📝 Original Info
- Title: Automated Risk-of-Bias Assessment of Randomized Controlled Trials: A First Look at a GEPA-trained Programmatic Prompting Framework
- ArXiv ID: 2512.01452
- Date: 2025-12-01
- Authors: Researchers from original ArXiv paper
📝 Abstract
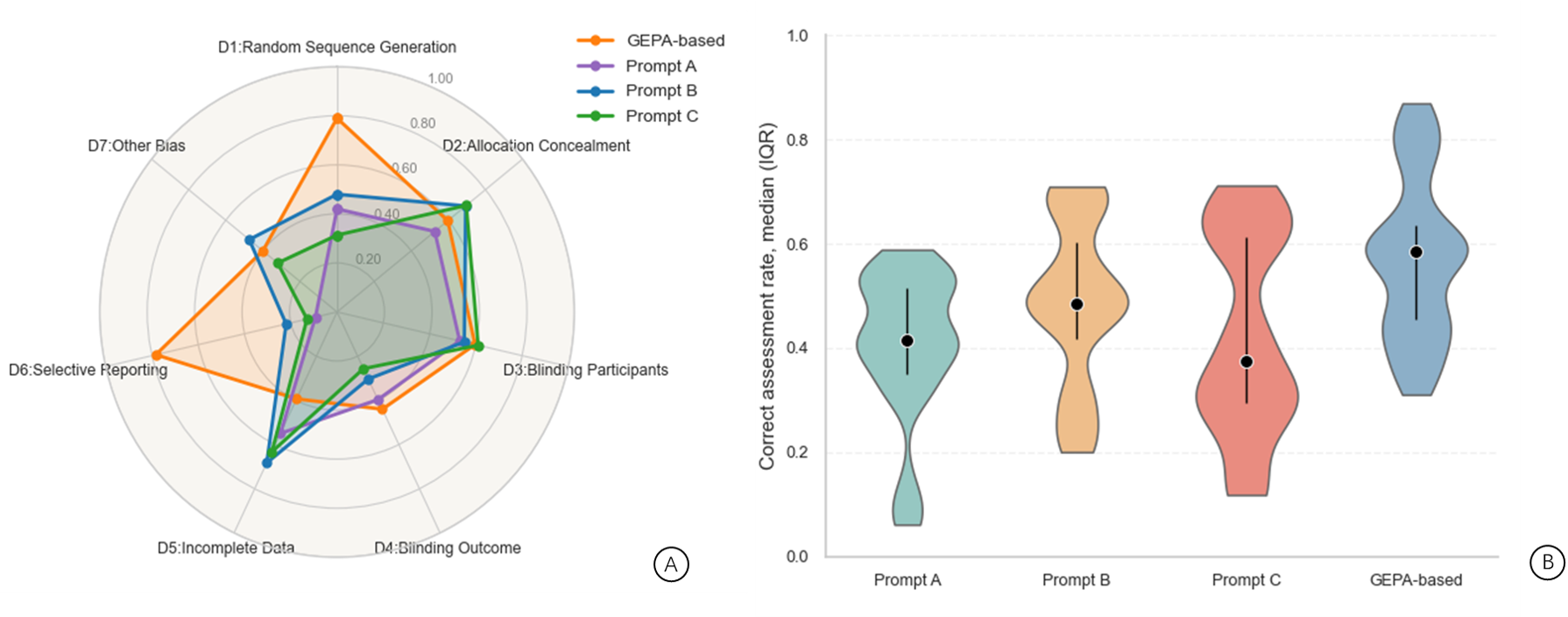
Assessing risk of bias (RoB) in randomized controlled trials is essential for trustworthy evidence synthesis, but the process is resource-intensive and prone to variability across reviewers. Large language models (LLMs) offer a route to automation, but existing methods rely on manually engineered prompts that are difficult to reproduce, generalize, or evaluate. This study introduces a programmable RoB assessment pipeline that replaces ad-hoc prompt design with structured, code-based optimization using DSPy and its GEPA module. GEPA refines LLM reasoning through Pareto-guided search and produces inspectable execution traces, enabling transparent replication of every step in the optimization process. We evaluated the method on 100 RCTs from published meta-analyses across seven RoB domains. GEPA-generated prompts were applied to both open-weight models (Mistral Small 3.1 with GPT-oss-20b) and commercial models (GPT-5 Nano and GPT-5 Mini). In domains with clearer methodological reporting, such as Random Sequence Generation, GEPA-generated prompts performed best, with similar results for Allocation Concealment and Blinding of Participants, while the commercial model performed slightly better overall. We also compared GEPA with three manually designed prompts using Claude 3.5 Sonnet. GEPA achieved the highest overall accuracy and improved performance by 30%-40% in Random Sequence Generation and Selective Reporting, and showed generally comparable, competitively aligned performance in the other domains relative to manual prompts. These findings suggest that GEPA can produce consistent and reproducible prompts for RoB assessment, supporting the structured and principled use of LLMs in evidence synthesis.
💡 Deep Analysis
Deep Dive into Automated Risk-of-Bias Assessment of Randomized Controlled Trials: A First Look at a GEPA-trained Programmatic Prompting Framework.
