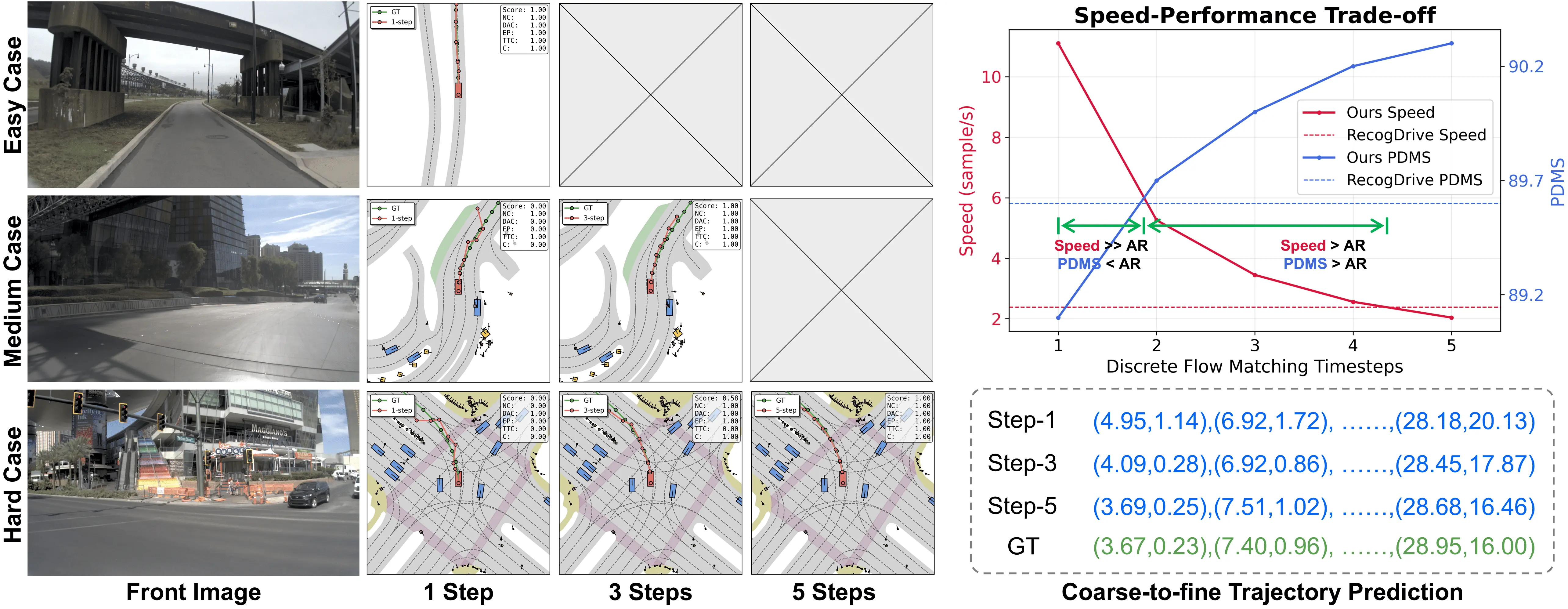
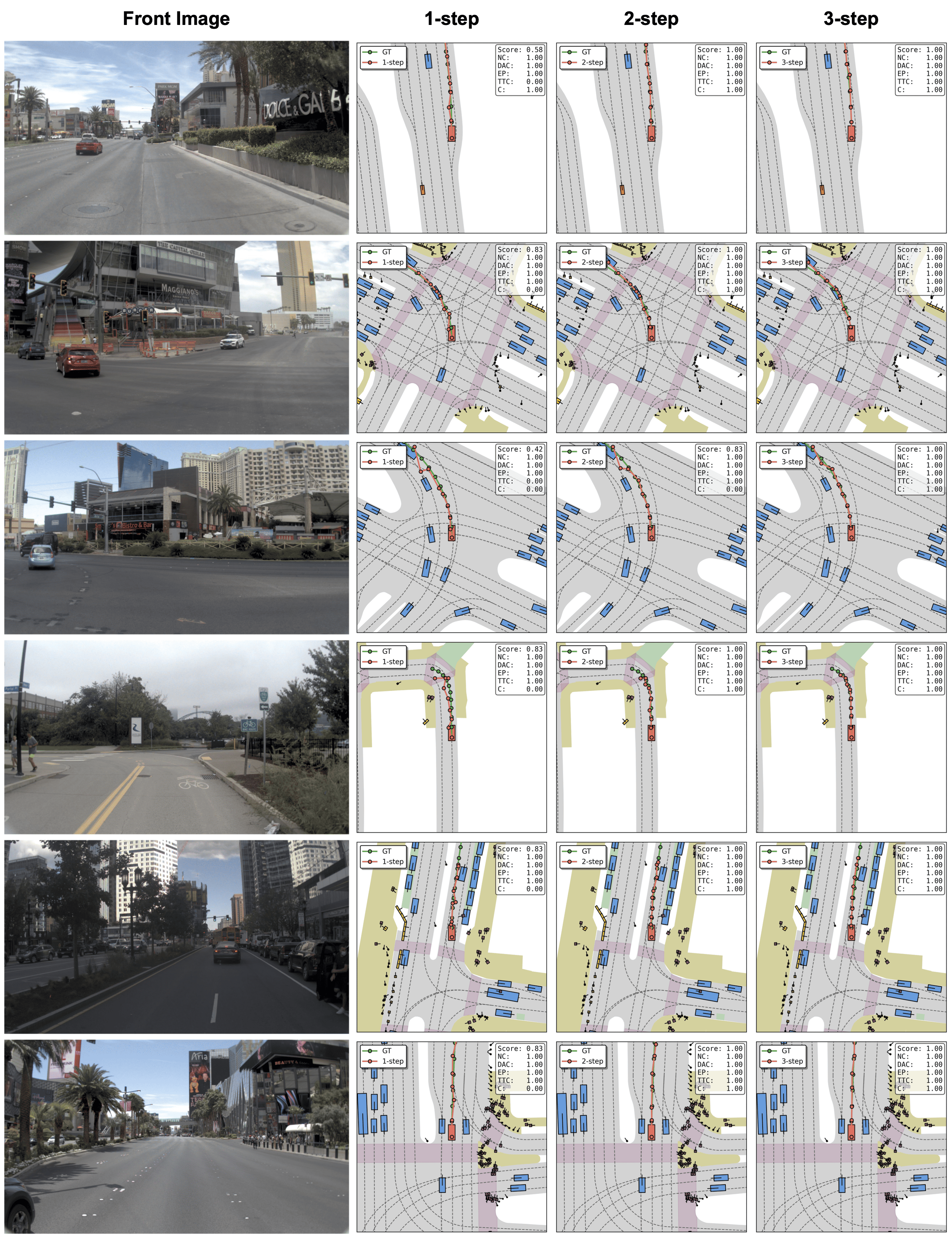
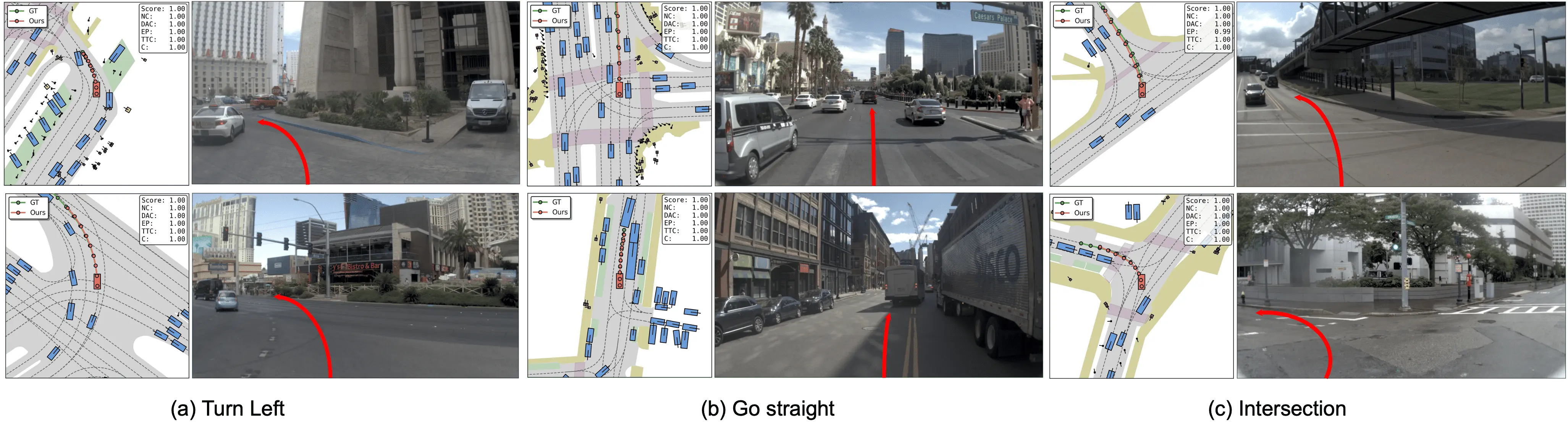
Code & Model: https://github.com/fudan-generative-vision/WAM-Flow Figure 1 . WAM-Flow enables flexible slow-fast and coarse-to-fine trajectory prediction. For straightforward driving scenarios, 1-step denoising achieves competitive performance (89.1 PDMS on NAVSIM-v1), while complex situations benefit from 5-step refinement, yielding further gains (90.3 PDMS). This corresponds to an inference speedup of 4.67× over RecogDrive [32] with 1-step denoising, while 5-step processing matches RecogDrive's latency. These results demonstrate the potential of discrete flow matching for building reliable and scalable autonomous driving systems.
Deep Dive into WAM‑Flow: 이산 흐름 매칭 기반 저지연·고정밀 자율주행 궤적 예측.
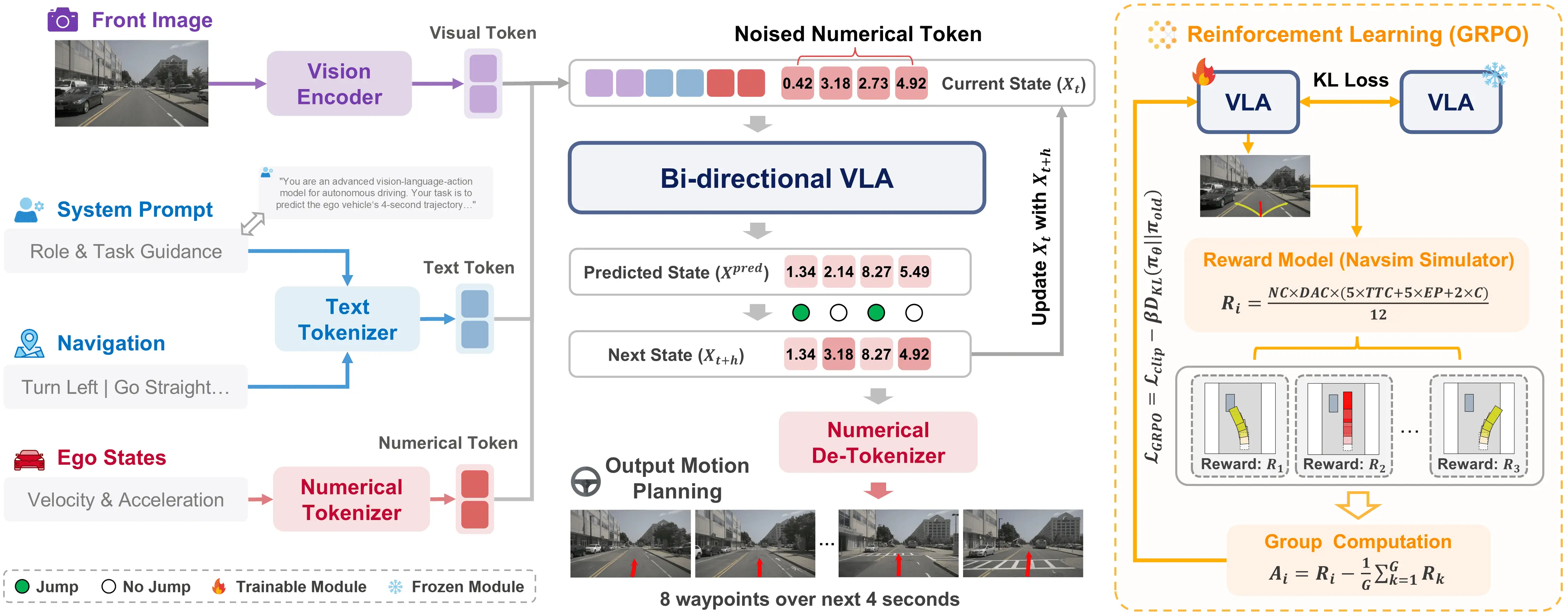
