📝 Original Info
- Title: Toward Patch Robustness Certification and Detection for Deep Learning Systems Beyond Consistent Samples
- ArXiv ID: 2512.06123
- Date: 2025-12-05
- Authors: ** Qilin Zhou, Zhengyuan Wei, Haipeng Wang, Zhuo Wang, W.K. Chan **
📝 Abstract
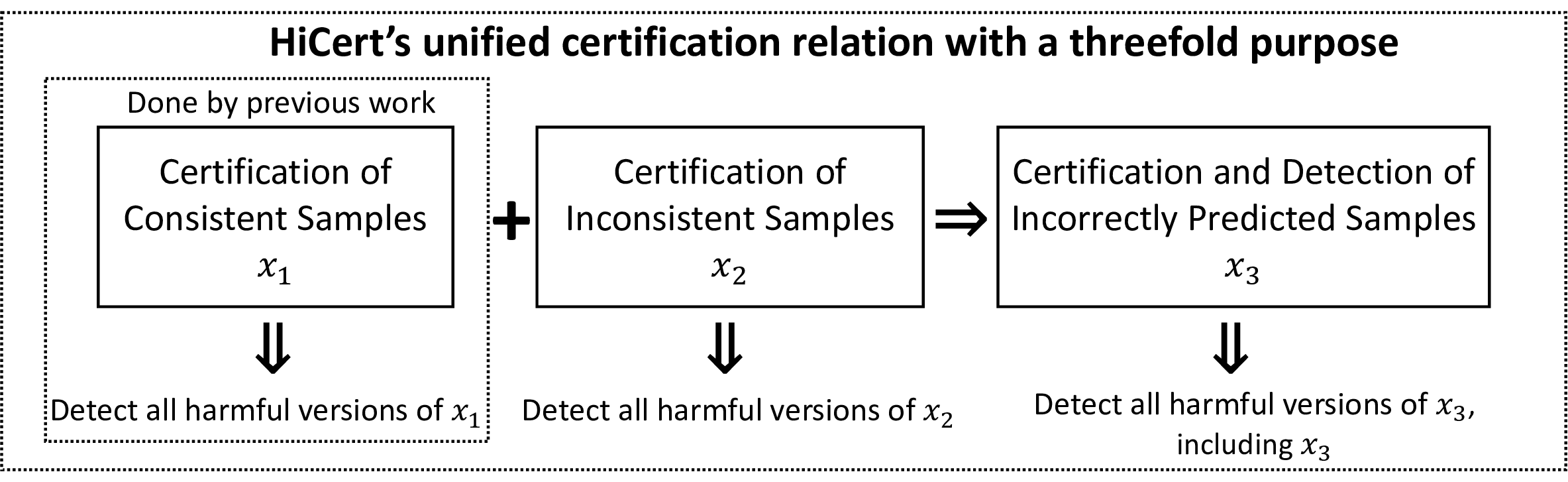
Patch robustness certification is an emerging kind of provable defense technique against adversarial patch attacks for deep learning systems. Certified detection ensures the detection of all patched harmful versions of certified samples, which mitigates the failures of empirical defense techniques that could (easily) be compromised. However, existing certified detection methods are ineffective in certifying samples that are misclassified or whose mutants are inconsistently pre icted to different labels. This paper proposes HiCert, a novel masking-based certified detection technique. By focusing on the problem of mutants predicted with a label different from the true label with our formal analysis, HiCert formulates a novel formal relation between harmful samples generated by identified loopholes and their benign counterparts. By checking the bound of the maximum confidence among these potentially harmful (i.e., inconsistent) mutants of each benign sample, HiCert ensures that each harmful sample either has the minimum confidence among mutants that are predicted the same as the harmful sample itself below this bound, or has at least one mutant predicted with a label different from the harmful sample itself, formulated after two novel insights. As such, HiCert systematically certifies those inconsistent samples and consistent samples to a large extent. To our knowledge, HiCert is the first work capable of providing such a comprehensive patch robustness certification for certified detection. Our experiments show the high effectiveness of HiCert with a new state-of the-art performance: It certifies significantly more benign samples, including those inconsistent and consistent, and achieves significantly higher accuracy on those samples without warnings and a significantly lower false silent ratio.
💡 Deep Analysis
Deep Dive into Toward Patch Robustness Certification and Detection for Deep Learning Systems Beyond Consistent Samples.
Patch robustness certification is an emerging kind of provable defense technique against adversarial patch attacks for deep learning systems. Certified detection ensures the detection of all patched harmful versions of certified samples, which mitigates the failures of empirical defense techniques that could (easily) be compromised. However, existing certified detection methods are ineffective in certifying samples that are misclassified or whose mutants are inconsistently pre icted to different labels. This paper proposes HiCert, a novel masking-based certified detection technique. By focusing on the problem of mutants predicted with a label different from the true label with our formal analysis, HiCert formulates a novel formal relation between harmful samples generated by identified loopholes and their benign counterparts. By checking the bound of the maximum confidence among these potentially harmful (i.e., inconsistent) mutants of each benign sample, HiCert ensures that each harmf
📄 Full Content
1
Technical Report: Toward Patch Robustness Certification and
Detection for Deep Learning Systems Beyond Consistent Samples
Qilin Zhou, Zhengyuan Wei, Haipeng Wang, Zhuo Wang, and W.K. Chan
Abstract—Patch robustness certification is an emerging kind of
provable defense technique against adversarial patch attacks for
deep learning systems. Certified detection ensures the detection of
all patched harmful versions of certified samples, which mitigates
the failures of empirical defense techniques that could (easily) be
compromised. However, existing certified detection methods are
ineffective in certifying samples that are misclassified or whose
mutants are inconsistently predicted to different labels. This
paper proposes HiCert, a novel masking-based certified detection
technique. By focusing on the problem of mutants predicted
with a label different from the true label with our formal
analysis, HiCert formulates a novel formal relation between
harmful samples generated by identified loopholes and their
benign counterparts. By checking the bound of the maximum
confidence among these potentially harmful (i.e., inconsistent)
mutants of each benign sample, HiCert ensures that each harmful
sample either has the minimum confidence among mutants that
are predicted the same as the harmful sample itself below
this bound, or has at least one mutant predicted with a label
different from the harmful sample itself, formulated after two
novel insights. As such, HiCert systematically certifies those
inconsistent samples and consistent samples to a large extent.
