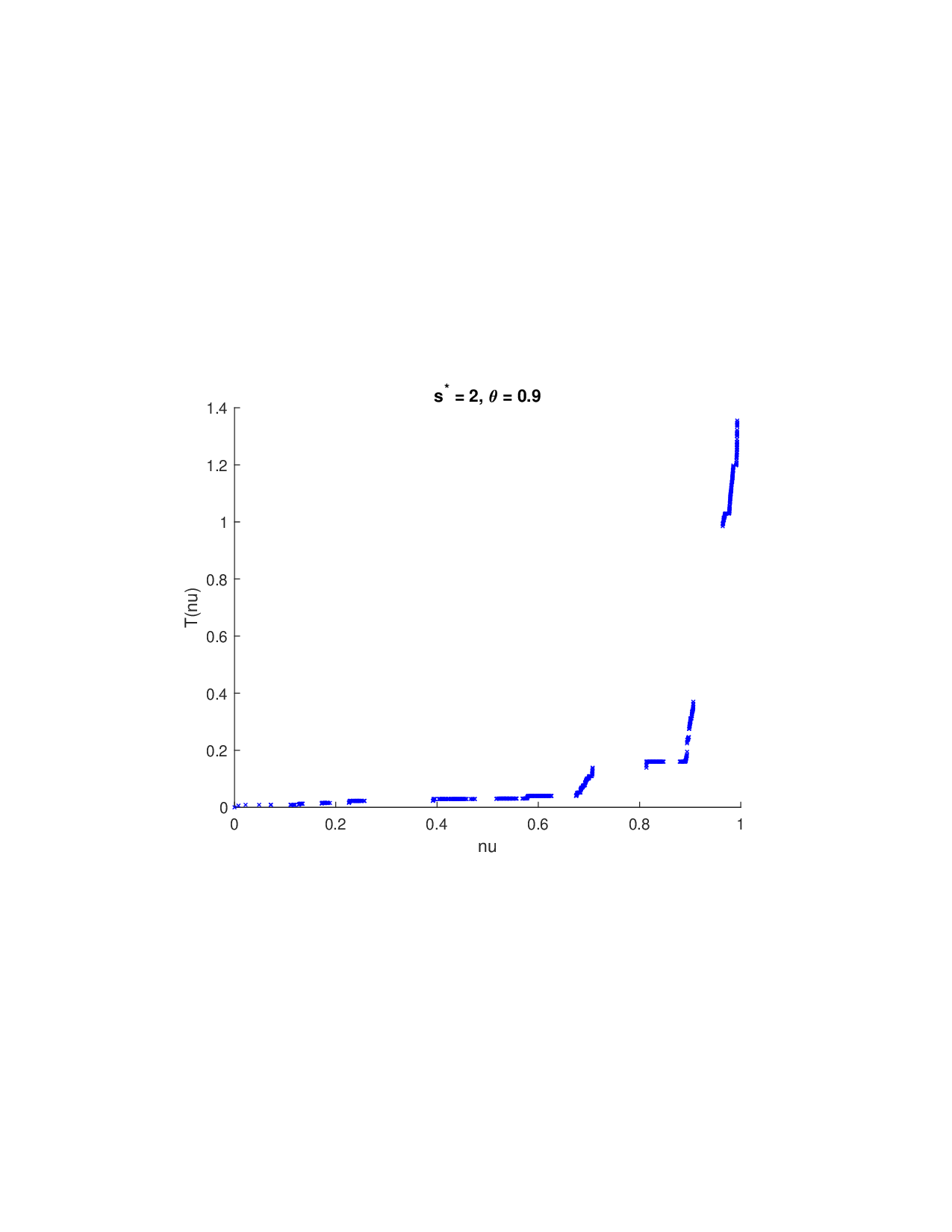
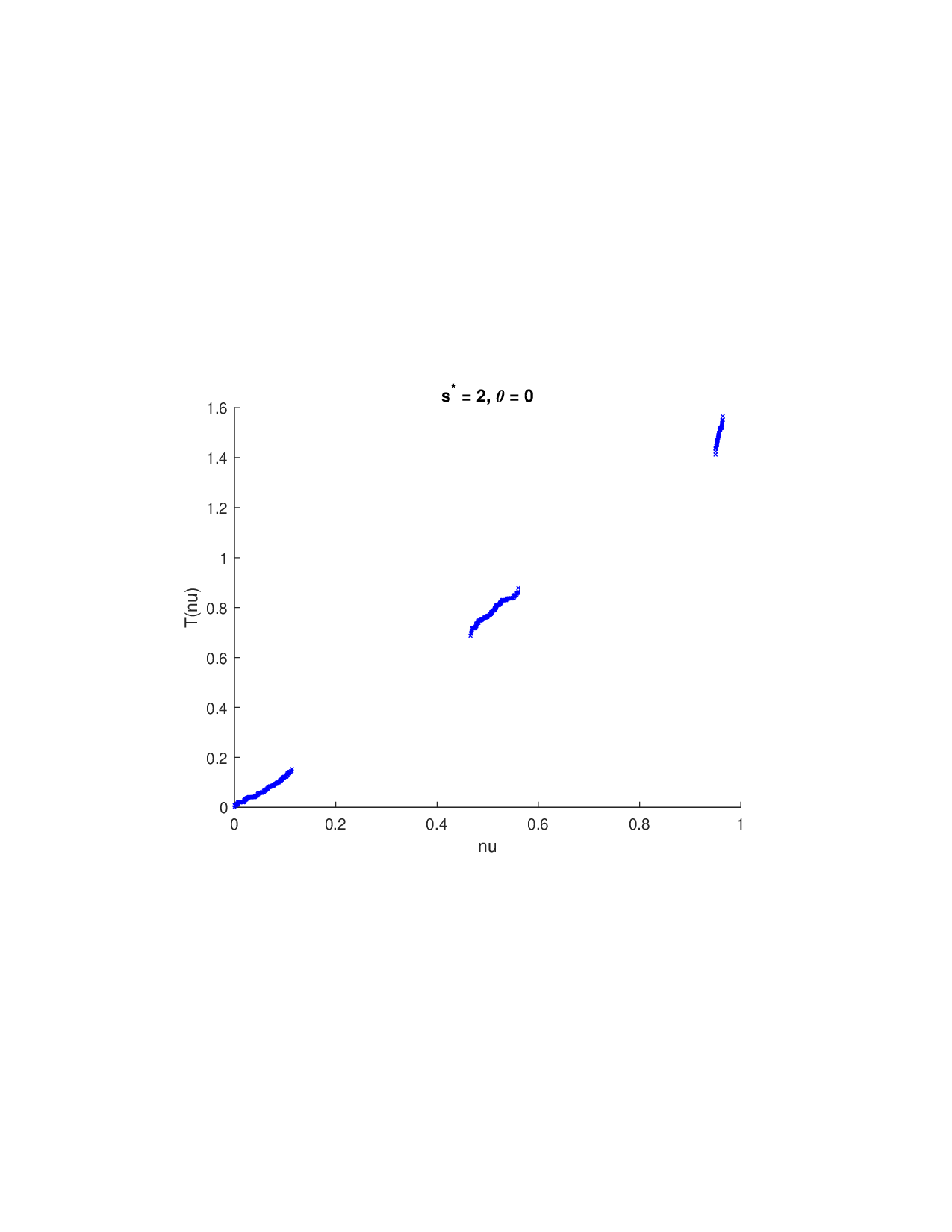
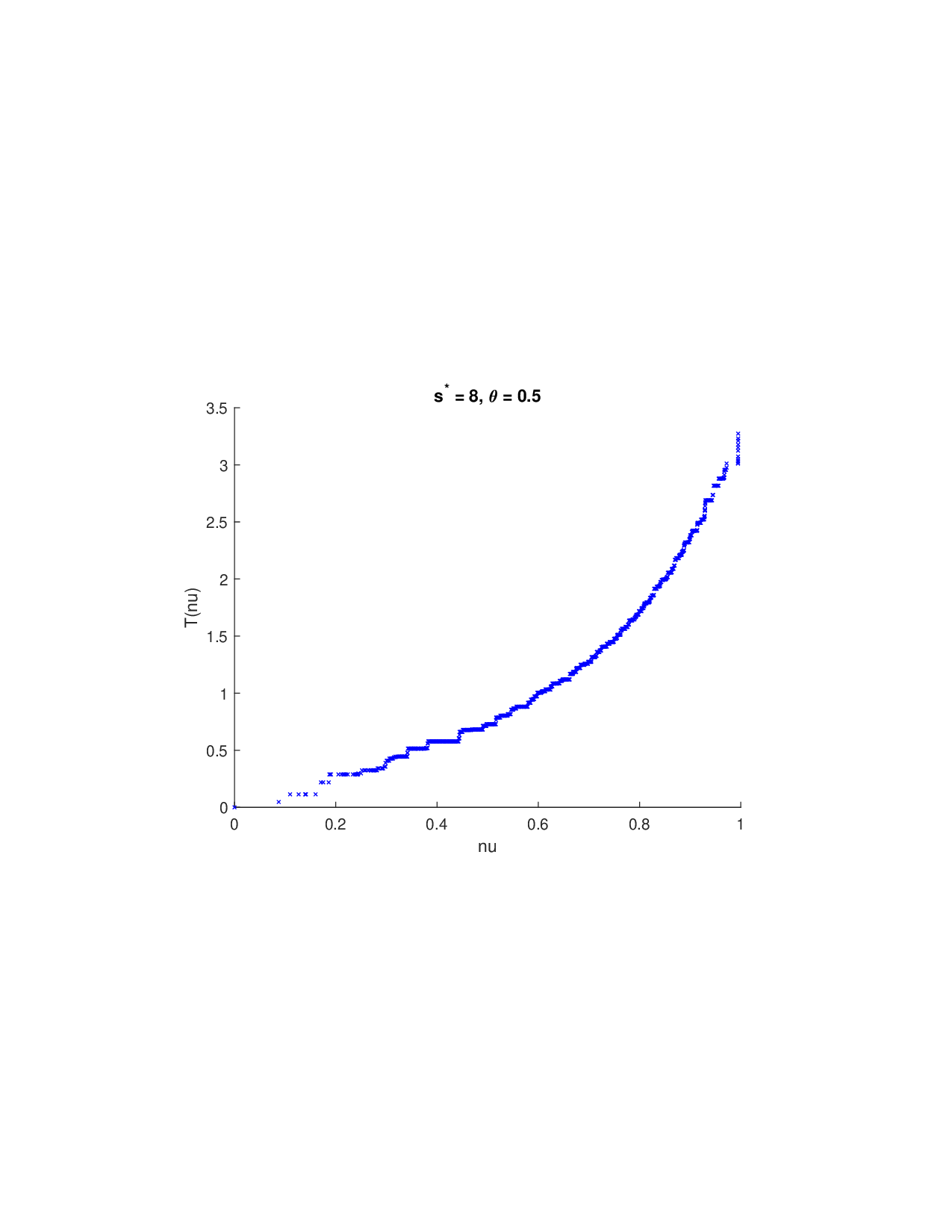
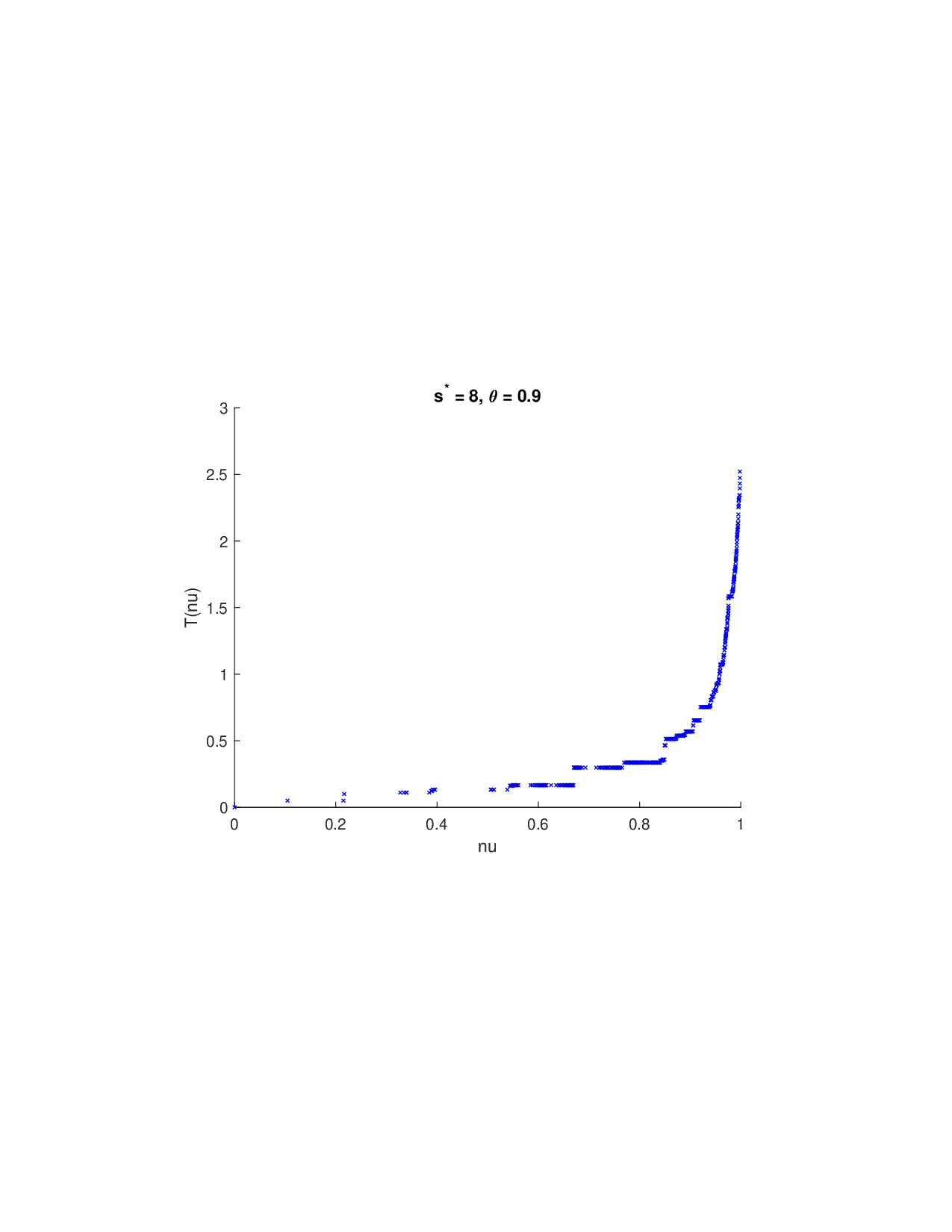
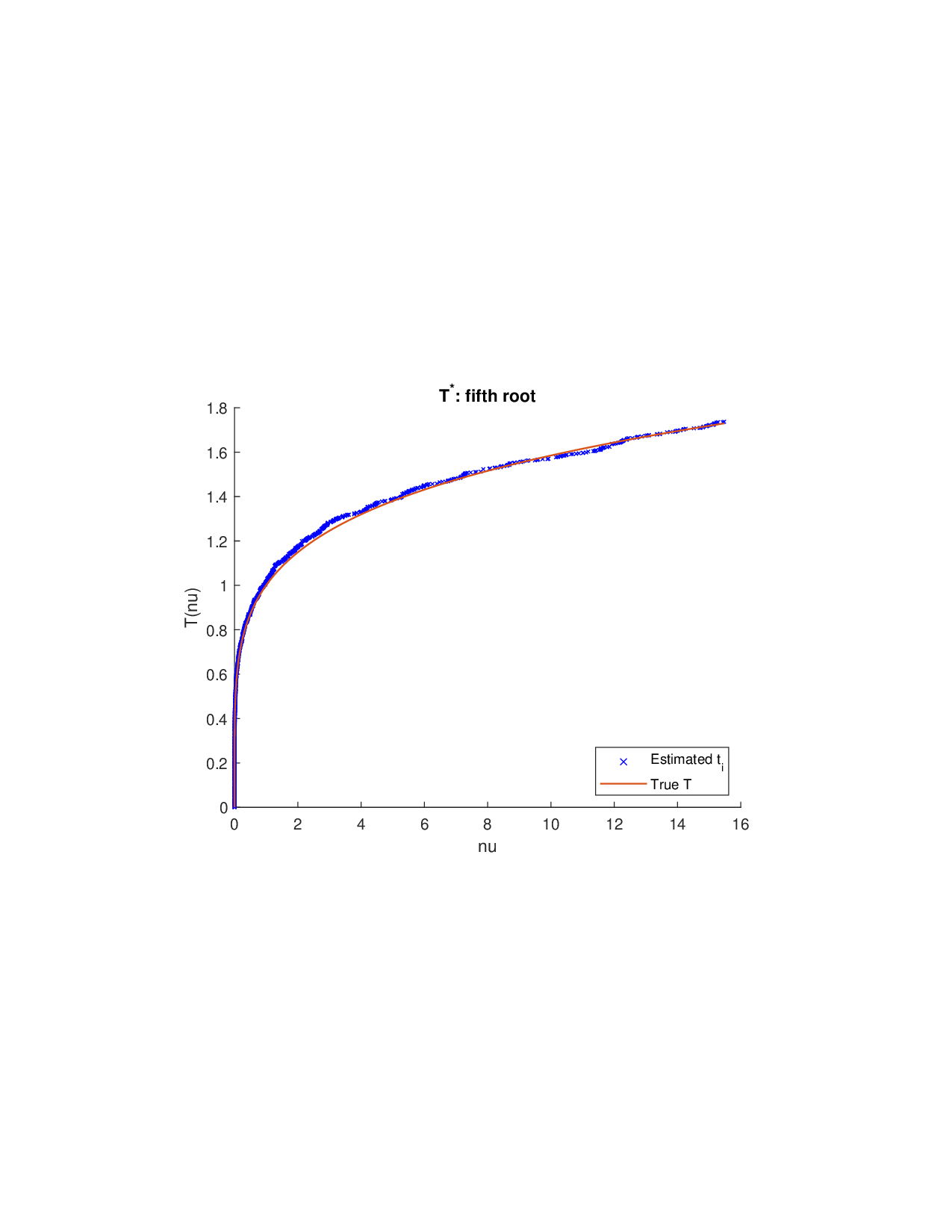
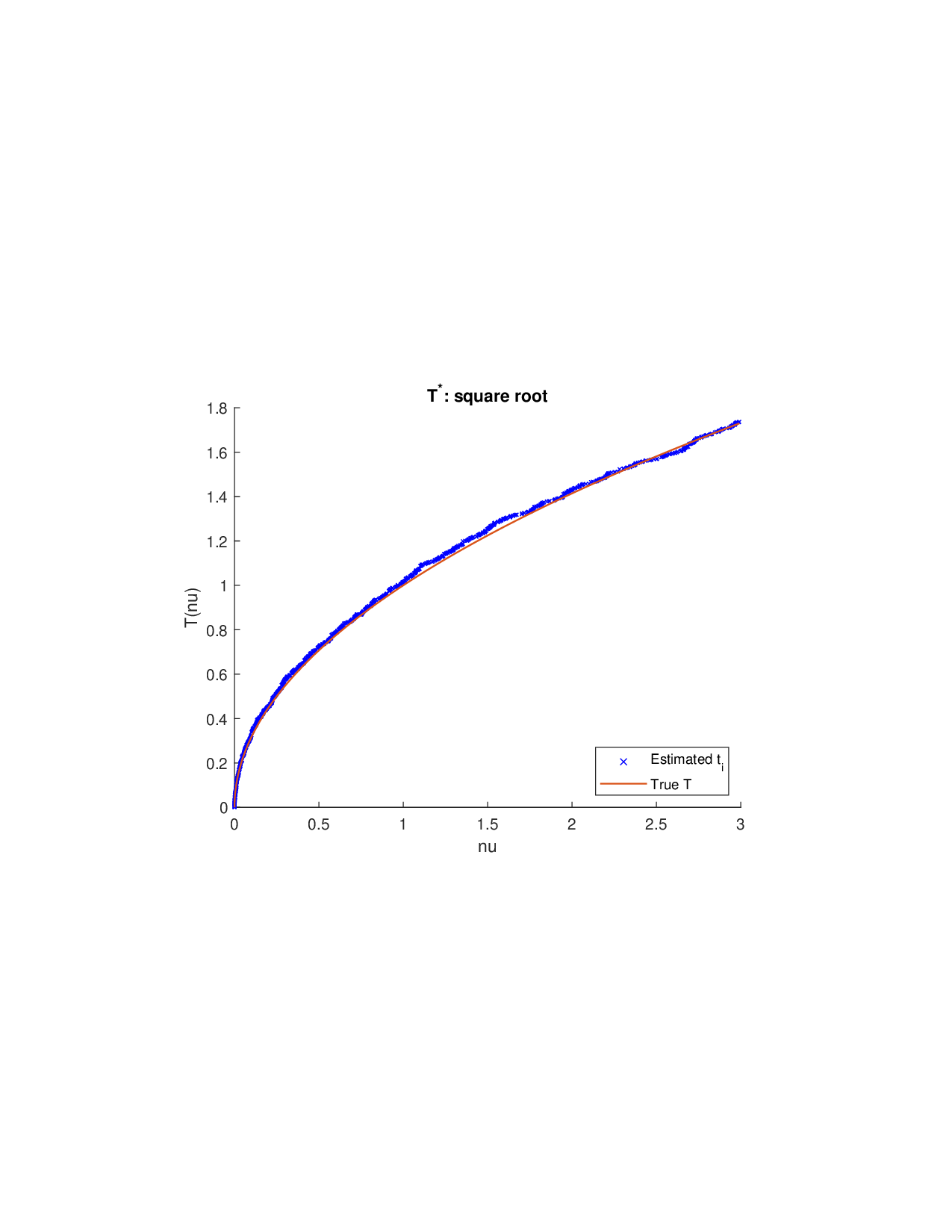
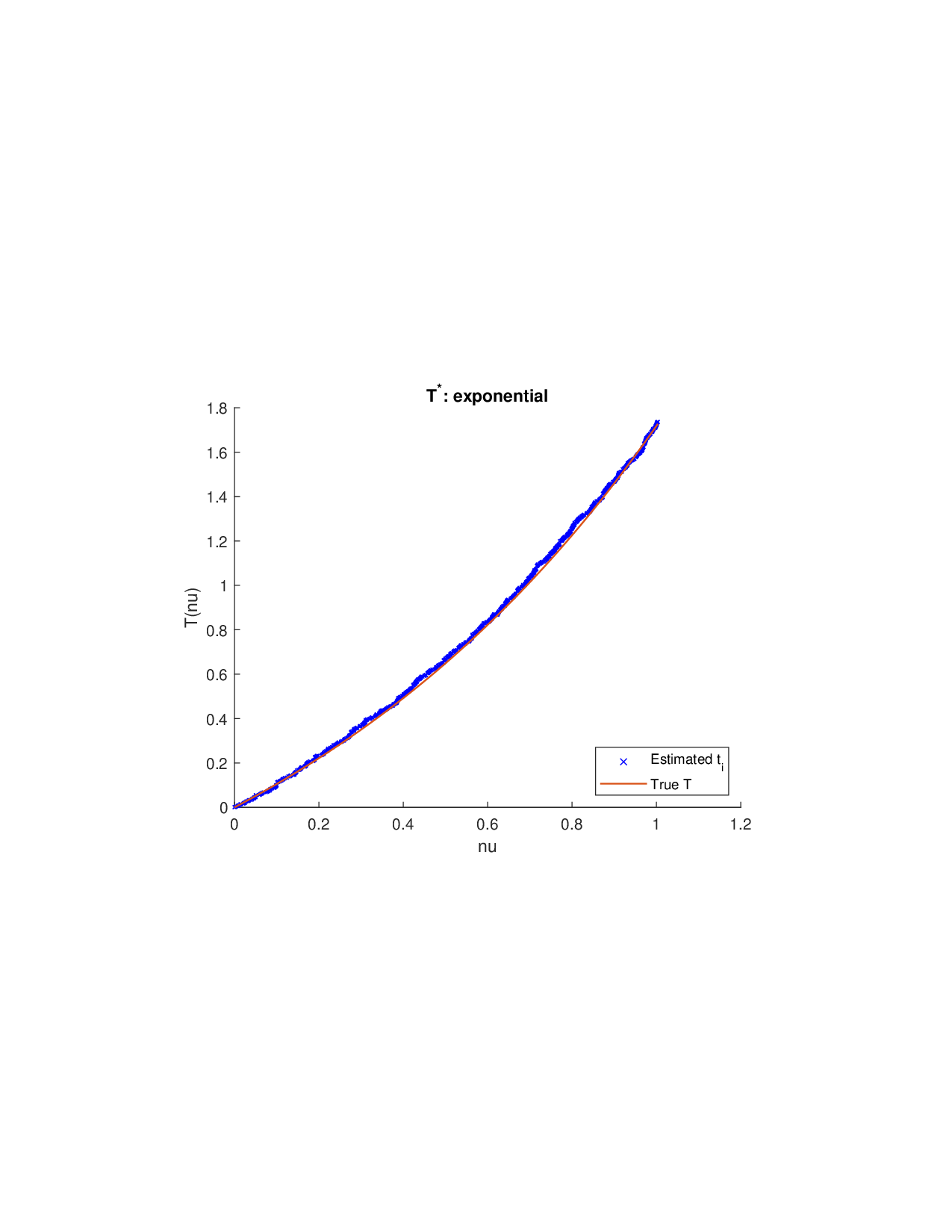
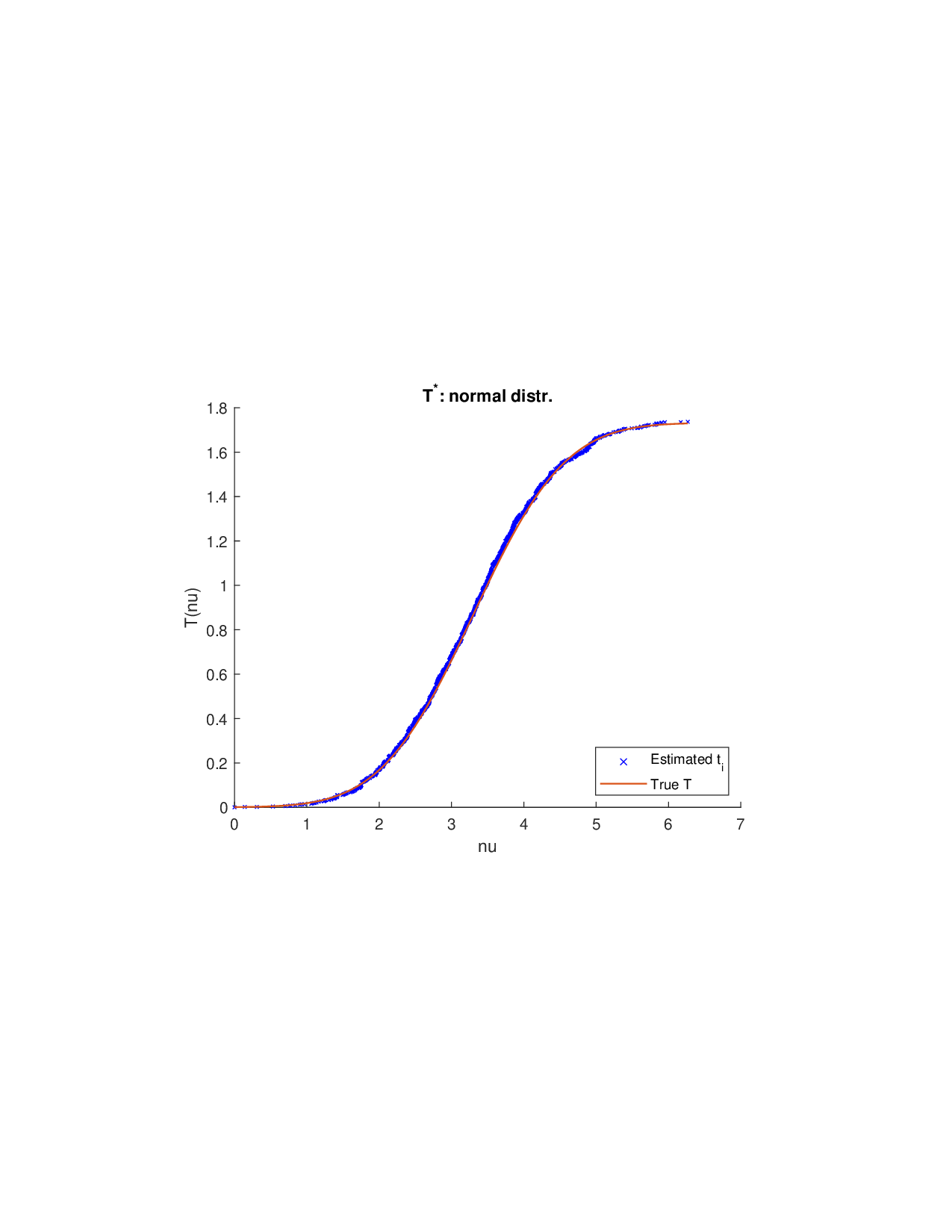
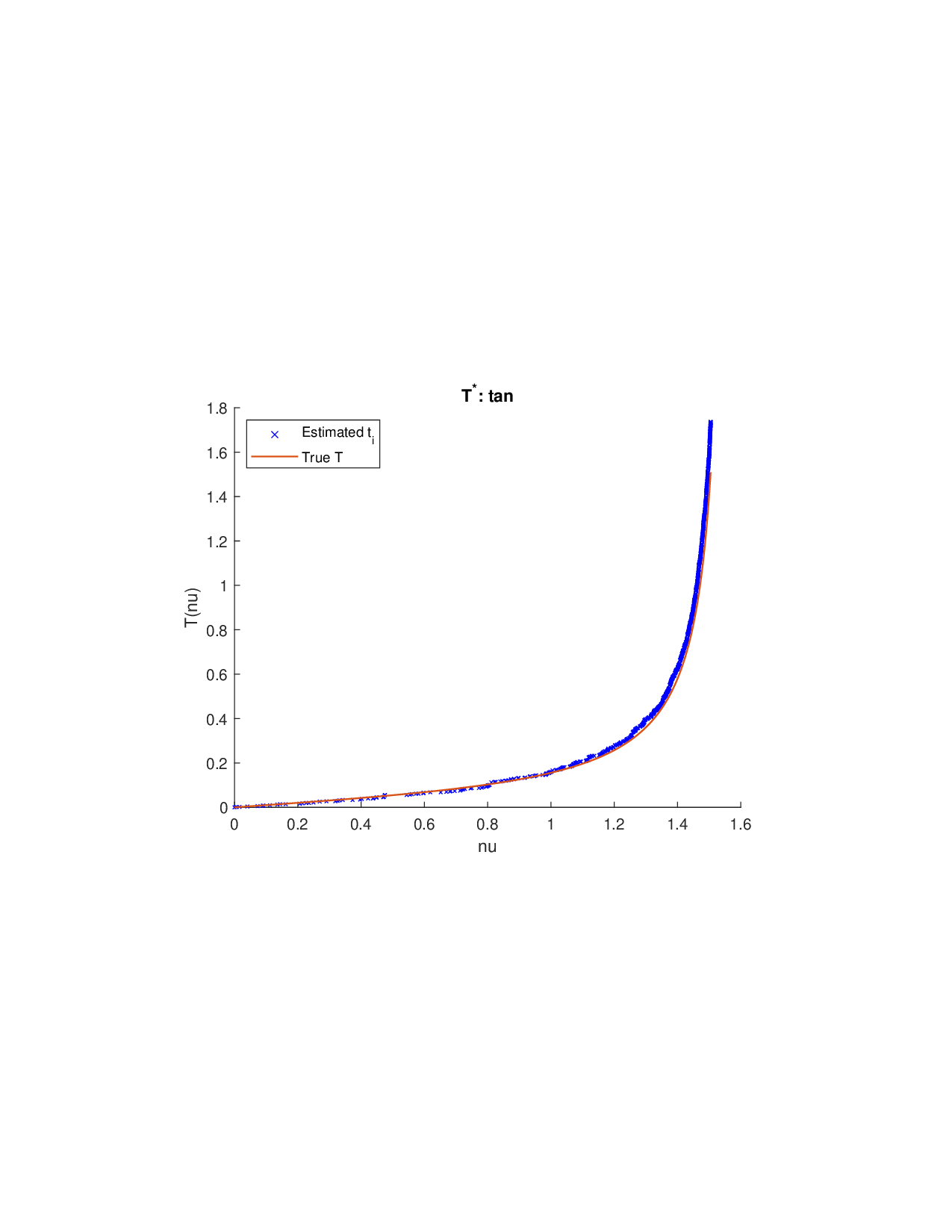
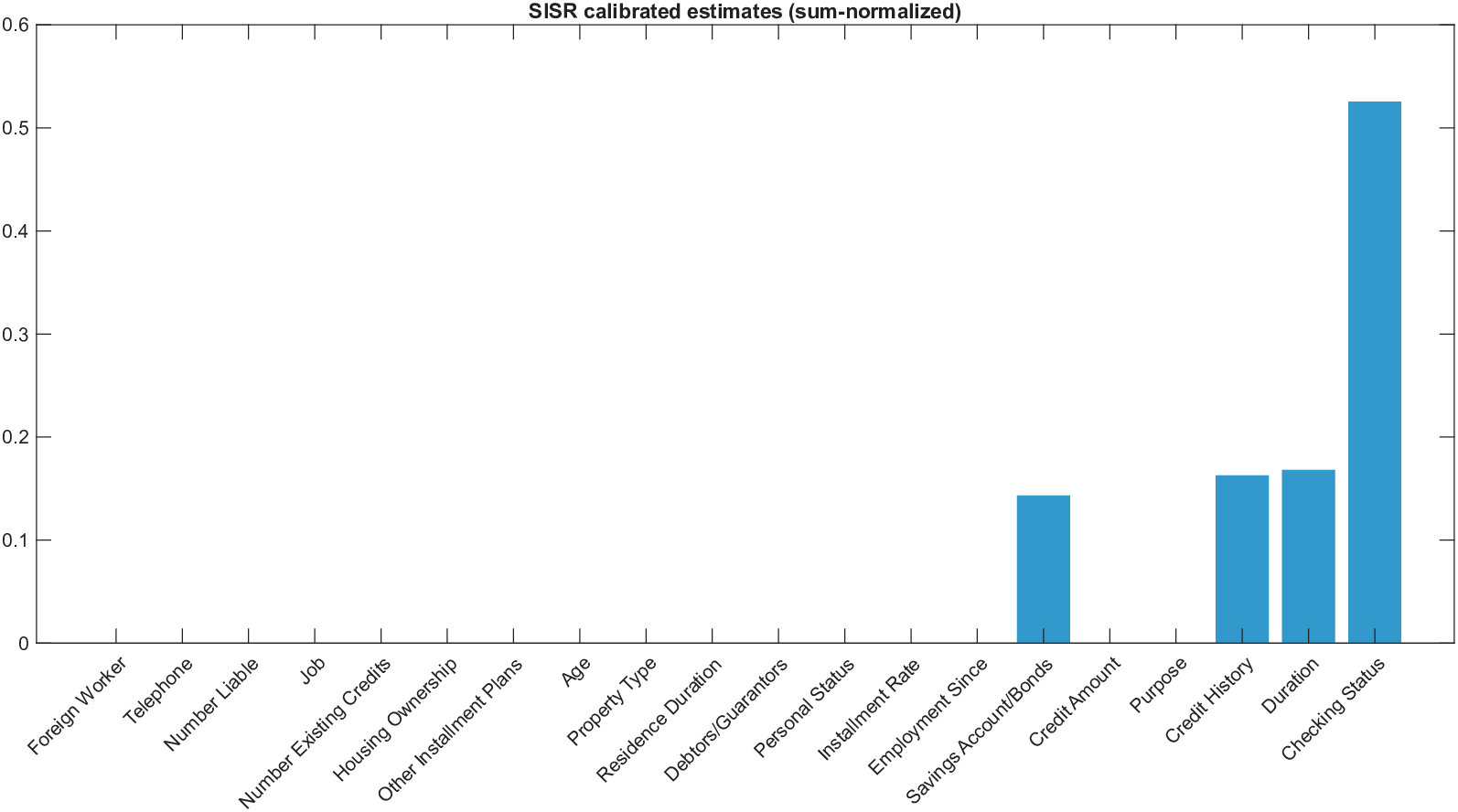
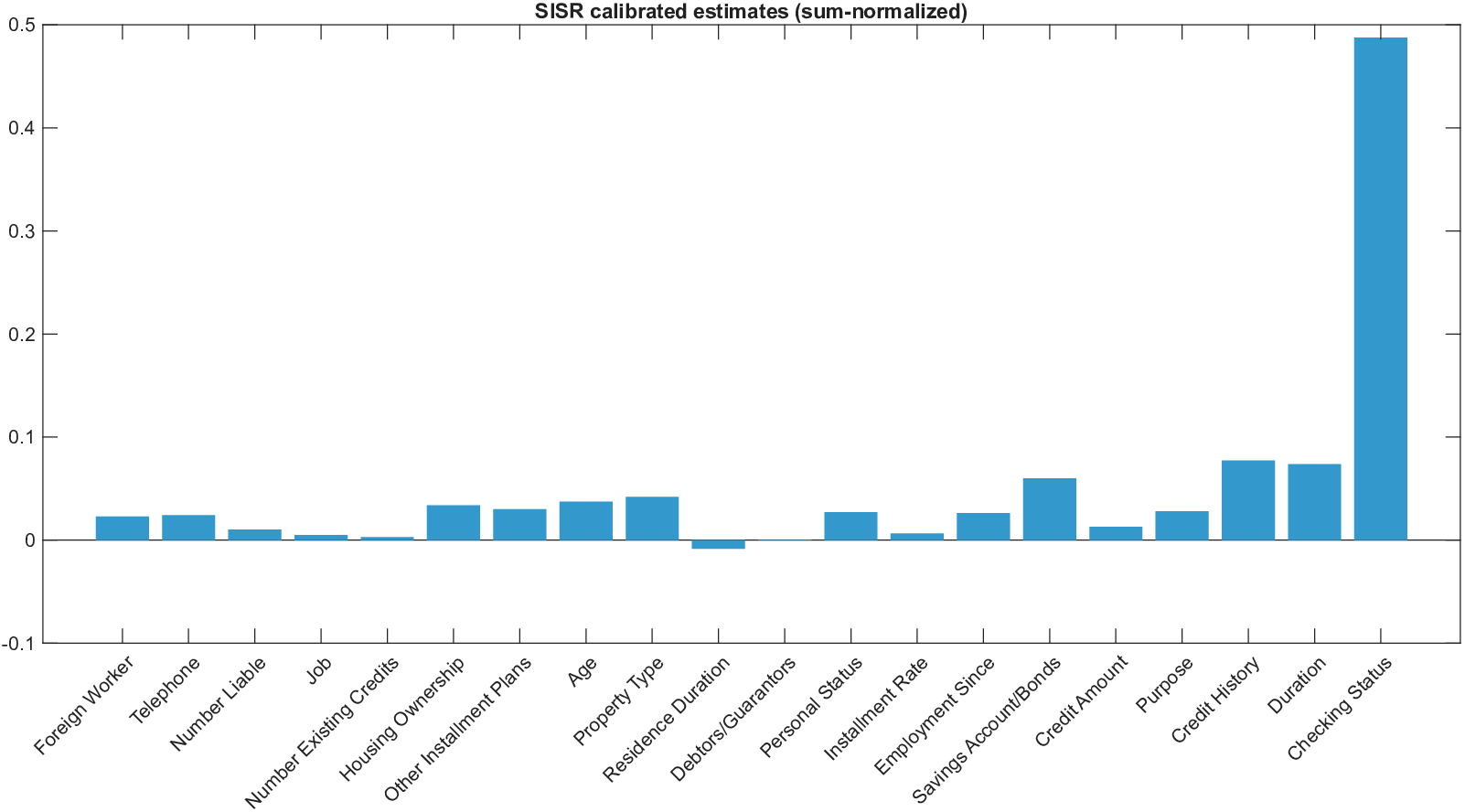
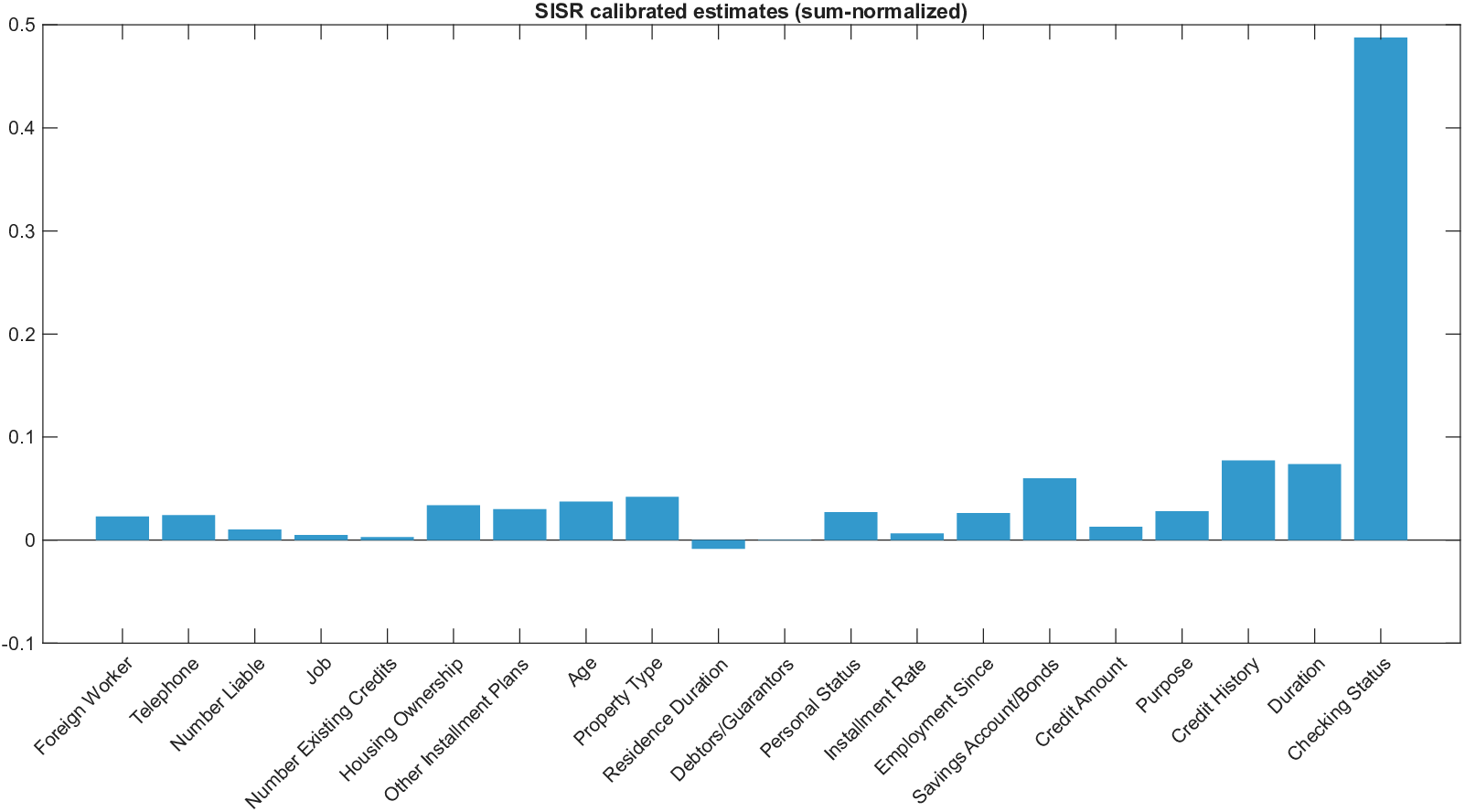
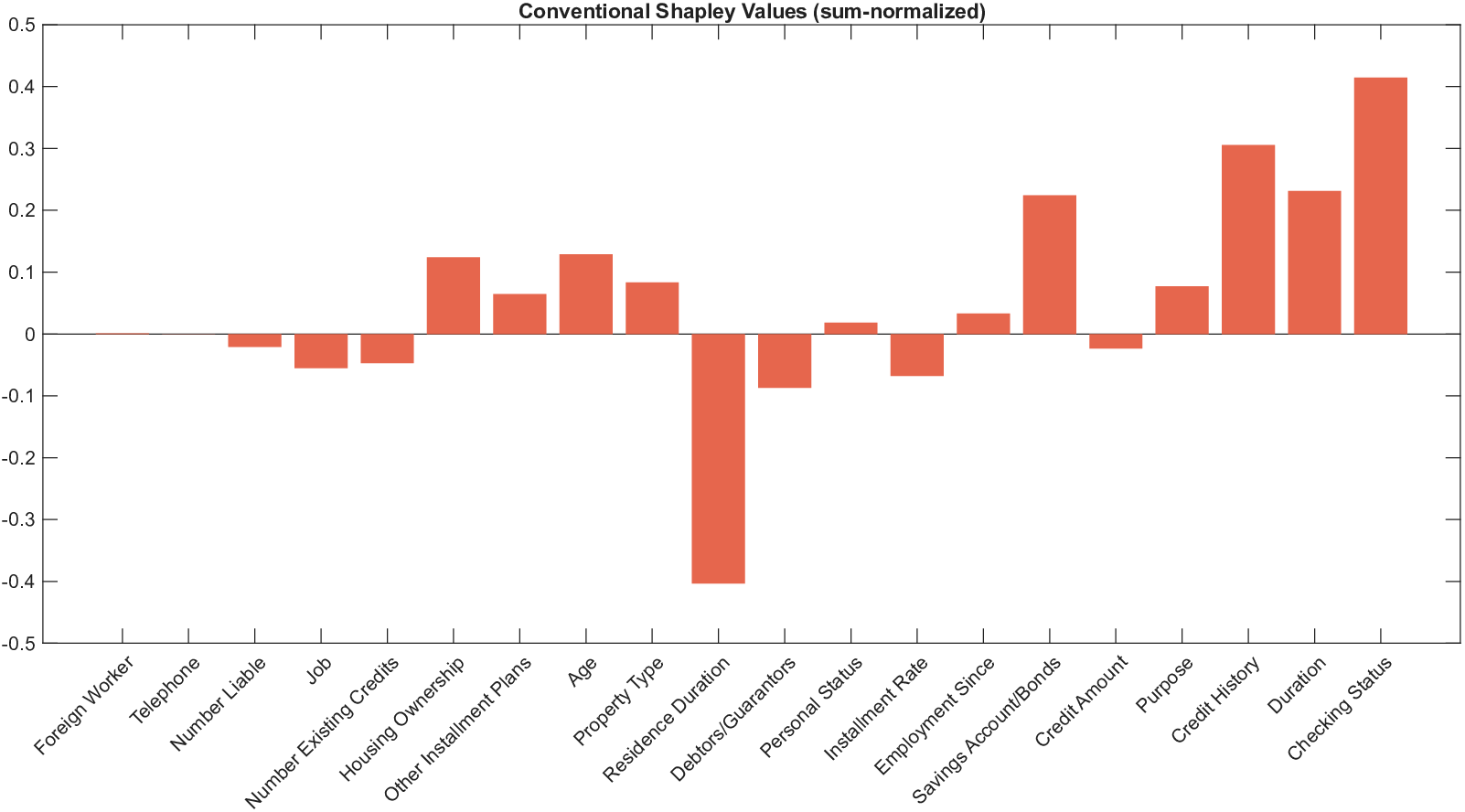
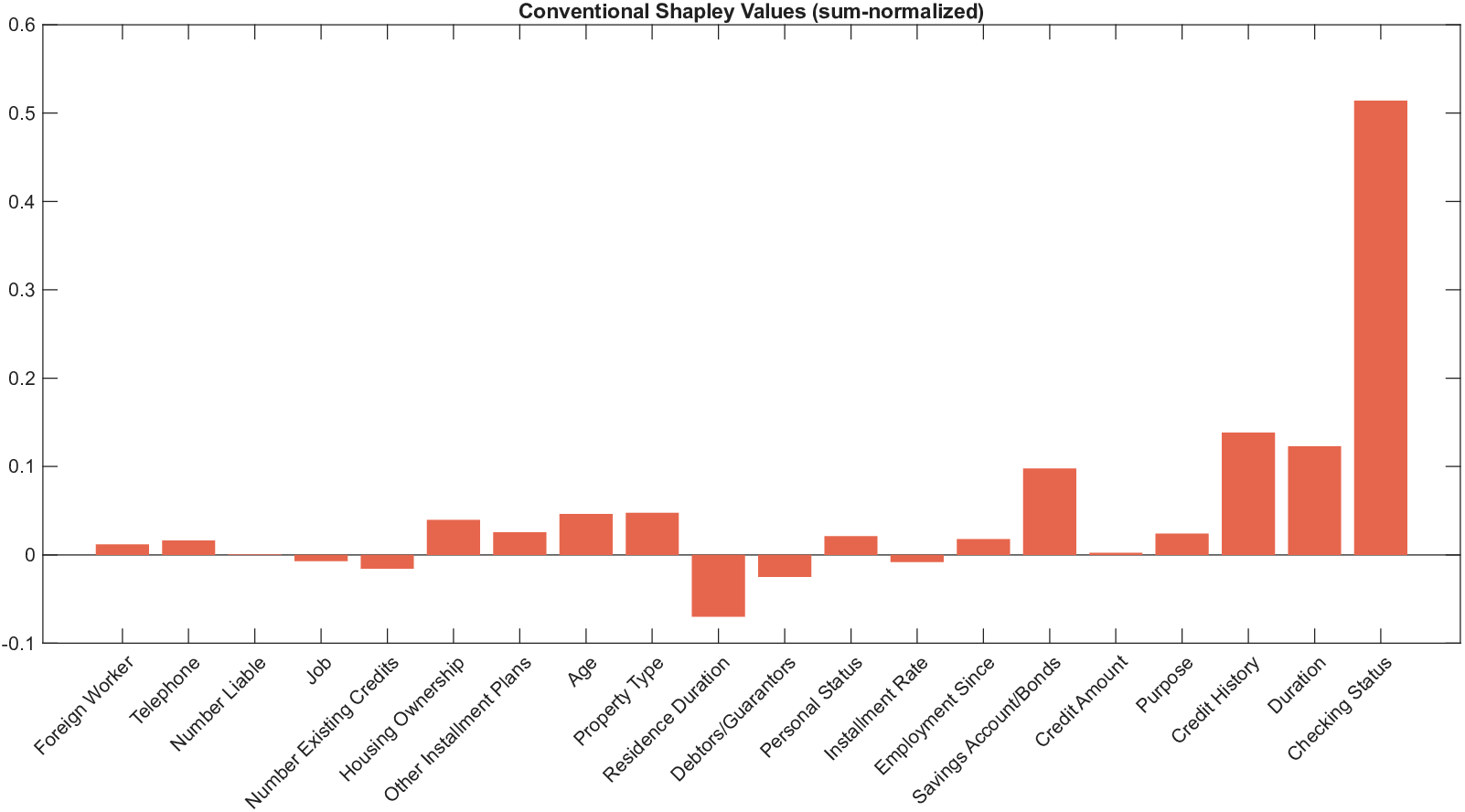
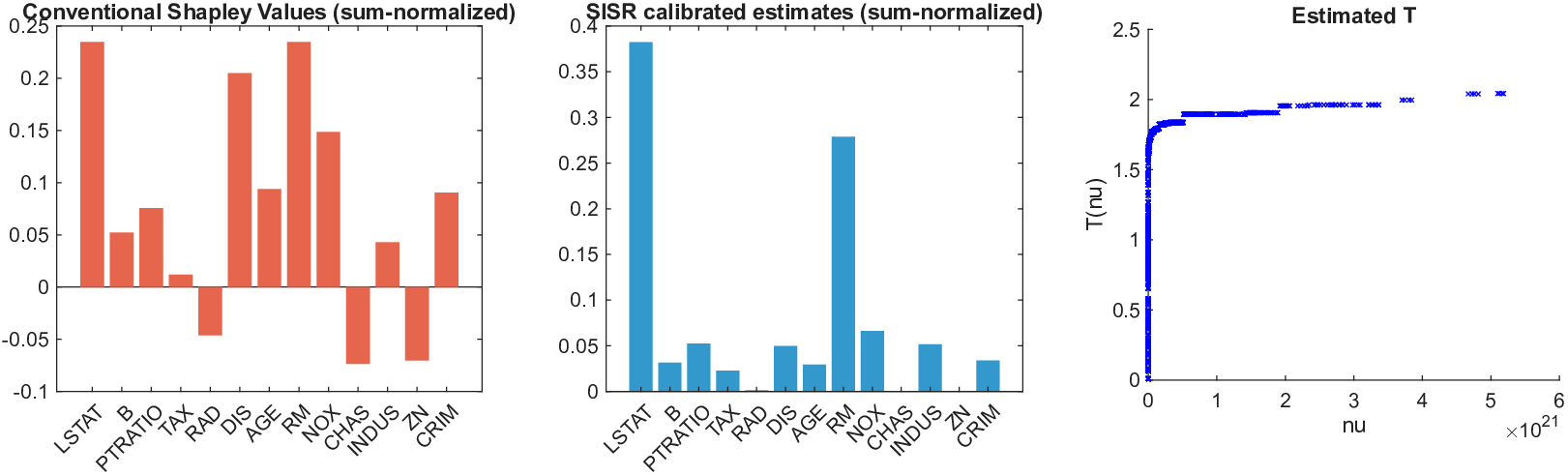
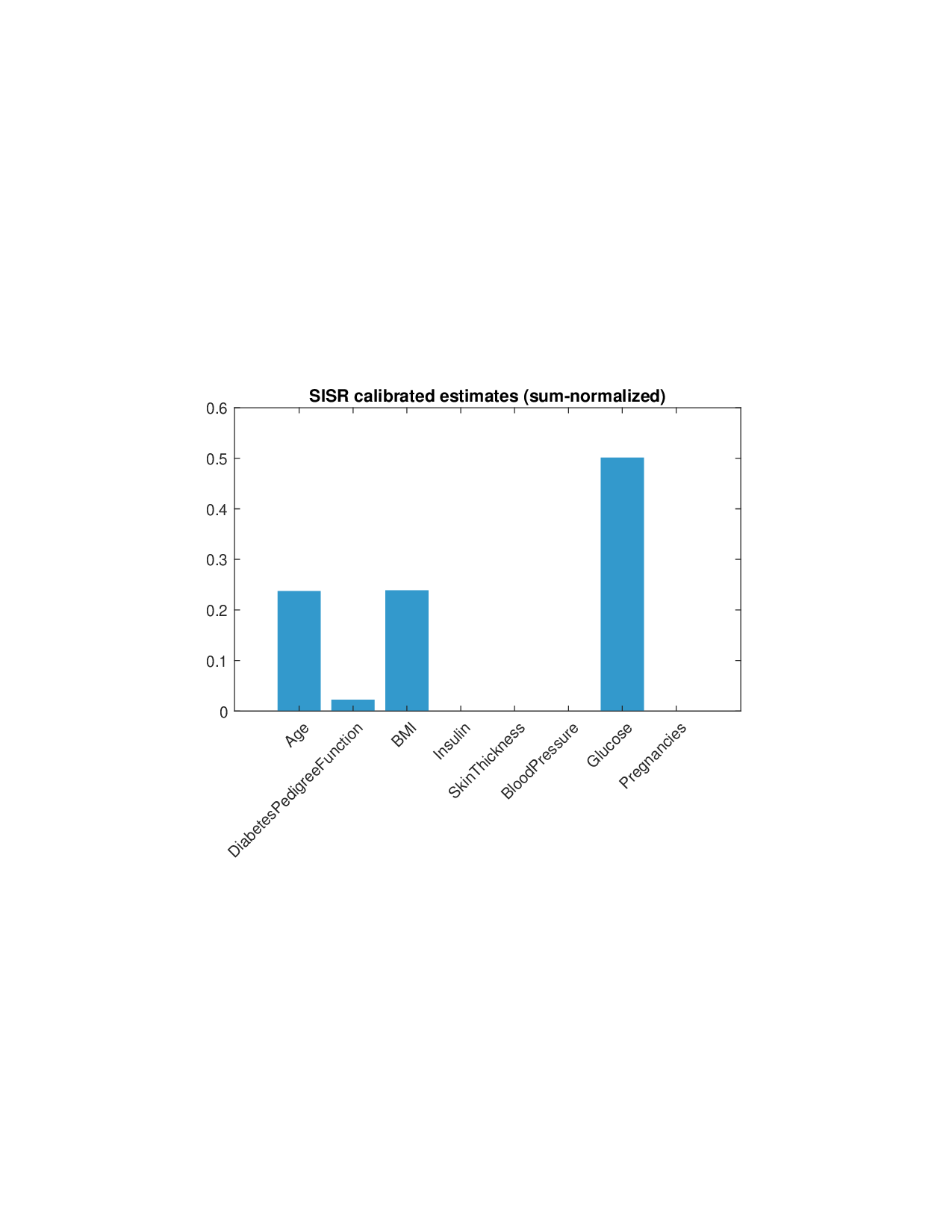
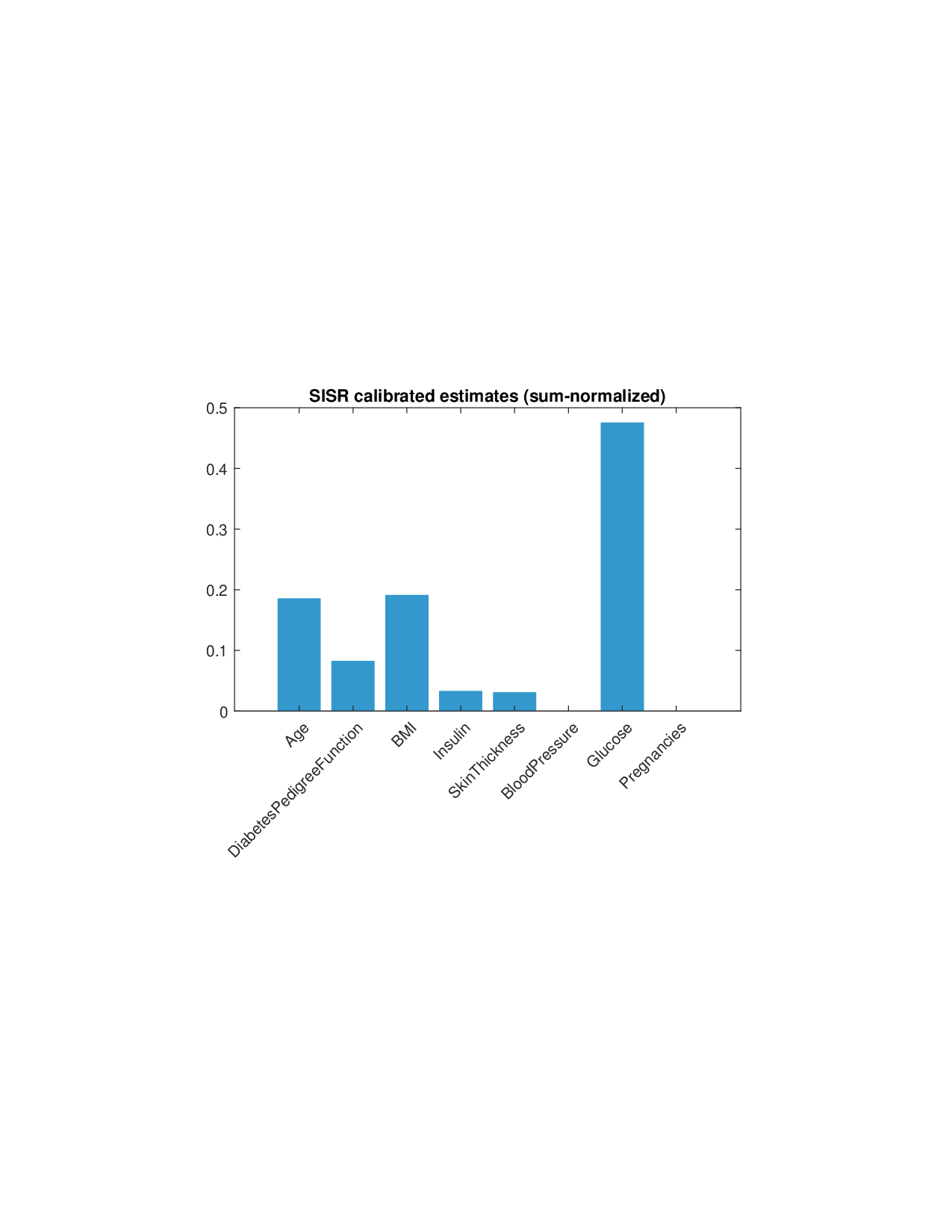
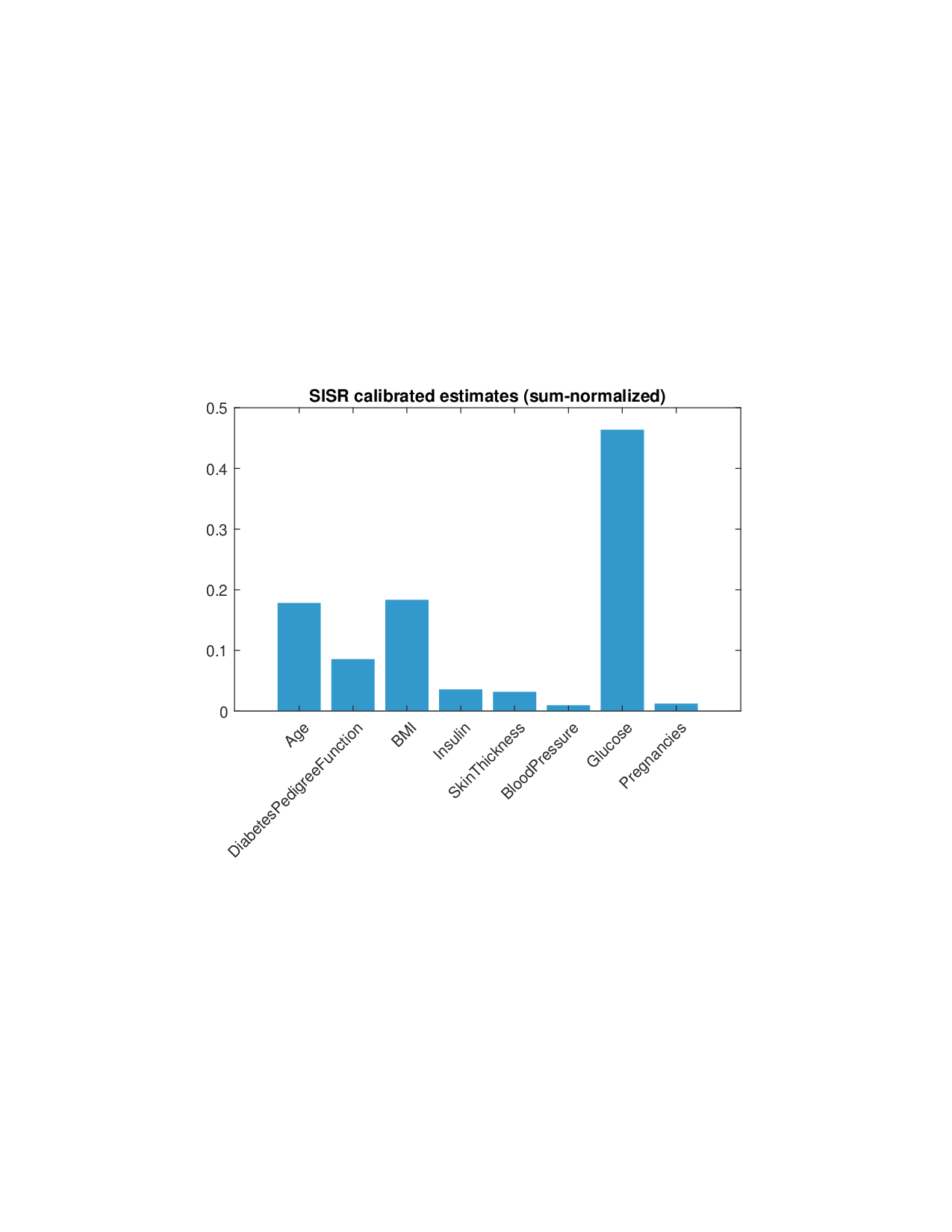
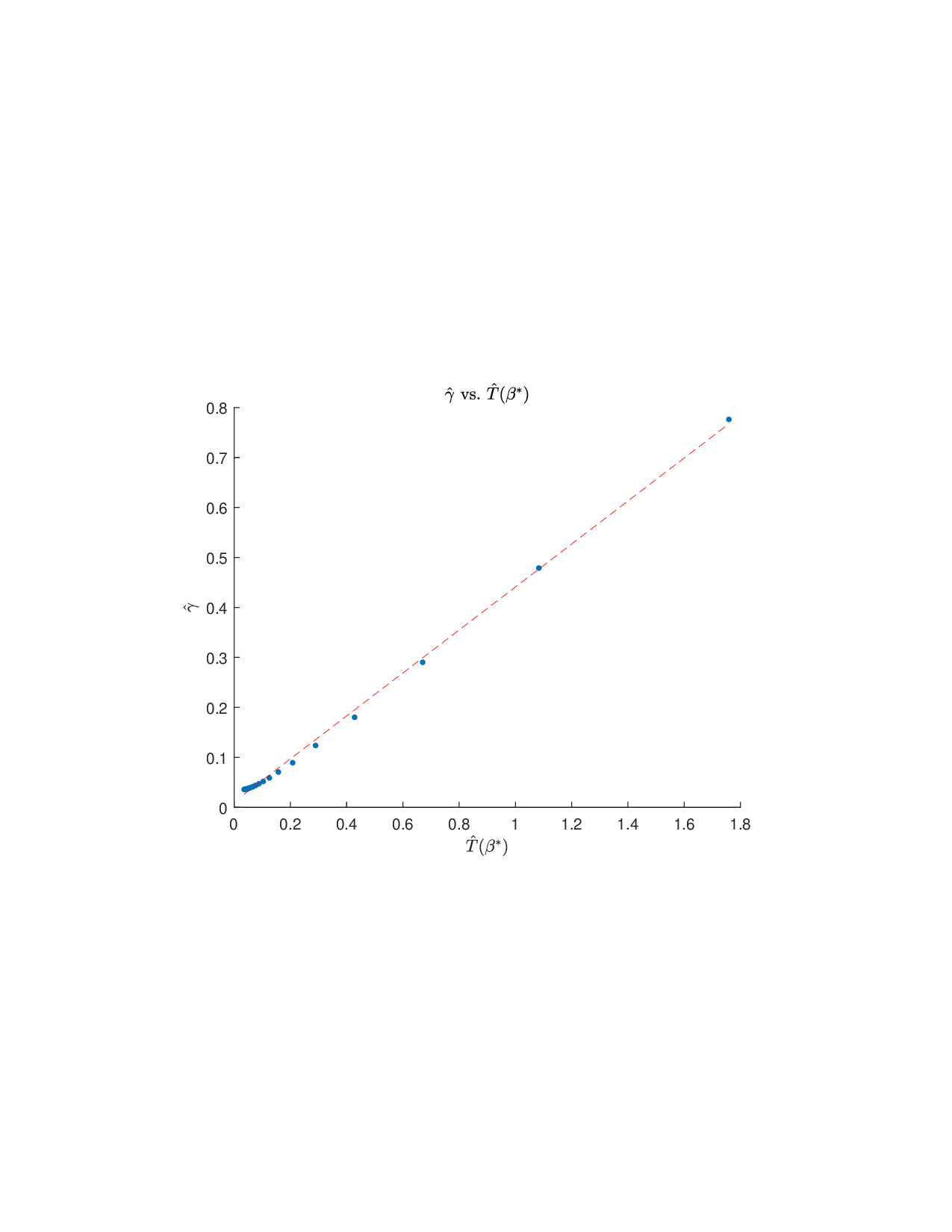
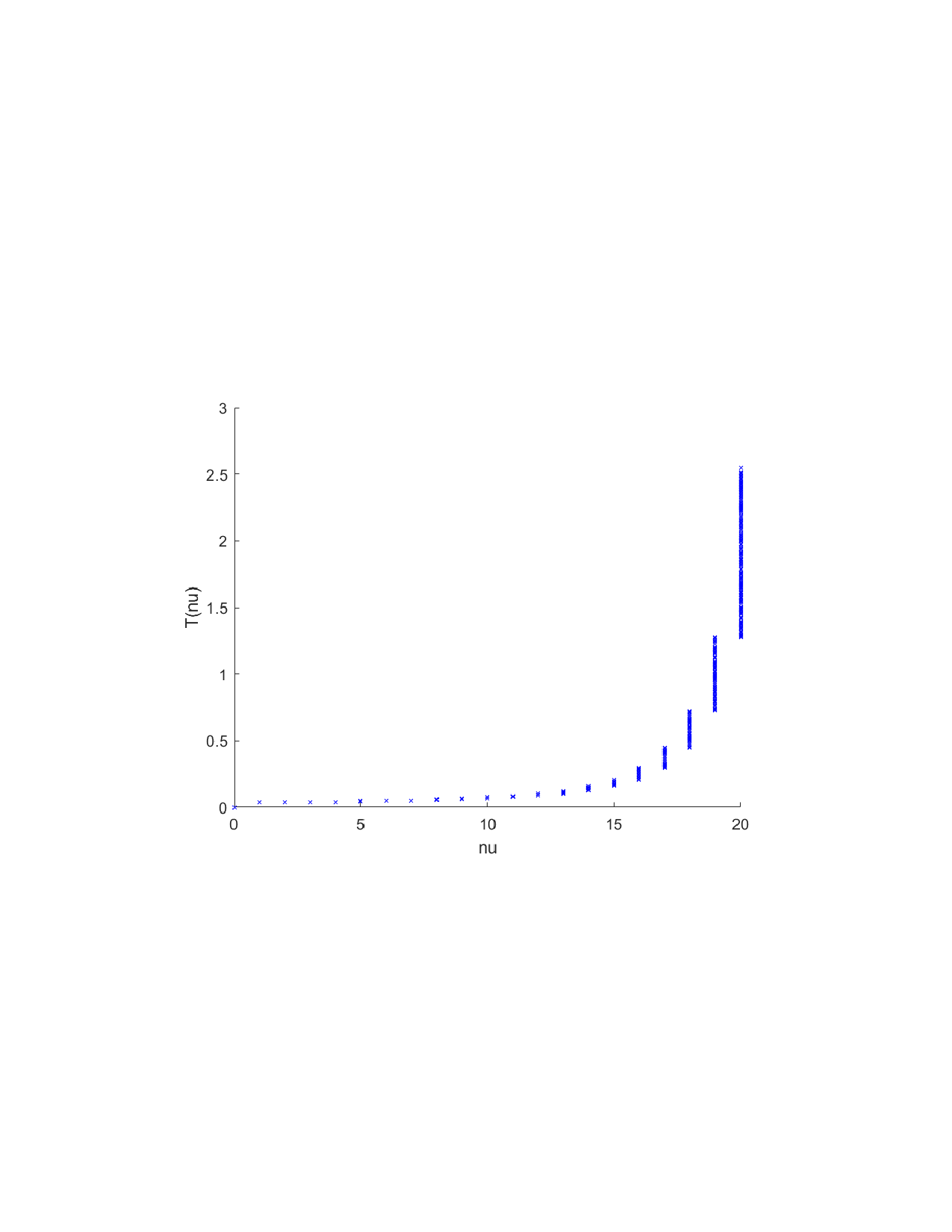
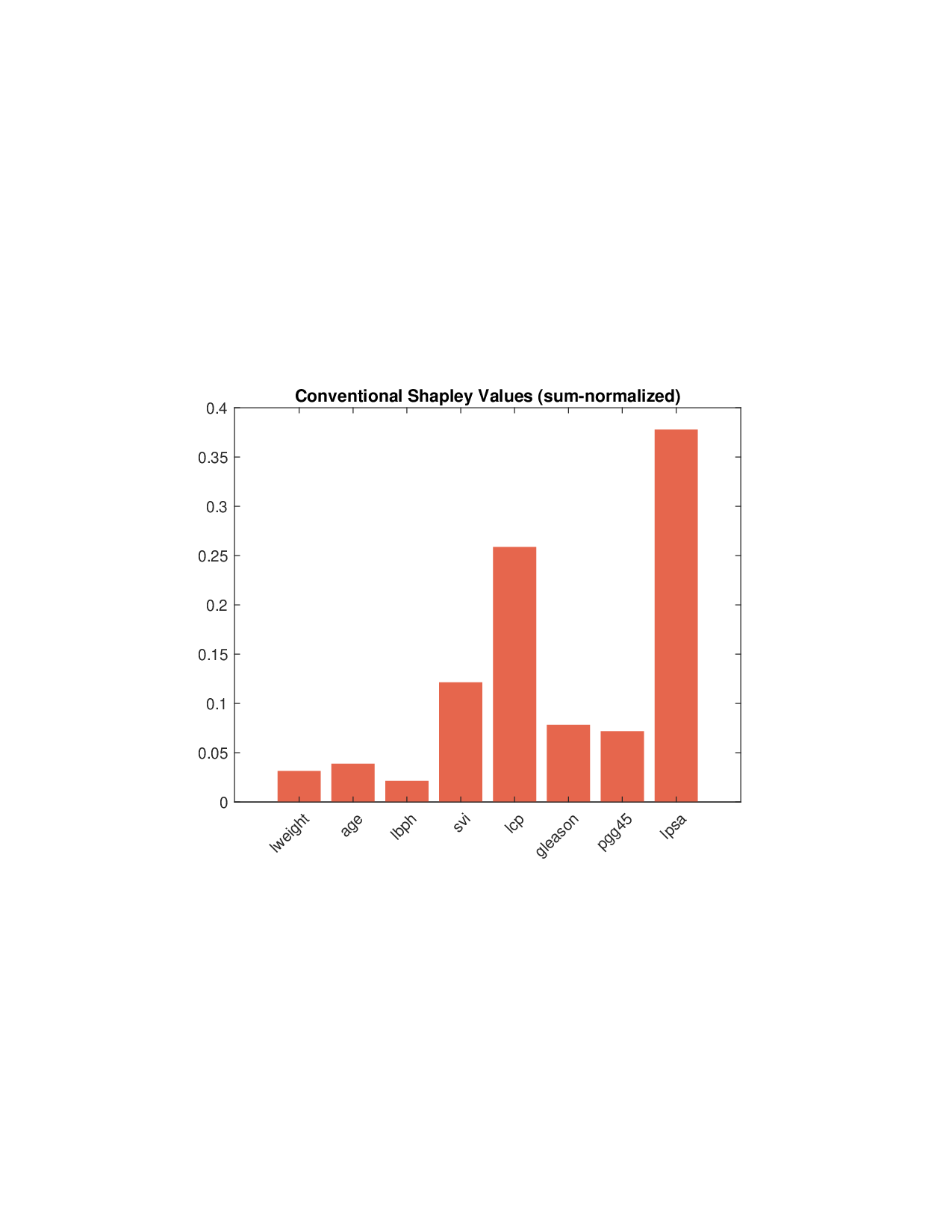
Shapley values, a gold standard for feature attribution in Explainable AI, face two primary challenges. First, the canonical Shapley framework assumes that the worth function