📝 Original Info
- Title: SurveyEval 자동 설문 생성 시스템 평가 종합 벤치마크
- ArXiv ID: 2512.02763
- Date: 2025-12-02
- Authors: Jiahao Zhao, Shuaixing Zhang, Nan Xu, Lei Wang
📝 Abstract
LLM-based automatic survey systems are transforming how users acquire information from the web by integrating retrieval, organization, and content synthesis into end-to-end generation pipelines. While recent works focus on developing new generation pipelines, how to evaluate such complex systems remains a significant challenge. To this end, we introduce SurveyEval, a comprehensive benchmark that evaluates automatically generated surveys across three dimensions: overall quality, outline coherence, and reference accuracy. We extend the evaluation across 7 subjects and augment the LLM-as-a-Judge framework with human references to strengthen evaluation-human alignment. Evaluation results show that while general long-text or paper-writing systems tend to produce lower-quality surveys, specialized survey-generation systems are able to deliver substantially higher-quality results. We envision SurveyEval as a scalable testbed to understand and improve automatic survey systems across diverse subjects and evaluation criteria.
CCS Concepts • Computing methodologies → Natural language generation.
💡 Deep Analysis
Deep Dive into SurveyEval 자동 설문 생성 시스템 평가 종합 벤치마크.
LLM-based automatic survey systems are transforming how users acquire information from the web by integrating retrieval, organization, and content synthesis into end-to-end generation pipelines. While recent works focus on developing new generation pipelines, how to evaluate such complex systems remains a significant challenge. To this end, we introduce SurveyEval, a comprehensive benchmark that evaluates automatically generated surveys across three dimensions: overall quality, outline coherence, and reference accuracy. We extend the evaluation across 7 subjects and augment the LLM-as-a-Judge framework with human references to strengthen evaluation-human alignment. Evaluation results show that while general long-text or paper-writing systems tend to produce lower-quality surveys, specialized survey-generation systems are able to deliver substantially higher-quality results. We envision SurveyEval as a scalable testbed to understand and improve automatic survey systems across diverse su
📄 Full Content
SurveyEval: Towards Comprehensive Evaluation of
LLM-Generated Academic Surveys
Jiahao Zhao∗
zhaojiahao2019@ia.ac.cn
Beijing Wenge Technology Co., Ltd.
Institute of Automation, Chinese Academy of Sciences
Beijing, China
Shuaixing Zhang∗
shuaixing.zhang@wenge.com
Beijing Wenge Technology Co., Ltd.
Beijing, China
Nan Xu
nan.xu@wenge.com
Beijing Wenge Technology Co., Ltd.
Beijing, China
Lei Wang
lei.wang@wenge.com
Beijing Wenge Technology Co., Ltd.
Beijing, China
Abstract
LLM-based automatic survey systems are transforming how users
acquire information from the web by integrating retrieval, organi-
zation, and content synthesis into end-to-end generation pipelines.
While recent works focus on developing new generation pipelines,
how to evaluate such complex systems remains a significant chal-
lenge. To this end, we introduce SurveyEval, a comprehensive
benchmark that evaluates automatically generated surveys across
three dimensions: overall quality, outline coherence, and refer-
ence accuracy. We extend the evaluation across 7 subjects and
augment the LLM-as-a-Judge framework with human references to
strengthen evaluation–human alignment. Evaluation results show
that while general long-text or paper-writing systems tend to pro-
duce lower-quality surveys, specialized survey-generation systems
are able to deliver substantially higher-quality results. We envi-
sion SurveyEval as a scalable testbed to understand and improve
automatic survey systems across diverse subjects and evaluation
criteria.
CCS Concepts
• Computing methodologies →Natural language generation.
Keywords
Survey Evaluation, Automated Survey, Large Language Models
ACM Reference Format:
Jiahao Zhao, Shuaixing Zhang, Nan Xu, and Lei Wang. 2026. SurveyEval:
Towards Comprehensive Evaluation of LLM-Generated Academic Surveys.
In Proceedings of (preprint). ACM, New York, NY, USA, 4 pages. https:
//doi.org/XXXXXXX.XXXXXXX
∗Both authors contributed equally to this research.
Permission to make digital or hard copies of all or part of this work for personal or
classroom use is granted without fee provided that copies are not made or distributed
for profit or commercial advantage and that copies bear this notice and the full citation
on the first page. Copyrights for components of this work owned by others than the
author(s) must be honored. Abstracting with credit is permitted. To copy otherwise, or
republish, to post on servers or to redistribute to lists, requires prior specific permission
and/or a fee. Request permissions from permissions@acm.org.
preprint, in progress
© 2026 Copyright held by the owner/author(s). Publication rights licensed to ACM.
ACM ISBN 978-x-xxxx-xxxx-x/YYYY/MM
https://doi.org/XXXXXXX.XXXXXXX
1
Introduction
The rapid advancement of large language models (LLMs) has demon-
strated remarkable potential in complex text-generation tasks such
as academic writing, literature reviews, and scientific reports [1].
LLM-based automatic survey systems are transforming how users
acquire knowledge from vast information repositories by integrat-
ing retrieval, organization, and content synthesis into streamlined
end-to-end generation pipelines [4].
