Foundation models often generate unreliable answers, while heuristic uncertainty estimators fail to fully distinguish correct from incorrect outputs, causing users to accept erroneous answers without statistical guarantees. We address this through the lens of false discovery rate (FDR) control, ensuring that among all accepted predictions, the proportion of errors does not exceed a target risk level. To this end, we propose LEC, a principled framework that reframes selective prediction as a decision problem governed by a linear expectation constraint over selection and error indicators. Under this formulation, we derive a finite-sample sufficient condition that relies only on a held-out set of exchangeable calibration data, enabling the computation of an FDR-constrained, retention-maximizing threshold. Furthermore, we extend LEC to two-model routing systems: if the primary model's uncertainty exceeds its calibrated threshold, the input is delegated to a subsequent model, while maintaining system-level FDR control. Experiments on both closed-ended and open-ended question answering (QA) and vision question answering (VQA) demonstrate that LEC achieves tighter FDR control and substantially improves sample retention compared to prior approaches.
Deep Dive into A Linear Expectation Constraint for Selective Prediction and Routing with False-Discovery Control.
Foundation models often generate unreliable answers, while heuristic uncertainty estimators fail to fully distinguish correct from incorrect outputs, causing users to accept erroneous answers without statistical guarantees. We address this through the lens of false discovery rate (FDR) control, ensuring that among all accepted predictions, the proportion of errors does not exceed a target risk level. To this end, we propose LEC, a principled framework that reframes selective prediction as a decision problem governed by a linear expectation constraint over selection and error indicators. Under this formulation, we derive a finite-sample sufficient condition that relies only on a held-out set of exchangeable calibration data, enabling the computation of an FDR-constrained, retention-maximizing threshold. Furthermore, we extend LEC to two-model routing systems: if the primary model’s uncertainty exceeds its calibrated threshold, the input is delegated to a subsequent model, while maintain
Foundation models, like large language models (LLMs) and large vision-language models (LVLMs), are increasingly being integrated into real-world decision-making pipelines (Xiaolan et al., 2025;Brady et al., 2025;Singhal et al., 2025), where it is crucial to evaluate the reliability of their outputs and determine whether to trust them. Uncertainty quantifi- cation (UQ) is a promising approach to estimate the uncertainty of model predictions, with the uncertainty score serving as an indicator of whether the model's output is likely to be incorrect (Zhang et al., 2024;Wang et al., 2025d;Duan et al., 2024;2025). In practice, when the model shows high uncertainty, its predictions should be clarified or abstained from to prevent the propagation of incorrect information.
