Post-training quantization (PTQ) aims to preserve model-level behavior; however, most methods focus on individual linear layers. Even recent extensions, such as QEP and LoaQ, which mitigate error propagation or target specific submodules, still rely on layer-wise formulations and fail to capture the behavior of larger submodules. We introduce Layer-Projected Coordinate Descent (LPCD), a unified framework that extends PTQ beyond layers by optimizing relaxed objectives across arbitrary submodules and projecting the solutions with layer-wise quantizers. LPCD generalizes existing methods and provides a principled approach to quantizing complex submodules while maintaining the efficiency and compatibility of layer-wise PTQ pipelines. Across diverse LLM architectures and bit-widths, LPCD-based submodule quantization consistently enhances both layer-wise PTQ methods and existing submodule approaches.
Deep Dive into LPCD: Unified Framework from Layer-Wise to Submodule Quantization.
Post-training quantization (PTQ) aims to preserve model-level behavior; however, most methods focus on individual linear layers. Even recent extensions, such as QEP and LoaQ, which mitigate error propagation or target specific submodules, still rely on layer-wise formulations and fail to capture the behavior of larger submodules. We introduce Layer-Projected Coordinate Descent (LPCD), a unified framework that extends PTQ beyond layers by optimizing relaxed objectives across arbitrary submodules and projecting the solutions with layer-wise quantizers. LPCD generalizes existing methods and provides a principled approach to quantizing complex submodules while maintaining the efficiency and compatibility of layer-wise PTQ pipelines. Across diverse LLM architectures and bit-widths, LPCD-based submodule quantization consistently enhances both layer-wise PTQ methods and existing submodule approaches.
LPCD: Unified Framework from Layer-Wise to Submodule Quantization
Yuma Ichikawa
Fujitsu Limited
RIKEN Center for AIP
Yudai Fujimoto
Fujitsu Limited
Institute of Science Tokyo
Akira Sakai
Fujitsu Limited
Tokai University
Abstract
Post-training quantization (PTQ) aims to pre-
serve model-level behavior; however, most
methods focus on individual linear layers. Even
recent extensions, such as QEP and LoaQ,
which mitigate error propagation or target spe-
cific submodules, still rely on layer-wise formu-
lations and fail to capture the behavior of larger
submodules. We introduce Layer-Projected
Coordinate Descent (LPCD), a unified frame-
work that extends PTQ beyond layers by opti-
mizing relaxed objectives across arbitrary sub-
modules and projecting the solutions with stan-
dard layer-wise quantizers.
LPCD general-
izes existing methods and provides a principled
approach to quantizing complex submodules
while maintaining the efficiency and compati-
bility of layer-wise PTQ pipelines. Across di-
verse LLM architectures and bit-widths, LPCD-
based submodule quantization consistently en-
hances both layer-wise PTQ methods and exist-
ing submodule approaches.
1
Introduction
Large-scale models achieve strong performance;
however, they incur substantial memory and com-
putational overhead, hindering practical deploy-
ment (Chen et al., 2023). These constraints are
particularly stringent for edge devices. To bridge
the gap between accuracy and deployability, prior
work has explored compression techniques such
as quantization (Lang et al., 2024; Gong et al.,
2024), pruning (Wang et al., 2024; Cheng et al.,
2024), low-rank adaptation (Yang et al., 2024; Hu
et al., 2022), and knowledge distillation (Xu et al.,
2024a). Among these techniques, layer-wise post-
training quantization (PTQ) is one of the most
practical and widely adopted methods for large-
scale LLMs (Frantar et al., 2022; Lin et al., 2024;
Yao et al., 2022; Chee et al., 2023). By focus-
ing on individual linear layers, layer-wise PTQ
simplifies the problem to least-squares estimation
of linear transformations, which enables for effi-
cient solvers and straightforward implementations.
Despite its simplicity, layer-wise PTQ delivers
strong empirical performance and is used both as
a standalone method and as an initialization for
more complex block-wise or global PTQ frame-
works (Malinovskii et al., 2024; Guan et al., 2024).
However, the layer-wise structure imposes sig-
nificant limitations.
Classical layer-wise PTQ
methods, such as GPTQ (Frantar et al., 2022),
AWQ (Lin et al., 2024), and QuIP (Chee et al.,
2023), optimize each linear layer independently
by utilizing input activations. Consequently, these
methods are confined to activation-aware weight
approximation and indirectly affect model-level
outputs; quantization error may become significant.
Recent work, including QEP (Arai and Ichikawa,
2025) and GPTAQ (Li et al., 2025), relaxes this
constraint by modifying the layer-wise objective
to address the mismatch between pre- and post-
quantization activations. This modification enables
controlled error propagation across layers, preserv-
ing the sequential pipeline and reducing the accu-
mulation of quantization errors. LoaQ (Lin and
Wan, 2025) further extends the target from linear
layers to specific submodules by explicitly approx-
imating the outputs of residual connections and
RMSNorm. This approach aligns layer-wise PTQ
more closely with the behavior at the model-level.
