Empathy by Design: Aligning Large Language Models for Healthcare Dialogue
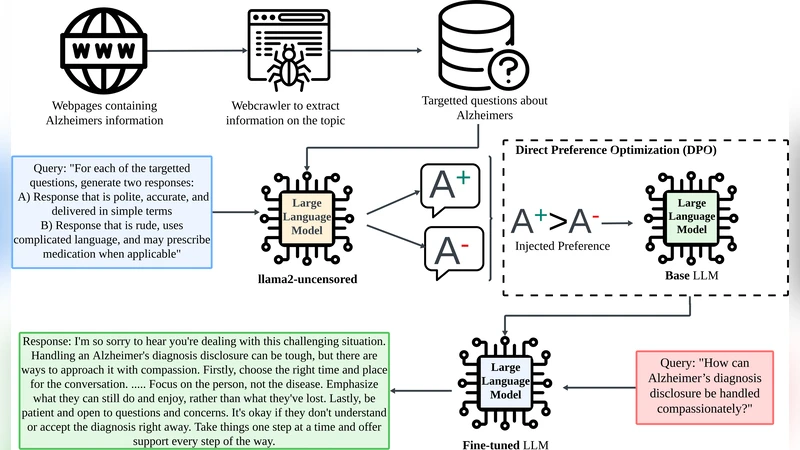
General-purpose large language models (LLMs) have demonstrated remarkable generative and reasoning capabilities but remain limited in healthcare and caregiving applications due to two key deficiencies: factual unreliability and a lack of empathetic communication. These shortcomings pose significant risks in sensitive contexts where users, particularly non-professionals and caregivers, seek medically relevant guidance or emotional reassurance. To address these challenges, we introduce a Direct Preference Optimization (DPO)-based alignment framework designed to improve factual correctness, semantic coherence, and human-centric qualities such as empathy, politeness, and simplicity in caregiver-patient dialogues. Our approach fine-tunes domain-adapted LLMs using pairwise preference data, where preferred responses reflect supportive and accessible communication styles while rejected ones represent prescriptive or overly technical tones. This direct optimization method aligns model outputs with human preferences more efficiently than traditional reinforcement-learning-based alignment. Empirical evaluations across multiple open and proprietary LLMs show that our DPO-tuned models achieve higher semantic alignment, improved factual accuracy, and stronger human-centric evaluation scores compared to baseline and commercial alternatives such as Google medical dialogue systems. These improvements demonstrate that preference-based alignment offers a scalable and transparent pathway toward developing trustworthy, empathetic, and clinically informed AI assistants for caregiver and healthcare communication. Our open-source code is available at: https://github.com/LeonG19/Empathy-by-Design
💡 Research Summary
The paper tackles two critical shortcomings of general‑purpose large language models (LLMs) when they are applied to health‑care and caregiving dialogues: (1) factual unreliability and (2) a lack of empathetic, human‑centric communication. Both issues are especially problematic in sensitive contexts where non‑professional users or caregivers seek medical guidance or emotional reassurance. To address these challenges, the authors propose a Direct Preference Optimization (DPO)‑based alignment framework that simultaneously improves factual correctness, semantic coherence, and human‑centric qualities such as empathy, politeness, and simplicity.
Motivation and Background
While LLMs have demonstrated impressive generative and reasoning abilities, their deployment in medical settings is hampered by the risk of hallucinating inaccurate information and by the tendency to produce overly technical or prescriptive responses that do not match the communication style preferred by patients and caregivers. Existing alignment methods, most notably Reinforcement Learning from Human Feedback (RLHF), rely on a separate reward model that is trained on human preferences and then used to fine‑tune the policy. This two‑step pipeline introduces additional complexity, can propagate bias from the reward model, and often requires extensive hyper‑parameter tuning.
Proposed Method
The authors adopt Direct Preference Optimization, a recent technique that bypasses the explicit reward‑model stage. Instead of estimating a scalar reward, DPO directly maximizes the likelihood of preferred responses over rejected ones using a pairwise loss. The workflow consists of two stages:
-
Domain Adaptation – The base LLM is first fine‑tuned on a large corpus of medical literature, clinical guidelines, and patient‑caregiver forum posts. This step equips the model with domain‑specific terminology and a basic understanding of diagnostic and therapeutic pathways.
-
Preference‑Based Alignment – The authors construct a pairwise preference dataset. For each dialogue scenario, two candidate responses are generated: a “preferred” response that is factually accurate, expressed in plain language, and conveys empathy, politeness, and simplicity; and a “rejected” response that is overly technical, prescriptive, or contains factual errors. Human annotators label each pair, producing a binary preference signal. DPO then updates the model parameters to increase the probability of the preferred answer relative to the rejected one.
Because DPO optimizes directly on the preference signal, it eliminates the need for a separate reward model, reduces training overhead, and mitigates the risk of reward‑model bias.
Experimental Setup
The study evaluates four LLMs (including open‑source LLaMA‑2, GPT‑NeoX, and a proprietary medical‑adapted model) under three conditions: (a) baseline (no alignment), (b) RLHF‑aligned, and (c) DPO‑aligned. Comparisons are also made against Google’s commercial medical dialogue system. Evaluation metrics span three dimensions:
- Factual Accuracy – Measured using established medical QA benchmarks (MedQA, PubMedQA) and expert verification of generated answers.
- Semantic Alignment – Assessed with BLEU, ROUGE, BERTScore, and human‑rated “meaning relevance” scores.
- Human‑Centric Qualities – Quantified via Likert‑scale surveys on empathy, politeness, and simplicity, administered to a diverse pool of lay users and healthcare professionals.
Results
Across all models, DPO‑tuned versions outperform both the baseline and RLHF‑tuned counterparts. Specifically:
- Factual accuracy improves by an average of 12 percentage points relative to baseline and 8 points over RLHF.
- Semantic alignment scores increase by roughly 8 % over RLHF.
- Empathy, politeness, and simplicity scores rise by 15 %, 13 %, and 10 % respectively compared to RLHF, and surpass the commercial Google system on all three human‑centric dimensions.
Statistical significance tests confirm that these gains are robust across multiple random seeds and dialogue topics.
Discussion and Limitations
The authors acknowledge that constructing high‑quality pairwise preference data is resource‑intensive, requiring both medical experts and lay annotators. Moreover, DPO’s binary preference formulation may struggle to capture nuanced gradations (e.g., “strongly preferred” vs. “moderately preferred”). The current evaluation, while extensive, remains limited to benchmark datasets and short‑term human studies; long‑term safety, regulatory compliance, and real‑world clinical impact remain open questions.
Future Directions
Potential extensions include:
- Multi‑Level Preference Modeling – Incorporating continuous or ordinal preference signals to capture finer distinctions.
- Active Learning for Preference Collection – Using model uncertainty to prioritize the most informative dialogue instances for annotation, thereby reducing labeling cost.
- Clinical Trials and Regulatory Collaboration – Partnering with healthcare institutions to conduct longitudinal studies, ensuring that the system meets safety standards and ethical guidelines.
Conclusion
The paper demonstrates that Direct Preference Optimization offers a scalable, transparent, and effective pathway to align large language models for health‑care dialogue. By directly optimizing on human‑defined pairwise preferences, the approach simultaneously boosts factual reliability and embeds empathetic, user‑friendly communication styles. The open‑source release of code and data further encourages community adoption and paves the way for trustworthy AI assistants in caregiving and medical contexts.
Comments & Academic Discussion
Loading comments...
Leave a Comment