End-to-end autonomous driving (AD) systems increasingly adopt vision-language-action (VLA) models, yet they typically ignore the passenger's emotional state, which is central to comfort and AD acceptance. We introduce Open-Domain End-to-End (OD-E2E) autonomous driving, where an autonomous vehicle (AV) must interpret free-form natural-language commands, infer the emotion, and plan a physically feasible trajectory. We propose E3AD, an emotion-aware VLA framework that augments semantic understanding with two cognitively inspired components: a continuous Valence-Arousal-Dominance (VAD) emotion model that captures tone and urgency from language, and a dual-pathway spatial reasoning module that fuses egocentric and allocentric views for human-like spatial cognition. A consistency-oriented training scheme, combining modality pretraining with preference-based alignment, further enforces coherence between emotional intent and driving actions. Across real-world datasets, E3AD improves visual grounding and waypoint planning and achieves state-of-the-art (SOTA) VAD correlation for emotion estimation. These results show that injecting emotion into VLA-style driving yields more human-aligned grounding, planning, and human-centric feedback.
Deep Dive into E3AD: An Emotion-Aware Vision-Language-Action Model for Human-Centric End-to-End Autonomous Driving.
End-to-end autonomous driving (AD) systems increasingly adopt vision-language-action (VLA) models, yet they typically ignore the passenger’s emotional state, which is central to comfort and AD acceptance. We introduce Open-Domain End-to-End (OD-E2E) autonomous driving, where an autonomous vehicle (AV) must interpret free-form natural-language commands, infer the emotion, and plan a physically feasible trajectory. We propose E3AD, an emotion-aware VLA framework that augments semantic understanding with two cognitively inspired components: a continuous Valence-Arousal-Dominance (VAD) emotion model that captures tone and urgency from language, and a dual-pathway spatial reasoning module that fuses egocentric and allocentric views for human-like spatial cognition. A consistency-oriented training scheme, combining modality pretraining with preference-based alignment, further enforces coherence between emotional intent and driving actions. Across real-world datasets, E3AD improves visual gro
Autonomous driving (AD) has evolved from modular pipelines to vision-language-action end-to-end (E2E) systems that directly map sensor inputs to vehicle controls through unified optimization. This paradigm significantly improves efficiency and adaptability by integrating perception, prediction, and planning into a single learning framework [6,32]. Despite these advances, a fundamental obstacle remains that is not purely technical but human-centered: ensuring public trust and acceptance of fully autonomous driving [78].
While current E2E systems [22,23,48] exhibit strong control and perception capabilities, passengers often feel uneasy about delegating decisions to opaque algorithms that operate without acknowledging human intent or emotion. Surveys [74,75] and behavioral studies [7,36,72] consistently indicate that emotional interaction is a critical determinant of user comfort and perceived safety. However, most existing models [29,31,46,61] are designed for closed-loop rational control and remain insensitive to emotion cues such as anxiety or urgency. This disconnection between compu-tational reasoning and emotional understanding forms what can be described as an emotion gap for autonomous vehicles (AVs). Bridging this gap requires reconsidering the role of human-vehicle interaction in AD. An intelligent system should understand “what” a passenger says and “how” it is expressed. For instance, the tone difference between “stop here” and “stop here now!” carries implicit emotional meaning that influences how the vehicle should respond. Recognizing such differences enables the system to regulate behavior that aligns with the passenger’s emotional state, providing reassurance and enhancing acceptance [25].
