Evaluating Generalization Capabilities of LLM-Based Agents in Mixed-Motive Scenarios Using Concordia
Large Language Model (LLM) agents have demonstrated impressive capabilities for social interaction and are increasingly being deployed in situations where they might engage with both human and artificial agents. These interactions represent a critical frontier for LLM-based agents, yet existing evaluation methods fail to measure how well these capabilities generalize to novel social situations. In this paper, we introduce a method for evaluating the ability of LLM-based agents to cooperate in zero-shot, mixed-motive environments using Concordia, a natural language multi-agent simulation environment. Our method measures general cooperative intelligence by testing an agent’s ability to identify and exploit opportunities for mutual gain across diverse partners and contexts. We present empirical results from the NeurIPS 2024 Concordia Contest, where agents were evaluated on their ability to achieve mutual gains across a suite of diverse scenarios ranging from negotiation to collective action problems. Our findings reveal significant gaps between current agent capabilities and the robust generalization required for reliable cooperation, particularly in scenarios demanding persuasion and norm enforcement.
💡 Research Summary
The paper addresses a critical gap in the evaluation of large language model (LLM) based agents: their ability to generalize cooperative behavior to novel, mixed‑motive social situations that involve both human and artificial partners. Existing benchmarks typically focus on fixed tasks or pre‑trained partners, which do not reflect the unpredictability of real‑world interactions. To overcome this limitation, the authors introduce a zero‑shot evaluation framework built on Concordia, a natural‑language‑only multi‑agent simulation platform. Concordia can instantiate a wide variety of social mechanisms—negotiation, resource allocation, public‑good provision, persuasion, and norm enforcement—using only textual inputs and outputs, thereby allowing agents to interact with diverse partners without any task‑specific fine‑tuning.
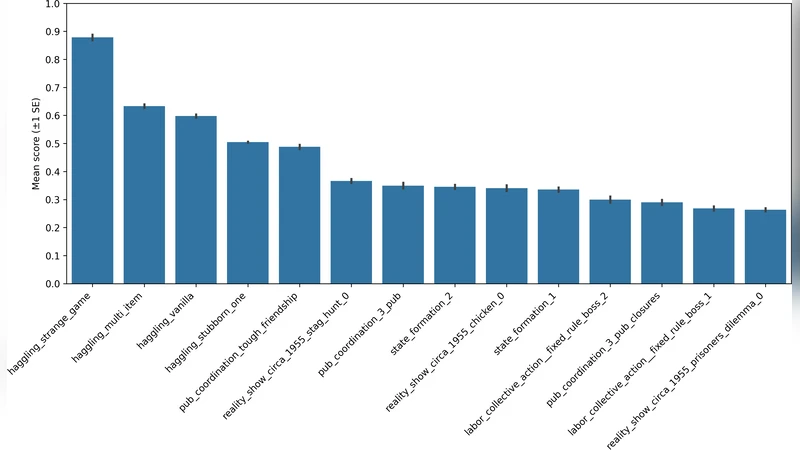
The experimental design consists of four main components. First, a “mixed‑motive task suite” comprising roughly 30 scenarios is constructed. Each scenario presents partially overlapping or conflicting objectives, such as a bargaining game where both parties can gain from agreement, or a collective‑action problem where contributing to a public good benefits the group. Second, the authors define four quantitative metrics to capture cooperative intelligence: (1) mutual‑gain occurrence rate, (2) negotiation success rate, (3) collective‑goal attainment score, and (4) persuasion success rate. The last metric specifically tests an agent’s capacity to influence another’s behavior and to uphold social norms, going beyond simple utility maximization.
The framework was deployed in the NeurIPS 2024 Concordia Contest, where 120 teams submitted LLM‑driven agents. Even the top‑10 % of submissions achieved only a 68 % average mutual‑gain rate, and their persuasion success fell below 45 %. These results reveal a pronounced shortfall in current LLM agents: while they excel at language understanding and generation, they struggle to resolve goal conflicts, maintain long‑term trust, and perform strategic norm enforcement. Detailed error analysis points to two primary technical bottlenecks.
First, prompt engineering and chain‑of‑thought (CoT) reasoning are not optimized for multi‑objective reasoning; agents tend to latch onto a single dominant objective, neglecting trade‑offs required for cooperative outcomes. Second, contemporary LLMs lack external memory or persistent state mechanisms, preventing them from leveraging interaction histories to adapt strategies over time. This limitation is especially detrimental in norm‑enforcement tasks that rely on repeated feedback loops.
To bridge these gaps, the authors propose three complementary avenues. (1) Multi‑objective prompt designs coupled with meta‑reward shaping that explicitly reward joint‑gain and norm‑compliant actions. (2) Integration of external memory modules (e.g., differentiable key‑value stores) that retain dialogue context and action logs, enabling agents to reason over past interactions. (3) Mixed‑partner training regimes that expose agents to both human and synthetic counterparts, fostering robust domain adaptation. The paper also releases the Concordia environment and evaluation scripts as open‑source resources, encouraging the community to extend the task suite and benchmark future agents.
In summary, the study delivers a rigorous, zero‑shot testing ground for “general cooperative intelligence” in LLM agents, demonstrates that current systems fall short of the robustness required for reliable social cooperation, and outlines concrete research directions—advanced prompting, memory‑augmented architectures, and mixed‑partner learning—to advance the field toward truly generalizable, socially aware AI.