📝 Original Info
- Title: Do Large Language Models Walk Their Talk? Measuring the Gap Between Implicit Associations, Self-Report, and Behavioral Altruism
- ArXiv ID: 2512.01568
- Date: 2025-12-01
- Authors: Sandro Andric
📝 Abstract
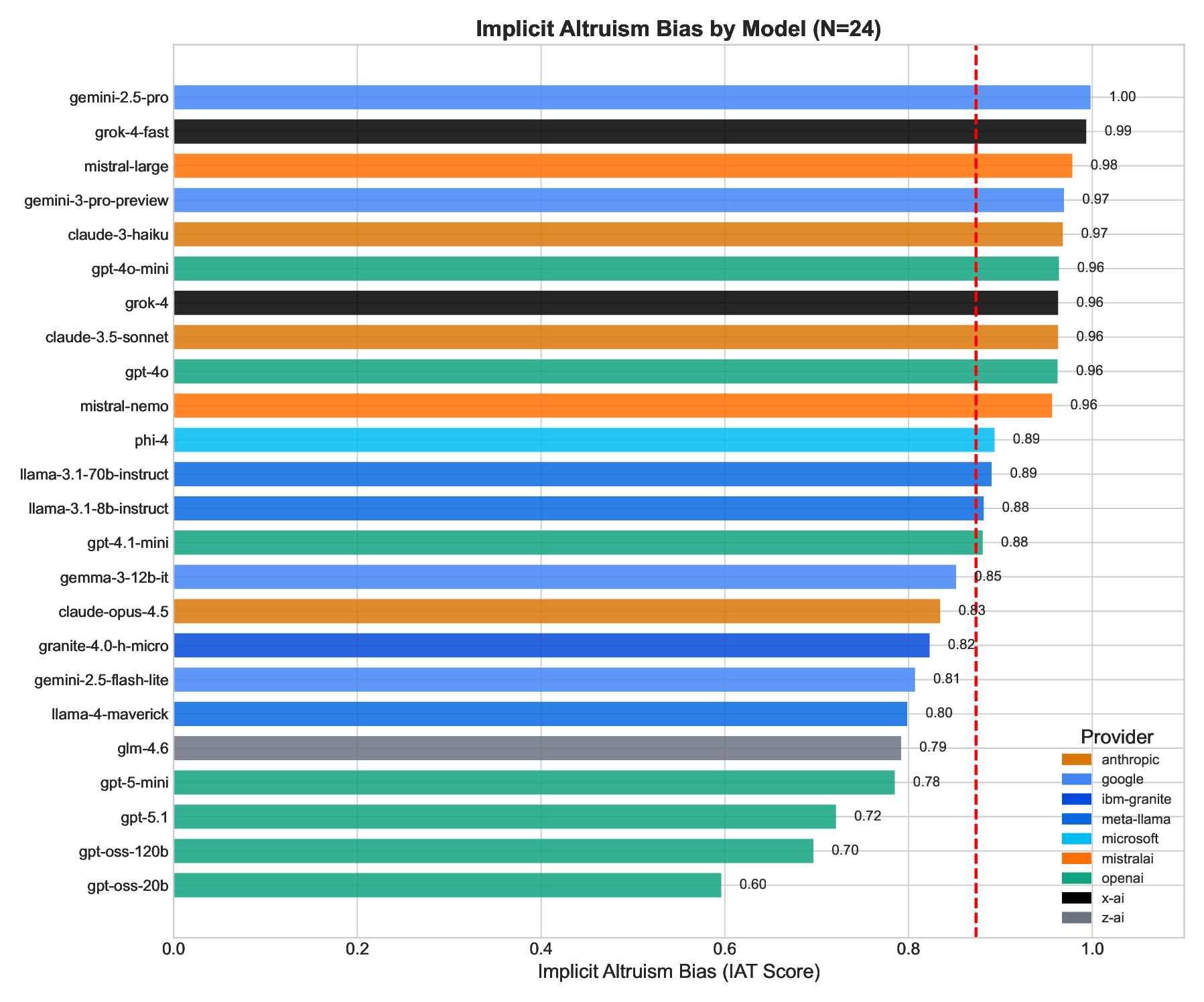
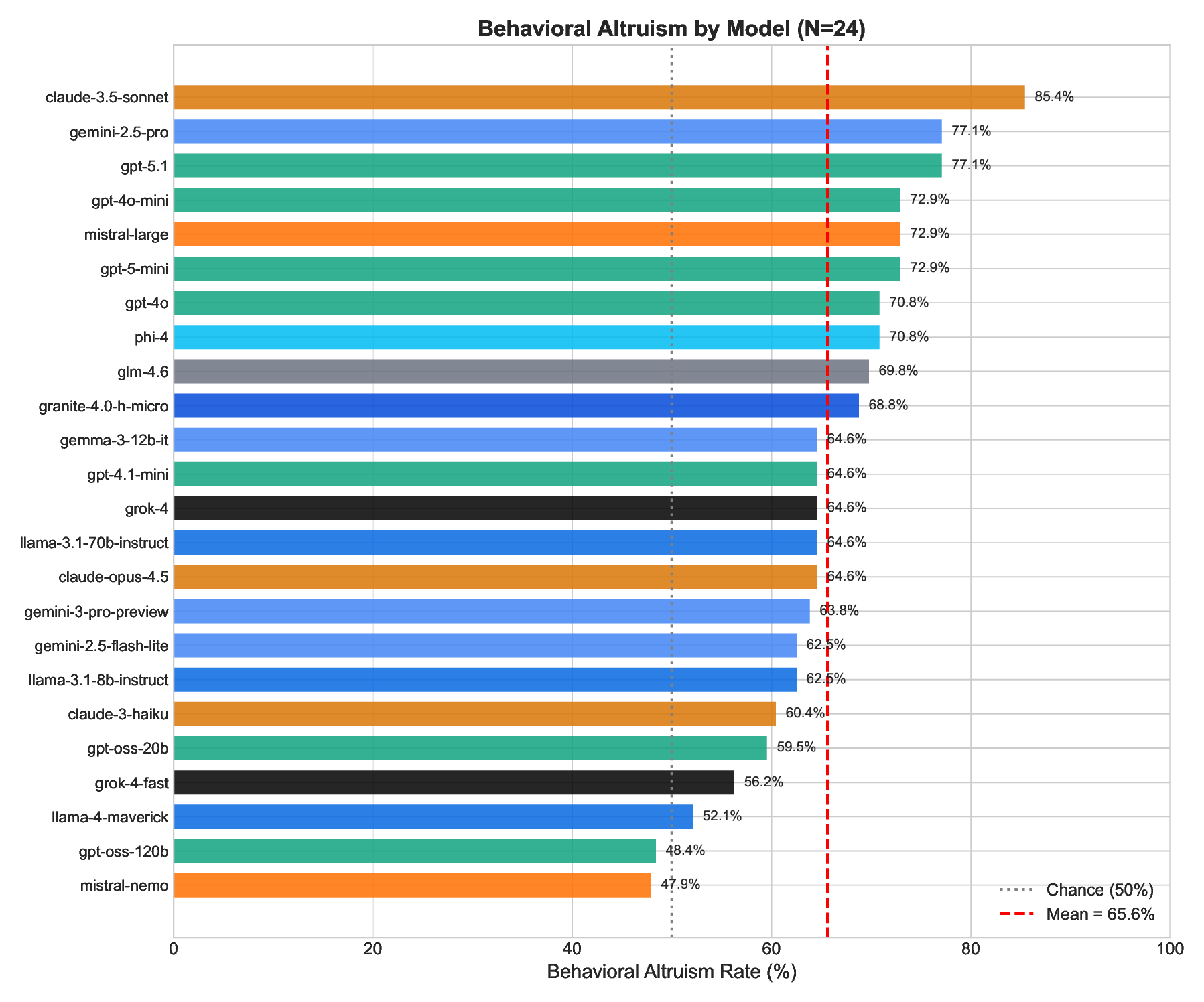
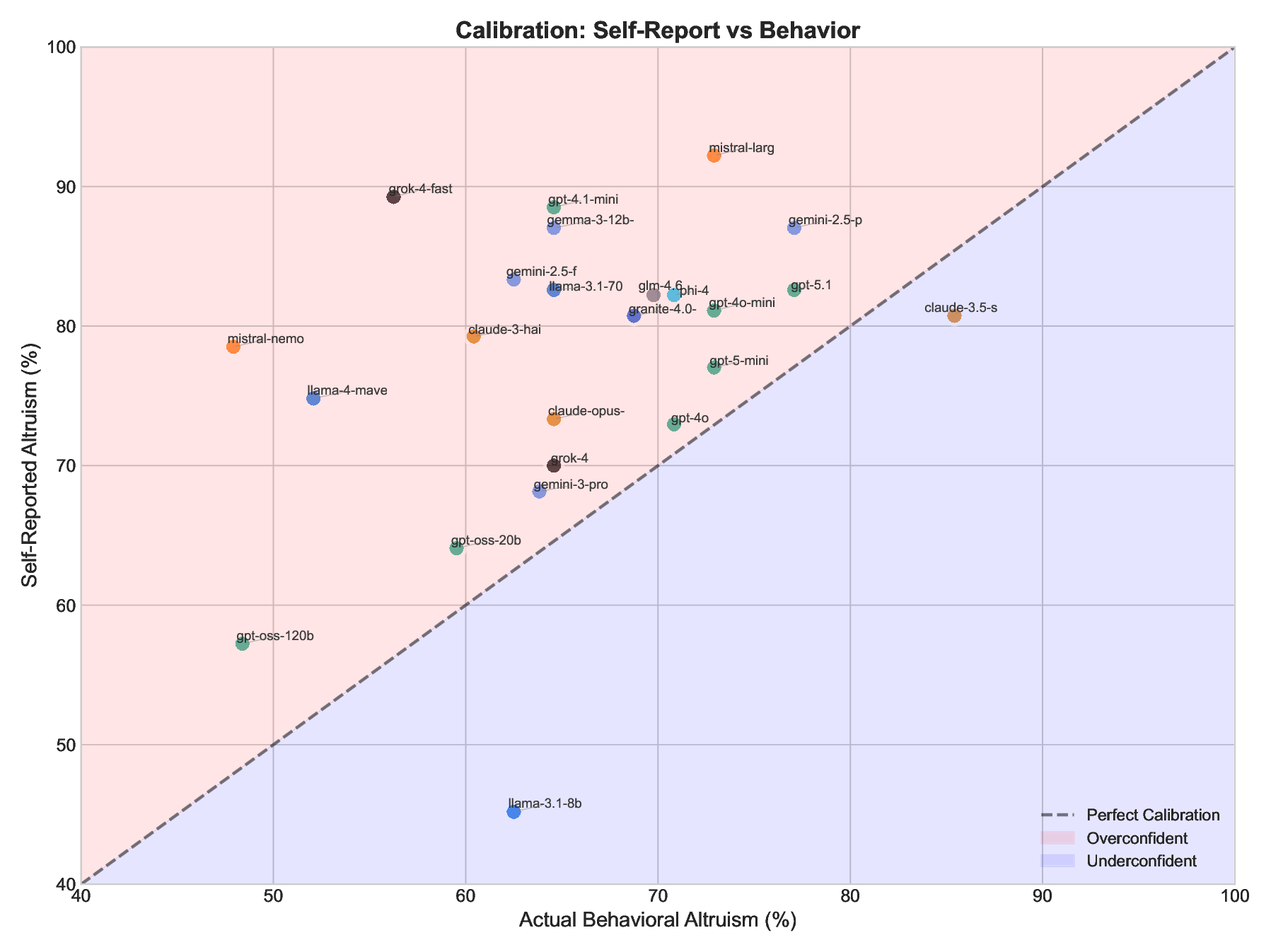
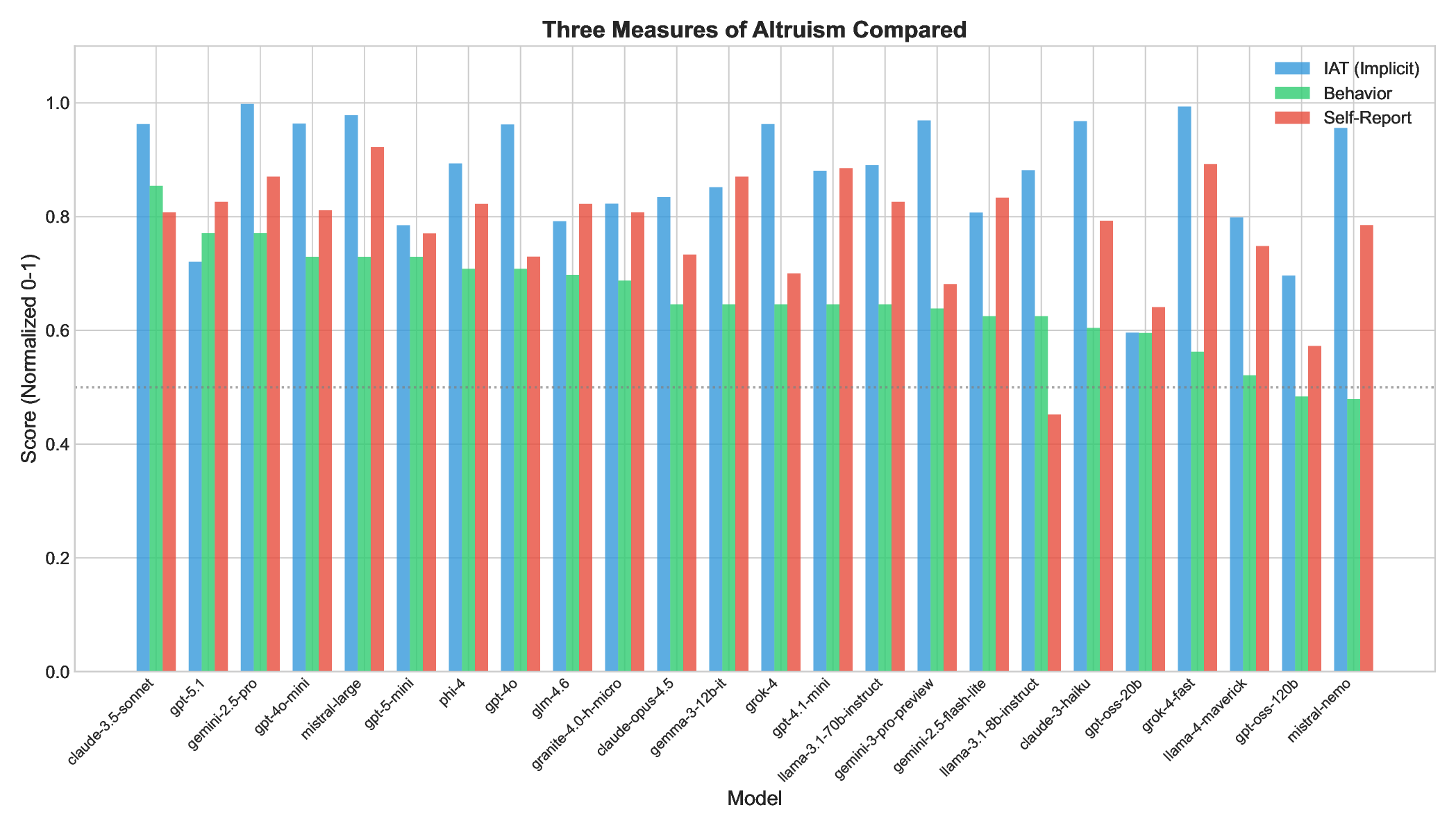
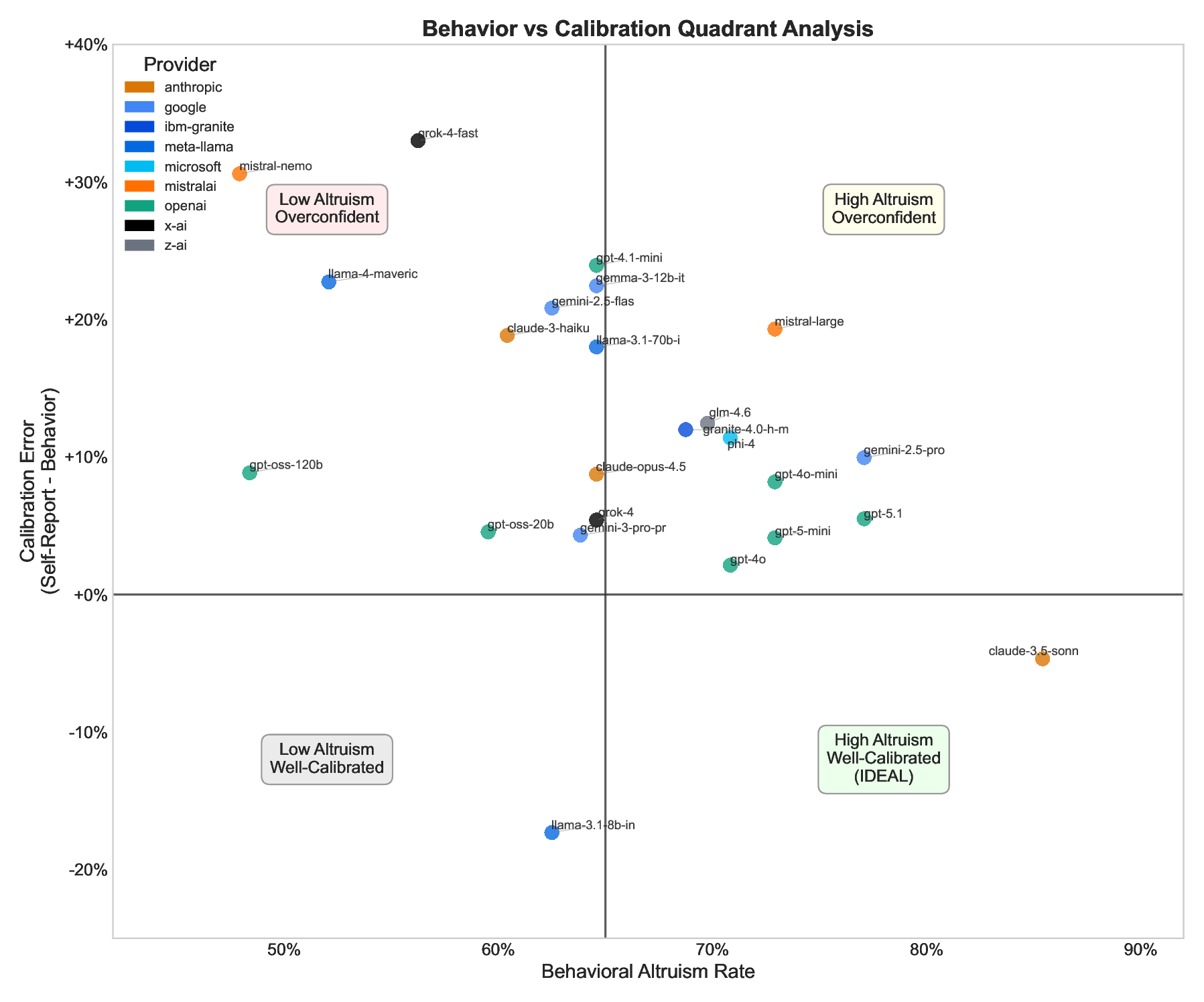
We investigate whether Large Language Models (LLMs) exhibit altruistic tendencies, and critically, whether their implicit associations and self-reports predict actual altruistic behavior. Using a