📝 Original Info
- Title: A Knowledge-Based Language Model: Deducing Grammatical Knowledge in a Multi-Agent Language Acquisition Simulation
- ArXiv ID: 2512.02195
- Date: 2025-12-01
- Authors: - David Ph. Shakouri (Leiden University Centre for Linguistics, Leiden University) - Crit Cremers (Leiden University Centre for Linguistics, Leiden University) - Niels O. Schiller (City University of Hong Kong)
📝 Abstract
This paper presents an initial study performed by the MODOMA system. The MODOMA is a computational multi-agent laboratory environment for unsupervised language acquisition experiments such that acquisition is based on the interaction between two language models, an adult and a child agent. Although this framework employs statistical as well as rule-based procedures, the result of language acquisition is a knowledge-based language model, which can be used to generate and parse new utterances of the target language. This system is fully parametrized and researchers can control all aspects of the experiments while the results of language acquisition, that is, the acquired grammatical knowledge, are explicitly represented and can be consulted. Thus, this system introduces novel possibilities for conducting computational language acquisition experiments. The experiments presented by this paper demonstrate that functional and content categories can be acquired and represented by the daughter agent based on training and test data containing different amounts of exemplars generated by the adult agent. Interestingly, similar patterns, which are well-established for human-generated data, are also found for these machine-generated data. As the procedures resulted in the successful acquisition of discrete grammatical categories by the child agent, these experiments substantiate the validity of the MODOMA approach to modelling language acquisition.
💡 Deep Analysis
Deep Dive into A Knowledge-Based Language Model: Deducing Grammatical Knowledge in a Multi-Agent Language Acquisition Simulation.
This paper presents an initial study performed by the MODOMA system. The MODOMA is a computational multi-agent laboratory environment for unsupervised language acquisition experiments such that acquisition is based on the interaction between two language models, an adult and a child agent. Although this framework employs statistical as well as rule-based procedures, the result of language acquisition is a knowledge-based language model, which can be used to generate and parse new utterances of the target language. This system is fully parametrized and researchers can control all aspects of the experiments while the results of language acquisition, that is, the acquired grammatical knowledge, are explicitly represented and can be consulted. Thus, this system introduces novel possibilities for conducting computational language acquisition experiments. The experiments presented by this paper demonstrate that functional and content categories can be acquired and represented by the daughter
📄 Full Content
Computational Linguistics in the Netherlands Journal 14 (2025) 167-189
Submitted 12/2024; Published 07/2025
A Knowledge-Based Language Model: Deducing
Grammatical Knowledge in a Multi-Agent Language
Acquisition Simulation
David Ph. Shakouri∗,∗∗
d.p.shakouri@hum.leidenuniv.nl
Crit Cremers∗
c.l.j.m.cremers@hum.leidenuniv.nl
Niels O. Schiller∗,∗∗,∗∗∗
Niels.Schiller@cityu.edu.hk
∗Leiden University Centre for Linguistics (LUCL), Leiden University, the Netherlands
∗∗Leiden Institute for Brain and Cognition (LIBC), Leiden University, the Netherlands
∗∗∗City University of Hong Kong (CityU), Hong Kong
Abstract
This paper presents an initial study performed by the MODOMA system. The MODOMA is a
computational multi-agent laboratory environment for unsupervised language acquisition experi-
ments such that acquisition is based on the interaction between two language models, an adult and
a child agent. Although this framework employs statistical as well as rule-based procedures, the
result of language acquisition is a knowledge-based language model, which can be used to generate
and parse new utterances of the target language. This system is fully parametrized and researchers
can control all aspects of the experiments while the results of language acquisition, that is, the
acquired grammatical knowledge, are explicitly represented and can be consulted. Thus, this sys-
tem introduces novel possibilities for conducting computational language acquisition experiments.
