Relevance judgments are central to the evaluation of Information Retrieval (IR) systems, but obtaining them from human annotators is costly and time-consuming. Large Language Models (LLMs) have recently been proposed as automated assessors, showing promising alignment with human annotations. Most prior studies have treated documents as fixed units, feeding their full content directly to LLM assessors. We investigate how text summarization affects the reliability of LLM-based judgments and their downstream impact on IR evaluation. Using state-of-the-art LLMs across multiple TREC collections, we compare judgments made from full documents with those based on LLMgenerated summaries of different lengths. We examine their agreement with human labels, their effect on retrieval effectiveness evaluation, and their influence on IR systems' ranking stability. Our findings show that summary-based judgments achieve comparable stability in systems' ranking to full-document judgments, while introducing systematic shifts in label distributions and biases that vary by model and dataset. These results highlight summarization as both an opportunity for more efficient large-scale IR evaluation and a methodological choice with important implications for the reliability of automatic judgments.
Deep Dive into The Effect of Document Summarization on LLM-Based Relevance Judgments.
Relevance judgments are central to the evaluation of Information Retrieval (IR) systems, but obtaining them from human annotators is costly and time-consuming. Large Language Models (LLMs) have recently been proposed as automated assessors, showing promising alignment with human annotations. Most prior studies have treated documents as fixed units, feeding their full content directly to LLM assessors. We investigate how text summarization affects the reliability of LLM-based judgments and their downstream impact on IR evaluation. Using state-of-the-art LLMs across multiple TREC collections, we compare judgments made from full documents with those based on LLMgenerated summaries of different lengths. We examine their agreement with human labels, their effect on retrieval effectiveness evaluation, and their influence on IR systems’ ranking stability. Our findings show that summary-based judgments achieve comparable stability in systems’ ranking to full-document judgments, while introduci
Evaluation in Information Retrieval (IR) fundamentally relies on relevance judgments, the decisions made by human assessors regarding to what extent a document satisfies an information need. These judgments form the basis for evaluating and ranking search systems [39,40]. However, collecting them at scale is both costly and time-consuming. For instance, a typical TREC track demands a team of six trained assessors working full-time for several weeks [48]. Recent advances in Large Language Models (LLMs) offer a potential alternative to manual judging by generating relevance labels at scale [19,20,29,61]. Compared to human assessors, including crowd workers, LLMs reduce costs and turnaround time while hopefully maintaining sufficient alignment with human labels to preserve system comparisons [5,51]. Empirical studies further suggest that LLM-based judgments are less affected by context switching and often produce more consistent outcomes [21].
At the same time, the form of evidence presented to the assessor plays a crucial role. Full-document judgments provide rich context but demand significant resources, making summarization an attractive alternative. Summarization is one of the core abilities of modern LLMs [7,34,36,44], and initial studies suggest that summary-based evidence can provide little loss in accuracy compared to full documents [45]. However, summaries also represent a form of semantic compression that comes with a risk of bias or distorted evaluation outcomes [3,42,56,60]. In IR, prior work on LLM assessors has concentrated mainly on full-document judgments [5,19,51], and existing summarization evaluation frameworks do not address how summarized evidence affects LLM-based relevance judgments.