Vision-language-action models for end-to-end autonomous driving [32,58,62] aim to map egocentric driving-view Figure 2. Architecture of the proposed WAM-Flow framework. Our method takes as input a front-view image, a natural-language navigation command with a system prompt, and the ego-vehicle states, and outputs an 8-waypoint future trajectory spanning 4 seconds through parallel denoising. The model is first trained via supervised fine-tuning to learn accurate trajectory prediction. We then apply simulatorguided GRPO to further optimize closed-loop behavior. The GRPO reward function integrates safety constraints (collision avoidance, drivable-area compliance) with performance objectives (ego-progress, time-to-collision, comfort).
video inputs and natural-language instructions into both causal reasoning and precise ego-vehicle motion planning, while satisfying stringent efficiency and safety requirements. A fundamental challenge in this domain is the design of a policy representation that effectively balances three critical aspects: expressive reasoning capabilities, high-fidelity continuous control, and robust closed-loop performance. Existing approaches can be broadly categorized into dual-system and single-system paradigms. Dualsystem methods [20,32,50,60,61] typically employ autoregressive vision-language models (VLMs) [3,36,46,48,63] as auxiliary reasoning modules to provide high-level driving intent, scene summaries, or linguistic guidance for downstream motion planning networks, which often utilize diffusion-based iterative optimization [13,19,24,34] to generate smooth, complex action distributions. In contrast, single-system approaches [7,23,52,58, 62] such as EMMA [23] and DrivingGPT [7] reformulate trajectory or action prediction as a text generation problem within the VLM, enabling reasoning and planning directly in the linguistic space. This work investigates a novel alternative based on discrete flow matching (DFM), which offers distinct advantages for autonomous driving applications.
Discrete flow matching [8,12,14,27,42,44,47,57] models probability transport over discrete token spaces via a continuous-time Markov chain (CTMC) that carries a simple base distribution to the data distribution. Unlike autoregressive decoders that commit to tokens sequentially and accumulate exposure-bias errors, Discrete flow matching supports fully parallel denoising and bidi-rectional refinement during generation. These properties enable coarse-to-fine planning: beginning with a coarse motion hypothesis, the model increases trajectory fidelity through additional denoising steps, yielding a tunable compute-accuracy trade-off. This flexibility aligns well with autonomous driving, where simple scenes admit rapid approximate plans while complex interactions require higherprecision refinement. Despite these advantages, discrete flow matching remains largely unexplored for VLA policies in end-to-end autonomous driving.