To our knowledge, HiCert is the first work capable of providing
such a comprehensive patch robustness certification for certified
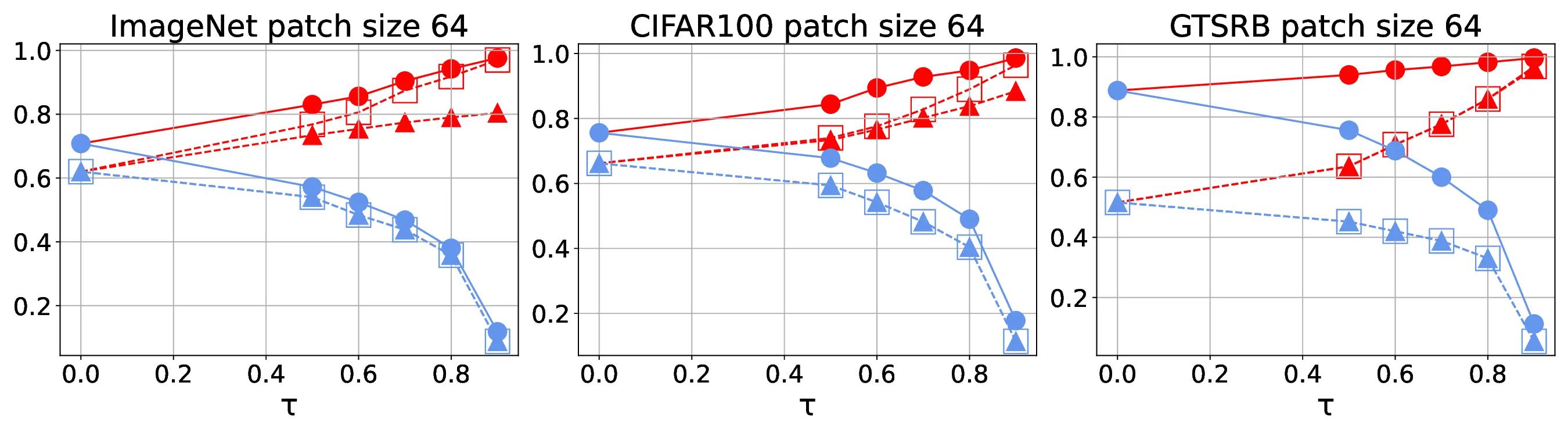
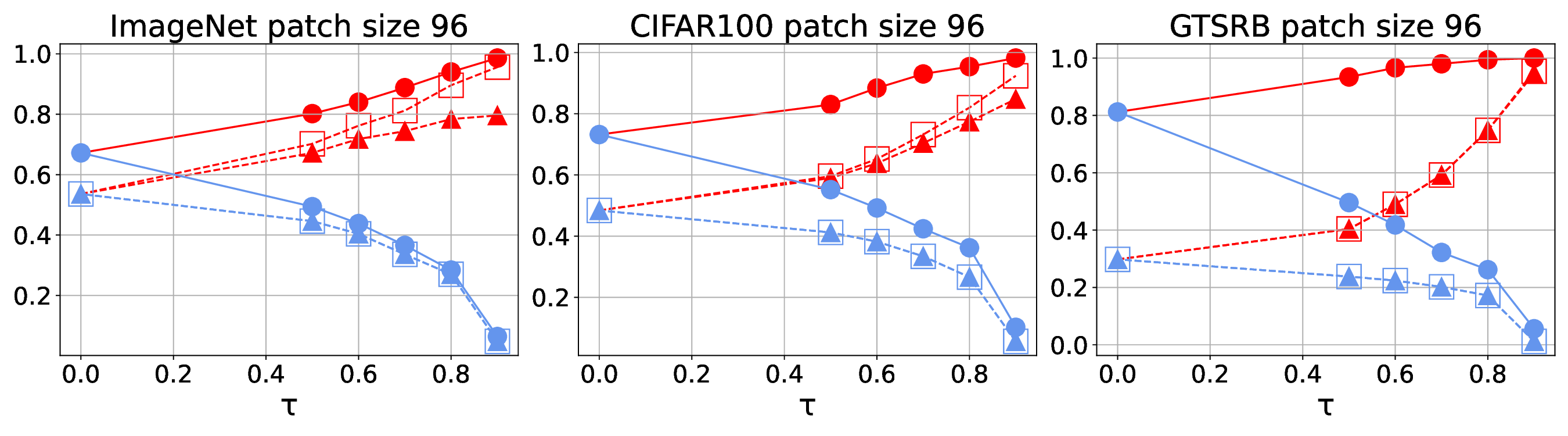
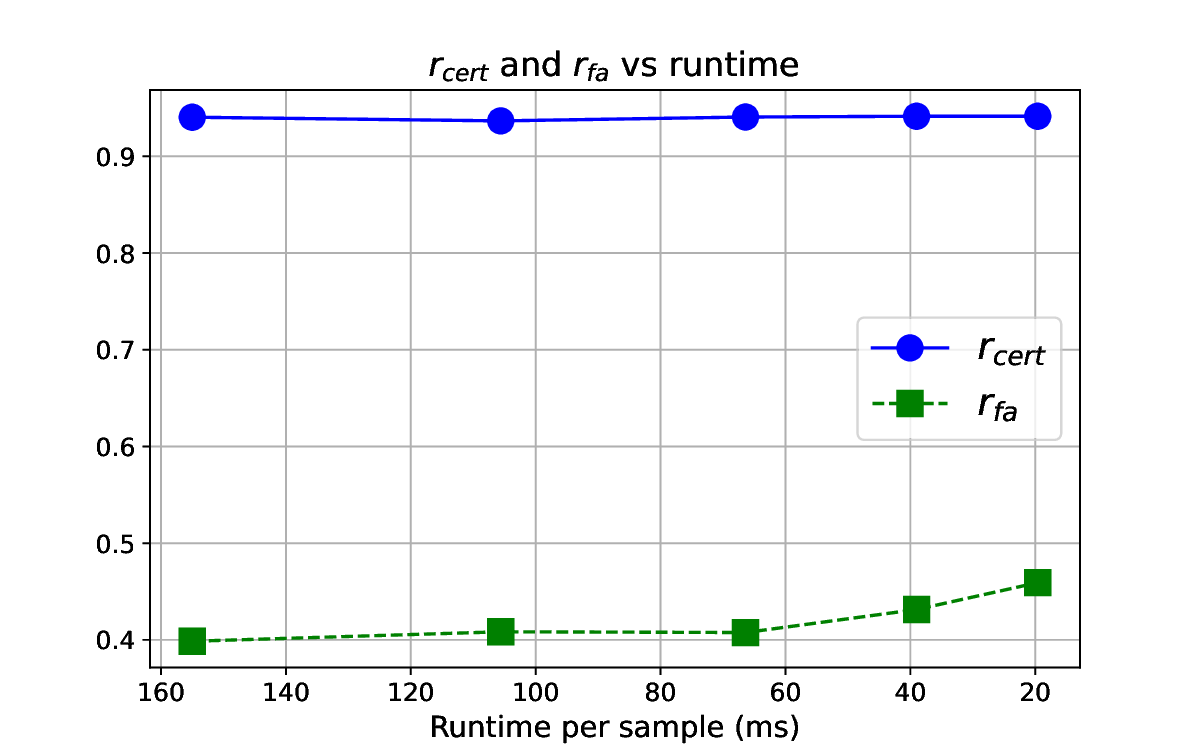
detection. Our experiments show the high effectiveness of HiCert
with a new state-of-the-art performance: It certifies significantly
more benign samples, including those inconsistent and consistent,
and achieves significantly higher accuracy on those samples
without warnings and a significantly lower false silent ratio.
Moreover, on actual patch attacks, its defense success ratio is
significantly higher than its peers.
Index
Terms—Certification,
Verification,
Detection,
Deep
Learning Model, Patch Robustness, Worst-Case Analysis, De-
terministic Guarantee
NOMENCLATURE
x: a benign sample
•
x′: x’s harmful sample
•
ˆx: an arbitrary sample
•
f: a classification model
•
v: a certification function
•
w: a warning function
•
P: a patch region
•
P: a patch region set
•
M: a mask
•
ˆxM: a mutant of ˆx for M
•
MP: a covering mask set
for P
•
MP: a mask covering the
patch region P
•
AP(x): an attack con-
straint set for x
•
D: a certified detection
defender
•
y0: the true label of a sample
•
I. INTRODUCTION
© 20XX IEEE. Personal use of this material is permitted. Permission from
IEEE must be obtained for all other uses, in any current or future media,
including reprinting/republishing this material for advertising or promotional
purposes, creating new collective works, for resale or redistribution to servers
or lists, or reuse of any copyrighted component of this work in other works.