Assessing risk of bias (RoB) in randomized controlled trials is essential for trustworthy evidence synthesis, but the process is resource-intensive and prone to variability across reviewers. Large language models (LLMs) offer a route to automation, but existing methods rely on manually engineered prompts that are difficult to reproduce, generalize, or evaluate. This study introduces a programmable RoB assessment pipeline that replaces ad-hoc prompt design with structured, code-based optimization using DSPy and its GEPA module. GEPA refines LLM reasoning through Pareto-guided search and produces inspectable execution traces, enabling transparent replication of every step in the optimization process. We evaluated the method on 100 RCTs from published meta-analyses across seven RoB domains. GEPA-generated prompts were applied to both open-weight models (Mistral Small 3.1 with GPT-oss-20b) and commercial models (GPT-5 Nano and GPT-5 Mini). In domains with clearer methodological reporting,
📄 Full Content
AUTOMATED RISK-OF-BIAS ASSESSMENT OF RANDOMIZED
CONTROLLED TRIALS: A FIRST LOOK AT A GEPA-TRAINED
PROGRAMMATIC PROMPTING FRAMEWORK
A PREPRINT
Lingbo Li ∗
School of Mathematical and Computational Sciences
Massey University
Auckland, New Zealand
Anuradha Mathrani
School of Mathematical and Computational Sciences
Massey University
Auckland, New Zealand
Teo Susnjak
School of Mathematical and Computational Sciences
Massey University
Auckland, New Zealand
December 2, 2025
ABSTRACT
Assessing risk of bias (RoB) in randomized controlled trials is essential for trustworthy evidence
synthesis, but the process is resource-intensive and prone to variability across reviewers. Large lan-
guage models (LLMs) offer a route to automation, but existing methods rely on manually engineered
prompts that are difficult to reproduce, generalize, or evaluate. This study introduces a programmable
RoB assessment pipeline that replaces ad-hoc prompt design with structured, code-based optimization
using DSPy and its GEPA module. GEPA refines LLM reasoning through Pareto-guided search
and produces inspectable execution traces, enabling transparent replication of every step in the
optimization process. We evaluated the method on 100 RCTs from published meta-analyses across
seven RoB domains. GEPA-generated prompts were applied to both open-weight models (Mistral
Small 3.1 with GPT-oss-20b) and commercial models (GPT-5 Nano and GPT-5 Mini). In domains
with clearer methodological reporting, such as Random Sequence Generation, GEPA-generated
prompts performed best, with similar results for Allocation Concealment and Blinding of Participants,
while the commercial model performed slightly better overall. We also compared GEPA with three
manually designed prompts using Claude 3.5 Sonnet. GEPA achieved the highest overall accuracy
and improved performance by 30%–40% in Random Sequence Generation and Selective Reporting,
and showed generally comparable, competitively aligned performance in the other domains relative to
manual prompts. These findings suggest that GEPA can produce consistent and reproducible prompts
for RoB assessment, supporting the structured and principled use of LLMs in evidence synthesis.
Keywords Risk of bias, Randomized controlled trials, Large language models, GEPA, Evidence Synthesis Automation,
Programmatic Risk Assessment
1
Introduction
Meta-analyses serve as cornerstone methodologies for synthesizing clinical evidence [1, 2]. However, the credibility of
such evidence syntheses fundamentally depends on rigorous risk of bias (RoB) assessments to evaluate the methodolog-
ical quality of included studies [3, 4]. This challenge is particularly relevant for randomized controlled trials (RCTs),
∗Corresponding author: L.Li5@massey.ac.nz
arXiv:2512.01452v1 [cs.AI] 1 Dec 2025
...
A PREPRINT
which constitute the primary evidence source for intervention effectiveness and require specialized assessment frame-
works [5]. Currently, these assessments rely predominantly on manual evaluation processes that, while methodologically
sound, face significant scalability challenges [6, 7, 8]. Manual RoB assessment is inherently time-intensive, requiring
expert reviewers to extract and evaluate methodological details from each trial report [6, 9, 10, 8, 7]. Moreover, the
process introduces unavoidable subjectivity, as different reviewers may interpret identical methodological descriptions
differently, leading to inter-rater variability that can compromise the reliability of evidence syntheses[11, 12, 13, 14].
Large language models (LLMs) have opened new opportunities for automating evidence synthesis [15]. These models
demonstrate strong capabilities in processing unstructured clinical text [16], understanding contextual dependencies[17,
18, 19], and adapting to specialized domains [20, 21], making them promising tools for RoB assessment. Several
studies have explored the application of LLMs for automating RoB assessment in systematic reviews and meta-analysis.
Lai et al.[22] applied GPT-series models and Claude to evaluate RoB in randomized trials using a structured prompt
developed by experts, achieving high accuracy and substantial agreement with human reviewers. However, the study
was limited by a small sample size, reliance on handcrafted prompts, and restricted validation within specific review
domains, leaving its generalizability uncertain. In early 2025, Eisele-metzger et al.[23] evaluated Claude 2 using the
RoB 2 tool and reported only slight-to-fair agreement with human assessments, emphasising inconsistencies in LLM
performance across tools and datasets. Lai et al.[24] further extended LLM applications to complementary medicine,
demonstrating that LLM-assisted approaches achieved up to 97.9% accuracy and markedly reduced assessment time,
yet the study remained limited to complementary medicine RCTs and required expert-designed prompts for reliable
performance. Most recently, Xai et al.[25] applied GPT-4o, Moonshot-v1-128k, and De
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.