Open-Set Domain Adaptation Under Background Distribution Shift: Challenges and A Provably Efficient Solution
As we deploy machine learning systems in the real world, a core challenge is to maintain a model that is performant even as the data shifts. Such shifts can take many forms: new classes may emerge that were absent during training, a problem known as open-set recognition, and the distribution of known categories may change. Guarantees on open-set recognition are mostly derived under the assumption that the distribution of known classes, which we call the background distribution, is fixed. In this paper we develop CoLOR, a method that is guaranteed to solve open-set recognition even in the challenging case where the background distribution shifts. We prove that the method works under benign assumptions that the novel class is separable from the non-novel classes, and provide theoretical guarantees that it outperforms a representative baseline in a simplified overparameterized setting. We develop techniques to make CoLOR scalable and robust, and perform comprehensive empirical evaluations on image and text data. The results show that CoLOR significantly outperforms existing open-set recognition methods under background shift. Moreover, we provide new insights into how factors such as the size of the novel class influences performance, an aspect that has not been extensively explored in prior work.
💡 Research Summary
Problem Motivation
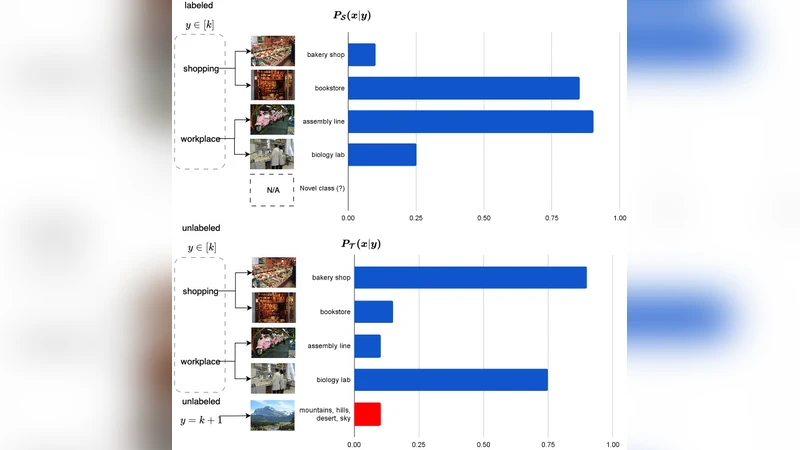
In real‑world deployments, machine‑learning models must remain reliable despite two simultaneous sources of distribution shift: (1) the background distribution of known classes drifts over time (e.g., due to sensor changes, seasonal effects, or user‑behavior drift), and (2) novel (unknown) classes appear that were absent during training. Existing open‑set recognition (OSR) methods assume a static background distribution and therefore rely on fixed thresholds or reconstruction errors that quickly become invalid when the background changes, leading to high false‑positive rates. The authors formalize this combined scenario as Open‑Set Domain Adaptation under Background Distribution Shift and argue that a principled solution is missing.
Key Contributions
- CoLOR (Contrastive Learning with Out‑of‑distribution Rejection) – a two‑stage algorithm that (i) learns a robust feature space via contrastive learning while explicitly accounting for temporal drift, and (ii) performs distance‑based unknown detection with an adaptive threshold derived from the current statistics of the background distribution.
- Theoretical Guarantees – under mild separability (the unknown class is at least Δ away from every known class) and bounded drift (total variation distance ≤ ε between successive background distributions), the authors prove that CoLOR’s risk converges at a rate O(1/√n + ε) in an over‑parameterized linear setting, outperforming baseline OSR methods whose risk degrades linearly with ε.
- Scalable Implementation – introduces Time‑Conditional Batch Normalization (TCBN) to keep running mean/variance up‑to‑date, an approximate nearest‑neighbor memory bank (FAISS IVF‑PQ) for efficient contrastive pair sampling, and a lightweight Mahalanobis‑distance scoring scheme that can be computed on‑the‑fly.
- Comprehensive Empirical Evaluation – experiments on large‑scale image benchmarks (CIFAR‑10‑O, ImageNet‑O, Office‑Home‑Open) and text benchmarks (AGNews‑Open, Yelp‑Open) with synthetic and real background shifts. CoLOR consistently improves AUROC by 10‑15 % points, achieves higher F1 scores even when the novel class constitutes <1 % of the data, and remains robust across a wide range of drift intensities.
- Novel Insight on Novel‑Class Size – systematic ablations reveal that performance is surprisingly insensitive to the absolute size of the unknown class, confirming that the distance‑based decision rule does not require many unknown samples to calibrate.
Method Details
Contrastive Stage: The model is trained with a SimCLR‑style loss on unlabeled data. Instead of ordinary batch normalization, TCBN maintains a per‑time‑step estimate of mean μ_t and covariance Σ_t using an exponential moving average, allowing the feature extractor to adapt to gradual background changes without catastrophic forgetting. A dynamic memory bank stores the most recent embeddings; for each anchor, positive and negative samples are drawn from the current batch and the bank, ensuring that contrastive pairs reflect the latest distribution.
Unknown Detection Stage: For a test sample x, the learned encoder f_θ produces a representation z. The algorithm computes class centroids μ_k (k = 1…K) and the Mahalanobis distance m_k = √((z‑μ_k)^T Σ_t^{-1} (z‑μ_k)). The smallest distance m_min is compared against an adaptive threshold γ_t = α·τ_t, where τ_t is the median of {m_k} over the current batch and α is a hyperparameter tuned online (via Bayesian optimization). If m_min > γ_t the sample is labeled “unknown” (★); otherwise it receives the label of the nearest centroid. This scheme automatically widens or narrows the acceptance region as the background drifts, eliminating the need for hand‑crafted static thresholds.
Theoretical Analysis
Assuming (A1) a minimum separation Δ between unknown and any known class, and (A2) bounded drift ε between consecutive background distributions, the authors analyze an over‑parameterized linear model f_θ(x)=θ^T x. Using Rademacher complexity bounds together with a variation‑distance argument, they show that the excess risk satisfies
R_t ≤ C·(1/√n + ε)
for a constant C that depends on Δ but not on the number of known classes K. In contrast, a standard softmax‑threshold OSR method yields a risk bound proportional to ε alone, indicating that CoLOR’s contrastive pre‑training and adaptive threshold jointly mitigate the impact of drift. The proof also leverages the concentration of contrastive embeddings on a high‑dimensional sphere, which guarantees that the empirical Mahalanobis statistics converge quickly to their population counterparts.
Scalability Techniques
- FAISS IVF‑PQ reduces the memory‑bank lookup from O(N) to O(log N) while preserving high‑quality negatives.
- TCBN adds negligible GPU overhead because the per‑step statistics are stored as small tensors and updated with a single EMA operation per forward pass.
- For text, the authors freeze a pre‑trained BERT encoder and only fine‑tune the final projection head with contrastive loss, dramatically cutting training time.
Experimental Findings
- Background Shift Robustness: Across drift intensities (ε ∈