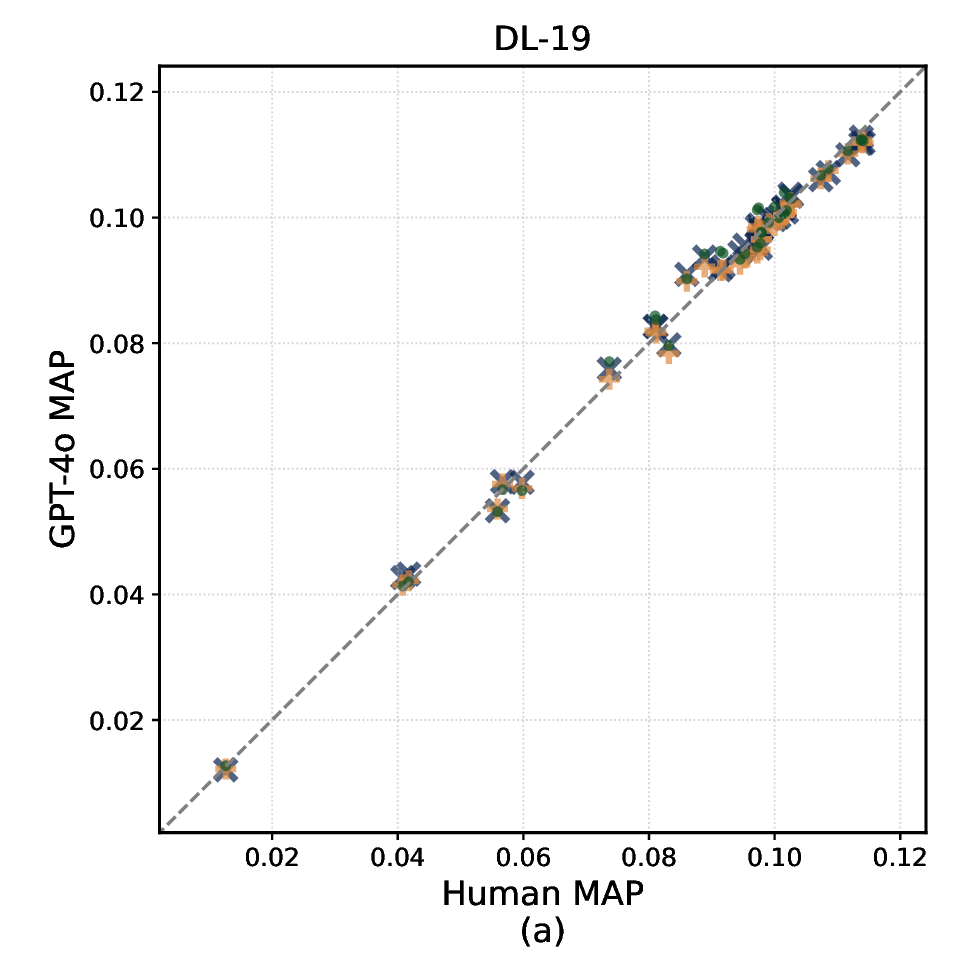
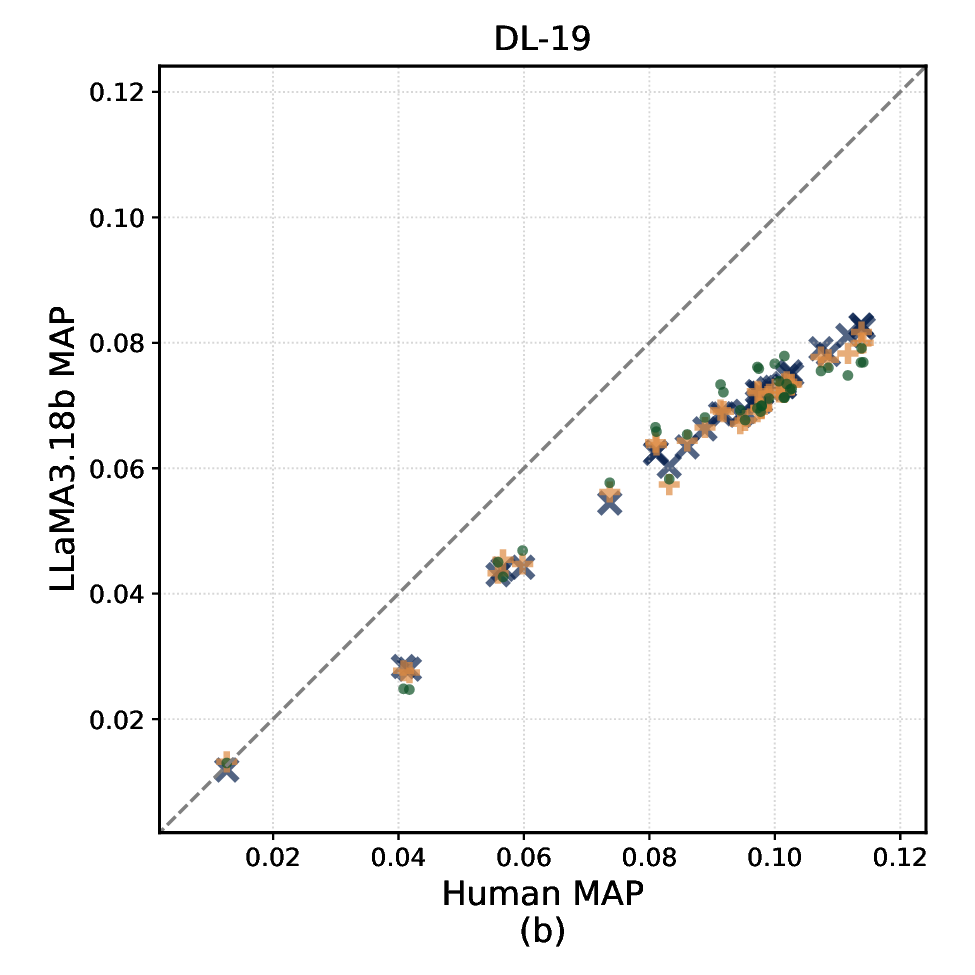
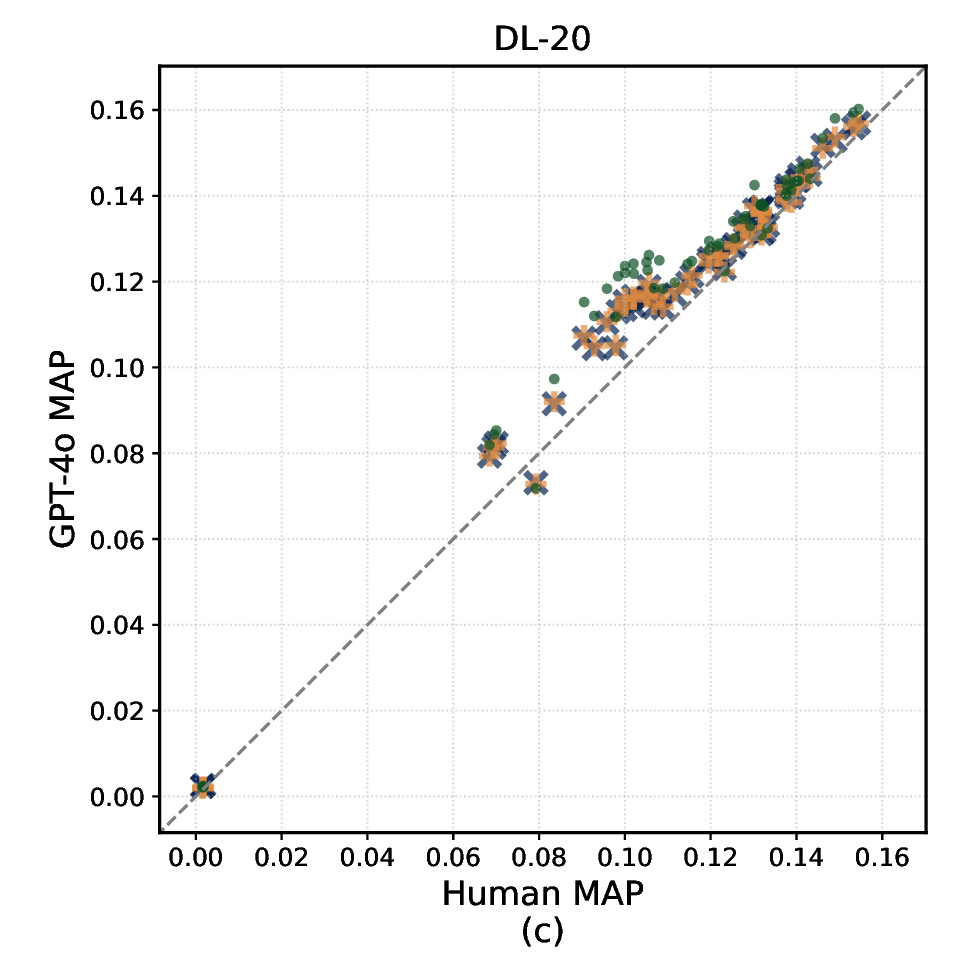
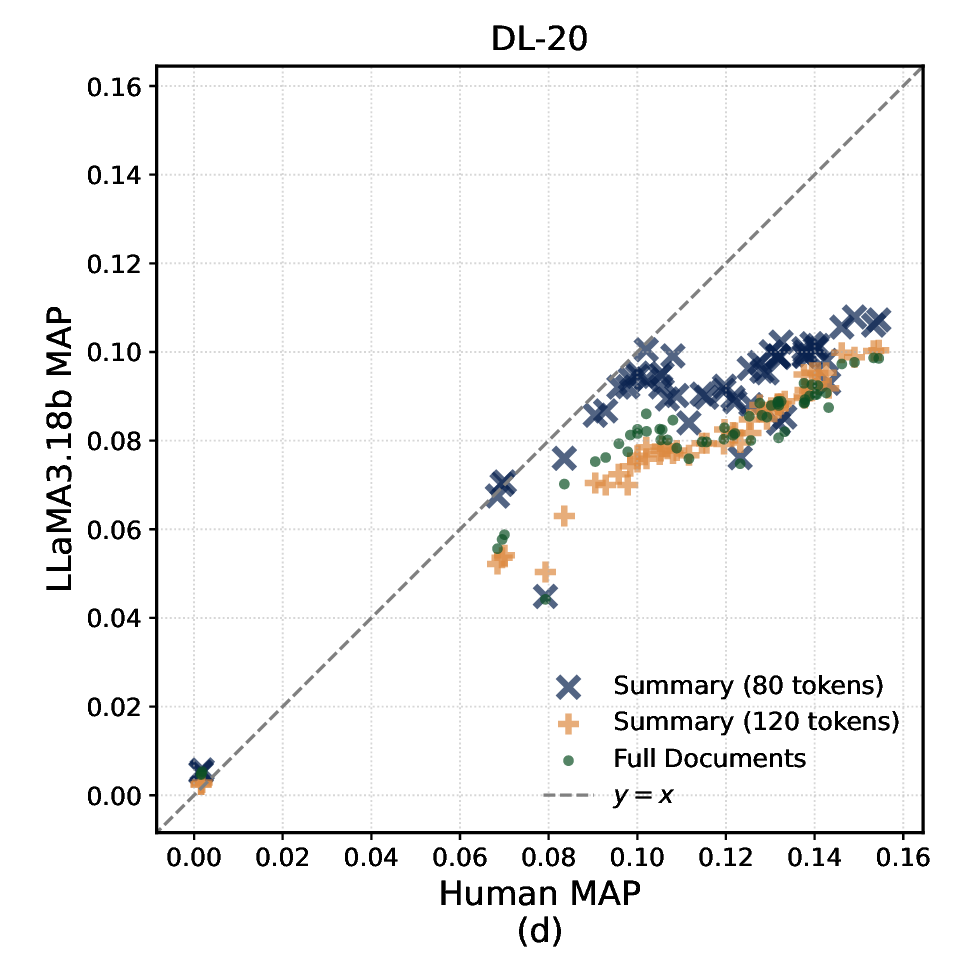
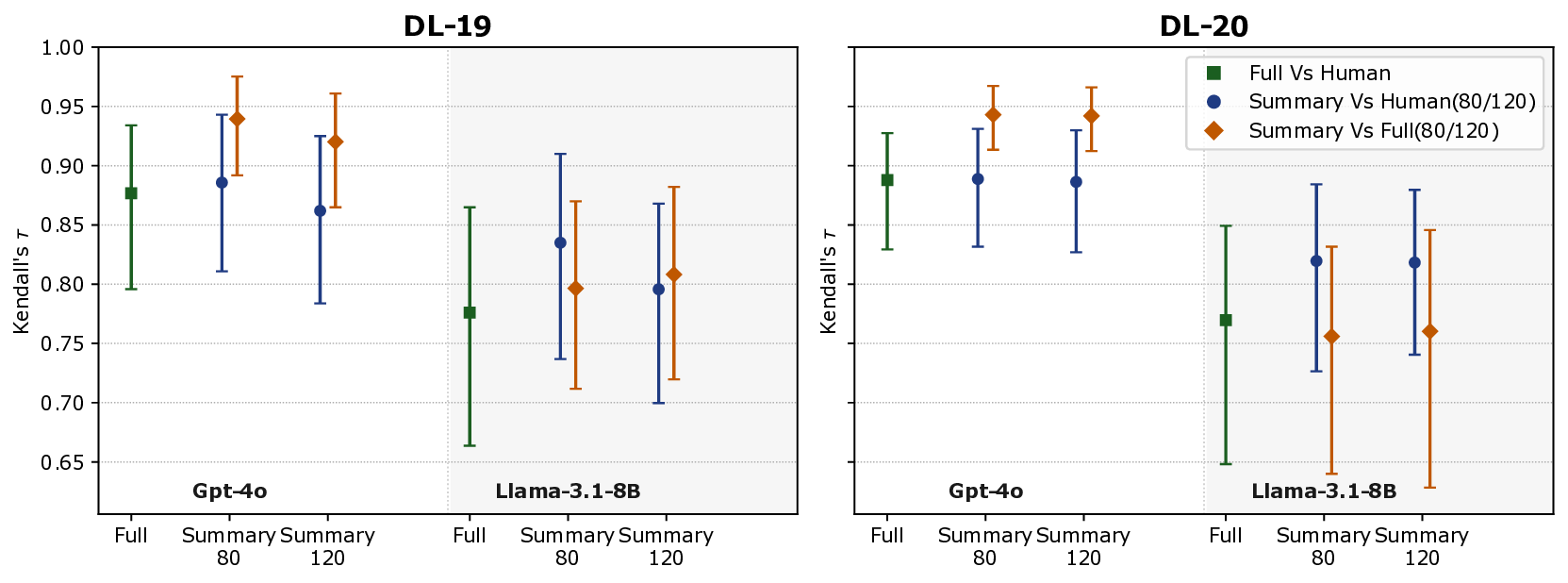
In this paper, we present the first systematic study comparing summarybased and full-document LLM relevance judgments across three popular TREC datasets. We analyze how judgments under these two modalities differ in their agreement with human labels, their impact on system effectiveness evaluation, and on systems’ ranking stability (i.e., how systems are ranked on the basis of their effectiveness). We also examine the reliability of different summary lengths and associated costs. Specifically, we address the following research questions: RQ1 How do relevance judgments from LLMs and humans compare in label distribution and agreement under full-document vs summary modalities? RQ2 