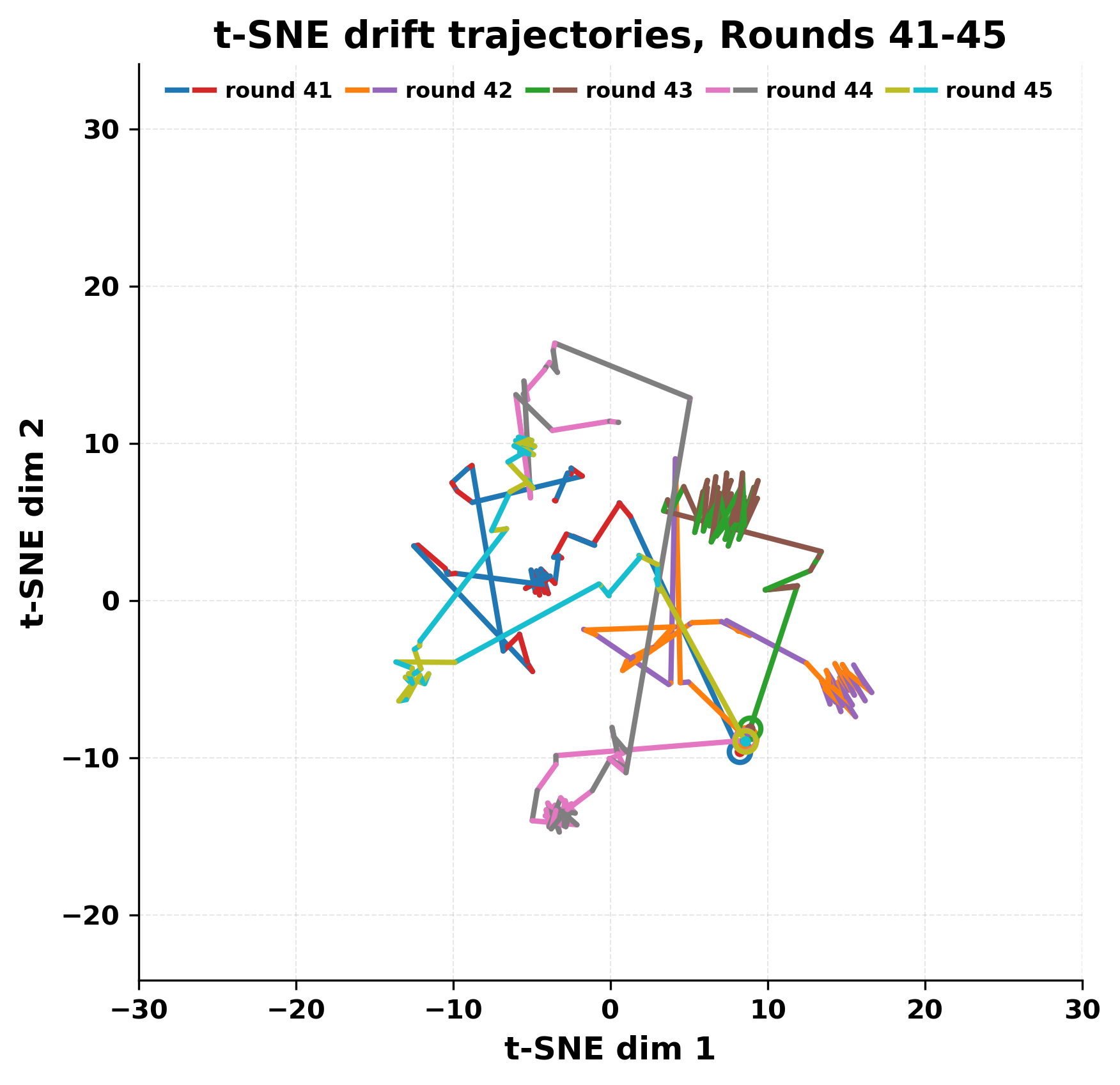
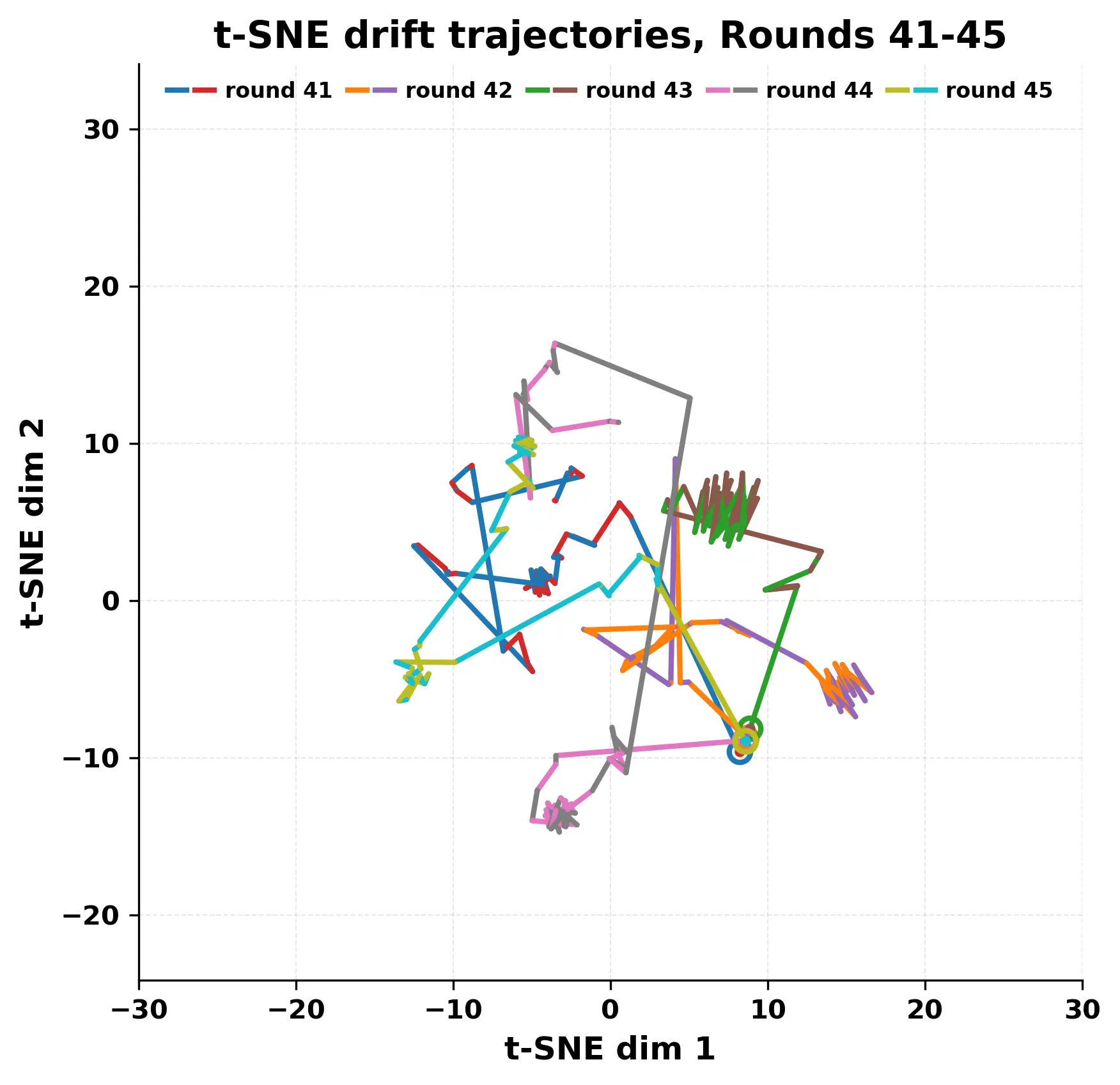
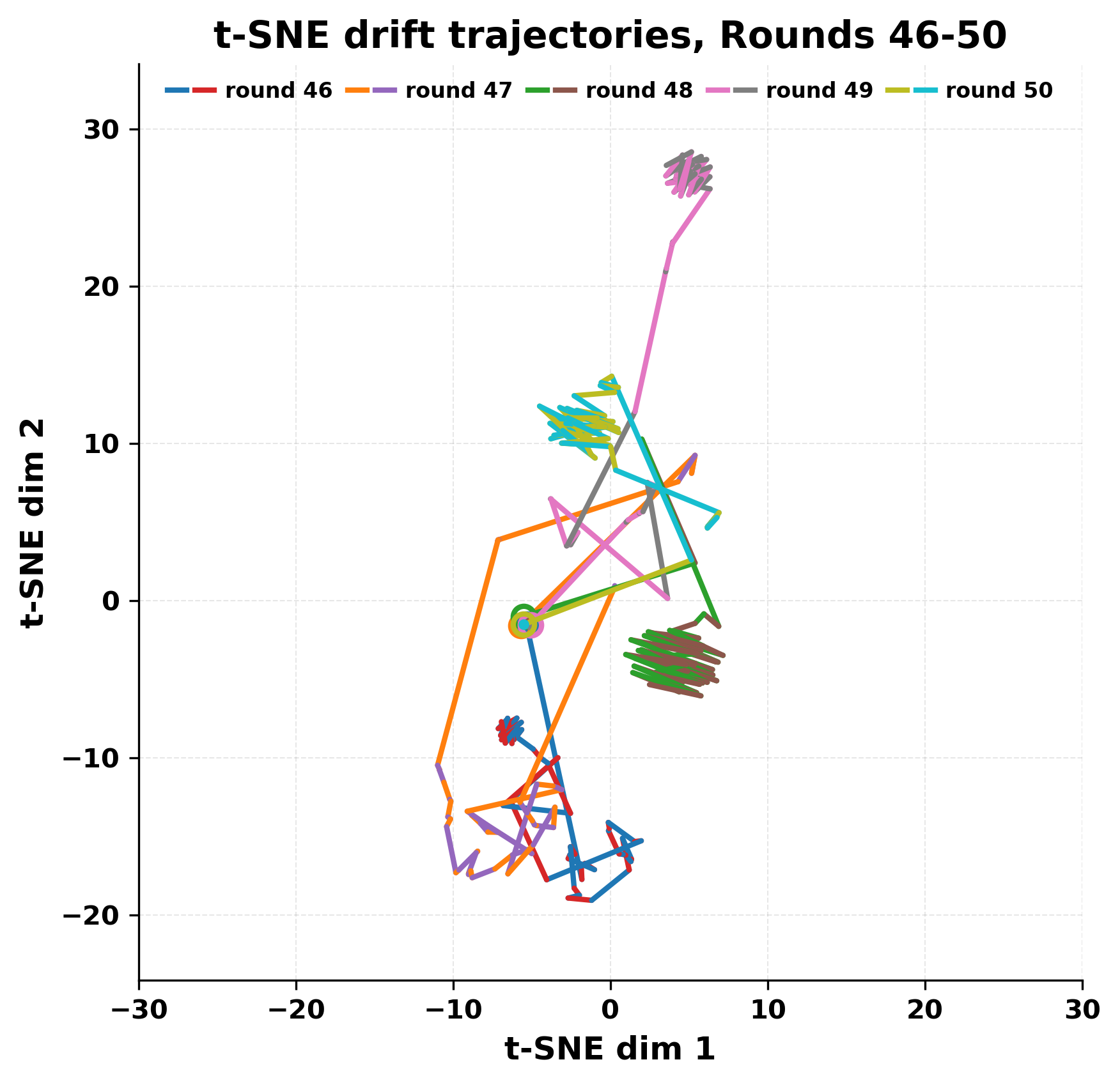
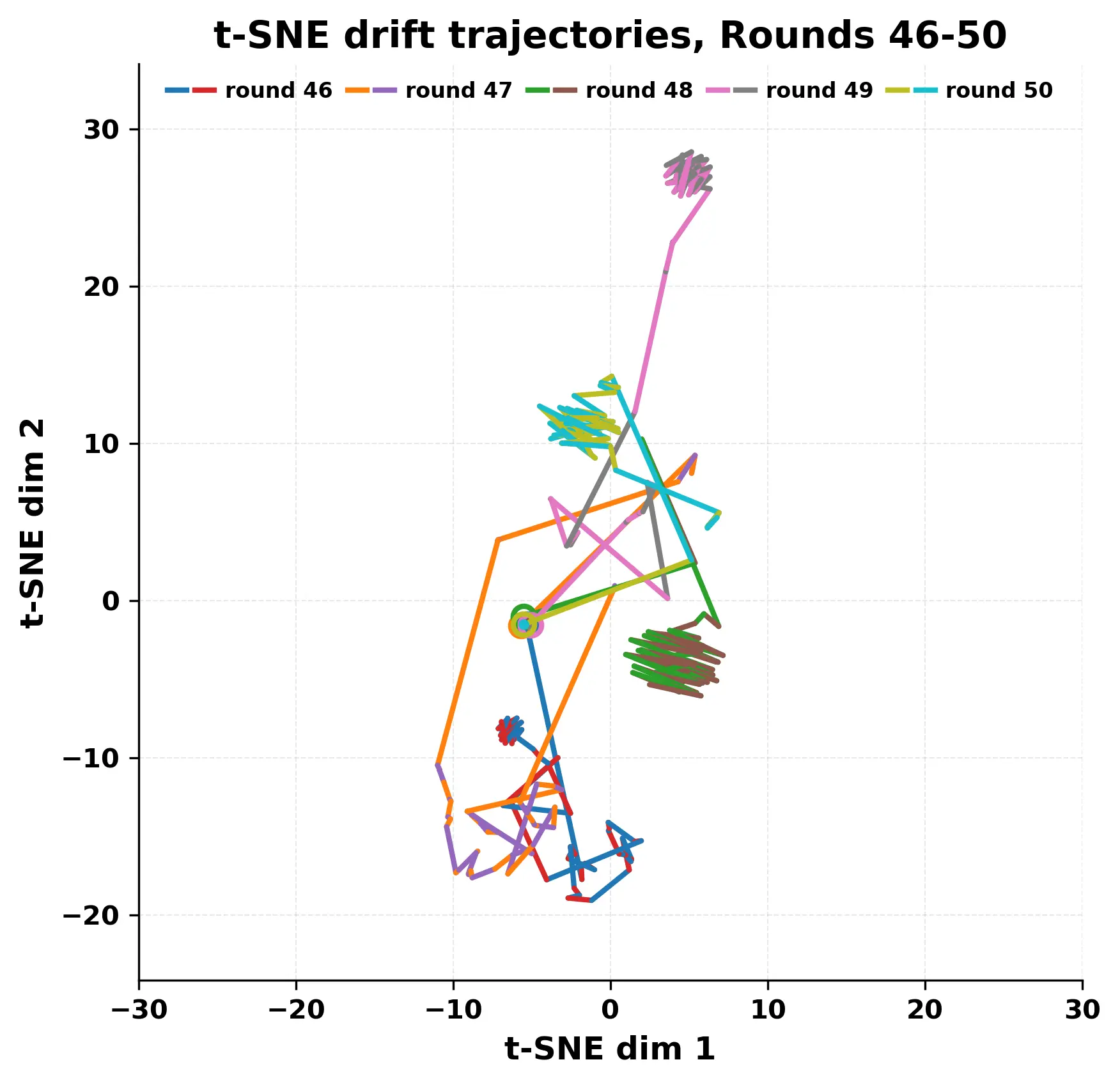
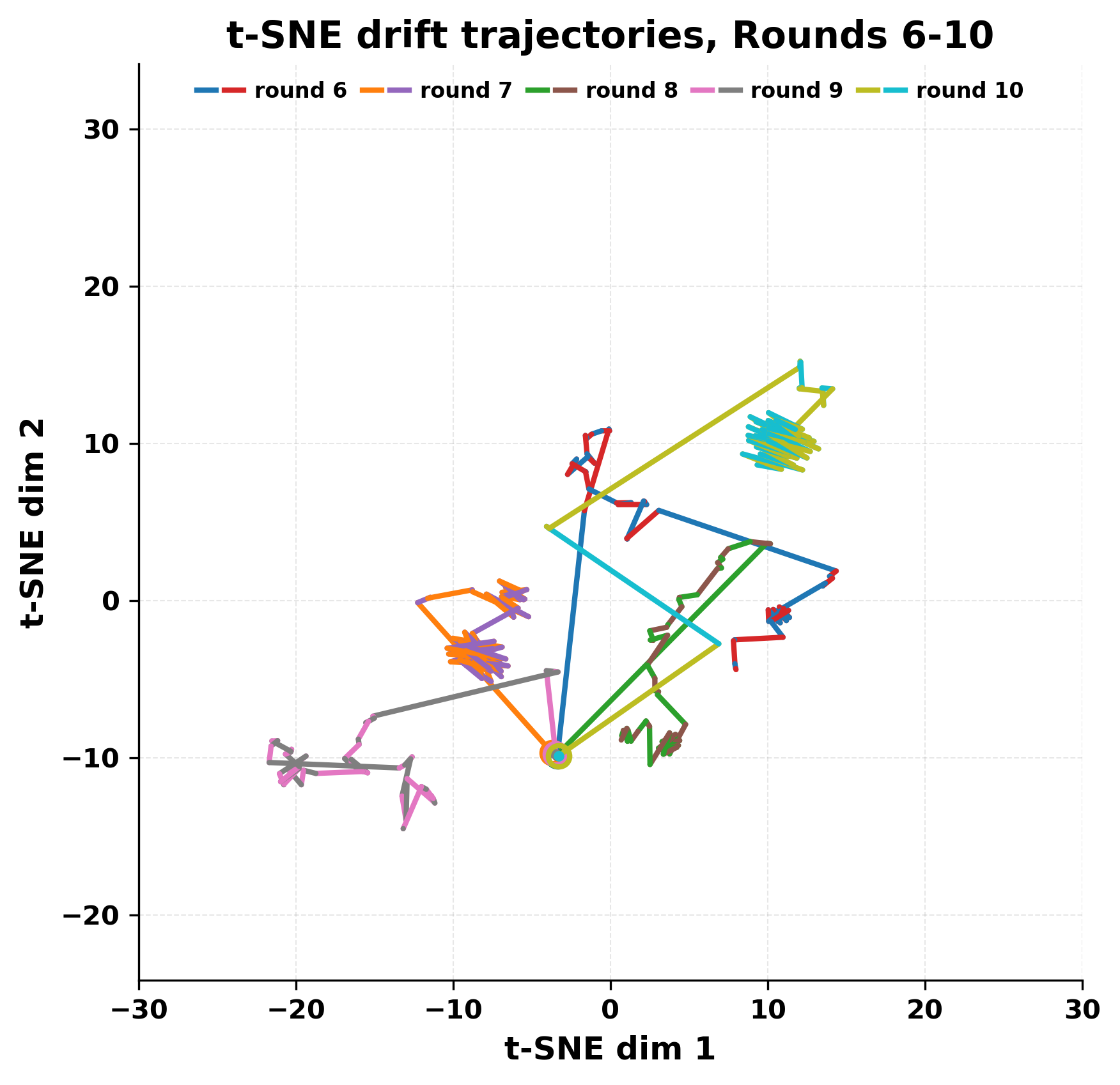
In this work, we report what happens when two large language models respond to each other for many turns without any outside input in a multi-agent setup. The setup begins with a short seed sentence. After that, each model reads the other's output and generates a response. This continues for a fixed number of steps. We used Mistral Nemo Base 2407 and Llama 2 13B hf. We observed that most conversations start coherently but later fall into repetition. In many runs, a short phrase appears and repeats across turns. Once repetition begins, both models tend to produce similar output rather than introducing a new direction in the conversation. This leads to a loop where the same or similar text is produced repeatedly. We describe this behavior as a form of convergence. It occurs even though the models are large, trained separately, and not given any prompt instructions. To study this behavior, we apply lexical and embedding-based metrics to measure how far the conversation drifts from the initial seed and how similar the outputs of the two models becomes as the conversation progresses.
💡 Deep Analysis
Deep Dive into Convergence of Outputs When Two Large Language Models Interact in a Multi-Agentic Setup.
