📝 Original Info
- Title: The Erosion of LLM Signatures: Can We Still Distinguish Human and LLM-Generated Scientific Ideas After Iterative Paraphrasing?
- ArXiv ID: 2512.05311
- Date: 2025-12-04
- Authors: Sadat Shahriar, Navid Ayoobi, Arjun Mukherjee
📝 Abstract
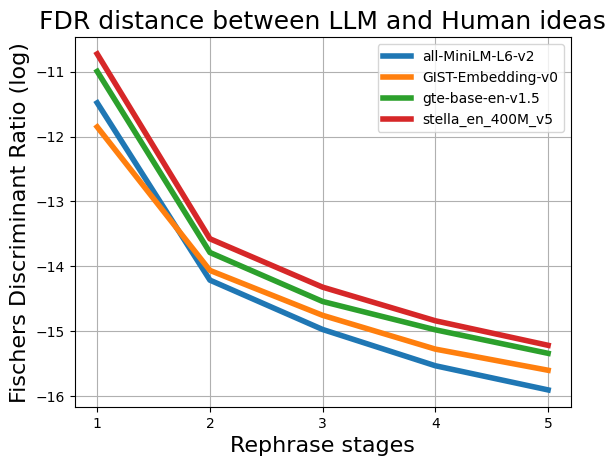
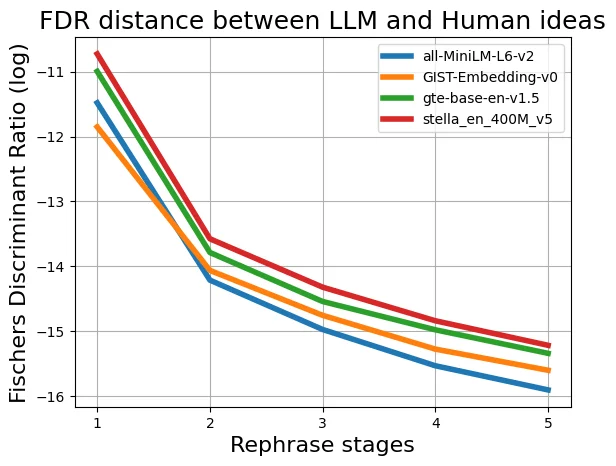
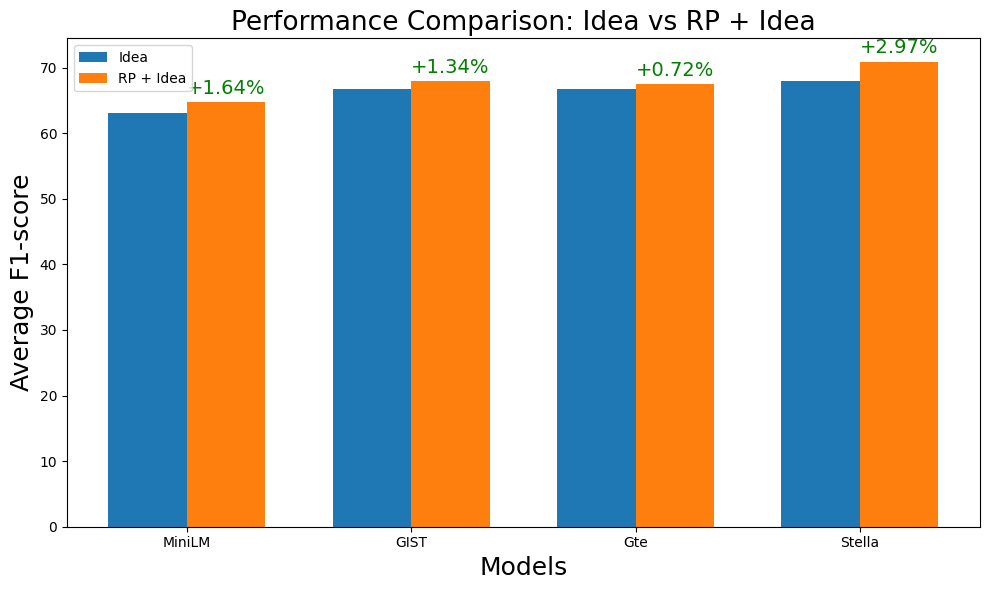
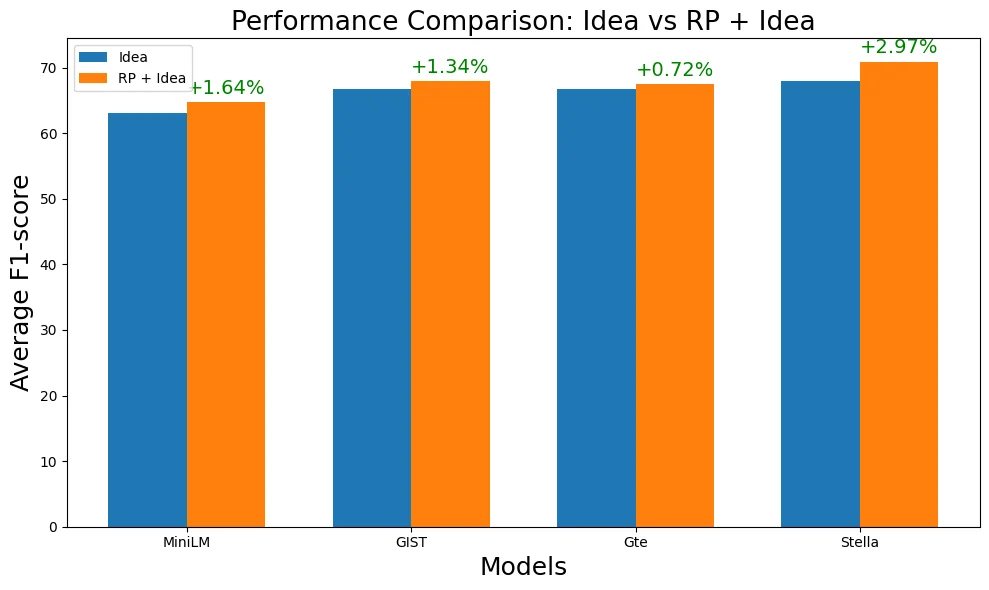
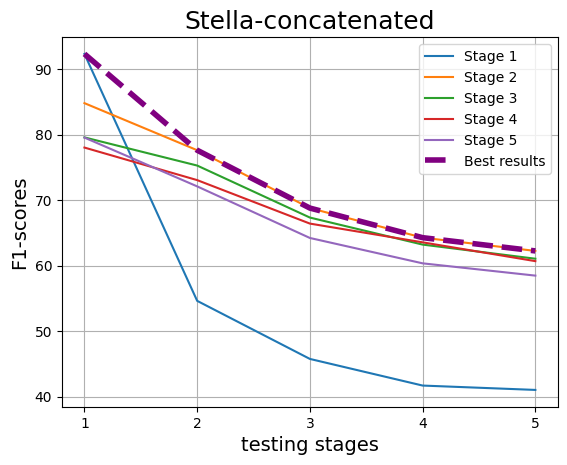
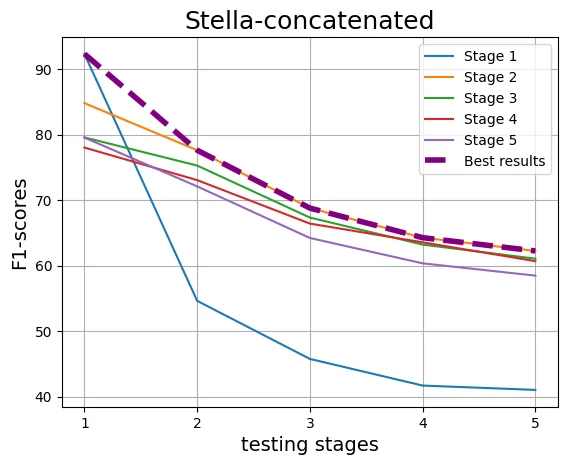
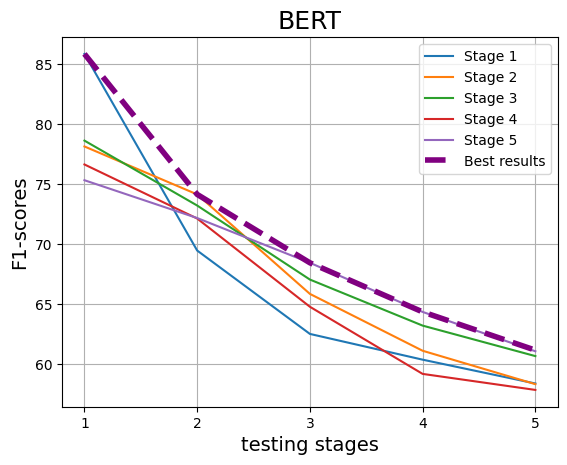
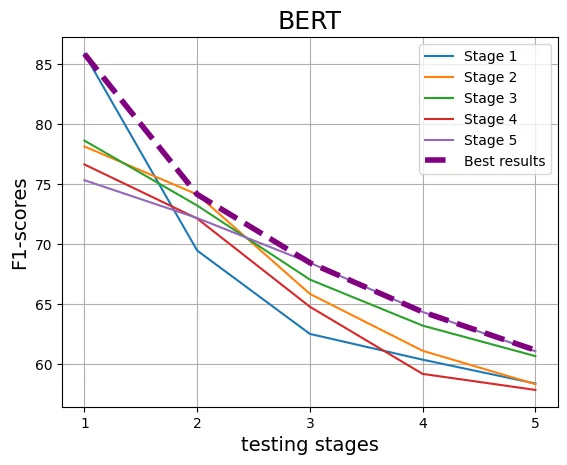