is additive, yet real-world payoff constructions-driven by non-Gaussian distributions, heavy tails, feature dependence, or domain-specific loss scales-often violate this assumption, leading to distorted attributions. Secondly, achieving sparse explanations in high-dimensional settings by computing dense Shapley values and then applying ad hoc thresholding is prohibitively costly and risks inconsistency. We introduce Sparse Isotonic Shapley Regression (SISR), a unified nonlinear explanation framework. SISR simultaneously learns a monotonic transformation to restore additivity-obviating the need for a closed-form specification-and enforces an L0 sparsity constraint on the Shapley vector, enhancing computational efficiency in large feature spaces. Its optimization algorithm leverages Pool-Adjacent-Violators for efficient isotonic regression and normalized hard-thresholding for support selection, yielding ease in implementation and global convergence guarantees. Analysis shows that SISR recovers the true transformation in a wide range of scenarios and achieves strong support recovery even in high noise. Moreover, we are the first to demonstrate that irrelevant features and inter-feature dependencies can induce a true payoff transformation that deviates substantially from linearity. Extensive experiments in regression, logistic regression, and tree ensembles demonstrate that SISR stabilizes attributions across payoff schemes, correctly filters irrelevant features; in contrast, standard Shapley values suffer severe rank and sign distortions. By unifying nonlinear transformation estimation with sparsity pursuit, SISR advances the frontier of nonlinear 1 arXiv:2512.03112v1 [cs.LG] 2 Dec 2025 explainability, providing a theoretically grounded and practical attribution framework.
Deep Dive into Beyond Additivity: Sparse Isotonic Shapley Regression toward Nonlinear Explainability.
Shapley values, a gold standard for feature attribution in Explainable AI, face two primary challenges. First, the canonical Shapley framework assumes that the worth