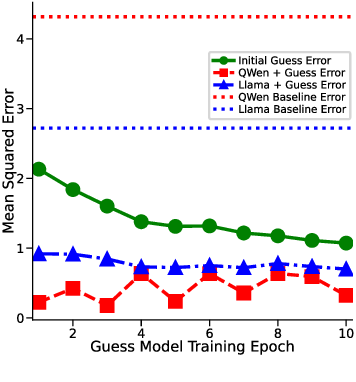
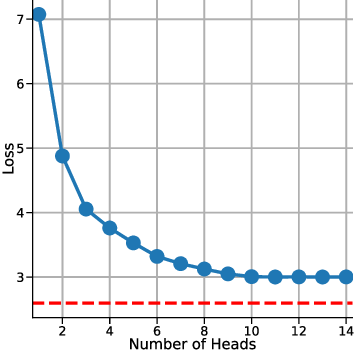
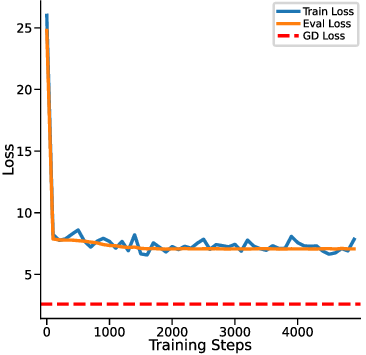
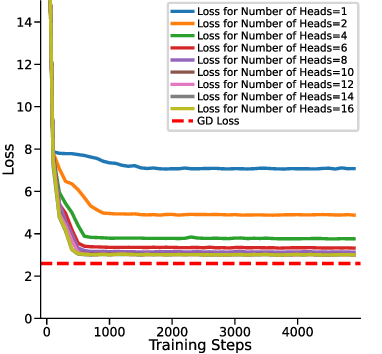
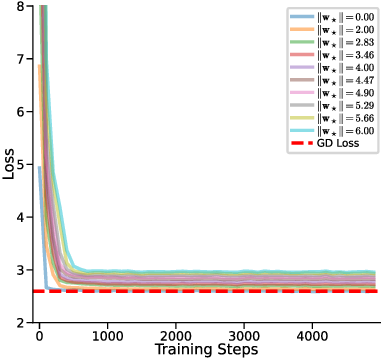
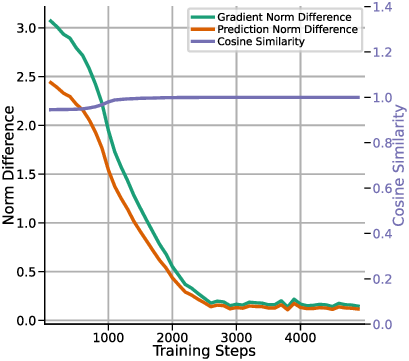
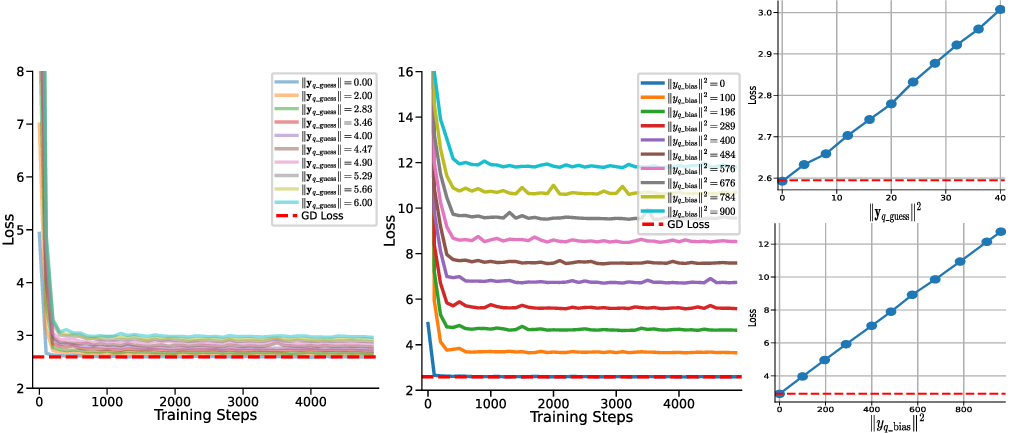
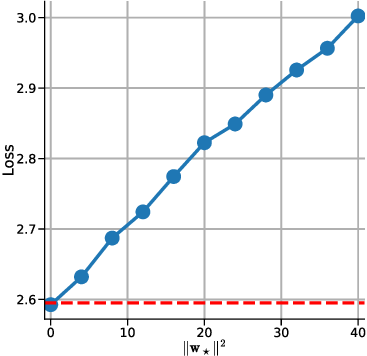In-context learning (ICL) in large language models (LLMs) is a striking phenomenon, yet its underlying mechanisms remain only partially understood. Previous work connects linear self-attention (LSA) to gradient descent (GD), this connection has primarily been established under simplified conditions with zero-mean Gaussian priors and zero initialization for GD. However, subsequent studies have challenged this simplified view by highlighting its overly restrictive assumptions, demonstrating instead that under conditions such as multi-layer or nonlinear attention, self-attention performs optimization-like inference, akin to but distinct from GD. We investigate how multi-head LSA approximates GD under more realistic conditions-specifically when incorporating non-zero Gaussian prior means in linear regression formulations of ICL. We first extend multi-head LSA embedding matrix by introducing an initial estimation of the query, referred to as the initial guess. We prove an upper bound on the number of heads needed for ICL linear regression setup. Our experiments confirm this result and further observe that a performance gap between one-step GD and multi-head LSA persists. To address this gap, we introduce y q -LSA, a simple generalization of single-head LSA with a trainable initial guess y q . We theoretically establish the capabilities of y q -LSA and provide experimental validation on linear regression tasks, thereby extending the theory that bridges ICL and GD. Finally, inspired by our findings in the case of linear regression, we consider widespread LLMs augmented with initial guess capabilities, and show that their performance is improved on a semantic similarity task.
Deep Dive into The Initialization Determines Whether In-Context Learning Is Gradient Descent.
In-context learning (ICL) in large language models (LLMs) is a striking phenomenon, yet its underlying mechanisms remain only partially understood. Previous work connects linear self-attention (LSA) to gradient descent (GD), this connection has primarily been established under simplified conditions with zero-mean Gaussian priors and zero initialization for GD. However, subsequent studies have challenged this simplified view by highlighting its overly restrictive assumptions, demonstrating instead that under conditions such as multi-layer or nonlinear attention, self-attention performs optimization-like inference, akin to but distinct from GD. We investigate how multi-head LSA approximates GD under more realistic conditions-specifically when incorporating non-zero Gaussian prior means in linear regression formulations of ICL. We first extend multi-head LSA embedding matrix by introducing an initial estimation of the query, referred to as the initial guess. We prove an upper bound on the
