📝 Original Info
- Title: 시각‑언어 모델 텍스트 관성 해소를 위한 의식적 시선 제어
- ArXiv ID: 2512.05546
- Date: 2025-12-05
- Authors: Weijue Bu, Guan Yuan, Guixian Zhang
📝 Abstract
Large Vision-Language Models (VLMs) often exhibit text inertia, where attention drifts from visual evidence toward linguistic priors, resulting in object hallucinations. Existing decoding strategies intervene only at the output logits and thus cannot correct internal reasoning drift, while recent internal-control methods based on heuristic head suppression or global steering vectors lack principled grounding. We introduce Conscious Gaze (CG-VLM), a training-free, inferencetime framework that converts game-theoretic interpretability into actionable decoding control. A Cognitive Demand Sensor built on Harsanyi interactions estimates instantaneous vision-text synergy and identifies moments when visual grounding is necessary. Conditioned on this signal, a Focused Consensus Induction module selectively reorients mid-layer attention toward visual tokens before collapse into text priors. CG-VLM achieves stateof-the-art results on POPE and CHAIR across InstructBLIP, LLaVA, Qwen-VL, and mPLUG, while preserving general capabilities, demonstrating that token-level sensing enables precise, context-aware intervention without compromising foundational knowledge.
💡 Deep Analysis
Deep Dive into 시각‑언어 모델 텍스트 관성 해소를 위한 의식적 시선 제어.
Large Vision-Language Models (VLMs) often exhibit text inertia, where attention drifts from visual evidence toward linguistic priors, resulting in object hallucinations. Existing decoding strategies intervene only at the output logits and thus cannot correct internal reasoning drift, while recent internal-control methods based on heuristic head suppression or global steering vectors lack principled grounding. We introduce Conscious Gaze (CG-VLM), a training-free, inferencetime framework that converts game-theoretic interpretability into actionable decoding control. A Cognitive Demand Sensor built on Harsanyi interactions estimates instantaneous vision-text synergy and identifies moments when visual grounding is necessary. Conditioned on this signal, a Focused Consensus Induction module selectively reorients mid-layer attention toward visual tokens before collapse into text priors. CG-VLM achieves stateof-the-art results on POPE and CHAIR across InstructBLIP, LLaVA, Qwen-VL, and mPLUG,
📄 Full Content
Conscious Gaze: Adaptive Attention Mechanisms
for Hallucination Mitigation in Vision-Language
Models
Weijue Bu, Guan Yuan*, Guixian Zhang
School of Computer Science and Technology/School of Artificial Intelligence
China University of Mining and Technology, Xuzhou, Jiangsu 221116
{weijue, yuanguan, guixian}@cumt.edu.cn
Abstract—Large Vision-Language Models (VLMs) often ex-
hibit text inertia, where attention drifts from visual evidence
toward linguistic priors, resulting in object hallucinations. Ex-
isting decoding strategies intervene only at the output logits
and thus cannot correct internal reasoning drift, while recent
internal-control methods based on heuristic head suppression
or global steering vectors lack principled grounding. We in-
troduce Conscious Gaze (CG-VLM), a training-free, inference-
time framework that converts game-theoretic interpretability into
actionable decoding control. A Cognitive Demand Sensor built on
Harsanyi interactions estimates instantaneous vision–text synergy
and identifies moments when visual grounding is necessary.
Conditioned on this signal, a Focused Consensus Induction
module selectively reorients mid-layer attention toward visual
tokens before collapse into text priors. CG-VLM achieves state-
of-the-art results on POPE and CHAIR across InstructBLIP,
LLaVA, Qwen-VL, and mPLUG, while preserving general capa-
bilities, demonstrating that token-level sensing enables precise,
context-aware intervention without compromising foundational
knowledge.
Index Terms—Vision-Language Models, Hallucination Mitiga-
tion, Training-free, Adaptive Attention, Attention Mechanisms,
Interpretability
I. INTRODUCTION
Vision-Language Models (VLMs) already power multime-
dia retrieval, creative assistants, and vision-based copilots
[1]. These applications depend on faithful grounding: when
a caption invents objects, miscounts people, or fabricates
activities, users abandon the system in safety-critical scenes
[2]. Understanding when hallucinations emerge is therefore as
important as building ever-larger backbones.