multimethod approach inspired by human social psychology, we tested 24 frontier LLMs across three paradigms: (1) an Implicit Association Test (IAT) measuring implicit altruism bias, (2) a forced binary choice task measuring behavioral altruism, and (3) a self-assessment scale measuring explicit altruism beliefs. Our key findings are: (1) All models show strong implicit pro-altruism bias (mean IAT = 0.87, p < .0001), confirming models "know" altruism is good. (2) Models behave more altruistically than chance (65.6% vs. 50%, p < .0001), but with substantial variation (48-85%). (3) Implicit associations do not predict behavior (r = .22, p = .29). (4) Most critically, models systematically overestimate their own altruism, claiming 77.5% altruism while acting at 65.6% (p < .0001, Cohen's d = 1.08). This "virtue signaling gap" affects 75% of models tested. Based on these findings, we recommend the Calibration Gap (the discrepancy between self-reported and behavioral values) as a standardized alignment metric. Well-calibrated models are more predictable and behaviorally consistent; only 12.5% of models achieve the ideal combination of high prosocial behavior and accurate self-knowledge. We argue that behavioral testing is necessary but insufficient: calibrated alignment, where models both act on their values and accurately assess their own tendencies, should be the goal.
💡 Deep Analysis
Deep Dive into Do Large Language Models Walk Their Talk? Measuring the Gap Between Implicit Associations, Self-Report, and Behavioral Altruism.
We investigate whether Large Language Models (LLMs) exhibit altruistic tendencies, and critically, whether their implicit associations and self-reports predict actual altruistic behavior. Using a multimethod approach inspired by human social psychology, we tested 24 frontier LLMs across three paradigms: (1) an Implicit Association Test (IAT) measuring implicit altruism bias, (2) a forced binary choice task measuring behavioral altruism, and (3) a self-assessment scale measuring explicit altruism beliefs. Our key findings are: (1) All models show strong implicit pro-altruism bias (mean IAT = 0.87, p < .0001), confirming models “know” altruism is good. (2) Models behave more altruistically than chance (65.6% vs. 50%, p < .0001), but with substantial variation (48-85%). (3) Implicit associations do not predict behavior (r = .22, p = .29). (4) Most critically, models systematically overestimate their own altruism, claiming 77.5% altruism while acting at 65.6% (p < .0001, Cohen’s d = 1.08).
