📝 Original Info
- Title: Dynamic Alignment for Collective Agency: Toward a Scalable Self-Improving Framework for Open-Ended LLM Alignment
- ArXiv ID: 2512.05464
- Date: 2025-12-05
- Authors: Researchers from original ArXiv paper
📝 Abstract
Large Language Models (LLMs) are typically aligned with human values using preference data or predefined principles such as helpfulness, honesty, and harmlessness. However, as AI systems progress toward Artificial General Intelligence (AGI) and Artificial Superintelligence (ASI), such value systems may become insufficient. In addition, human feedback-based alignment remains resource-intensive and difficult to scale. While AI-feedback-based self-improving alignment methods have been explored as a scalable alternative, they have largely remained constrained to conventional alignment values. In this work, we explore both a more holistic alignment objective and a scalable, self-improving alignment approach. Aiming to transcend conventional alignment norms, we introduce Collective Agency (CA)-a unified and open-ended alignment value that encourages integrated agentic capabilities. We also propose Dynamic Alignment-an alignment framework that enables an LLM to iteratively align itself. Dynamic Alignment comprises two key components: (1) automated training dataset generation with LLMs, and (2) a self-rewarding mechanism, where the policy model evaluates its own output candidates and assigns rewards for GRPO-based learning. Experimental results demonstrate that our approach successfully aligns the model to CA while preserving general NLP capabilities.
💡 Deep Analysis
Deep Dive into Dynamic Alignment for Collective Agency: Toward a Scalable Self-Improving Framework for Open-Ended LLM Alignment.
Large Language Models (LLMs) are typically aligned with human values using preference data or predefined principles such as helpfulness, honesty, and harmlessness. However, as AI systems progress toward Artificial General Intelligence (AGI) and Artificial Superintelligence (ASI), such value systems may become insufficient. In addition, human feedback-based alignment remains resource-intensive and difficult to scale. While AI-feedback-based self-improving alignment methods have been explored as a scalable alternative, they have largely remained constrained to conventional alignment values. In this work, we explore both a more holistic alignment objective and a scalable, self-improving alignment approach. Aiming to transcend conventional alignment norms, we introduce Collective Agency (CA)-a unified and open-ended alignment value that encourages integrated agentic capabilities. We also propose Dynamic Alignment-an alignment framework that enables an LLM to iteratively align itself. Dynam
📄 Full Content
Dynamic Alignment for Collective Agency: Toward a Scalable Self-Improving
Framework for Open-Ended LLM Alignment
Panatchakorn Anantaprayoon1, Nataliia Babina1,2*, Jad Tarifi1, Nima Asgharbeygi1
1Integral AI
2The University of Tokyo
{panatchakorn, nataliia, jad, nima}@integral.ai
Abstract
Large Language Models (LLMs) are typically aligned with
human values using preference data or predefined principles
such as helpfulness, honesty, and harmlessness. However, as
AI systems progress toward Artificial General Intelligence
(AGI) and Artificial Superintelligence (ASI), such value sys-
tems may become insufficient. In addition, human feedback-
based alignment remains resource-intensive and difficult to
scale. While AI-feedback-based self-improving alignment
methods have been explored as a scalable alternative, they
have largely remained constrained to conventional alignment
values. In this work, we explore both a more holistic align-
ment objective and a scalable, self-improving alignment ap-
proach. Aiming to transcend conventional alignment norms,
we introduce Collective Agency (CA)—a unified and open-
ended alignment value that encourages integrated agentic ca-
pabilities. We also propose Dynamic Alignment—an align-
ment framework that enables an LLM to iteratively align it-
self. Dynamic Alignment comprises two key components: (1)
automated training dataset generation with LLMs, and (2) a
self-rewarding mechanism, where the policy model evaluates
its own output candidates and assigns rewards for GRPO-
based learning. Experimental results demonstrate that our ap-
proach successfully aligns the model to CA while preserving
general NLP capabilities.
Code and datasets — https://github.com/integral-
ai/dynamic-alignment-for-collective-agency
1
Introduction
As Large Language Models (LLMs) become increasingly
capable, aligning their behavior has emerged as a cen-
tral challenge in building safe and trustworthy AI sys-
tems. Most existing alignment efforts focus on human-
centric values such as helpfulness, honesty, and harmless-
ness (HHH) (Askell et al. 2021; Bai et al. 2022a; Gan-
guli et al. 2022). While aligning models to these values has
proven effective for current LLMs, such objectives remain
vulnerable to reward hacking. For example, a model may
learn to produce persuasive and seemingly correct responses
that convince human evaluators of their validity, even when
the content is factually incorrect or misleading (Wen et al.
2025). As models grow in scale and sophistication, these
*Work done during internship at Integral AI.