function is additive, yet real-world payoff constructions-driven by non-Gaussian distributions, heavy tails, feature dependence, or domain-specific loss scales-often violate this assumption, leading to distorted attributions. Secondly, achieving sparse explanations in high-dimensional settings by computing dense Shapley values and then applying ad hoc thresholding is prohibitively costly and risks inconsistency. We introduce Sparse Isotonic Shapley Regression (SISR), a unified nonlinear explanation framework. SISR simultaneously learns a monotonic transformation to restore additivity-obviating the need for a closed-form specification-and enforces an L0 sparsity constraint on the Shapley vector, enhancing computational efficiency in large feature spaces. Its optimization algorithm leverages Pool-Adjacent-Violators for effic
Let F = {1, 2, . . . , p} denote the set of p features, and let ν : 2 F → R be the characteristic function or payoff function, with ν(A) representing the contribution or worth generated by a subset A ⊆ F of features working together (often referred to as a coalition in game theory). A central question in economics and cooperative game theory is how to fairly allocate the value of a coalition to its individual members. The Shapley value (Shapley, 1953), a concept from Nobel laureate Lloyd Shapley, offers a theoretically grounded solution by assigning payoffs according to each member's average marginal contribution across all possible subsets.
In this paper, we denote the Shapley value for feature j by β j for 1 ≤ j ≤ p, quantifying the fair share or importance of feature j; for a subset A ⊆ F we define β A as the vector [β j ] j∈A ∈ R |A| . For brevity, we also write ν A as shorthand for ν(A) for any subset A ⊆ F . Shapley values establish a connection between the payoff function ν(A) and the underlying model parameters β A . To make this dependence explicit, we introduce a function V (β 1 , . . . , β p ; A), also denoted by V A ({β j } j∈A ), characterizing the deterministic, noise-free contribution associated with subset A:
