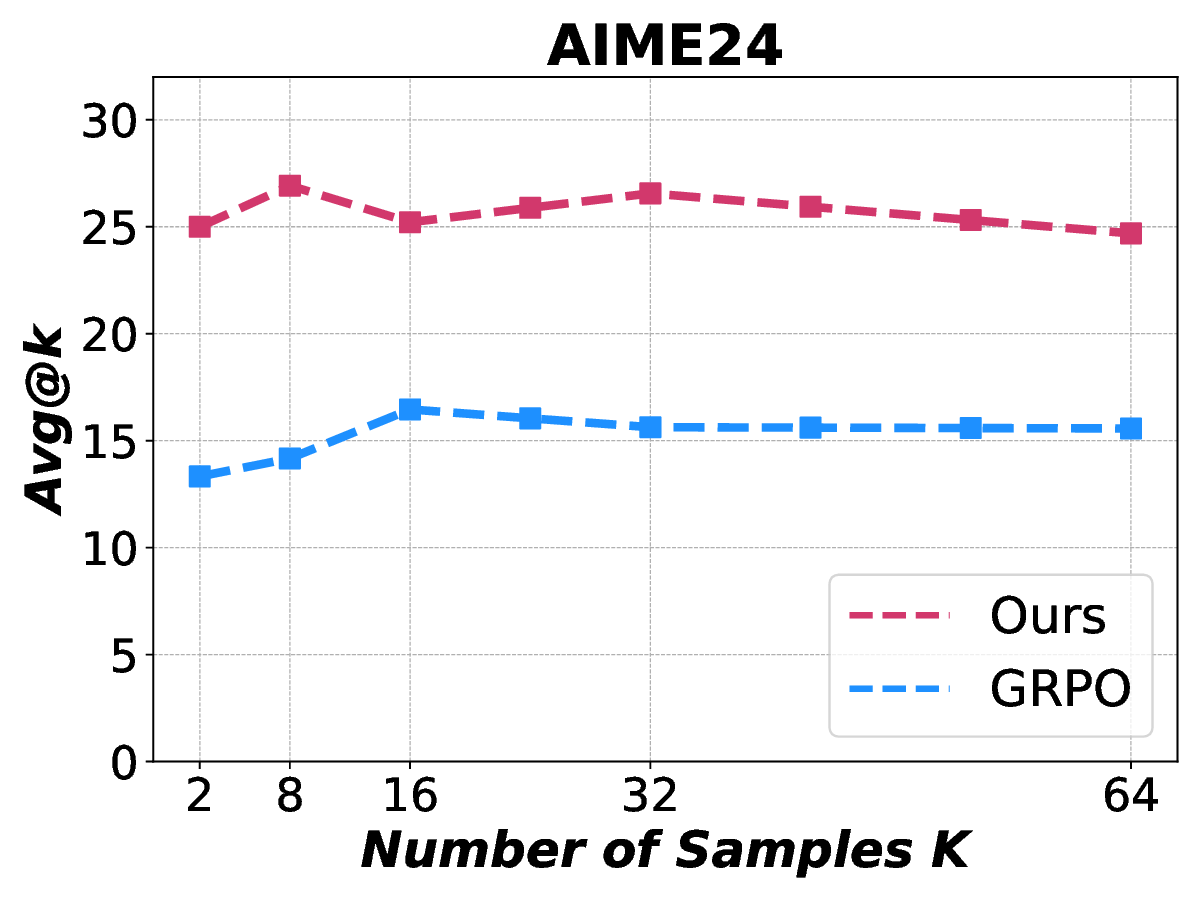
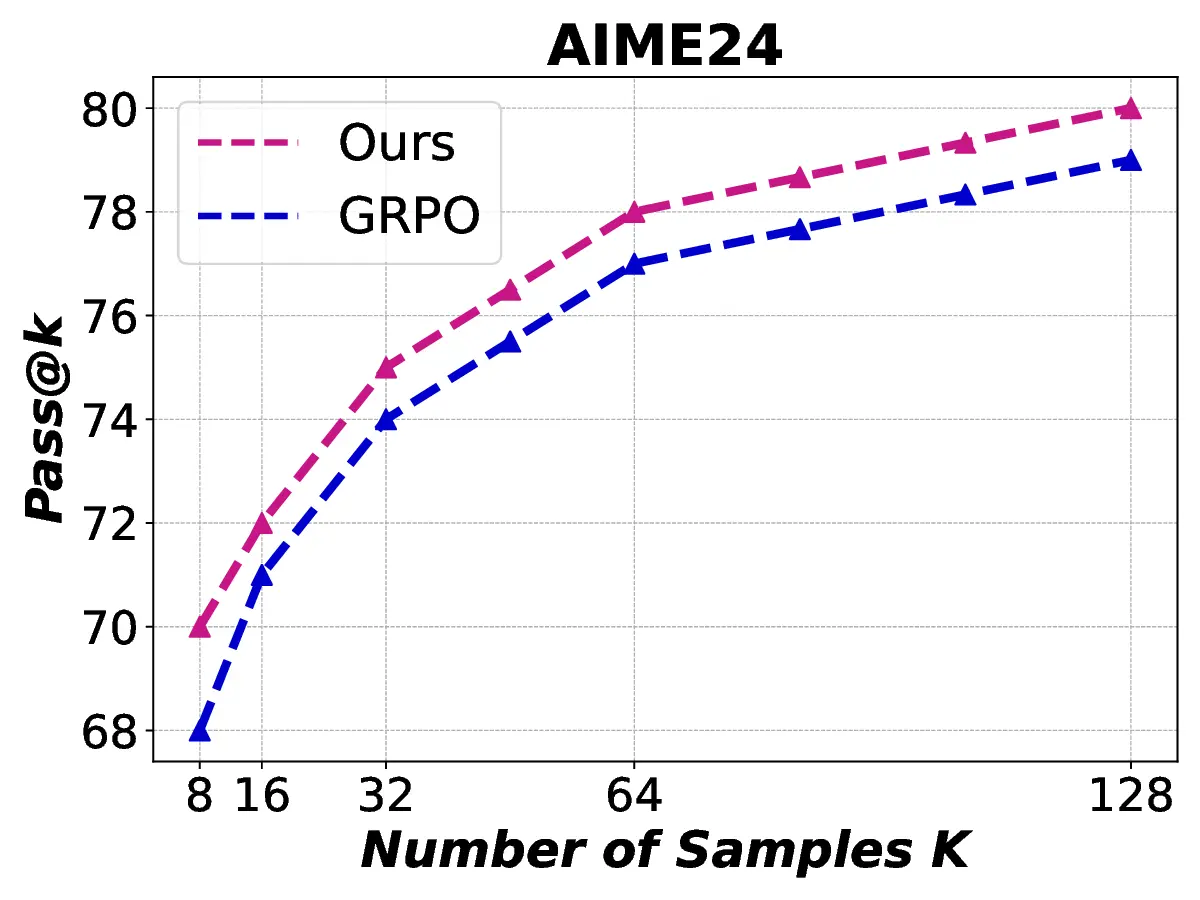
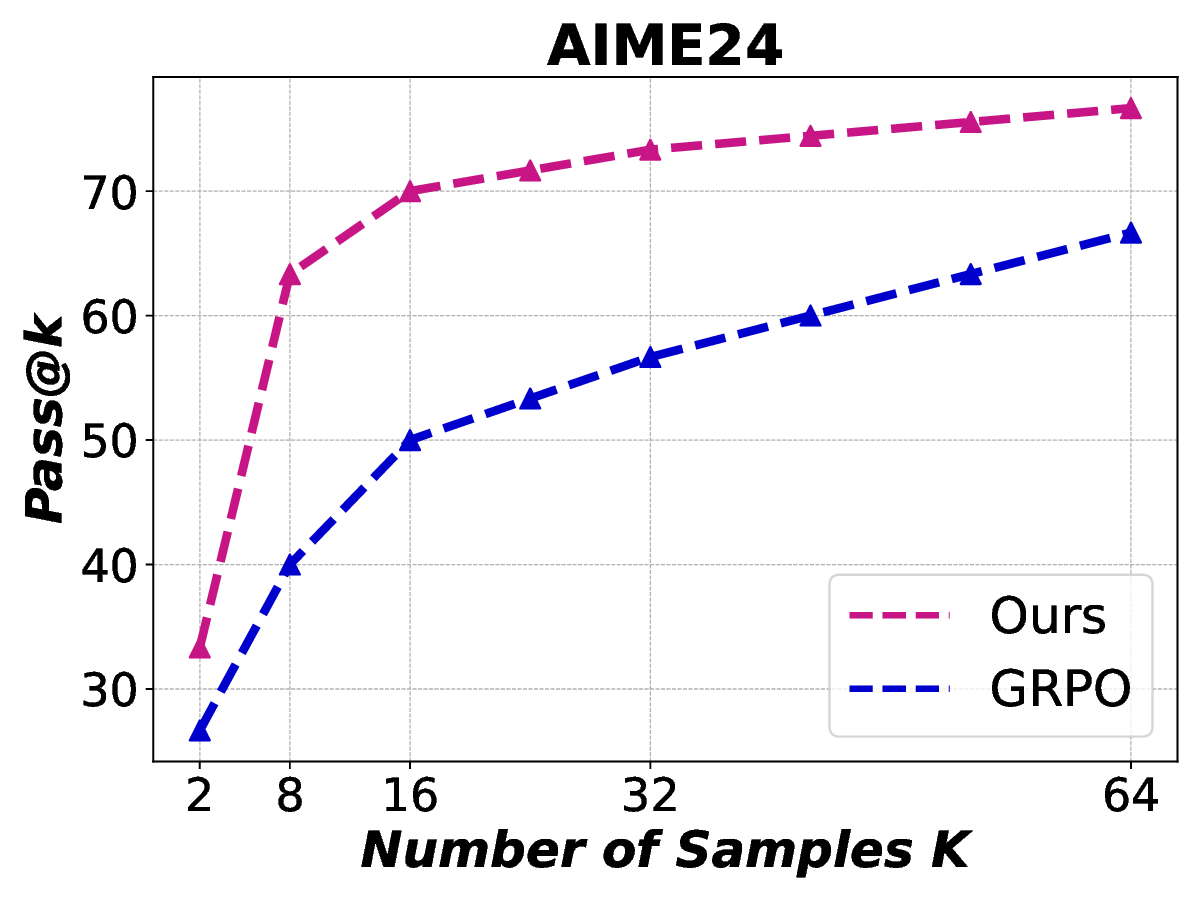
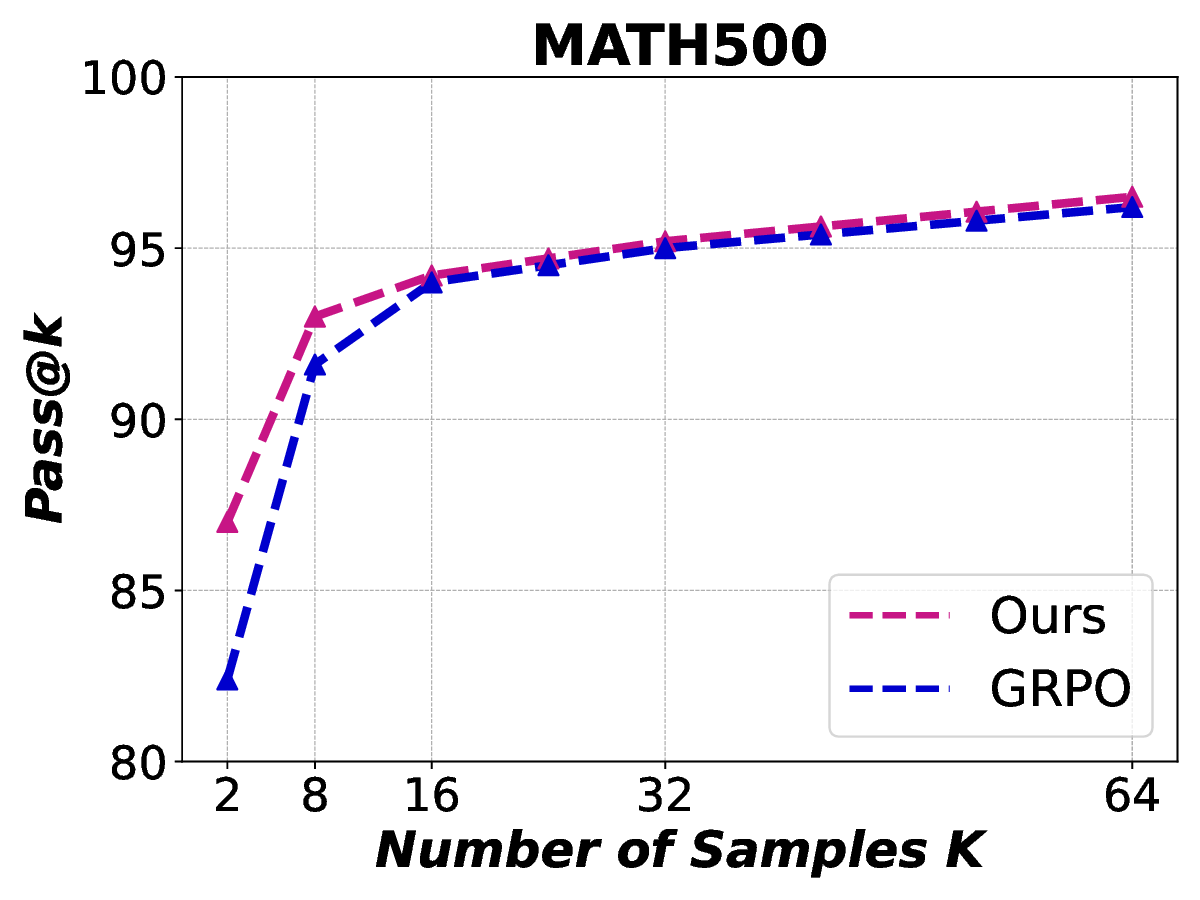
Reinforcement learning with verifiable rewards (RLVR) has demonstrated superior performance in enhancing the reasoning capability of large language models (LLMs). However, this accuracy-oriented learning paradigm often suffers from entropy collapse, which reduces policy exploration and limits reasoning capabilities. To address this challenge, we propose an efficient reinforcement learning framework that leverages entropy signals at both the semantic and token levels to improve reasoning. From the data perspective, we introduce semantic entropy-guided curriculum learning, organizing training data from low to high semantic entropy to guide progressive optimization from easier to more challenging tasks. For the algorithmic design, we adopt non-uniform token treatment