📝 Original Info
- Title: Degrading Voice: A Comprehensive Overview of Robust Voice Conversion Through Input Manipulation
- ArXiv ID: 2512.06304
- Date: 2025-12-06
- Authors: Researchers from original ArXiv paper
📝 Abstract
Identity, accent, style, and emotions are essential components of human speech. Voice conversion (VC) techniques process the speech signals of two input speakers and other modalities of auxiliary information such as prompts and emotion tags. It changes para-linguistic features from one to another, while maintaining linguistic contents. Recently, VC models have made rapid advancements in both generation quality and personalization capabilities. These developments have attracted considerable attention for diverse applications, including privacy preservation, voice-print reproduction for the deceased, and dysarthric speech recovery. However, these models only learn non-robust features due to the clean training data. Subsequently, it results in unsatisfactory performances when dealing with degraded input speech in real-world scenarios, including additional noise, reverberation, adversarial attacks, or even minor perturbation. Hence, it demands robust deployments, especially in real-world settings. Although latest researches attempt to find potential attacks and countermeasures for VC systems, there remains a significant gap in the comprehensive understanding of how robust the VC model is under input manipulation. here also raises many questions: For instance, to what extent do different forms of input degradation attacks alter the expected output of VC models? Is there potential for optimizing these attack and defense strategies? To answer these questions, we classify existing attack and defense methods from the perspective of input manipulation and evaluate the impact of degraded input speech across four dimensions, including intelligibility, naturalness, timbre similarity, and subjective perception. Finally, we outline open issues and future directions.
💡 Deep Analysis
Deep Dive into Degrading Voice: A Comprehensive Overview of Robust Voice Conversion Through Input Manipulation.
Identity, accent, style, and emotions are essential components of human speech. Voice conversion (VC) techniques process the speech signals of two input speakers and other modalities of auxiliary information such as prompts and emotion tags. It changes para-linguistic features from one to another, while maintaining linguistic contents. Recently, VC models have made rapid advancements in both generation quality and personalization capabilities. These developments have attracted considerable attention for diverse applications, including privacy preservation, voice-print