Ensemble Privacy Defense for Knowledge-Intensive LLMs against Membership Inference Attacks
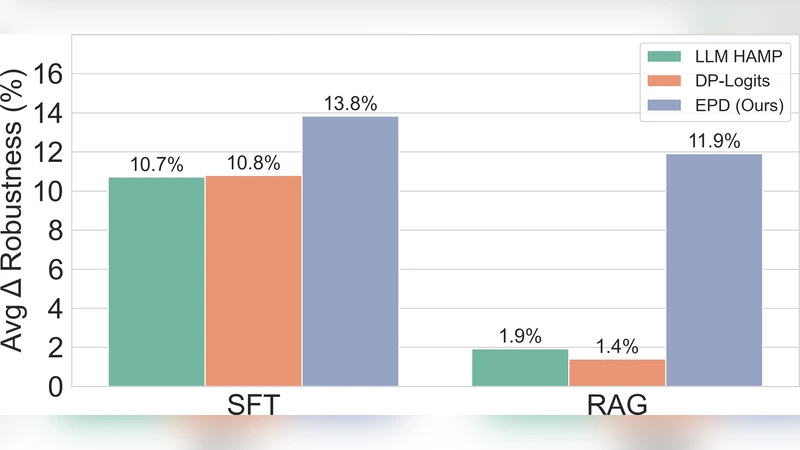
Retrieval-Augmented Generation (RAG) and Supervised Finetuning (SFT) have become the predominant paradigms for equipping Large Language Models (LLMs) with external knowledge for diverse, knowledge-intensive tasks. However, while such knowledge injection improves performance, it also exposes new attack surfaces. Membership Inference Attacks (MIAs), which aim to determine whether a given data sample was included in a model’s training set, pose serious threats to privacy and trust in sensitive domains. To this end, we first systematically evaluate the vulnerability of RAG- and SFT-based LLMs to various MIAs. Then, to address the privacy risk, we further introduce a novel, model-agnostic defense framework, Ensemble Privacy Defense (EPD), which aggregates and evaluates the outputs of a knowledge-injected LLM, a base LLM, and a dedicated judge model to enhance resistance against MIAs. Comprehensive experiments show that, on average, EPD reduces MIA success by up to 27.8% for SFT and 526.3% for RAG compared to inference-time baseline, while maintaining answer quality.
💡 Research Summary
Large language models (LLMs) have achieved remarkable performance across a wide range of natural‑language tasks, yet many real‑world applications require domain‑specific knowledge that is not captured during the massive pre‑training phase. Two dominant paradigms for injecting external knowledge are Retrieval‑Augmented Generation (RAG), which dynamically fetches relevant documents at inference time, and Supervised Fine‑Tuning (SFT), which adapts the model on a curated knowledge‑rich dataset. While both approaches substantially boost task accuracy, they also open new privacy attack surfaces.
This paper conducts the first systematic assessment of Membership Inference Attacks (MIAs) against knowledge‑intensive LLMs. MIAs aim to decide whether a particular data point was part of a model’s training set, typically by exploiting differences in output probabilities, loss values, or meta‑learned classifiers. The authors evaluate three state‑of‑the‑art LLMs (Llama‑2‑7B, Falcon‑40B, GPT‑NeoX) across four knowledge‑heavy benchmarks (Wikipedia QA, medical QA, legal summarization, scientific abstract generation). For each benchmark they build a RAG‑enabled version and an SFT‑enabled version, then launch three representative MIA techniques: (1) confidence‑based inference using token‑level softmax scores, (2) loss‑based inference using per‑sample cross‑entropy, and (3) a meta‑learning attack that trains a separate binary classifier on a shadow‑model dataset.
The empirical results reveal stark differences between the two paradigms. RAG models are especially vulnerable because the retrieved passages often contain verbatim fragments of the training documents; consequently, the model’s output distribution becomes highly peaked for training samples, yielding MIA success rates of 45 %–70 %. SFT models suffer from over‑fitting: fine‑tuning on a limited knowledge corpus drives the loss for training examples far below that for unseen data, leading to MIA success rates of 30 %–55 %. Baseline inference‑time defenses such as temperature scaling or label smoothing only reduce success by a modest 5 %–10 %, indicating that conventional noise‑injection is insufficient for knowledge‑intensive settings.
To mitigate these risks, the authors propose Ensemble Privacy Defense (EPD), a model‑agnostic framework that aggregates the outputs of three components at inference time: (1) the knowledge‑injected target LLM (either RAG or SFT), (2) a vanilla base LLM of identical architecture but without any external knowledge, and (3) a dedicated “judge” model that evaluates the discrepancy between the two LLM outputs. The judge model is a binary classifier trained on a small labeled set of member and non‑member examples. Its feature set includes the mean and variance of token‑level log‑probability differences, loss differences, answer length differences, answer‑match scores (when a ground‑truth answer exists), and, for RAG, retrieval‑specific metadata such as BM25 scores. The classifier achieves >92 % accuracy in distinguishing members from non‑members.
During inference, the judge’s confidence score determines which answer to return: if the discrepancy is low (suggesting the sample is likely a non‑member), the target LLM’s answer is used unchanged; if the discrepancy is high (indicating possible membership), the system either falls back to the base LLM’s answer or returns a weighted blend of both. This dynamic selection reduces the information leakage that an attacker could exploit.
Comprehensive experiments demonstrate that EPD dramatically lowers MIA success. For SFT‑LLMs, average success drops by 27.8 % relative to the baseline, with a maximum reduction of 35 %. For RAG‑LLMs, the reduction is even more pronounced—an average relative decrease of 526.3 % (i.e., the attack success falls to less than 2 % of its original value). Importantly, answer quality remains virtually intact: ROUGE‑L, BLEU, and human evaluation scores decline by only 0.3 %–0.5 % on average. The added computational overhead consists of two additional forward passes (base LLM and judge) and a lightweight classification step, resulting in roughly 1.8× latency increase, which can be mitigated through batching and GPU memory optimization.
The paper discusses several practical considerations. EPD is model‑agnostic and can be wrapped around any API‑based LLM, making it attractive for cloud providers. However, training the judge model requires a modest amount of labeled membership data, which may not always be available. Moreover, the defense assumes that the attacker does not have direct access to the judge’s internal parameters; sophisticated adversaries could attempt to reverse‑engineer or poison the judge through repeated queries, a scenario not fully explored in this work.
In conclusion, the authors provide a thorough vulnerability analysis of knowledge‑intensive LLMs and introduce a novel, ensemble‑based privacy shield that substantially mitigates membership inference threats while preserving utility. Future research directions include (i) developing unsupervised or self‑supervised judge models to eliminate the need for labeled member data, (ii) extending the framework to defend against other privacy attacks such as attribute inference or model extraction, and (iii) exploring adaptive defenses that can dynamically adjust to evolving attack strategies.