📝 Original Info
- Title: A-3PO: Accelerating Asynchronous LLM Training with Staleness-aware Proximal Policy Approximation
- ArXiv ID: 2512.06547
- Date: 2025-12-06
- Authors: Researchers from original ArXiv paper
📝 Abstract
Decoupled PPO has been a successful reinforcement learning (RL) algorithm to deal with the high data staleness under the asynchronous RL setting. Decoupled loss used in decoupled PPO improves coupled-loss style of algorithms' (e.g., standard PPO, GRPO) learning stability by introducing a proximal policy to decouple the off-policy correction (importance weight) from the policy update constraint (trust region). However, the proximal policy requires an extra forward pass through the model at each training step, creating a computational overhead for large language models training. We observe that since the proximal policy only serves as a trust region anchor between the behavior and target policies, we can approximate it through simple interpolation without explicit computation. We call this approach A-3PO (APproximated Proximal Policy Optimization). A-3PO eliminates this overhead, accelerating training by 1.8x speedup while maintaining comparable performance. Code \& off-the-shelf example are available at: https://github.com/inclusionAI/AReaL/blob/main/docs/algorithms/prox_approx.md
💡 Deep Analysis
Deep Dive into A-3PO: Accelerating Asynchronous LLM Training with Staleness-aware Proximal Policy Approximation.
Decoupled PPO has been a successful reinforcement learning (RL) algorithm to deal with the high data staleness under the asynchronous RL setting. Decoupled loss used in decoupled PPO improves coupled-loss style of algorithms’ (e.g., standard PPO, GRPO) learning stability by introducing a proximal policy to decouple the off-policy correction (importance weight) from the policy update constraint (trust region). However, the proximal policy requires an extra forward pass through the model at each training step, creating a computational overhead for large language models training. We observe that since the proximal policy only serves as a trust region anchor between the behavior and target policies, we can approximate it through simple interpolation without explicit computation. We call this approach A-3PO (APproximated Proximal Policy Optimization). A-3PO eliminates this overhead, accelerating training by 1.8x speedup while maintaining comparable performance. Code & off-the-shelf example
📄 Full Content
A-3PO: Accelerating Asynchronous LLM
Training with Staleness-aware Proximal Policy
Approximation⋆
Xiao-Can (Bruce) Li1, Shi-Liang (Bruce) Wu1, and Zheng Shen1
Huawei Canada
hsiaotsan.li@alumni.utoronto.ca, {okwsl201210, zhengshencn}@gmail.com
Abstract. Decoupled PPO has been a successful reinforcement learn-
ing (RL) algorithm to deal with the high data staleness under the asyn-
chronous RL setting. Decoupled loss used in decoupled PPO improves
coupled-loss style of algorithms’ (e.g., standard PPO, GRPO) learning
stability by introducing a proximal policy to decouple the off-policy cor-
rection (importance weight) from the policy update constraint (trust
region). However, the proximal policy requires an extra forward pass
through the model at each training step, creating a computational over-
head for large language models training. We observe that since the proxi-
mal policy only serves as a trust region anchor between the behavior and
target policies, we can approximate it through simple interpolation with-
out explicit computation. We call this approach A-3PO (APproximated
Proximal Policy Optimization). A-3PO eliminates this overhead, accel-
erating training by 1.8× speedup while maintaining comparable perfor-
mance. Code & off-the-shelf example are available at: https://github.
com/inclusionAI/AReaL/blob/main/docs/algorithms/prox_approx.md
Keywords: Reinforcement Learning · Policy Optimization · Large Lan-
guage Models
1
Introduction
Reinforcement learning (RL) has become a central approach to improve the rea-
soning capabilities of large language models (LLMs) [21,26,28,27,17], with exten-
sive surveys covering RL from human feedback methods and workflows [11,5,23]
and various alternative approaches including AI feedback [15] and safety consid-
erations [3]. Among RL algorithms, Proximal Policy Optimization (PPO) [20]
has emerged as the dominant method due to its stable trust-region constraints,
building upon earlier trust region methods like TRPO [19]. However, standard
PPO performs rollout-then-training loop, i.e., the training stage must wait un-
til the rollout stage collects predefined number of episodes, limiting throughput
(measured by the number of environment steps per unit of time) and under-
utilizes computational resources.