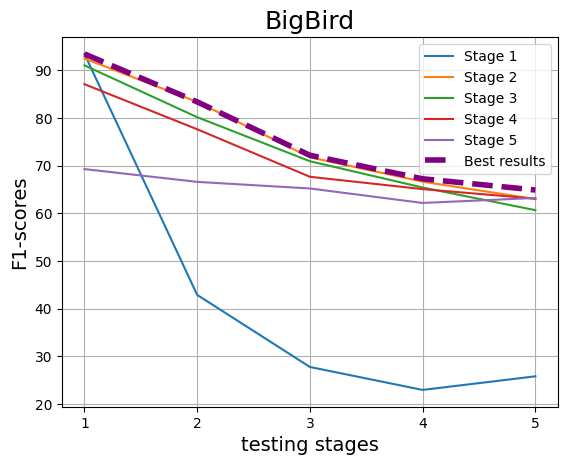
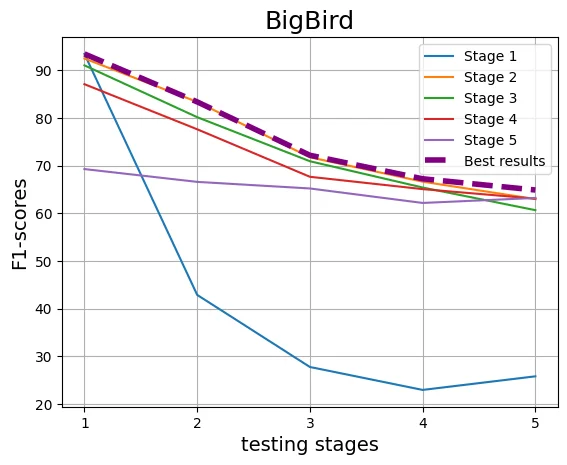
With the increasing reliance on LLMs as research agents, distinguishing between LLM and human-generated ideas has become crucial for understanding the cognitive nuances of LLMs' research capabilities. While detecting LLM-generated text has been extensively studied, distinguishing human vs LLM-generated scientific ideas remains an unexplored area. In this work, we systematically evaluate the ability of state-of-the-art (SOTA) machine learning models to differentiate between human and LLM-generated ideas, particularly after successive paraphrasing stages. Our findings highlight the challenges SOTA models face in source attribution, with detection performance declining by an average of 25.4% after five consecutive paraphrasing stages. Additionally, we demonstrate that incorporating the research problem as contextual information improves detection performance by up to 2.97%. Notably, our analysis reveals that detection algorithms struggle significantly when ideas are paraphrased into a simplified, non-expert style, contributing the most to the erosion of distinguishable LLM signatures.