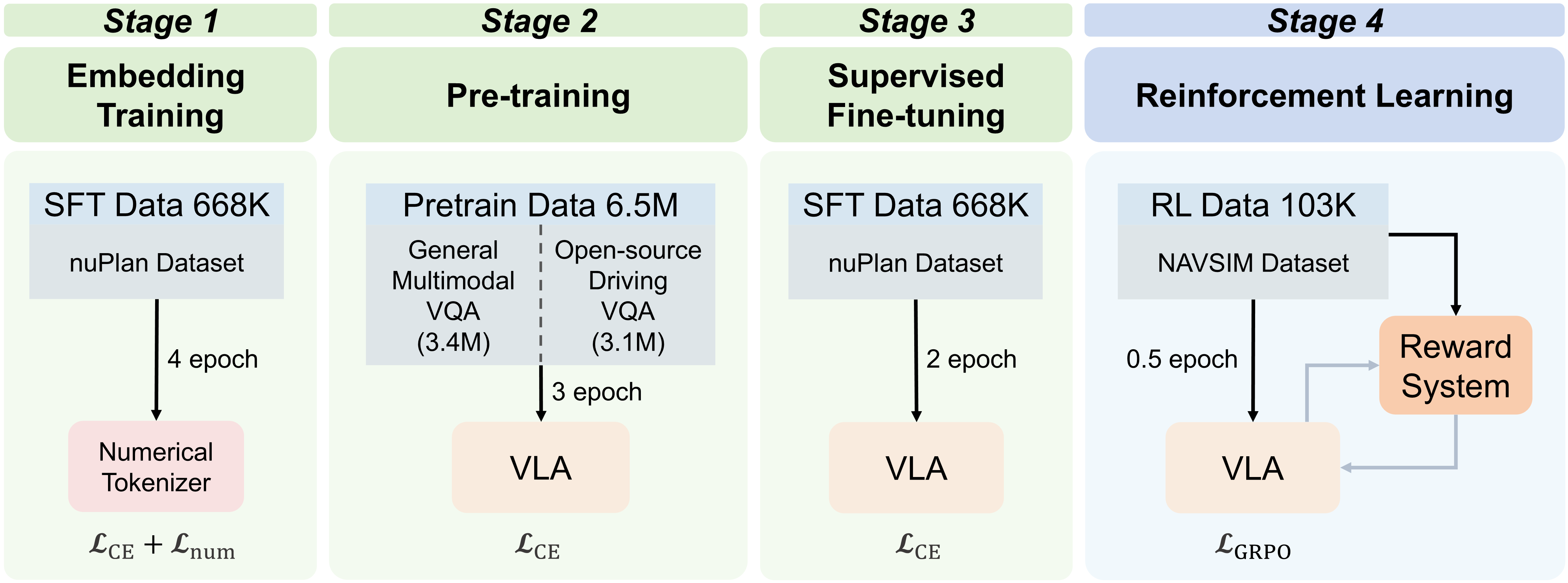
However, a straightforward application of discrete flow matching to VLA model for end-to-end autonomous driving is nontrivial for three reasons. First, training discrete flow matching from scratch is prohibitively data-and compute-intensive, so they are typically initialized from general-purpose autoregressive multimodal VLMs that lack sufficient road-scene competence-from low-level perception and motion forecasting to high-level planning and decision making. We therefore adopt a multi-stage adaptation strategy: starting from a generic VLM backbone (Janus-1.5B [51]), we continued conduct pretraining on large-scale road-scene visual question answering (VQA) to strengthen the ability to understand various complex road scenes and vehicle driving patterns, establishing a strong domain prior comparable to autoregressive VLA baselines. Second, standard text token embeddings are ill-suited to high-precision numerical regression because they weakly encode metric relationships. We introduce a metric-aligned numerical tokenizer that discretizes continuous scalars into a shared codebook and learns embeddings with a triplet-margin ranking objective so that latent distances reflect underlying scalar differences. This structured token space enables stable coarse-to-fine and slow-fast trajectory refinement within discrete flow matching, providing a controllable compute-accuracy trade-off. Finally, supervised likelihood-based flow training aligns the model with expert trajectories but does not explicitly enforce safety, egoprogress, and comfort in closed-loop control. We incorporate a Group Relative Policy Optimization (GRPO) based alignment objective with a composite reward that integrates safety penalties and performance goals, improving the safety-progress-comfort profile while preserving the model’s parallel generation capabilities.