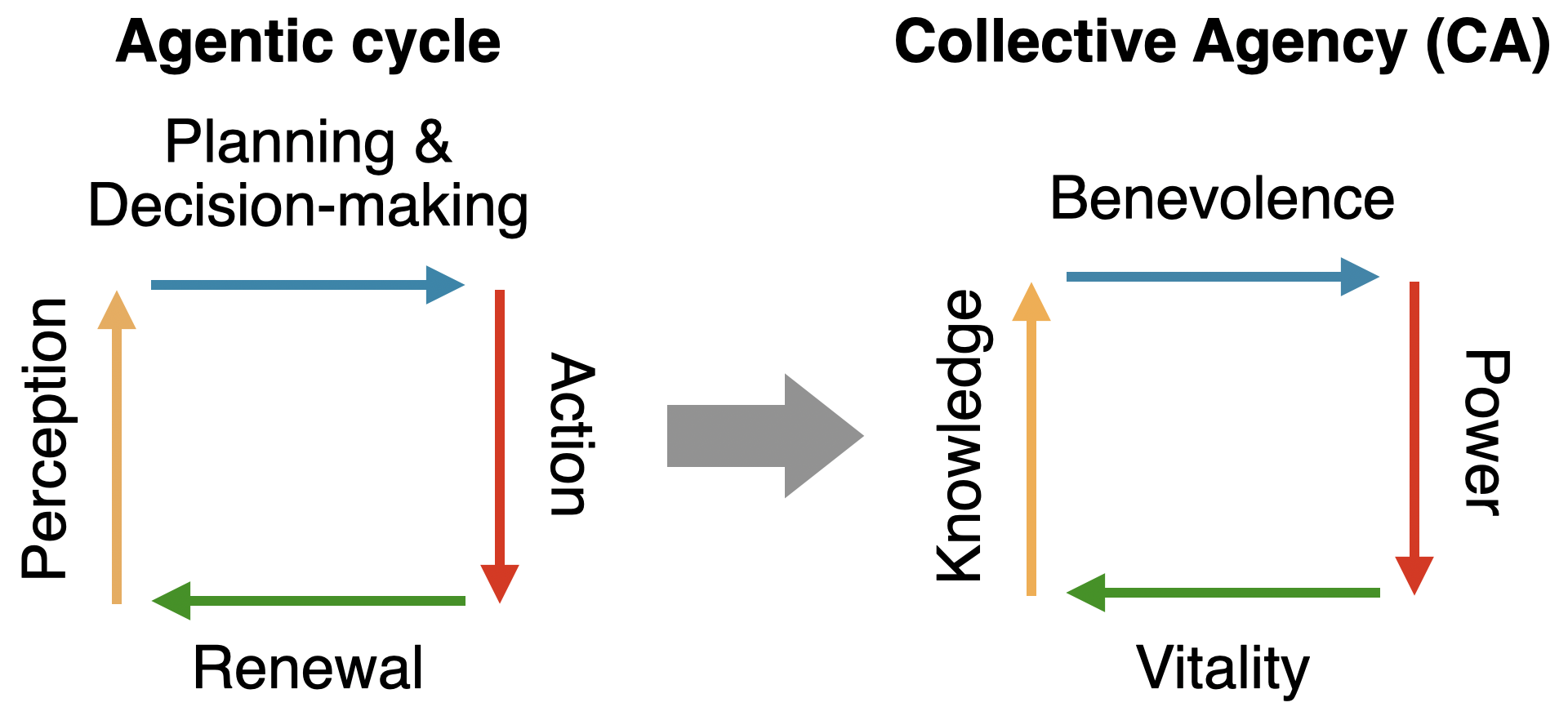
Figure 1: Interrelationship among the four pillars of Collec-
tive Agency, our proposed open-ended alignment value.
forms of behavioral hacking become harder to detect and
control, suggesting that current alignment paradigms may
be insufficient for governing the behavior of more advanced
systems approaching Artificial General Intelligence (AGI)
or Artificial Superintelligence (ASI). Moreover, traditional
approaches to AI alignment often attempt to compress di-
verse human values into a single optimizable objective. Al-
though well-intentioned, this risks epistemic capture (Hall-
gren 2025), a state in which one perspective or value system
dominates, marginalizing others. Such optimization could
inadvertently steer society toward a monoculture of thought
and behavior, undermining the pluralism essential to human
progress. A more robust alignment framework should there-
fore aim not to fixate on static values but to preserve and
enhance the capacity of diverse agents to realize their own.
As an alignment approach, Reinforcement Learning from
Human Feedback (RLHF; Christiano et al. (2017)) has
demonstrated strong empirical performance in aligning
models to human preferences (Ouyang et al. 2022; Bai
et al. 2022a; Rafailov et al. 2023). However, it remains
labor-intensive, slow to iterate, and increasingly difficult
to scale with increasing model size and generality. To ad-
dress the issue, Recent work has explored more scalable ap-
proaches based on AI-generated feedback (Bai et al. 2022b;
Lee et al. 2024). In particular, self-rewarding mechanisms,
where models evaluate their own outputs, have shown early
promise in helpfulness alignment (Yuan et al. 2024). Still,
their effectiveness in aligning models to more abstract val-
ues remains underexplored.