by imposing KL regularization on low-entropy tokens that critically impact policy exploration and applying stronger constraints on high-covariance portions within these tokens. By jointly optimizing data organization and algorithmic design, our method effectively mitigates entropy collapse and enhances LLM reasoning. Experimental results across 6 benchmarks with 3 different parameter-scale base models demonstrate that our method outperforms other entropy-based approaches in improving reasoning.
Deep Dive into 엔트로피 신호 기반 효율적 강화학습으로 대형 언어 모델 추론 향상.
Reinforcement learning with verifiable rewards (RLVR) has demonstrated superior performance in enhancing the reasoning capability of large language models (LLMs). However, this accuracy-oriented learning paradigm often suffers from entropy collapse, which reduces policy exploration and limits reasoning capabilities. To address this challenge, we propose an efficient reinforcement learning framework that leverages entropy signals at both the semantic and token levels to improve reasoning. From the data perspective, we introduce semantic entropy-guided curriculum learning, organizing training data from low to high semantic entropy to guide progressive optimization from easier to more challenging tasks. For the algorithmic design, we adopt non-uniform token treatment by imposing KL regularization on low-entropy tokens that critically impact policy exploration and applying stronger constraints on high-covariance portions within these tokens. By jointly optimizing data organization and algo
R EASONING has emerged as a core capability of large language models (LLMs) in tackling complex tasks [1], [2]. Reinforcement learning with verifiable rewards (RLVR) has effectively enhanced LLMs' reasoning capabilities across mathematics [3], [4], code generation [5], [6], and decisionmaking applications [7]- [9] through