However, when the model generates hallucinations or exhibits overconfidence in its erroneous predictions (Shorinwa et al., 2025;Atf et al., 2025), uncertainty scores derived from model logits or consistency measures may remain low, leading users to accept incorrect answers without task-specific risk guarantees (Angelopoulos et al., 2024). Split conformal prediction (SCP) can convert any heuristic uncertainty to a rigorous one (Angelopoulos & Bates, 2021;Campos et al., 2024a). Assuming data exchangeability, SCP produces prediction sets that include ground-truth answers with at least a user-defined probability. Nonetheless, set-valued predictions often contain unreliable candidates, leading to biased decision-making in downstream tasks (Wang et al., 2025a;Cresswell et al., 2025). In this paper, we investigate point prediction with certain provable finite-sample guarantees.
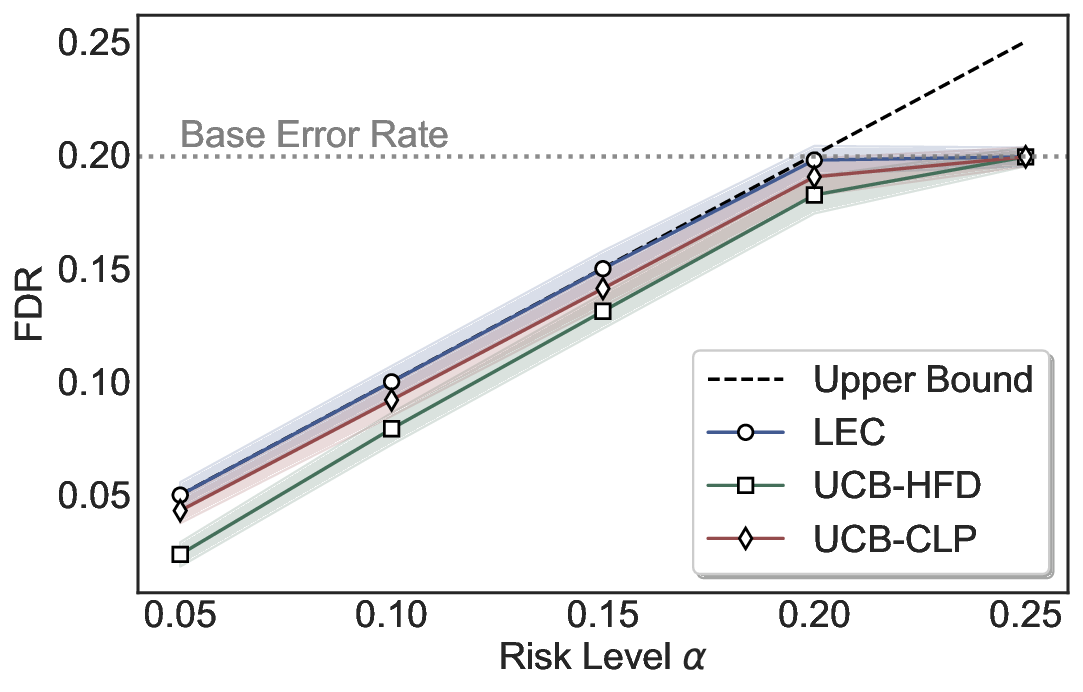
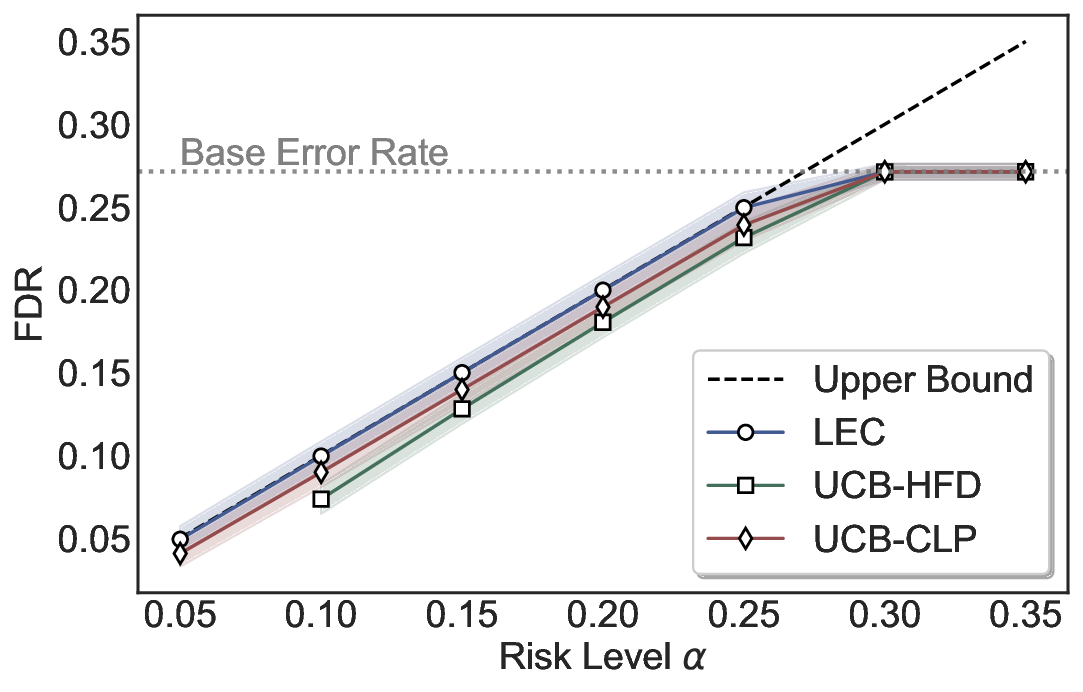
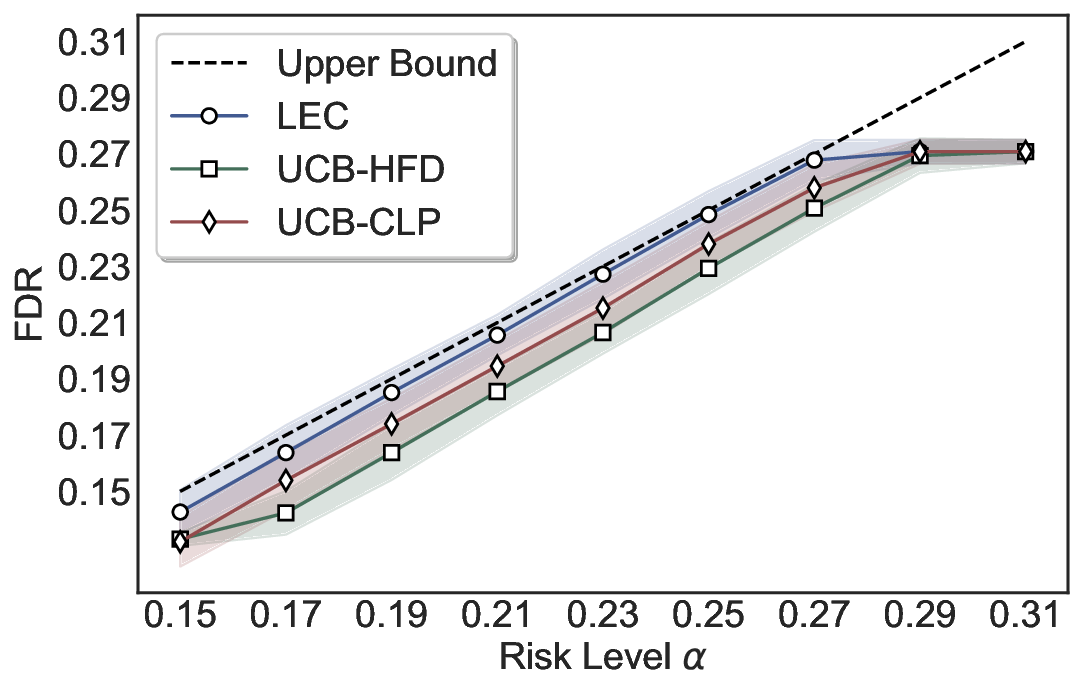
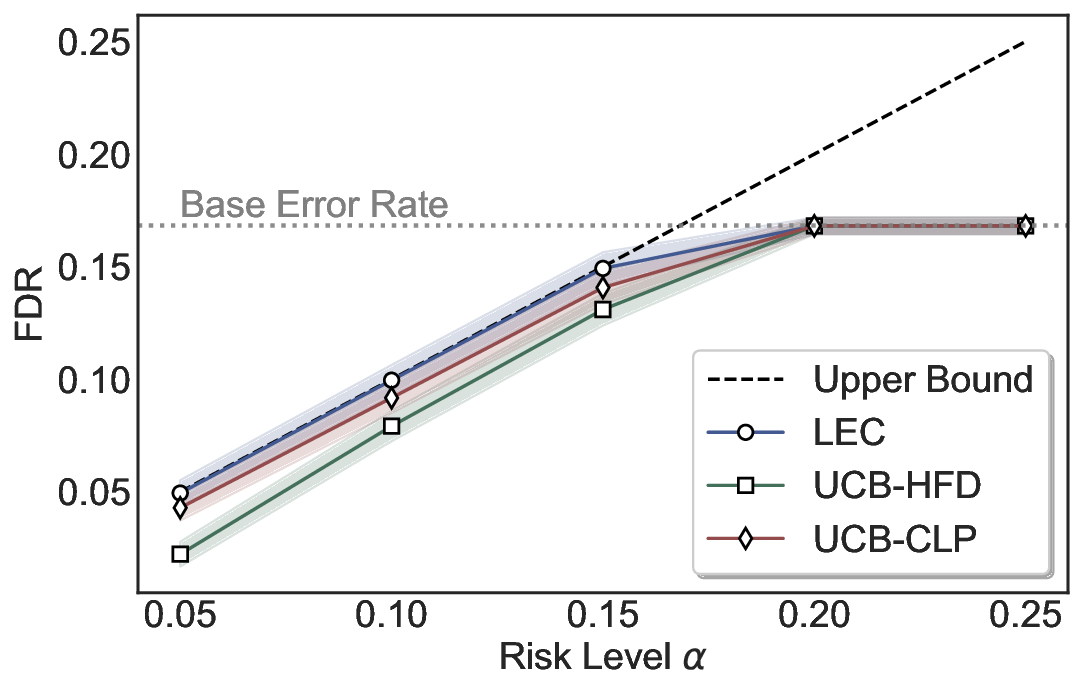
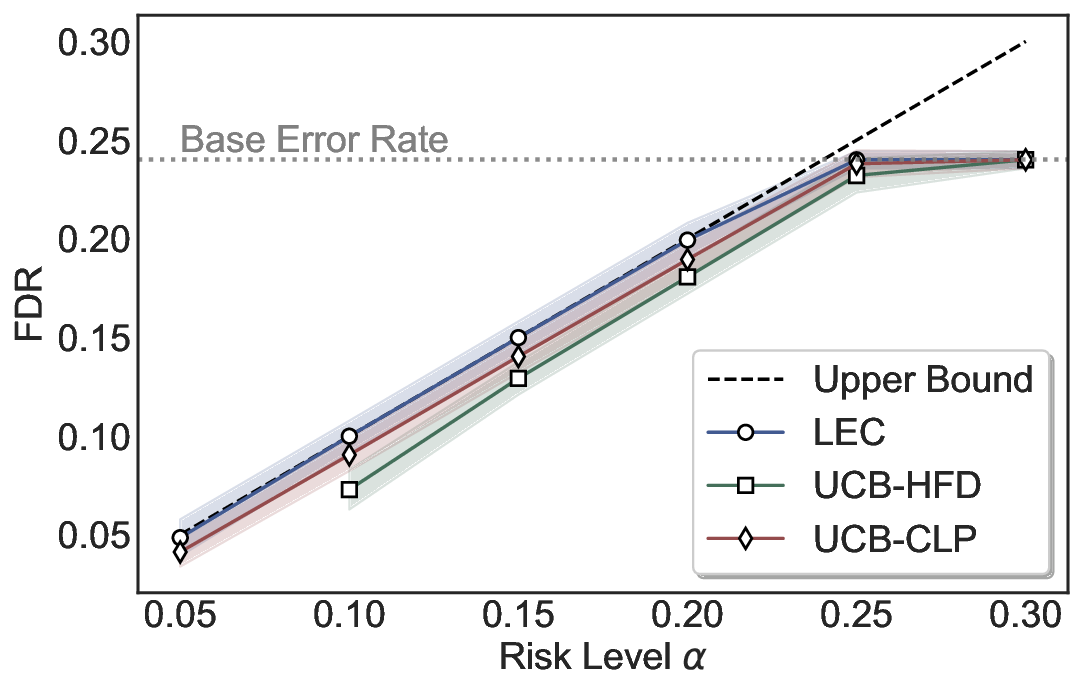
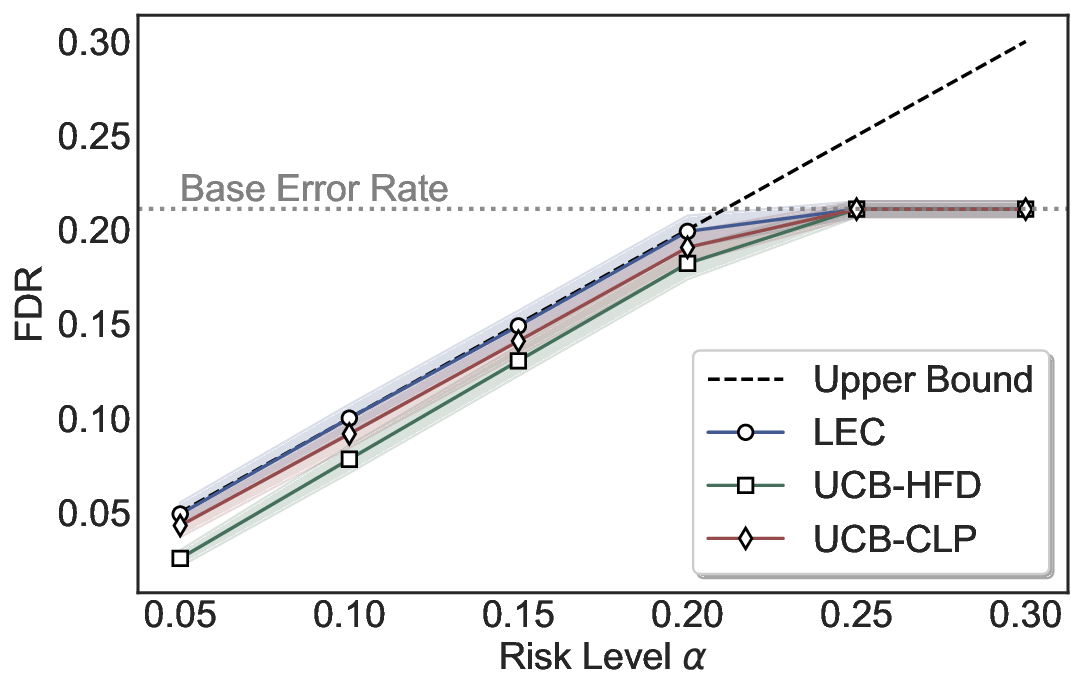
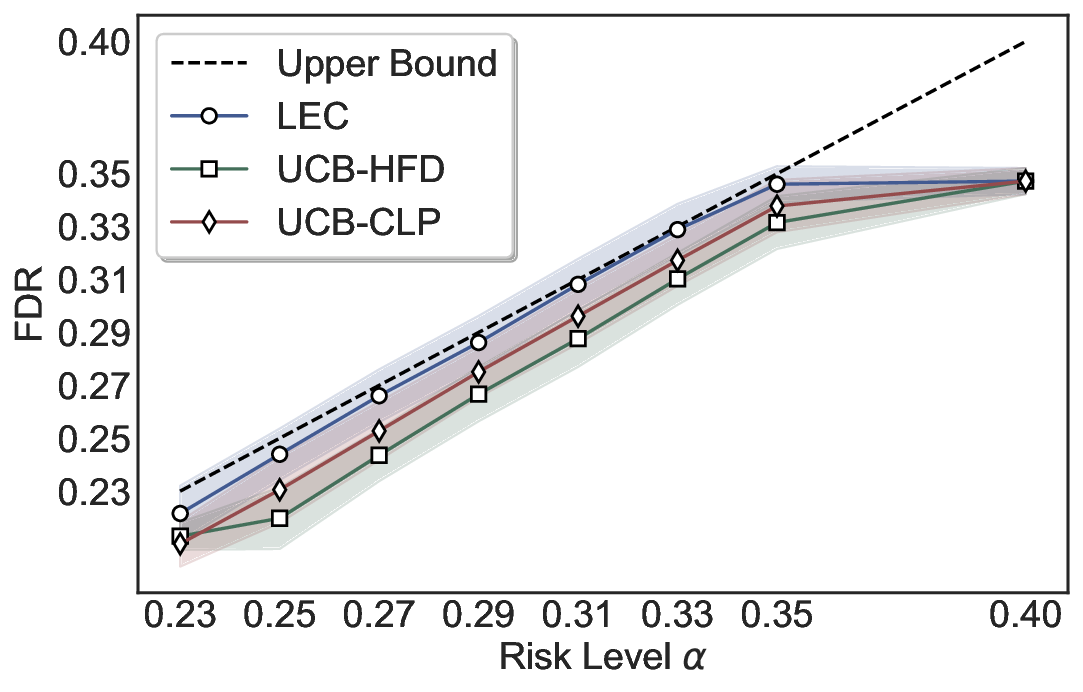
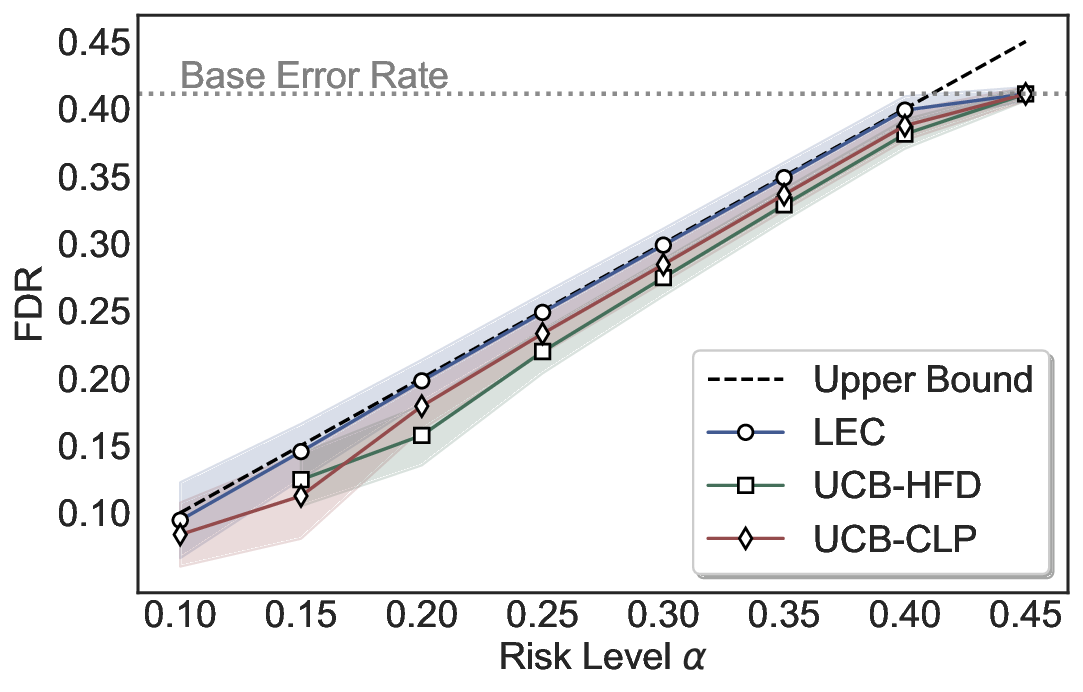
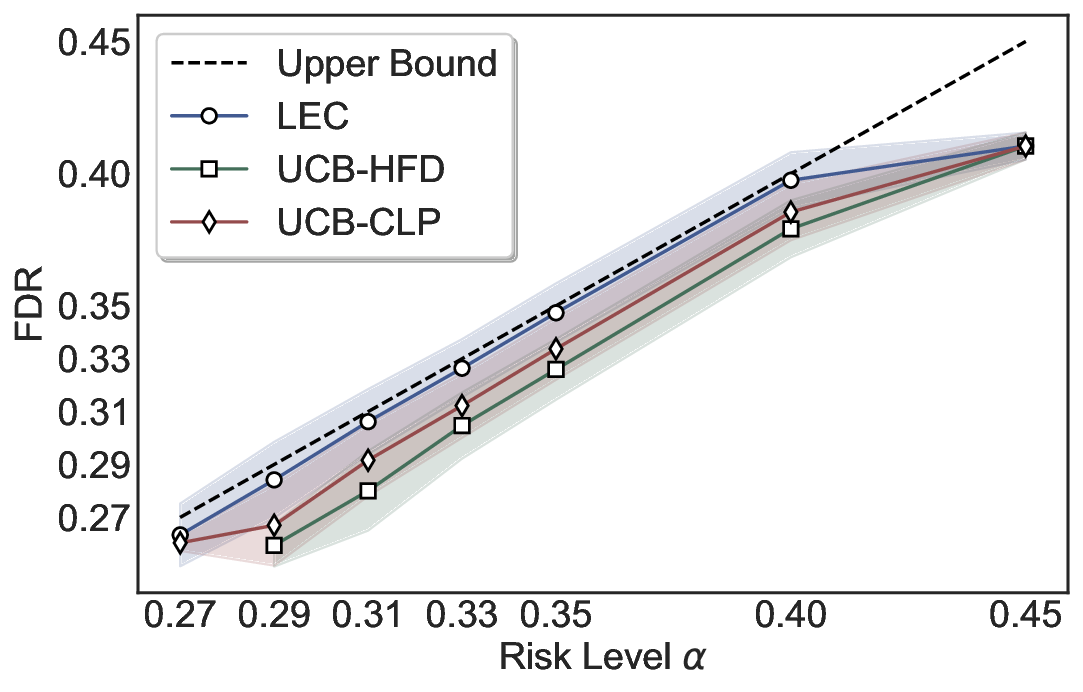
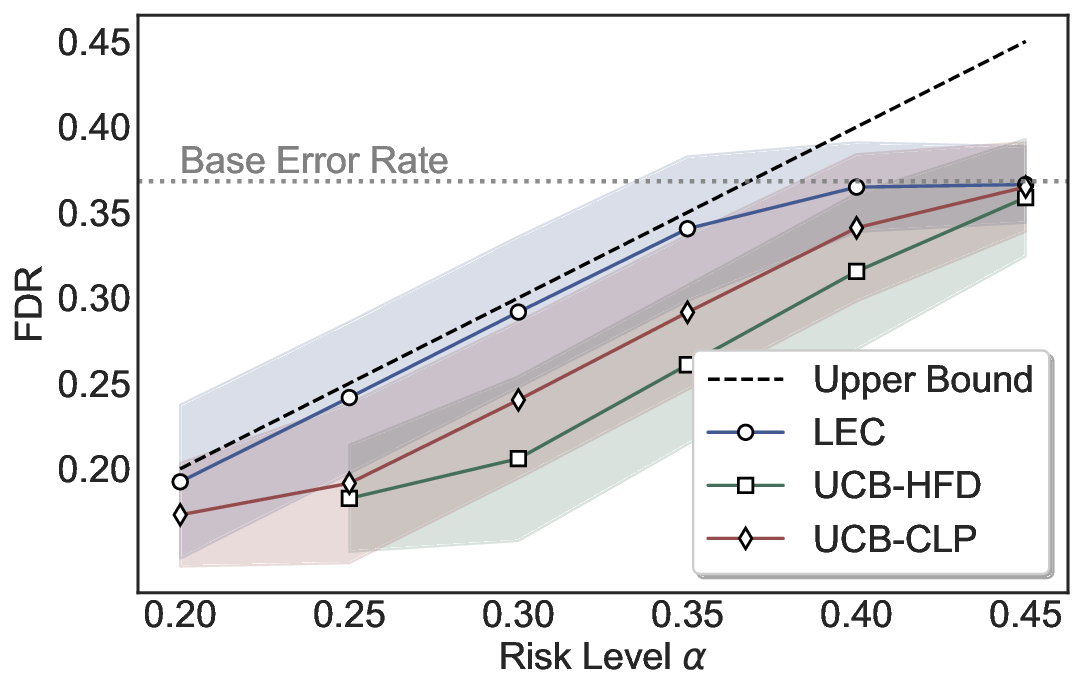
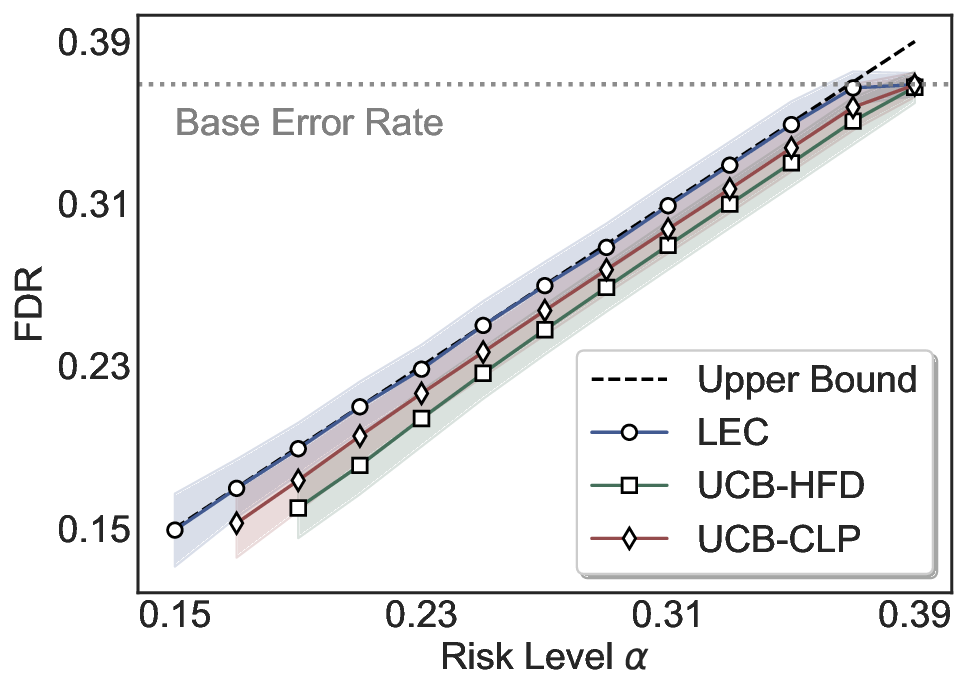
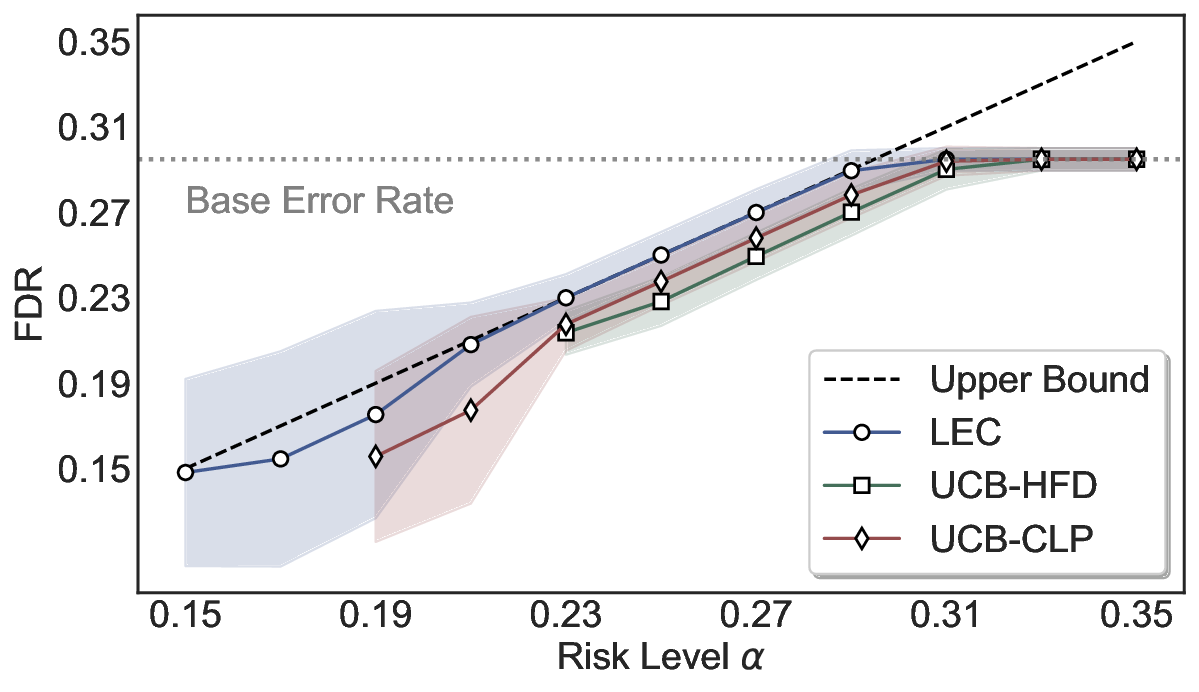
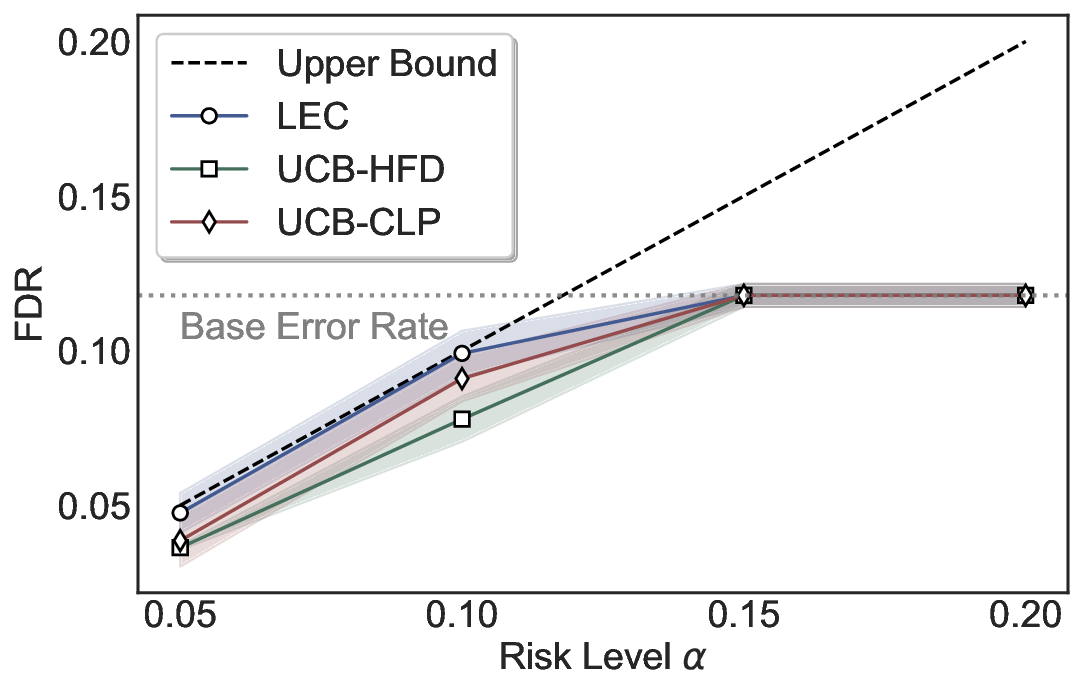
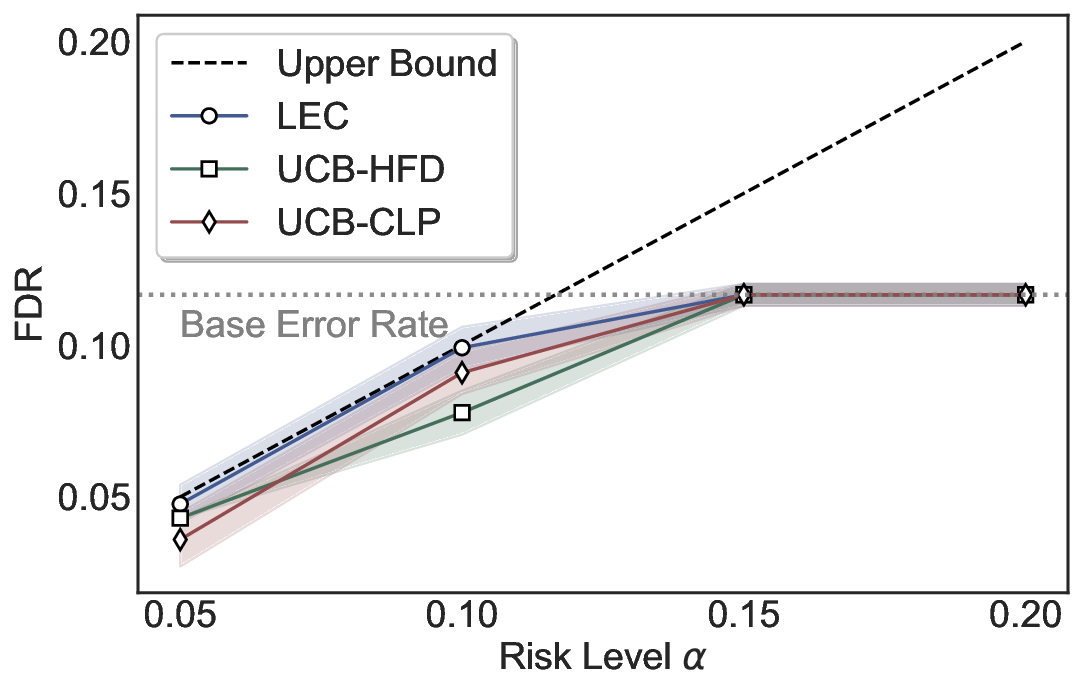
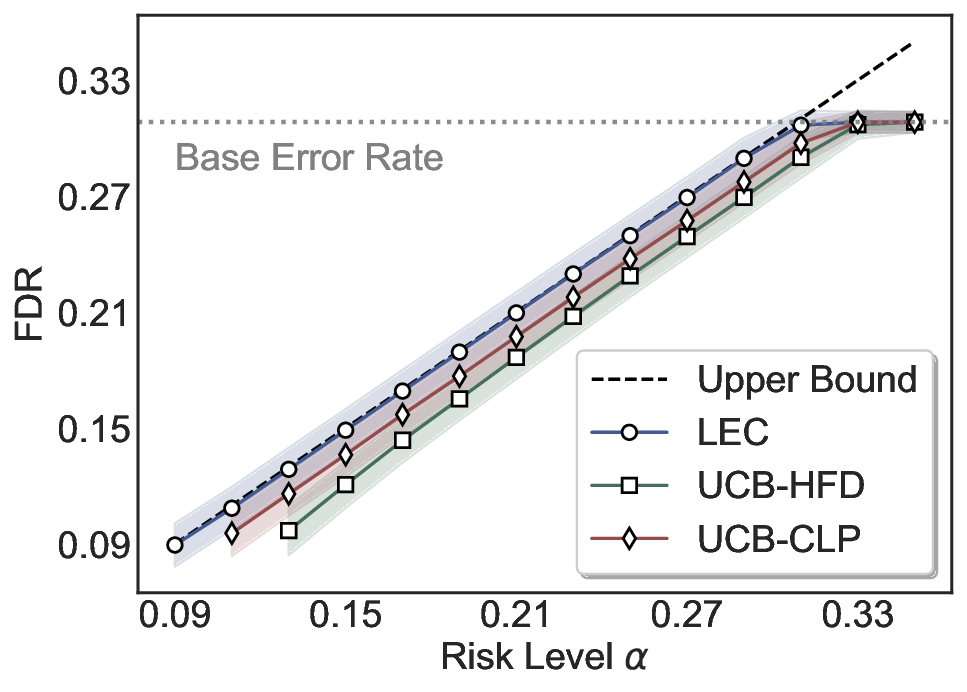
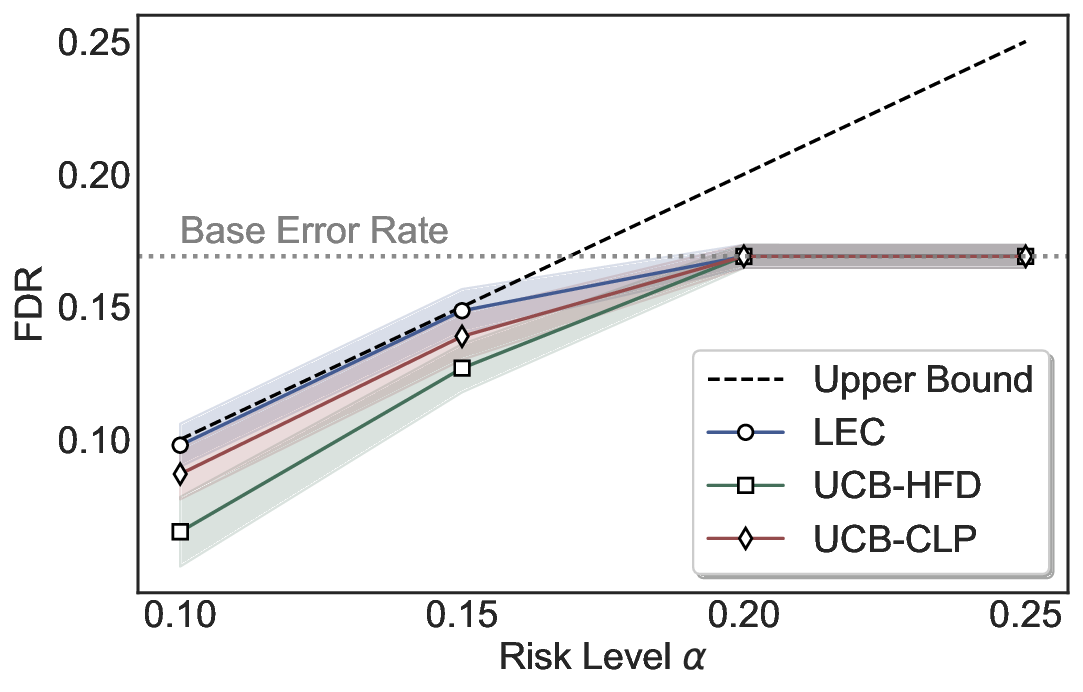
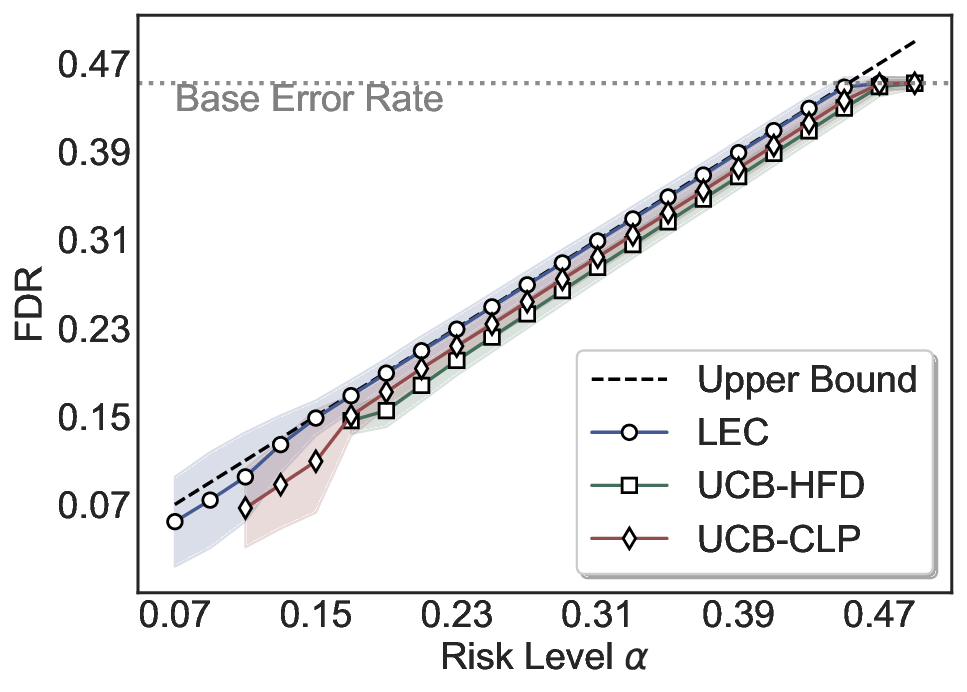
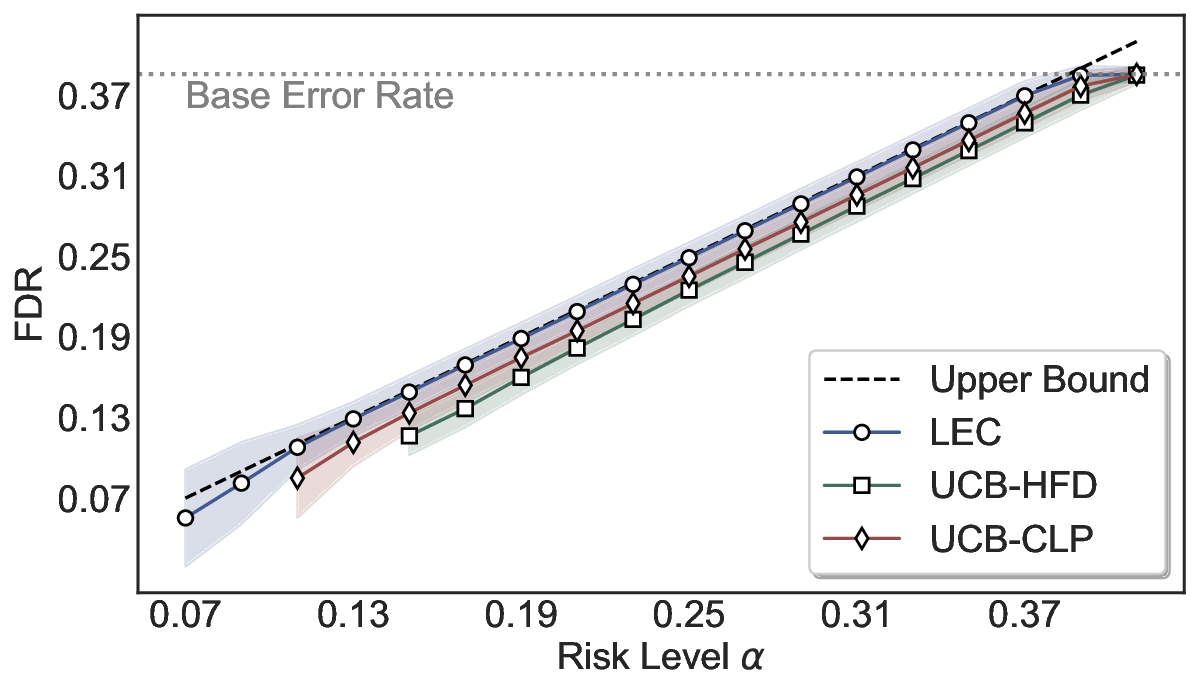
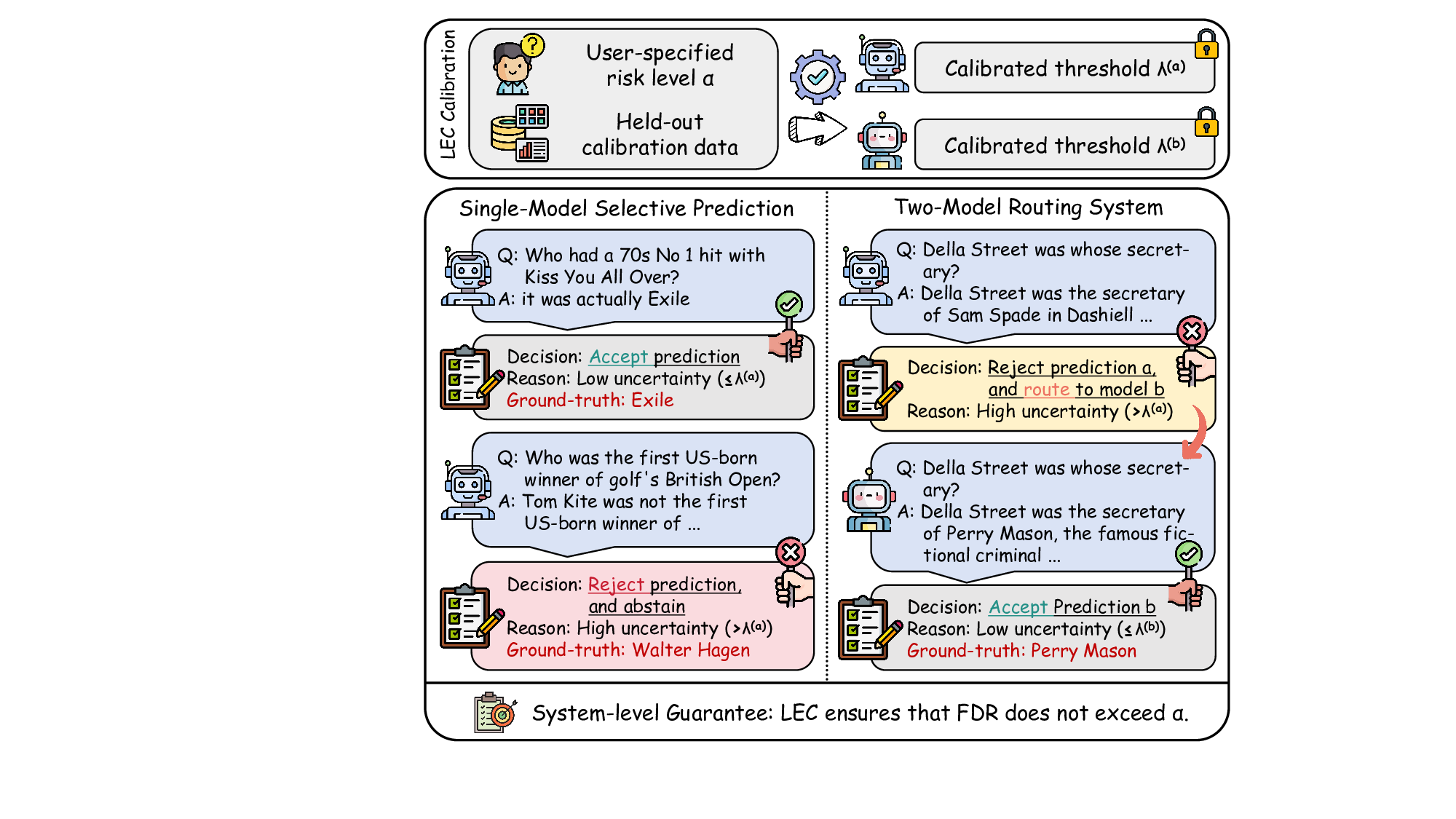
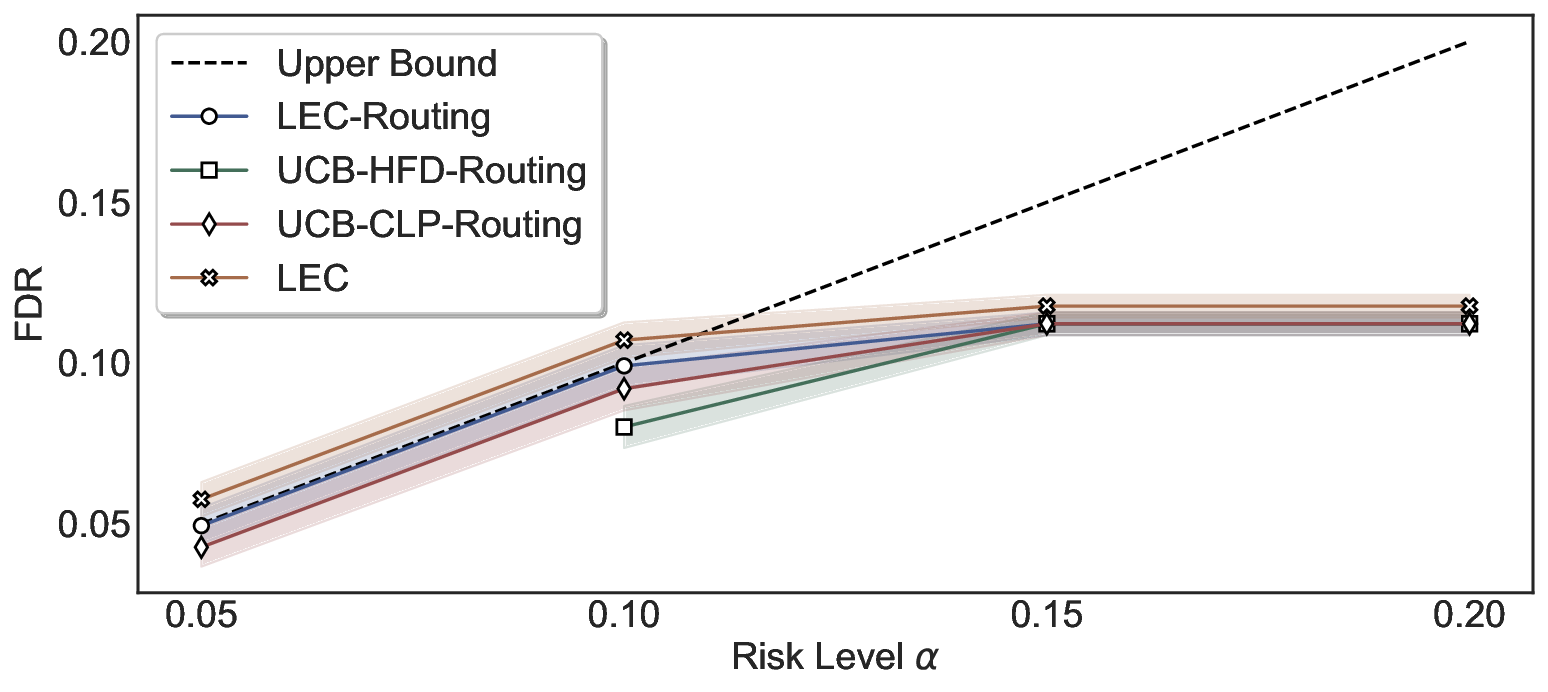
Although uncertainty scores cannot perfectly separate correct from incorrect predictions, selective prediction allows us to enforce a risk level (e.g., α): a prediction is accepted if and only if its associated uncertainty score falls below a calibrated threshold, ensuring the false discovery rate (FDR) among accepted predictions does not exceed α. To achieve this principally, we introduce LEC, which reframes selective prediction not as an uncertainty-ranking problem, but as a decision problem governed by a statistical constraint. The central idea is to express FDR control as a constraint on the expectation of a linear functional involving two binary indicators: one capturing whether a prediction is selected and the other indicating whether it is incorrect. This formulation enables us to establish a finite-sample sufficient condition utilizing calibration uncertainty scores and error labels that, if satisfied, guarantees FDR control for unseen test samples. Since this condition depends only on the empirical quantities from the calibration set, it yields a calibrated threshold that maximizes coverage subject to the FDR constraint.