How do summary-based relevance judgments affect system effectiveness evaluation and the stability of effectiveness-based systems ranking? RQ3 How do different levels of semantic compression (i.e., summary lengths) affect the reliability and consistency of LLM-based relevance judgments?
Test-collection-based evaluation has underpinned IR since the Cranfield experiments, where documents, topics, and human relevance judgments (qrels) enable reproducible system comparison [11]. While early studies showed that assessor disagreement is common, system rankings are generally robust to such variability [54,55,62]. Later work examined assessor effects, pooling bias, and the robustness of evaluation metrics under incomplete judgments, reinforcing both the strengths and limitations of human-based evaluation [8,9,46,57]. These studies established the foundations of IR evaluation practice, with human relevance judgments serving as the reference standard against which automated approaches must be validated.
Recent research has investigated LLMs as automated relevance assessors, with the potential to supplement or even replace human judges. Surveys of the emerging LLM-as-a-judge paradigm provide systematic analyses of its functionality, methodology, applications, and limitations [19,30]. Empirical IR studies have shown that LLM judgments often align closely with human labels and largely preserve system comparisons, both under full-document evidence and in TREC-style or commercial retrieval settings [5,19,20,51,52]. Large-scale experiments show that LLM assessors scale efficiently and are often more self-consistent than human annotators [2,21]. The LLMJudge challenge (SIGIR 2024) extended this line of work by releasing LLM-based relabelings of TREC Deep Learning judgments to study assessor bias, prompt sensitivity, and model selection effects [43]. At the same time, several works caution against over-reliance on LLM assessors. Clarke and Dietz [10] and Dietz et al. [16] argue that LLM judgments risk bias and lack transparency, while Soboroff [47] emphasizes the need for careful methodology to avoid misleading outcomes. These critiques suggest that LLM reliability depends heavily on prompt design, dataset context, and evaluation protocols, yet nearly all prior work assumes full-document evidence, leaving open whether judgments remain robust under summarization.
In parallel, summarization research has developed evaluation frameworks that emphasize dimensions such as faithfulness, completeness, and conciseness [49]. Benchmarks such as SummEval and G
…(Full text truncated)…
This content is AI-processed based on ArXiv data.