📝 Original Info
- Title: Peek-a-Boo Reasoning: Contrastive Region Masking in MLLMs
- ArXiv ID: 2512.08976
- Date: 2025-12-03
- Authors: Researchers from original ArXiv paper
📝 Abstract
We introduce Contrastive Region Masking (CRM), a training free diagnostic that reveals how multimodal large language models (MLLMs) depend on specific visual regions at each step of chain-of-thought (CoT) reasoning. Unlike prior approaches limited to final answers or attention maps, CRM provides causal, step-level attribution by systematically masking annotated regions and contrasting the resulting reasoning traces with unmasked baselines. Applied to datasets such as VisArgs[1], CRM reveals distinct failure modes: some models preserve reasoning structure, but hallucinate when evidence is missing, while others ground tightly to visual cues yet collapse under perturbations. By shifting the evaluation from correctness of answers to faithfulness of reasoning, CRM reframes visual benchmarks as diagnostic tools, highlighting the need for multimodal evaluation frameworks that measure not just performance, but also robustness and fidelity of reasoning.
💡 Deep Analysis
Deep Dive into Peek-a-Boo Reasoning: Contrastive Region Masking in MLLMs.
We introduce Contrastive Region Masking (CRM), a training free diagnostic that reveals how multimodal large language models (MLLMs) depend on specific visual regions at each step of chain-of-thought (CoT) reasoning. Unlike prior approaches limited to final answers or attention maps, CRM provides causal, step-level attribution by systematically masking annotated regions and contrasting the resulting reasoning traces with unmasked baselines. Applied to datasets such as VisArgs[1], CRM reveals distinct failure modes: some models preserve reasoning structure, but hallucinate when evidence is missing, while others ground tightly to visual cues yet collapse under perturbations. By shifting the evaluation from correctness of answers to faithfulness of reasoning, CRM reframes visual benchmarks as diagnostic tools, highlighting the need for multimodal evaluation frameworks that measure not just performance, but also robustness and fidelity of reasoning.
📄 Full Content
Peek-a-Boo Reasoning: Contrastive Region Masking in
MLLMs
Isha Chaturvedi
Independent Researcher
chaturvedi.isha6@gmail.com
Anjana Nair
Algoverse AI Research
nairanjana696@gmail.com
Yushen Li
Algoverse AI Research
ethanli9688@outlook.com
Adhitya Rajendra Kumar
Algoverse AI Research
email2adhitya@gmail.com
Kevin Zhu
Algoverse AI Research
zhu502846@berkeley.edu
Sunishchal Dev
Algoverse AI Research
sunishchaldev@gmail.com
Ashwinee Panda
Princeton University
ashwinee@princeton.edu
Vasu Sharma
Algoverse AI Research
sharma.vasu55@gmail.com
Abstract
We introduce Contrastive Region Masking (CRM), a training free diagnostic that
reveals how multimodal large language models (MLLMs) depend on specific visual
regions at each step of chain-of-thought (CoT) reasoning. Unlike prior approaches
limited to final answers or attention maps, CRM provides causal, step-level attri-
bution by systematically masking annotated regions and contrasting the resulting
reasoning traces with unmasked baselines. Applied to datasets such as VisArgs[1],
CRM reveals distinct failure modes: some models preserve reasoning structure, but
hallucinate when evidence is missing, while others ground tightly to visual cues
yet collapse under perturbations. By shifting the evaluation from correctness of an-
swers to faithfulness of reasoning, CRM reframes visual benchmarks as diagnostic
tools, highlighting the need for multimodal evaluation frameworks that measure
not just performance, but also robustness and fidelity of reasoning.
1
Introduction
Chain-of-thought reasoning [10] has emerged as a powerful technique for improving reasoning in
large language models (LLMs). It encourages models to generate step-by-step intermediate reasoning
before producing final answers. Multimodal large language models (MLLMs) [14][17][16][15][13]
have advanced the integration of visual and textual information, enabling complex reasoning over
images and language[11]. However, these models often lack fine-grained selectivity, leading to
reasoning failures such as hallucinated logic, semantic drift, and brittle answers when irrelevant
or distracting visual content is present[19]. MLLMs often fail to reason selectively over the most
relevant image regions, especialy in complex tasks that involve multiple objects or scenes[12]. Our
analysis on VisArgs dataset shows that state-of-the-art models like GPT-4o [21], Gemini-1.5-Flash
[22], Qwen-2.5-VL-7b-Instruct [23], Llama-3.2-90B-Vision-Instruct [24] exhibit these weaknesses.
Prior methods have been fragmented: some inspect attention (e.g., FOCUS [2]), some explore
grounding or region replay (e.g., VGR [3], Argus [4]), and others fine-tune visual reasoning (e.g.,
ICoV [6]). Crucially, none systematically link step-wise reasoning failures to specific visual regions,
leaving an important gap in understanding how visual content drives reasoning.
*Accepted at the NeurIPS 2025 Workshop on Foundations of Reasoning in Language Models (FoRLM)
39th Conference on Neural Information Processing Systems (NeurIPS 2025).
arXiv:2512.08976v1 [cs.LG] 3 Dec 2025
This raises a central question: What happens to a model’s reasoning process when key visual
regions are removed?