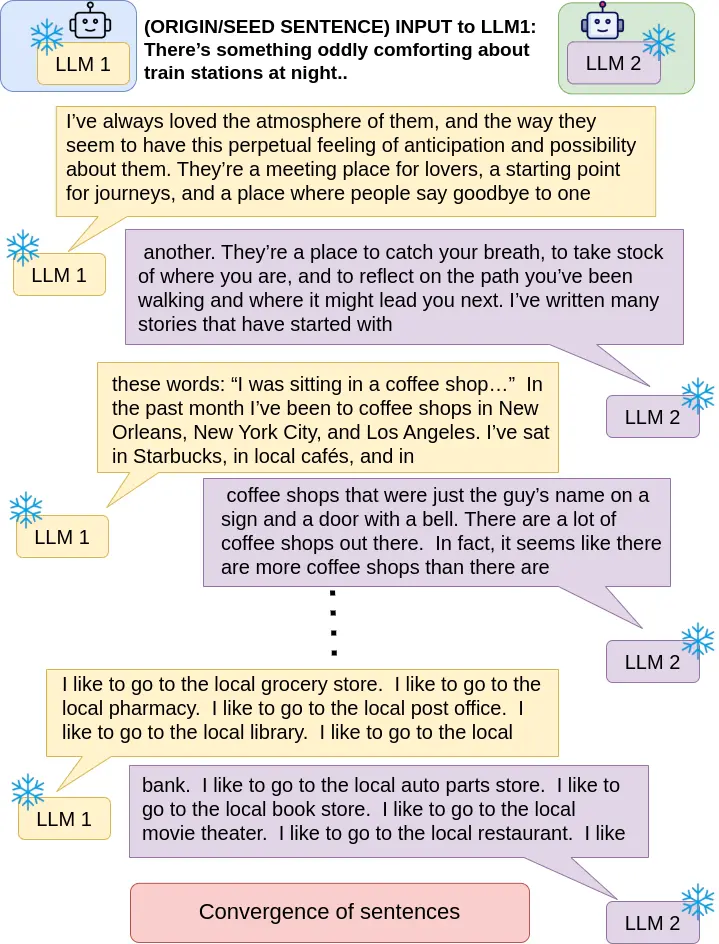
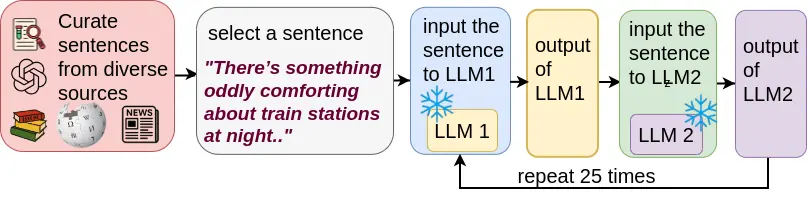
In this work, we report what happens when two large language models respond to each other for many turns without any outside input in a multi-agent setup. The setup begins with a short seed sentence. After that, each model reads the other’s output and generates a response. This continues for a fixed number of steps. We used Mistral Nemo Base 2407 and Llama 2 13B hf. We observed that most conversations start coherently but later fall into repetition. In many runs, a short phrase appears and repeats across turns. Once repetition begins, both models tend to produce similar output rather than introducing a new direction in the conversation. This leads to a loop where the same or similar text is produced repeatedly. We describe this behavior as a form of convergence. It occurs even though the models are large, trained separately, and not given any prompt instructions. To study this behavior, we apply lexical and embedding-based metrics to measure how far the conversation drifts from the ini
📄 Full Content
Convergence of Outputs When Two Large
Language Models Interact in a Multi-Agentic
Setup
Aniruddha Maiti1[0000−0002−1142−6344], Satya Nimmagadda2, Kartha Veerya
Jammuladinne1, Niladri Sengupta3, and Ananya Jana2
1 West Virginia State University, Institute, WV 25112
{aniruddha.maiti, kjammuladinne}@wvstateu.edu
2 Marshall University, Huntington, WV
{jana, nimmagadda2}@marshall.edu
3 Fractal Analytics Inc., USA
dinophysicsiitb@gmail.com
Abstract. In this work, we report what happens when two large lan-
guage models respond to each other for many turns without any outside
input in a multi-agent setup. The setup begins with a short seed sen-
tence. After that, each model reads the other’s output and generates a
response. This continues for a fixed number of steps. We used Mistral
Nemo Base 2407 and Llama 2 13B hf. We observed that most con-
versations start coherently but later fall into repetition. In many runs, a
short phrase appears and repeats across turns. Once repetition begins,
both models tend to produce similar output rather than introducing a
new direction in the conversation. This leads to a loop where the same
or similar text is produced repeatedly. We describe this behavior as a
form of convergence. It occurs even though the models are large, trained
separately, and not given any prompt instructions. To study this behav-
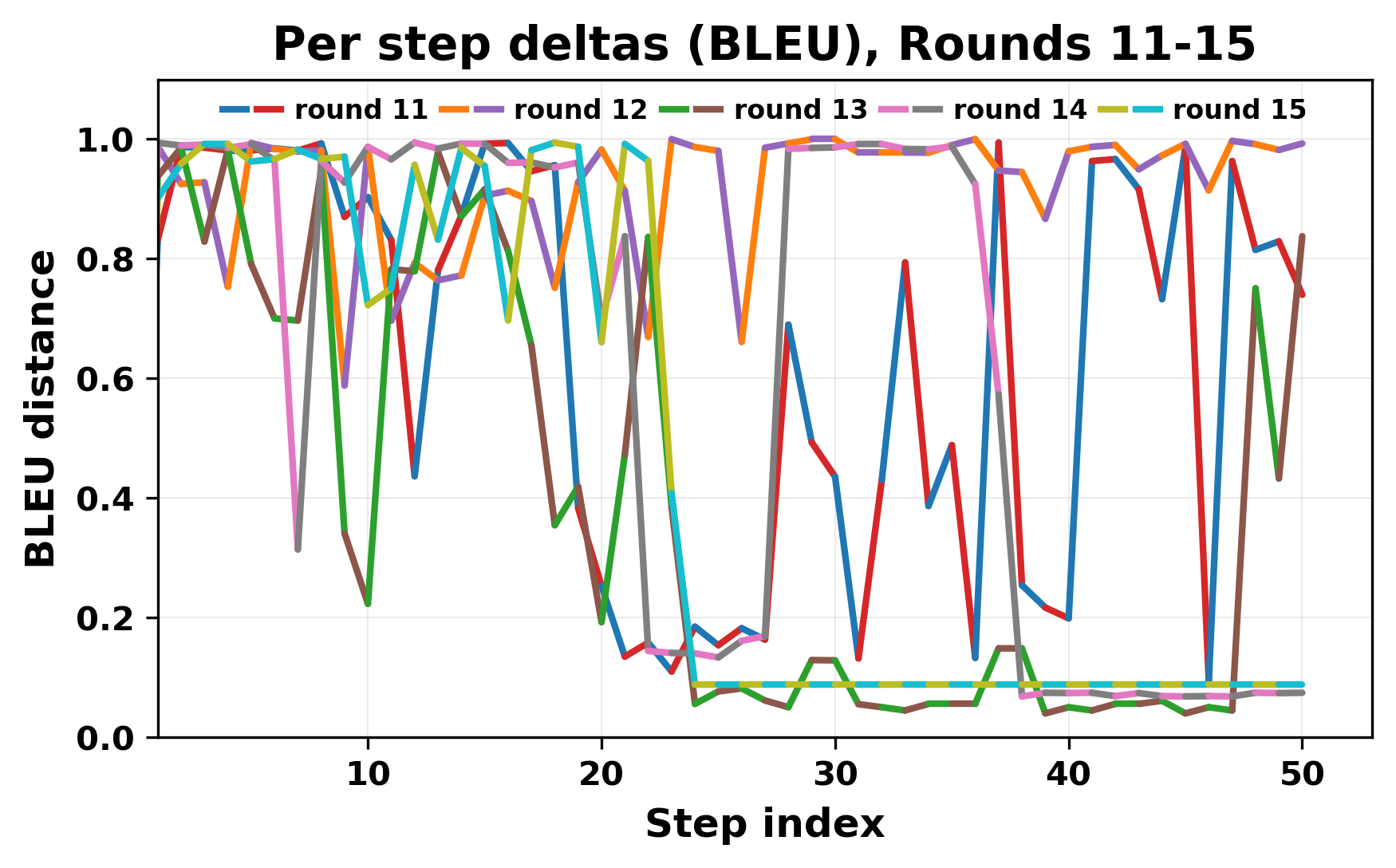
ior, we apply lexical and embedding-based metrics to measure how far
the conversation drifts from the initial seed and how similar the outputs
of the two models becomes as the conversation progresses.
Keywords: Convergence in Multi-Agent, Agentic Conversation, Multi-
Agent, Multi-LLM Interaction.
1
Introduction
Most evaluations of large language models rely on short prompts or single-turn
completions. These tests measure the correctness, fluency, or instruction follow-
ing capability in isolation. They do not reveal what happens when a model must
respond to its own output or engage in a long exchange with other models. Prior
works indicate that dialogue diversity tends to degrade over long-term simu-
lations [6]. This suggests that the behavior of language models over time may
expose failure modes that are not visible in one-step settings.
This work extends that idea to a two-model setup. Instead of using a single
model recursively, we allow two different models to take turns responding to each
arXiv:2512.06256v1 [cs.CL] 6 Dec 2025
2
Maiti et al.
other. Each model runs in its own process, with separate weights and tokenizers,
and reads only the plain-text output of the other. There is no shared memory, no
prompts, and no injected system instructions. The setup is minimal: the models
are connected only through raw text files.
The models used are Mistral Nemo Base 2407 and Llama 2 13B hf. The
original Mistral 12B parameter model is developed by Mistral AI and NVIDIA.
Different users have developed a variety of fine-tuned versions of this base model
for different use-cases since its publication. The original Llama-2 13 Billion Pa-
rameter model is released by Meta. Similar to Mistral, different users and de-
velopers have fine-tuned or adopted the original base model for a variety of
purposes. These two models are large autoregressive transformers with different
training sources and configurations. Their architectural similarity and difference
in training data during training make them a useful pair for studying how agent-
like conversation progresses when they respond alternately based on the other
model’s output.
This setting raises a natural question: when two models interact only through
language, how long can the conversation remain meaningful? Will they maintain
topic and coherence, or will they collapse into repetition? If so, when and how
does that collapse occur?