Large language models (LLMs) exhibit the interesting phenomenon of in-context learning (ICL), whereby models adapt to new tasks from a few input-label pairs presented in the context, without parameter updates (Brown et al., 2020;Dong et al., 2024). This capability has motivated extensive efforts to clarify the underlying mechanisms. A prominent line of work interprets ICL in simplified linear regression settings as implicitly
Theoretical studies on ICL have analyzed its mechanisms to understand how LLMs effectively learn from contextual examples (Brown et al., 2020). ICL can be framed as an implicit Bayesian process where the model performs posterior inference over a latent task structure based on contextual examples, performing a form of posterior updating (Xie et al., 2022;Falck et al., 2024;Panwar et al., 2024;Ye et al., 2024). Alternatively, a more recent perspective suggests that ICL in transformers is akin to gradient-based optimization occurring within their forward pass. Von Oswald et al. (2023) demonstrate that self-attention layers can approximate gradient descent by constructing task-specific updates to token representations. They provide a mechanistic explanation by showing how optimized transformers can implement gradient descent dynamics with a given learning rate (Rossi et al., 2024;Zhang et al., 2025). While this work provides a new perspective on ICL, it limits the analysis to simple regression tasks and it simplifies the transformer architecture by considering a single-head self-attention layer without applying the sfmx(•) function on the attention weights (also known as linear attention). Ahn et al. (2023) extend the work of Von Oswald et al. (2023) by showing how the in-context dynamics can learn to implement preconditioned gradient descent, where the preconditioner is implicitly optimized during pretraining. More recently, Mahankali et al. (2024) prove that a single self-attention layer converges to the global minimum of the squared error loss. Zhang et al. (2024b); Wang et al. (2025) also analyze a more complex transformer architecture with a (linear) multi-layer perceptron (MLP) or softmax after the linear self-attention layer, showing the importance of such block when pretraining for more complex tasks. In a related direction, Cheng et al. (2024) show that transformers can implement functional gradient descent to learn non-linear functions in context, further strengthening the view of ICL as gradient-based optimization.
