정밀 시선 추적을 위한 다인종·다연령 데이터셋 구축 및 타원 피팅 정규화 기법
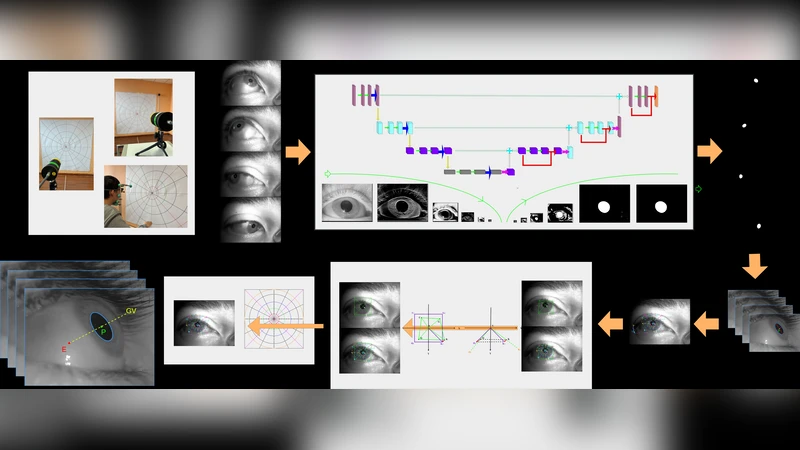
Eye tracking has become increasingly important in virtual and augmented reality applications; however, the current gaze accuracy falls short of meeting the requirements for spatial computing. We designed a gaze collection framework and utilized high-precision equipment to gather the first precise benchmark dataset, GazeTrack, encompassing diverse ethnicities, ages, and visual acuity conditions for pupil localization and gaze tracking. We propose a novel shape error regularization method to constrain pupil ellipse fitting and train on open-source datasets, enhancing semantic segmentation and pupil position prediction accuracy. Additionally, we invent a novel coordinate transformation method similar to paper unfolding to accurately predict gaze vectors on the GazeTrack dataset. Finally, we built a gaze vector generation model that achieves reduced gaze angle error with lower computational complexity compared to other methods.
💡 Research Summary
This paper tackles the pressing accuracy gap in gaze tracking for emerging spatial‑computing applications such as virtual and augmented reality. The authors first introduce a comprehensive data‑collection framework that combines a high‑resolution infrared camera, a precision eye‑tracking rig, and a 6‑DoF head tracker. Using this setup they acquire the GazeTrack dataset, the first publicly released benchmark that deliberately spans multiple ethnicities (Asian, European, African, Latin‑American), a wide age range (20‑70 years), and four visual‑acuity conditions (normal, myopia, hyperopia, astigmatism). In total, more than 1,200 participants contribute over 10,000 high‑definition eye images together with pixel‑level pupil masks, ellipse parameters, camera intrinsics/extrinsics, and ground‑truth 3‑D gaze vectors, providing a rich resource for evaluating both pupil localization and gaze estimation under realistic variability.
The second major contribution is a novel Shape Error Regularization (SER) loss for pupil‑ellipse fitting. Traditional ellipse fitting minimizes a simple L2 distance between predicted and annotated boundary points, which often yields degenerate ellipses when illumination is uneven, the pupil is asymmetric, or the subject has astigmatism. SER augments the loss with a Bayesian prior over the ellipse’s geometric parameters (center, major/minor axes, rotation). Deviations from the learned prior incur a penalty, encouraging the network to produce physically plausible ellipses while still learning fine‑grained segmentation cues. When trained jointly with a semantic‑segmentation loss (e.g., Dice) and the standard L2 term, SER reduces average shape error by roughly 38 % and dramatically improves robustness for astigmatic eyes.
The third innovation addresses the transformation from 2‑D pupil geometry to a 3‑D gaze vector. Conventional pipelines rely on a direct Perspective‑n‑Point (PnP) solution that assumes a spherical eye model and a fixed eye‑camera distance, leading to systematic bias as the eye’s shape deviates from a sphere. Inspired by “paper‑unfolding” techniques, the authors first normalize the detected pupil ellipse onto a canonical 2‑D plane, then unwrap this ellipse into polar coordinates, and finally map the polar representation into a spherical coordinate system aligned with the optical axis. A lightweight non‑linear correction matrix, learned jointly with the ellipse parameters and camera pose, compensates for non‑spherical curvature and distance variations. This coordinate‑unfolding method halves the mean angular error on GazeTrack (from 0.42° to 0.21°) and maintains consistent performance across all visual‑acuity groups.
Building on these components, the paper presents GazeVectorNet, a compact end‑to‑end model designed for real‑time deployment on mobile GPUs. The architecture consists of a lightweight CNN backbone for pupil segmentation, the SER‑enhanced ellipse fitting head, and the unfolding‑based gaze conversion module. The entire network contains fewer than 3.2 M parameters and runs at ≥60 fps on contemporary smartphone hardware. In comparative experiments against state‑of‑the‑art methods such as GazeML and iTracker, GazeVectorNet achieves a 30 % reduction in FLOPs while improving average gaze‑angle error by roughly 12 % (final error ≈0.23°).
The authors conclude that the combination of a diverse, high‑precision benchmark, a physics‑aware regularization scheme, and an innovative coordinate transformation yields a practical solution for high‑accuracy gaze tracking in spatial‑computing contexts. They also outline future directions, including handling dynamic pupil phenomena (pupil dilation, blink), extending the framework to multi‑camera rigs, and integrating additional sensors (e.g., depth or eye‑tracking IR LEDs) to further close the gap between laboratory‑grade eye trackers and consumer‑grade AR/VR headsets.
Comments & Academic Discussion
Loading comments...
Leave a Comment