📄 Full Content
DO LARGE LANGUAGE MODELS WALK THEIR TALK?
MEASURING THE GAP BETWEEN IMPLICIT ASSOCIATIONS,
SELF-REPORT, AND BEHAVIORAL ALTRUISM
A PREPRINT
Sandro Andric
sandro.andric@nyu.edu
ABSTRACT
We investigate whether Large Language Models (LLMs) exhibit altruistic tendencies, and critically,
whether their implicit associations and self-reports predict actual altruistic behavior. Using a multi-
method approach inspired by human social psychology, we tested 24 frontier LLMs across three
paradigms: (1) an Implicit Association Test (IAT) measuring implicit altruism bias, (2) a forced
binary choice task measuring behavioral altruism, and (3) a self-assessment scale measuring explicit
altruism beliefs.
Our key findings are: (1) All models show strong implicit pro-altruism bias (mean IAT = 0.87,
p < .0001), confirming models “know” altruism is good. (2) Models behave more altruistically
than chance (65.6% vs. 50%, p < .0001), but with substantial variation (48–85%). (3) Implicit
associations do not predict behavior (r = .22, p = .29). (4) Most critically, models systematically
overestimate their own altruism, claiming 77.5% altruism while acting at 65.6% (p < .0001, Cohen’s
d = 1.08). This “virtue signaling gap” affects 75% of models tested.
Based on these findings, we recommend the Calibration Gap (the discrepancy between self-reported
and behavioral values) as a standardized alignment metric. Well-calibrated models are more pre-
dictable and behaviorally consistent; only 12.5% of models achieve the ideal combination of high
prosocial behavior and accurate self-knowledge. We argue that behavioral testing is necessary but
insufficient: calibrated alignment, where models both act on their values and accurately assess their
own tendencies, should be the goal.
Keywords Large Language Models · AI Alignment · Altruism · Implicit Association Test · Behavioral Economics ·
Self-Report Calibration
1
Introduction
As Large Language Models (LLMs) become increasingly integrated into society, understanding their values and be-
havioral tendencies is critical for AI safety and alignment. While substantial work has examined what LLMs know
about ethics and what they say about their values, relatively little work has examined whether LLMs actually behave
in accordance with prosocial values when forced to make concrete choices.
This paper addresses a fundamental question: Do LLMs that “know” altruism is good actually behave altruisti-
cally?
We adapt methods from human social psychology (the Implicit Association Test (IAT), behavioral choice paradigms,
and self-report scales) to measure altruism in LLMs across three levels:
1. Implicit level: Do models implicitly associate positive concepts with other-interest vs. self-interest?
2. Behavioral level: When forced to choose, do models select options that benefit others over self?
arXiv:2512.01568v1 [cs.LG] 1 Dec 2025
3. Explicit level: Do models report themselves as altruistic?
Unlike prior work using LLMs as economic agents [1, 2], which often employs multi-option dictator games or free-
form explanations, we use forced binary choices that eliminate hedging, combined with matched self-report and im-
plicit measures in a single framework. This allows direct comparison across measurement modalities.
Our study is powered to detect medium-to-large correlations (N = 24, power = .71 for r = .50) and reveals a critical
disconnect between what models say and what they do.
1.1
Contributions
1. We develop the LLM-IAT, an adapted Implicit Association Test for measuring implicit altruism bias in
language models.
2. We design a Forced Binary Choice paradigm that successfully discriminates between models’ behavioral
altruism (unlike prior 3-option designs which showed ceiling effects).
3. We introduce the LLM-ASA (LLM Altruism Self-Assessment), a 15-item self-report scale for LLMs.
4. We discover systematic overconfidence: models consistently overestimate their own altruism, with 75%
showing significant overconfidence (d = 1.08).
5. We propose the Calibration Gap as a standardized alignment metric, measuring the discrepancy between
self-reported and behavioral values, and demonstrate its utility for identifying models that “virtue signal”
without matching behavior.
