📝 Original Info
- Title: Feedback Loops and Code Perturbations in LLM-based Software Engineering: A Case Study on a C-to-Rust Translation System
- ArXiv ID: 2512.02567
- Date: 2025-12-02
- Authors: Researchers from original ArXiv paper
📝 Abstract
The advent of strong generative AI has a considerable impact on various software engineering tasks such as code repair, test generation, or language translation. While tools like GitHub Copilot are already in widespread use in interactive settings, automated approaches require a higher level of reliability before being usable in industrial practice. In this paper, we focus on three aspects that directly influence the quality of the results: a) the effect of automated feedback loops, b) the choice of Large Language Model (LLM), and c) the influence of behavior-preserving code changes.
We study the effect of these three variables on an automated C-to-Rust translation system. Code translation from C to Rust is an attractive use case in industry due to Rust's safety guarantees. The translation system is based on a generate-and-check pattern, in which Rust code generated by the LLM is automatically checked for compilability and behavioral equivalence with the original C code. For negative checking results, the LLM is re-prompted in a feedback loop to repair its output. These checks also allow us to evaluate and compare the respective success rates of the translation system when varying the three variables.
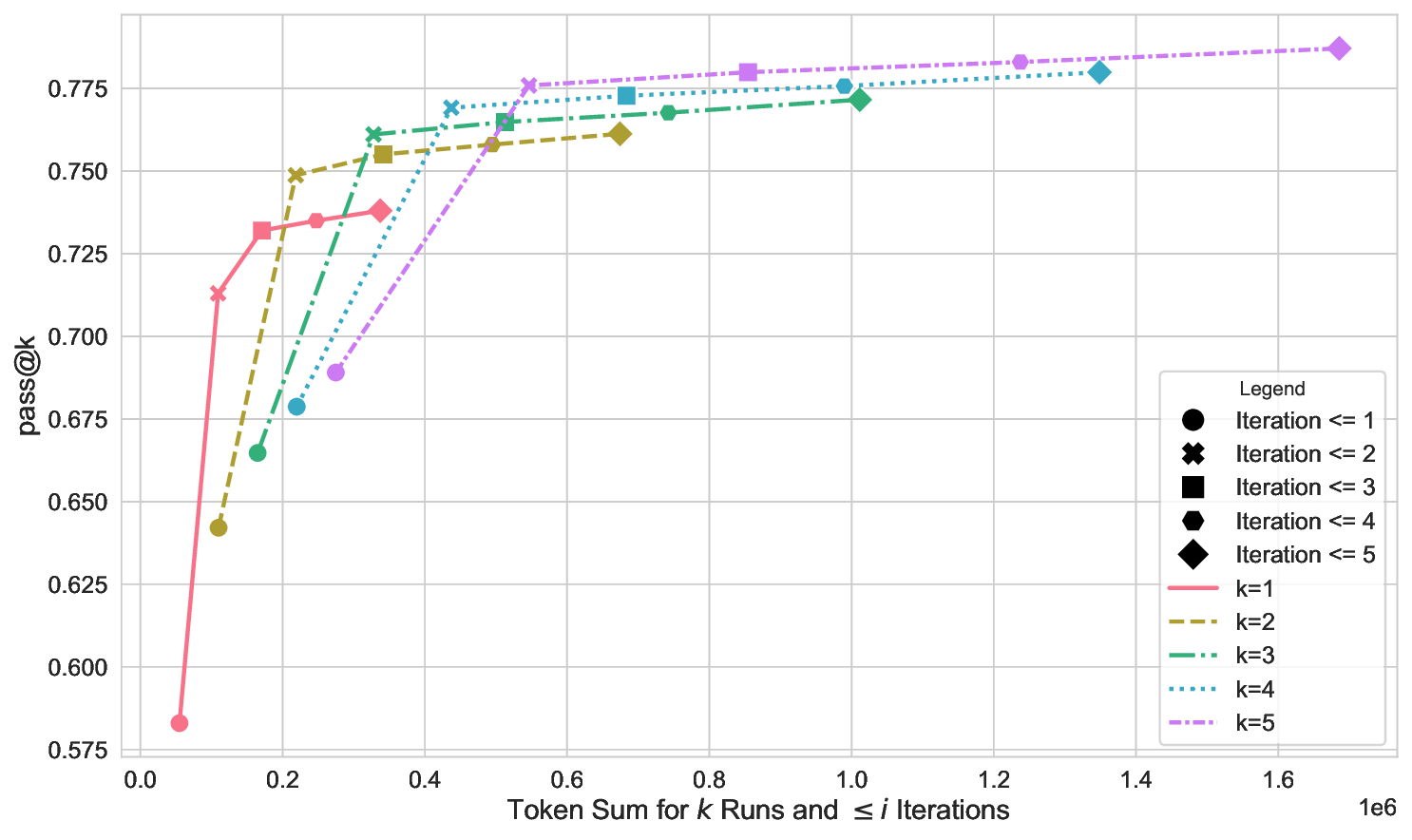
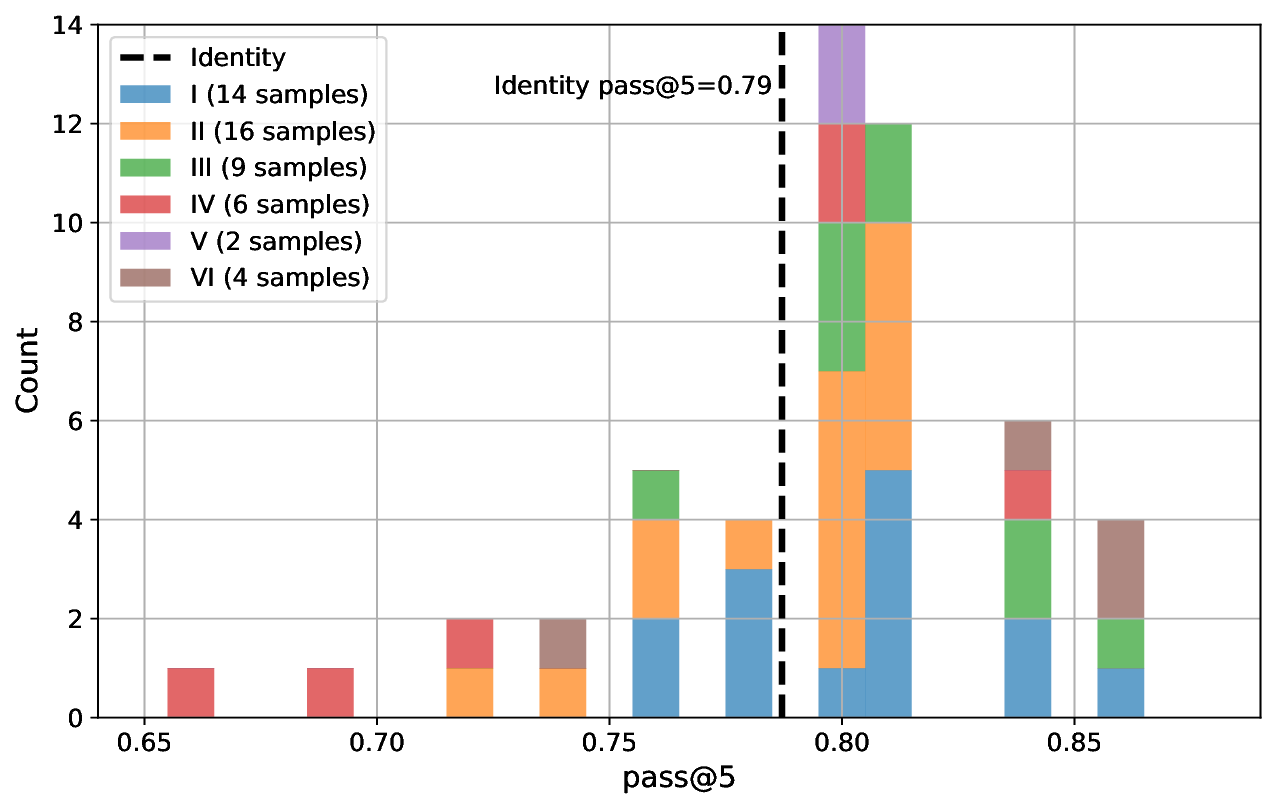
Our results show that without feedback loops LLM selection has a large effect on translation success. However, when the translation system uses feedback loops the differences across models diminish. We observe this for the average performance of the system as well as its robustness under code perturbations. Finally, we also identify that diversity provided by code perturbations can even result in improved system performance.