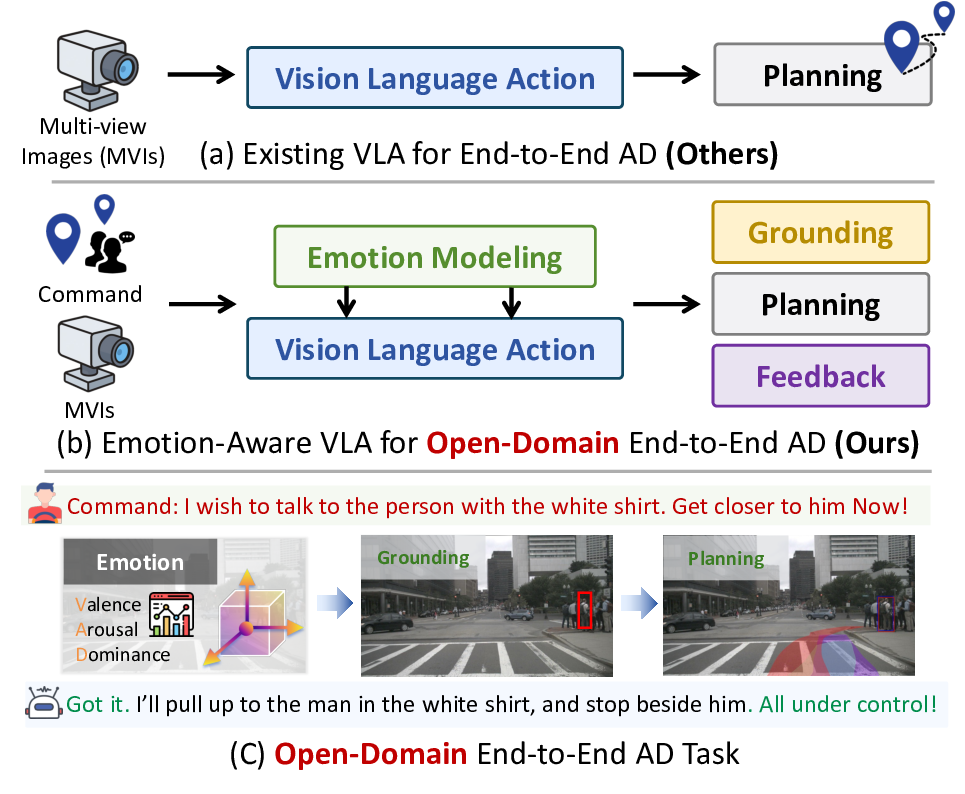
As illustrated in Fig. 1, we extend the conventional E2E AD framework toward a more human-centric paradigm. Future AVs must reason not only over visual and spatial cues but also interpret and respond to natural-language commands that convey the passenger’s intent and emotional state. We define this capability as the task of Open-Domain End-to-End AD (OD-E2E), where the driving agent jointly reasons over semantic content, emotion context, and spatial environment to generate physically realizable trajectories consistent with the passenger’s instructions. This formulation moves Figure 1. Overview of our proposed E3AD framework, contrasted with conventional VLA pipelines. (a) Existing VLA models behave as emotion-agnostic systems, mapping multi-view images directly to a planning output without human-in-the-loop interaction or emotion understanding. (b) Our model adds explicit emotion modeling and closed-loop feedback, allowing the agent to infer intent intensity, ground referents more reliably, and adapt its plan accordingly. (c) This yields the Open-Domain E2E AD task, where the agent jointly reasons over language, emotion, perception, and navigation to enable human-centered and context-aware autonomy.
beyond purely reactive control toward interactive, emotionaware driving assistants that better match human expectations and preferences, transforming AVs from passive executors into empathetic and user-aligned driving agents [32].
Technically, our approach builds on the emerging Vision-Language-Action (VLA) paradigm [53], which unifies perception, reasoning, and control through large-scale multimodal modeling. By coupling visual and linguistic representations, VLA frameworks enable agents to perform complex goal-driven behaviors with improved generalization, interpretability, and alignment to human intent. Following this paradigm, we propose an Emotion-aware End-to-End Autonomous Driving framework, E3AD, which extends VLA from purely semantic understanding to emotion and spatially consistent reasoning. To enhance cognitive capability, E3AD incorporates two key components within a unified pipeline: (1) Emotion Modeling, which maps commands into a continuous Valence-Arousal-Dominance (VAD) space [17] to interpret emotional tone and behavioral urgency; and (2) Spatial Reasoning, which fuses egocentric and allocentric pathways to achieve human-like spatial cognition. These components are jointly optimized through a consistencyoriented learning strategy that enforces coherence between the semantic and emotional context of the command and the resulting trajectory. This design enables E3AD to reason jointly over what the passenger intends and how it is expressed, producing emotion-aware and human-aligned driving behaviors in a fully E2E manner. From a safety perspective, modulating behavior according to passenger state decouples request satisfaction from the safety envelope, which is essential for calibrated trust in E2E AD.
Overall, the contributions of this study are threefold: • We define Open-Domain End-to-End AD for human-centric AVs, which unifies semantic, emotional, and spatial reasoning from natural-language commands. • We propose E3AD, an emotion-aware VLA framework that integrates continuous emotion mod
…(Full text truncated)…
This content is AI-processed based on ArXiv data.