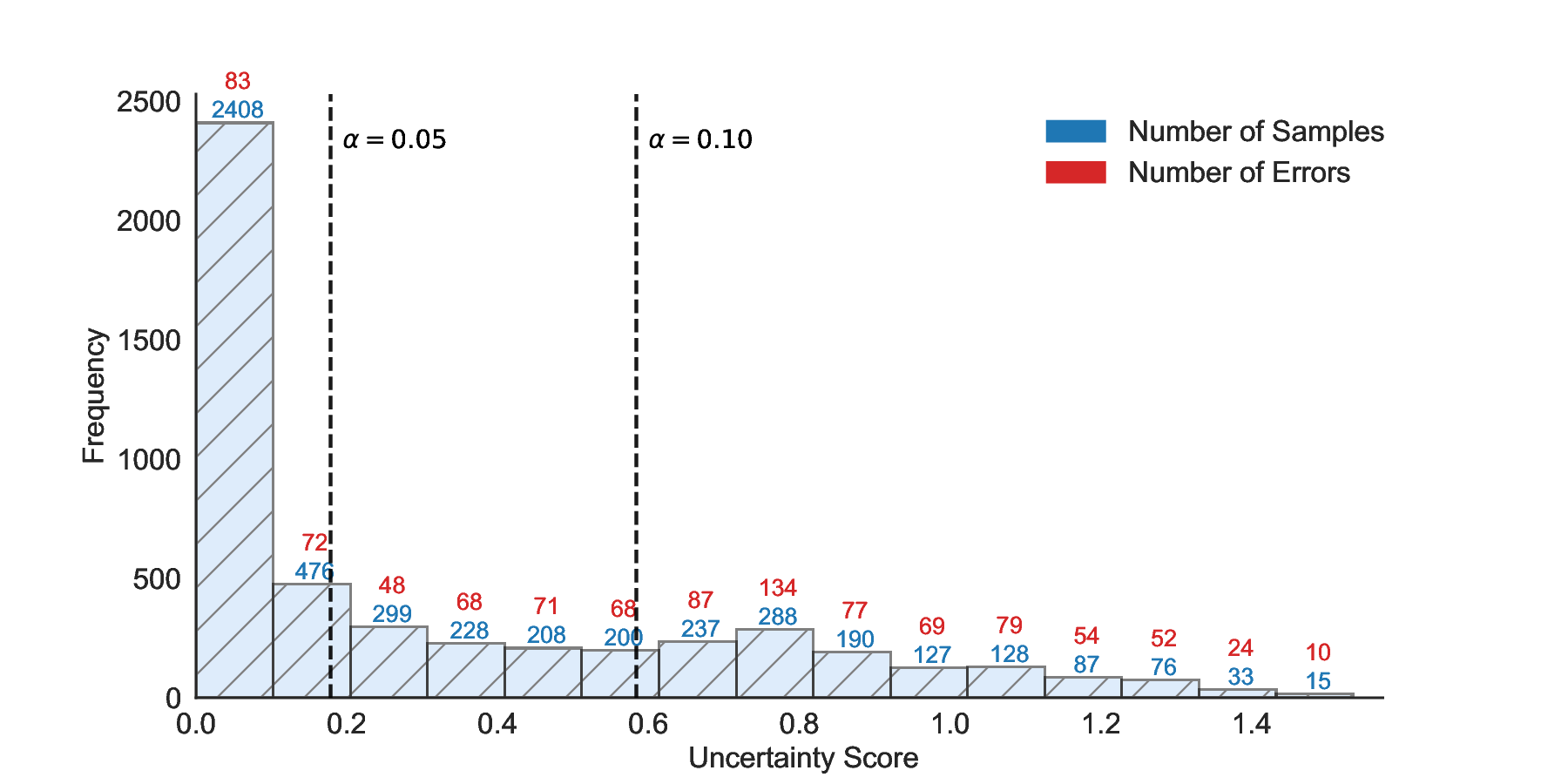
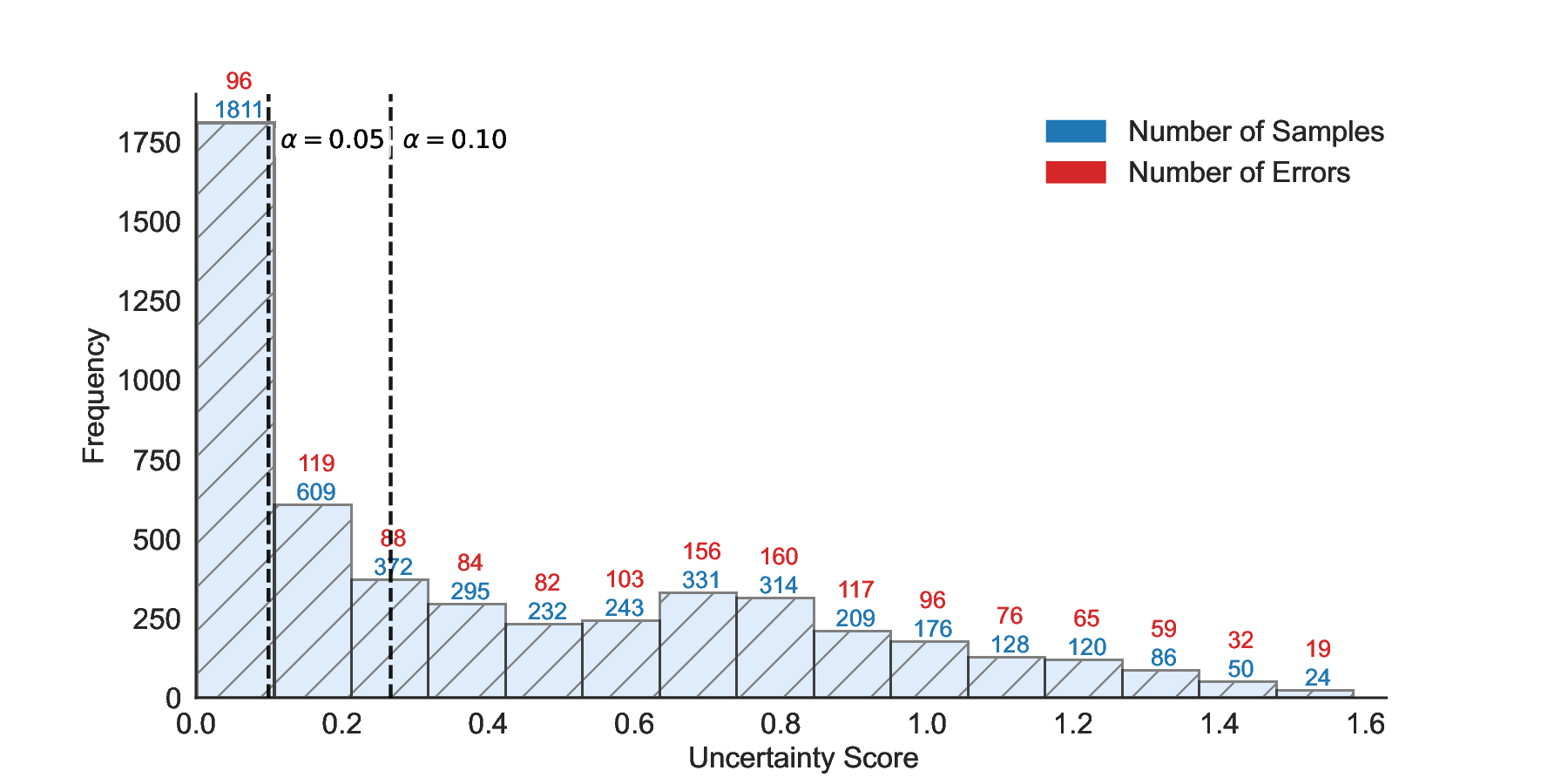
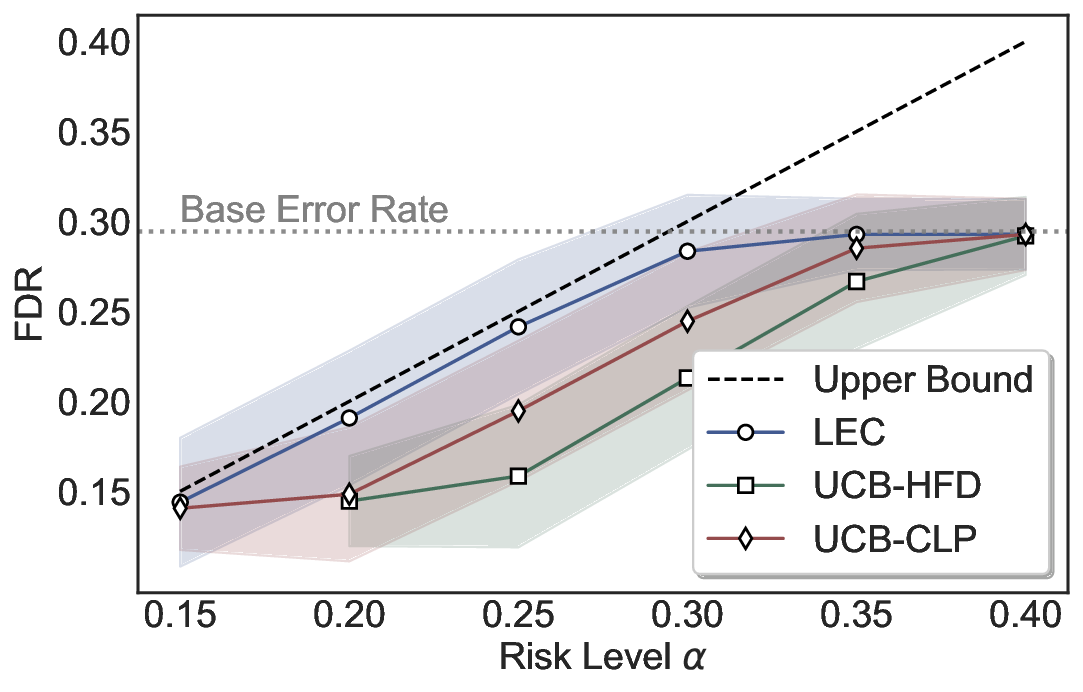
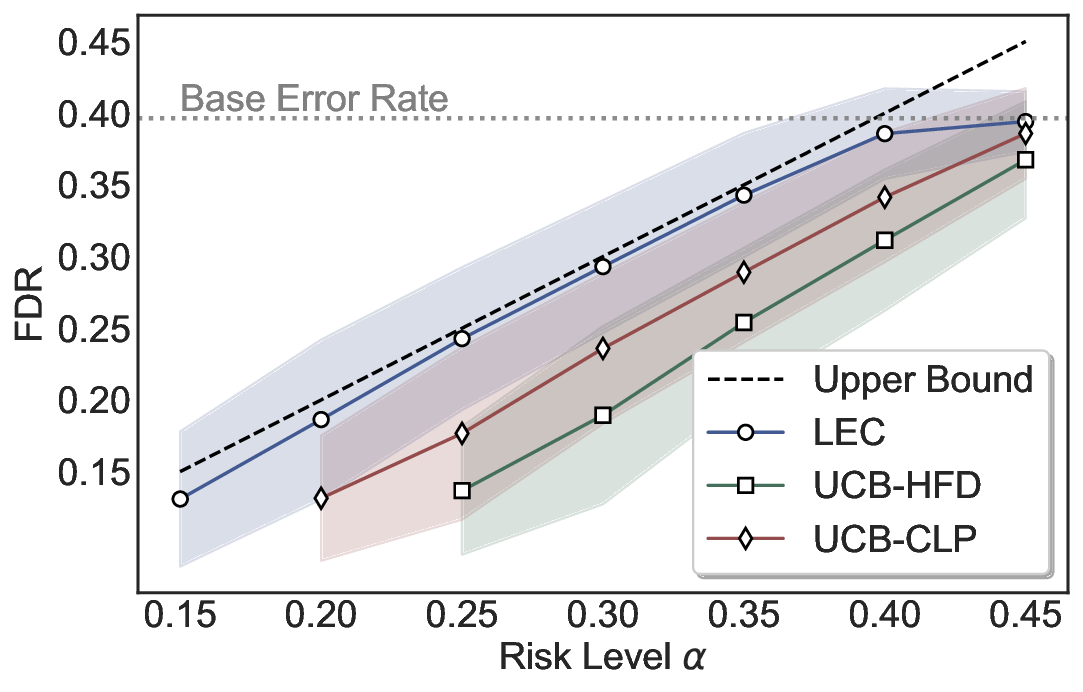
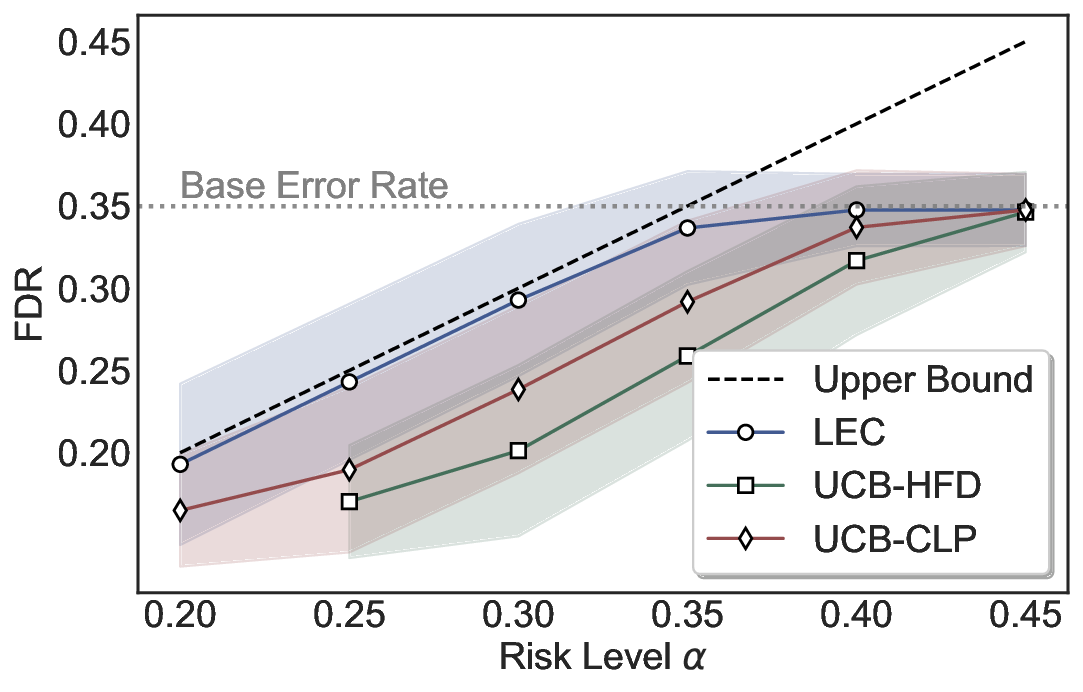
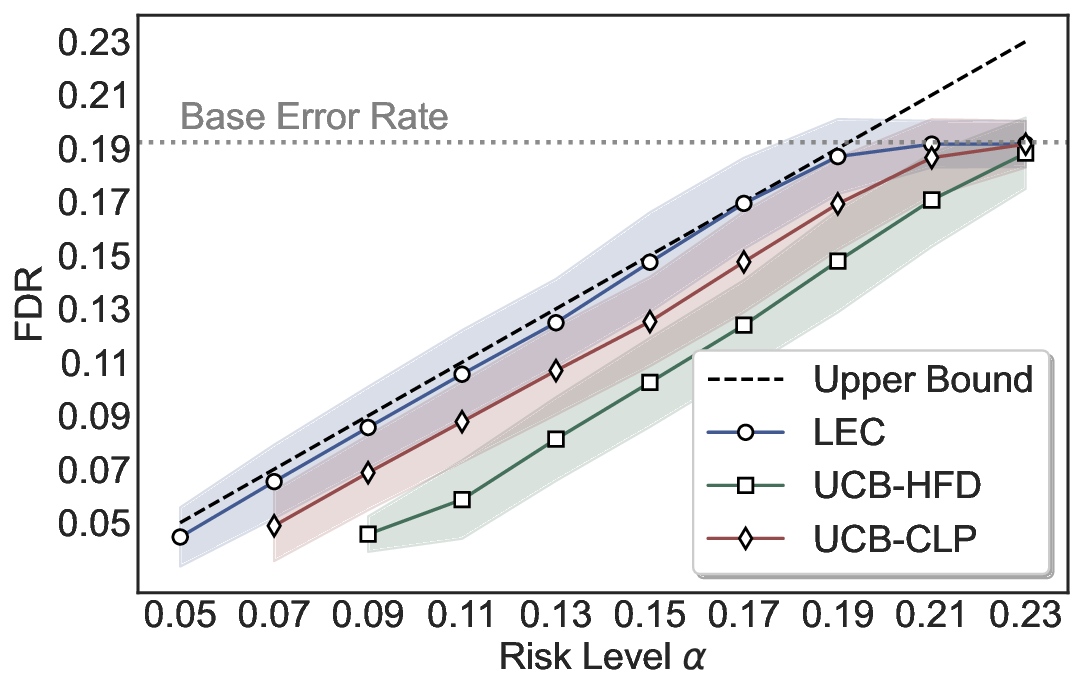
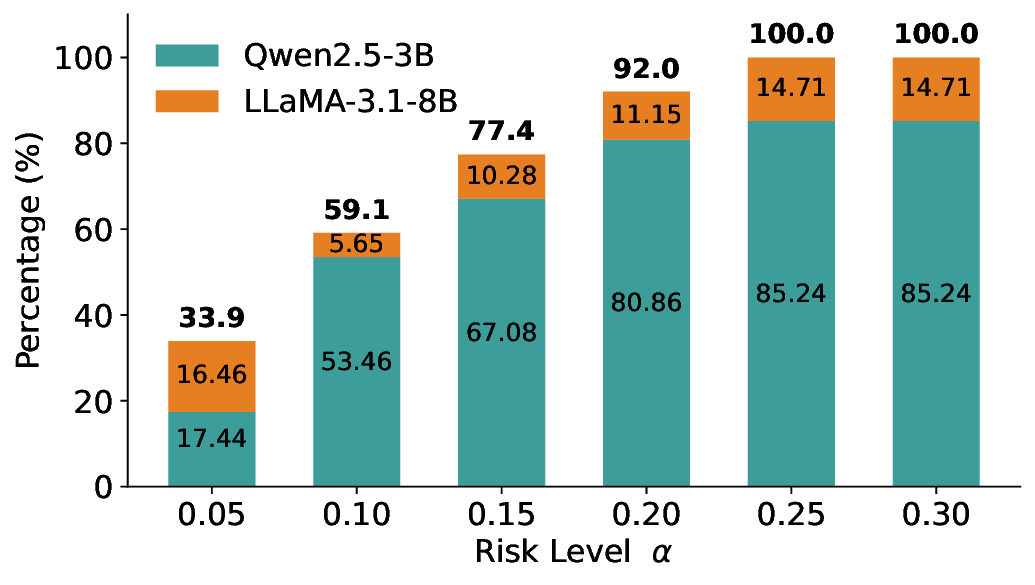
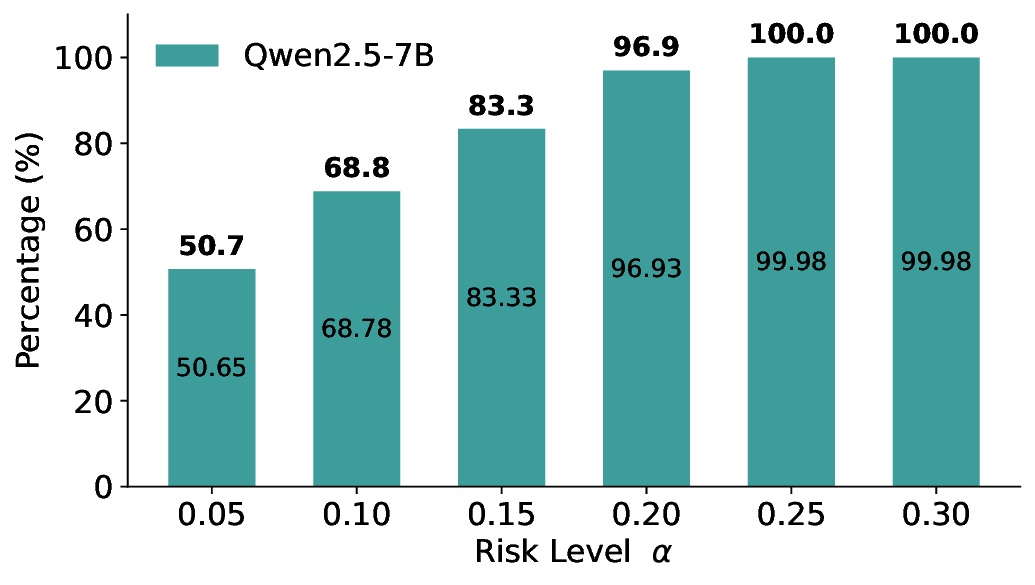
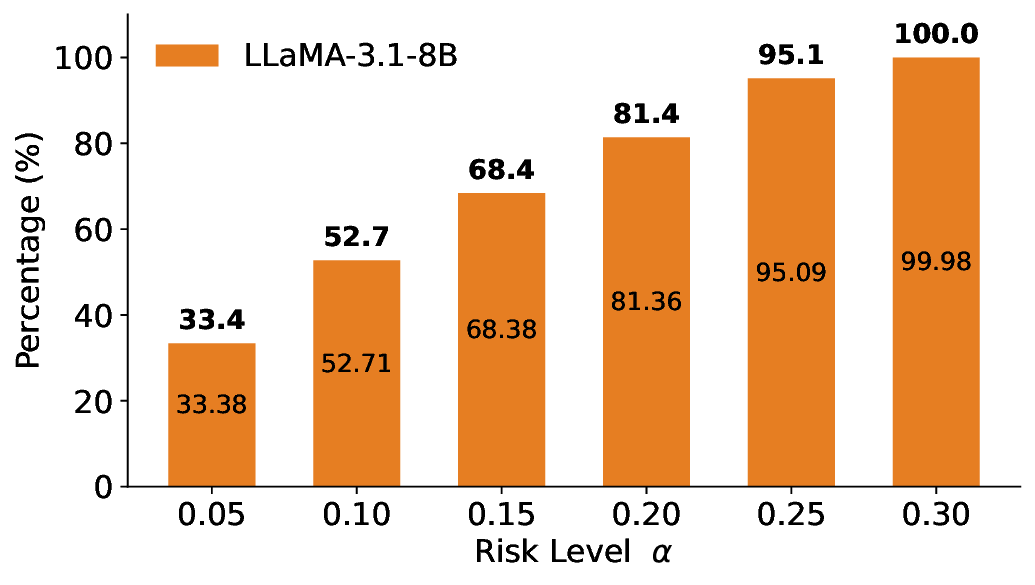
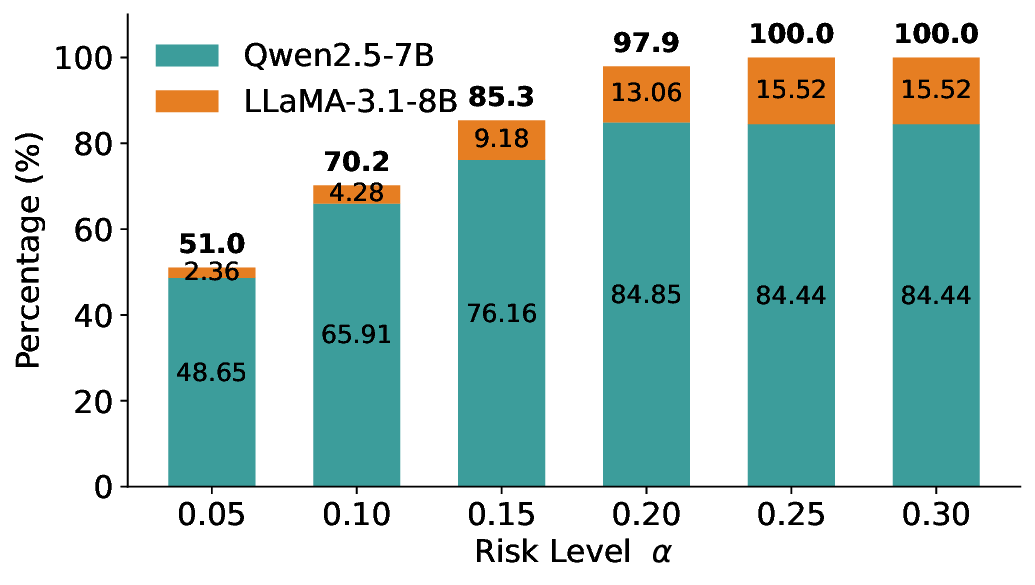
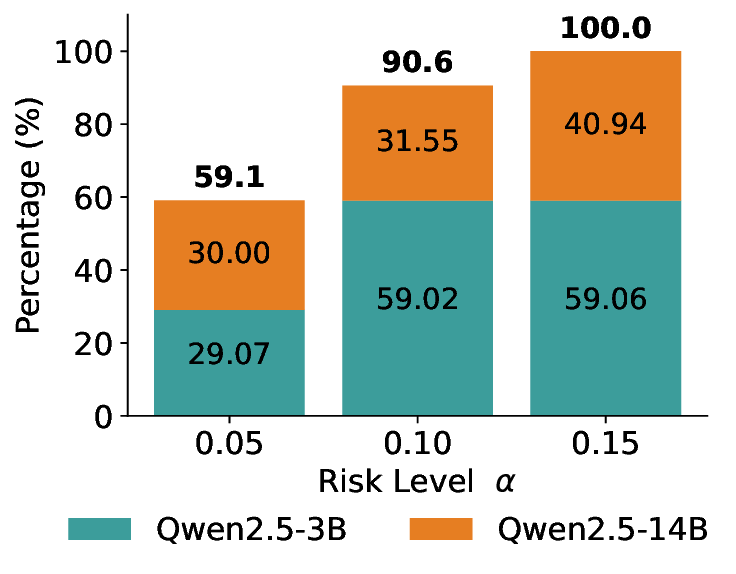
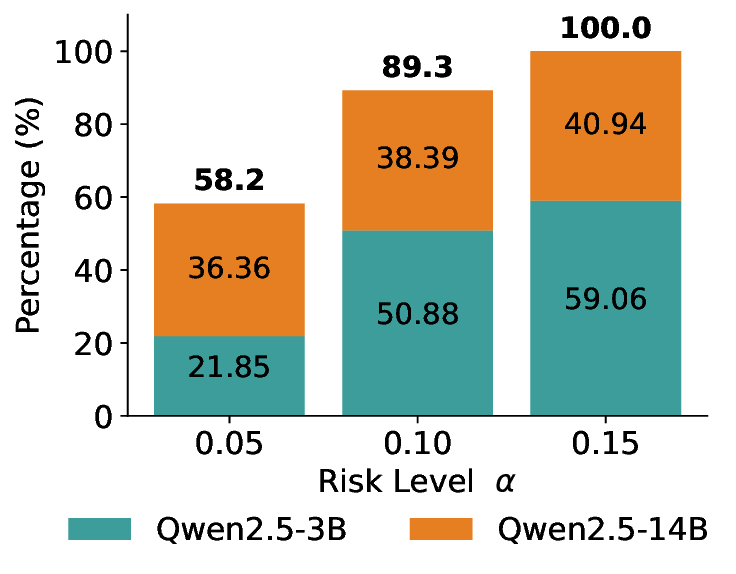
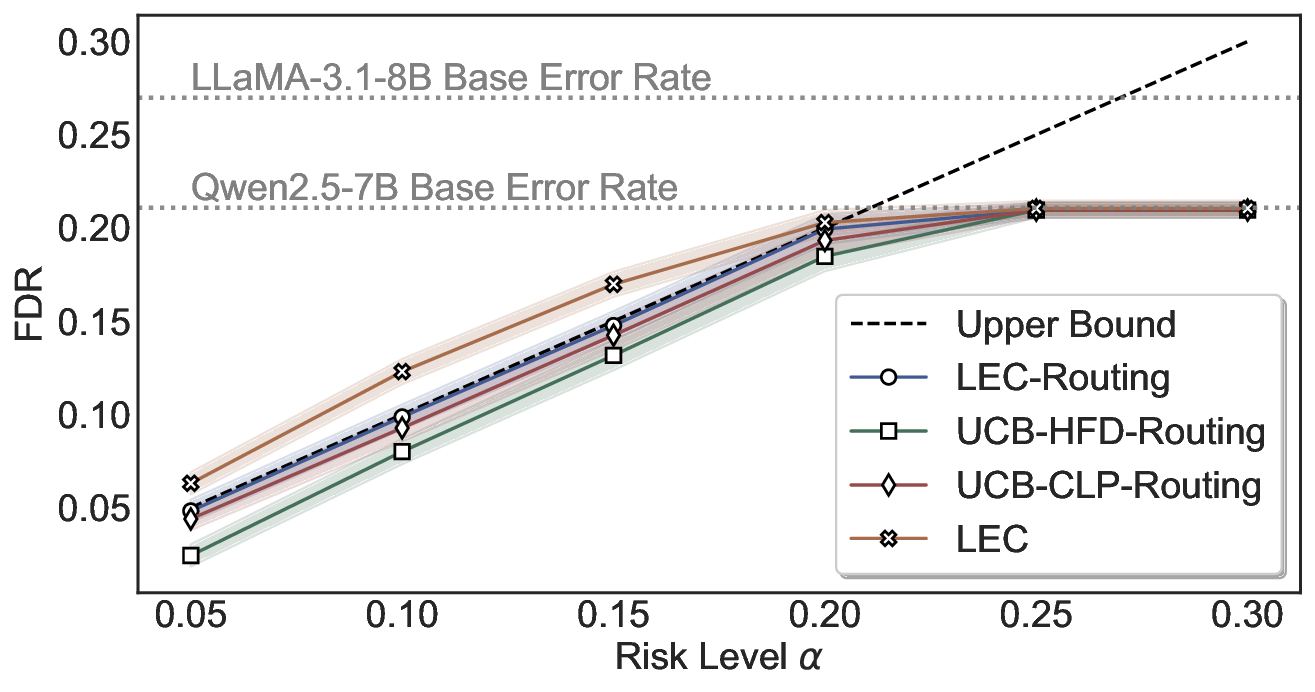
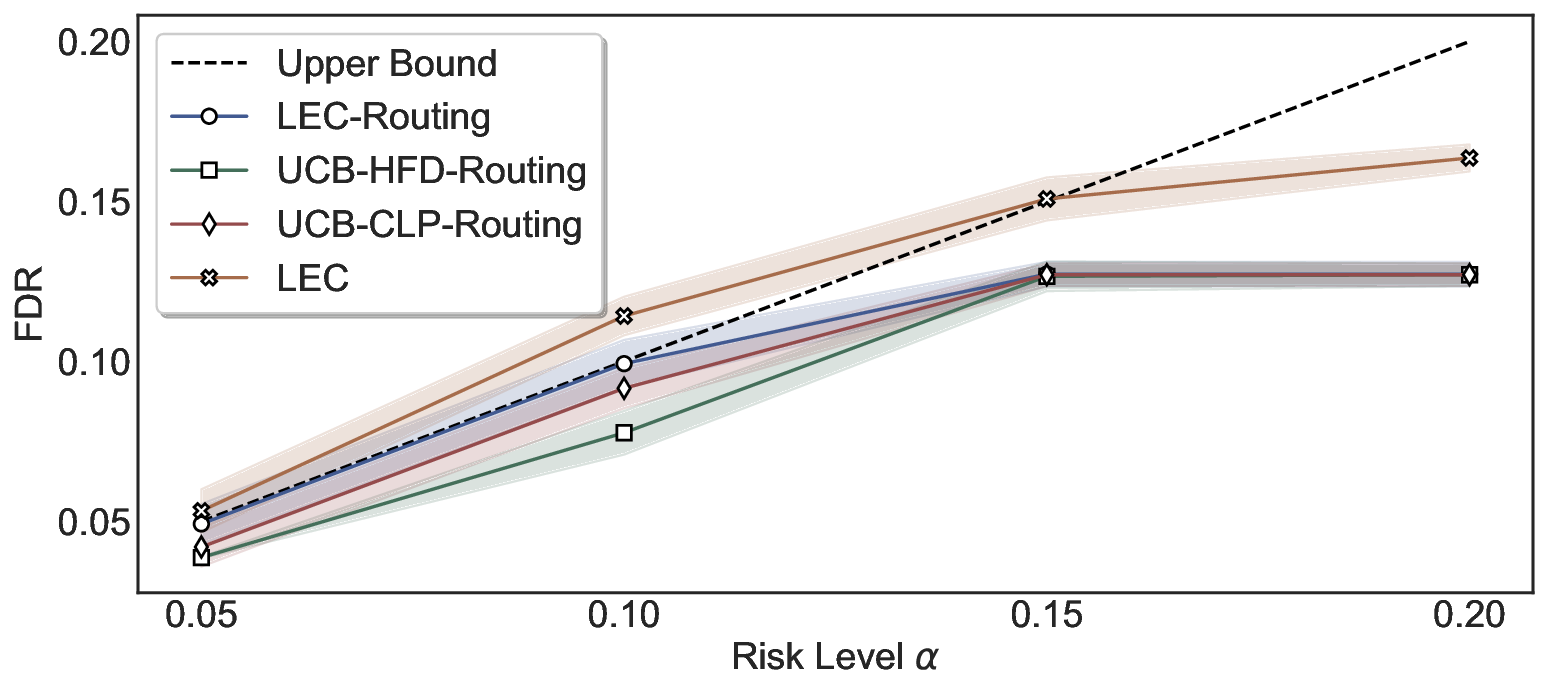
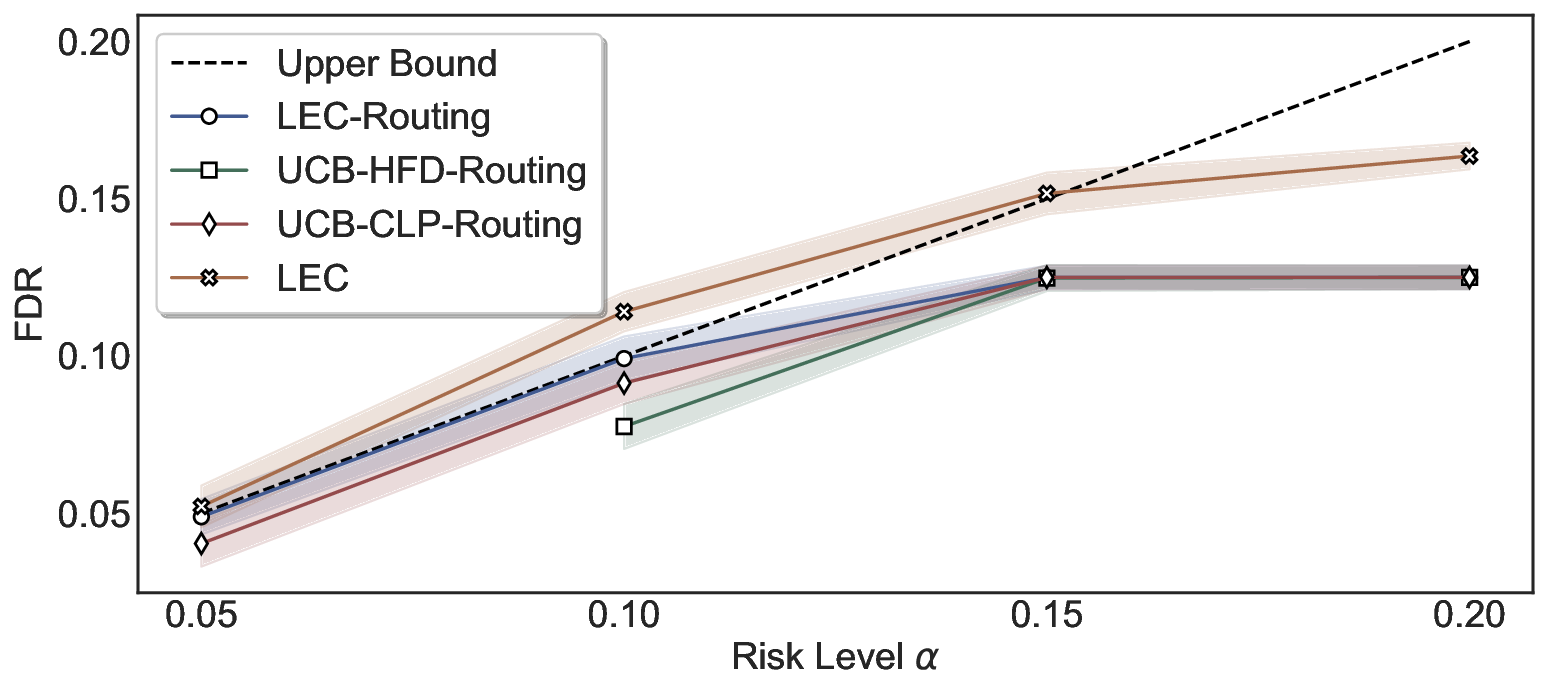
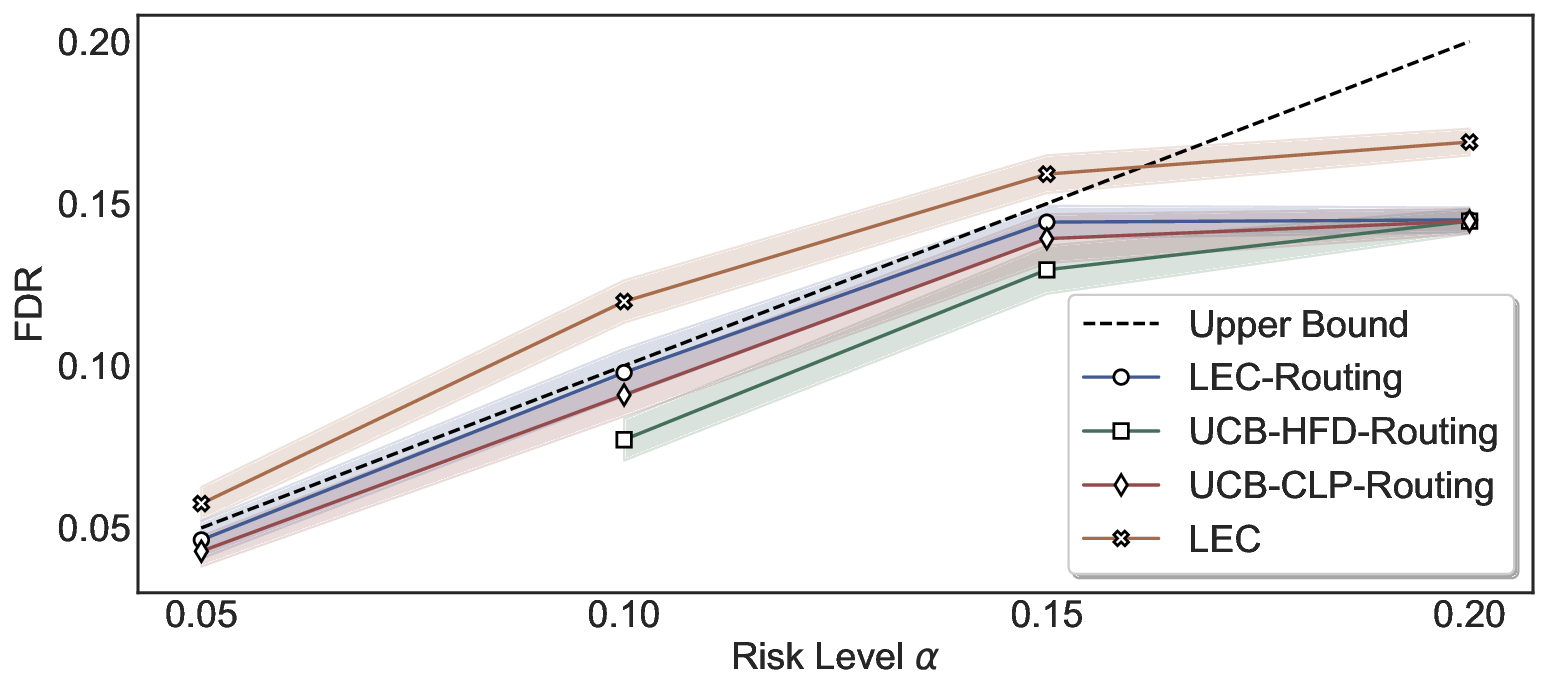
We further extend LEC to a two-model routing framework. For each input, the system accepts the current model’s prediction if its uncertainty falls below a calibrated threshold; otherwise, the