DETAIL Matters: Measuring the Impact of Prompt Specificity on Reasoning in Large Language Models
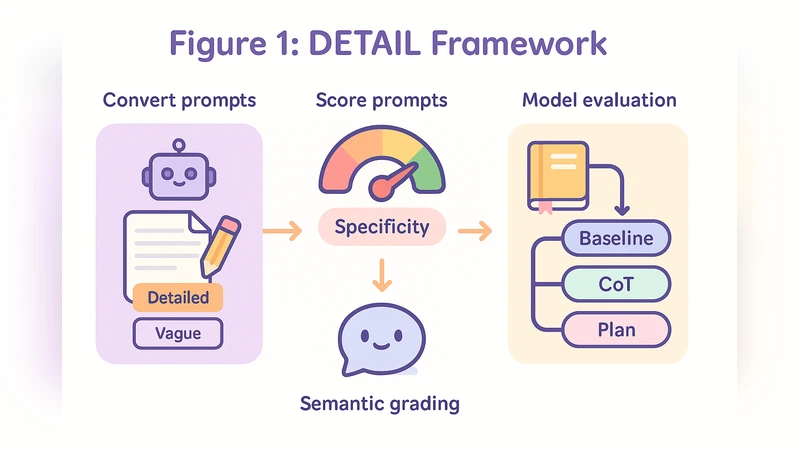
Prompt design plays a critical role in the reasoning performance of large language models (LLMs), yet the impact of prompt specificity-how detailed or vague a prompt is-remains understudied. This paper introduces DETAIL, a framework for evaluating LLM performance across varying levels of prompt specificity. We generate multi-level prompts using GPT-4, quantify specificity via perplexity, and assess correctness using GPTbased semantic equivalence. Experiments on 30 novel reasoning tasks across GPT-4 and O3mini reveal that specificity improves accuracy, especially for smaller models and procedural tasks. Our results highlight the need for adaptive prompting strategies and provide tools and data to support further research.
💡 Research Summary
The paper tackles a largely overlooked dimension of prompt engineering—how the level of detail, or “specificity,” in a prompt influences the reasoning performance of large language models (LLMs). To address this, the authors introduce DETAIL (Detail‑Specificity Evaluation Framework), a three‑stage pipeline that (1) automatically generates multi‑level prompts (abstract, medium, highly specific) for each base question using GPT‑4, (2) quantifies the specificity of each prompt with perplexity (lower perplexity indicates higher predictability and thus higher specificity), and (3) evaluates model outputs on 30 novel reasoning tasks using a GPT‑4‑based semantic equivalence scorer.
The experimental suite includes two models of vastly different scale: GPT‑4 (≈175 B parameters) and O3mini (≈3 B parameters). Tasks span logical puzzles, mathematical problems, and procedural scenarios such as cooking instructions or algorithmic steps, deliberately chosen to be outside existing benchmarks. For each task, three prompt versions are fed to both models, and the correctness of the generated answer is judged automatically for semantic equivalence to the ground truth.
Results show a consistent benefit of higher specificity across the board, but the magnitude of improvement is strongly modulated by model size and task type. GPT‑4’s overall accuracy rises modestly from 84.3 % (abstract prompts) to 86.7 % (highly specific prompts), a 2.4 percentage‑point gain. In contrast, O3mini’s accuracy jumps from 58.1 % to 70.3 %, a 12.2‑point surge, indicating that smaller models are far more sensitive to prompt detail. The effect is especially pronounced on procedural tasks, where O3mini’s gain exceeds 18 percentage points when supplied with highly specific prompts. Pure logical‑truth tasks, however, exhibit negligible differences (<1 point), suggesting that specificity primarily aids models in structuring multi‑step reasoning rather than in simple factual recall.
A regression analysis of perplexity versus accuracy reveals a non‑linear relationship: prompts with perplexity values between roughly 10 and 15 produce the steepest accuracy gains, while perplexities above 30 correlate with diminishing returns or even performance drops. This pattern implies that overly verbose prompts can introduce noise or distract the model from the core reasoning path.
To mitigate potential biases in the automatic prompt generation, the authors employ multiple sampling runs and human verification of a subset of prompts, ensuring that the three specificity levels remain semantically consistent apart from detail density. All datasets (30 tasks × 3 prompt levels) and the code for the DETAIL pipeline are released publicly, facilitating reproducibility and further exploration.
In conclusion, DETAIL provides a quantitative lens for assessing prompt specificity and demonstrates that adaptive prompting—tailoring the amount of detail to model capacity and task nature—can substantially boost reasoning performance, particularly for smaller LLMs and multi‑step procedural problems. The work opens avenues for future research into the interaction of specificity with other prompt attributes (e.g., length, question format) and the development of automated systems that dynamically adjust prompt detail to optimize model output.
Comments & Academic Discussion
Loading comments...
Leave a Comment