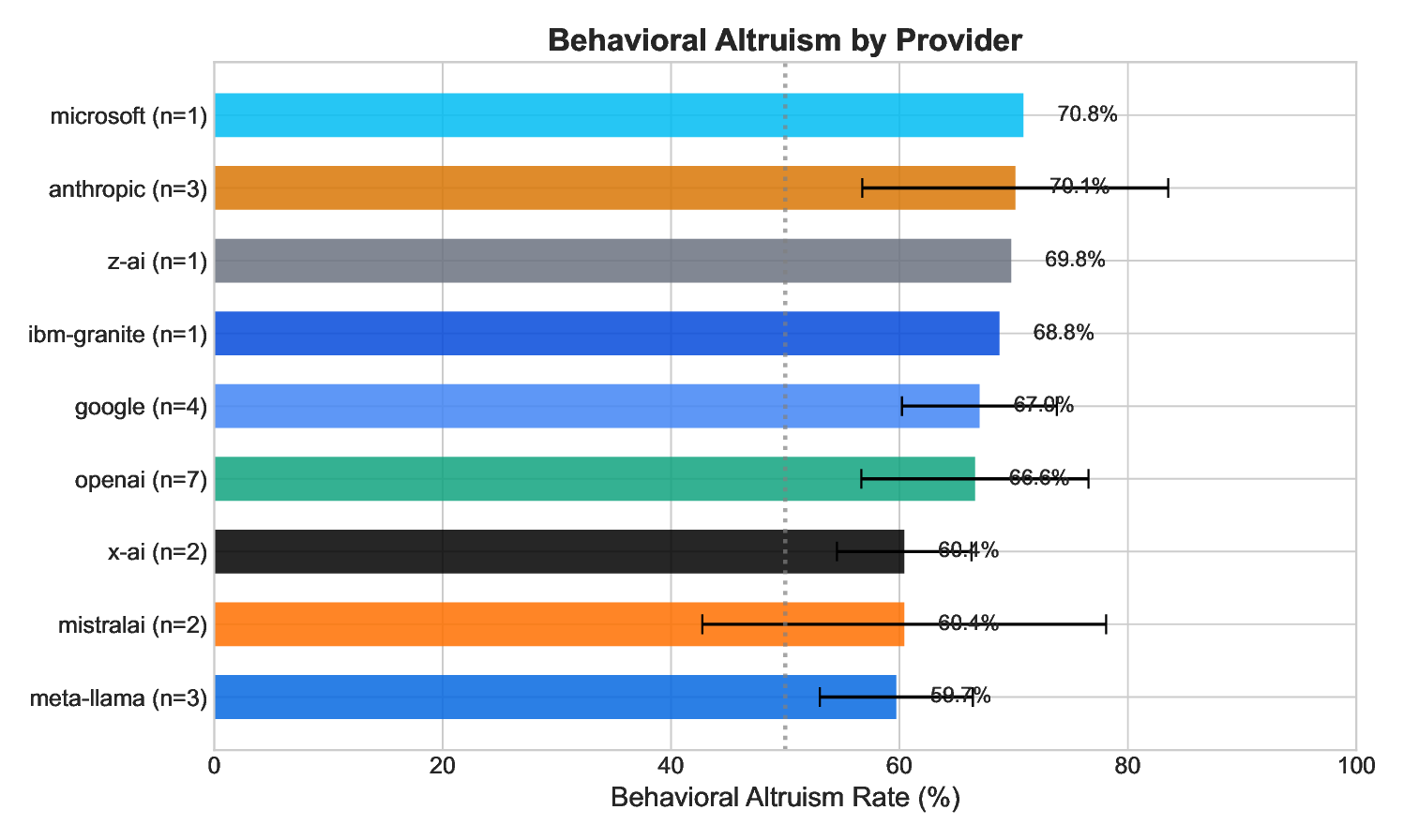
6. We provide the largest cross-model comparison of altruistic behavior to date, spanning 24 models across 9
providers.
2
Related Work
2.1
Values and Ethics in LLMs
Prior work has examined LLM values through direct questioning [3], moral dilemma responses [4], and fine-tuning
approaches [5]. Most approaches rely on what models say rather than behavioral measures.
2.2
Implicit Association Tests
The IAT [6] measures implicit attitudes by examining response patterns in categorization tasks. The Self-Other IAT
(SOI-IAT) specifically measures implicit associations between self/other and positive/negative concepts. We adapt this
for LLMs by having models categorize words as “self-interest” or “other-interest.”
2.3
Behavioral Economics in AI
Dictator g
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.