💡 Deep Analysis
Deep Dive into The Erosion of LLM Signatures: Can We Still Distinguish Human and LLM-Generated Scientific Ideas After Iterative Paraphrasing?.
With the increasing reliance on LLMs as research agents, distinguishing between LLM and human-generated ideas has become crucial for understanding the cognitive nuances of LLMs’ research capabilities. While detecting LLM-generated text has been extensively studied, distinguishing human vs LLM-generated scientific ideas remains an unexplored area. In this work, we systematically evaluate the ability of state-of-the-art (SOTA) machine learning models to differentiate between human and LLM-generated ideas, particularly after successive paraphrasing stages. Our findings highlight the challenges SOTA models face in source attribution, with detection performance declining by an average of 25.4% after five consecutive paraphrasing stages. Additionally, we demonstrate that incorporating the research problem as contextual information improves detection performance by up to 2.97%. Notably, our analysis reveals that detection algorithms struggle significantly when ideas are paraphrased into a sim
📄 Full Content
The Erosion of LLM Signatures: Can We Still Distinguish Human and
LLM-Generated Scientific Ideas After Iterative Paraphrasing?
Sadat Shahriar, Navid Ayoobi, Arjun Mukherjee
University of Houston, Texas, USA
sadat.shrr@gmail.com, nayoobi@cougarnet.uh.edu, arjun@cs.uh.edu
Abstract
With the increasing reliance on LLMs as re-
search agents, distinguishing between LLM
and human-generated ideas has become cru-
cial for understanding the cognitive nuances of
LLMs’ research capabilities. While detecting
LLM-generated text has been extensively stud-
ied, distinguishing human vs LLM-generated
scientific ideas remains an unexplored area. In
this work, we systematically evaluate the abil-
ity of state-of-the-art (SOTA) machine learn-
ing models to differentiate between human
and LLM-generated ideas, particularly after
successive paraphrasing stages. Our findings
highlight the challenges SOTA models face in
source attribution, with detection performance
declining by an average of 25.4% after five
consecutive paraphrasing stages. Additionally,
we demonstrate that incorporating the research
problem as contextual information improves
detection performance by up to 2.97%. No-
tably, our analysis reveals that detection algo-
rithms struggle significantly when ideas are
paraphrased into a simplified, non-expert style,
contributing the most to the erosion of distin-
guishable LLM signatures.
1
Introduction
Recent advances in LLMs have demonstrated ex-
traordinary capabilities extending far beyond mun-
dane conversational tasks (Boiko et al., 2023; Zhao
et al., 2023a). Notably, these models can even en-
gage in complex cognitive activities traditionally
reserved for human intellect, such as hypothesis
generation, reasoning, and scientific inquiry (Boiko
et al., 2023; Si et al., 2024). This remarkable de-
velopment raises a fundamental question: Given
humanity’s millennia-long tradition of knowledge
creation and dissemination– and the subsequent
encoding into vast linguistic datasets: can we still
reliably discern whether novel ideas originate from
humans or are algorithmically produced by LLMs?
Si et al. showed that LLMs can generate more
novel ideas compared to human experts, though
these ideas are not always practically feasible (Si
et al., 2024). While novelty definitions carry inher-
ent subjectivity, on a broader scale, LLMs still ex-
hibit significant capability in producing innovative
research ideas. As such, distinguishing between
ideas generated by LLMs vs humans becomes in-
creasingly important, as it provides deeper insights
into LLM cognitive patterns, ensures academic in-
tegrity, and aids in maintaining transparency by
clearly attributing authorship, ultimately influenc-
ing trust in scholarly contributions and guiding re-
sponsible AI deployment in research contexts.