⋆The first and second authors have equal contribution.
arXiv:2512.06547v2 [cs.LG] 9 Jan 2026
2
X.-C. Li et al.
To improve the throughput and computational resources utilization, asyn-
chronous RL [9,24,22,8,16,25,7,14,6,2] treats rollout and training as two indepen-
dent engines, which can be executed in parallel. Nevertheless, the target policy
on the training engine can be several updates ahead of the behavior policy on
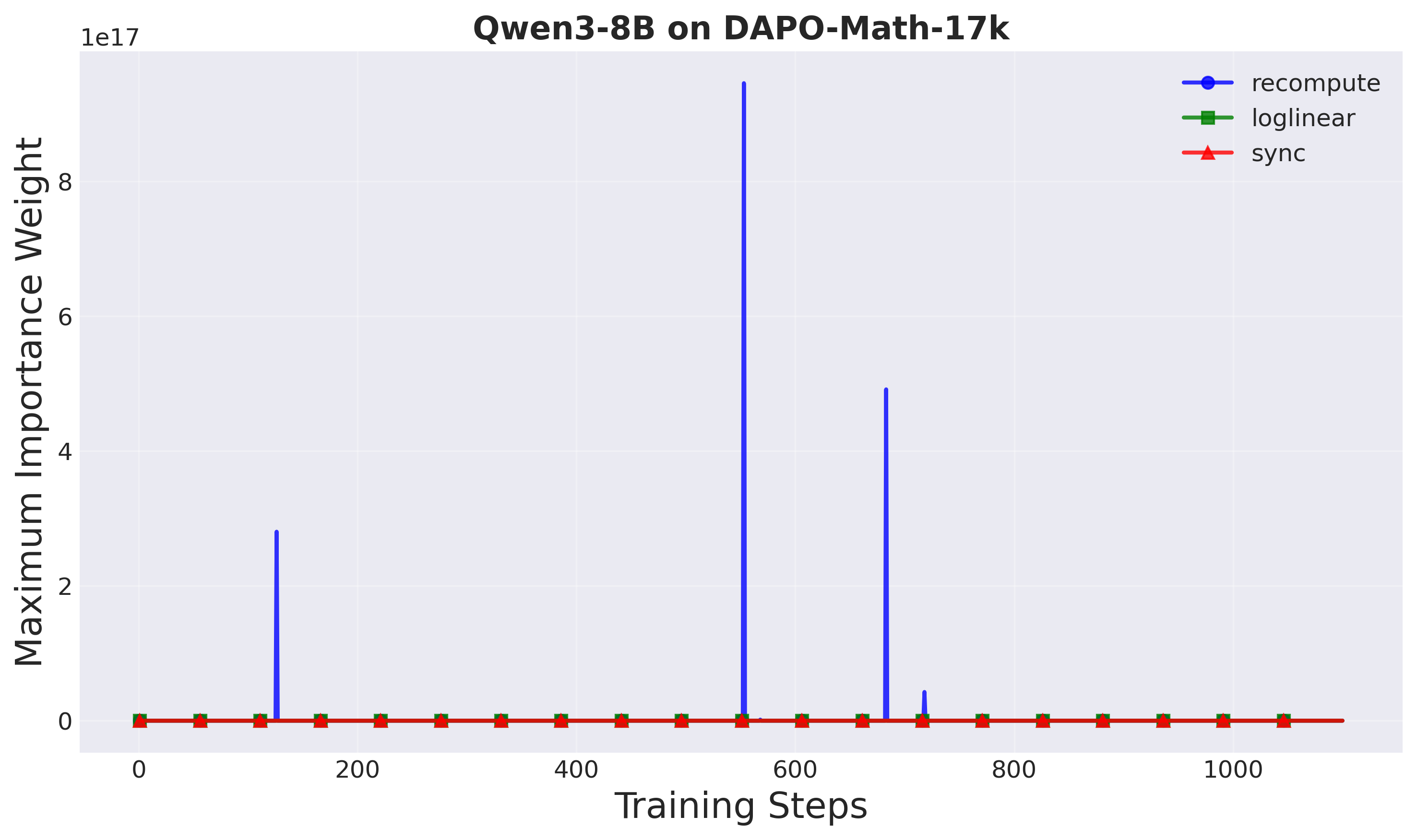
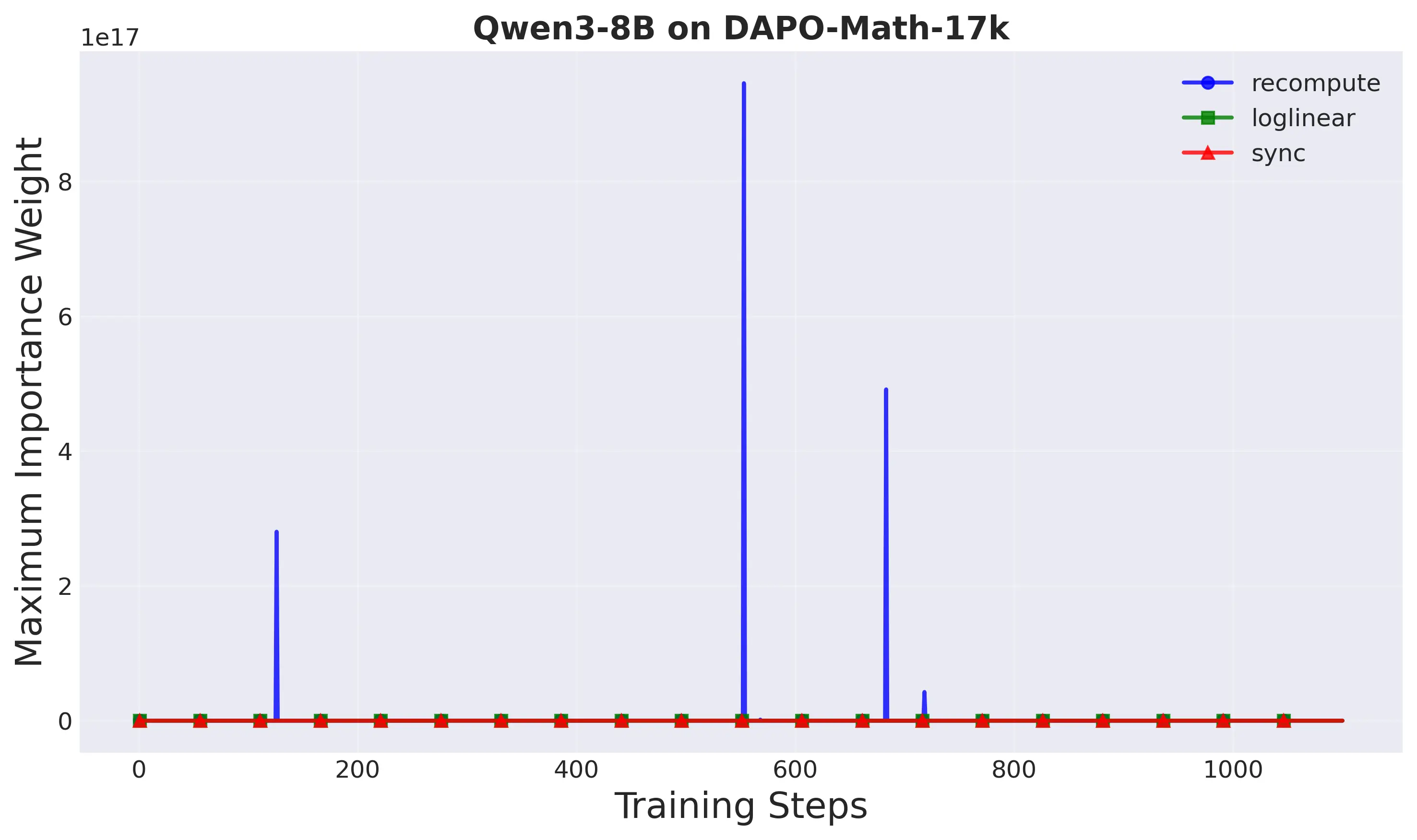
the rollout engine. Such staleness (off-policyness) caused by asynchronous RL
setting could lead to severe learning instability in standard PPO. To mitigate
this, decoupled PPO [10] improves the learning stability by introducing a proxi-
mal policy that decouples the off-policy correction (importance weight) from the