input is routed to the subsequent model. If neither model satisfies its acceptance criterion, the system abstains. To preserve statistical guarantees, we impose a linear expectation constraint on the system-level selection and error indicators, which enables joint calibration of modelspecific thresholds with unified FDR control. Figure 1 illustrates examples of selective prediction in single-model and two-model routing systems, where uncertainty serves as the decision signal for accepting, routing, or abstaining.
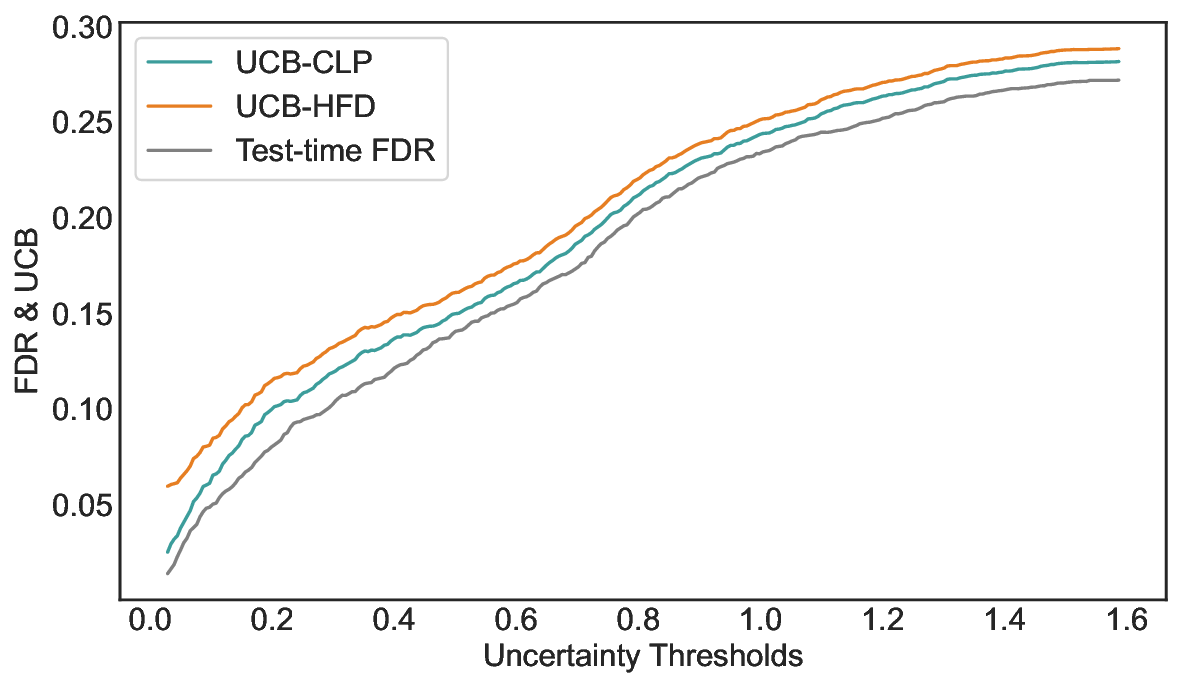
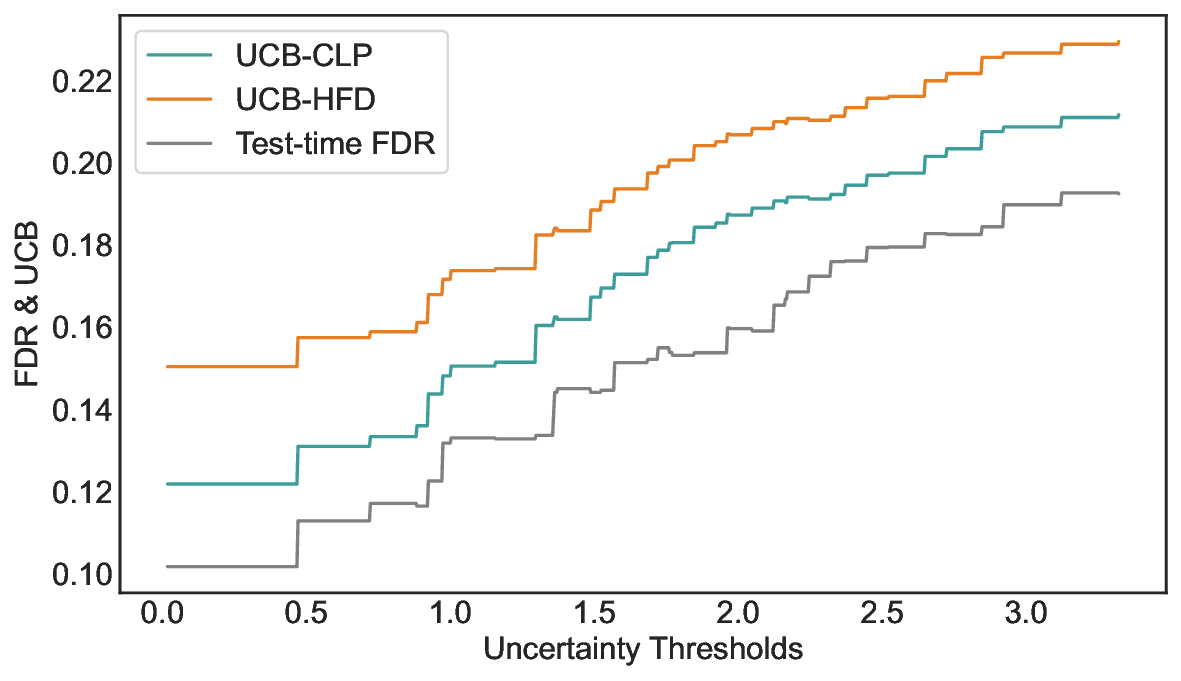
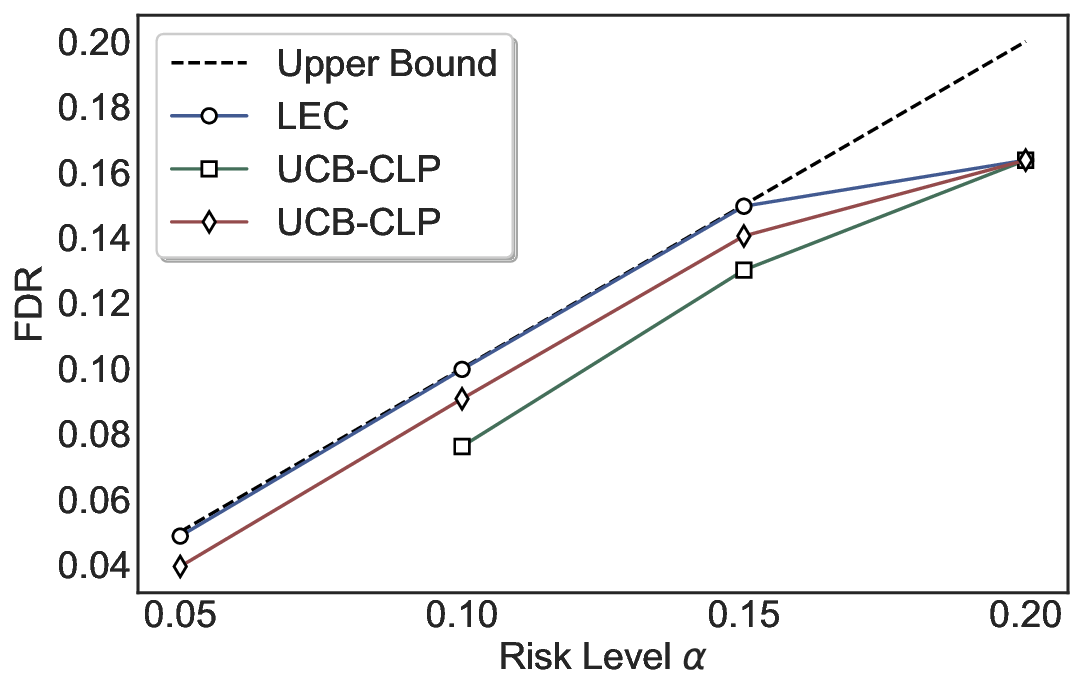
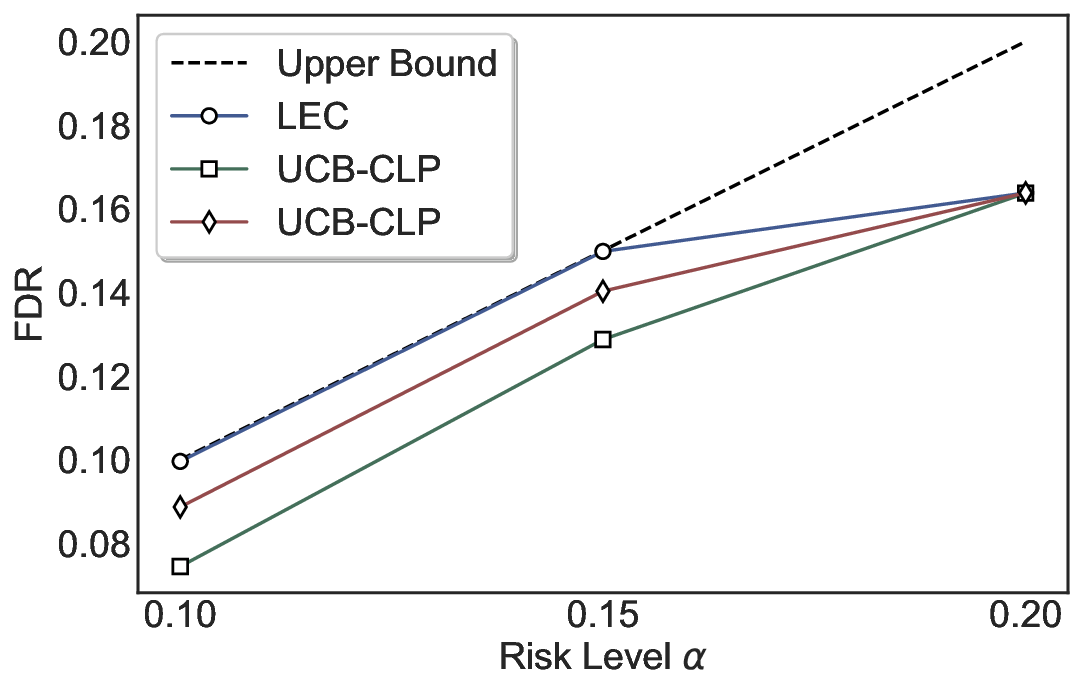
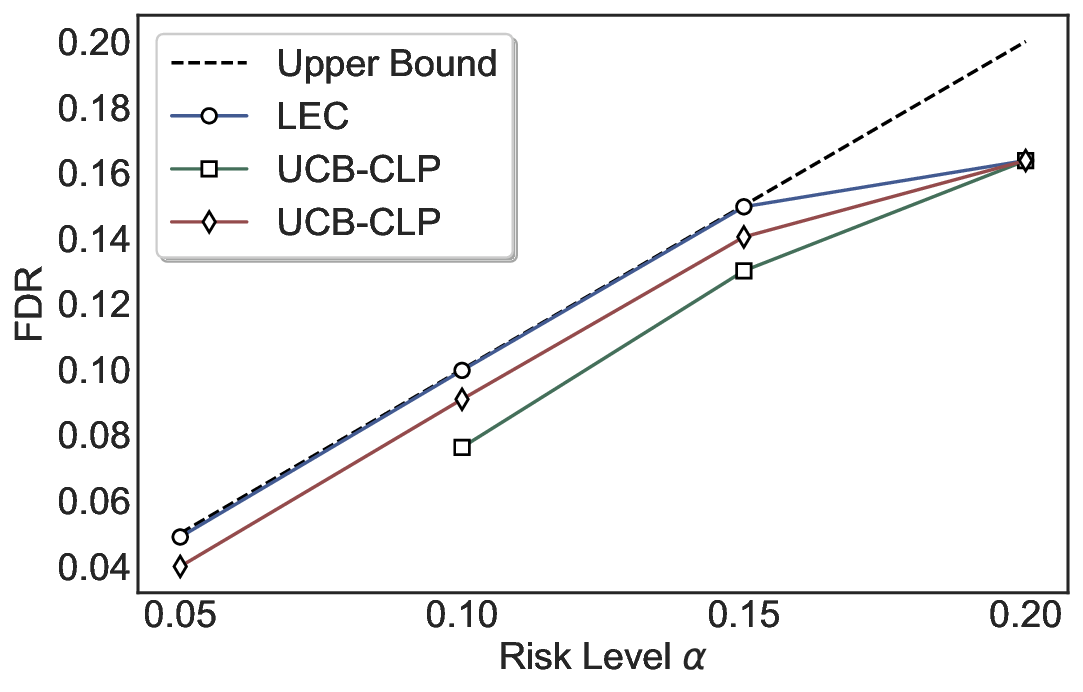
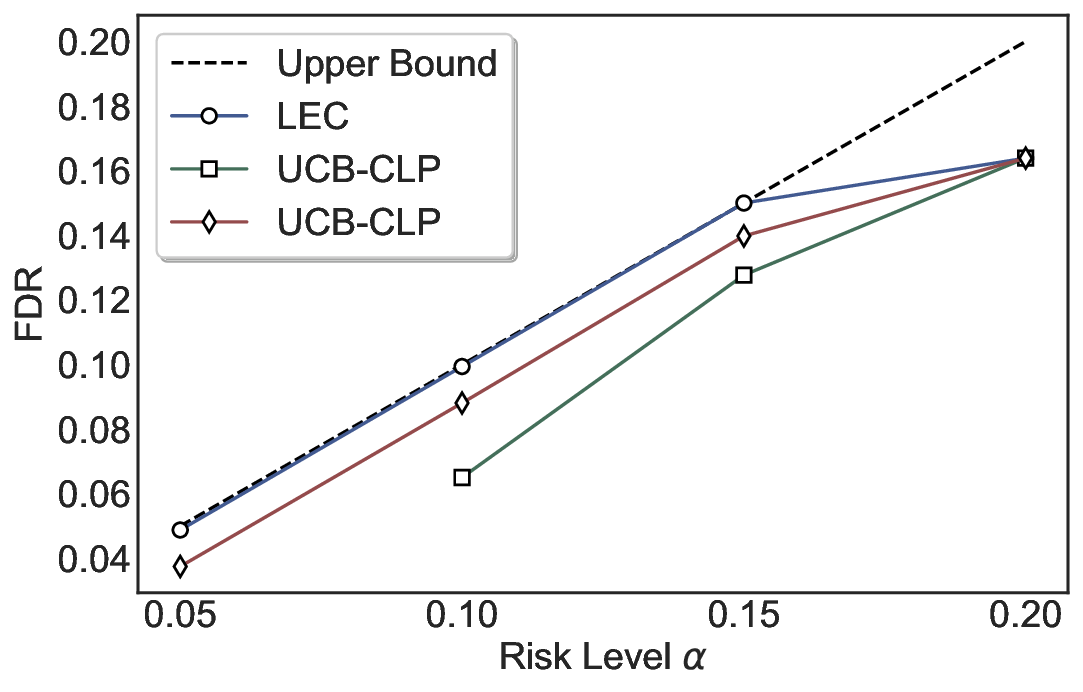
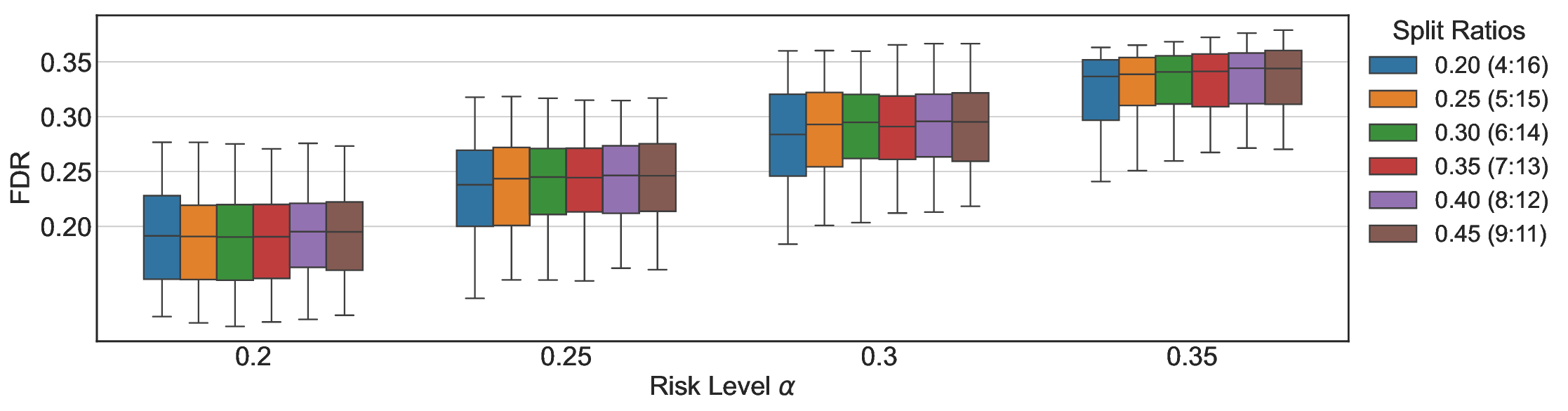
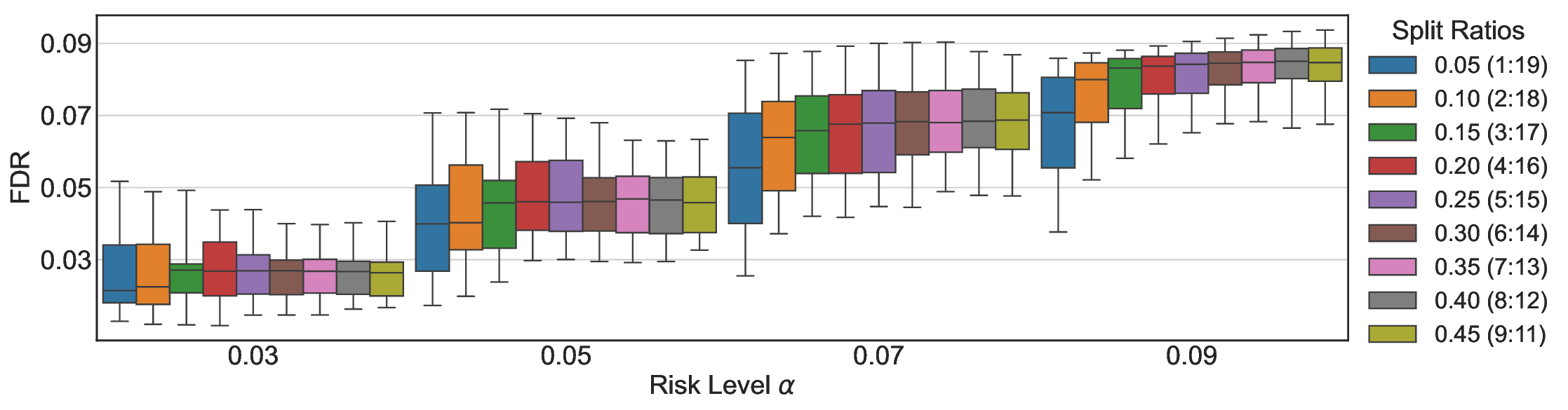