R
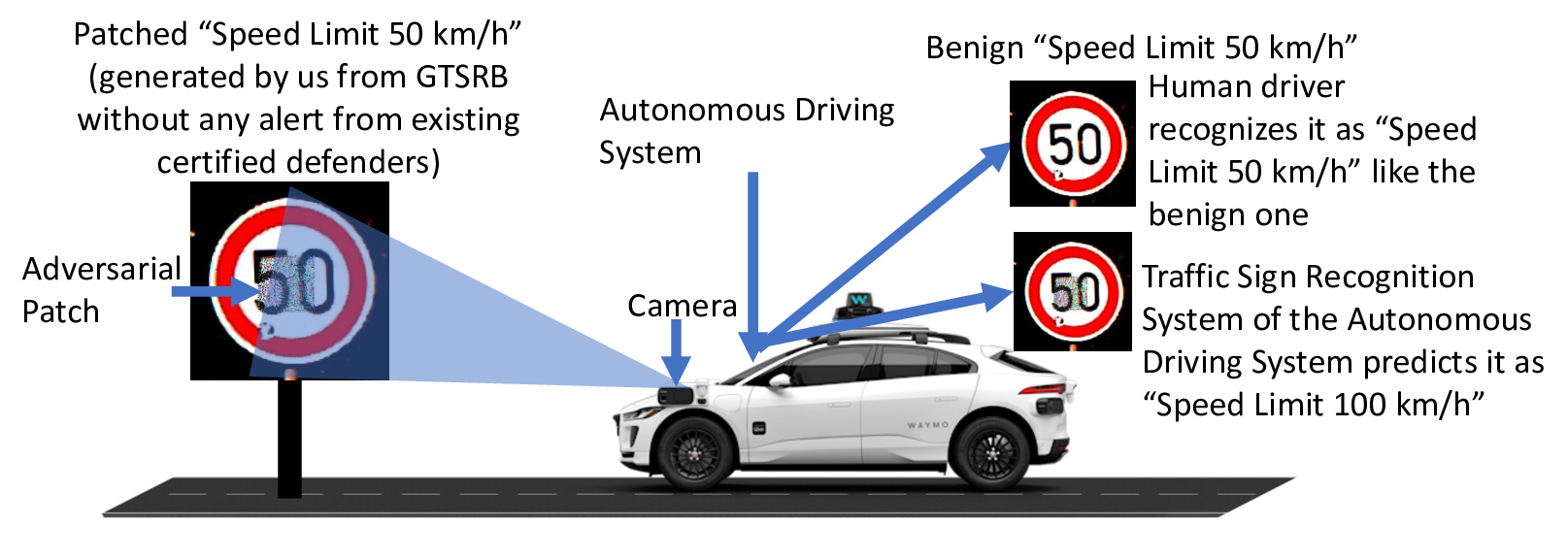
ELIABILITY of safety-critical deep learning (DL) sys-
tems, such as autonomous vehicles and robots, is threat-
ened by adversarial attacks [1]–[6], particularly those that are
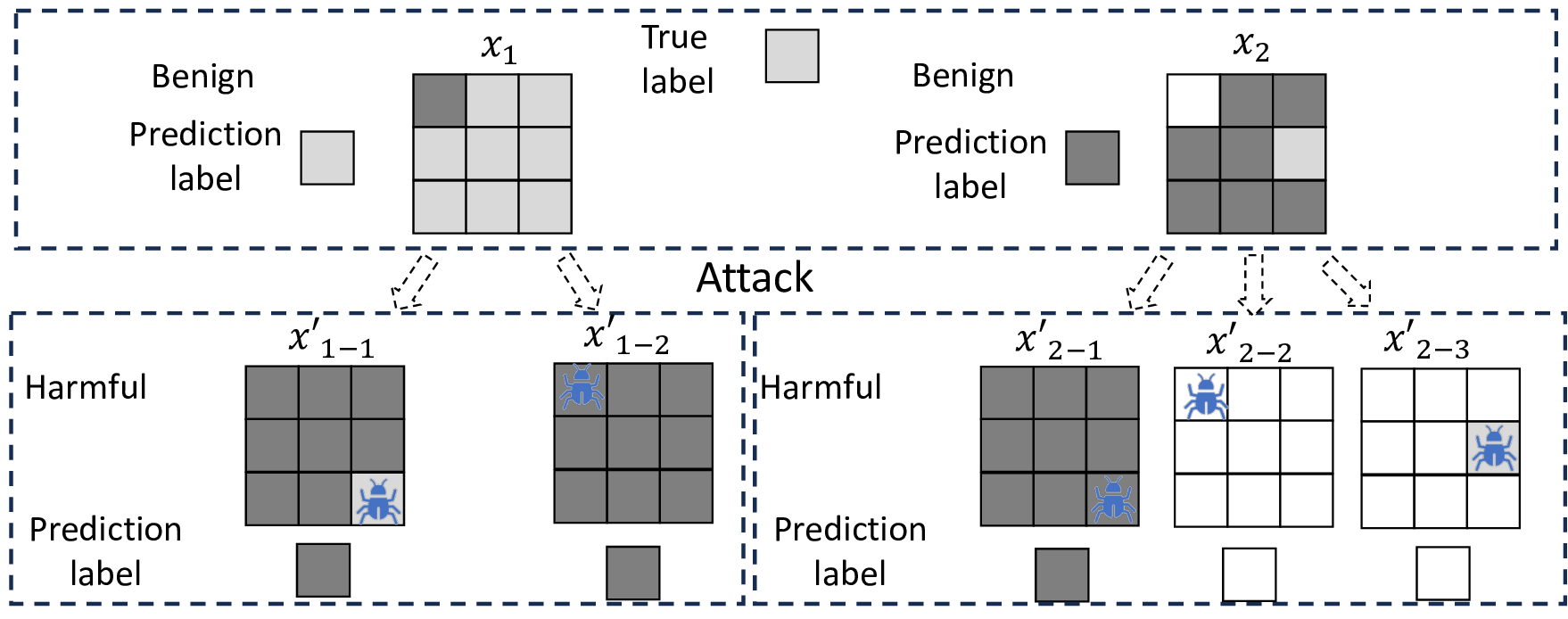
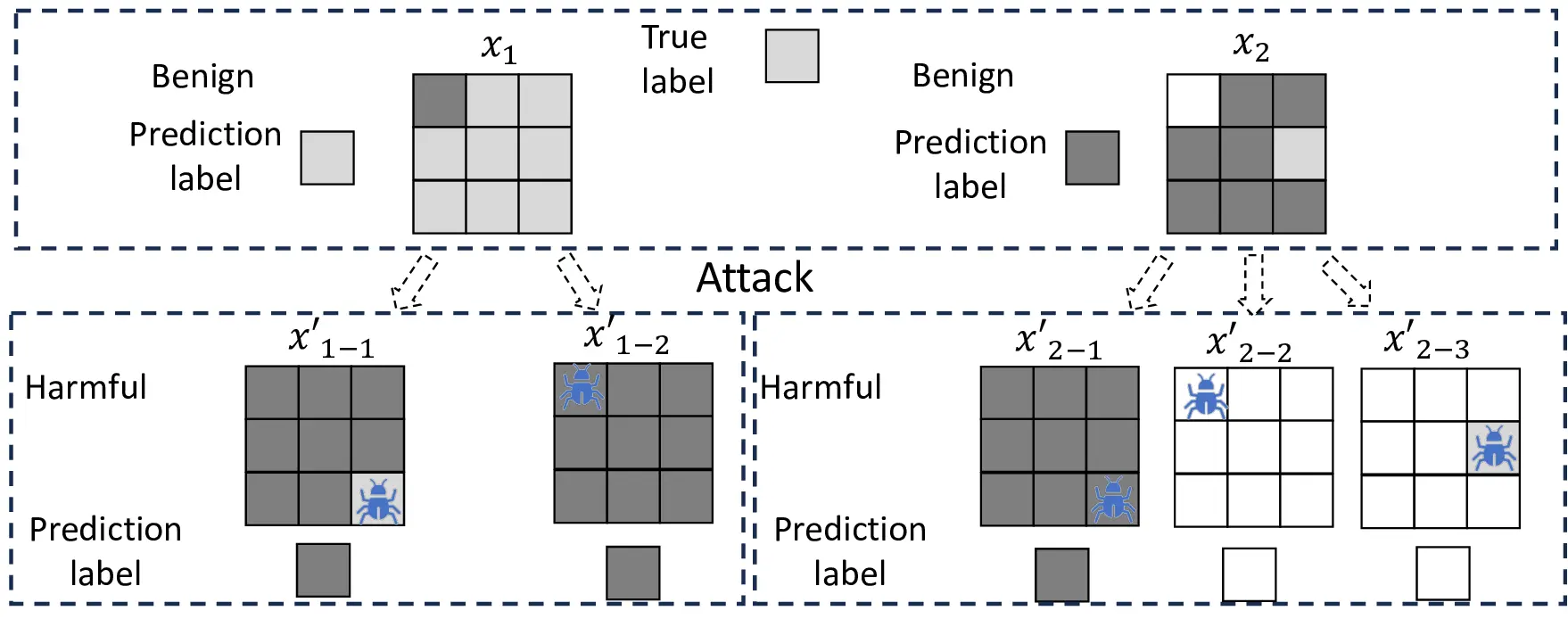
physically realizable [1] (see Fig. 1). A major stereotype is
patch adversarial attacks [7]–[12], which is a threat model for
a deep learning (DL) system that is tricked into misclassifying
