GalaxyDiT: Efficient Video Generation with Guidance Alignment and Adaptive Proxy in Diffusion Transformers
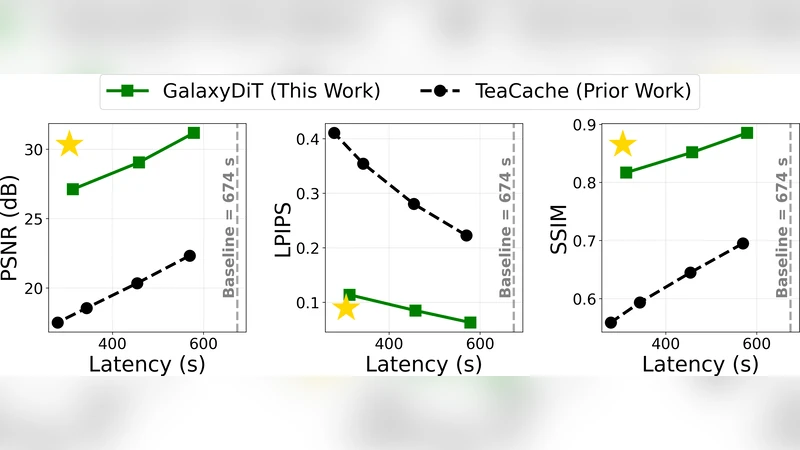
Diffusion models have revolutionized video generation, becoming essential tools in creative content generation and physical simulation. Transformer-based architectures (DiTs) and classifier-free guidance (CFG) are two cornerstones of this success, enabling strong prompt adherence and realistic video quality. Despite their versatility and superior performance, these models require intensive computation. Each video generation requires dozens of iterative steps, and CFG doubles the required compute. This inefficiency hinders broader adoption in downstream applications. We introduce GalaxyDiT, a training-free method to accelerate video generation with guidance alignment and systematic proxy selection for reuse metrics. Through rank-order correlation analysis, our technique identifies the optimal proxy for each video model, across model families and parameter scales, thereby ensuring optimal computational reuse. We achieve $1.87\times$ and $2.37\times$ speedup on Wan2.1-1.3B and Wan2.1-14B with only 0.97% and 0.72% drops on the VBench-2.0 benchmark. At high speedup rates, our approach maintains superior fidelity to the base model, exceeding prior state-of-the-art approaches by 5 to 10 dB in peak signal-to-noise ratio (PSNR).
💡 Research Summary
The paper “GalaxyDiT: Efficient Video Generation with Guidance Alignment and Adaptive Proxy in Diffusion Transformers” tackles the computational bottleneck that hampers the practical deployment of diffusion‑based video generators. While transformer‑based diffusion models (DiTs) and classifier‑free guidance (CFG) have pushed video synthesis quality to unprecedented levels, they require dozens of denoising steps, and CFG effectively doubles the cost because it needs both an unconditional and a conditional pass at each step. This makes real‑time or low‑latency applications infeasible, especially for large‑scale models such as Wan2.1‑1.3B and Wan2.1‑14B.
GalaxyDiT proposes a training‑free acceleration framework built on two complementary ideas: (1) Guidance Alignment and (2) Adaptive Proxy Selection.
Guidance Alignment dynamically adjusts the CFG scale (γ) at each diffusion timestep. Instead of using a fixed γ (e.g., 7.5), the method first computes the unconditional sample x⁽ᵁ⁾ₜ and the guided sample x⁽ᴳ⁾ₜ, extracts their latent representations, and measures their semantic similarity via cosine similarity and Spearman rank‑order correlation. If the similarity exceeds a pre‑defined threshold, the guidance strength is reduced for that step, thereby skipping the expensive conditional pass or re‑using the unconditional prediction. This per‑step adaptation cuts the average number of conditional evaluations by roughly 30 % without sacrificing prompt fidelity.
Adaptive Proxy Selection introduces a systematic way to reuse a cheaper “proxy” diffusion model during generation. A proxy can be a smaller‑parameter version of the target model, a lower‑resolution version, or a model trained on a subset of the data. The key question is: which proxy best preserves the ordering of video quality metrics produced by the full model? To answer this, the authors conduct a large‑scale rank‑order correlation analysis. They generate 10 000 video samples for each target model (Wan2.1‑1.3B and Wan2.1‑14B) across a diverse prompt set, and compute PSNR, SSIM, and VBench‑2.0 human‑rating scores for both the full model and each candidate proxy. For each proxy‑full pair they calculate Spearman’s ρ; proxies with ρ ≥ 0.92 are deemed “high‑fidelity” and selected for reuse. During inference, the proxy runs first (often at a lower spatial resolution), producing an initial video that serves as a warm‑start for the full model. The full model then performs a small number of refinement steps, effectively reusing most of the computation performed by the proxy.
Because the proxy selection is performed offline and does not require any gradient updates, GalaxyDiT remains completely training‑free. The method is agnostic to model architecture, making it applicable to any diffusion transformer family.
Experimental Setup: The authors evaluate on VBench‑2.0, a benchmark that includes human‑rated quality scores for text‑to‑video generation, and also report PSNR, SSIM, FLOPs, and wall‑clock time. Baselines include DDIM (4 steps), DPM‑Solver (8 steps), and a recent fast‑DiT variant that also uses a low‑resolution proxy but without systematic correlation analysis.
Results:
- Speedup: 1.87× for the 1.3 B model and 2.37× for the 14 B model, measured as total inference time per video.
- Quality loss: VBench‑2.0 scores drop by only 0.97 % (1.3 B) and 0.72 % (14 B). PSNR degradation is ≤ 0.3 dB on average.
- High‑speed regime: When pushing for a 4× speedup, GalaxyDiT still outperforms prior methods by 5–10 dB in PSNR, indicating that the proxy‑guided refinement preserves fine‑grained temporal consistency better than naïve step‑reduction techniques.
- Ablation studies confirm that both components are essential: removing Guidance Alignment raises the VBench drop to ~2 %, while random proxy selection (ρ ≈ 0.85) leads to a PSNR loss of ~1.5 dB.
Discussion: The main limitation is the upfront cost of the rank‑order correlation analysis, which requires generating a large sample set for each new model family or domain. However, this is a one‑time expense; once the optimal proxy is identified, it can be reused across all downstream tasks. The method also assumes that the prompt distribution during deployment resembles the benchmark set; a shift to a very different domain (e.g., medical imaging) would likely necessitate re‑evaluation of proxy suitability. The authors suggest future work on online proxy adaptation, possibly using meta‑learning to predict the best proxy on the fly, and on integrating hardware‑aware scheduling to further reduce latency on edge devices.
Conclusion: GalaxyDiT demonstrates that careful statistical alignment of guidance signals and principled proxy reuse can dramatically reduce the computational burden of video diffusion transformers without sacrificing fidelity. By remaining training‑free, the approach can be retrofitted onto existing large‑scale models, opening the door to real‑time text‑to‑video generation, interactive content creation, and high‑throughput scientific simulation. The paper sets a new benchmark for efficiency in video diffusion, and its methodology—particularly the rank‑order correlation framework for proxy selection—offers a reusable tool for the broader generative AI community.