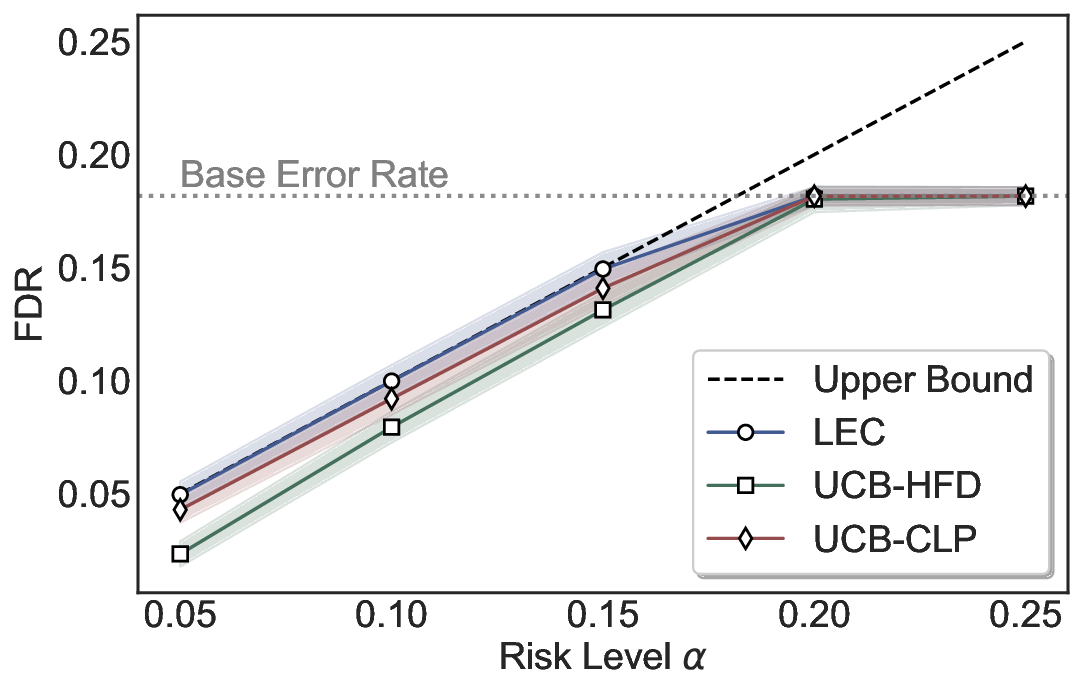
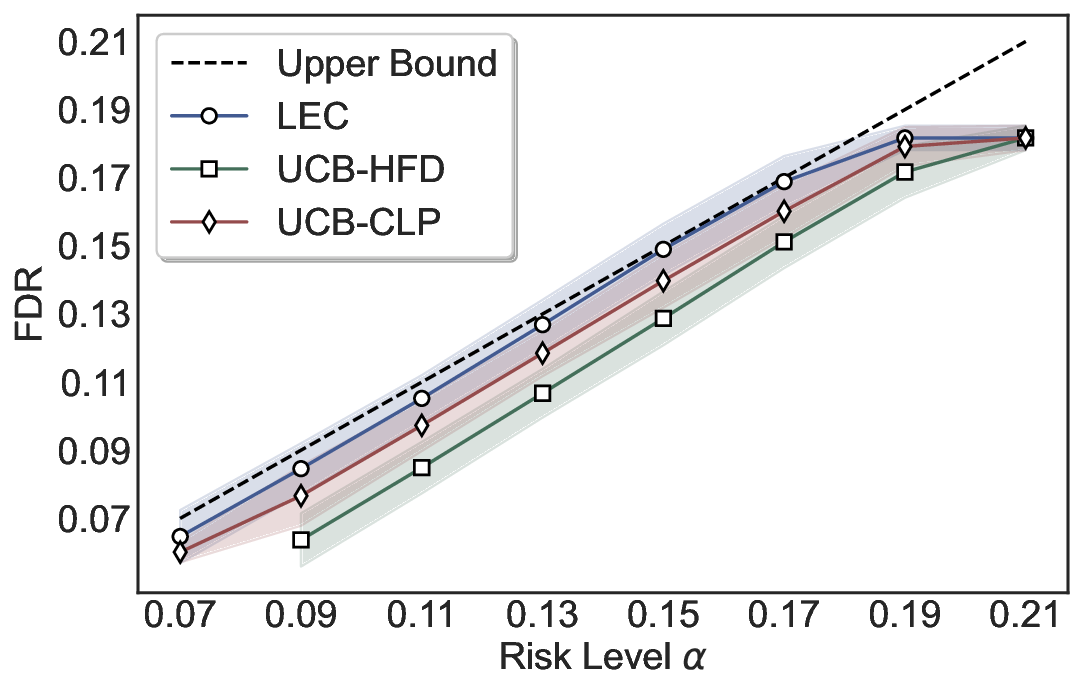
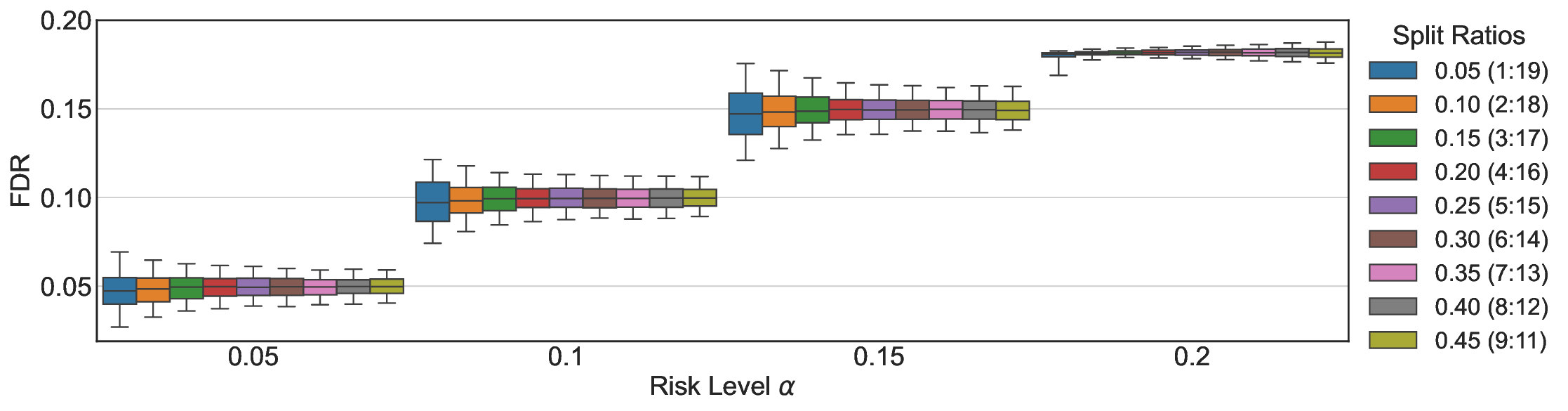
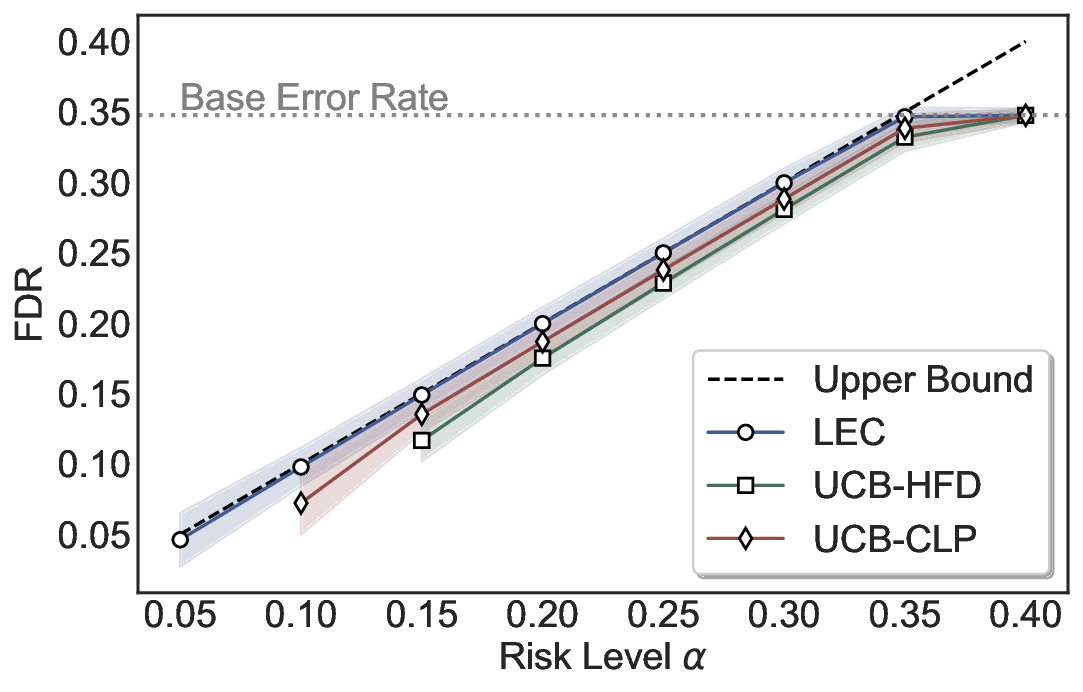
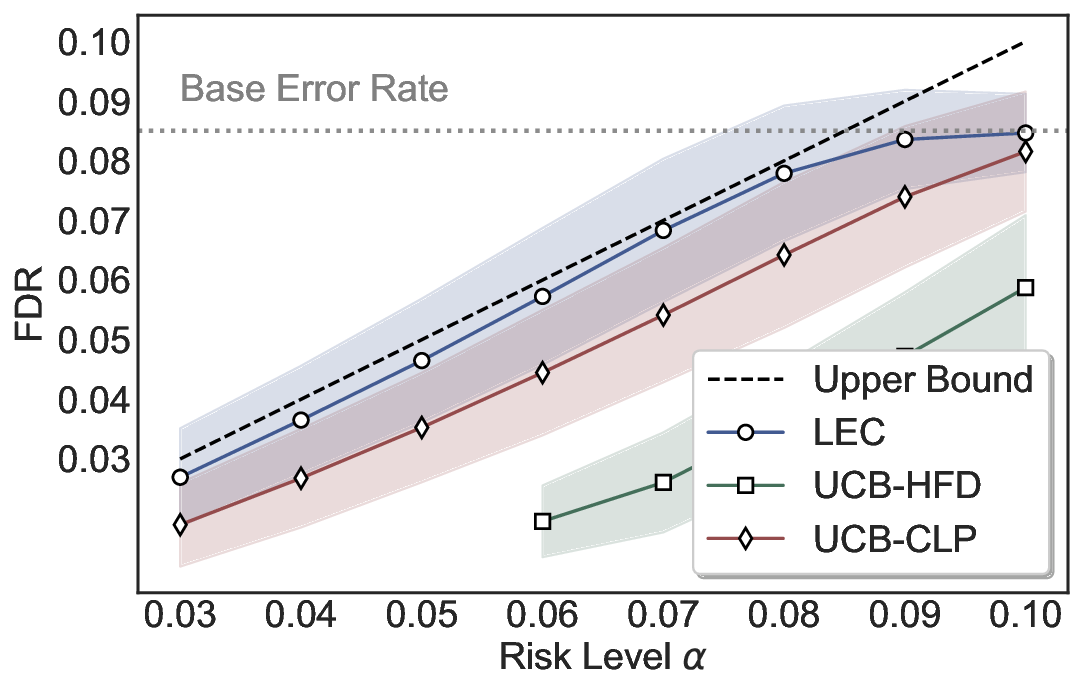
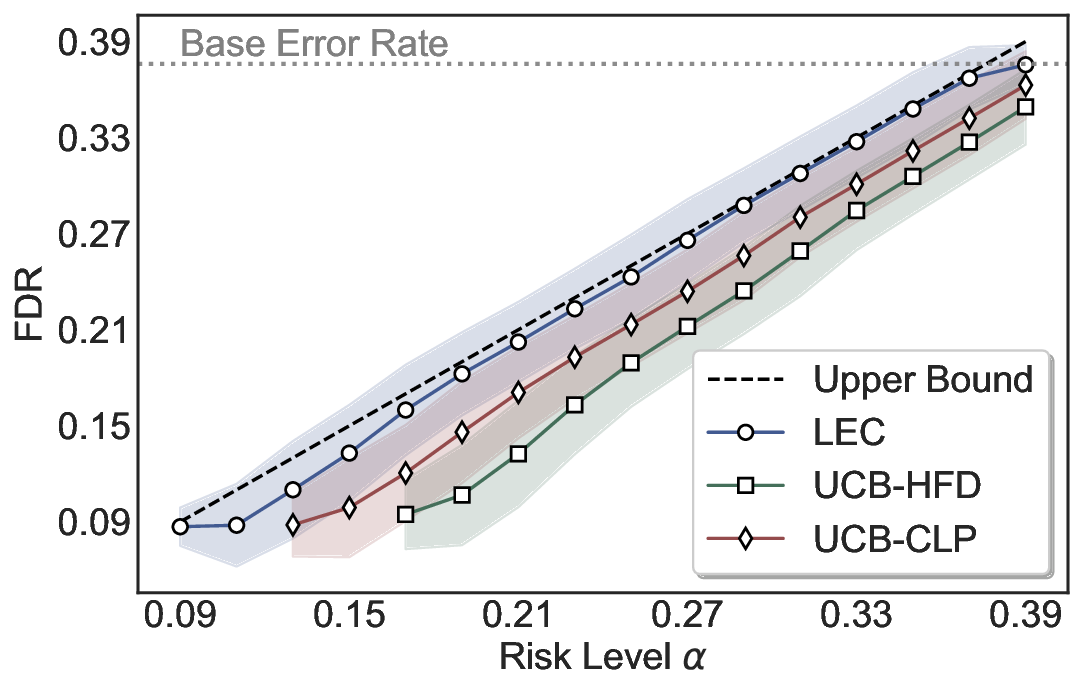
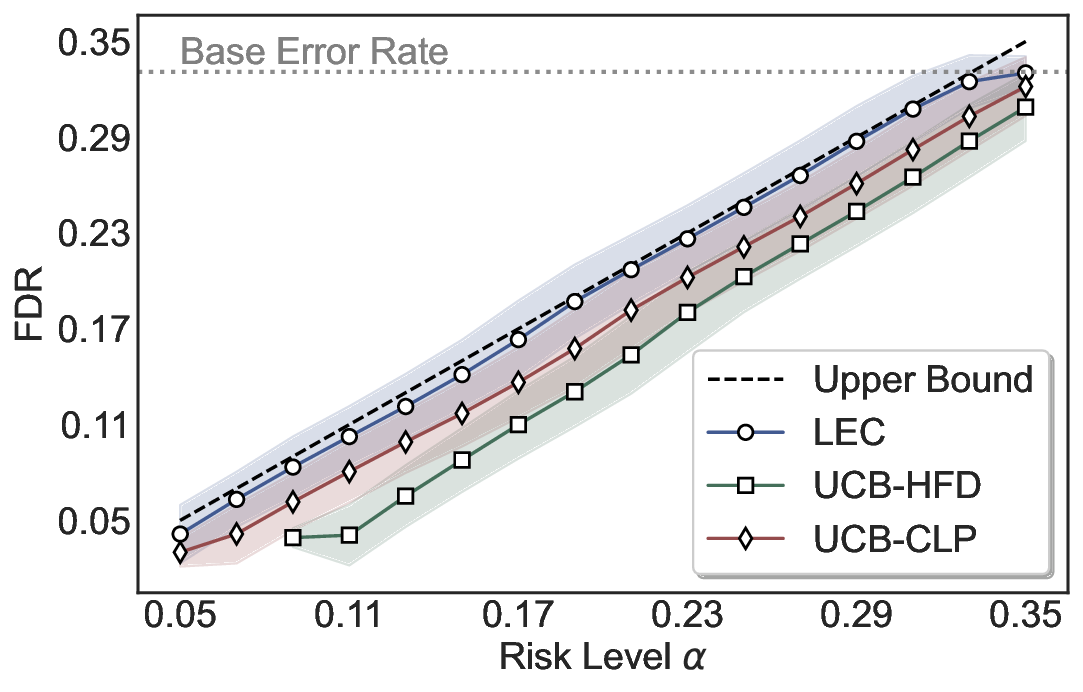
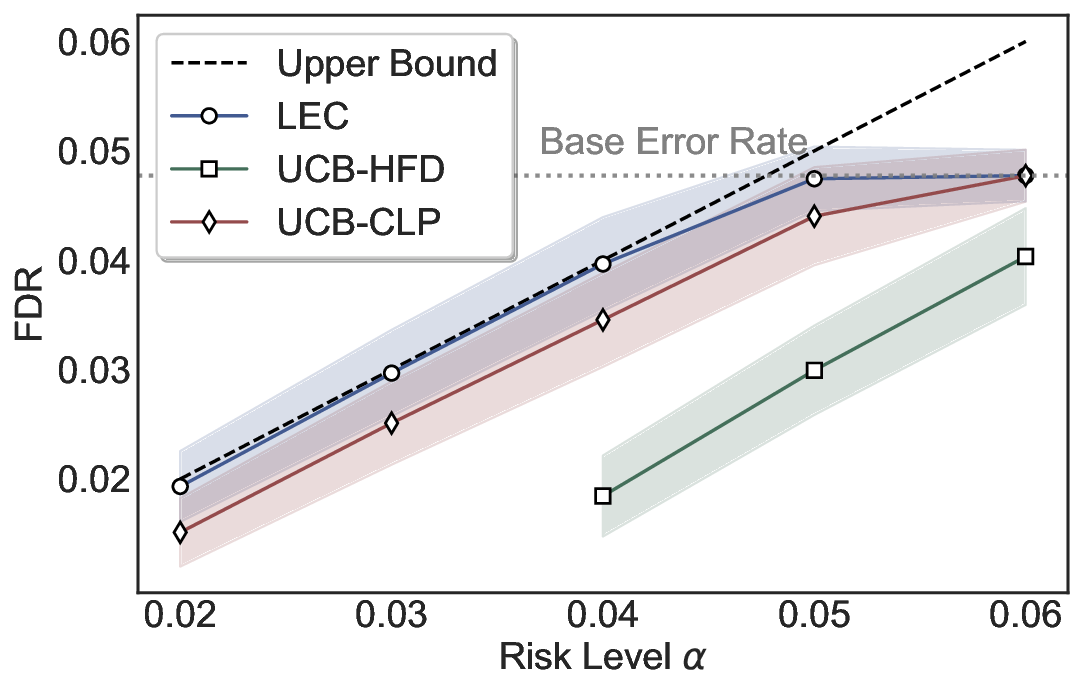
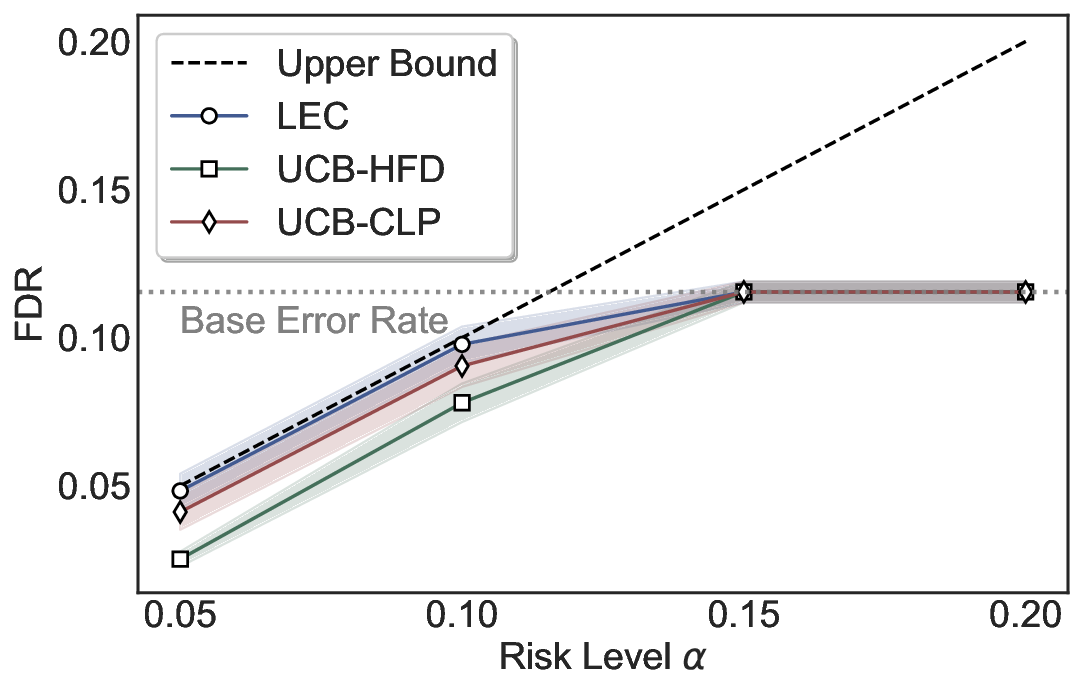
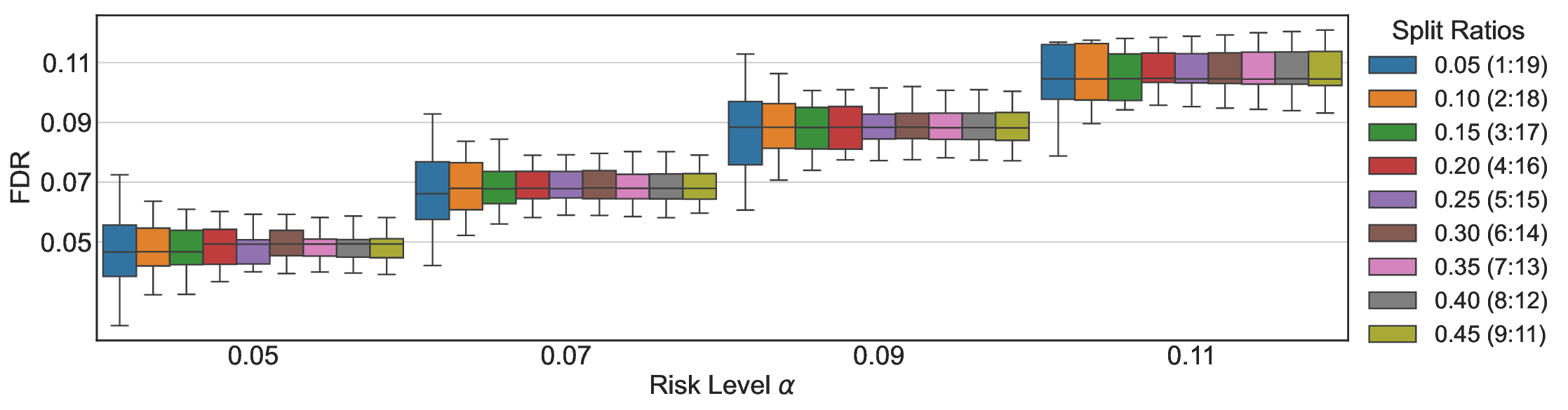
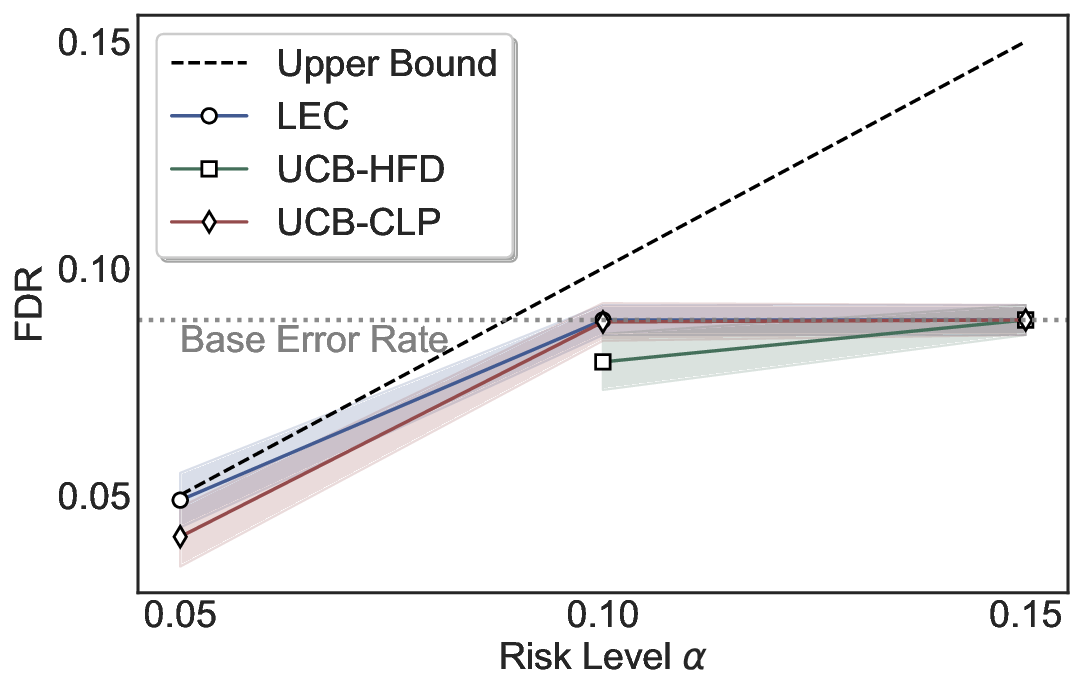
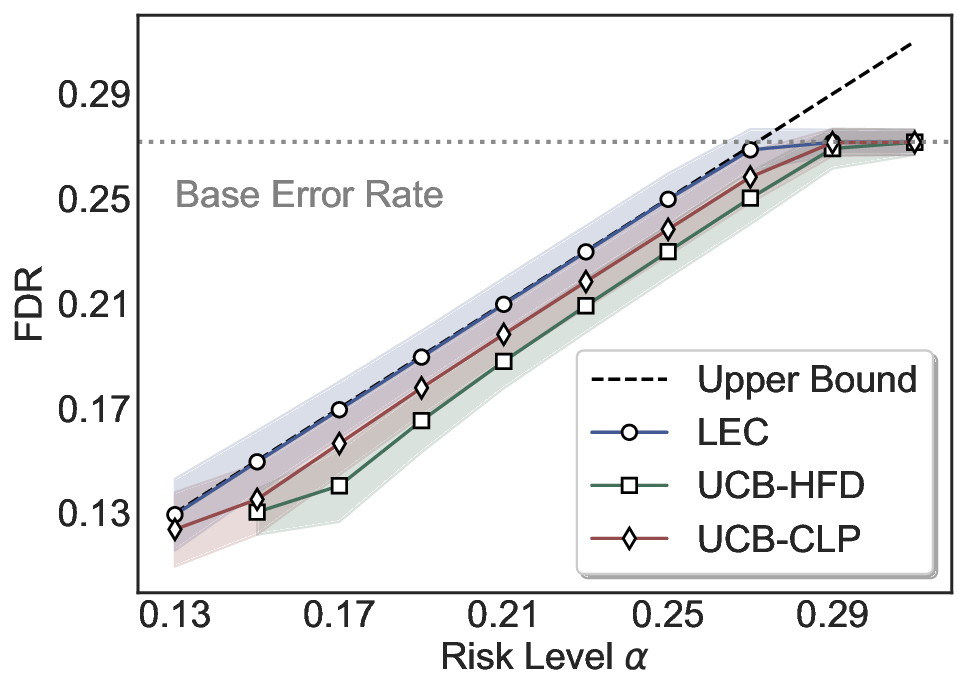
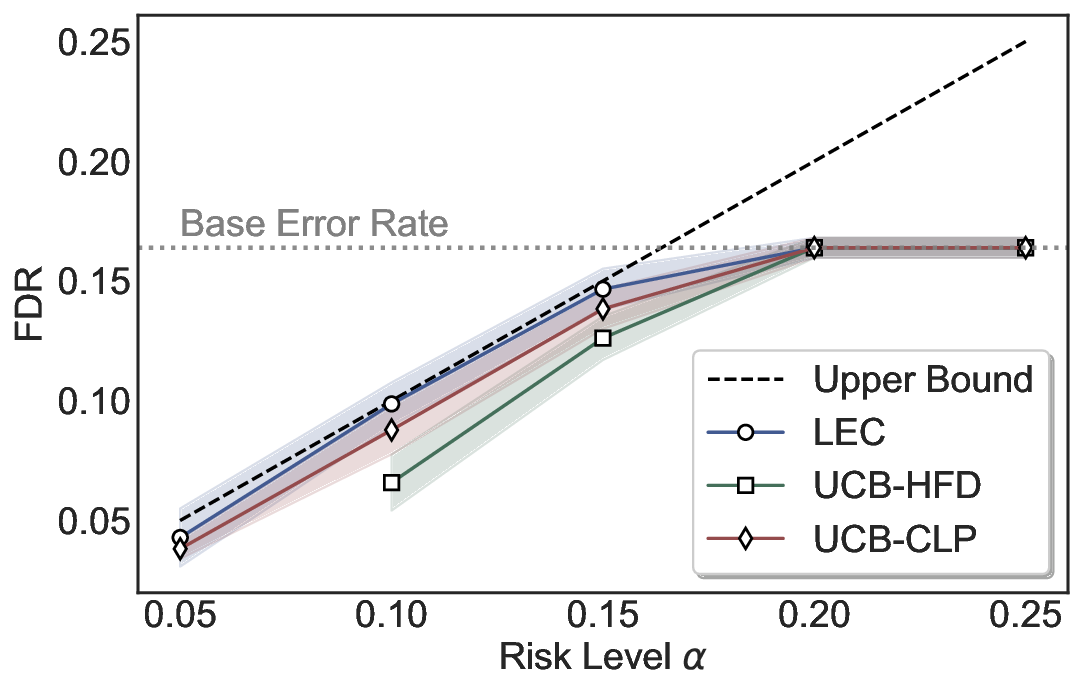
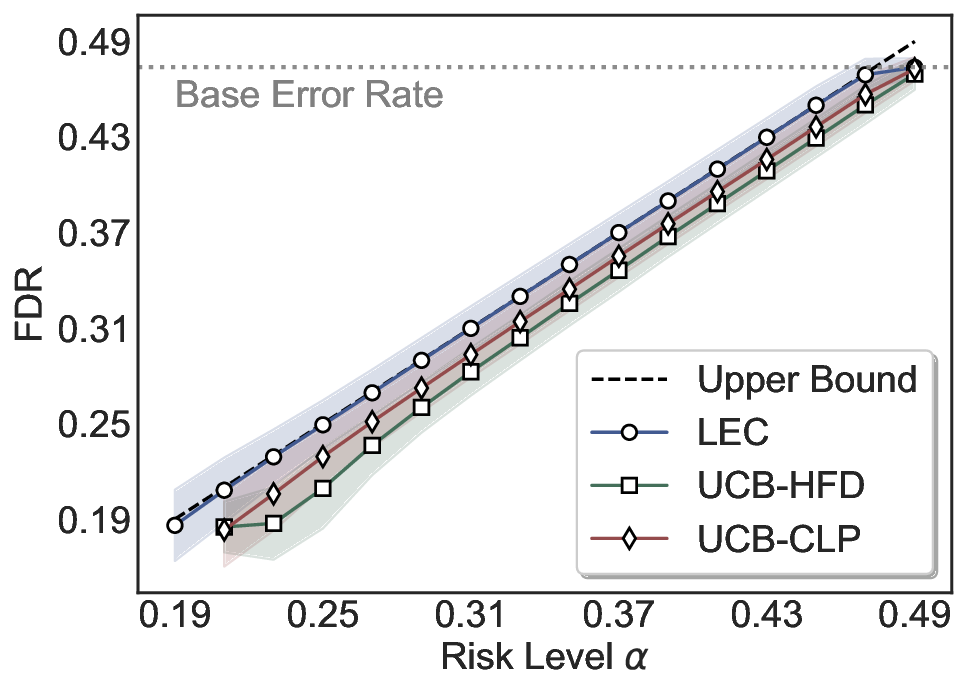
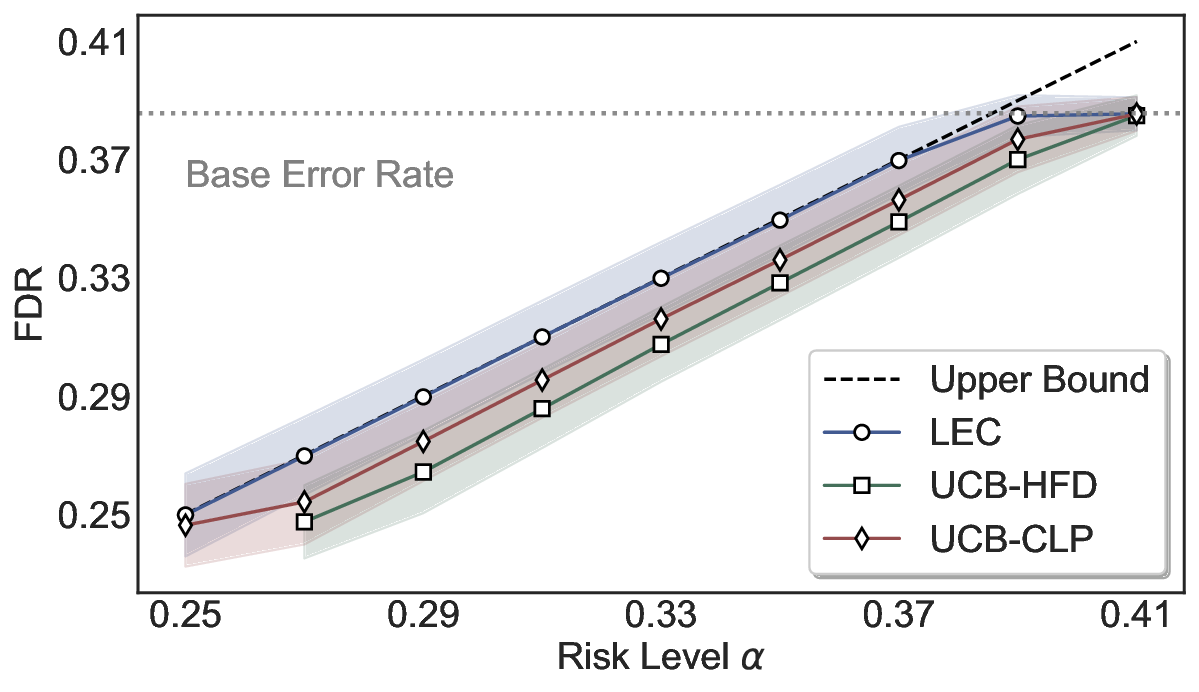
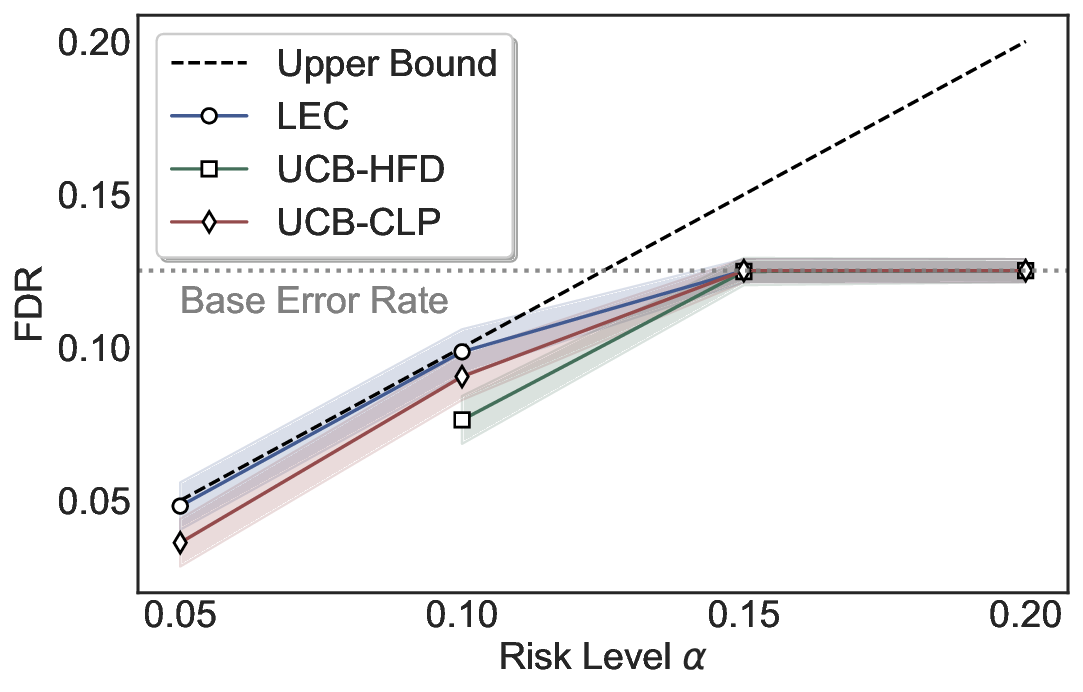
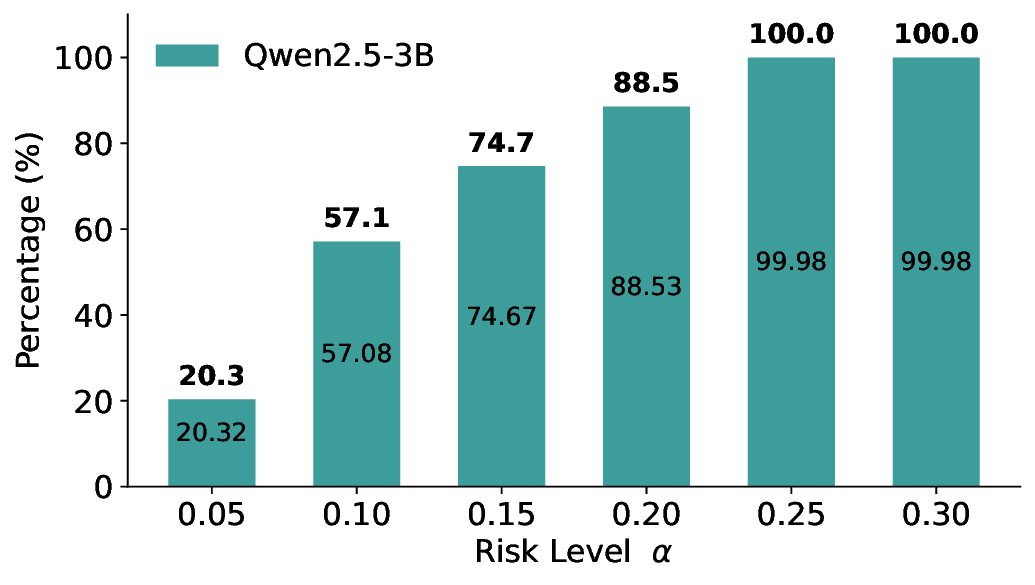
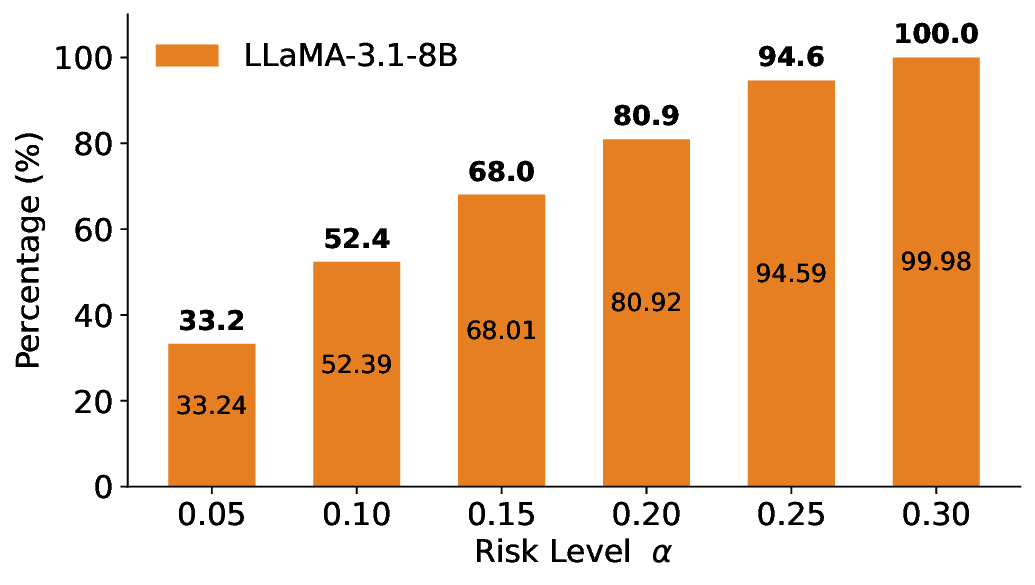
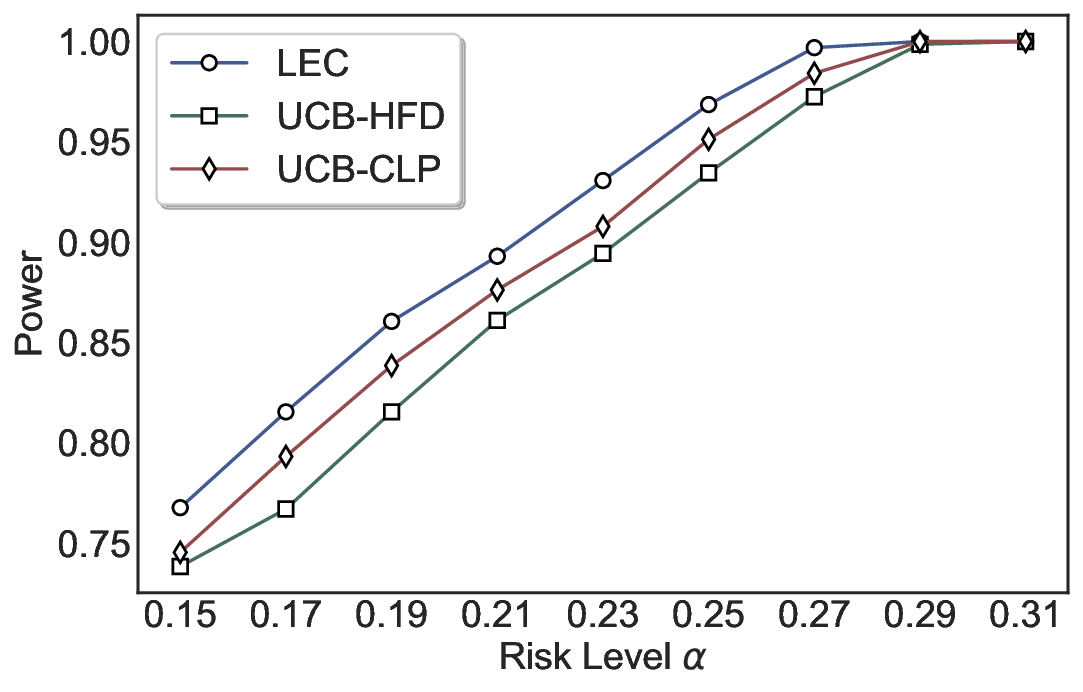
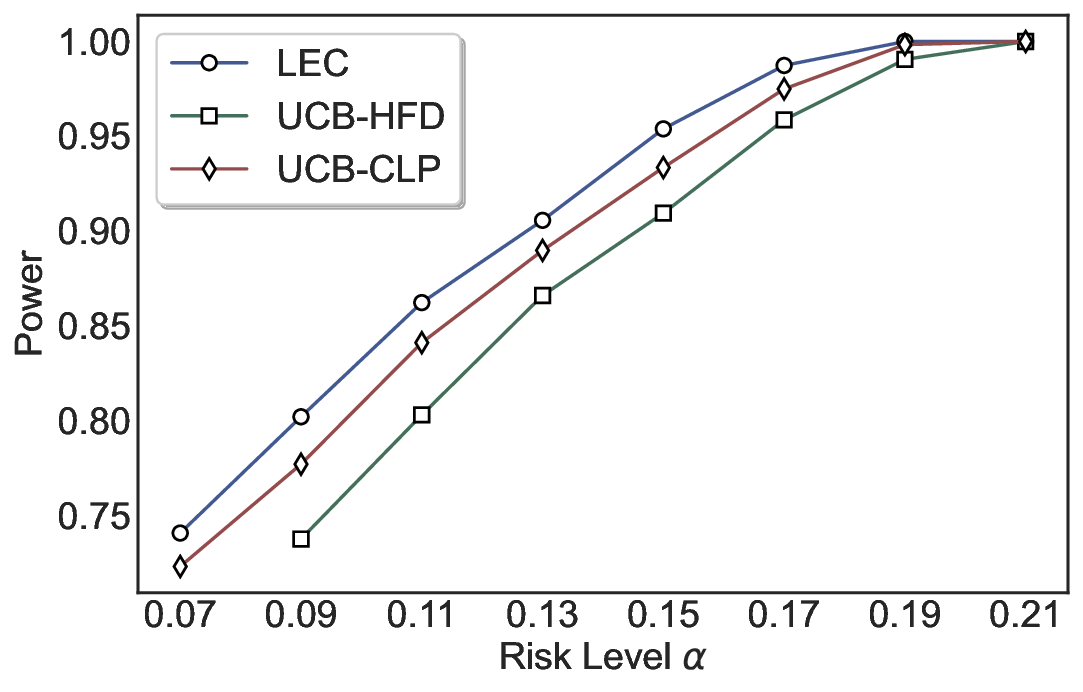
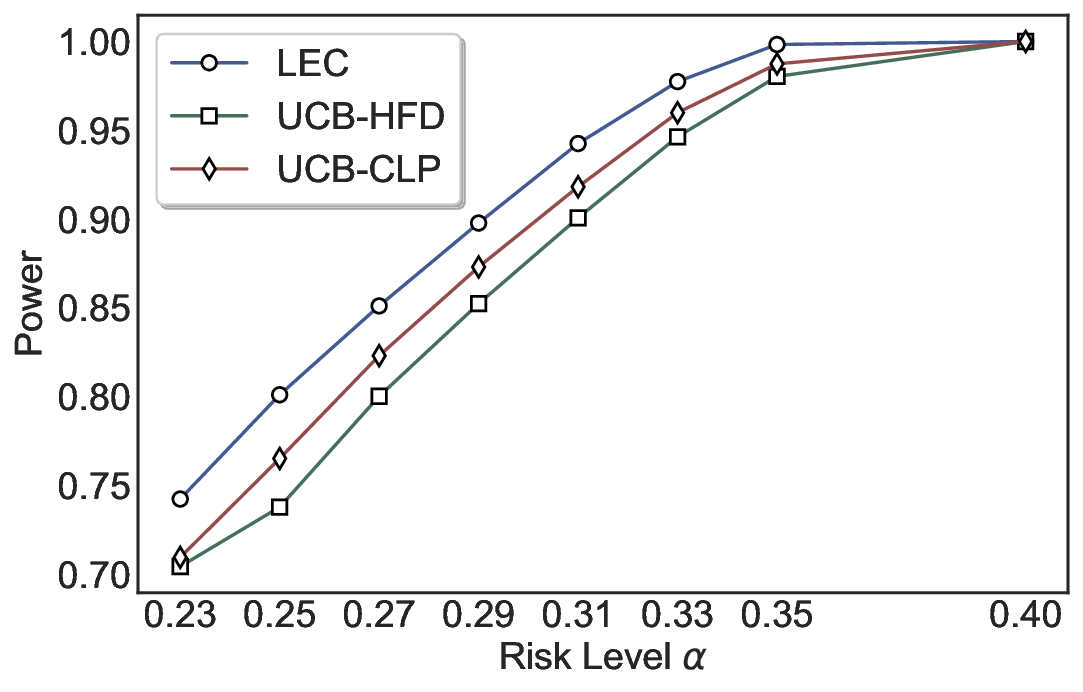