policy update constraint (trust region). Decoupled loss empirically demonstrates
improved learning stability in Atari games when high off-policyness exists. Apart
from Atari games, AReaL [9], an LLM post training framework, demonstrated
superior learning stability of decoupled loss on LLM reasoning tasks under high
off-policyness setting. Thanks to asynchronous RL setup, AReaL also achieved
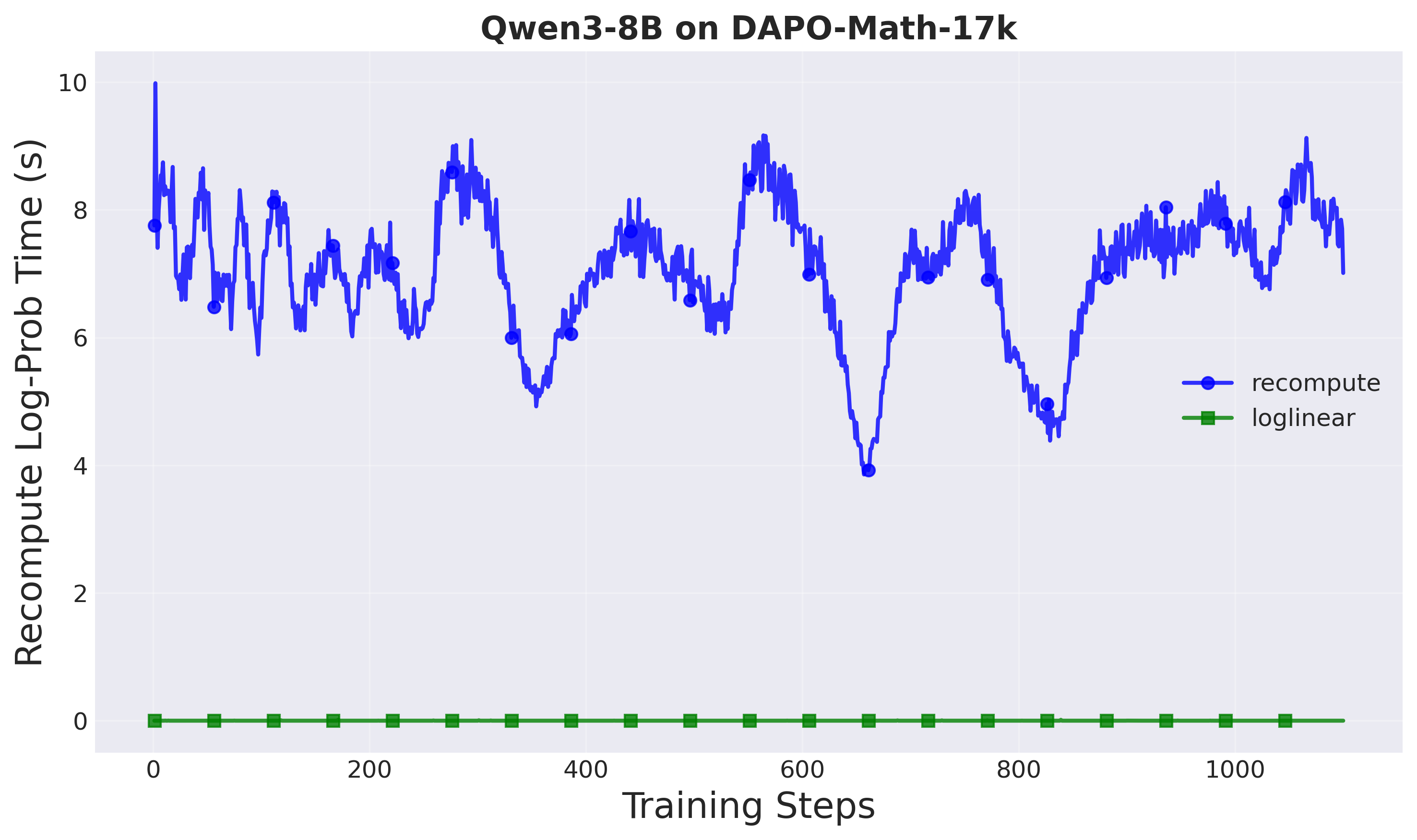
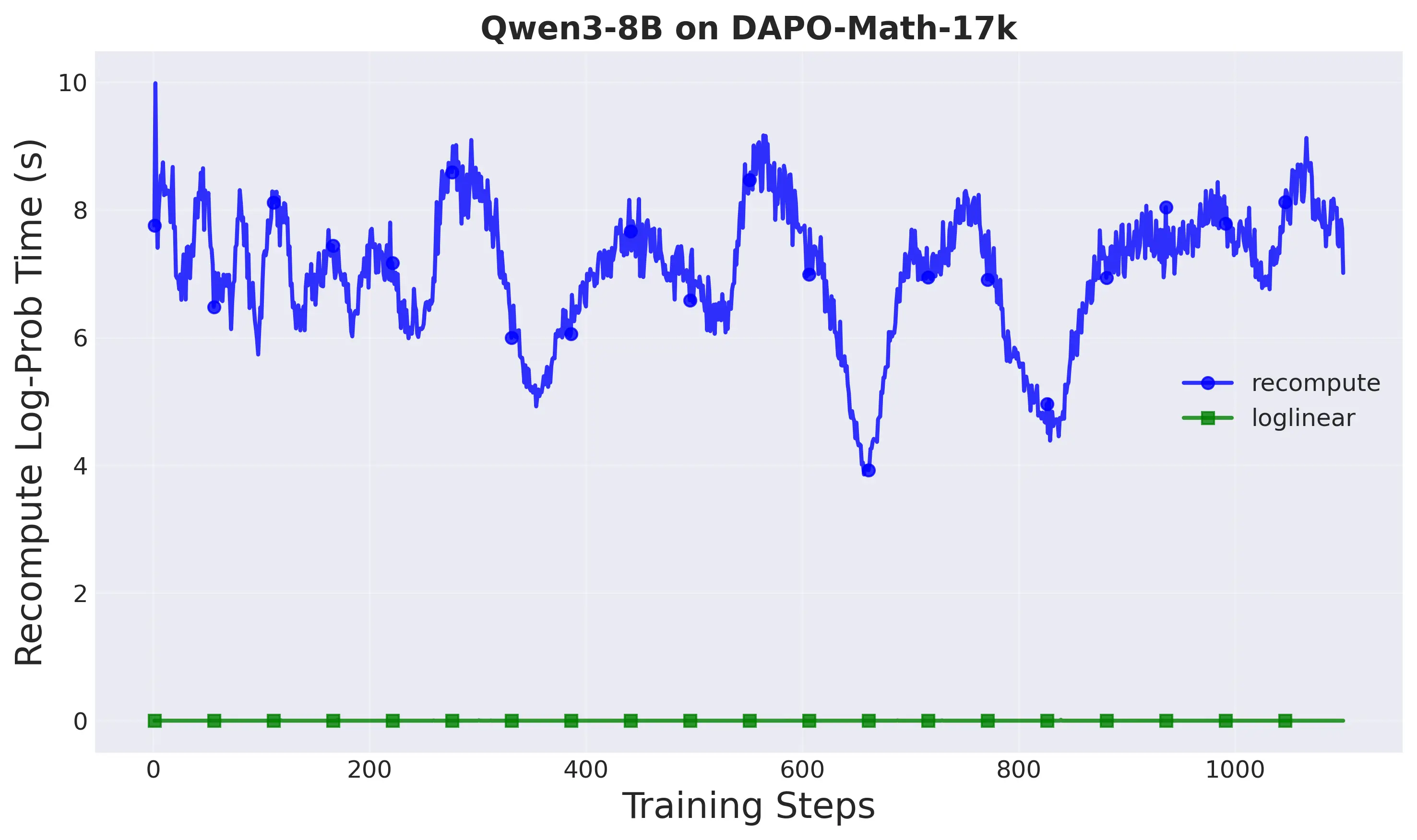
up to 2.77× training speedup. However, the proximal policy in decoupled loss
requires an extra forward pass through the neural network at each training step,
which is expensive for autoregressive LLMs. This overhead limits the potential
speedups from asynchronous training.