Recent works have also raised important critiques of the ICL to GD hypothesis, questioning both its theoretical assumptions and empirical applicability. For example, Shen et al. (2023;2024) point out that many theoretical results-such as those in Von Oswald et al. (2023)-rely on overly simplified settings, including linearized attention mechanisms, handcrafted weights, or order-invariant assumptions not satisfied in real models. Giannou et al. (2024); Fu et al. (2024) demonstrated that in a multi-layer self-attention setting, the internal iterations of the Transformer conform more closely to the second-order convergence speed of Newton’s Method. Therefore, the interpretation of ICL needs to be examined under more realistic assumptions.
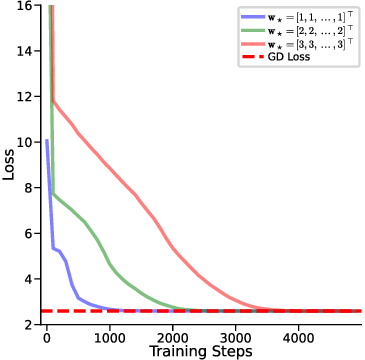
In this work, we extend the above lines of research by emphasizing more realistic priors, specifically, non-zero prior means. While Zhang et al. (2024a); Mahdavi et al. (2024) explore broader prior distributions by analyzing covariate structures or modify the distribution of input feature, our focus instead lies on the interplay between a non-zero prior mean and the capacity of LSA to emulate GD. We note that while Ahn et al. (2023); Mahankali et al. (2024); Zhang et al. (2024b) provide compelling theoretical analyses, their work does not include experimental validations. In doing so, our study builds upon and generalizes the prior-zero analyses found in Von Oswald et al. (2023); Ahn et al. (2023), illuminating new challenges and insights that arise when priors deviate from zero, both theoretically and empirically.
We use x ∈ R d and y ∈ R to denote a feature vector and its label, respectively. We consider a fixed number of context examples, denoted by C > 0. We denote the context examples as (X, y) ∈ R C×d × R C , where each row represents a context example, denoted by (
To formalize an in-context learning (ICL) problem, the input of a model is an embedding matrix given by
where x q ∈ R d is a new query input and y q ∈ R is an initial guess of the prediction for the query x q . The model’s output corresponds to a prediction of y ∈ R. Notice that the embedding matrix in equation 2 is a slight extension to the commonly used embedding matrix, e.g. presented in Von Oswald et al. (2023), where y q is set to be zero by default. Its interpretation will be clearer in the next two sections.
Linear regression tasks. We formalize the linear regression tasks as follows. Assume that (X, y, x q , y) are generated by:
• First, a task paramete
…(Full text truncated)…
This content is AI-processed based on ArXiv data.