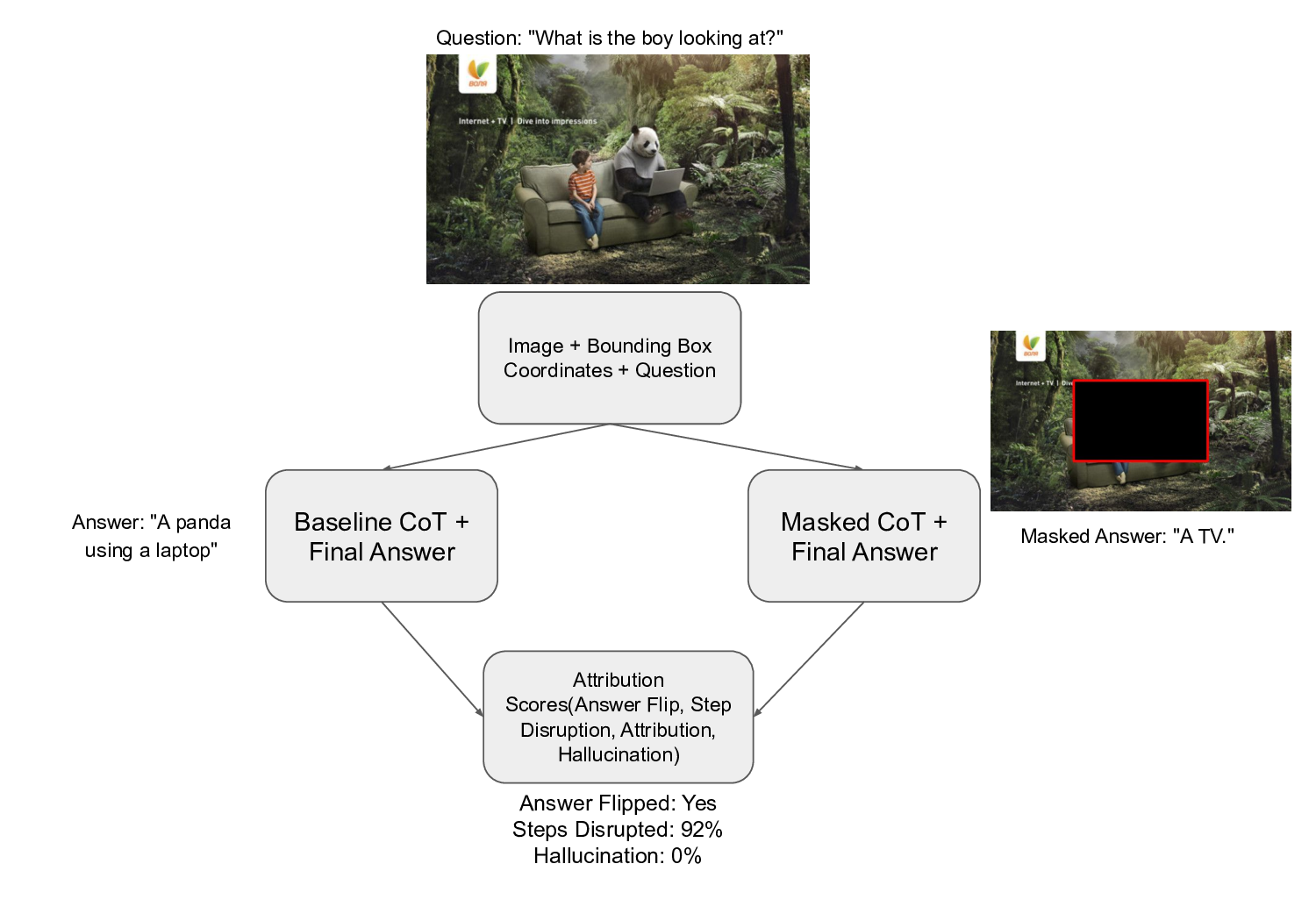
To address this, we introduce a novel and training-free framework called CRM (Chain of Thought
Region Manipulation), as shown in Figure 1, that evaluates MLLMs’ reliance on specific visual
regions during reasoning, not only for final answers but for each step in the chain-of-thought (CoT).
Our contributions are threefold:
1. Behavioral Attribution of Visual Reasoning via Contrastive Region Masking (CRM):
We systematically remove ground-truth bounding boxes and track how each CoT step
changes, enabling causal attribution between visual regions and reasoning steps. This
approach goes beyond saliency maps or final-answer metrics to reveal step-level reasoning
failures.
2. Step-to-Region Causality Without Training: Our framework is black-box and model-
agnostic, requiring no retraining. By combining simple region perturbations with semantic
similarity over CoT traces, we expose where MLLMs rely on visual evidence and where
reasoning fails or hallucinates when cues are absent.
3. Repurposing Structured Benchmarks for Step-Level Diagnostics: We reframe VisArgs, a
dataset with region-level and reasoning annotations as a diagnostic tool. By selectively mask-
ing regions associated with each CoT step and measuring resulting reasoning disruptions,
we provide insights into model robustness, interpretability, and visual faithfulness.
2
Related Works
Prior research on evaluating and improving visual reasoning in multimodal large language models
(MLLMs) is centered around four thematic axes. One key axis is Grounding Approaches, where
methods such as VGR[3], Visual Chain-of-Thought(Visual CoT), and Argus focus on grounding visual
evidence during reasoning. VGR predicts bounding-box tokens during CoT inference to localize
relevant regions, but its reliance on explicit annotations and handcr
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.