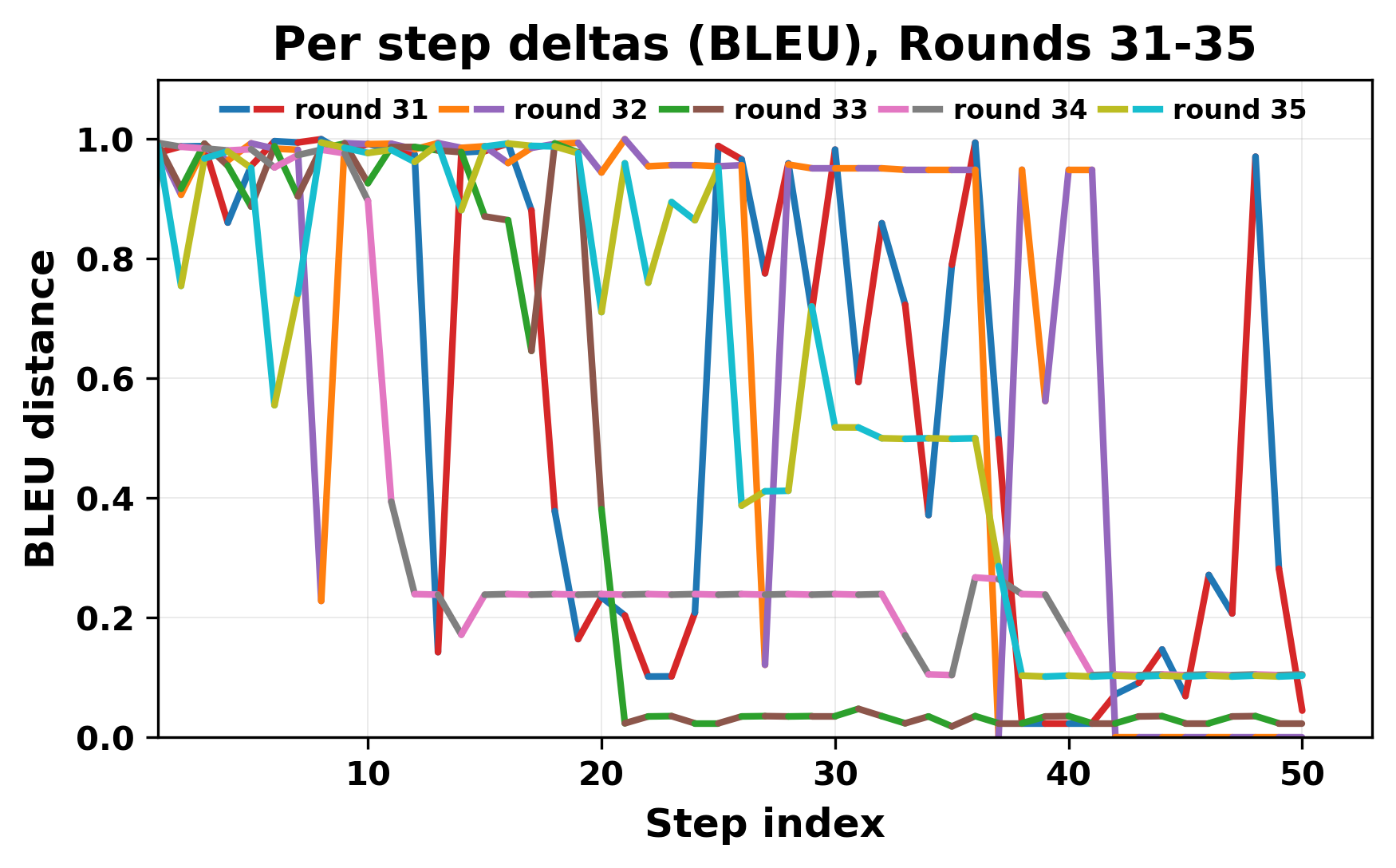
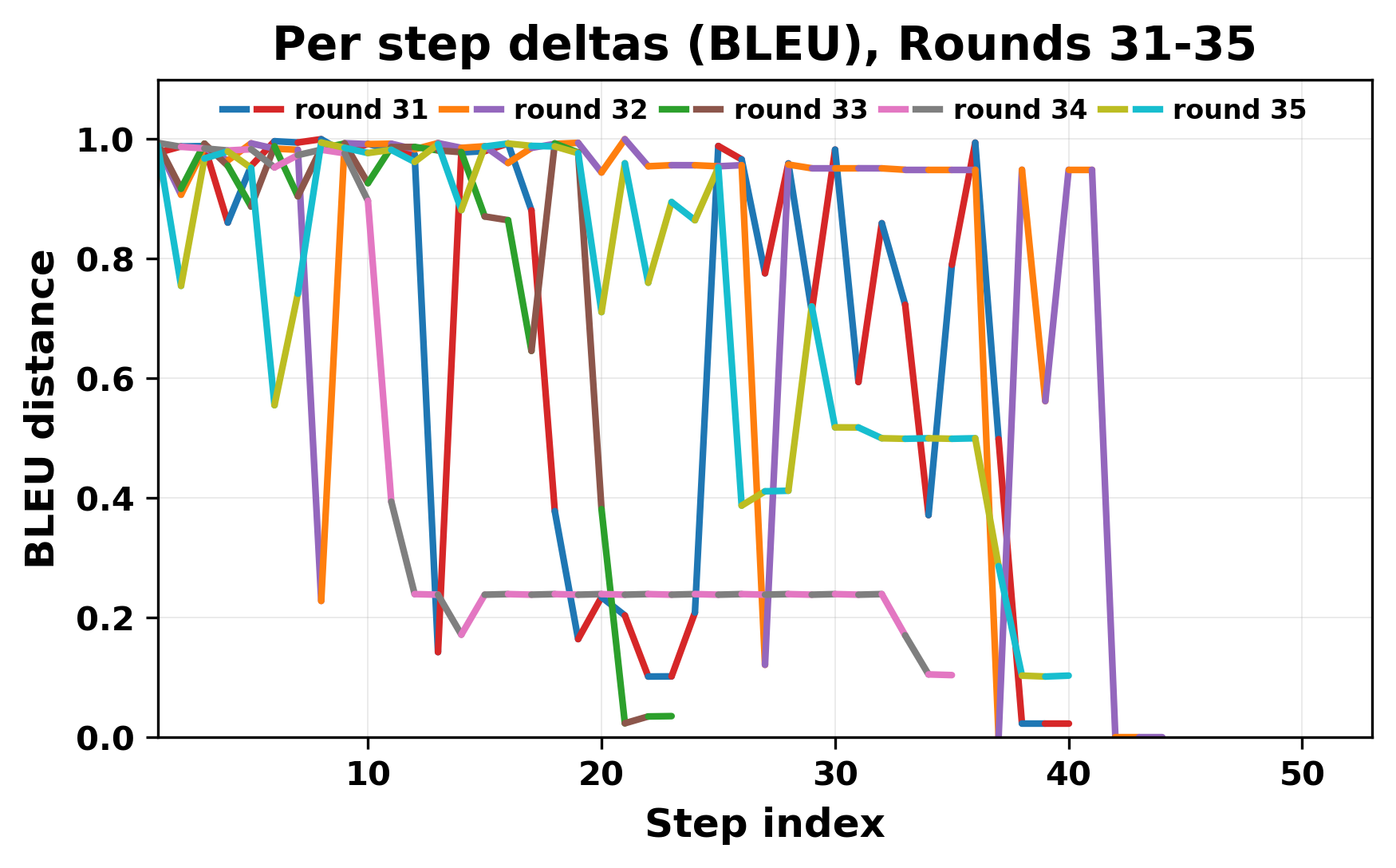
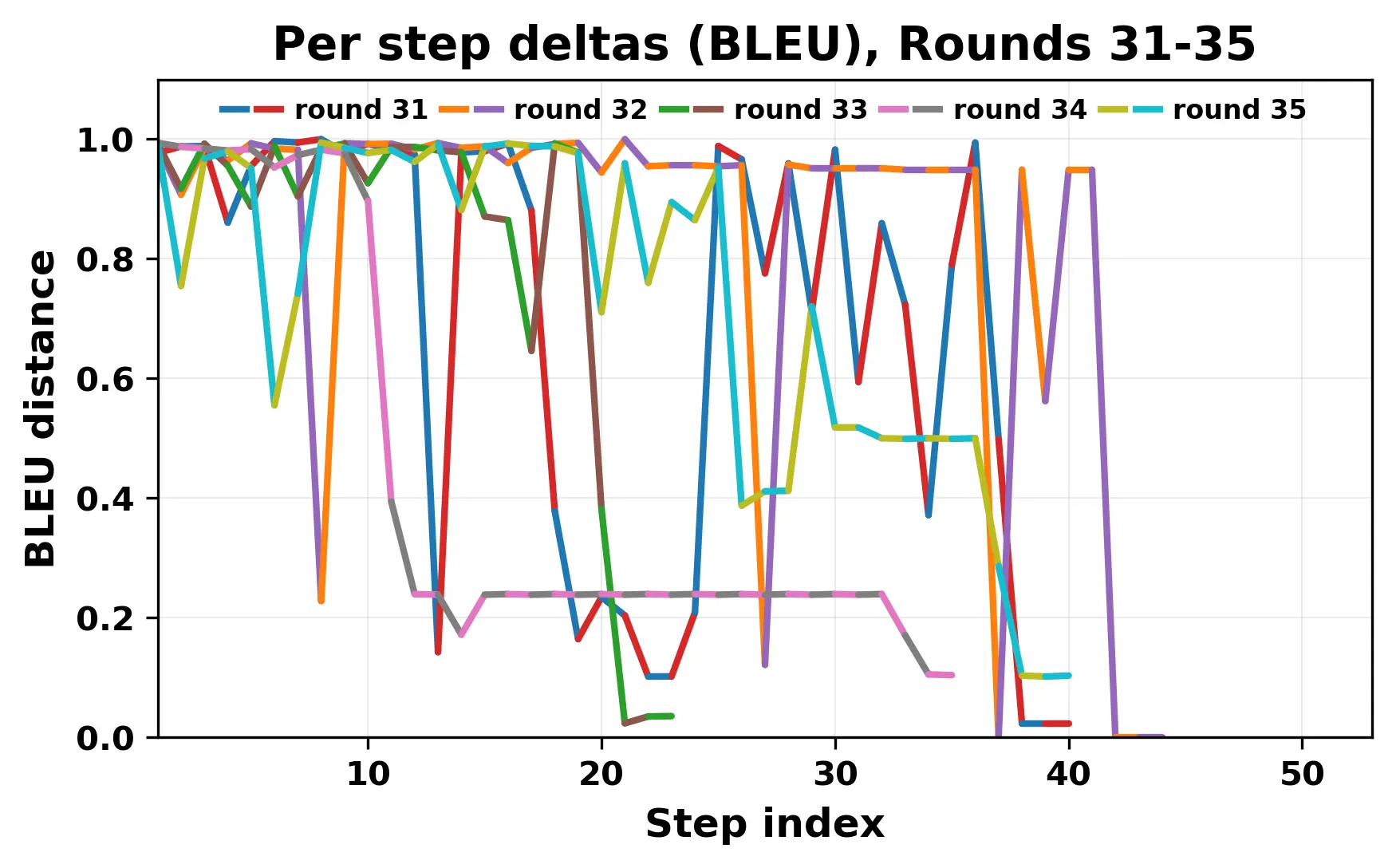
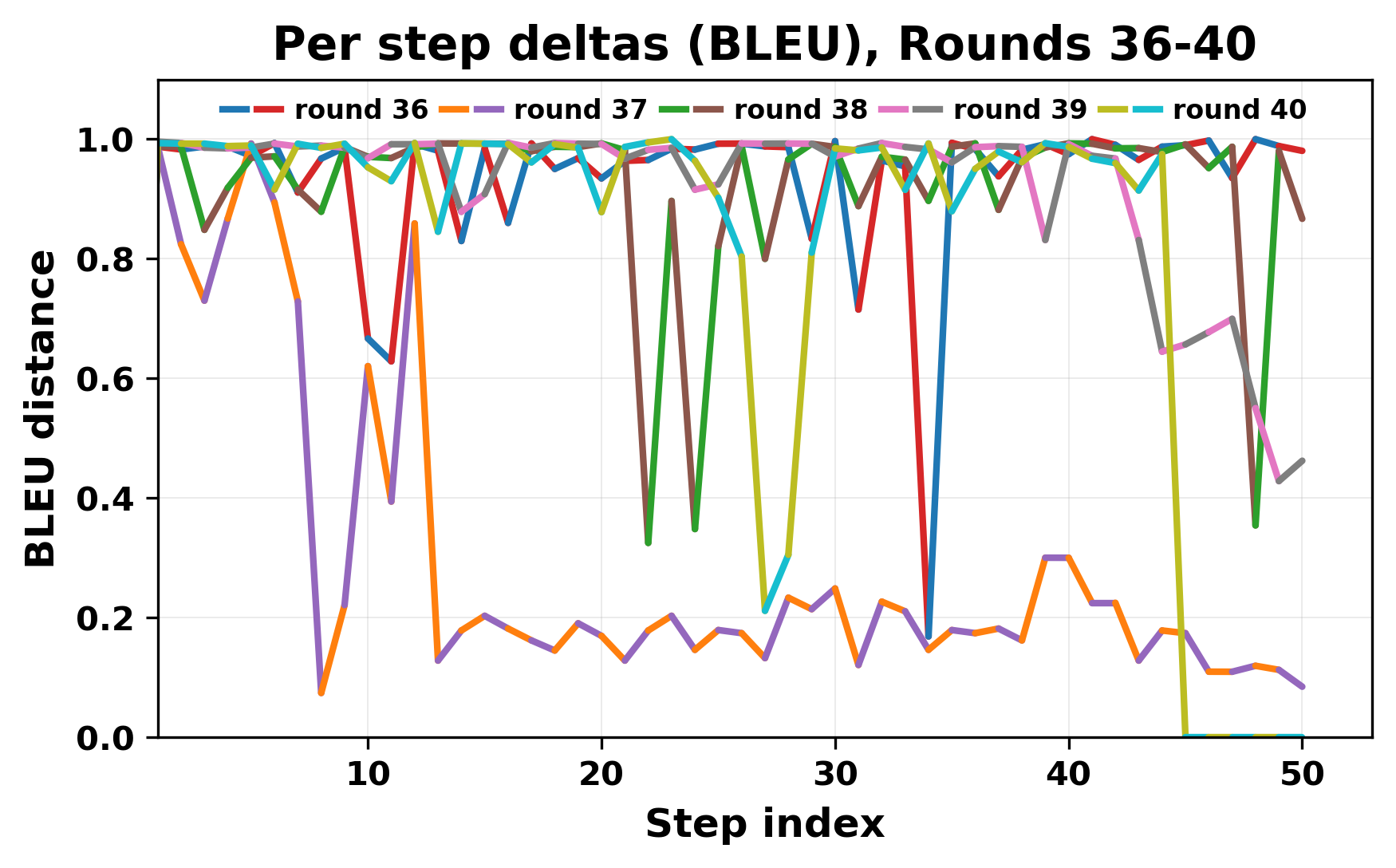
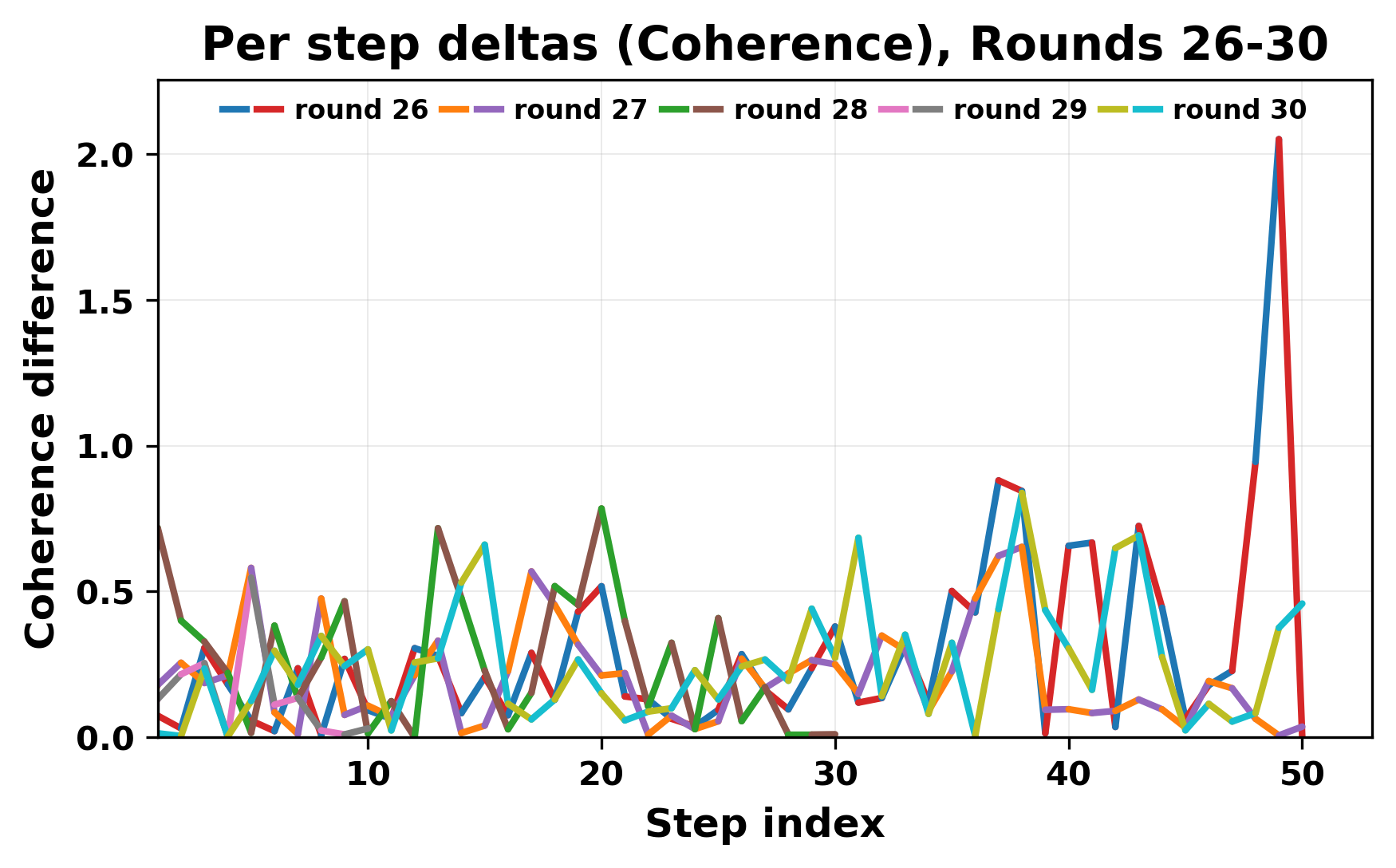
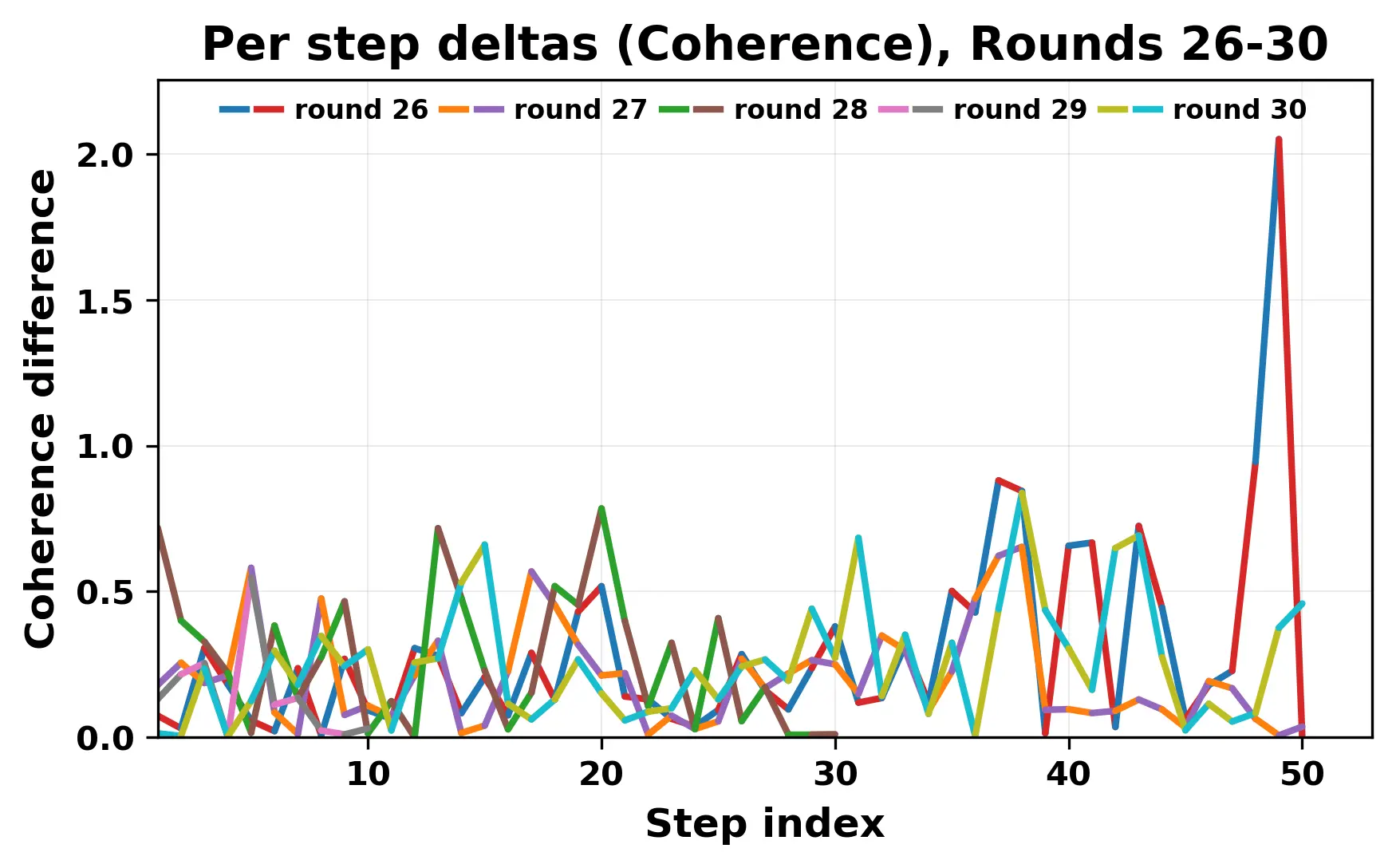
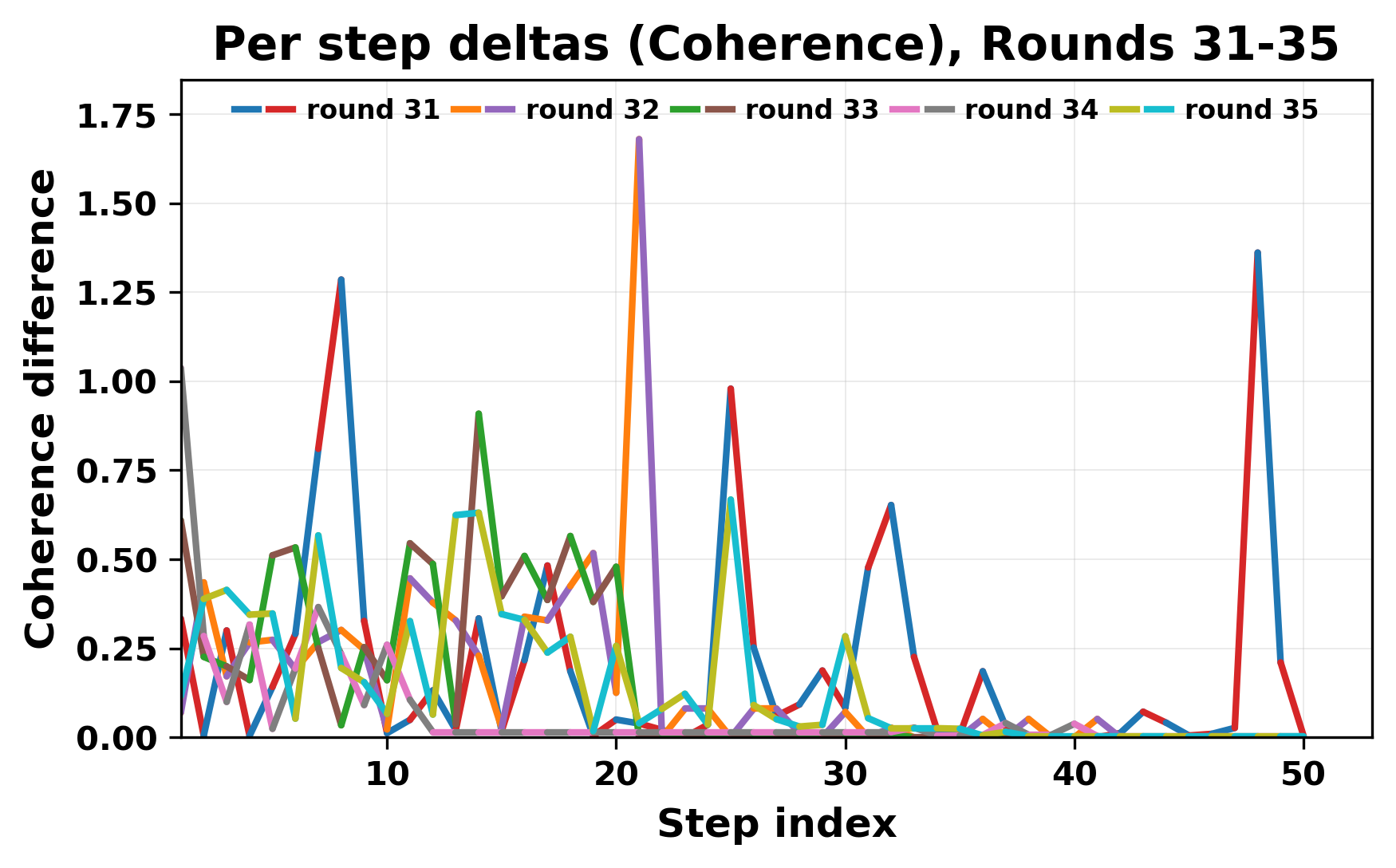
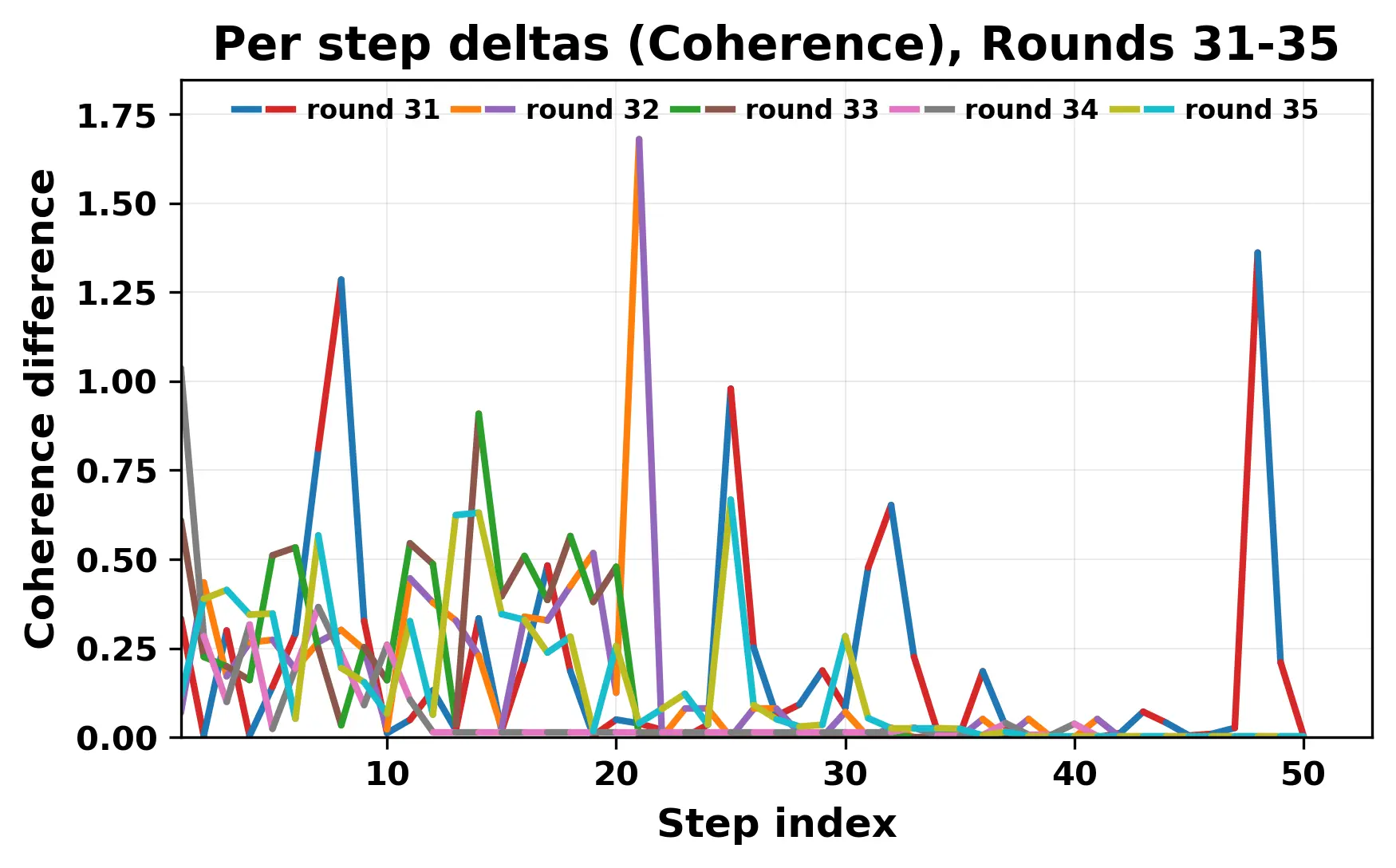
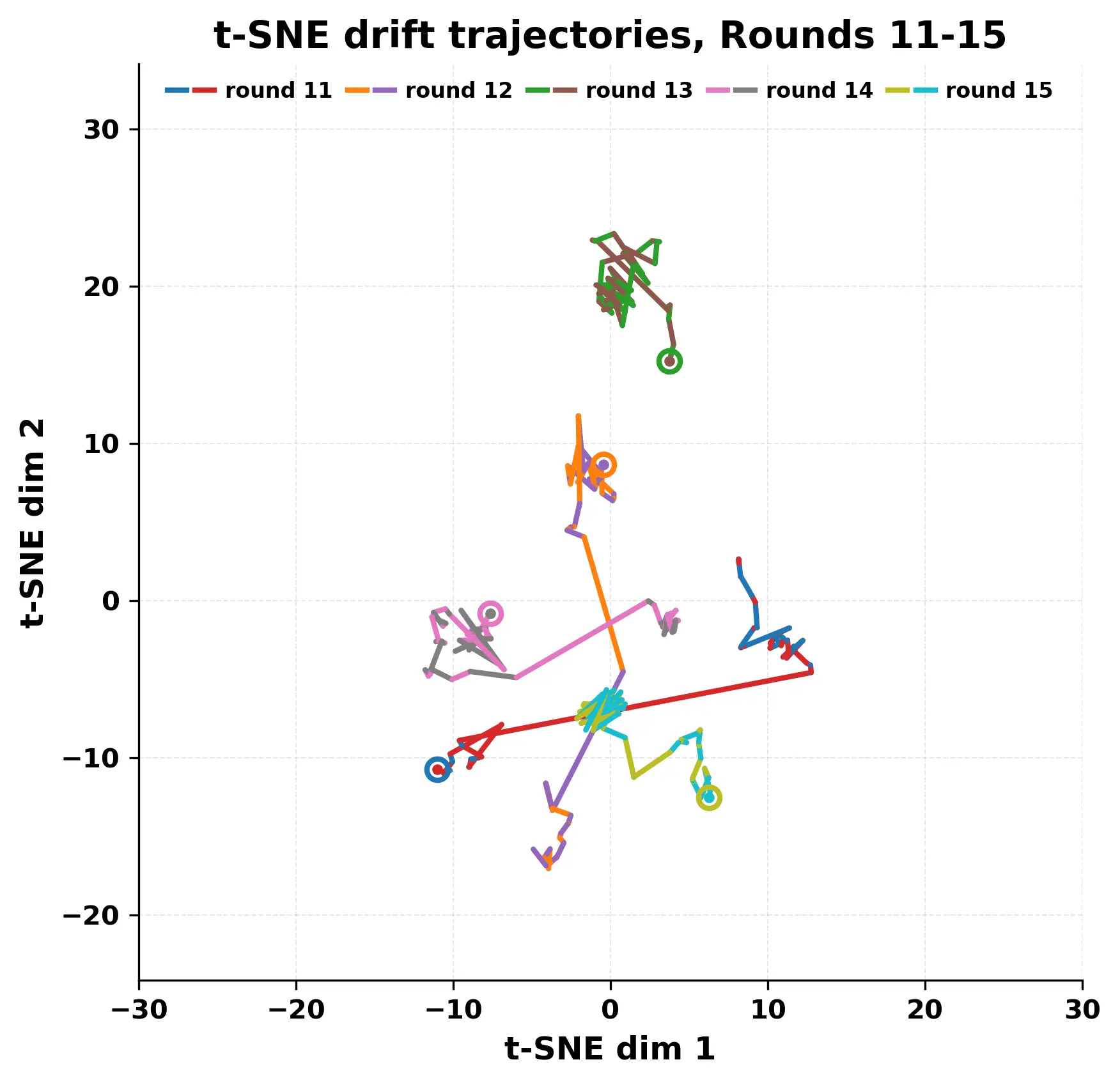