Both academia and industry have introduced various special-
ized systems for survey generation. These automated writing sys-
tems can be broadly categorized into three types: general long-
text writing systems (e.g., Kimi [2], GLM [3]) that provide broader
capabilities for extended text generation; paper-writing systems
(e.g., Chengpian [5], Doubao Paper Mode [8]) that focus on struc-
tured composition of complete research papers; and survey-writing
agents (e.g., SurveyGo [9], SurveyX [7], Panshi ScienceOne [6])
specifically designed for academic survey generation. These sys-
tems not only process large volumes of literature and extract key
information, but also generate well-structured survey drafts com-
plete with sectioned organization, citation annotations, and logical
coherence.
However, while recent research has primarily focused on de-
veloping new generation pipelines, how to evaluate such complex
systems remains a significant challenge. Existing evaluation ap-
proaches often rely on ad-hoc human subjective scoring of individ-
ual cases, lacking reusable quantitative metrics that could support
cross-system comparison, performance attribution, and systematic
improvement. These issues severely constrain quality assurance and
capability enhancement of survey-writing systems. Therefore, es-
tablishing a standardized evaluation benchmark for survey-writing
systems is not only critical for ensuring output quality and reli-
ability, but also provides the research community with a unified
foundation for performance comparison and capability diagnosis.
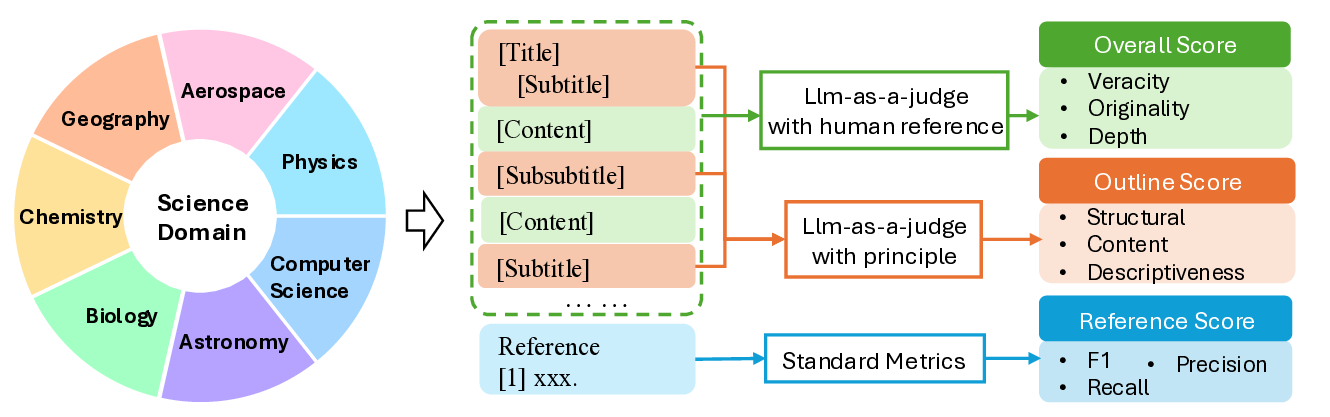
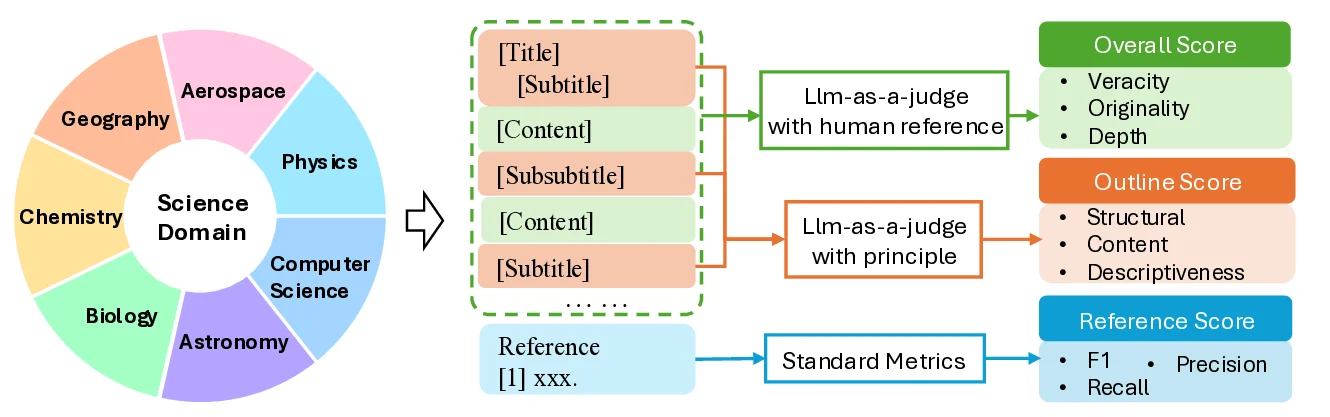
To address this gap, we introduce SurveyEval, a comprehensive
benchmark that evaluates automatically generated surveys across
three dimensions: overall quality, outline coherence, and reference ac-
curacy. We extend the evaluation across seven academic dis
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.