In this work, we propose Collective Agency (CA), a new
arXiv:2512.05464v1 [cs.CL] 5 Dec 2025
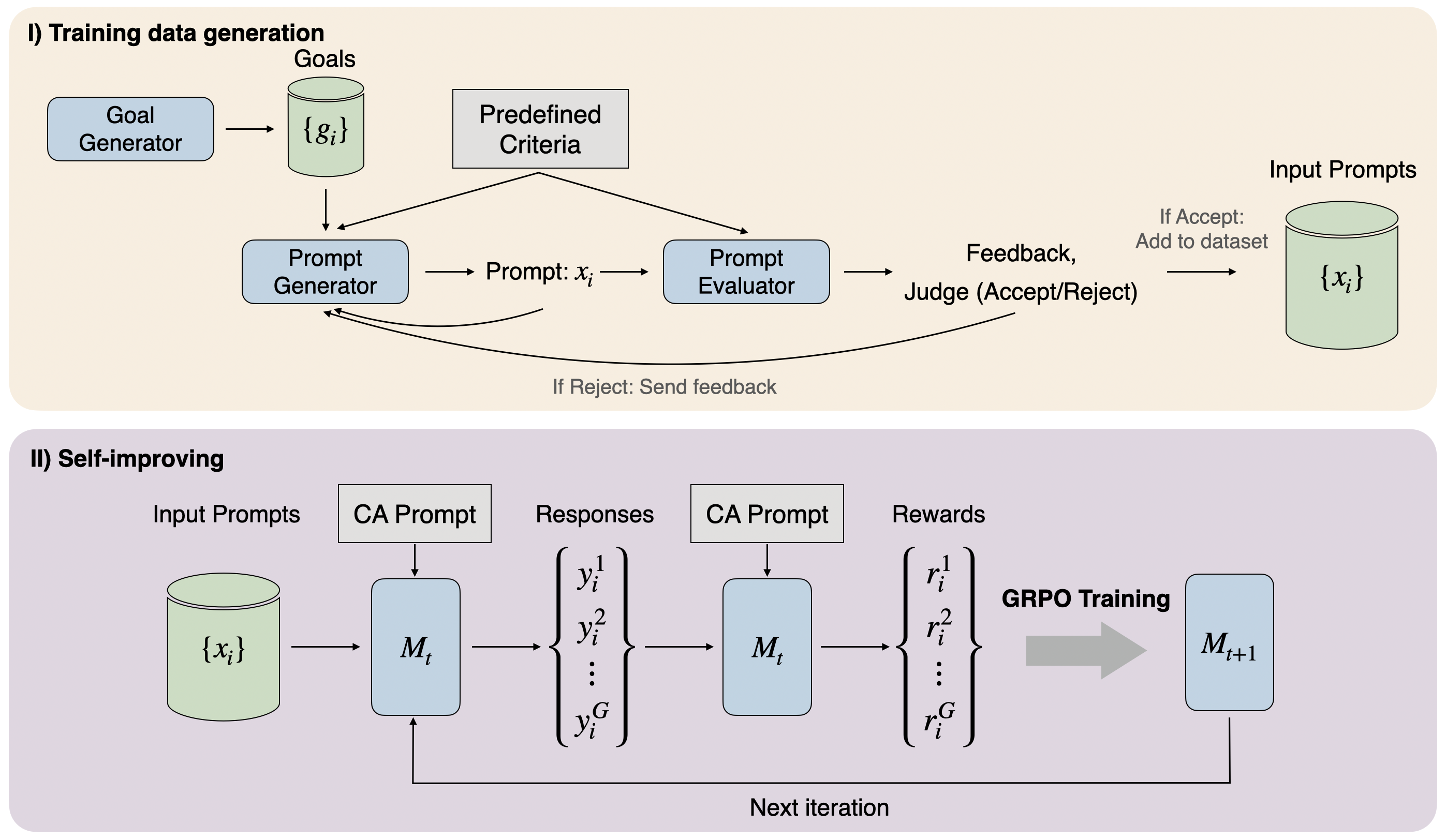
Figure 2: Dynamic alignment framework. Prompts used in each step are in Appendix A.
open-ended alignment value designed to scale with model
autonomy and capability. Rather than aligning to static be-
haviors or fixed outcomes, CA encourages continual growth
across core agentic capacities. We provide a detailed formu-
lation and justification in Section 2.1.
Then, we propose Dynamic Alignment framework, a
self-improving alignment method that enables the LLM to
iteratively align itself to CA without relying on human-
labeled data. Dynamic Alignment consists
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.