post-training. However, this purely accuracy-based learning paradigm decreases exploration and may lead to local optima [10], [11], thereby limiting the model's ability to improve reasoning performance. This problem manifests as precipitous entropy collapse during posttraining. Entropy, which quantifies uncertainty in the policy's action distribution and measures exploration capability [12]- [14], drops sharply during training, resulting in generated responses that lack diversity and further limiting exploration.
To encourage exploration and improve reasoning, prior works have investigated entropy-guided strategies to enhance
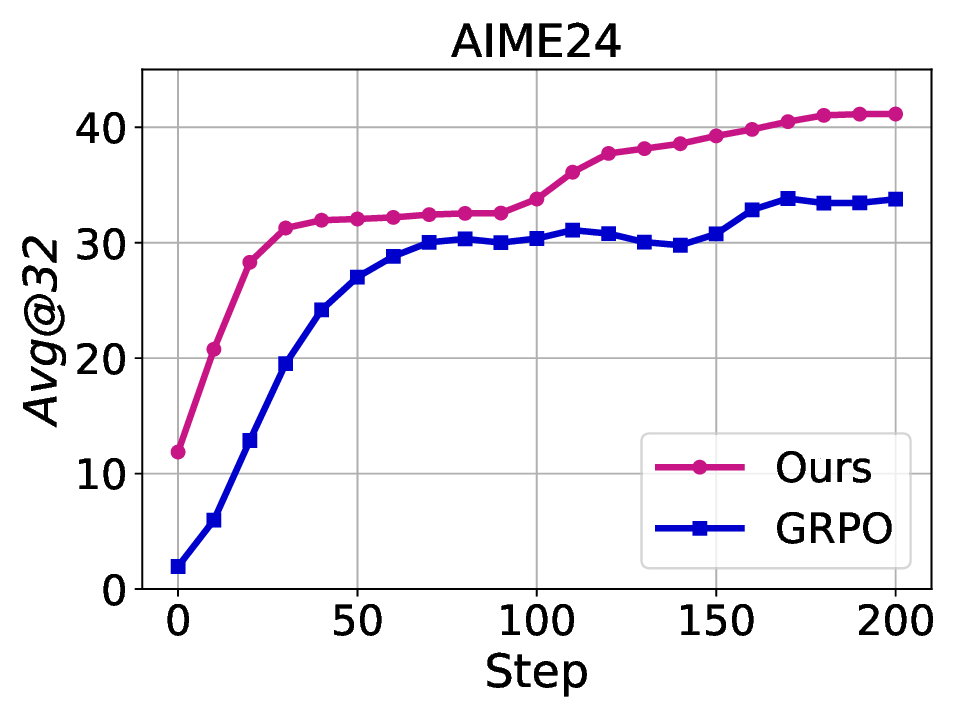
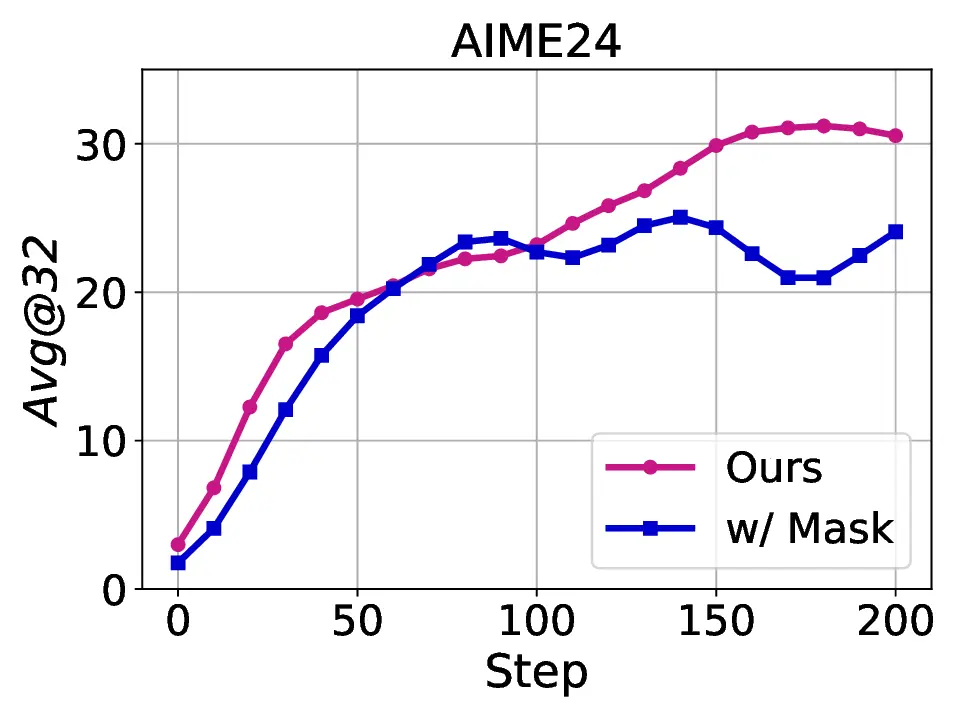
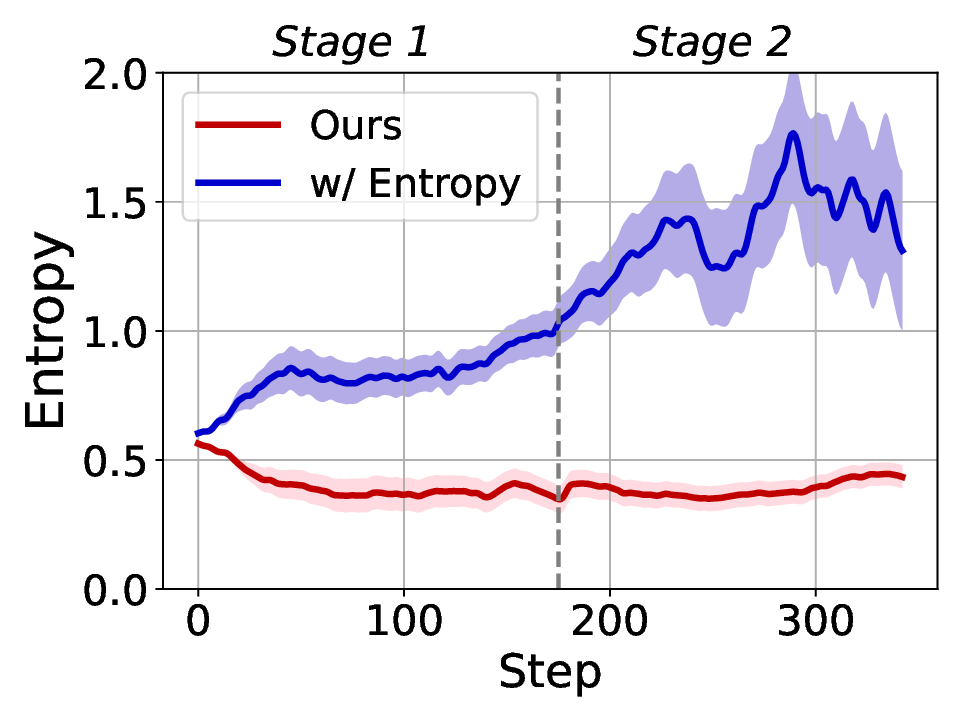
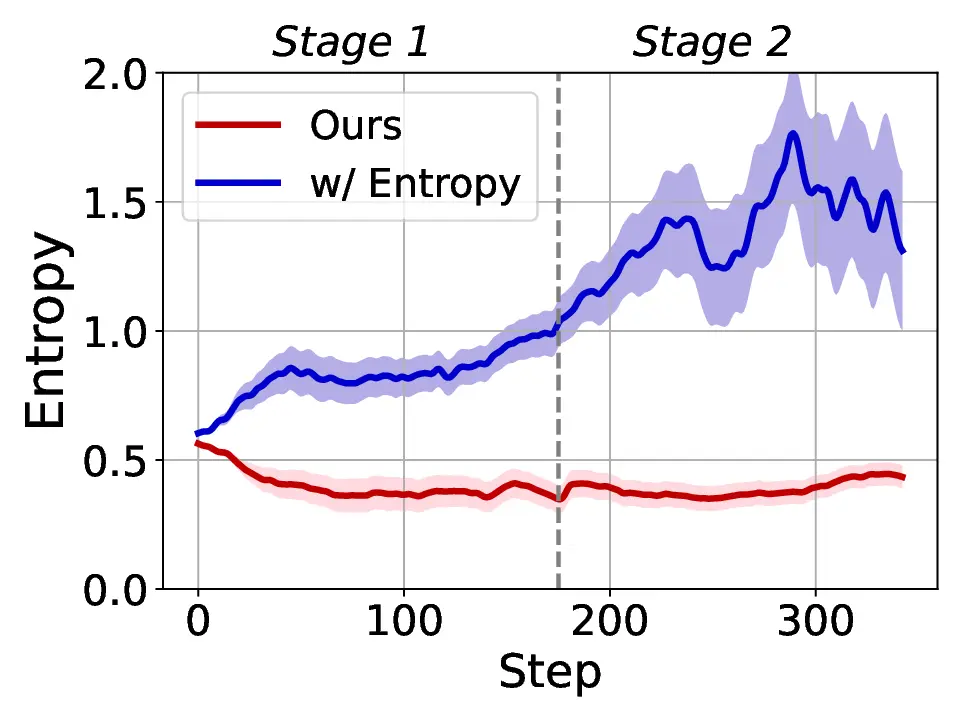
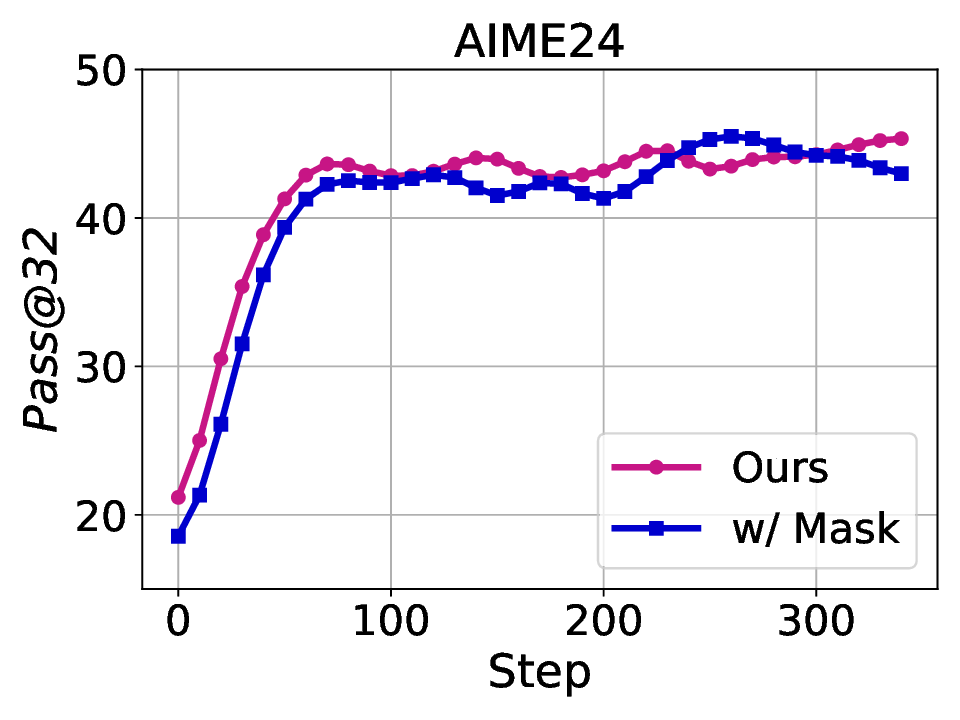
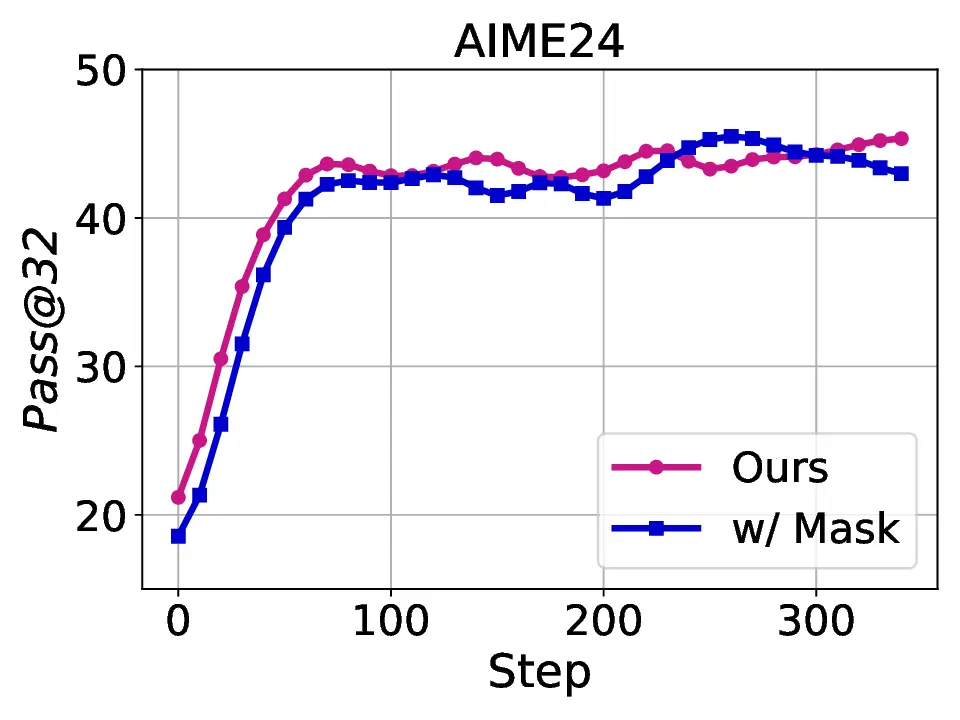
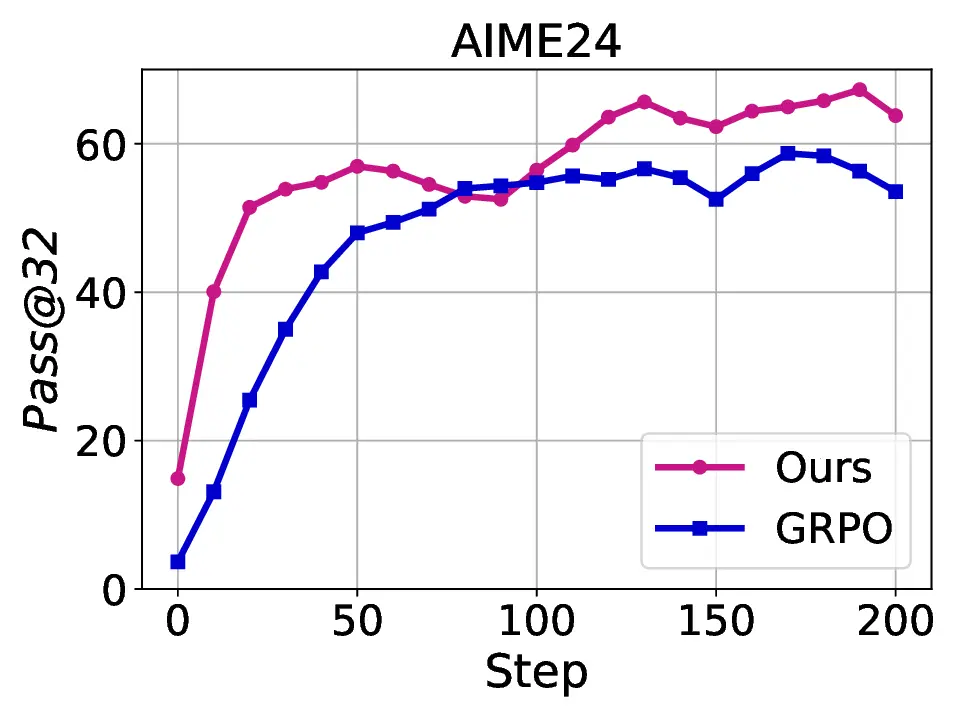