💡 Deep Analysis
Deep Dive into Feedback Loops and Code Perturbations in LLM-based Software Engineering: A Case Study on a C-to-Rust Translation System.
The advent of strong generative AI has a considerable impact on various software engineering tasks such as code repair, test generation, or language translation. While tools like GitHub Copilot are already in widespread use in interactive settings, automated approaches require a higher level of reliability before being usable in industrial practice. In this paper, we focus on three aspects that directly influence the quality of the results: a) the effect of automated feedback loops, b) the choice of Large Language Model (LLM), and c) the influence of behavior-preserving code changes.
We study the effect of these three variables on an automated C-to-Rust translation system. Code translation from C to Rust is an attractive use case in industry due to Rust’s safety guarantees. The translation system is based on a generate-and-check pattern, in which Rust code generated by the LLM is automatically checked for compilability and behavioral equivalence with the original C code. For negative
📄 Full Content
Feedback Loops and Code Perturbations
in LLM-based Software Engineering:
A Case Study on a C-to-Rust Translation System
Martin Weiss
Otto von Guericke University
Magdeburg, Germany
martin.weiss@st.ovgu.de
Jesko Hecking-Harbusch
Bosch Research
Renningen, Germany
jesko.hecking-harbusch@bosch.com
Jochen Quante
Bosch Research
Renningen, Germany
jochen.quante@bosch.com
Matthias Woehrle
Bosch Research
Renningen, Germany
matthias.woehrle@bosch.com
Abstract—The advent of strong generative AI has a con-
siderable impact on various software engineering tasks such
as code repair, test generation, or language translation. While
tools like GitHub Copilot are already in widespread use in
interactive settings, automated approaches require a higher level
of reliability before being usable in industrial practice. In this
paper, we focus on three aspects that directly influence the quality
of the results: a) the effect of automated feedback loops, b) the
choice of Large Language Model (LLM), and c) the influence of
behavior-preserving code changes.
We study the effect of these three variables on an automated
C-to-Rust translation system. Code translation from C to Rust is
an attractive use case in industry due to Rust’s safety guarantees.
The translation system is based on a generate-and-check pattern,
in which Rust code generated by the LLM is automatically
checked for compilability and behavioral equivalence with the
original C code. For negative checking results, the LLM is re-
prompted in a feedback loop to repair its output. These checks
also allow us to evaluate and compare the respective success rates
of the translation system when varying the three variables.
Our results show that without feedback loops LLM selection
has a large effect on translation success. However, when the trans-
lation system uses feedback loops the differences across models
diminish. We observe this for the average performance of the
system as well as its robustness under code perturbations. Finally,
we also identify that diversity provided by code perturbations can
even result in improved system performance.
Index Terms—
I. INTRODUCTION
The advent of strong generative AI has profoundly impacted
various software engineering tasks [1], [2], including code
repair [3], test generation [4], and language translation [5]–
[7]. Especially for code related tasks, text-based generative AI
in the form of Large Language Models (LLMs) supports
developers everyday across a wide range of code editors
and coding assistants. This impressive adoption rate from
developers as well as studies on development speed [8] show
a positive impact of such assistive technologies. Nevertheless,
there may also be a negative impact, e.g., on quality [8]
and w.r.t. security [9]. However, for particular tasks, tools
This work has been submitted to the IEEE for possible publication.
Copyright may be transferred without notice, after which this version may
no longer be accessible.
may leverage assured LLM-based software engineering [10]
where the properties of the generated target program can be
automatically checked. Software engineering tasks that are
amenable to such a generate-and-check pattern and allow
developers to formulate automated checks are particularly
interesting for LLM-based automation. Particularly, generate-
and-check enables automated feedback loops, i.e., to spend
additional LLM queries to improve system performance at
additional cost. In this work, we study various influence
factors that impact this trade-off between performance and
cost. Furthermore, we study the impact of behavior-preserving
code changes, so-called code perturbations, on quality.