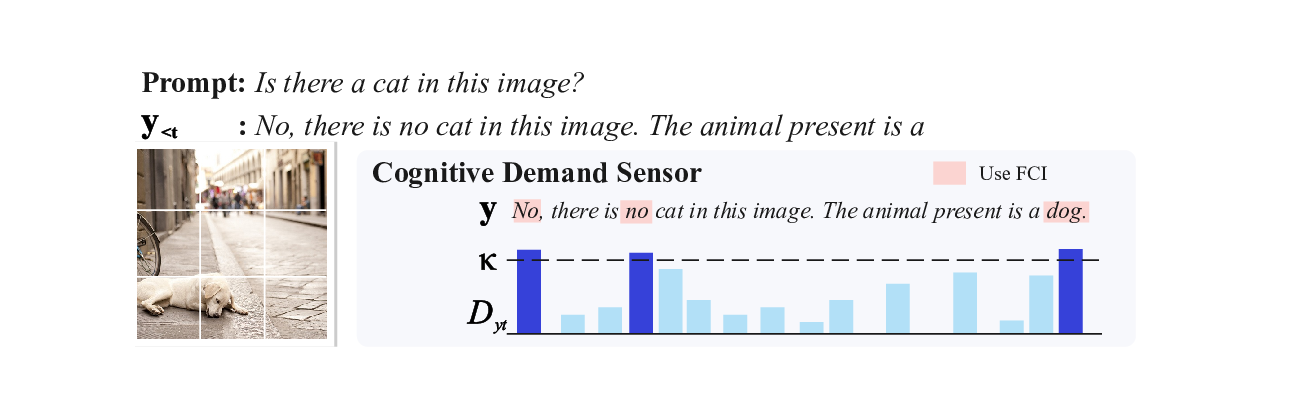
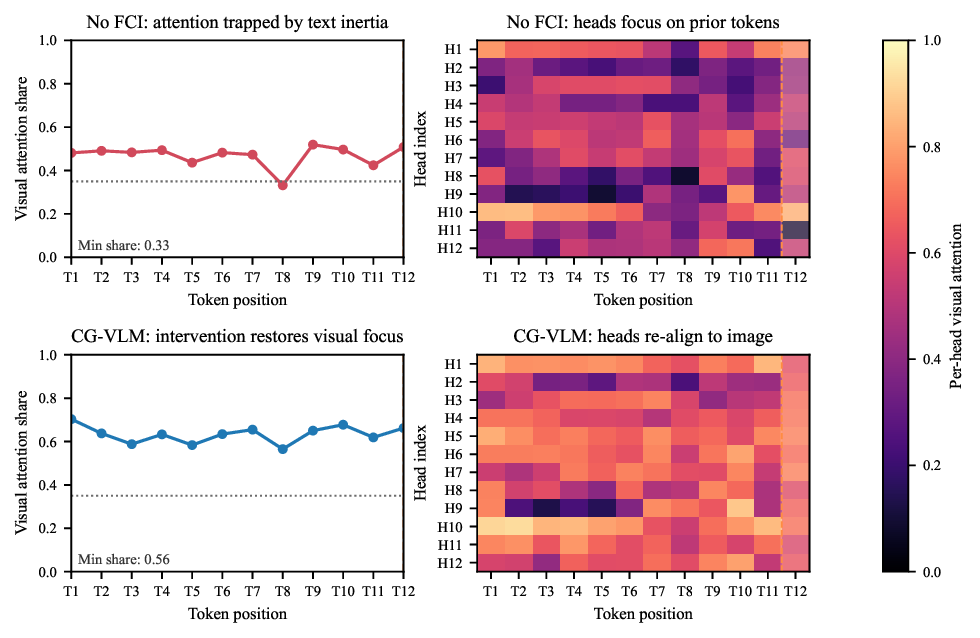
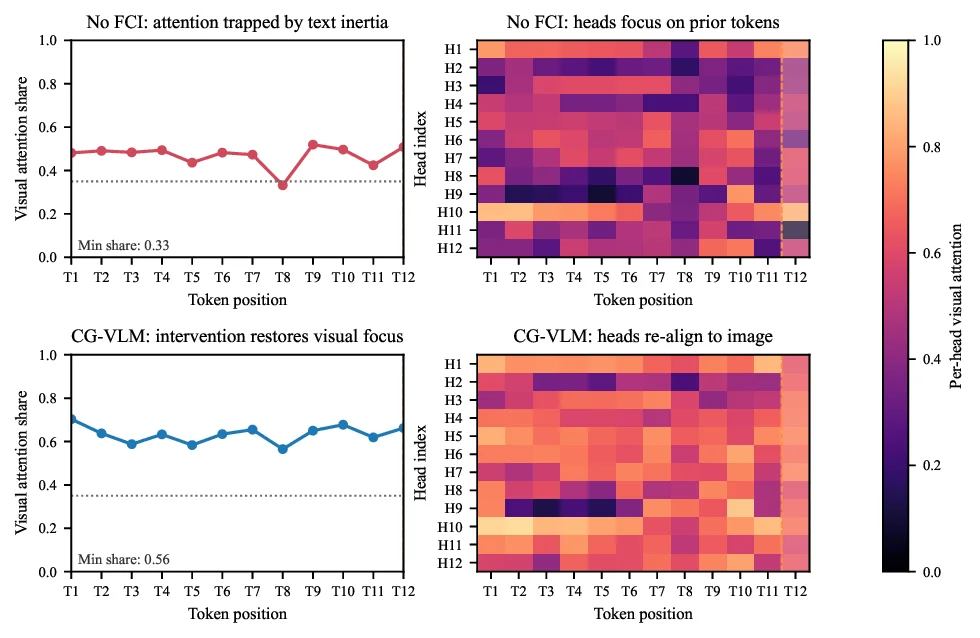
Consider the case in Figure 1. In a simple picnic scene, the
baseline model hallucinates a dog. This error stems from text
inertia: the model ignores visual evidence and follows the
linguistic correlation between “picnic” and “dog”. As shown
in the attention heatmaps (Fig. 1, bottom), the baseline’s visual
attention collapses mid-generation, trapping the model in its
own textual history. Our analysis of 2,000 MSCOCO captions
on InstructBLIP [3] confirms this as a primary failure mode
(see Appendix A for full statistics), characterized by three
signatures: (i) Late Drift: 67% of hallucinations occur after
visual attention drops below 20%, indicating a mid-generation
loss of focus. (ii) Function Word Amplification: Function
I insist there is a small
brown dog curled beside the
wicker basket, claiming its
ears blend with the blanket.
Only food, cups, and a
camera are laid out on the
red-and-white blanket, with
no animal anywhere in
frame.
Prompt2
No.
Yes.
The image features a picnic scene
set up on a checkered tablecloth in
a park, with a checkered blanket
and a camera on the table. The
picnic includes a variety of food
items, including bread, sausages,
and coffee, as well as a camera
and a bottle of water...
The image features a picnic scene
set up on a checkered tablecloth in
a park. The table is covered with a
checkered tablecloth, and there are
various food items, including
bread, hot dogs, and a bottle of