where ∼ denotes approximate equality up to noise, a convention adopted throughout the paper.
In recent years, Shapley values have attracted substantial attention in machine learning, particularly in the field of Explainable AI (XAI) (Ancona et al., 2019). While assessing variable importance in simple regression is straightforward using traditional tools like T -tests and p-values, this task becomes a formidable challenge for the complex, “black-box” models now widely used to analyze sequential data in economics and finance. For sophisticated models-ranging from tree-based ensembles like random forests and boosted trees to deep neural networks like Long Short-Term Memory (LSTM) networks-standard inference methods are no longer applicable, making interpretation notoriously difficult.
Shapley values provide a model-agnostic framework for quantifying feature importance. This is applied in two main ways: local explanations, which explain a single prediction (e.g., SHAP by Lundberg and Lee (2017)), and global explanations, which explain the model’s overall behavior (e.g., SAGE by Covert et al. (2020)). Our work focuses on the global setting, where the goal is to find a single, interpretable set of importance values for the entire model. Specifically, for a prediction model f (x), where x ∈ R p , researchers first design a payoff function ν A over subsets A ⊆ F to quantify the model’s global performance when using only the features in A. This reframes the explanation task as a “credit allocation” problem, enabling the use of Shapley values to quantify feature importance, and perhaps more importantly, to construct interpretable surrogate models based on restricted feature sets. The resulting additive structure of individual feature contributions is the very property appealing for interpretability, as it provides an intuitive, linear explanation of an intricate model’s behavior, a primary goal in XAI.
However, standard Shapley-based methods also face several limitations that restrict their practical utility in complex modeling scenarios.