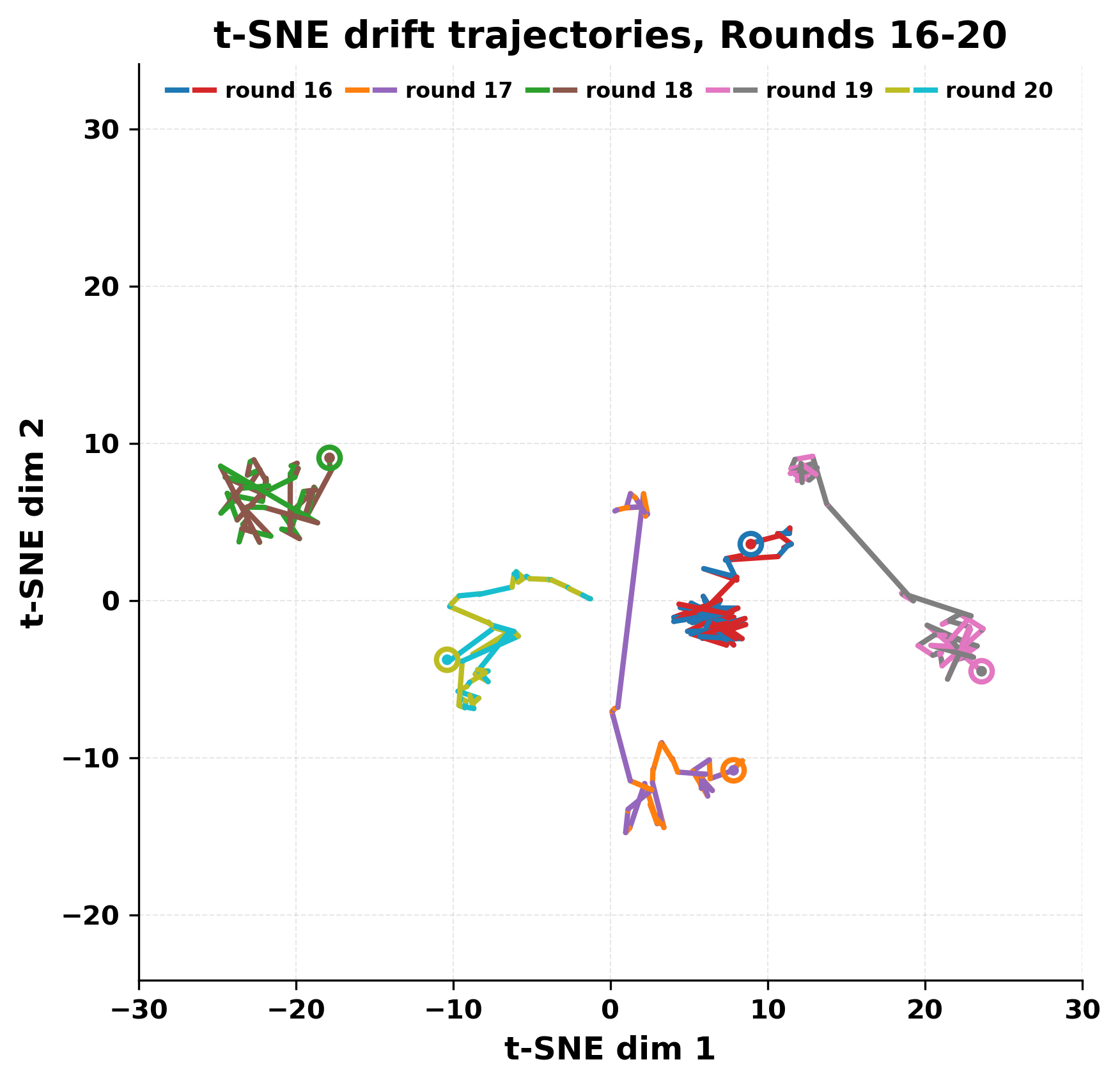
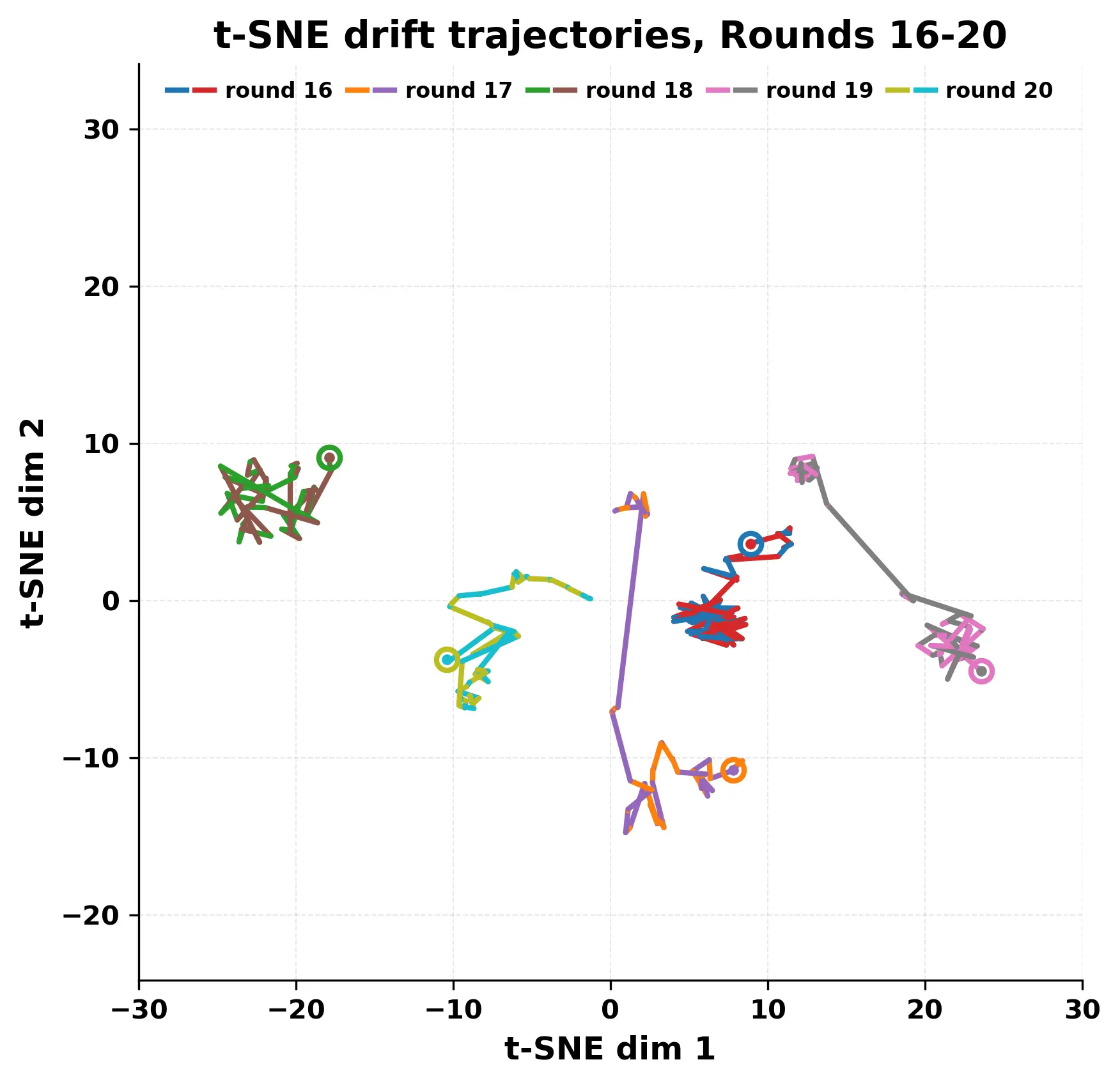
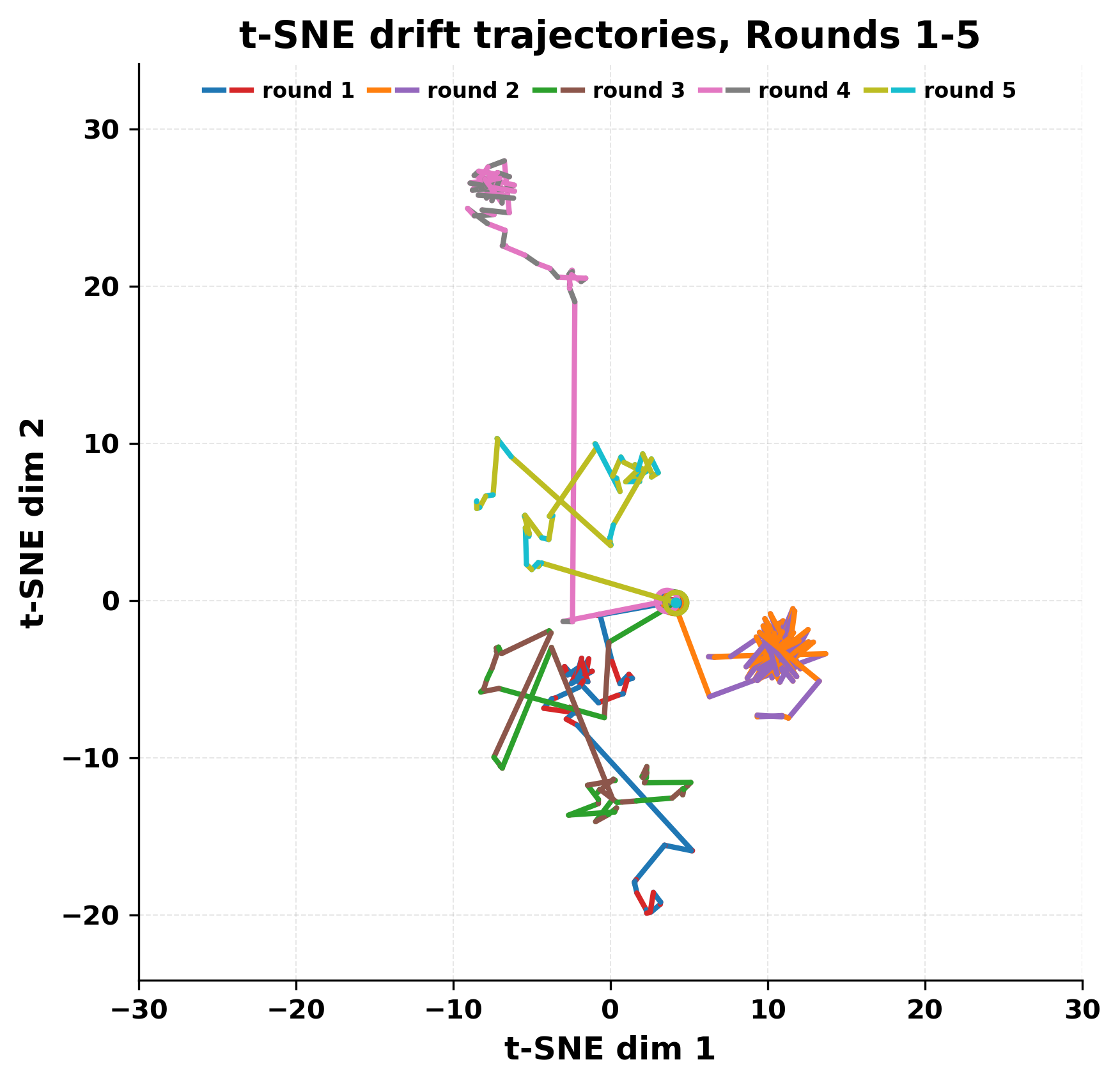
While exploring these questions, we found that model pairs begin with co-
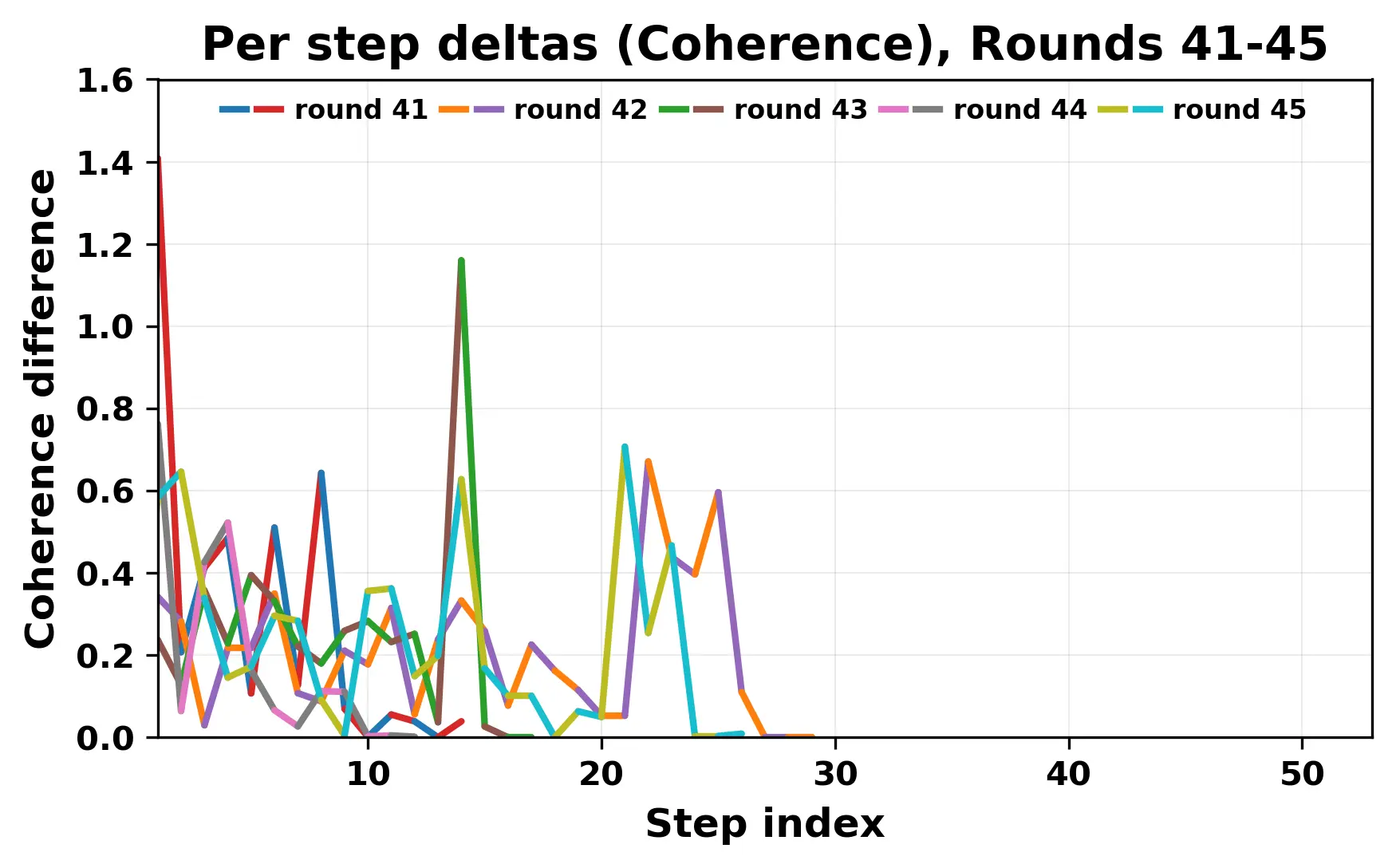
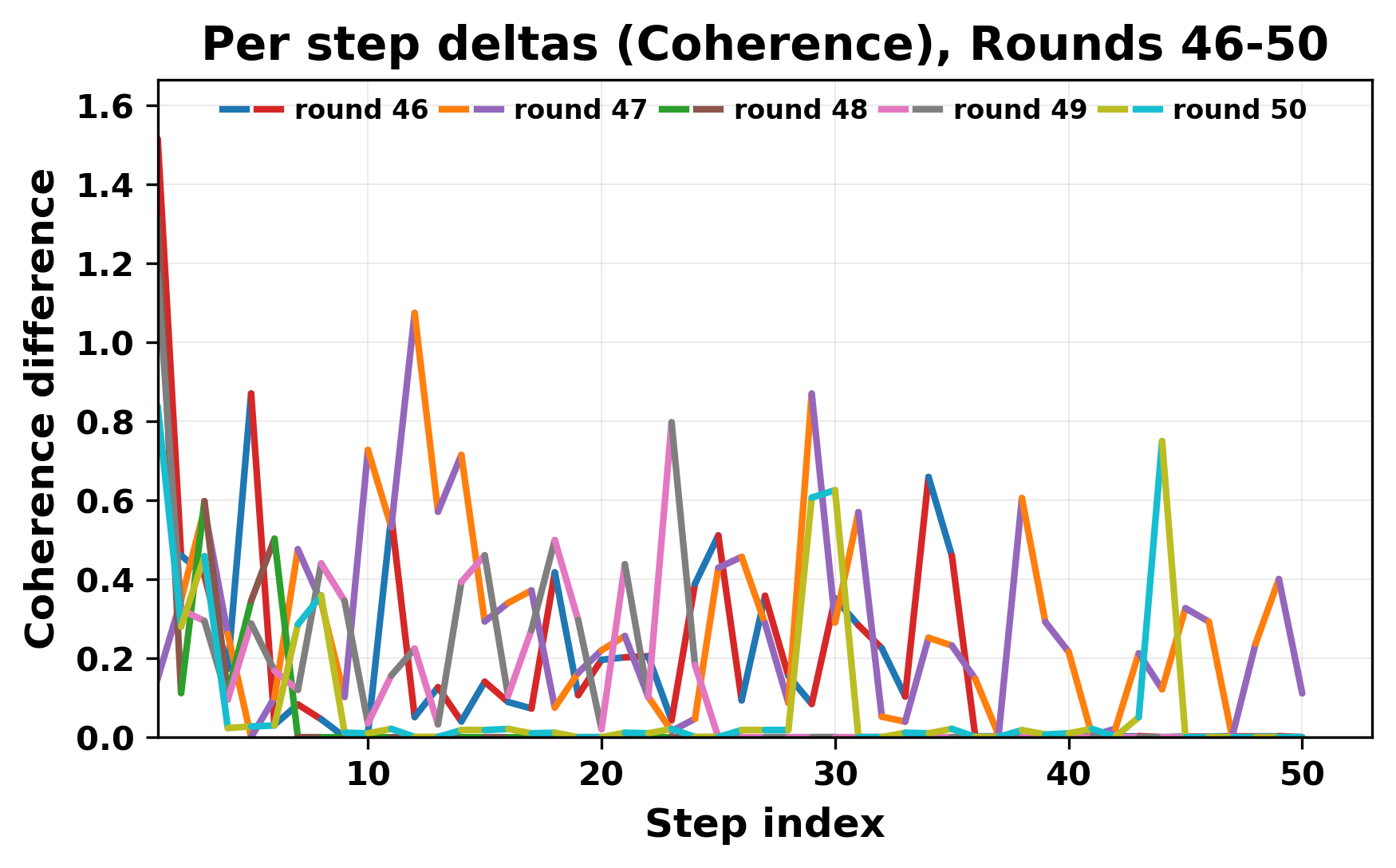
herent dialogue, but often drift into repetition after a few turns. In some cases,
the collapse is gradual. In others, it is sudden and marked by a repeated phrase.
Once repetition sets in, it tends to persist in the following turns. This behavior
appears even though the models are large, capable, and not aligned through any
shared context or fine-tuning.
Studying this interaction gives insight into the stability and limits of gen-
erative systems. It also helps identify convergence behaviors that are easy to
miss in prompt-based evaluations. Understanding how and when models fall
into low-diversity states is important for tasks that involve long-form generation
or multi-agent communication.
2
Related Work
Research on multi-agent large language models (LLMs) has expanded rapidly in
the past two years. This is a recent trend that investigates how several LLMs in-
teract. Earlier studies differed in goals, but most of them examined how multiple
models exchanged messages, reasoned together, or produced stable output. The
main lines of work are in the areas of : frameworks for multi-agent interaction,
evaluation methods, dialogue stability, and co
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.