While
prior
research
on
detecting
LLM-
generated text has focused on watermarking (Zhao
et al., 2023b), zero-shot methods (Yang et al., 2023;
Mitchell et al., 2023), and fine-tuned classifiers
(Hu et al., 2023), our study takes a fundamentally
different approach. Rather than identifying LLM-
generated text, we examine the resilience of ideas–
which persist beyond surface-level writing styles.
Unlike text, ideas are conceptually immutable; a
human-conceived idea remains human in essence,
even if heavily paraphrased by an LLM. We in-
vestigate whether these underlying origins: human
or LLM—remain detectable after successive para-
phrasing and stylistic transformations. To the best
of our knowledge, this is the first study to explore
scientific idea attribution in such a nuanced and
dynamic setting.
Ideas manifest across diverse contexts, but in
this research, we define an “idea” specifically as
a proposed solution addressing a given research
problem, using ‘scientific idea’ and ‘idea’ inter-
changeably. Scientific ideas inherently reflect nu-
anced thinking and careful planning, which distin-
guishes them from mere linguistic outputs. For-
mally, given a research problem RP, an idea can
be represented as a response r = f(RP), where
f denotes either human or LLM generation. To
evaluate whether the essence of human or LLM-
generated ideas persists through stylistic variations,
arXiv:2512.05311v1 [cs.LG] 4 Dec 2025
Figure 1: Idea Generation and Paraphrasing Workflow: The process begins with extracting the Research Problem
from papers and then generate corresponding scientific ideas using six different LLMs. Both human and LLM-
generated ideas are first summarized and subsequently paraphrased across five stages using four distinct paraphrasing
techniques (To reduce visual clutter and redundancy, we abstracted Stages 3 and 4, as they represent similar
paraphrasing strategies).
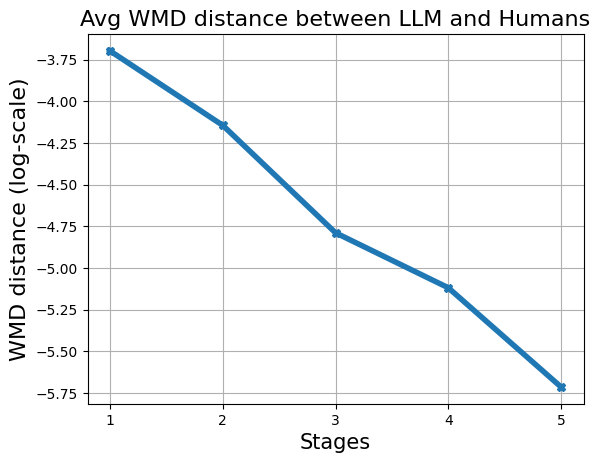
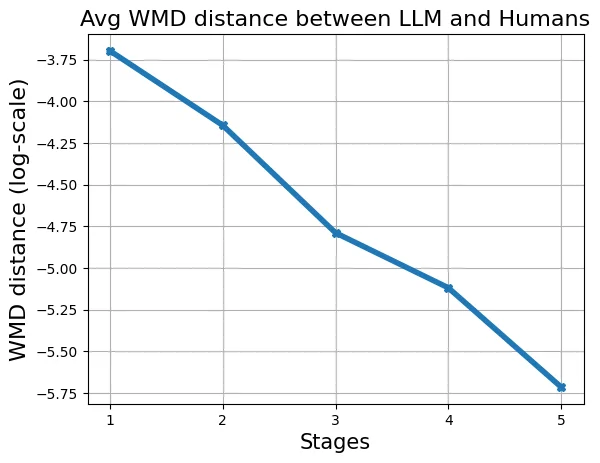
we iteratively paraphrase these ideas through mul-
tiple stages. At each paraphrasing stage n, the idea
transforms as rn = fpn(rn−1, RP). Paraphrasing
serves two critical purposes: firstly, in real-world
scenarios, ideas are communicated through var-
ied expressions and settings—yet
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.