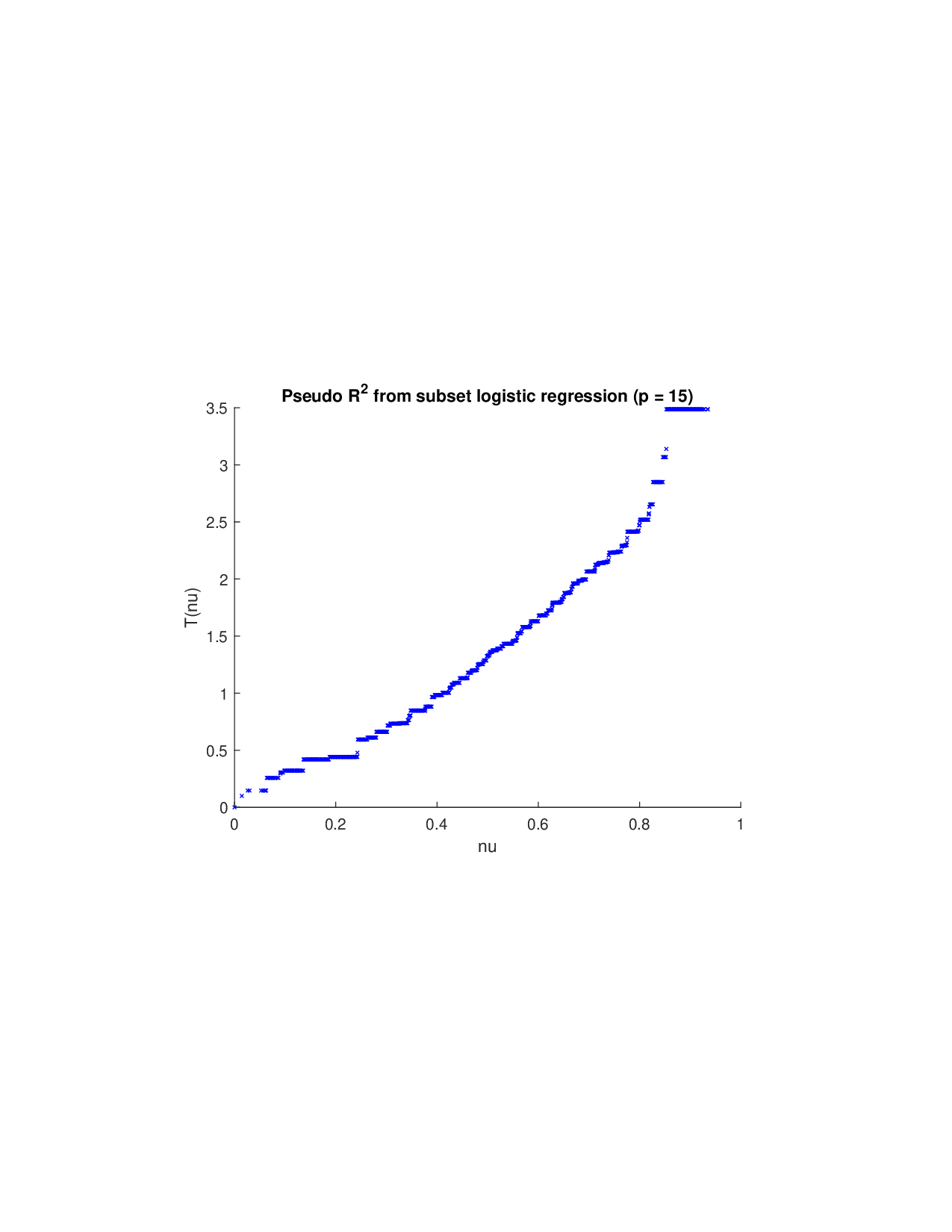
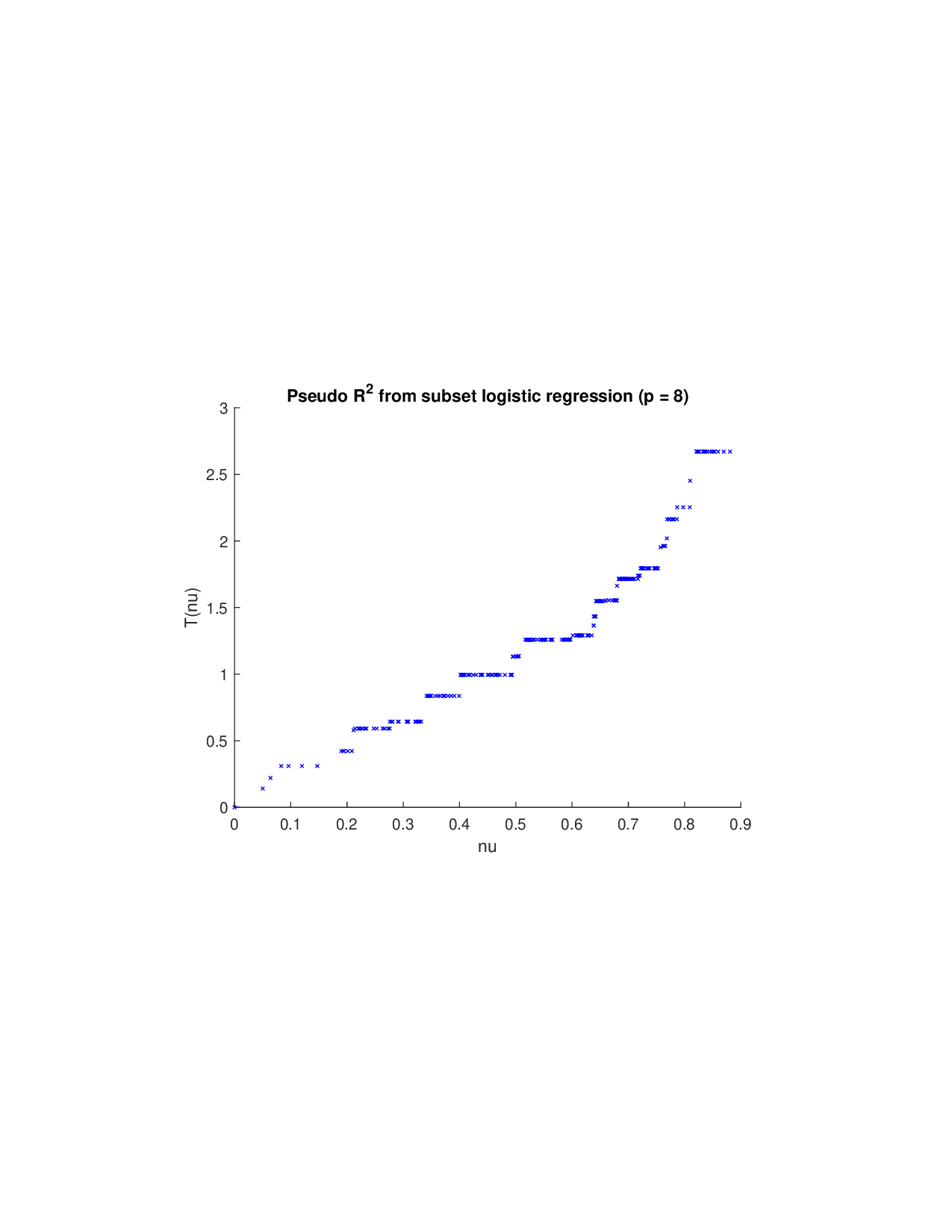
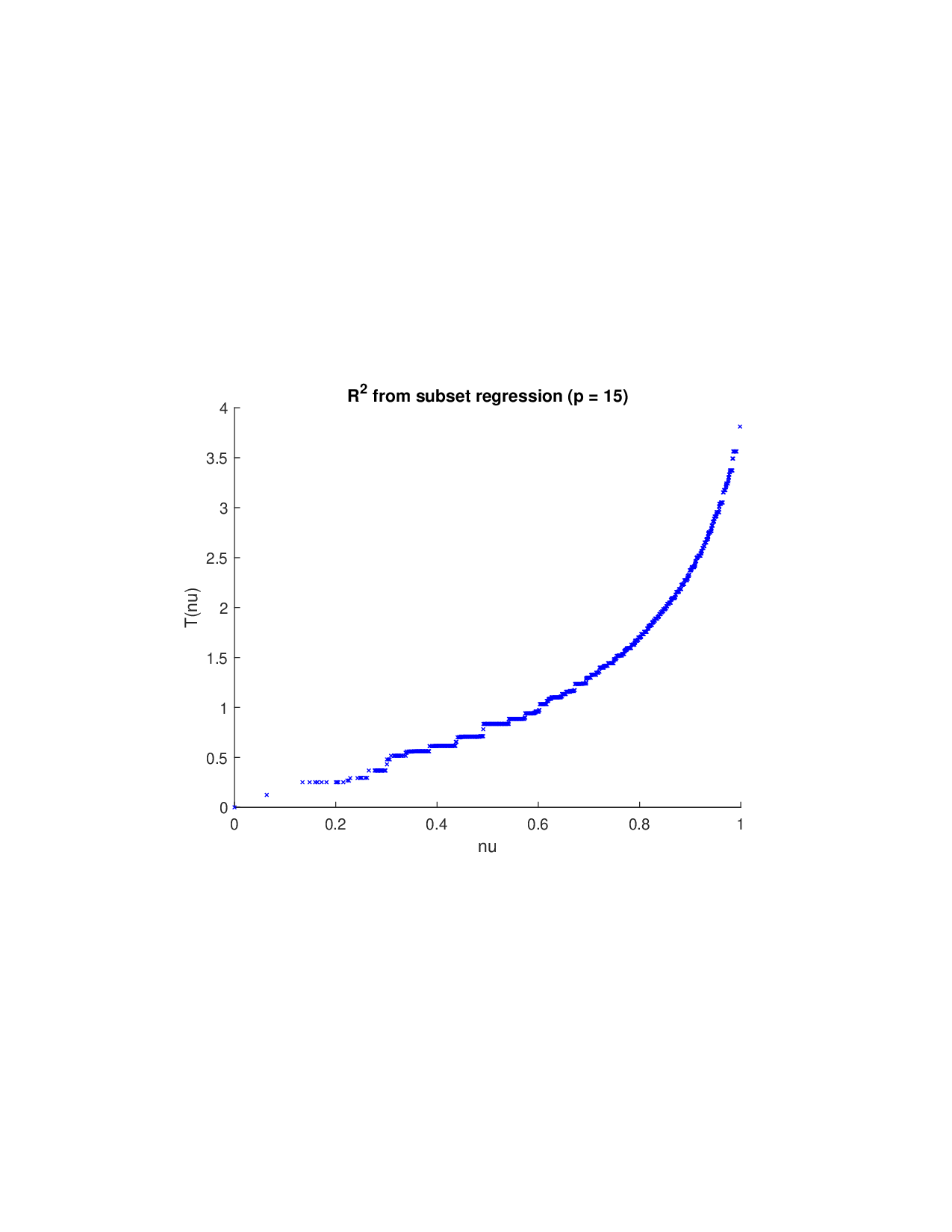
(i) Moving beyond additive frameworks: Given a prediction model, various methods have been proposed to construct the payoff function ν A for Shapley-value analysis. (a) A fundamental approach involves retraining the model on every subset of features A and defining ν A based on the reduction in statistical accuracy (such as R 2 in regression) (Lipovetsky and Conklin, 2001). However, this exhaustive procedure may be computationally prohibitive for modern AI models due to its exponential cost. (b) To circumvent retraining, SAGE (Covert et al., 2020) provides an efficient alternative: it keeps the trained model fixed and quantifies the expected loss increase when certain features are made unavailable. The approach marginalizes over missing inputs-conditionally in theory and, for scalability, interventionally in practice. (c) In contrast, SHAP and TreeSHAP (Lundberg and Lee, 2017;Lundberg et al., 2020) define local payoffs for each instance by marginalizing absent features and then derive global importance by aggregating the resulting local Shapley attributions. (d) Other global variants, such as Sobol-Shapley indices (Owen, 2014) and derivative-based formulations (Duan and Okten, 2025), approximate risk or variance decomposition under specific assumptions (feature independence, distributional priors, or model smoothness), often motivated by numerical sensitivity analysis rather than prediction risk. Once ν A is constructed, researchers often mechanically apply the Shapley formula to compute feature attributions.
However, the theoretical justification for Shapley values relies on several foundational “axioms’’-efficiency, symmetry, linearity, and nullity (Shap
…(Full text truncated)…
This content is AI-processed based on ArXiv data.