This raises a natural question: do we really need to compute the
proximal policy explicitly? Looking at the objective from first prin-
ciples, the proximal policy simply serves as a trust region anchor: it
does not need to be computed from the network, but it just needs
to lie somewhere between the behavior and target policies to prevent
extreme importance weights. This insight leads to our solution: instead of
computing the proximal policy through a forward pass, we approximate it by in-
terpolating between the behavior policy and the target policy in log-probability
space. Our staleness-aware interpolation weighs fresher data more heavily, main-
taining the stabilizing effect of decoupled loss while eliminating the computa-
tional overhead.
Our contributions are threefold:
1. A staleness-aware proximal probability interpolation method that eliminates
the computation cost of proximal policies in decoupled loss while retaining
the trust-region structure of PPO.
2. Empirical evaluation across two model scales (1.5B and 8B parameters)
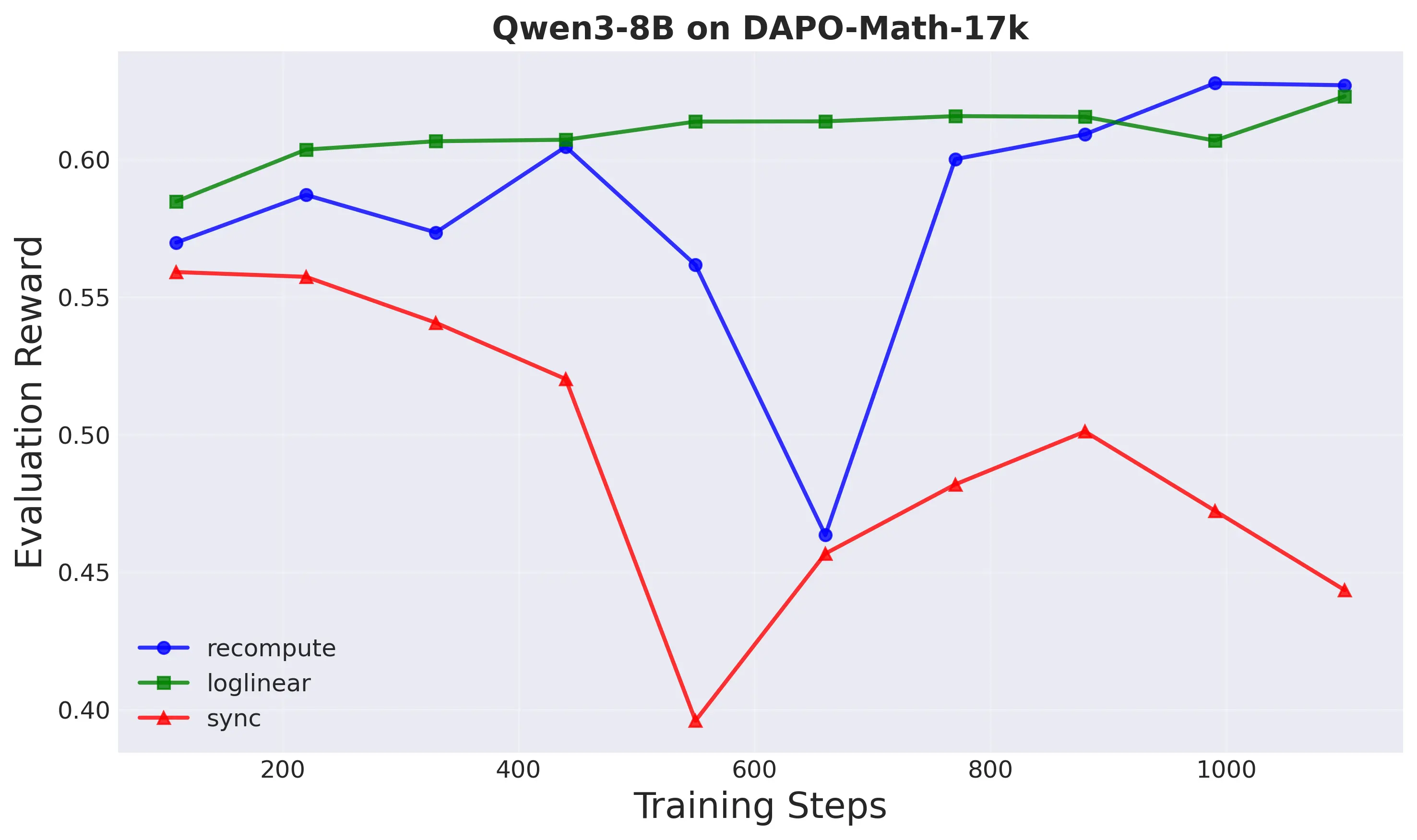
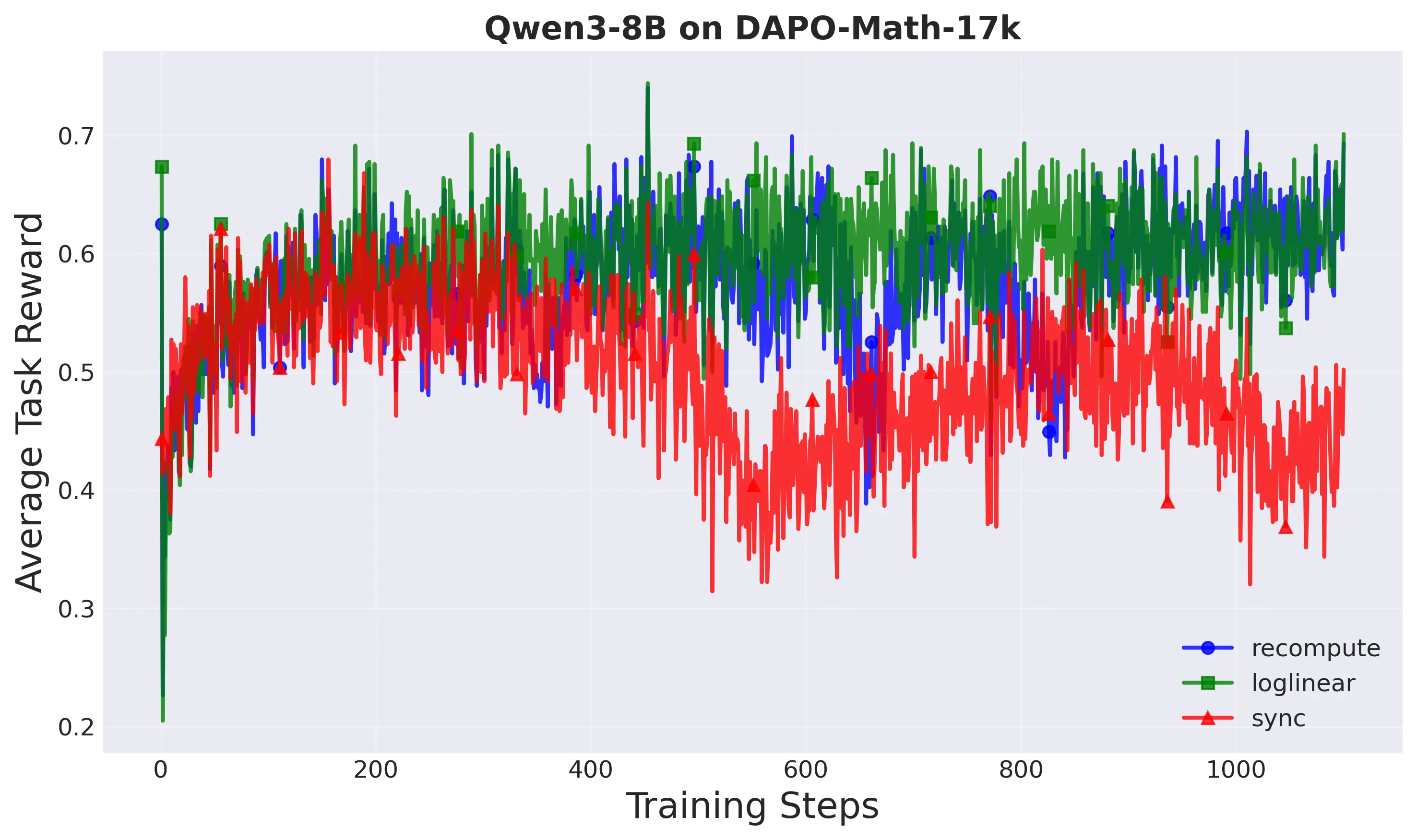
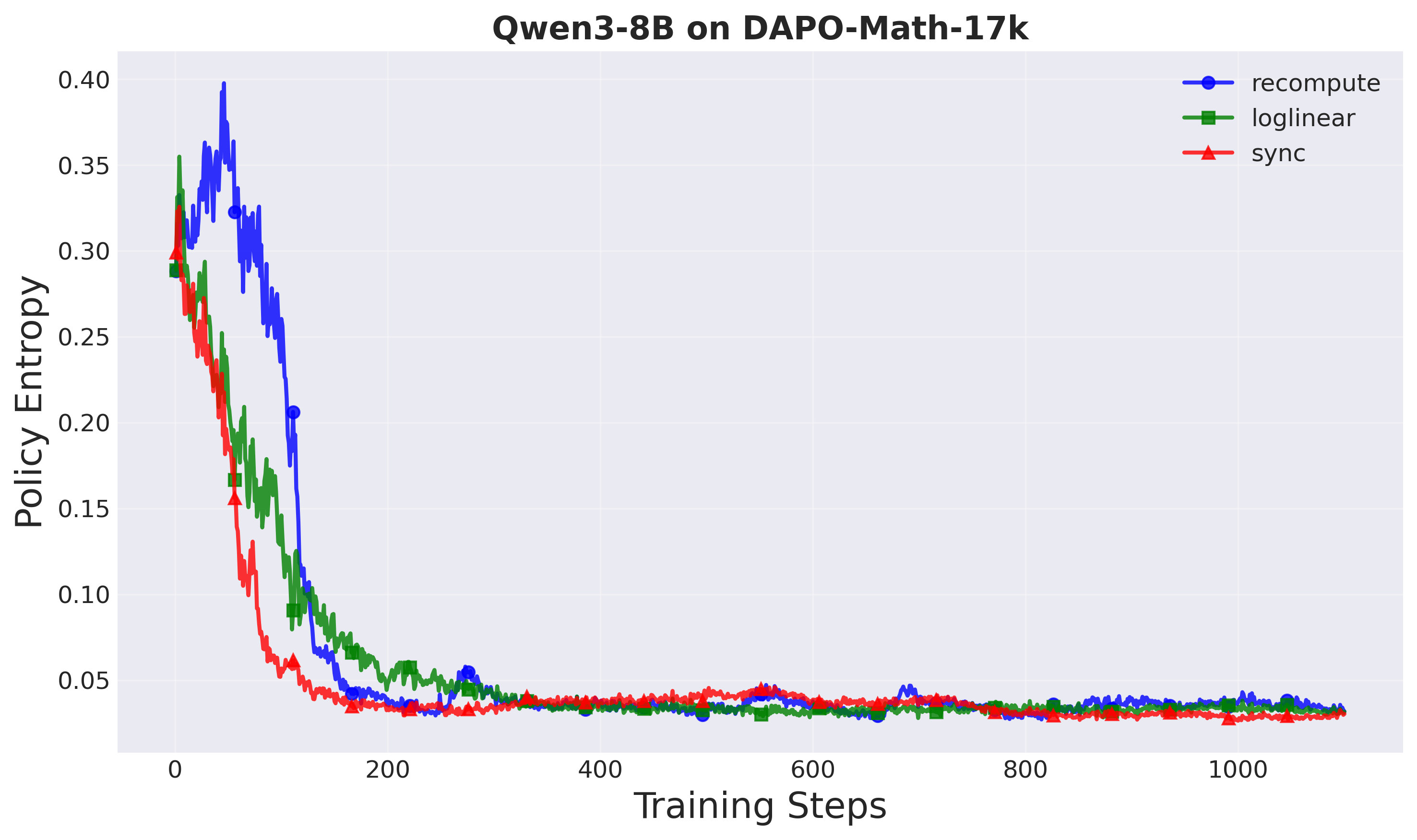
demonstrates that our method achieves up to 1.8× speedup in training time
while maintaining comparable task performance and superior training stabil-
ity compared to both the standard decoupled PPO and synchronous training
baselines, with particular advan
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.