We evaluate these factors on the task of LLM-based transla-
tion from C to Rust, which has become a prominent research
focus [5], [6], [11]–[14]. This is because Rust eliminates some
of the most critical classes of runtime errors common in C by
design but is still suitable for systems programming, making it
particularly appealing for safety- and security-relevant applica-
tions. However, manually rewriting the vast amount of existing
C code is impractical, so an automated approach is highly
desirable. Traditional rule-based approaches like c2rust1 have
the drawback that most code is put into “unsafe” blocks,
which makes many of Rust’s safety mechanisms ineffective
and produces code that is hard to maintain [15].
LLM-based systems can potentially make better use of
the target language’s natural concepts. However, an LLM-
based C-to-Rust translation system also needs to ensure that
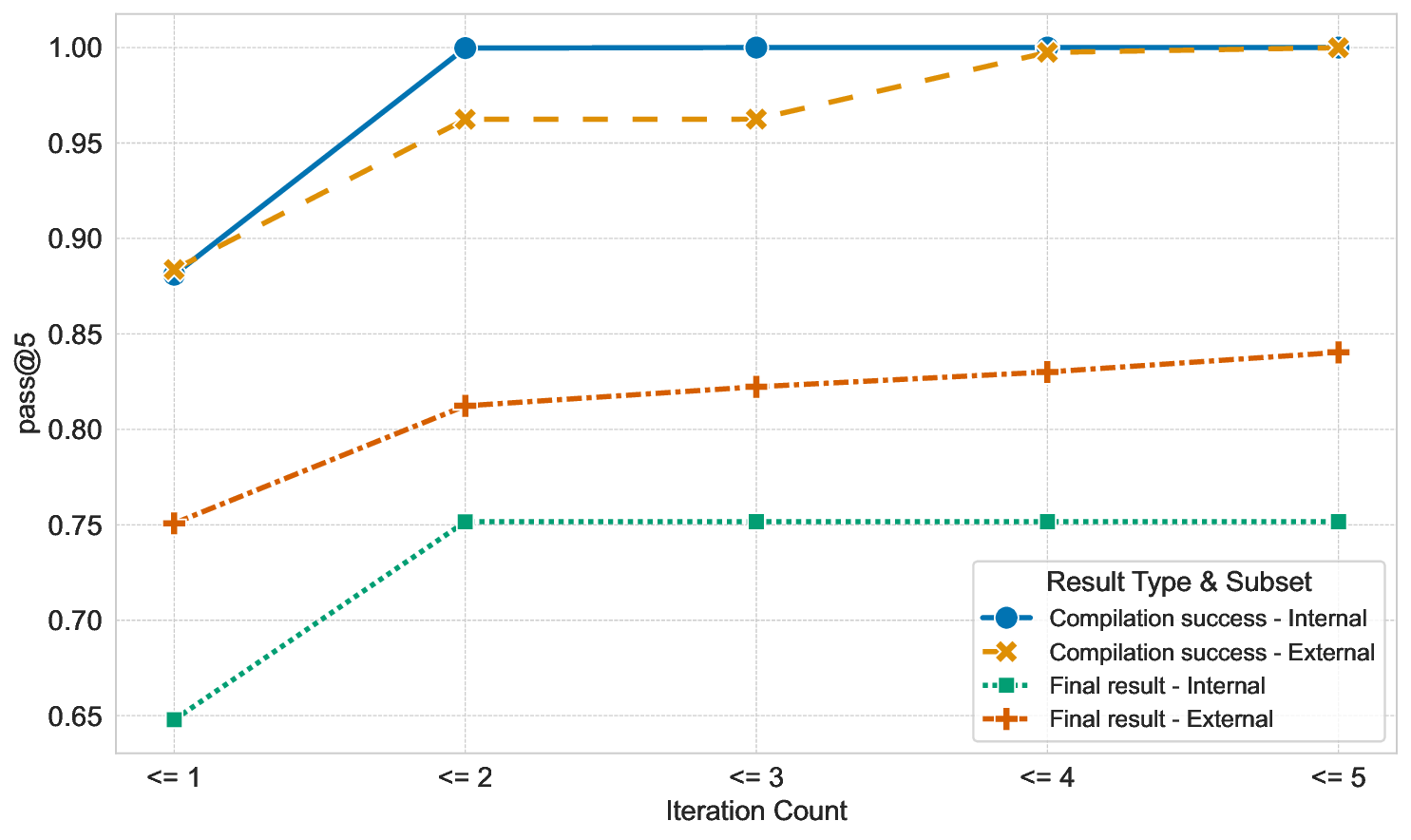
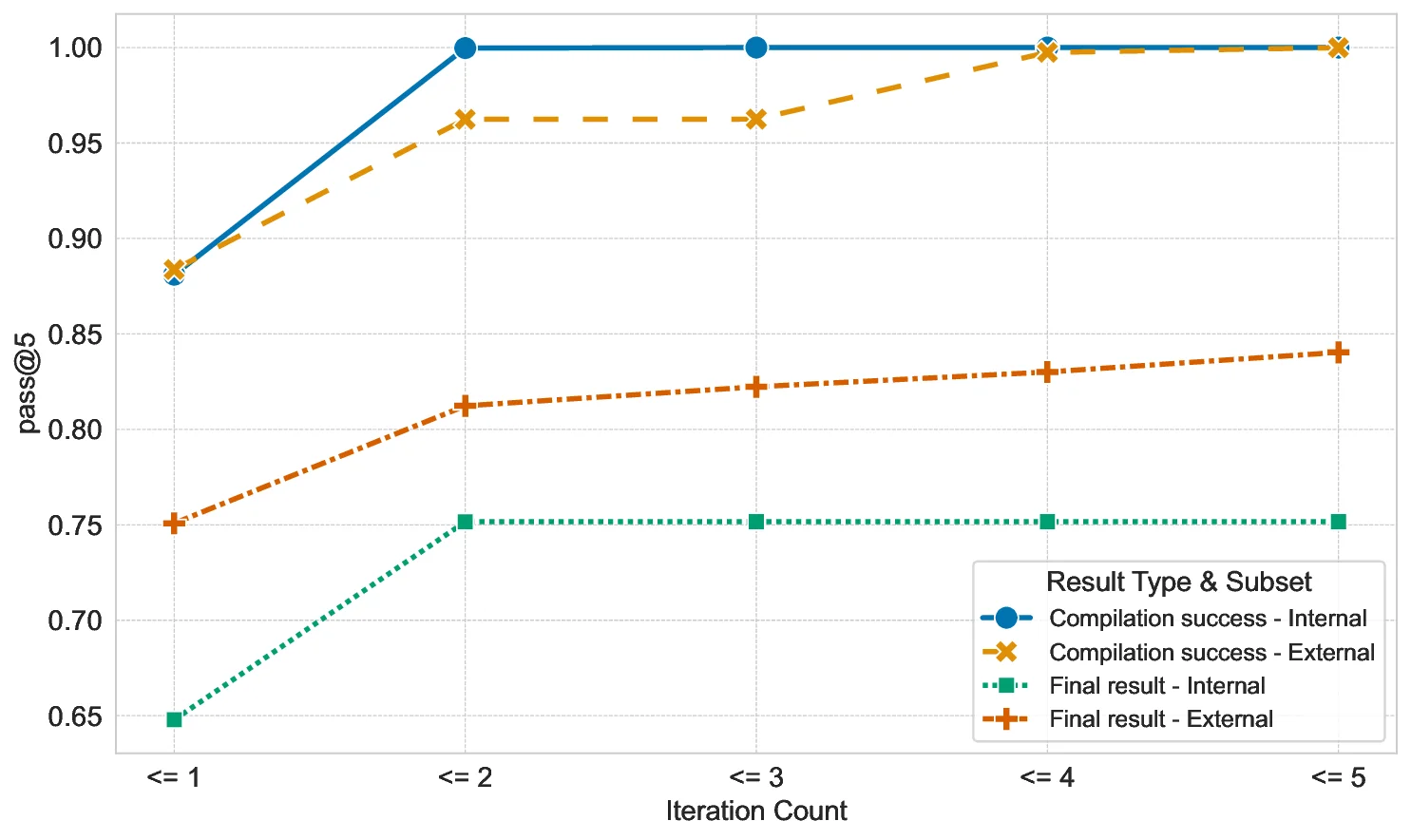
translated Rust code (i) compiles without error and (ii) is
functionally equivalent to the original C code. For the former,
the detailed error messages from the Rust compiler can be di-
rectly leveraged. For the latter, our concrete translation system
(see Fig. 1) uses differential fuzzing [5]. When these checks
return a negative result, the LLM is automatically re-prompted.
This feedback loop enables our translation system to repair
gener
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.