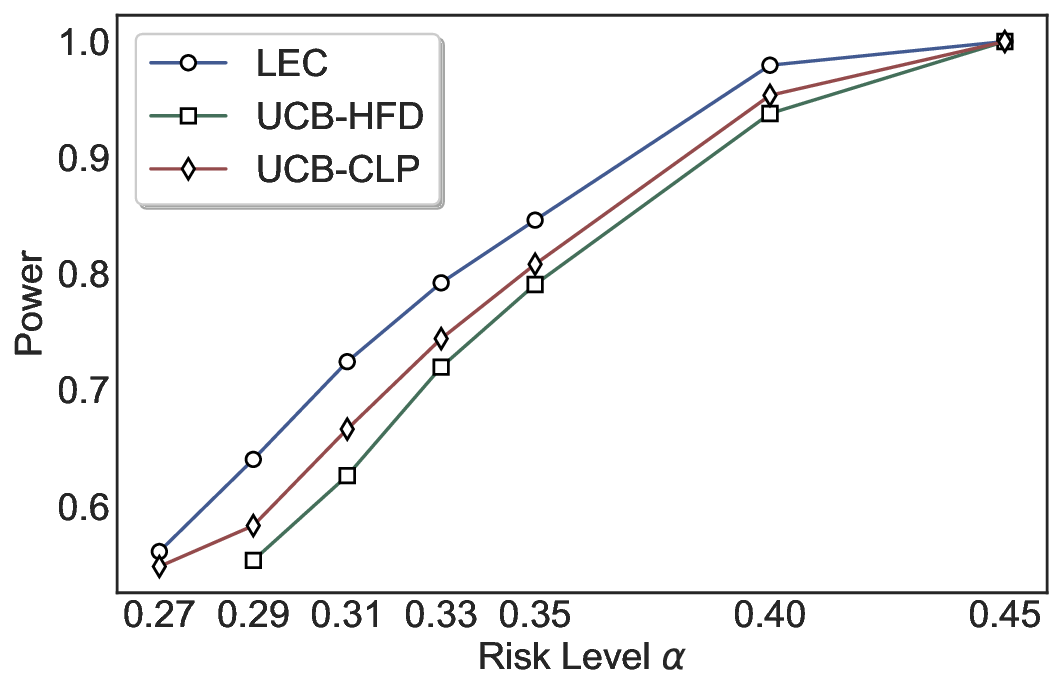
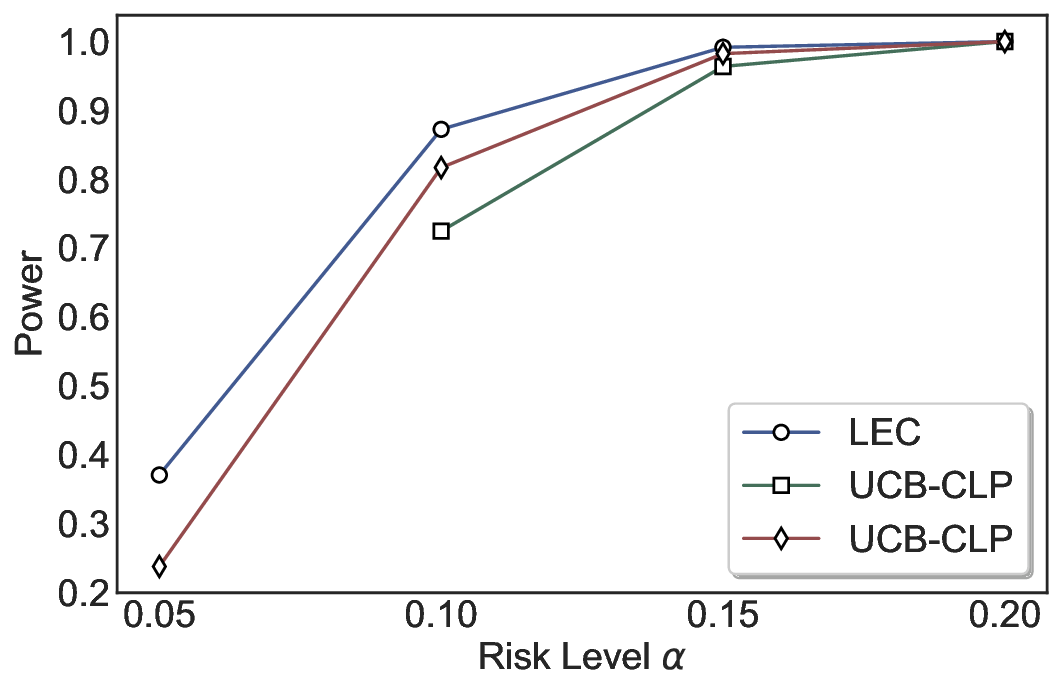
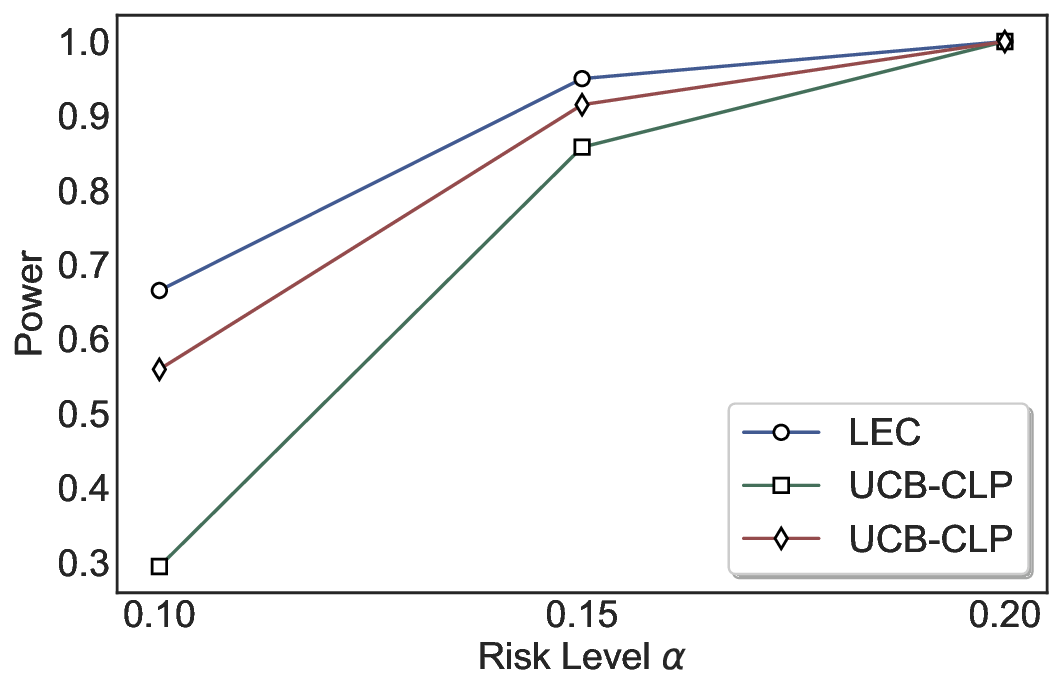
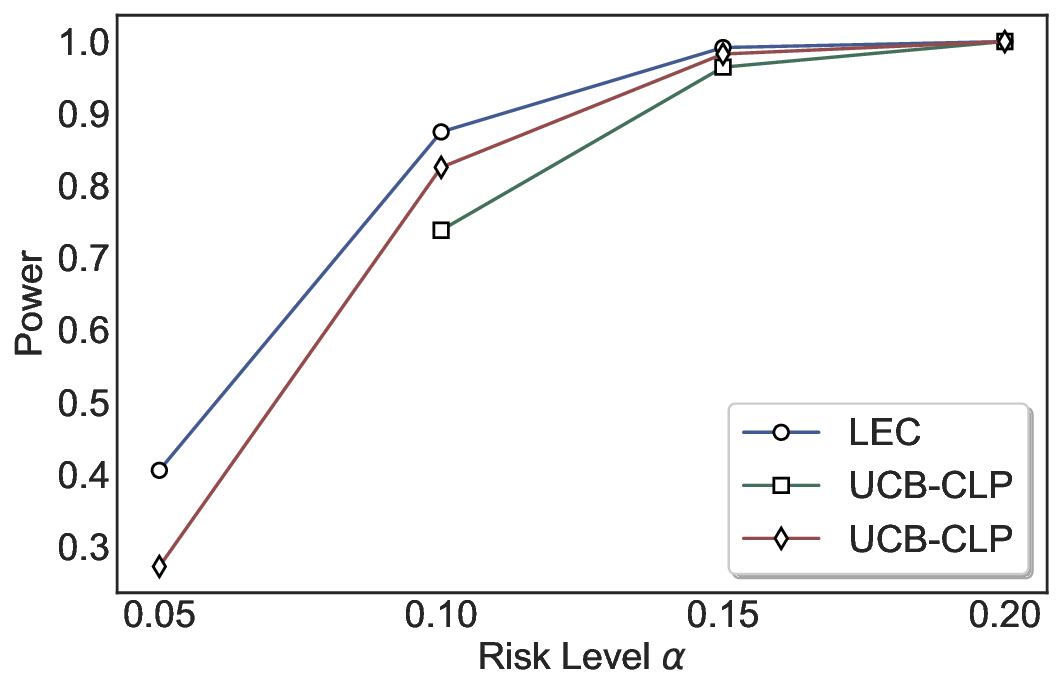
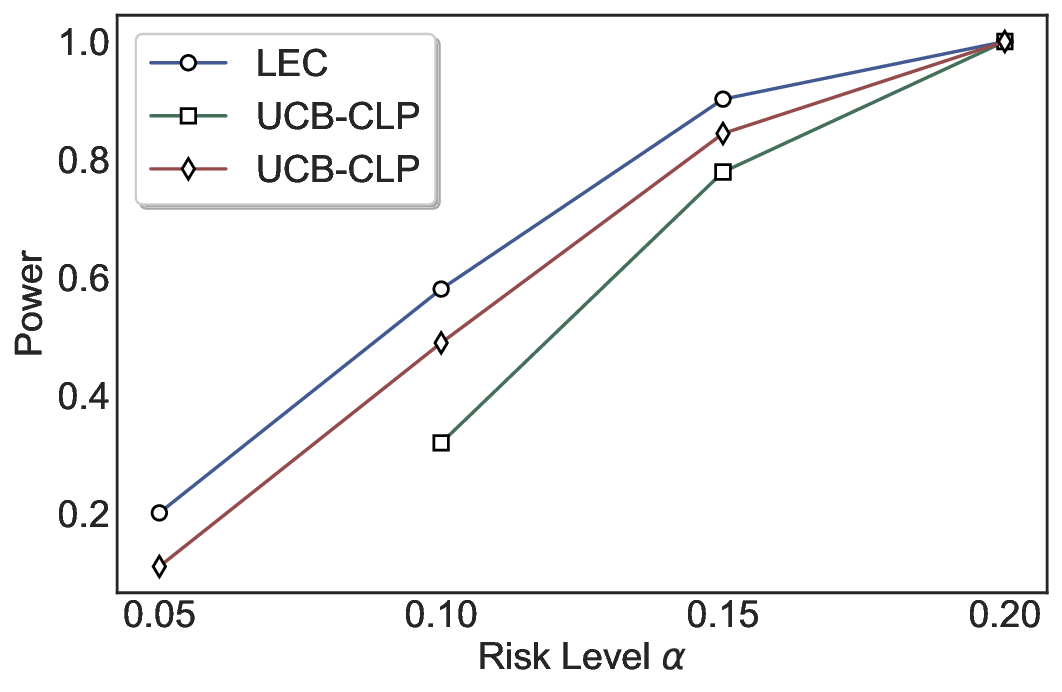
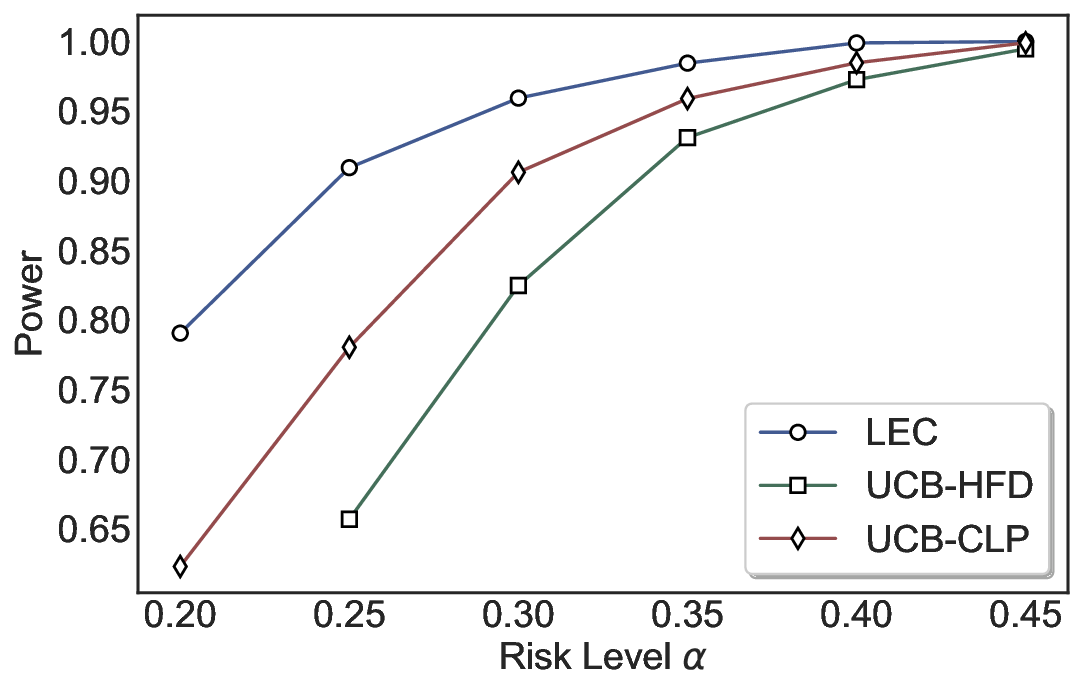
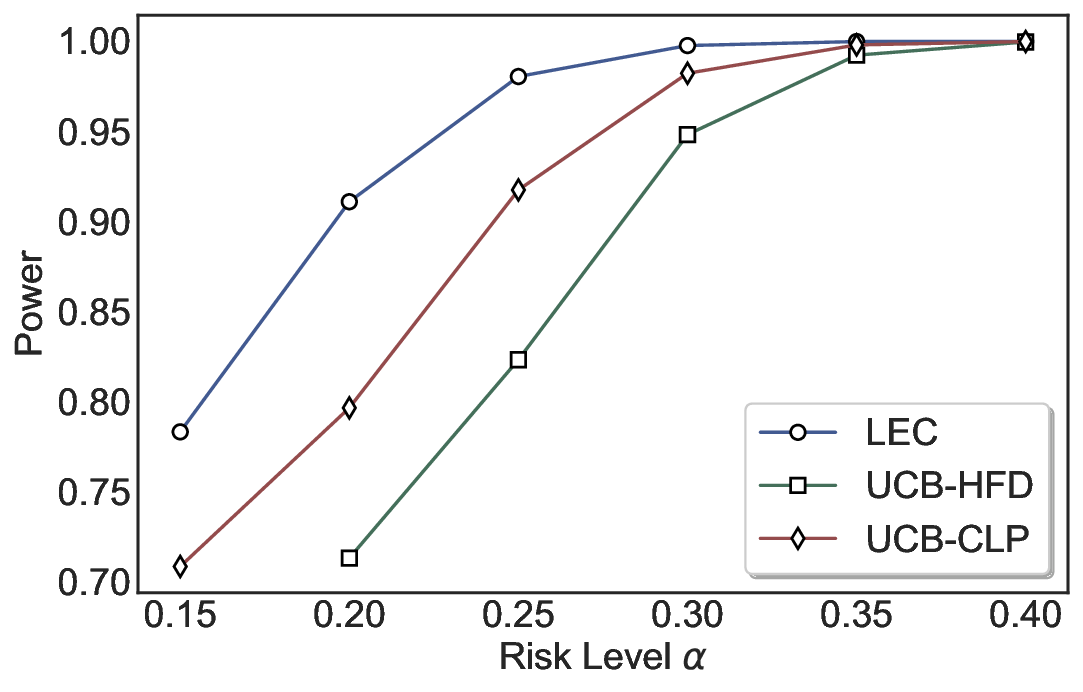
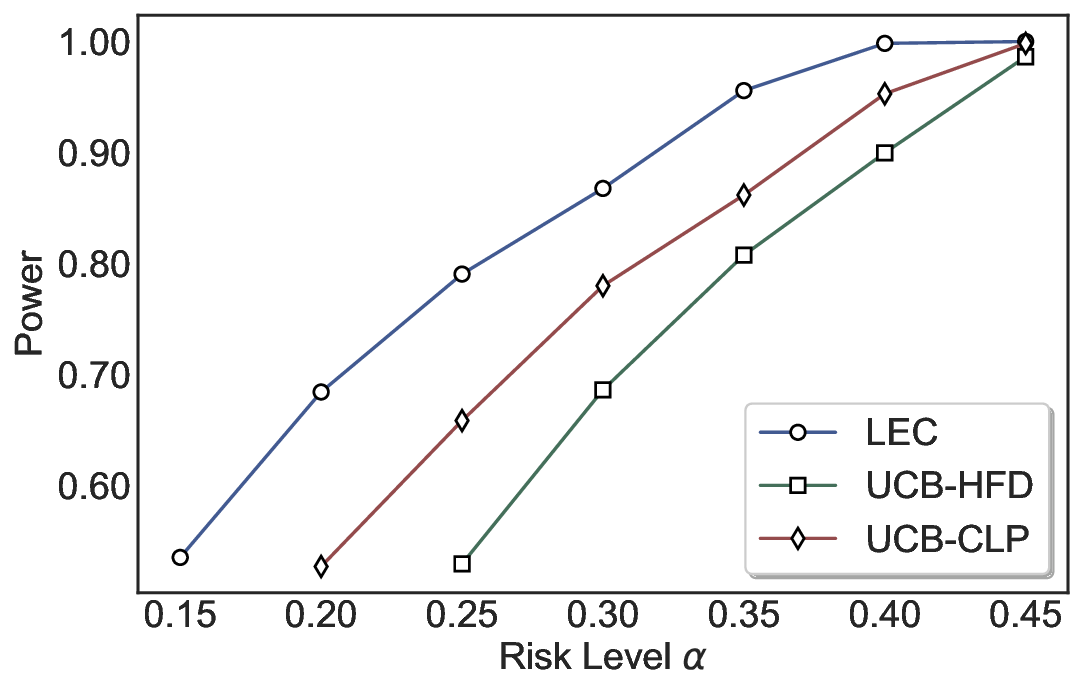
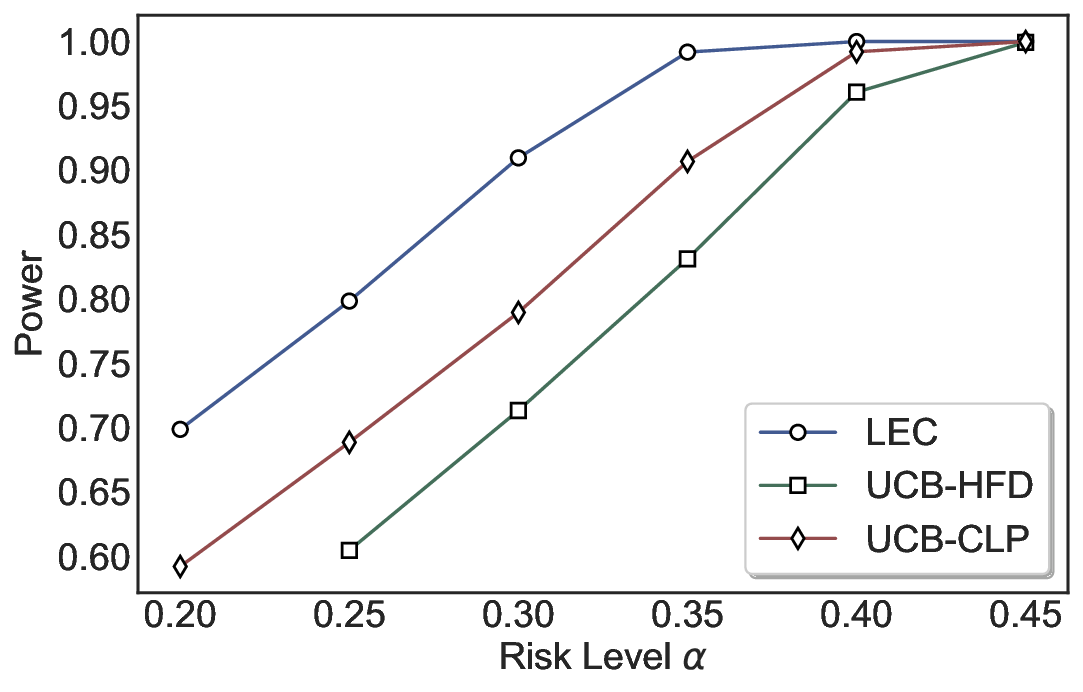
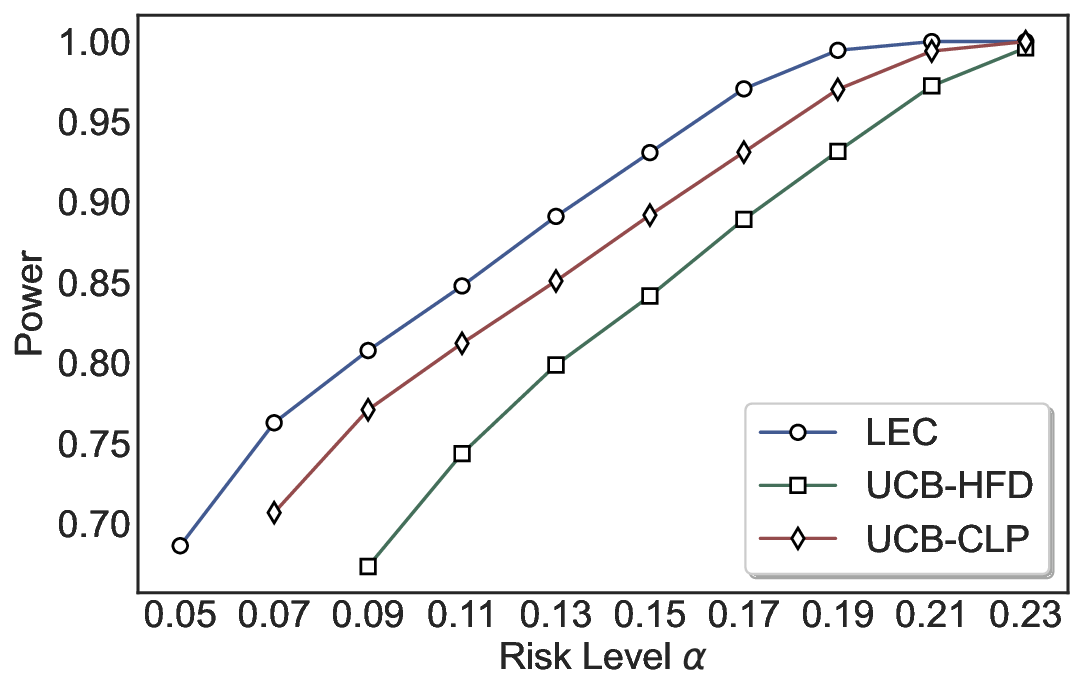
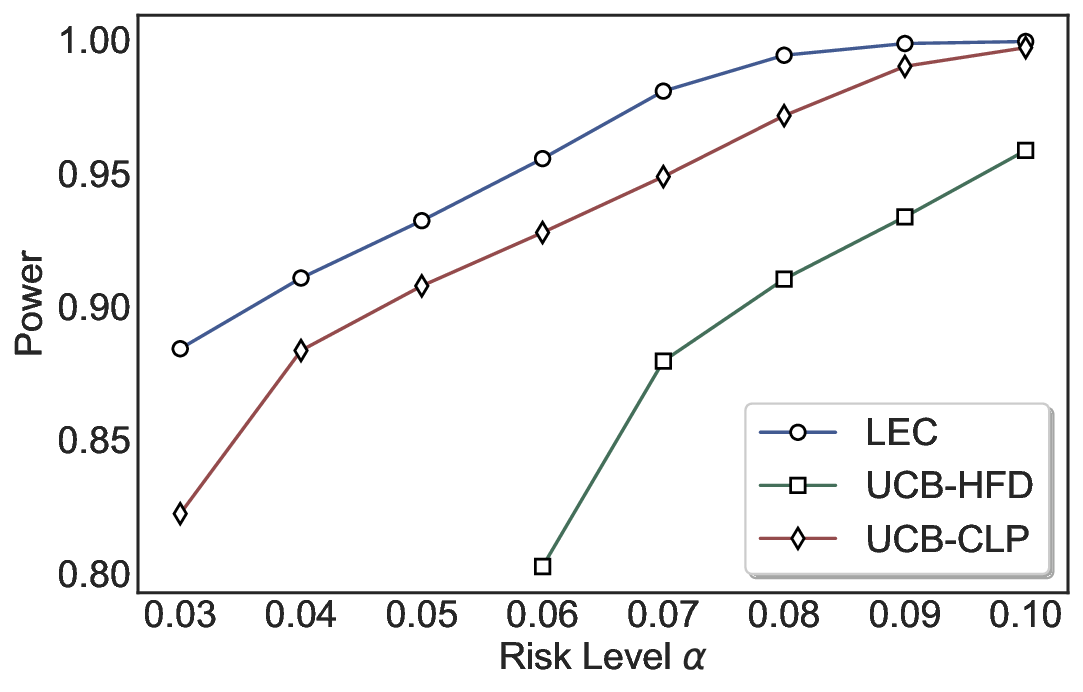
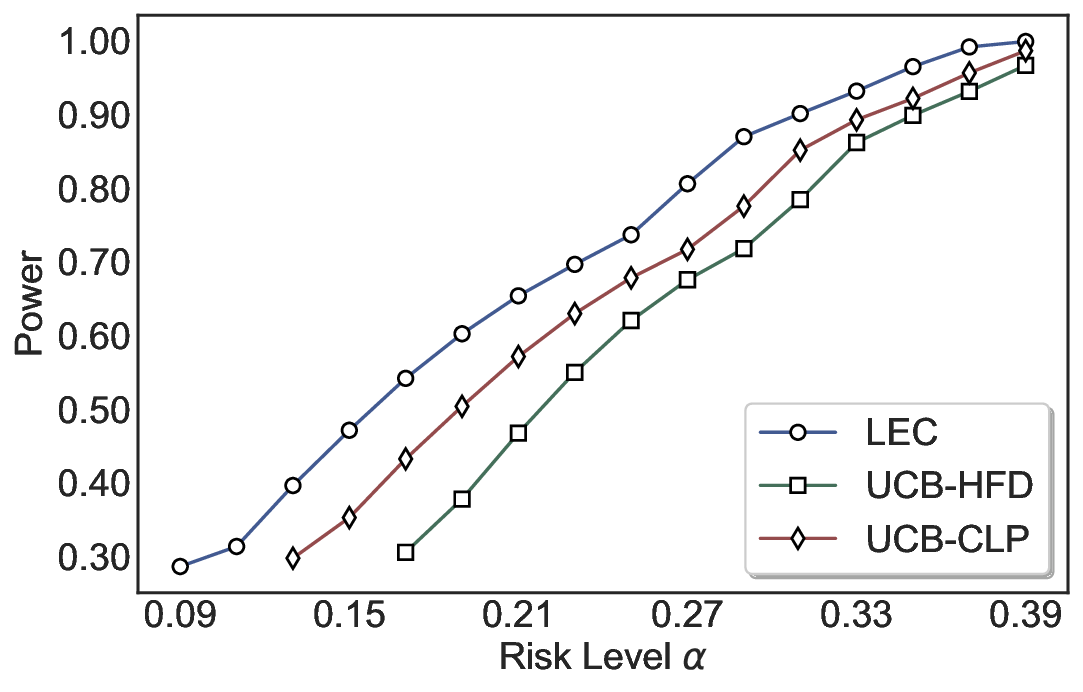
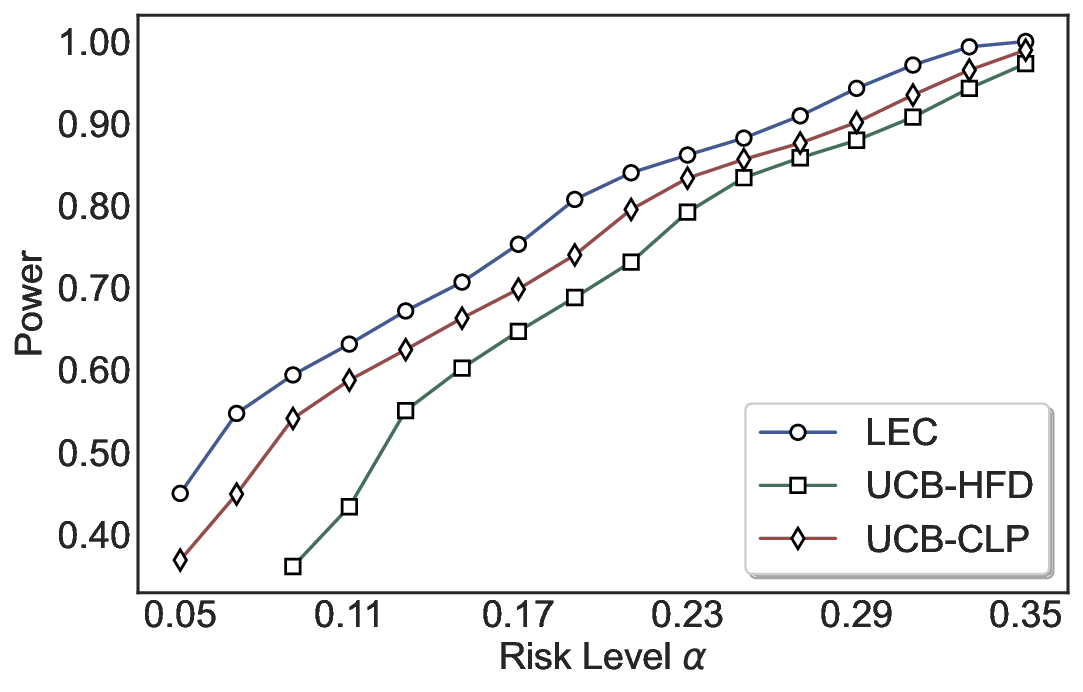
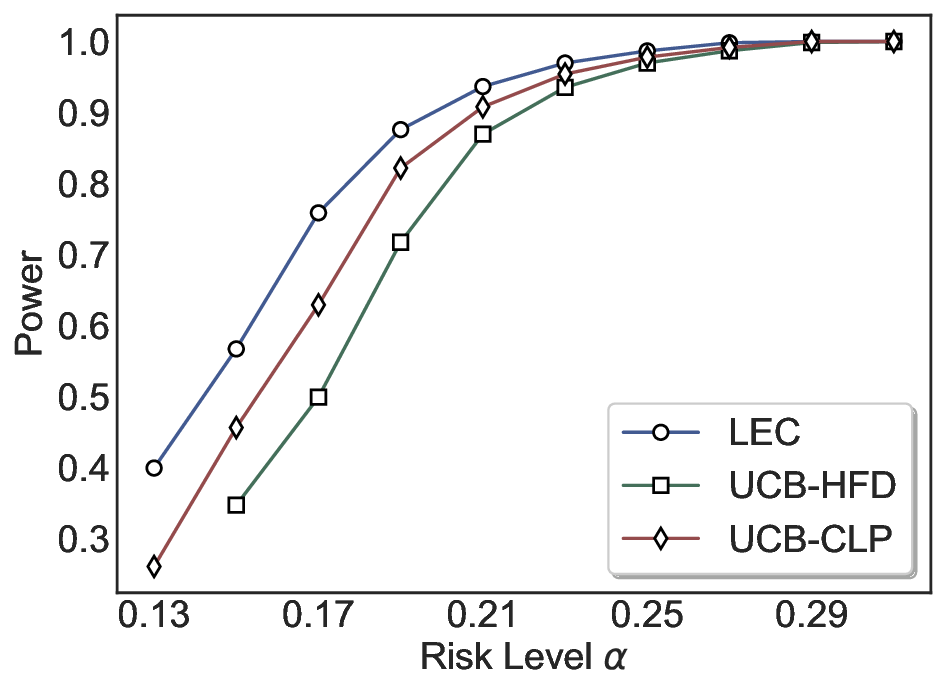
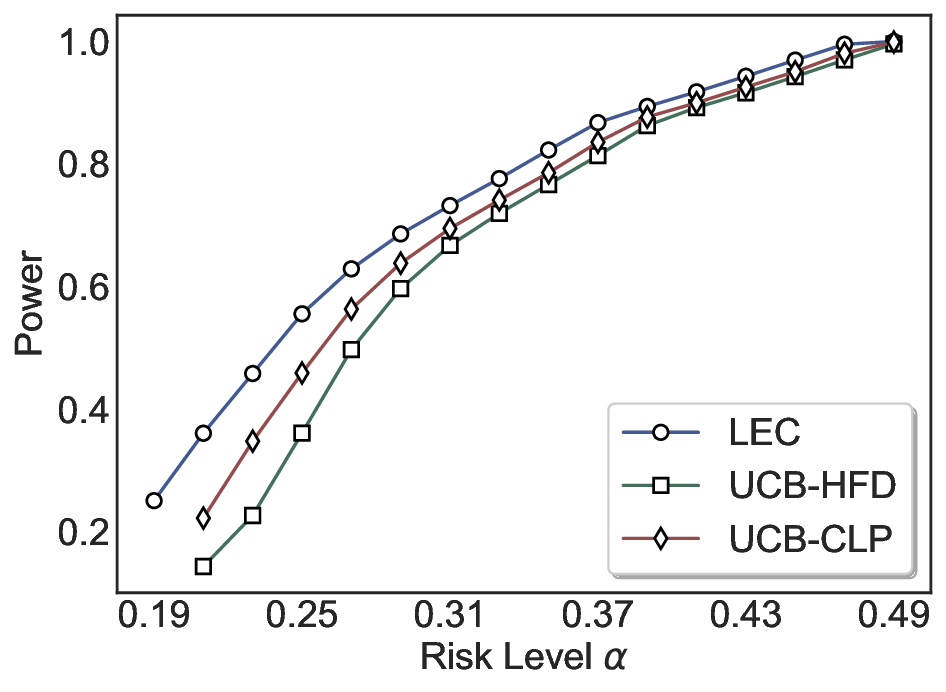
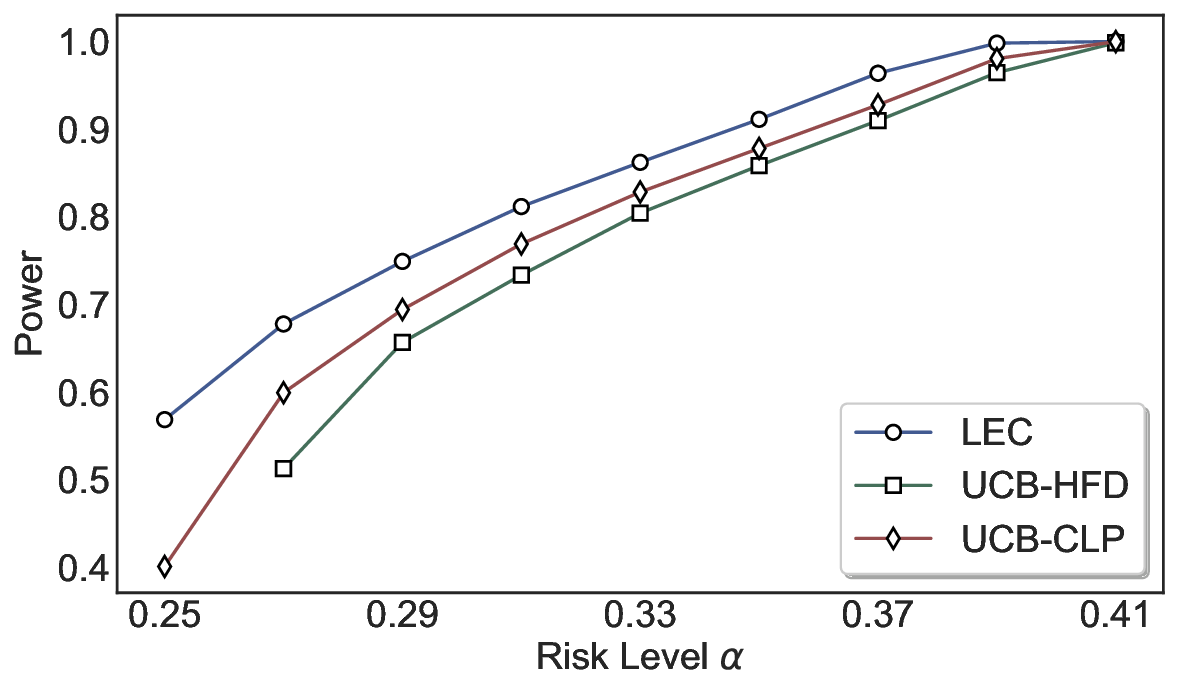
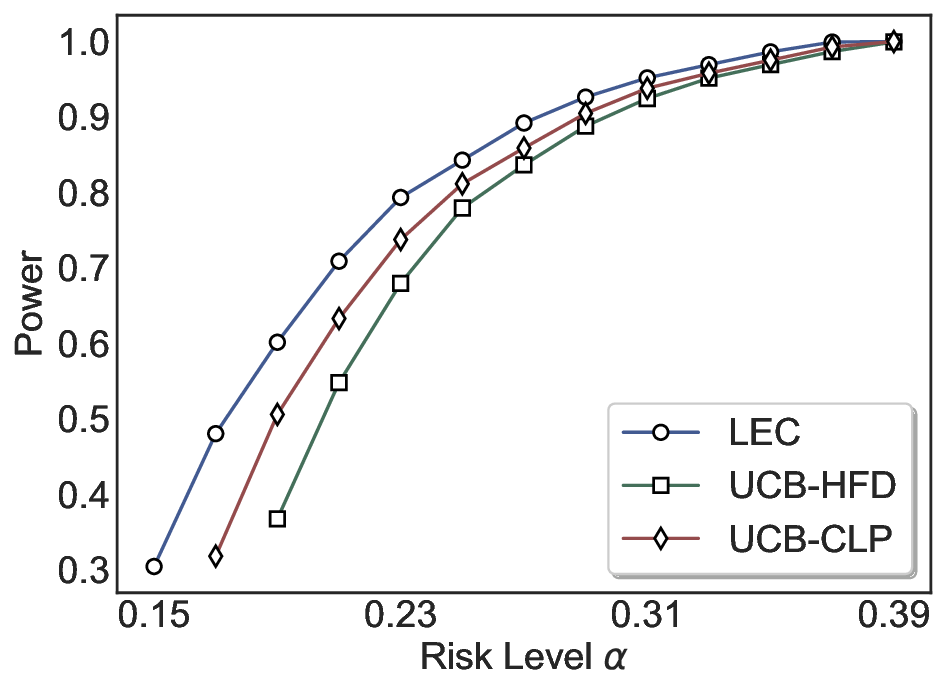
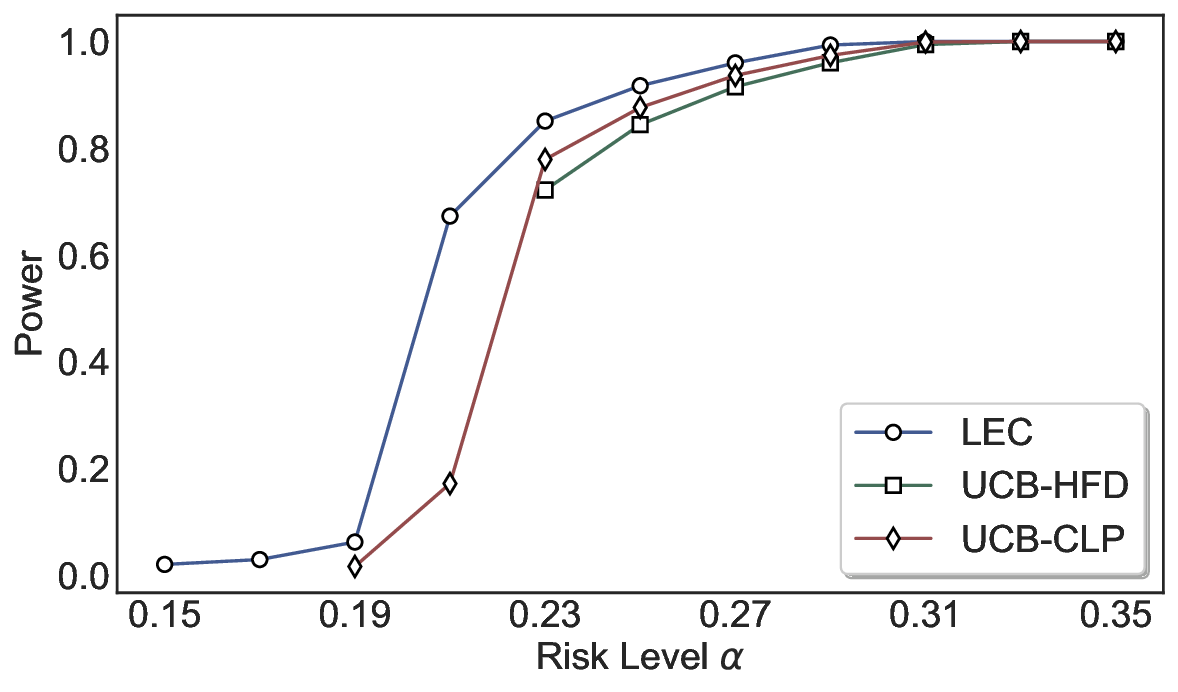
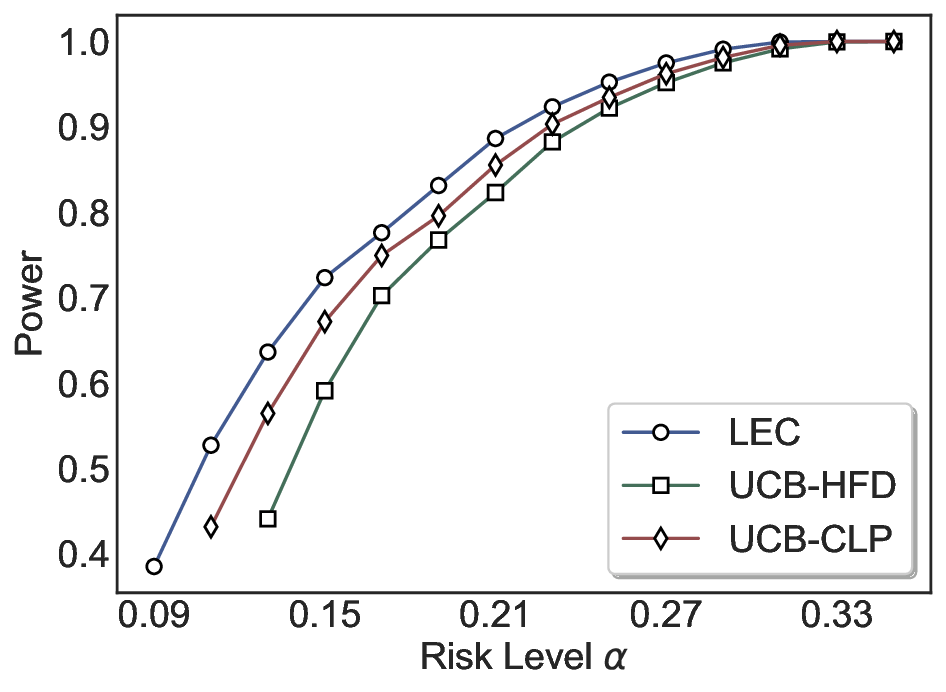
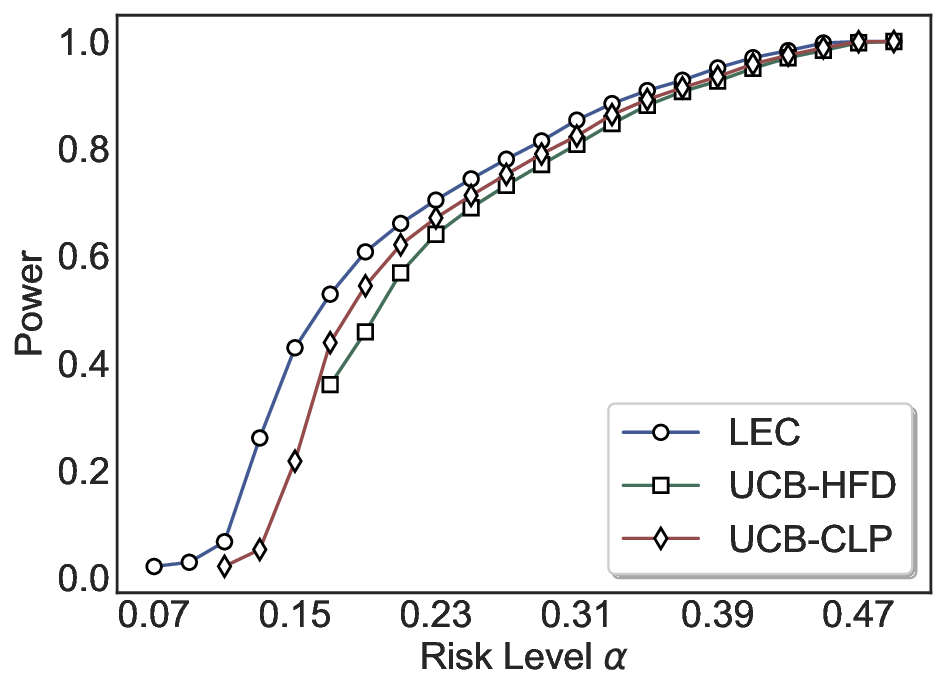