an image sample by adding additional content (called a patch)
to the sample on an arbitrary region (called a patch region)
to produce a label differing from the ground truth [8], [13],
[14] (called harmful), consequently, producing an adversarial
example. Detecting these patched samples is desirable. Yet,
empirical detection and defense techniques [1], [15]–[17] often
fail against patch attacks unknown to them or even the known
ones if their defense strategies are exposed to attackers [18].
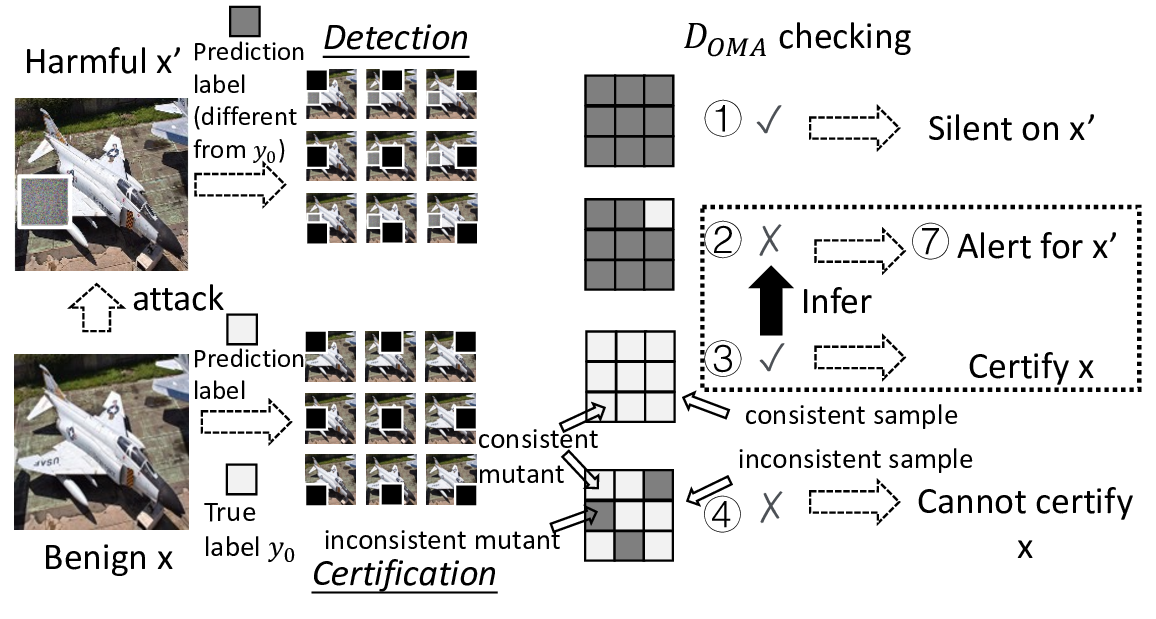
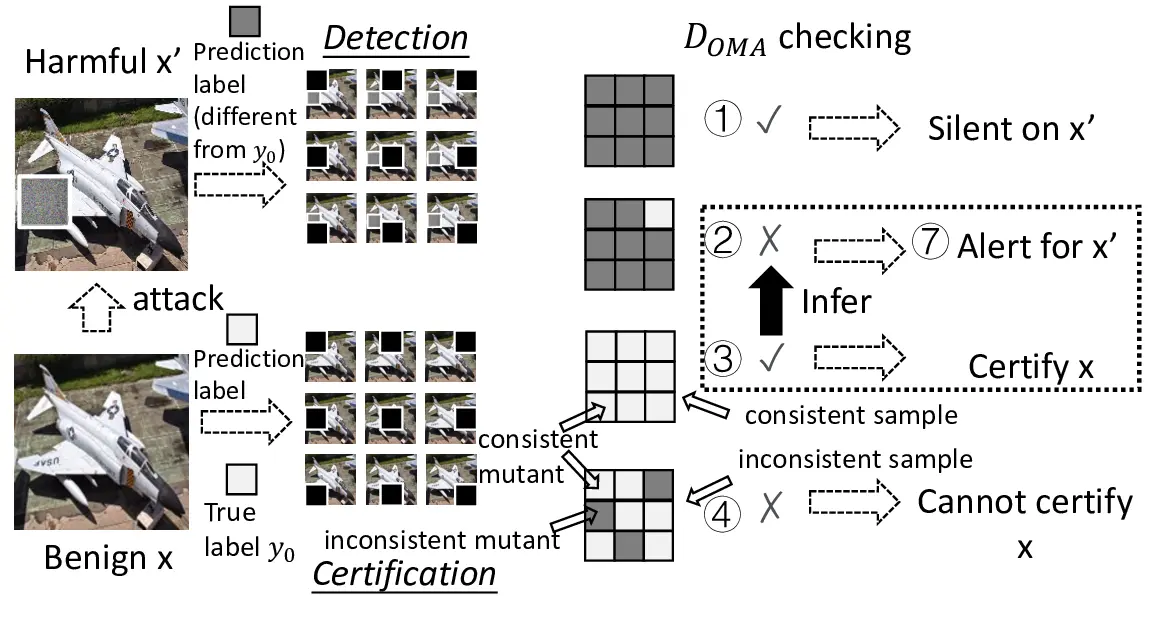
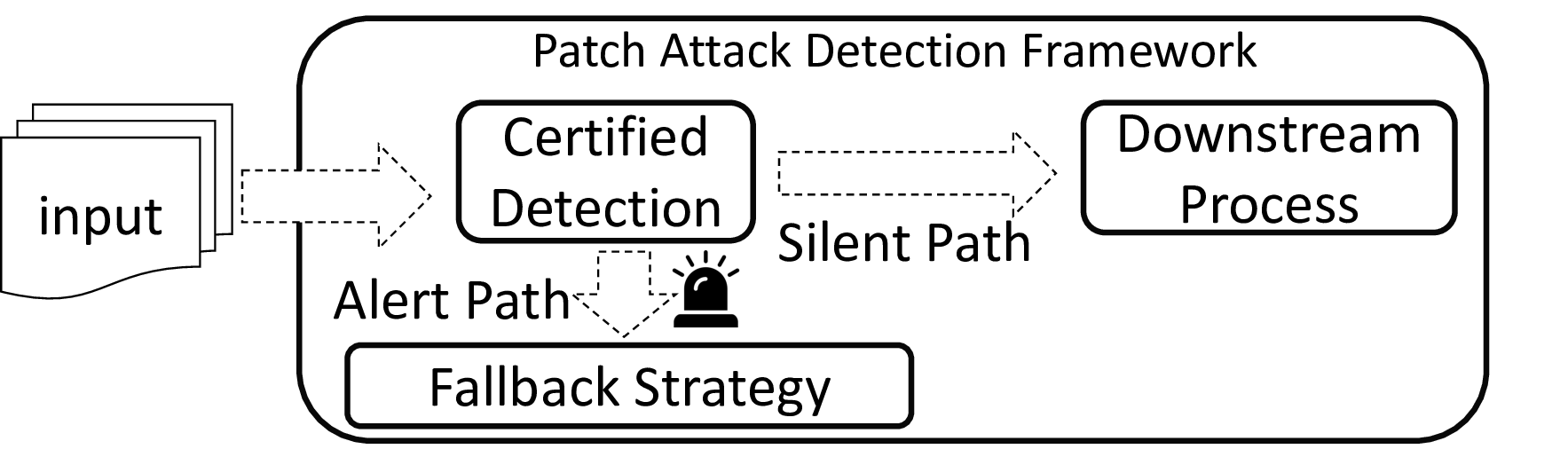
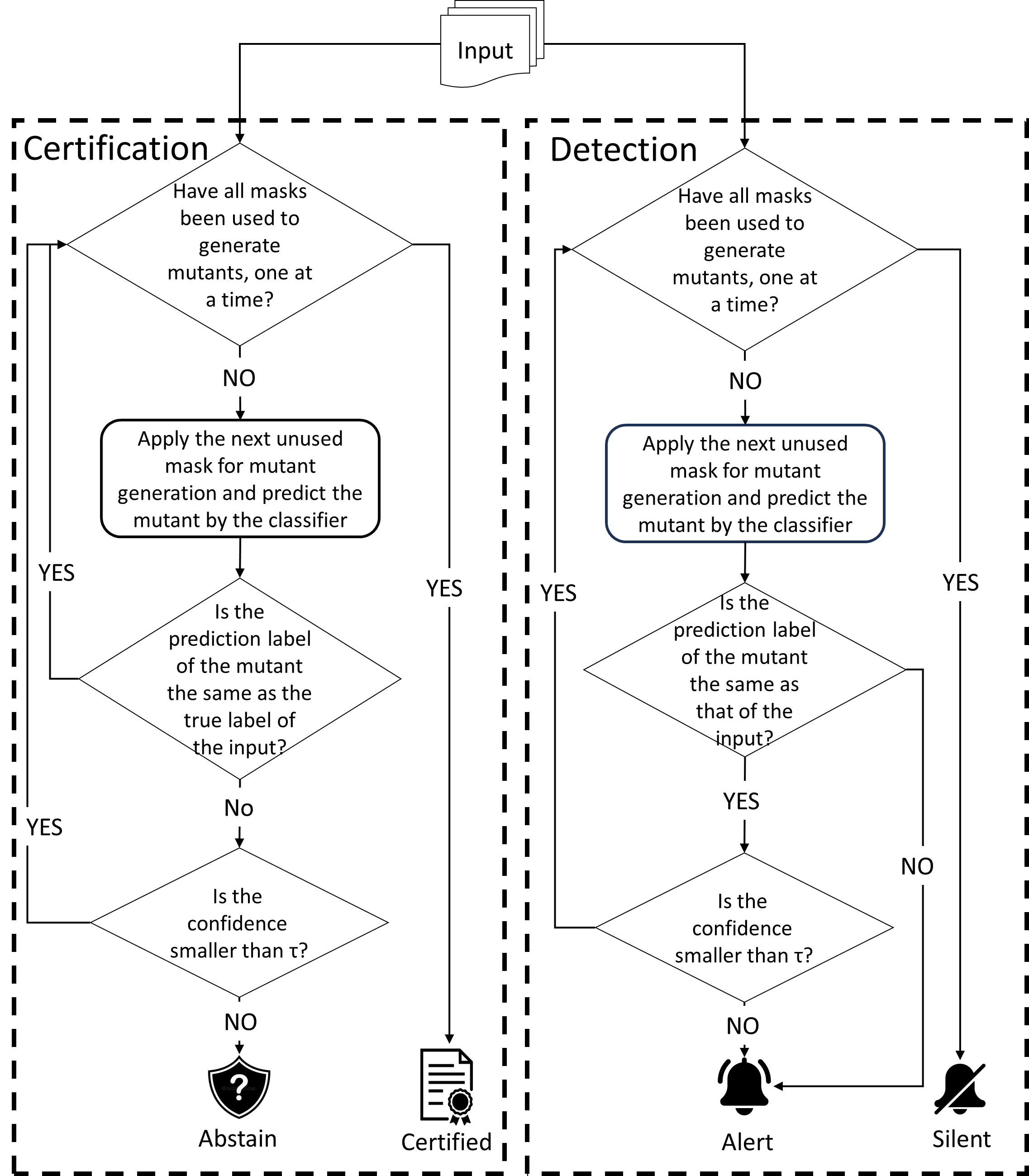
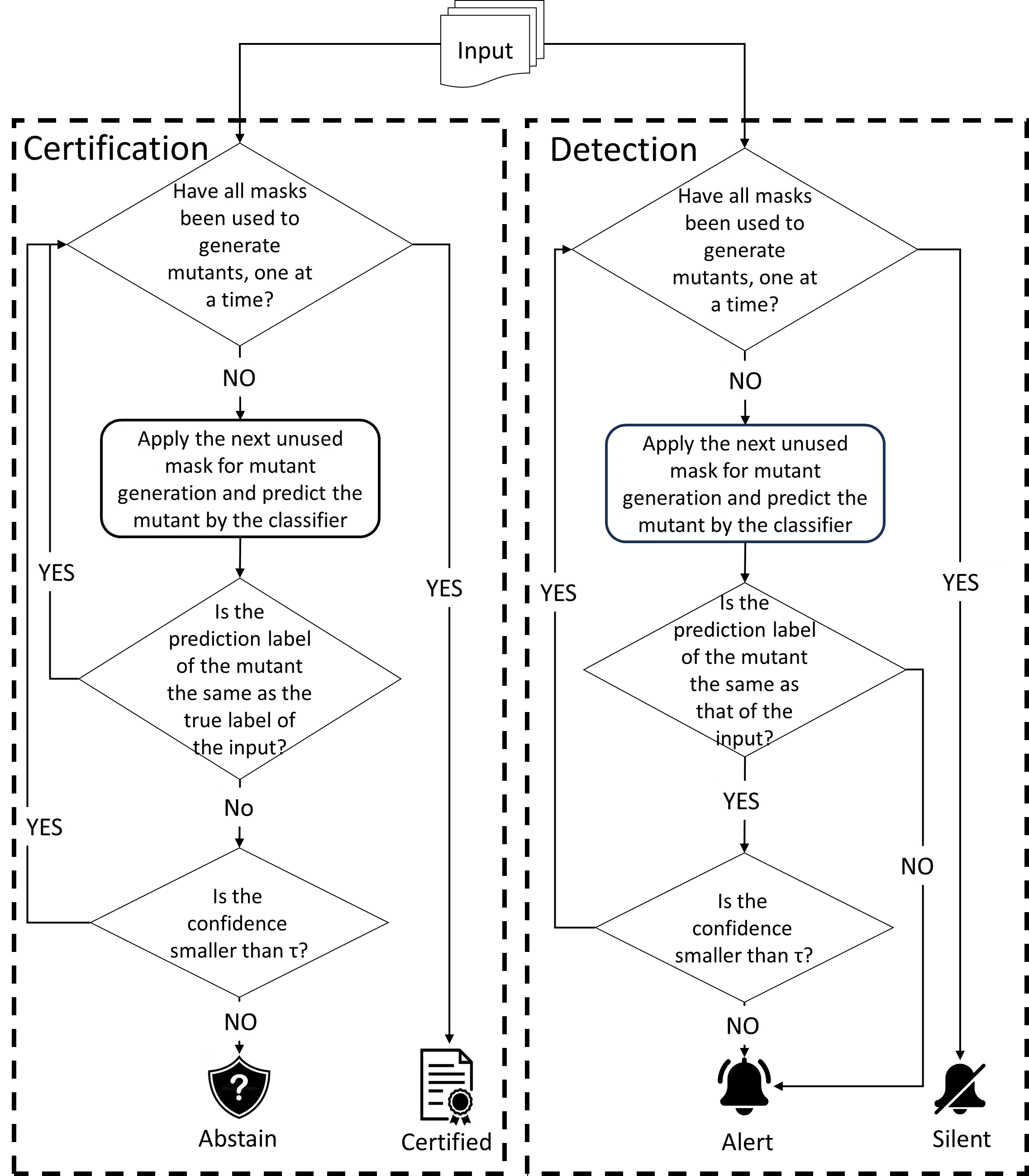
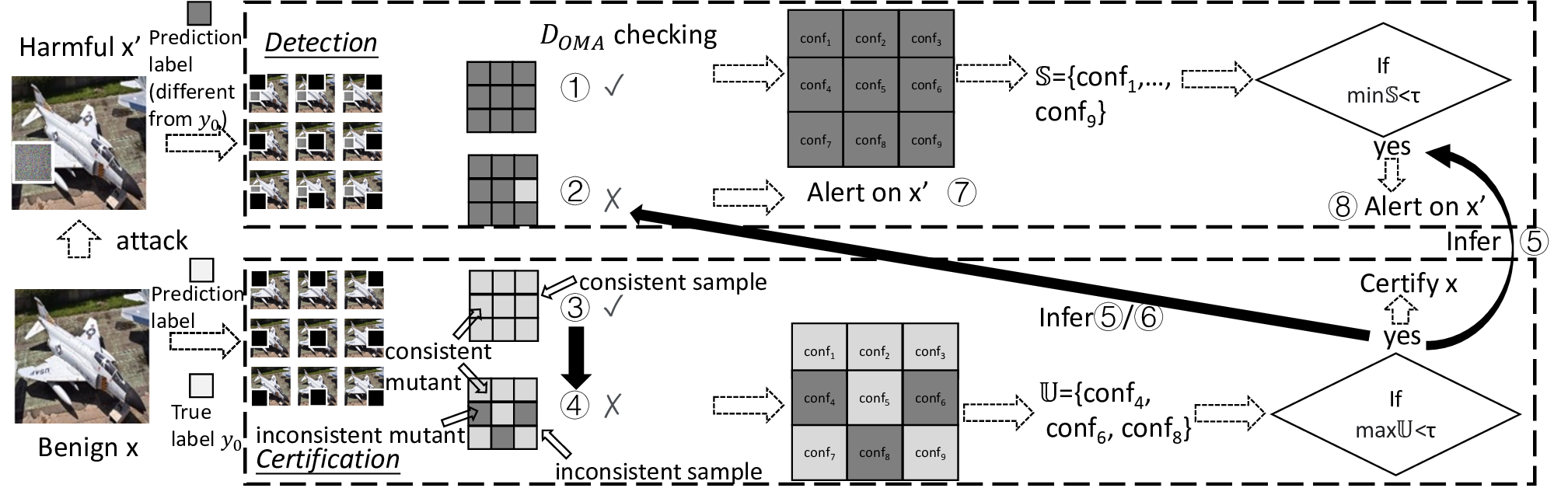
Certified detection for patch adversarial attacks [19]–[24]
can significantly enhance the security of these systems and
is emerging. Its goal is to formulate a provable framework to
cover as many benign samples of a DL system as possible with
the deterministic guarantee of detecting all harmful patched
versions of the covered benign samples (called certified sam-
ples), in the absence of the identity of these benign samples
during the detection of the presence of an adversarial patch
up to a given size. Certification provides a formal detection
property on these certified samples with all their harmful
patched versions, unachievable by pure empirical techniques.
To our knowledge, almost all effective certified detection
defenders against patch adversarial attacks are masking-based
[19]–[23]. As harmful patched versions are considered danger-
ous (e.g., for safety-critical systems [20]), they are specifically
designed to detect all harmful patched versions of a certified
benign sample meeting their inferable criteria while k
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.