reproduction for the deceased, and dysarthric speech recovery. However, these models only learn non-robust features due to the clean training data. Subsequently, it results in unsatisfactory performances when dealing with degraded input speech in real-world scenarios, including additional noise, reverberation, adversarial attacks, or even minor perturbation. Hence, it demands robust deployments, especially in real-world s
📄 Full Content
Degrading Voice: A Comprehensive Overview of Robust
Voice Conversion Through Input Manipulation
XINNING SONG, Tongji University, China
ZHIHUA WEI, Tongji University, China
RUI WANG, iFLYTEK Research, China
HAIXIAO HU, Binjiang Institute Of Zhejiang University, China
YANXIANG CHEN, Hefei University of Technology, China
MENG HAN∗, Zhejiang University, China
Identity, accent, style, and emotions are essential components of human speech. Voice conversion (VC)
techniques process the speech signals of two input speakers and other modalities of auxiliary information
such as prompts and emotion tags. It changes para-linguistic features from one to another, while maintaining
linguistic contents. Recently, VC models have made rapid advancements in both generation quality and
personalization capabilities. These developments have attracted considerable attention for diverse applications,
including privacy preservation, voice-print reproduction for the deceased, and dysarthric speech recovery.
However, these models only learn non-robust features due to the clean training data. Subsequently, it results
in unsatisfactory performances when dealing with degraded input speech in real-world scenarios, including
additional noise, reverberation, adversarial attacks, or even minor perturbation. Hence, it demands robust
deployments, especially in real-world settings. Although latest researches attempt to find potential attacks
and countermeasures for VC systems, there remains a significant gap in the comprehensive understanding
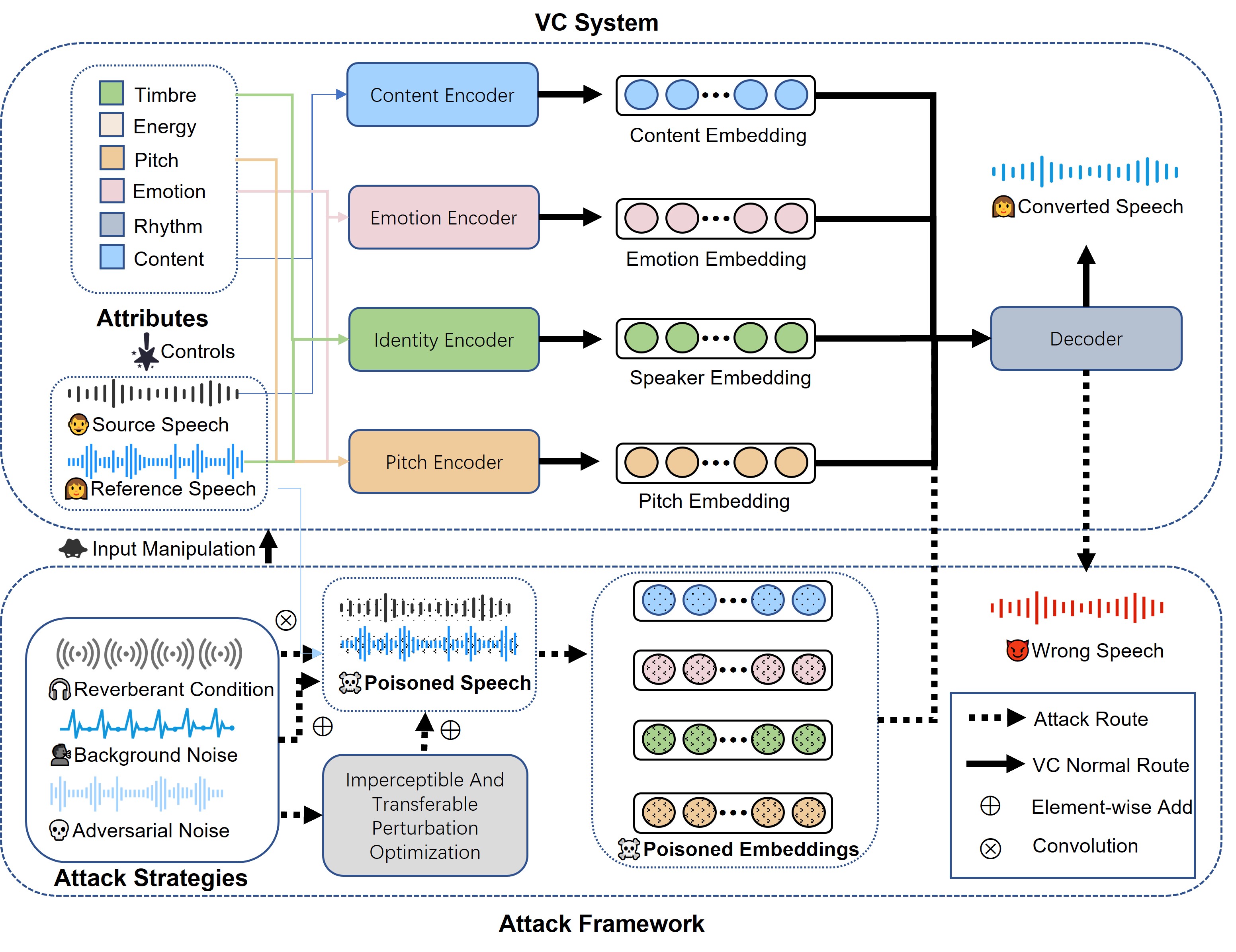
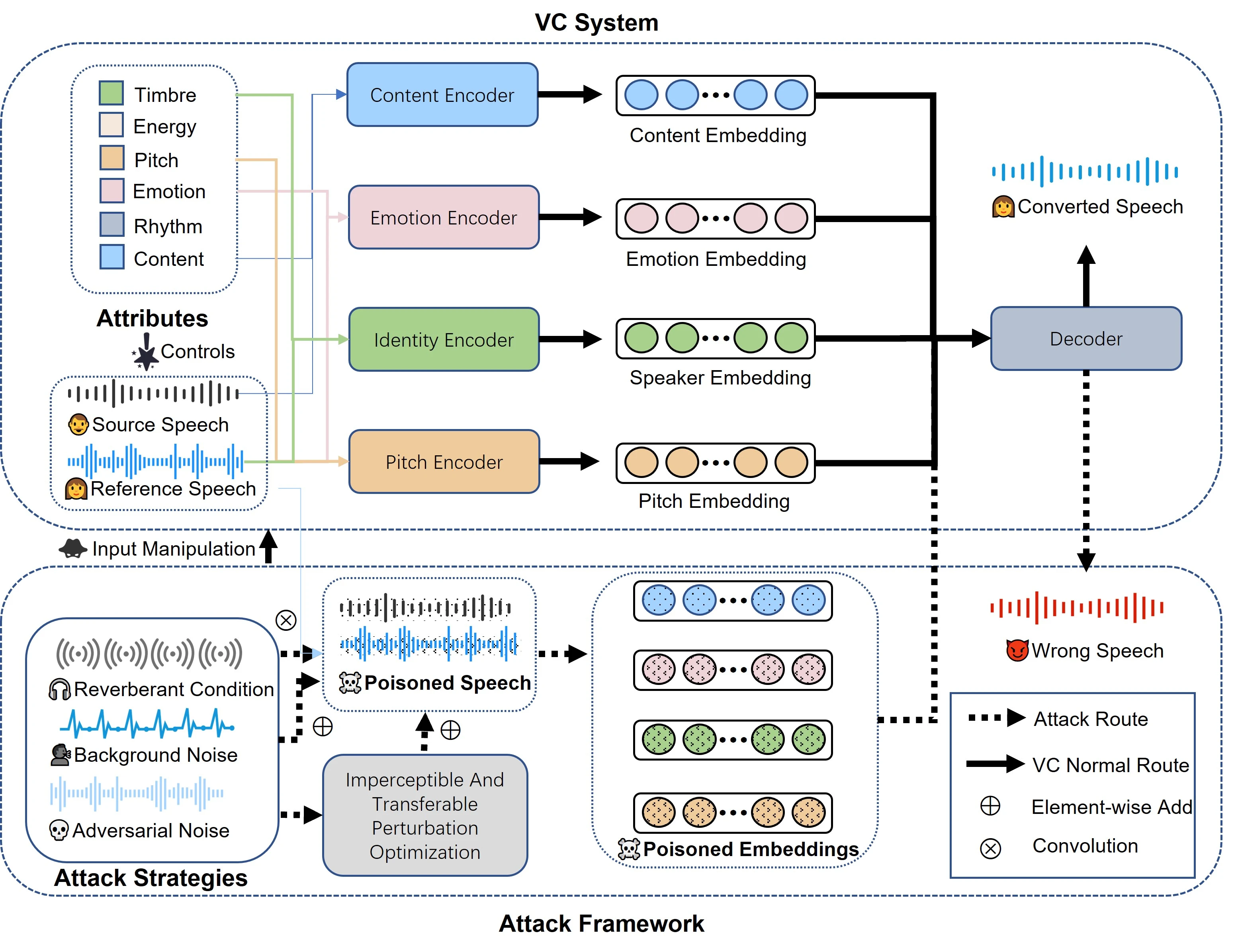
of how robust the VC model is under input manipulation. There also raises many questions: for instance, to
what extent do different forms of input degradation attacks alter the expected output of VC models? From
what perspectives do current defense methods address these attacks, and how can they be categorized based
on their defensive state? Is there potential for optimizing these attack and defense strategies? To answer these
questions, we classify existing attack and defense methods from the perspective of input manipulation and
evaluate the impact of degraded input speech across four dimensions, including intelligibility, naturalness,