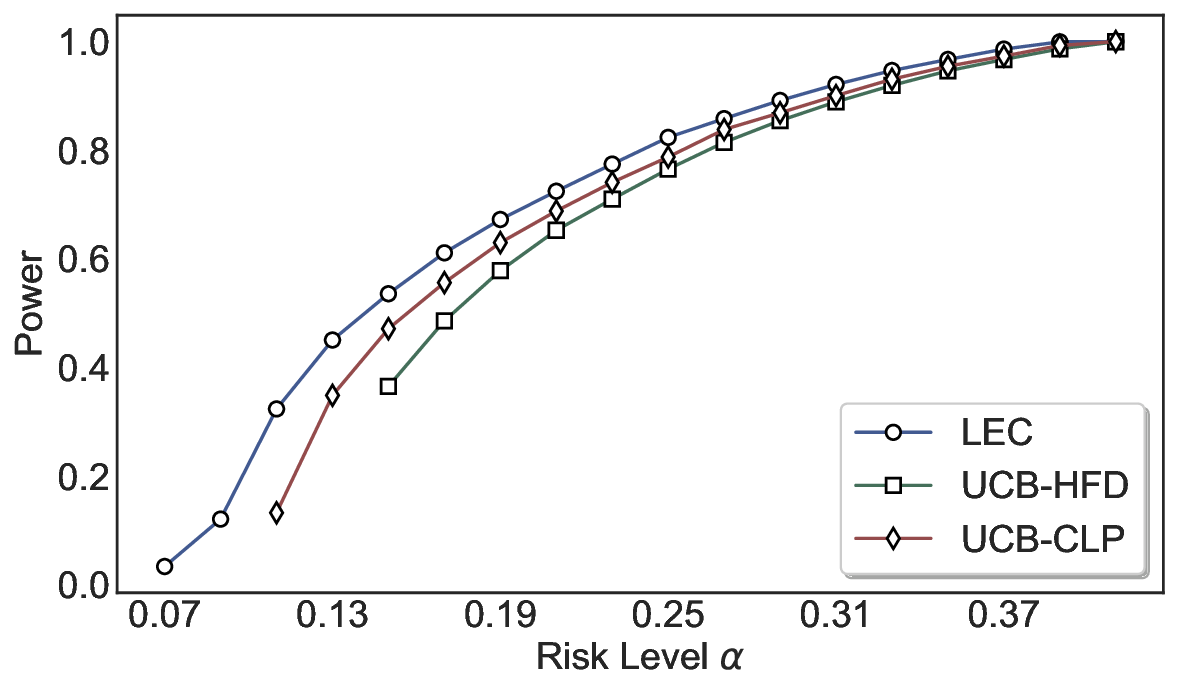
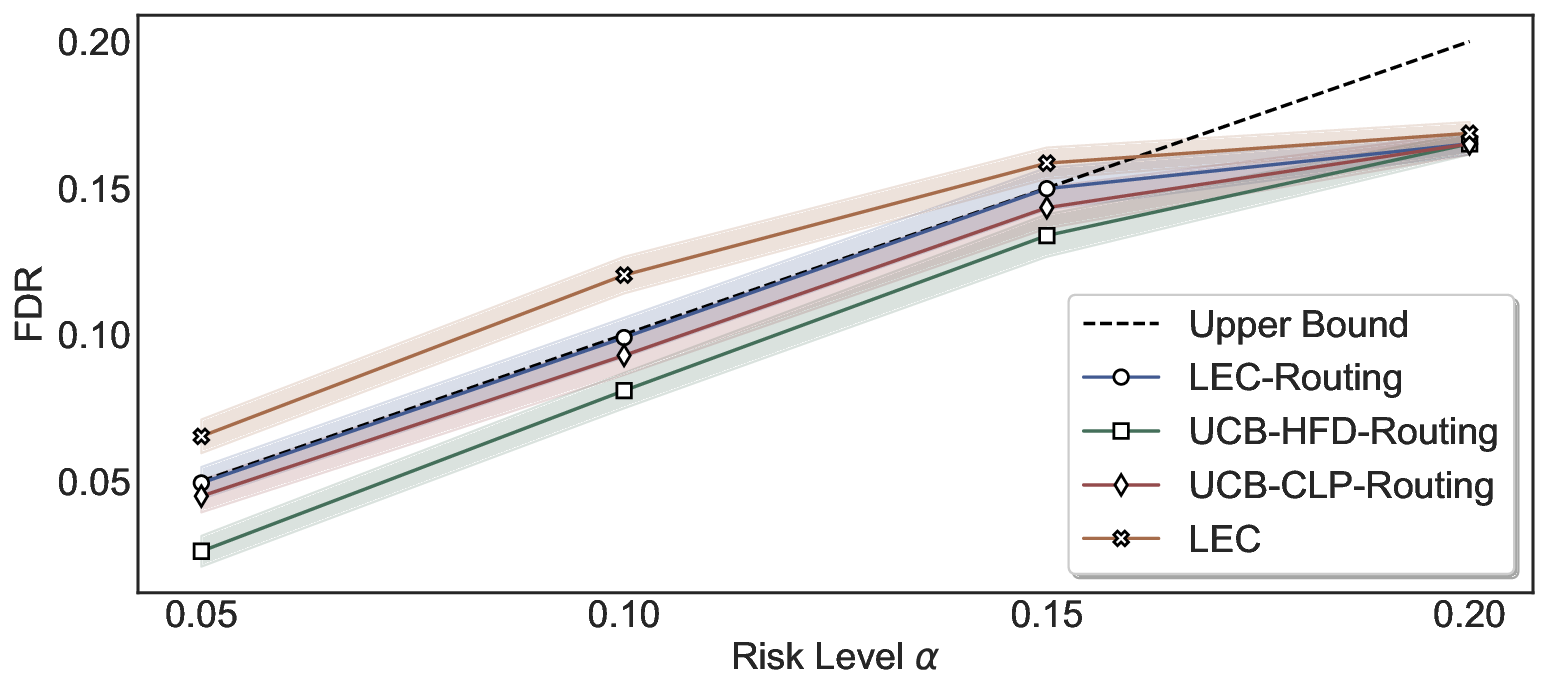
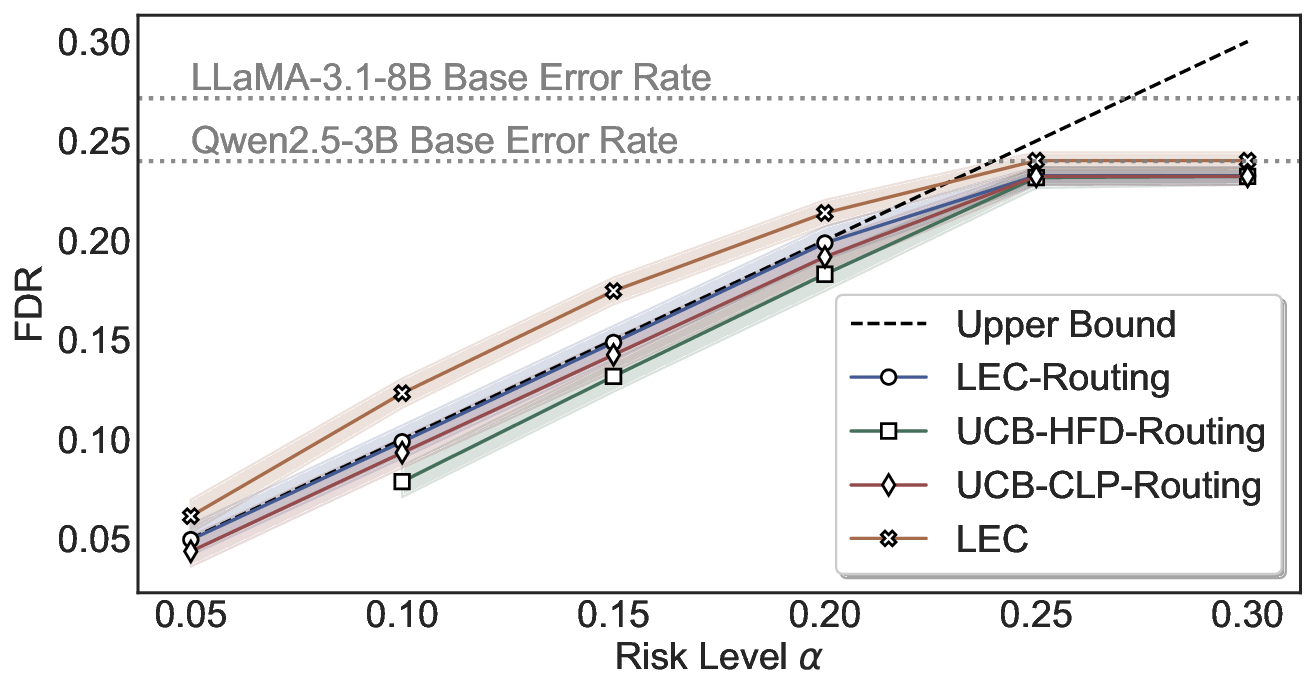
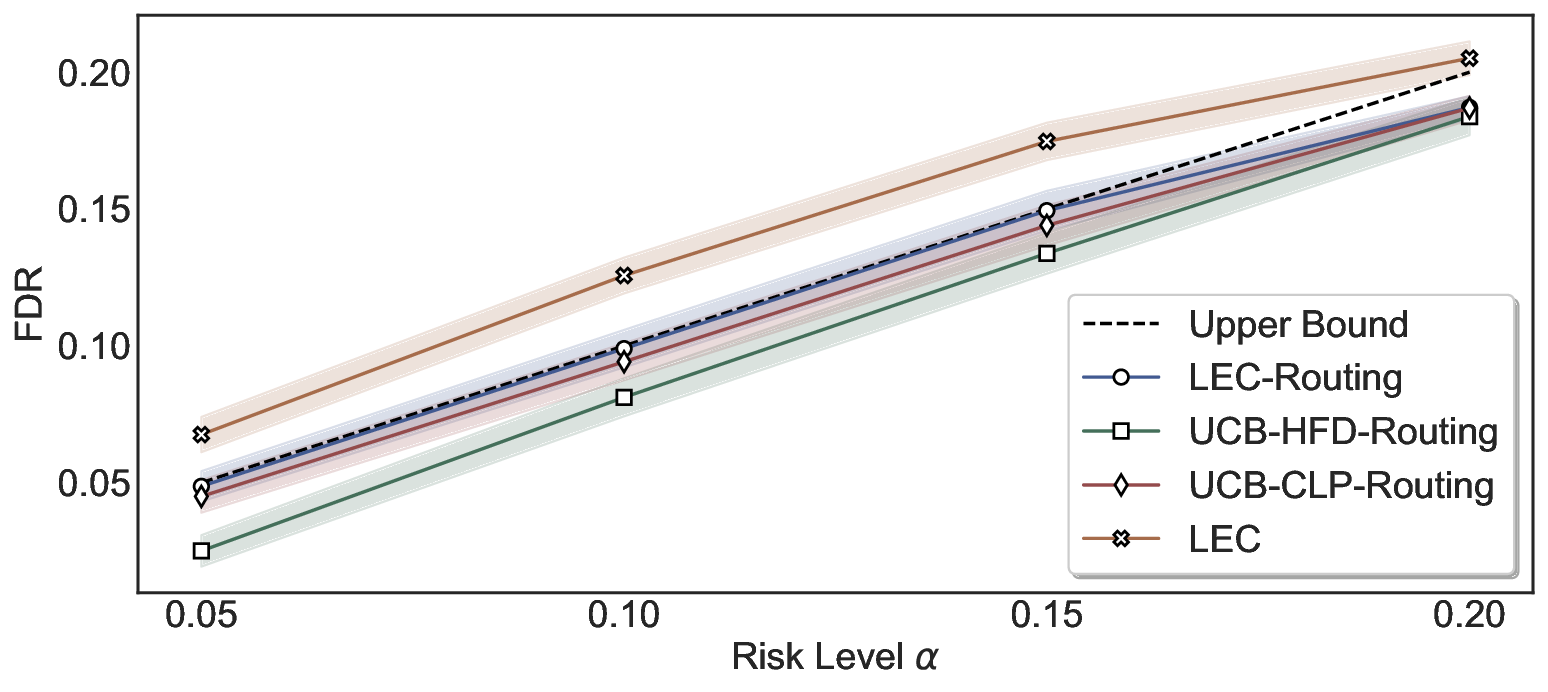
We evaluate LEC on four benchmarks across closed-ended and open-ended generation settings. In selective prediction of both single-model and two-model routing systems, LEC rigorously controls test-time FDR at various feasible risk levels. Compared to confidence interval-based methods (Wang et al., 2025c;Jung et al., 2025), LEC establishes a tighter risk bound while accepting more admissible samples (e.g., +9% on TriviaQA). Furthermore, across different UQ methods, admission functions, calibration-test split ratios, and sampling sizes under black-box scenarios, LEC maintains statistical rigor while consistently achieving higher power than the best baseline. These results highlight the practical effectiveness and generality of LEC, motivating its integration into real-world uncertainty-aware agentic systems.
SCP in LLMs. SCP provides statistical guarantees of coverage for correct answers (Campos et al., 2024b). It evaluates the nonconformity (or residual) between model prediction and ground-truth on a calibration set, and then computes a rigorously calibrated threshold, which is applied to construct prediction/conformal sets at test time. Under exchangeability (Angelopoulos et al., 2023), these sets contain admissible answers with at least a user-specified probability. However, previous research predominantly focuses on set-valued predictions (Quach et al., 2024;Kaur et al., 2024;Wang et al., 2024b;2025b;a), which are not inherently actionable due to unrel
…(Full text truncated)…
This content is AI-processed based on ArXiv data.