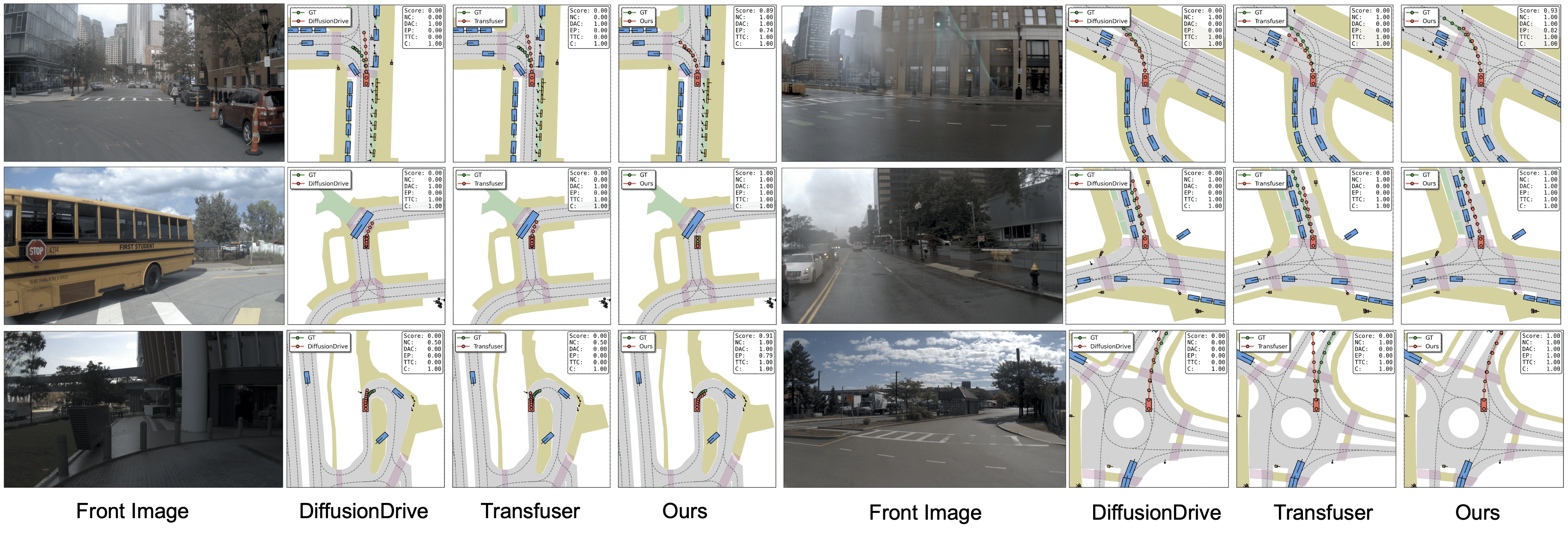
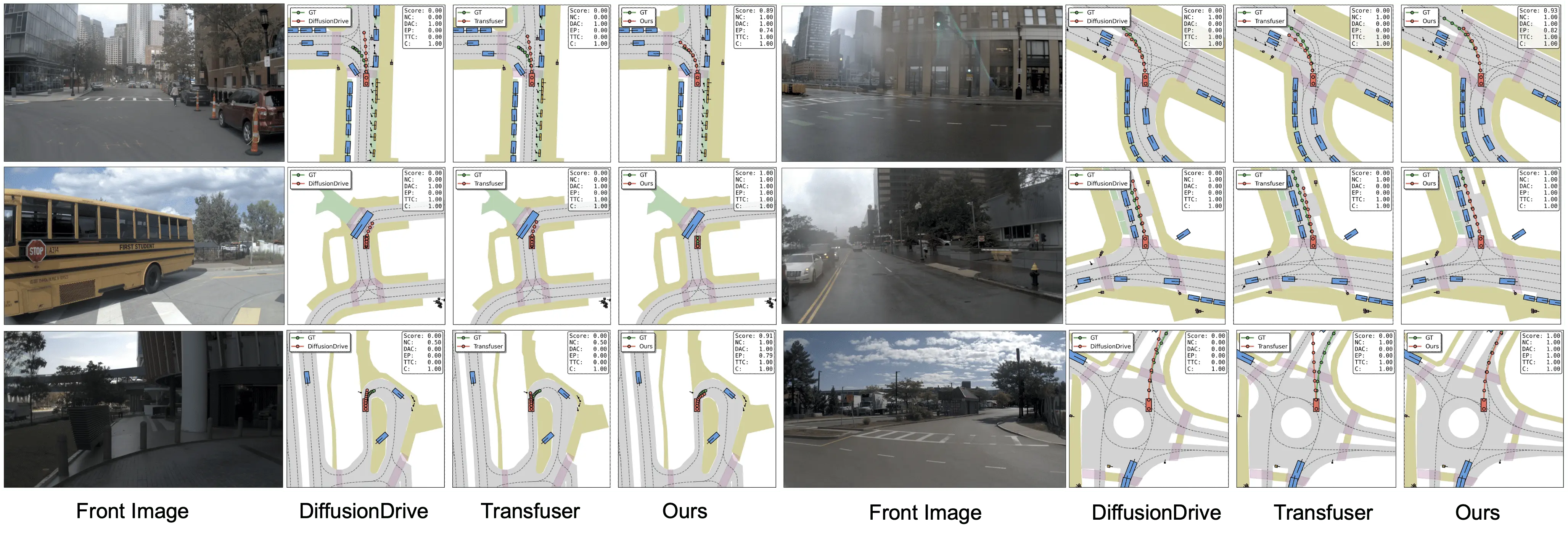
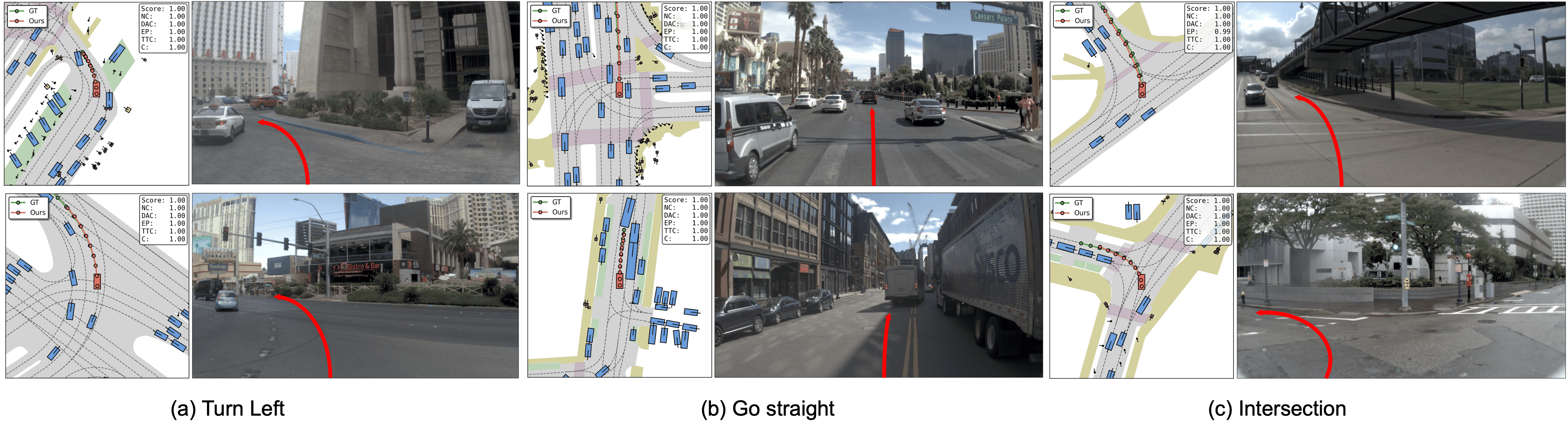
Experimental results on the NAVSIM v1 and v2 benchmarks demonstrate that WAM-Flow achieves superior performance in PDMS and EPDMS metrics compared to both autoregressive and diffus
…(Full text truncated)…
This content is AI-processed based on ArXiv data.