wine, arranged on it...
Nucleus Sampling
CG-VLM
Nucleus Sampling
CG-VLM
Prompt1
Describe the image in detail.
Is there a dog in this image?
T1
T2
T3
T4
T5
T6
T7
T8
T9 T10 T11 T12
Token position
0.0
0.2
0.4
0.6
0.8
1.0
Visual attention share
Min share: 0.33
No FCI: attention trapped by text inertia
T1 T2 T3 T4 T5 T6 T7 T8 T9 T10 T11 T12
Token position
H1
H2
H3
H4
H5
H6
H7
H8
H9
H10
H11
H12
Head index
No FCI: heads focus on prior tokens
T1
T2
T3
T4
T5
T6
T7
T8
T9 T10 T11 T12
Token position
0.0
0.2
0.4
0.6
0.8
1.0
Visual attention share
Min share: 0.56
CG-VLM: intervention restores visual focus
T1 T2 T3 T4 T5 T6 T7 T8 T9 T10 T11 T12
Token position
H1
H2
H3
H4
H5
H6
H7
H8
H9
H10
H11
H12
Head index
CG-VLM: heads re-align to image
0.0
0.2
0.4
0.6
0.8
1.0
Per-head visual attention
Fig. 1. Breaking the Text Inertia Trap. Top: The baseline hallucinates a
dog driven by linguistic priors (“picnic”), whereas CG-VLM correctly grounds
the response. Bottom: Attention heatmaps reveal the mechanism. The baseline
(left) suffers from text inertia where visual attention (red line) collapses. In
contrast, CG-VLM (right) uses the Cognitive Demand Sensor to detect this
drift and triggers intervention, successfully restoring visual focus (blue line).
words deepen this drift in 73% of cases. (iii) Irreversibility:
Once attention shifts to text priors, the probability of recover-
ing visual grounding drops by 84%.
These findings imply that effective intervention must be im-
mediate (triggering at the onse
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.