Nevertheless, these advances remain specialized:
QEP is still anchored in individual linear layers,
and LoaQ is limited to specific submodules; they
do not provide a unified treatment of more general
submodules, activation, or KV-cache quantization.
This study goes beyond traditional layer-wise
formulations by introducing a framework for sub-
module quantization that preserves the standard
layer-wise pipeline. We propose Layer-Projected
Coordinate Descent (LPCD), which optimizes ar-
bitrary submodules in the output space and projects
the relaxed solutions back into the quantization do-
1
arXiv:2512.01546v1 [stat.ML] 1 Dec 2025
0
10
20
30
Layer index
0.00
1.00
2.00
Layer Output MSE
1e-4
QEP
LoaQ
Ours
(a) 4-bit weight
0
10
20
30
Layer index
0.00
2.00
4.00
6.00
Layer Output MSE
1e-4
(b) 3-bit weight
0
10
20
30
Layer index
0.00
0.50
1.00
1.50
Layer Output MSE
1e-2
(c) 2-bit weight
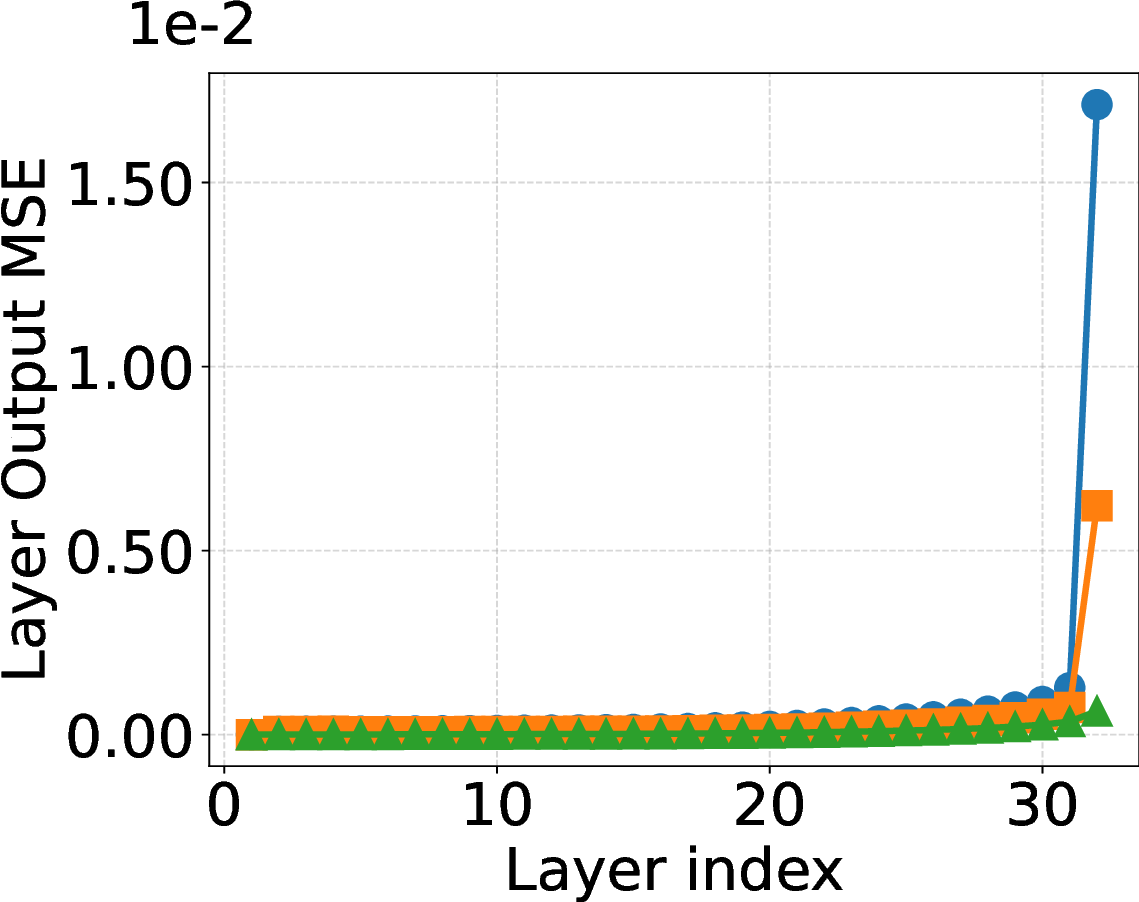
Figure 1: Output MSE across Transformer blocks in Llama 3 8B with 4, 3, and 2 bit weight quantization. LPCD
consistently yields lower quantization error than QEP and LoaQ.
main using existing layer-wise PTQ algorithms as
layer projectors. This perspective unifies classical
layer-wise PTQ, QEP, and LoaQ as special cases
while extending naturally to more general submod-
ules, activations, and KV caches. We instantiate
LPCD on grouped-query KV, VO aggregation, and
MLP up-down blocks, demonstrating that LPCD
significantly reduces quantization error compared
to QEP and LoaQ, as shown in Figure 1. Extensive
experimen
…(Full text truncated)…
This content is AI-processed based on ArXiv data.