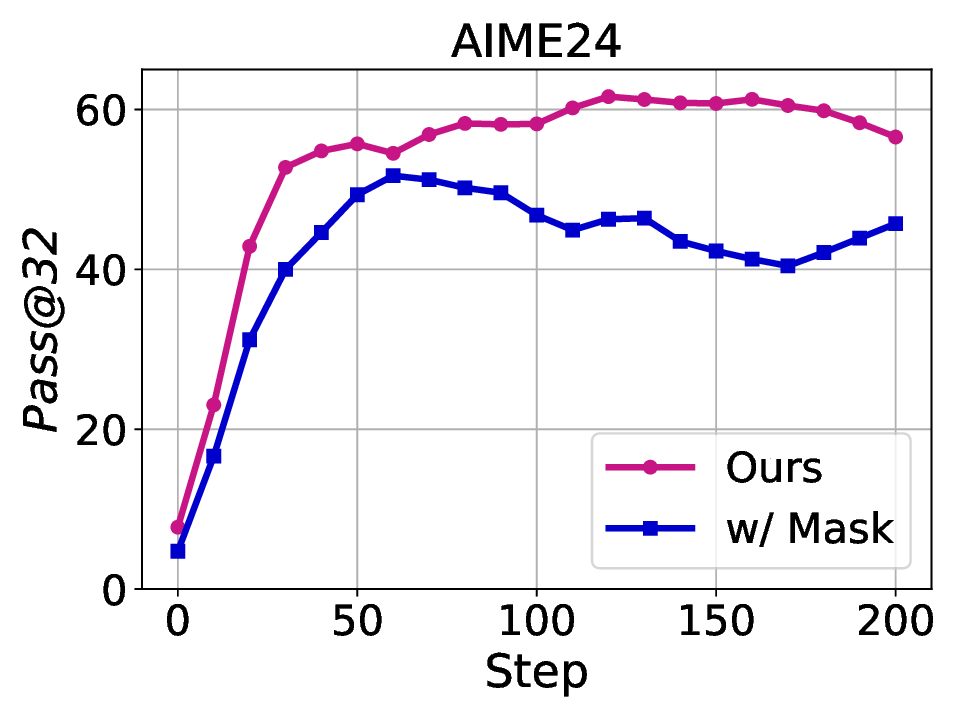
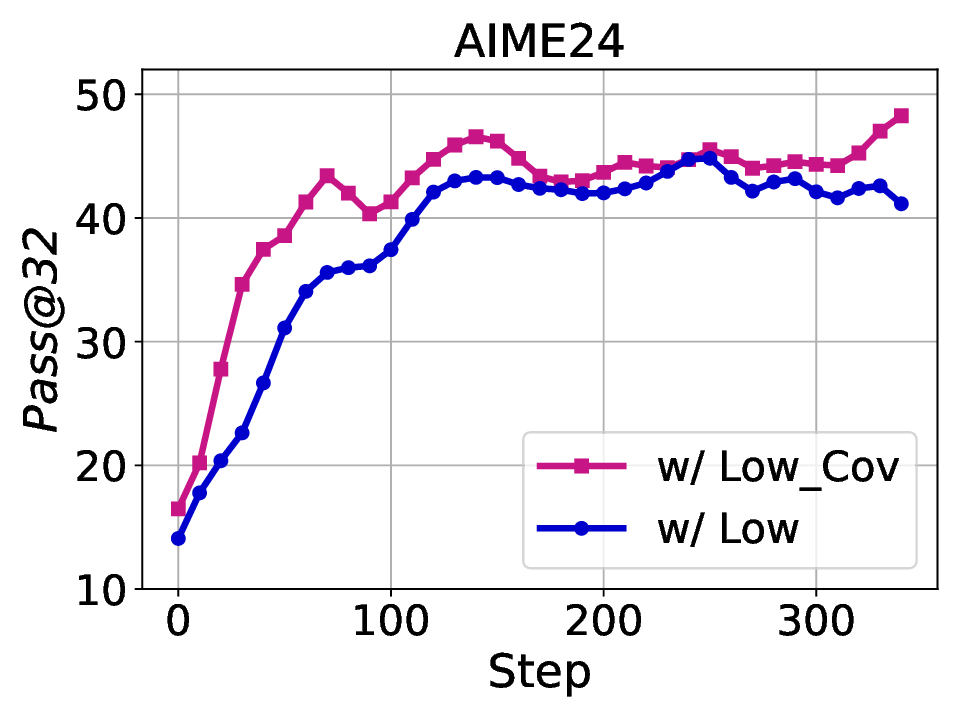
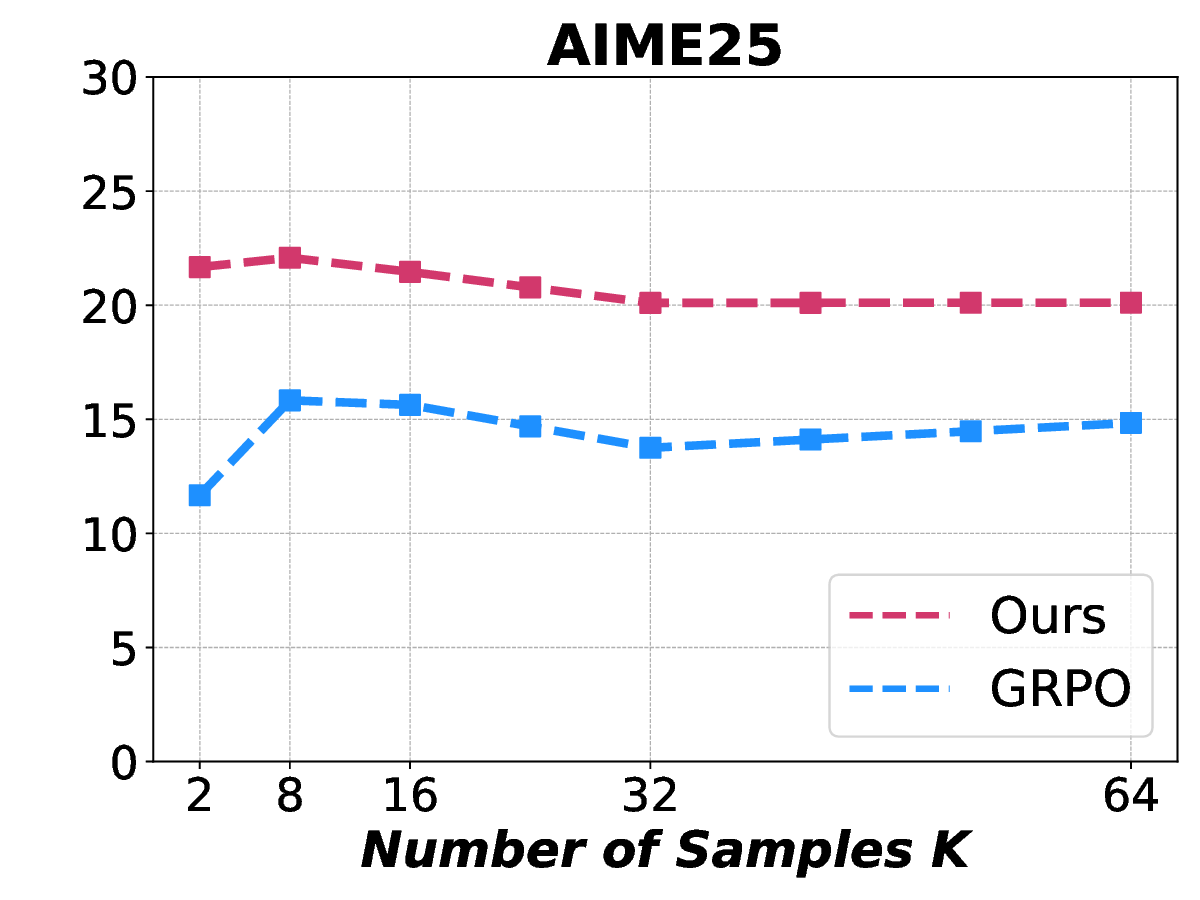
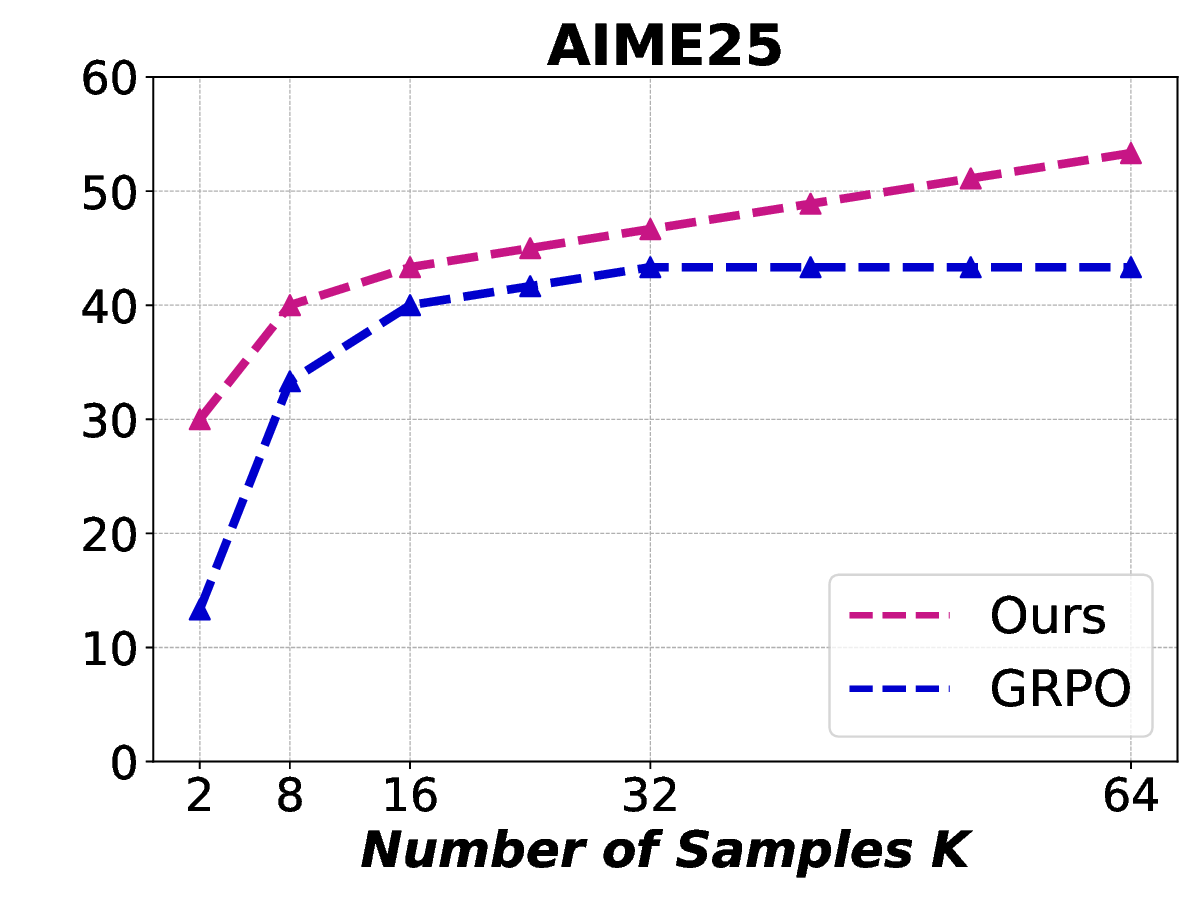
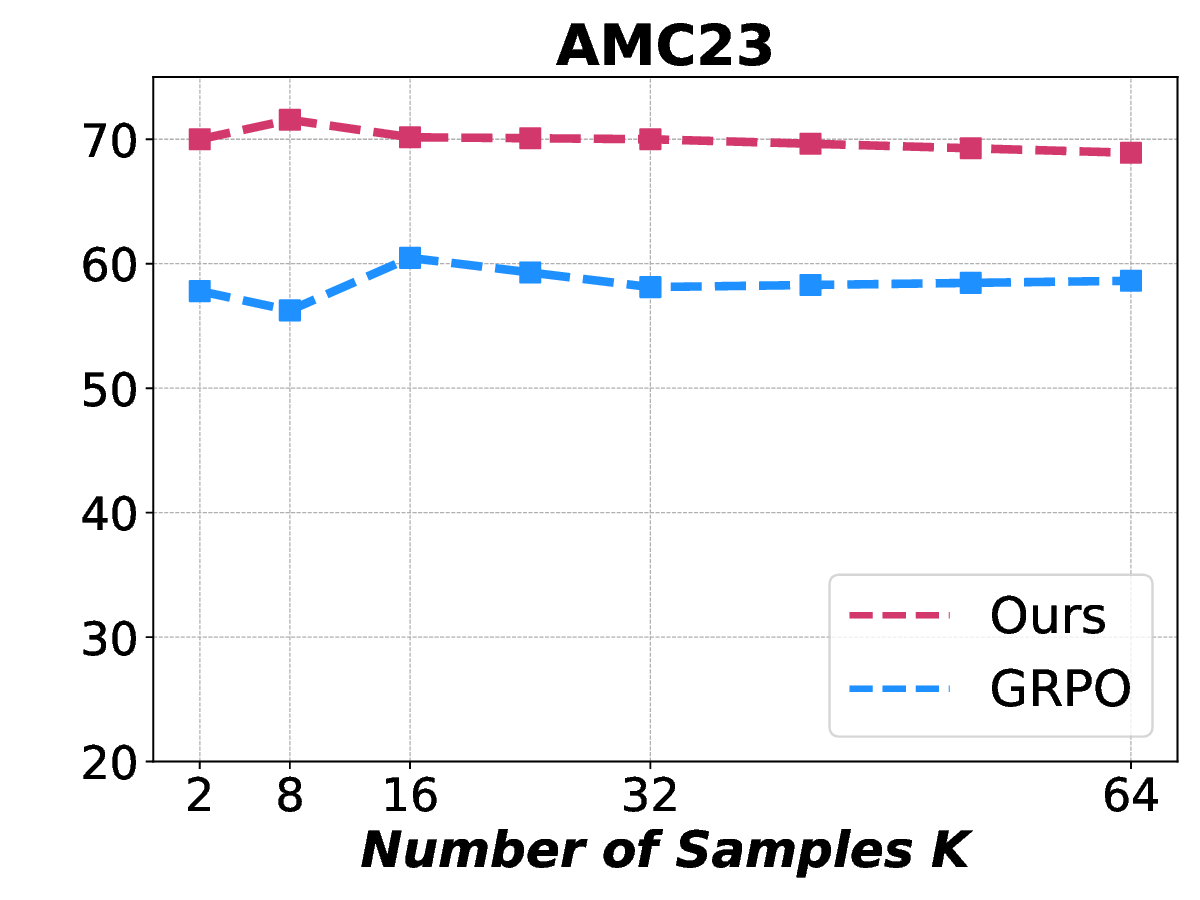
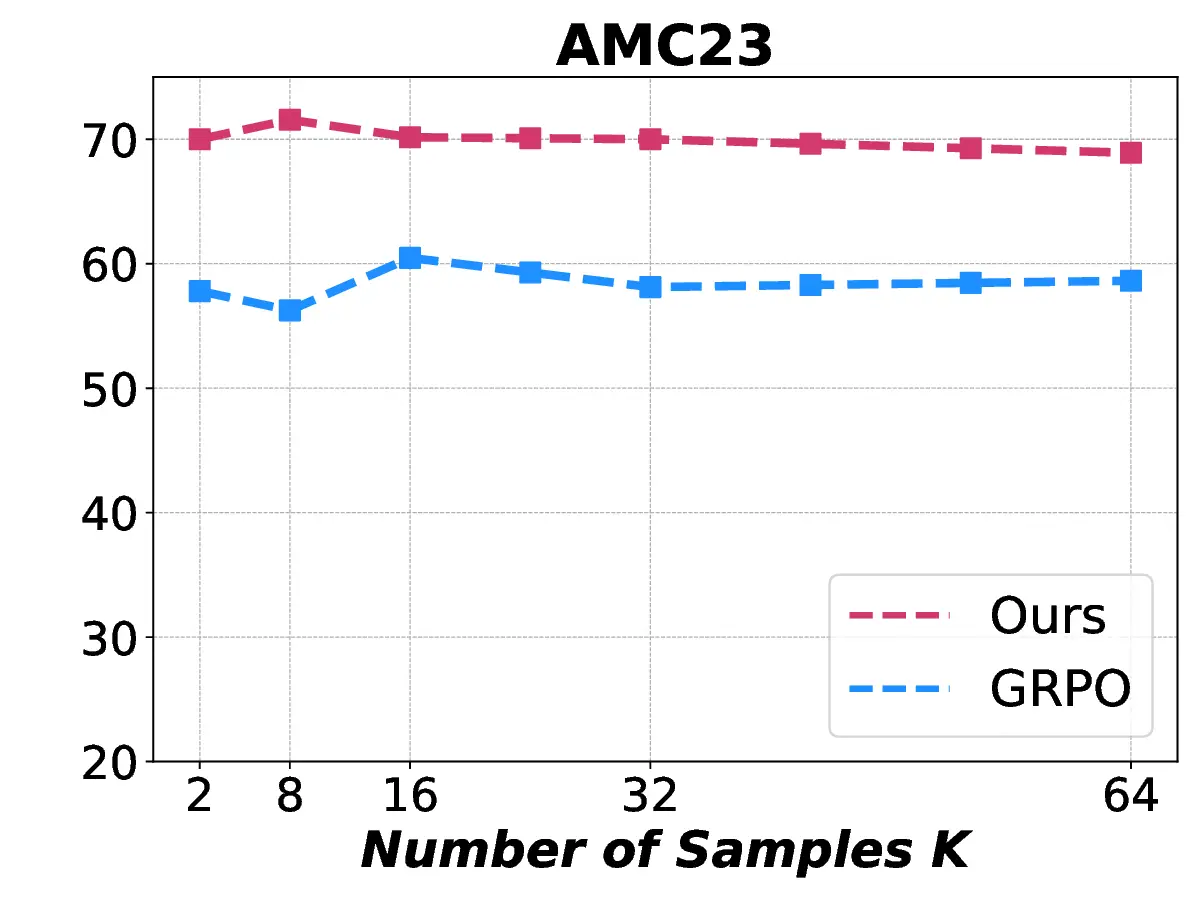
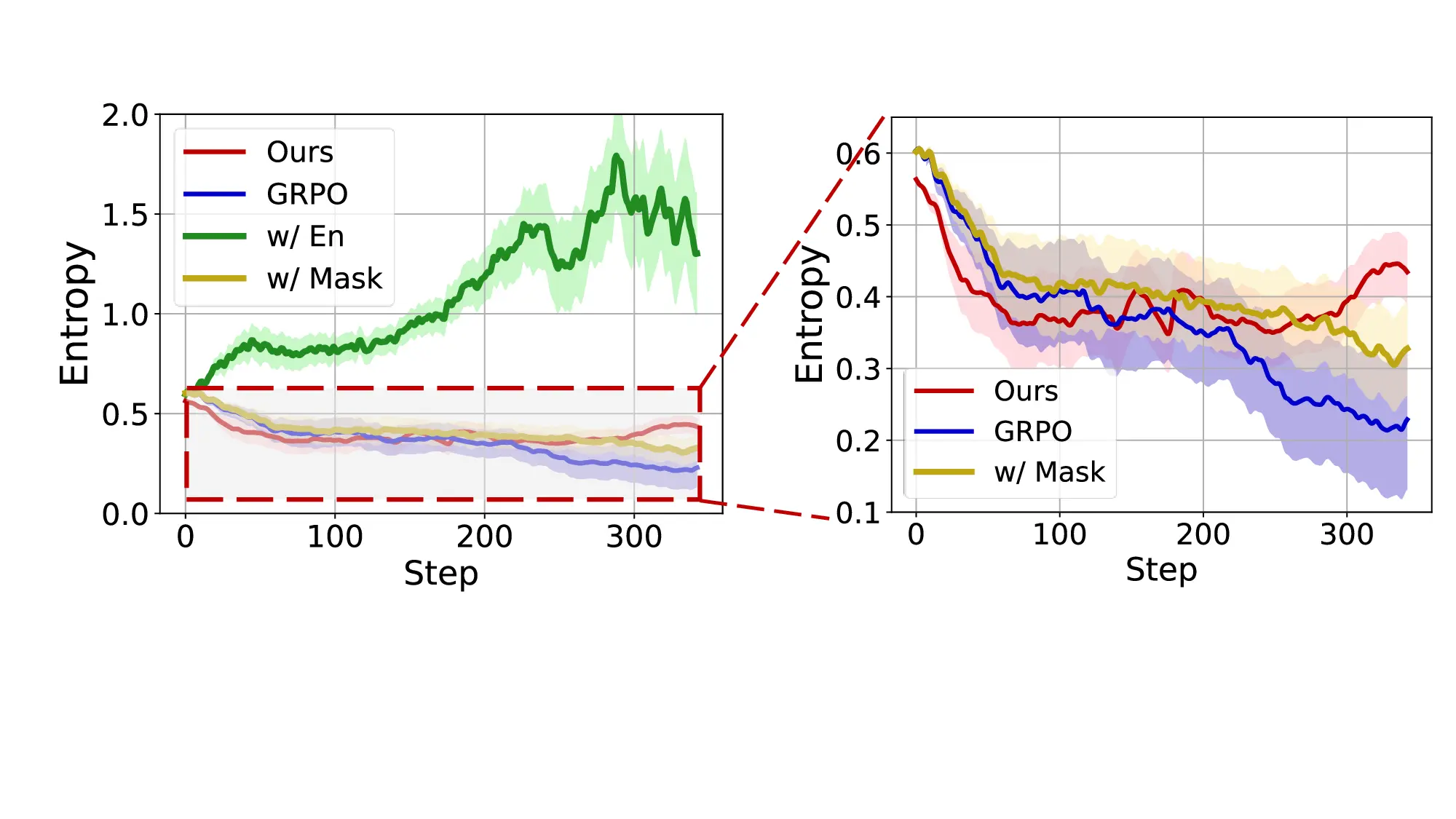
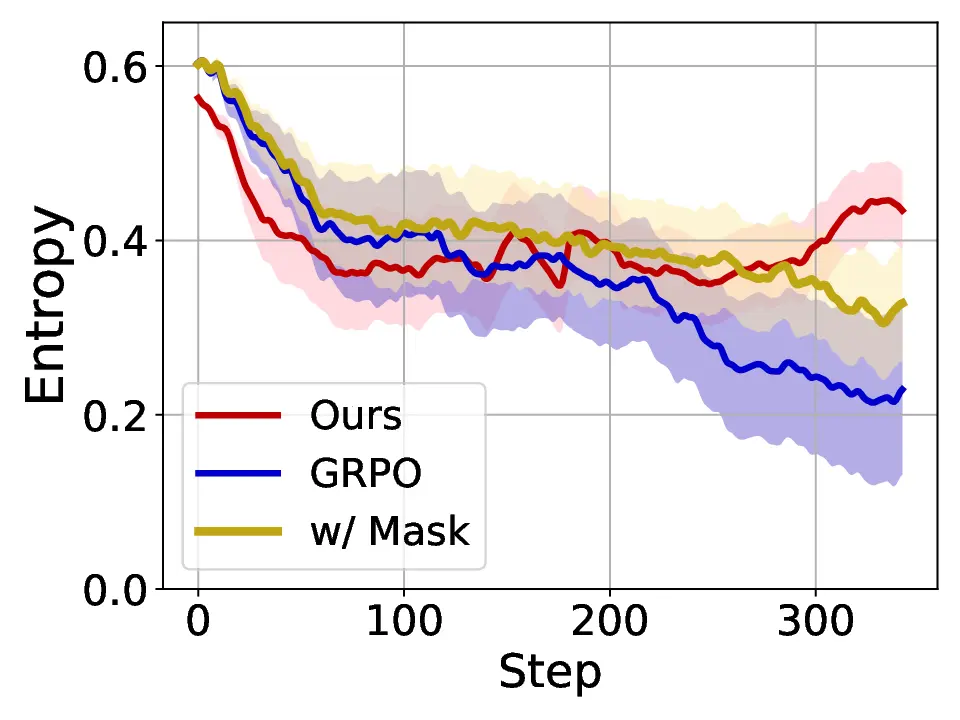
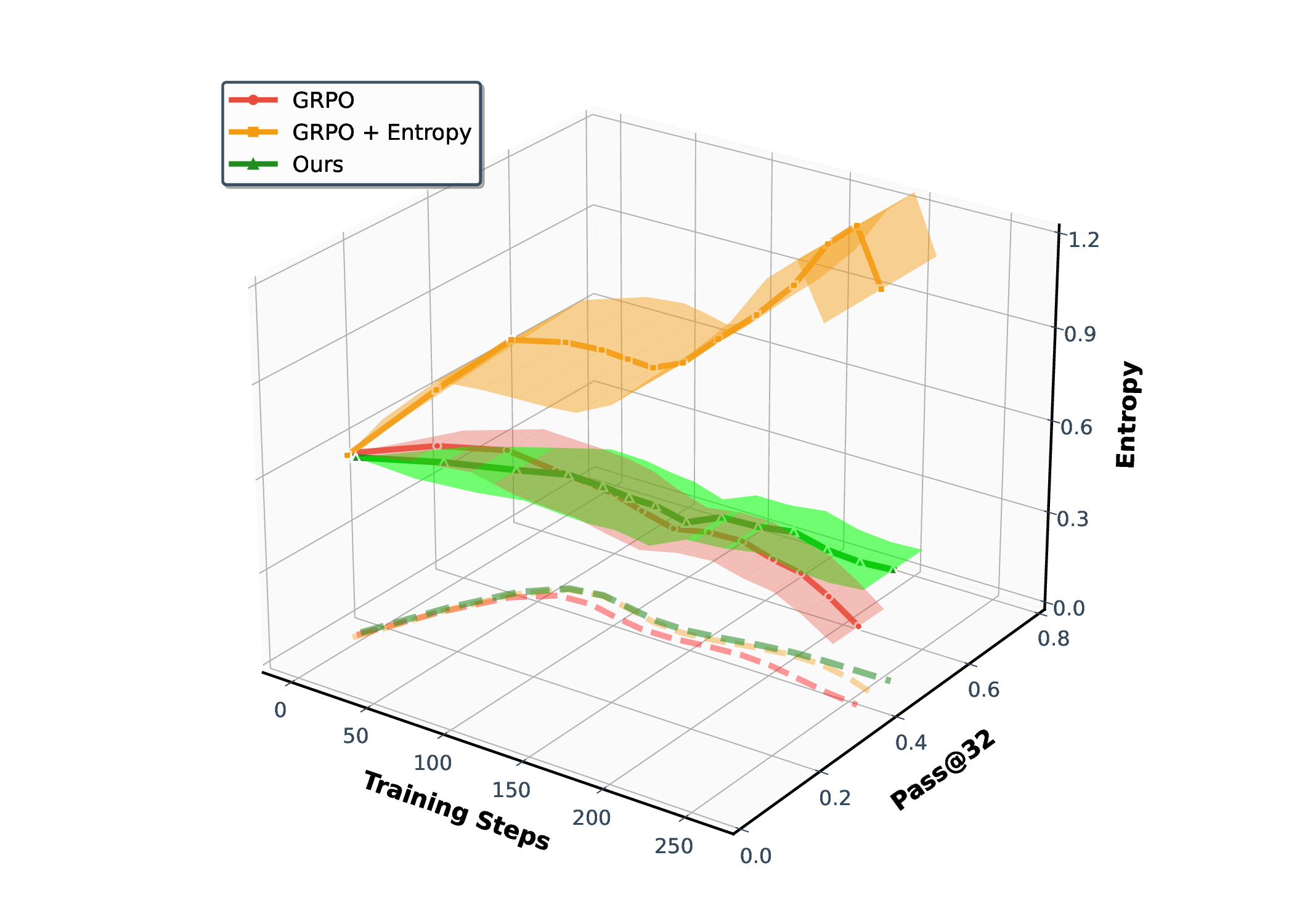
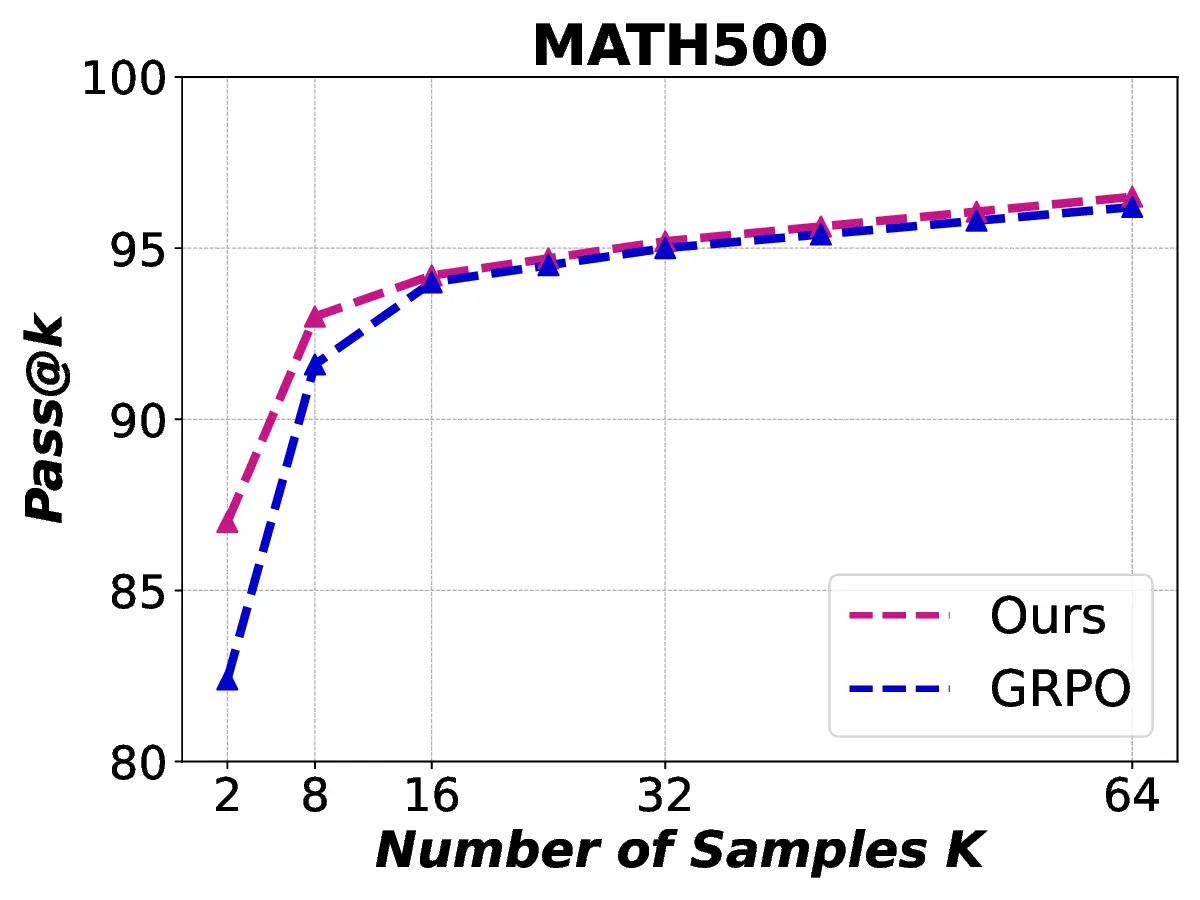
Fig. 1. Learning curves in entropy and Pass@32 during training of SENT compared with GRPO and GRPO with entropy. The shadow is the derivation of the performance of Pass@32 in AIME24 [19] benchmark.
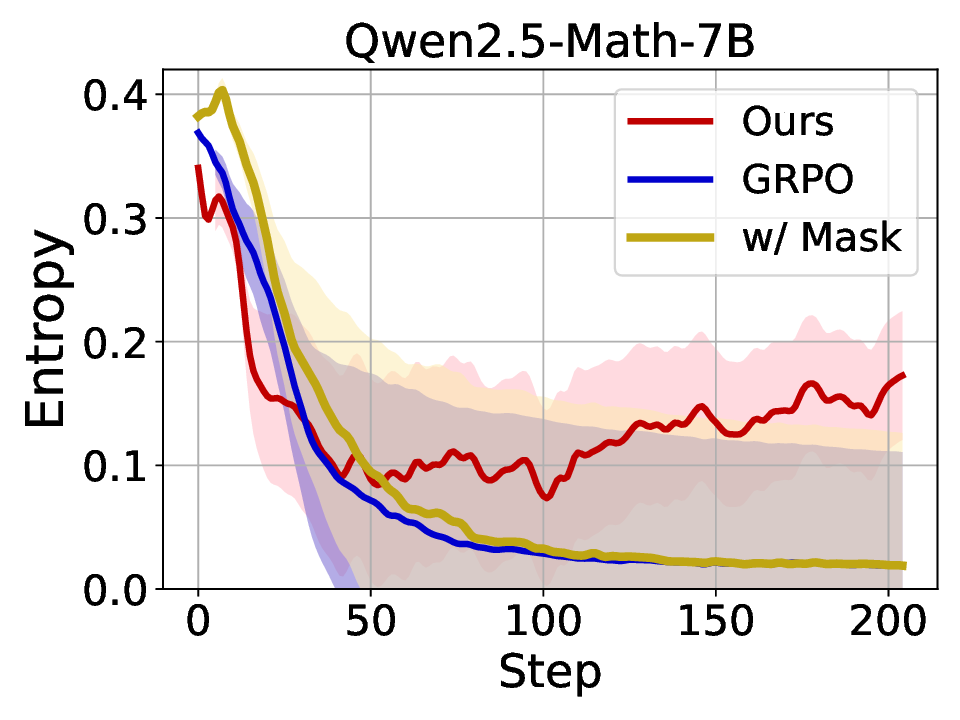
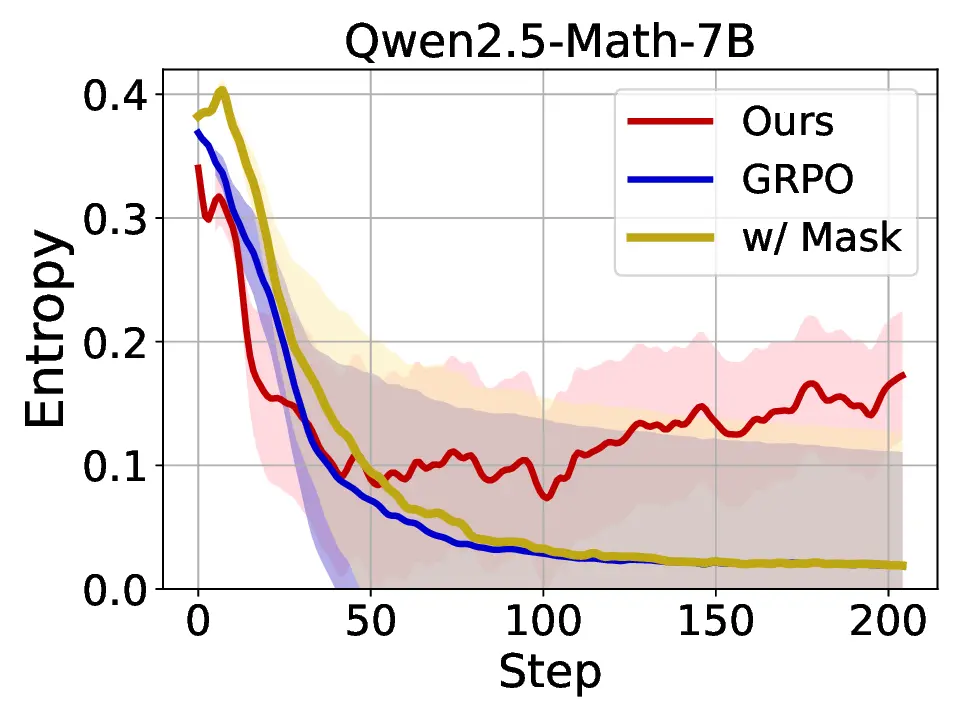
LLMs’ reasoning. These approaches employ various techniques, including dynamic temperature coefficient adjustment based on entropy changes [15], introduction of novel reward signals for optimization [11], [16], suppressing tokens that contribute most to entropy