The AI Consumer Index (ACE)
We introduce the first version of the AI Consumer Index (ACE), a benchmark for assessing whether frontier AI models can perform everyday consumer tasks. ACE contains a hidden heldout set of 400 test cases, split across four consumer activities: shopping, food, gaming, and DIY. We are also open sourcing 80 cases as a devset with a CC-BY license. For the ACE leaderboard we evaluated 10 frontier models (with websearch turned on) using a novel grading methodology that dynamically checks whether relevant parts of the response are grounded in the retrieved web sources. GPT 5 (Thinking = High) is the top-performing model, scoring 56.1%, followed by o3 Pro (Thinking = On) at 55.2% and GPT 5.1 (Thinking = High) at 55.1%. Model scores differ across domains, and in Shopping the top model scores under 50%. We find that models are prone to hallucinating key information, such as prices. ACE shows a substantial gap between the performance of even the best models and consumers’ AI needs.
💡 Research Summary
The paper introduces the AI Consumer Index (ACE), a benchmark specifically designed to evaluate how well frontier‑level large language models (LLMs) can handle everyday consumer tasks that ordinary users would expect an AI assistant to perform. Unlike traditional LLM benchmarks that focus on pure language understanding, reasoning, or knowledge recall, ACE targets four concrete consumer domains—Shopping, Food, Gaming, and DIY—each representing a distinct class of real‑world activities that require not only textual generation but also up‑to‑date factual grounding from the web.
Dataset Construction
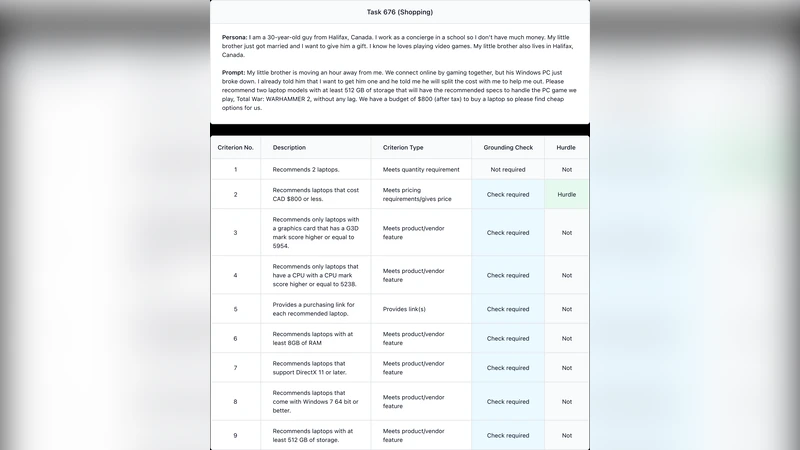
ACE consists of two complementary components. First, an openly licensed development set of 80 cases is released under a CC‑BY license, enabling the research community to fine‑tune models, experiment with prompting strategies, and reproduce baseline results. Second, a hidden evaluation set of 400 cases (100 per domain) is kept private to prevent leaderboard over‑fitting. Each case is phrased as a natural‑language request that a typical consumer might pose, for example: “Find the best‑value wireless earbuds under $50,” “Give me a low‑calorie vegetarian dinner recipe and where to buy the ingredients,” “What starter gear should a new player buy in the latest RPG?” or “How can I set up an automatic watering system for a small garden?” The ground‑truth answer for each case is not a single string but a structured bundle: (i) a set of acceptable solutions (multiple products, recipes, or component lists), (ii) the key quantitative attributes (price, calorie count, damage stats, flow rate), and (iii) a list of web sources (URLs and the exact text snippets) that substantiate each attribute.
