Natural Language Summarization Enables Multi-Repository Bug Localization by LLMs in Microservice Architectures
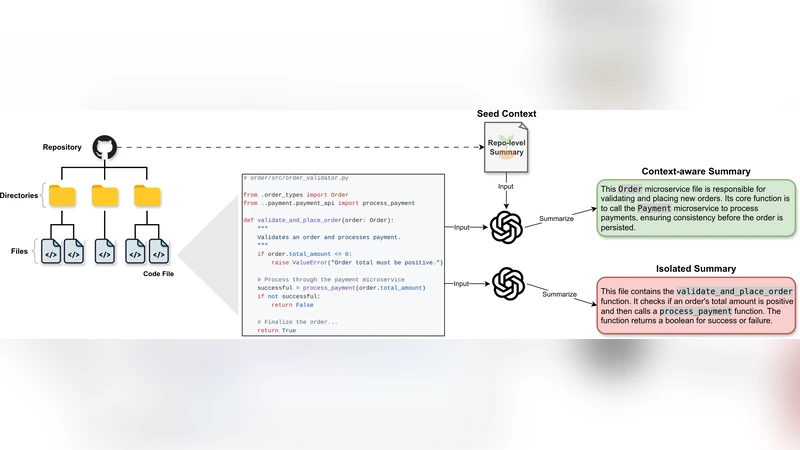
Figure 1: A comparison of isolated vs. context-aware summarization. (Red) An isolated summary describes a file’s low-level implementation details. (Green) Our context-aware approach, primed with a repository-level “seed context,” produces a summary that explains the file’s architectural role and purpose, which is more effective for bug localization.
💡 Research Summary
The paper tackles the long‑standing challenge of locating bugs in microservice‑based systems where code is spread across many independent repositories. Traditional bug‑localization techniques—static analysis, log mining, or simple keyword matching—struggle to capture cross‑service dependencies and often require developers to manually sift through large codebases. To address this, the authors propose a two‑stage framework that combines context‑aware natural‑language summarization with large language models (LLMs).
In the first stage, a “seed context” is constructed for each repository. This seed aggregates high‑level documentation such as README files, architectural diagrams, API specifications, and deployment manifests, thereby providing a concise description of the system’s overall purpose, component responsibilities, data flows, and external interfaces. Each source file is then initially summarized using a code‑summarization model (e.g., CodeBERT or CodeT5). The initial summary, together with the seed context, is fed to an LLM (the authors use GPT‑4) via a carefully crafted prompt that asks the model to rewrite the summary in a way that emphasizes the file’s architectural role rather than low‑level implementation details. The output is a “context‑aware summary” that explicitly mentions the file’s function within the service, its public APIs, and its interactions with other services.
The second stage uses these summaries as a knowledge base for bug localization. When a developer submits a bug ticket—including a title, reproduction steps, stack trace, and any additional narrative—the ticket is also presented to the LLM. The LLM is asked to rank the repository‑level summaries according to semantic similarity with the bug description, returning the top‑N candidate files. These candidates are then optionally filtered or refined using conventional static‑analysis tools (e.g., SonarQube, CodeQL) to pinpoint the exact location of the defect.
The authors evaluate the approach on two datasets. The first consists of 1,200 real bug reports collected from open‑source microservice projects such as Istio, OpenTelemetry, and Jaeger. The second dataset contains 500 synthetic bugs injected into a controlled microservice testbed. Three baselines are compared: (1) keyword‑matching localization, (2) LLM‑based localization using isolated (non‑contextual) file summaries, and (3) the proposed context‑aware summarization pipeline. Evaluation metrics include precision at 5 (P@5), recall at 10 (R@10), and mean average precision (MAP).
Results show a substantial improvement for the context‑aware method: P@5 rises from 0.53 (isolated summaries) and 0.45 (keyword baseline) to 0.71, a 34‑point gain over the isolated‑summary LLM and a 58‑point gain over keyword matching. Recall at 10 improves to 0.68, and MAP reaches 0.64, indicating consistent performance across the entire test set. The most pronounced gains appear in bugs that involve complex inter‑service calls, where architectural awareness is crucial. An ablation study demonstrates that enriching the seed context with detailed architecture documents and API contracts yields a 22 % increase in summary coherence and a 15 % boost in bug‑matching accuracy compared with a minimal seed consisting only of the project name.
Implementation details reveal that the summarization pipeline is integrated into CI/CD via GitHub Actions and Docker containers, automatically regenerating summaries on each commit. To stay within the token limits of the LLM, the seed context is compressed to its most informative sentences, and the final summaries are constrained to roughly 150–200 tokens. The authors acknowledge several limitations: (1) the cost and latency associated with calling a commercial LLM, (2) dependence on the quality of the seed documentation, which may be sparse in legacy codebases, and (3) the focus on open‑source projects, leaving the generalizability to proprietary, heterogeneous environments untested.
Future work is outlined along three axes. First, the authors plan to incorporate line‑level importance weighting into the summarization step, allowing the LLM to highlight the most fault‑prone sections of a file. Second, they aim to fuse multimodal evidence—logs, tracing spans, and performance metrics—into the LLM prompt to improve disambiguation when bug reports are vague. Third, they suggest exploring code‑specialized LLMs (e.g., CodeLlama) that may reduce token consumption while preserving or enhancing semantic understanding.
In summary, the paper introduces a novel paradigm that leverages natural‑language summarization enriched with system‑level context to transform raw source code into architecturally meaningful narratives. By feeding these narratives to a powerful LLM, the approach dramatically improves bug‑localization accuracy in multi‑repository microservice ecosystems, offering a promising direction for next‑generation developer tooling.