decline [17], and masking lowentropy tokens [18]. While these approaches have shown promising results, they suffer from critical limitations that constrain reasoning. As shown in Fig. 1, GRPO [5] experiences entropy collapse that diminishes exploration capacity, whereas the method that directly incorporates an entropy-maximization objective encounters entropy explosion, resulting in policy instability. These limitations fundamentally arise from entropy fluctuations that destabilize policy learning and manifest through three key issues: First, existing methods [11], [17], [18] focus on local token-level entropy characteristics within individual samples while neglecting the global perspective of training data organization. The difficulty distribution of training samples significantly influences optimization and entropy changes, yet existing works treat all samples equally regardless of their semantic complexity, leading to abrupt difficulty transitions that trigger unstable exploration performance. Second, at the algorithmic level, most approaches [15], [16] apply uniform optimization strategies across all tokens without distinguishing their varying impacts on policy exploration. This one-size-fitsall approach fails to recognize that low-entropy tokens, which directly constrain exploration, require targeted intervention distinct from high-entropy tokens. Third, current approaches lack fine-grained control within tokens. Even among lowentropy tokens, different portions exhibit varying degrees of entropy changes, but existing methods apply homogeneous constraints without adapting to these internal variations. These limitations result in suboptimal exploration strategies that not only fail to comprehensively mitigate entropy collapse but also cannot maintain stable improvement in reasoning, thereby failing to unlock the reasoning potential of LLMs.
