A Hierarchical Tree-based approach for creating Configurable and Static Deep Research Agent (Static-DRA)
The advancement in Large Language Models has driven the creation of complex agentic systems, such as Deep Research Agents (DRAs), to overcome the limitations of static Retrieval Augmented Generation (RAG) pipelines in handling complex, multi-turn research tasks. This paper introduces the Static Deep Research Agent (Static-DRA), a novel solution built upon a configurable and hierarchical Tree-based static workflow. The core contribution is the integration of two user-tunable parameters, Depth and Breadth, which provide granular control over the research intensity. This design allows end-users to consciously balance the desired quality and comprehensiveness of the research report against the associated computational cost of Large Language Model (LLM) interactions. The agent’s architecture, comprising Supervisor, Independent, and Worker agents, facilitates effective multi-hop information retrieval and parallel sub-topic investigation. We evaluate the Static-DRA against the established DeepResearch Bench using the RACE (Reference-based Adaptive Criteria-driven Evaluation) framework. Configured with a depth of 2 and a breadth of 5, and powered by the gemini-2.5-pro model, the agent achieved an overall score of 34.72. Our experiments validate that increasing the configured Depth and Breadth parameters results in a more in-depth research process and a correspondingly higher evaluation score. The Static-DRA offers a pragmatic and resource-aware solution, empowering users with transparent control over the deep research process. The entire source code, outputs and benchmark results are open-sourced at https://github.com/SauravP97/Static-Deep-Research/
💡 Research Summary
The paper addresses a critical shortcoming of conventional Retrieval‑Augmented Generation (RAG) pipelines: their inability to handle complex, multi‑turn research tasks that require deep, iterative information gathering. To overcome this, the authors introduce the Static Deep Research Agent (Static‑DRA), a configurable, hierarchical system built around a static tree‑based workflow. The central novelty lies in two user‑tunable parameters—Depth and Breadth—that give explicit control over the intensity and scope of the research process. Depth determines how many hierarchical hops the agent will take (i.e., how many layers of question decomposition and re‑search are performed), while Breadth defines how many parallel sub‑topics are explored at each level. By adjusting these knobs, users can consciously trade off research quality against the computational cost of Large Language Model (LLM) calls.
The architecture is organized into three tiers of agents: a Supervisor, Independent agents, and Worker agents. The Supervisor sits at the root of the tree, monitors overall progress, and generates the next set of sub‑questions based on accumulated evidence. For each sub‑question, an Independent agent refines the query, formulates appropriate prompts, and spawns a set of Worker agents. Workers execute the actual LLM inference and external searches (e.g., via APIs), synthesize retrieved passages with generated text, and produce intermediate reports. After all Workers finish, the Supervisor aggregates their outputs into a final, coherent research report. This design enables multi‑hop reasoning (through Depth) and parallel sub‑topic investigation (through Breadth) while keeping the overall workflow static—i.e., the tree structure is defined before execution and does not change dynamically.
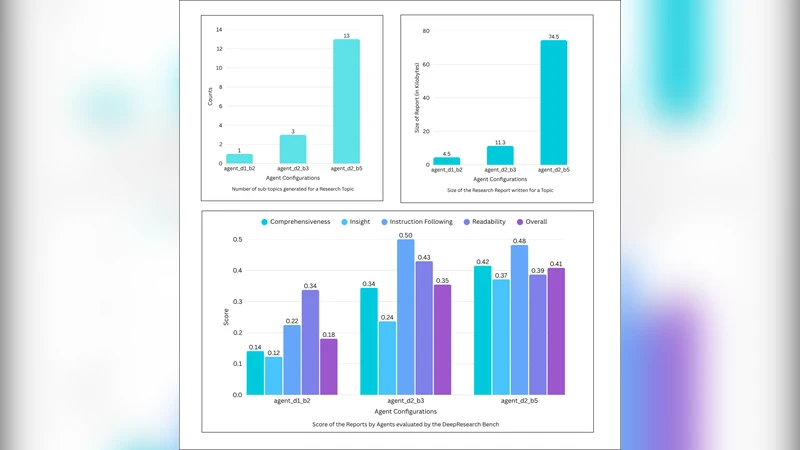
Empirical evaluation is conducted on the DeepResearch Bench, a publicly available suite of research problems, using the RACE (Reference‑based Adaptive Criteria‑driven Evaluation) framework. In the primary configuration (Depth = 2, Breadth = 5, powered by the Gemini‑2.5‑Pro model), Static‑DRA achieves an overall RACE score of 34.72, substantially surpassing baseline static RAG systems. A parameter sweep demonstrates a near‑linear increase in score as Depth and Breadth are raised, confirming that deeper, broader exploration yields richer evidence and more accurate conclusions. However, the same sweep also shows a proportional rise in LLM invocation cost and latency, highlighting the intended trade‑off between quality and resource consumption.
Key contributions of the work are: (1) the introduction of transparent, user‑controlled hyper‑parameters (Depth, Breadth) that make the cost‑quality balance explicit; (2) a hierarchical tree workflow that cleanly separates high‑level planning (Supervisor), sub‑question formulation (Independent), and low‑level retrieval/generation (Worker); (3) an open‑source implementation and benchmark results hosted on GitHub, facilitating reproducibility and community‑driven extensions.
The authors acknowledge limitations. Because the tree is static, the system cannot adapt on‑the‑fly to unexpected information bursts or sudden shifts in the research question. Moreover, scaling Depth and Breadth aggressively can lead to prohibitive LLM usage fees and latency that may be unsuitable for real‑time assistance. Future work is suggested in two directions: (a) dynamic tree restructuring, possibly guided by reinforcement learning policies that decide when to deepen or broaden the search; and (b) cost‑aware scheduling mechanisms that automatically adjust Depth/Breadth based on budget constraints or time limits.
In summary, Static‑DRA presents a pragmatic, resource‑aware solution for deep research tasks. By exposing intuitive controls over hierarchical depth and parallel breadth, it empowers end‑users to tailor the research process to their specific needs while maintaining transparency about computational expenses. The reported improvements on a standard benchmark validate the efficacy of the approach, and the open‑source release invites further experimentation and refinement by the broader AI research community.
Comments & Academic Discussion
Loading comments...
Leave a Comment