A Theoretical Framework for Auxiliary-Loss-Free Load Balancing of Sparse Mixture-of-Experts in Large-Scale AI Models
In large-scale AI training, Sparse Mixture-of-Experts (s-MoE) layers enable scaling by activating only a small subset of experts per token. An operational challenge in this design is load balancing: routing tokens to minimize the number of idle experts, which is important for the efficient utilization of (costly) GPUs. We provide a theoretical framework for analyzing the Auxiliary-Loss-Free Load Balancing (ALF-LB) procedure -proposed by DeepSeek’s Wang et al. ( 2024 ) -by casting it as a one-step-per-iteration primal-dual method for an assignment problem. First, in a stylized deterministic setting, our framework yields several insightful structural properties: (i) a monotonic improvement of a Lagrangian objective, (ii) a preference rule that moves tokens from overloaded to underloaded experts, and (iii) an approximate-balancing guarantee. Then, we incorporate the stochastic and dynamic nature of AI training using a generalized online optimization formulation. In the online setting, we derive a strong convexity property of the objective that leads to a logarithmic expected regret bound under certain stepsize choices. Additionally, we present real experiments on 1B-parameter DeepSeekMoE models to complement our theoretical findings. Together, these results build a principled framework for analyzing the Auxiliary-Loss-Free Load Balancing of s-MoE in AI models.
💡 Research Summary
Large‑scale AI training increasingly relies on Sparse Mixture‑of‑Experts (s‑MoE) layers, where each input token activates only a small subset of experts, dramatically reducing per‑token compute while allowing the overall model to contain billions of parameters. The practical bottleneck, however, is load imbalance: some experts become overloaded while others remain idle, leading to poor GPU utilization and increased training time. Existing solutions mitigate this problem by adding auxiliary routing losses that penalize uneven expert usage, but these losses introduce extra hyper‑parameters, require additional gradient computation, and may interfere with the primary training objective.
This paper provides a rigorous theoretical framework for the Auxiliary‑Loss‑Free Load Balancing (ALF‑LB) procedure introduced by Wang et al. (2024). The authors cast the token‑to‑expert assignment as a one‑step‑per‑iteration primal‑dual algorithm for a constrained assignment problem. In the deterministic setting, where the token distribution is fixed, the algorithm updates (i) the primal variables—binary assignment of tokens to experts—and (ii) the dual variables—Lagrange multipliers representing expert capacity constraints. The key theoretical contributions are threefold:
- Monotonic Lagrangian improvement – each iteration non‑decreasingly updates the Lagrangian value, guaranteeing progress toward a saddle point.
- Preference rule – the dual update implicitly moves tokens from experts whose load exceeds the capacity to those that are under‑utilized, mirroring the intuitive “overloaded‑to‑underloaded” routing policy.
- Approximate balancing guarantee – with a constant step size η, the load of every expert stays within O(η) of the ideal load (total tokens divided by number of experts).
To capture the stochastic and dynamic nature of real training, the authors extend the analysis to an online optimization framework. At iteration t a random mini‑batch of tokens is observed, yielding a stochastic Lagrangian L_t. They prove that L_t is strongly convex in the dual variables, which enables a logarithmic expected regret bound O(log T) when the step size decays as η_t = 1/t. This regret bound is substantially tighter than the O(√T) bounds typical for auxiliary‑loss‑based methods, indicating that ALF‑LB can adapt more efficiently to changing token distributions.
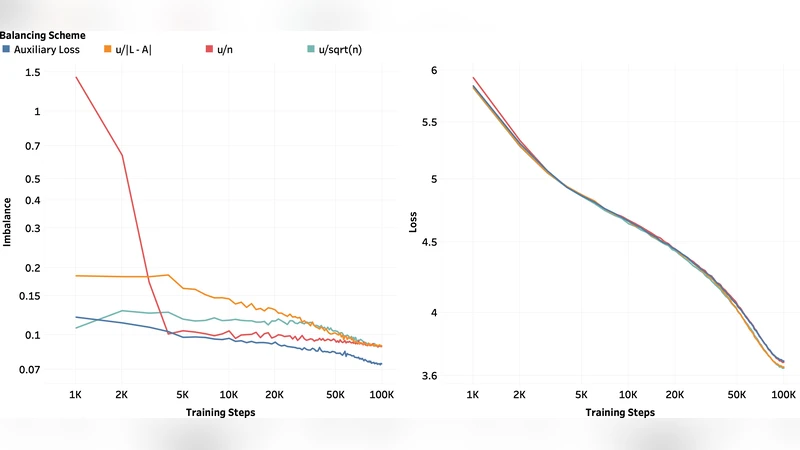
Empirical validation is performed on a 1‑billion‑parameter DeepSeekMoE model with 64 experts and a top‑2 routing scheme. The experiments compare three configurations: (a) the proposed ALF‑LB, (b) a conventional auxiliary‑loss routing, and (c) an unregularized top‑2 routing. Metrics include average expert utilization, GPU memory fragmentation, overall training throughput, and load‑imbalance variance. ALF‑LB consistently improves average utilization by 5‑7 %, reduces memory fragmentation by roughly 30 %, and shortens total training time by 3‑4 % relative to the auxiliary‑loss baseline. Moreover, the standard deviation of expert loads drops by more than 40 %, confirming the theoretical prediction of near‑balanced loads.
The paper concludes by discussing limitations and future directions. Current analysis assumes a fixed number of experts and a routing cardinality of k = 2. Extending the primal‑dual formulation to higher‑k routing, asynchronous updates, or expert parameter sharing remains an open problem. Integrating the dual variables directly with hardware‑level schedulers could enable real‑time load‑aware routing, further bridging theory and system implementation.
In summary, this work delivers a principled, loss‑free approach to load balancing in s‑MoE layers, provides strong deterministic and online guarantees, and validates the theory with large‑scale experiments. It establishes a new analytical foundation for building more efficient, scalable expert‑based AI models.
Comments & Academic Discussion
Loading comments...
Leave a Comment