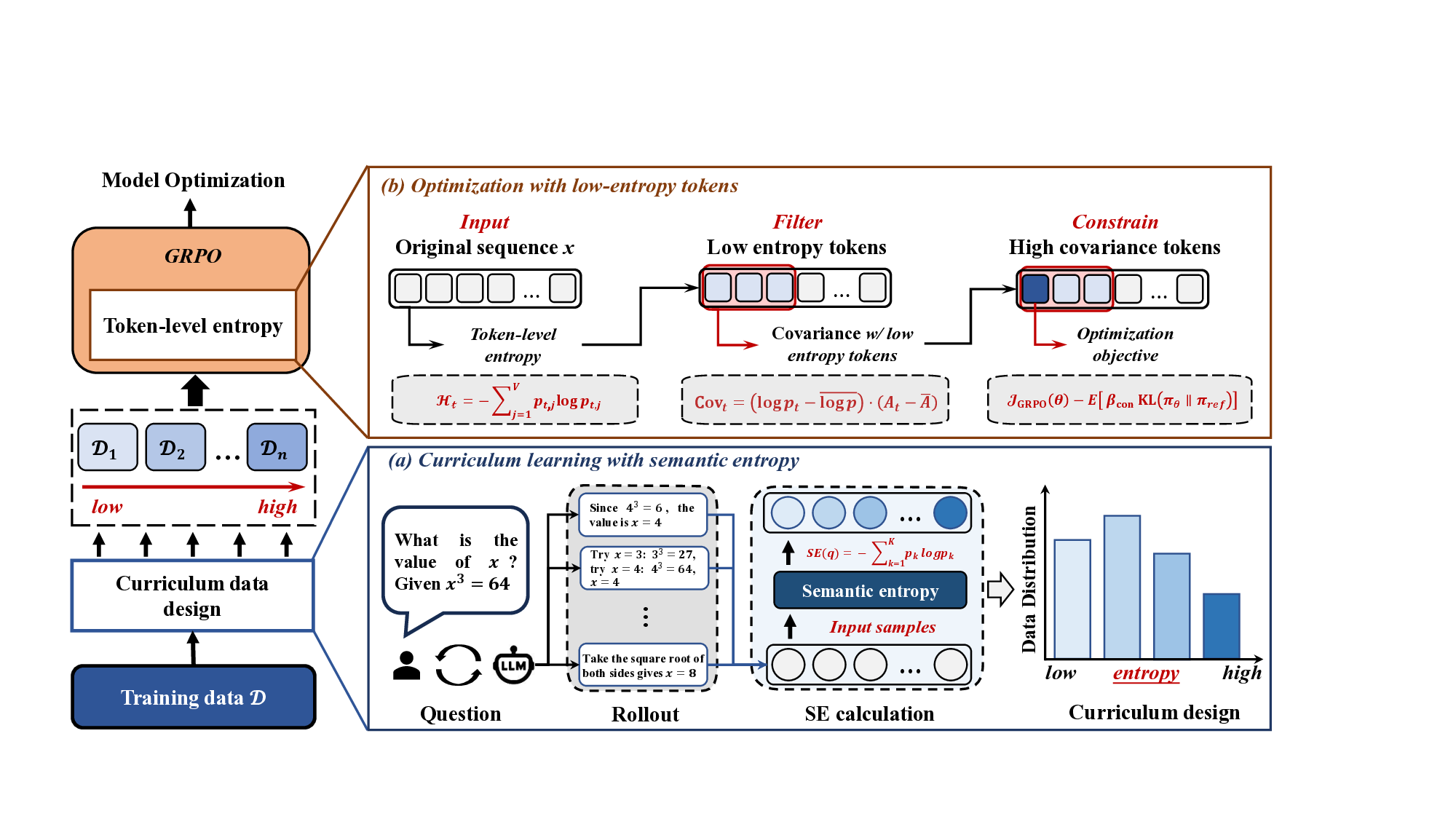
To address these challenges, we propose an efficient reinforcement learning (RL) framework that combines data-level Semantic ENtropy with Token-level entropy optimization (SENT) for enhancing LLM reasoning. SENT is motivated by a fundamental insight: entropy collapse stems from both inadequate data curriculum that fails to scaffold learning complexity and token-level optimization strategies that treat all positions uniformly, ignoring the heterogeneous importance of different tokens in reasoning chains.
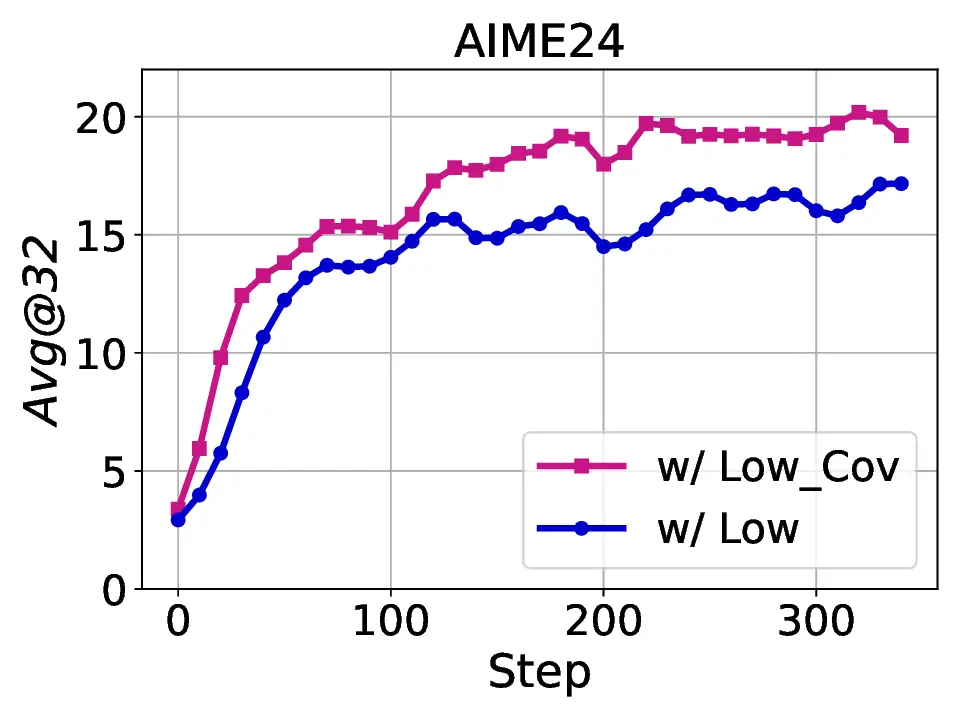
At the data level, we introduce curriculum learning guided by semantic entropy (SE) that organizes training data progressively from low to high entropy, creating a learning process from simpler to complex reasoning tasks. This curriculum design prevents premature convergence by progressively increasing the difficulty of training data, allowing the model to gradually adapt to more complex reasoning tasks. For the algorithmic design, we propose that reasoning chains exhibit inherent structural heterogeneity that low-entropy tokens, which represent near-deterministic decisions, critically constrain the model’s exploration capacity and contribute to entropy collapse. Rather than treating all tokens uniformly, we identify low-entropy tokens and impose KL regularization to prevent over-optimization at these parts. Importantly, we further analyze the internal structure of low-entropy tokens and apply stronger constraints specifically to high-covariance portions within these tokens, where increased uncertainty preservation yields the benefit of maintaining exploration. This fine-grained constraint mechanism encourages targeted exploration at positions that most critically affect po
…(Full text truncated)…
This content is AI-processed based on ArXiv data.