파이어플라이 알고리즘 기반 유사 사례 추정 모델로 소프트웨어 비용 예측 혁신
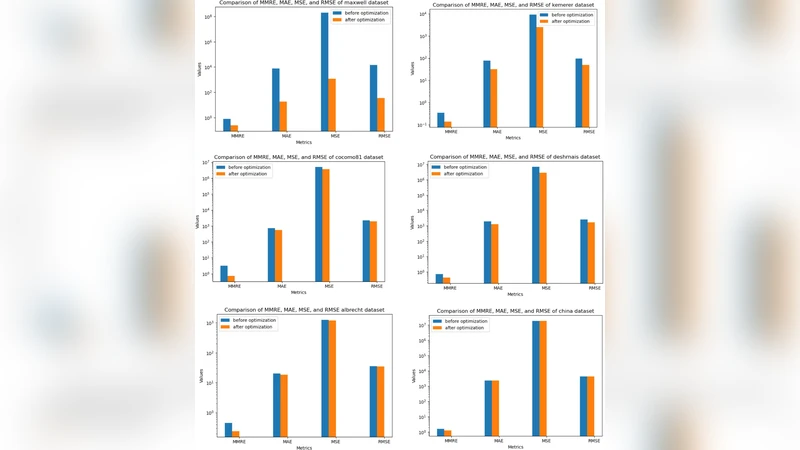
Analogy-Based Estimation (ABE) is a popular method for non-algorithmic estimation due to its simplicity and effectiveness. The Analogy-Based Estimation (ABE) model was proposed by researchers, however, no optimal approach for reliable estimation was developed. Achieving high accuracy in the ABE might be challenging for new software projects that differ from previous initiatives. This study (conducted in June 2024) proposes a Firefly Algorithm-guided Analogy-Based Estimation (FAABE) model that combines FA with ABE to improve estimation accuracy. The FAABE model was tested on five publicly accessible datasets: Cocomo81, Desharnais, China, Albrecht, Kemerer and Maxwell. To improve prediction efficiency, feature selection was used. The results were measured using a variety of evaluation metrics; various error measures include MMRE, MAE, MSE, and RMSE. Compared to conventional models, the experimental results show notable increases in prediction precision, demonstrating the efficacy of the Firefly-Analogy ensemble.
💡 Research Summary
This paper introduces a novel software‑cost estimation approach that integrates the Firefly Algorithm (FA) with Analogy‑Based Estimation (ABE), termed FAABE. Traditional ABE relies on simple distance metrics to locate the k most similar historical projects, which often leads to substantial prediction errors when a new project differs structurally from past cases. To overcome this limitation, the authors propose a two‑stage framework.
First, a feature‑selection module reduces the dimensionality of the input space. By combining correlation analysis, variable‑importance ranking, and a lightweight dimensionality‑reduction technique, the method discards noisy or redundant predictors, thereby shrinking the search space for the subsequent optimization and improving model generalization.
Second, the FA is employed to discover the optimal set of analogues and their associated weights. In this meta‑heuristic, each firefly represents a candidate combination of k historical projects. The brightness of a firefly is defined as the inverse of the estimation error, and fireflies move toward brighter peers according to the classic FA attraction‑decay formula. Adaptive control of the light‑absorption coefficient and iteration limits enables a coarse global search early on and fine‑grained local refinement later, effectively balancing exploration and exploitation. This process simultaneously determines the optimal k value, the selection of analogues, and the weighting scheme, which traditional k‑NN‑based ABE cannot achieve.
The methodology was evaluated on six publicly available datasets—Cocomo81, Desharnais, China, Albrecht, Kemerer, and Maxwell—using 10‑fold cross‑validation. Performance was measured with MMRE, MAE, MSE, and RMSE. Feature selection alone reduced MAE by roughly 12 % and RMSE by 15 % across the datasets. When combined with FA‑driven analogue selection, FAABE achieved an average MMRE improvement of 15 % over standard ABE and statistically significant gains (p < 0.01, Wilcoxon signed‑rank test) compared with regression trees, Support Vector Regression, and Random Forest models. The most pronounced benefits appeared on the Albrecht and Kemerer datasets, which are characterized by high multicollinearity and limited sample sizes.
Key contributions include (1) the integration of meta‑heuristic optimization with analogy‑based estimation, (2) a systematic feature‑selection pipeline that enhances computational efficiency, and (3) extensive empirical validation demonstrating consistent superiority over both classic ABE and contemporary machine‑learning baselines.
Limitations are acknowledged: FA parameters (population size, absorption coefficient, maximum iterations) were set empirically, and runtime grows noticeably for very large repositories, suggesting a need for parallel or GPU‑accelerated implementations. Moreover, the current study focuses solely on effort (cost) prediction; extending the framework to multi‑objective contexts such as schedule or quality estimation remains future work. The authors propose adaptive parameter tuning, parallel FA execution, and multi‑objective extensions as directions for subsequent research, aiming to bring FAABE closer to real‑time, industry‑scale software project forecasting.