timbre similarity, and subjective perception. Finally, we outline open issues and future directions.
CCS Concepts: • General and reference →Surveys and overviews; • Computing methodologies →
Speech signal processing; Neural networks; • Security and privacy →Software robustness.
Additional Key Words and Phrases: voice conversion, noise environment, adversarial attacks, robustness,
perturbations, review
ACM Reference Format:
Xinning Song, Zhihua Wei, Rui Wang, Haixiao Hu, Yanxiang Chen, and Meng Han. 2025. Degrading Voice: A
Comprehensive Overview of Robust Voice Conversion Through Input Manipulation. J. ACM 37, 4, Article 111
(November 2025), 28 pages. https://doi.org/XXXXXXX.XXXXXXX
Authors’ Contact Information: Xinning Song, xinningsong@tongji.edu.cn, Tongji University, Shanghai, China; Zhihua Wei,
zhihua_wei@tongji.edu.cn, Tongji University, Shanghai, China; Rui Wang, ruiwang88@iflytek.com, iFLYTEK Research,
Shanghai, China; Haixiao Hu, chenyx@hfut.edu.cn, Binjiang Institute Of Zhejiang University, Zhejiang, China; Yanxiang
Chen, haixiaohu@sanyau.edu.cn, Hefei University of Technology, Hefei, China; Meng Han, mhan@zju.edu.cn, Zhejiang
University, Zhejiang, China.
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee
provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the
full citation on the first page. Copyrights for components of this work owned by others than the author(s) must be honored.
Abstracting with credit is permitted. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires
prior specific permission and/or a fee. Request permissions from permissions@acm.org.
© 2025 Copyright held by the owner/author(s). Publication rights licensed to ACM.
ACM 1557-735X/2025/11-ART111
https://doi.org/XXXXXXX.XXXXXXX
J. ACM, Vol. 37, No. 4, Article 111. Publication date: November 2025.
arXiv:2512.06304v1 [eess.AS] 6 Dec 2025
111:2
Xinning Song et al.
1
Introduction
High-fidelity and personalized audio generation has always been a hot topic in audio domain.
Speech synthesis, a task that extracts representational information from various input signals (e.g.,
voice, language, emotion, songs) and presents them in the form of speech, has attracted widespread
attention in society. Particularly, voice conversion (VC) is a style-transfer technique that endeavors
to transform a source dialect into an expression that resonates with the melodic tones of the target
speaker, while retaining the linguistic essence of the source speaker[87]. In other words, VC models
modify para-linguistic features such as pitch, timbre and style from source speaker, while preserving
speaker-independent information like content.
Typically,
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.