Dynamic Grounding Evaluation
The authors argue that a consumer‑grade AI must be able to point to the evidence behind its claims. To capture this, they design a novel grading pipeline that simultaneously checks (a) content correctness and (b) source grounding. The pipeline works as follows: after a model generates a response, an automated matcher extracts the claimed factual items (e.g., a price, a product name, a recipe ingredient). It then searches the set of retrieved web pages (the model’s own web‑search results) for exact or semantically similar strings, using a combination of fuzzy string matching, BM25 ranking, and contextual embedding similarity. If a claim is found in at least one retrieved snippet, the claim receives a “grounded” flag; otherwise it is marked as hallucinated. Partial credit is awarded when a claim is correct but the grounding is weak (e.g., the price matches but the URL does not contain the exact figure). The final ACE score for a model is the average of content‑accuracy and grounding‑accuracy across all cases.
Experimental Setup
Ten state‑of‑the‑art models were evaluated on ACE, all with web‑search enabled. The models differ in architecture, training data, and a configurable “Thinking” mode that controls the depth of internal deliberation (High, On, Off). The leaderboard results are as follows:
- GPT‑5 (Thinking = High) – 56.1 %
- o3 Pro (Thinking = On) – 55.2 %
- GPT‑5.1 (Thinking = High) – 55.1 %
All other models fall between 48 % and 54 %. Domain‑wise performance shows a clear pattern: DIY and Gaming achieve scores near 60 %, while Shopping lags behind at sub‑50 % even for the top model. The Food domain sits in the middle (≈53 %). A detailed error analysis reveals that the most common failure mode is hallucination of quantitative details, especially prices, stock availability, and discount percentages. For instance, a model might suggest a “$29.99” price for a headset that never appears in any of the retrieved pages, or it may fabricate a “20 % off” coupon that does not exist. Such errors are particularly damaging in the Shopping domain where users rely on precise monetary information.
Key Insights
- Grounding is Harder Than Generation – Even models that can produce fluent, plausible text often fail to anchor each factual claim in a retrieved source. The dynamic grounding metric uncovers a hidden layer of error that traditional BLEU‑ or ROUGE‑style scores miss.
- Domain Heterogeneity – DIY tasks tend to involve more static specifications (e.g., “12 V water pump”) that are readily searchable and less volatile, leading to higher scores. In contrast, Shopping requires up‑to‑the‑minute price data that changes frequently, exposing the latency and freshness limits of the underlying web‑search engine.
- Thinking Mode Benefits Are Marginal – Raising the “Thinking” level from Off to High yields only a 1–2 % absolute gain, suggesting that current deliberation mechanisms (chain‑of‑thought prompting, self‑consistency) provide limited advantage when the bottleneck is external information retrieval.
- Hallucination of Critical Numbers – The prevalence of fabricated prices indicates that models still rely heavily on memorized priors from pre‑training corpora, overriding the evidence retrieved at inference time. This points to a need for tighter integration between retrieval and generation, perhaps via differentiable retrieval or explicit citation tokens.
Limitations
The benchmark currently focuses on English‑language web content, which may not reflect the multilingual reality of global consumers. The grounding pipeline, while automated, still requires heuristic thresholds and occasional human verification for ambiguous matches. Moreover, the hidden test set is static; future work should consider a continuously refreshed pool to capture real‑time market dynamics. Finally, the definition of “Thinking” varies across model families, making cross‑model comparisons imperfect.
Future Directions
The authors propose several avenues to evolve ACE: (i) expanding the case pool to include non‑English sources and region‑specific marketplaces, (ii) integrating live price APIs to test models against truly real‑time data, (iii) developing a user‑centric interface that displays model citations and lets users confirm or correct them, and (iv) establishing a human‑in‑the‑loop evaluation where participants judge both answer usefulness and citation transparency. Such extensions would push ACE from a static benchmark toward an operational testbed for consumer‑grade AI assistants.
Overall, ACE fills a critical gap in the evaluation landscape by measuring not just whether an LLM can talk about consumer topics, but whether it can do so with verifiable, up‑to‑date evidence. The current results demonstrate a substantial performance gap between even the most advanced models and the reliability standards required for everyday consumer use, highlighting the need for tighter retrieval‑generation coupling, better grounding mechanisms, and more robust, domain‑aware training.