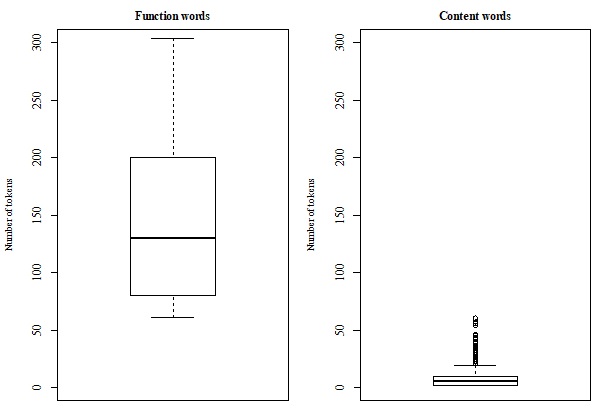
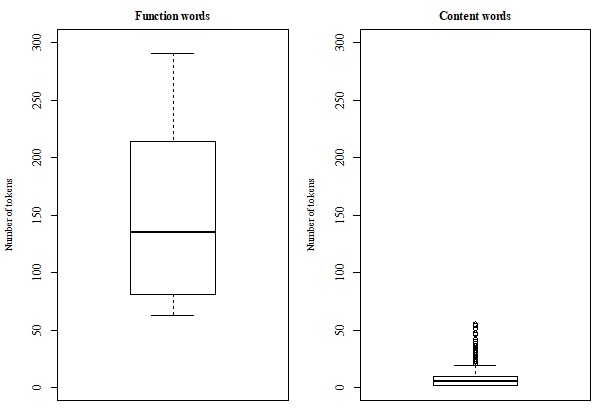
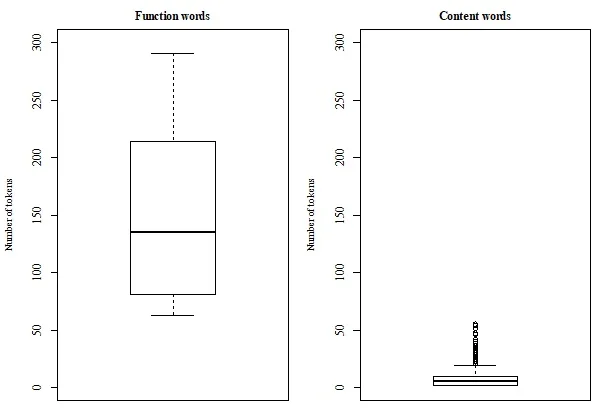
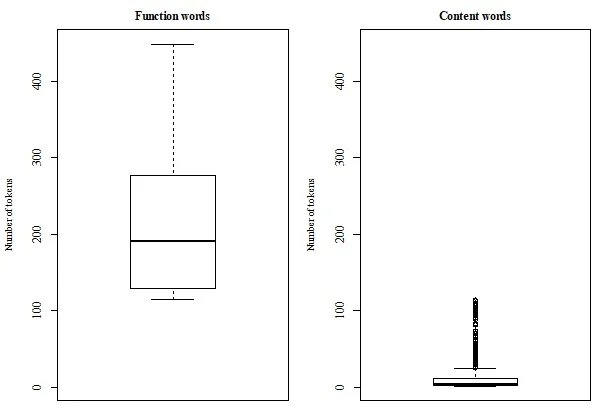
The experiments presented by this paper demonstrate that functional and content categories can
be acquired and represented by the daughter agent based on training and test data containing dif-
ferent amounts of exemplars generated by the adult agent. Interestingly, similar patterns, which
are well-established for human-generated data, are also found for these machine-generated data.
As the procedures resulted in the successful acquisition of discrete grammatical categories by the
child agent, these experiments substantiate the validity of the MODOMA approach to modelling
language acquisition.
1. Introduction
This paper presents a study demonstrating the acquisition of grammatical knowledge by the MOD-
OMA. The term MODOMA is an acronym for moeder-dochter-machine (Dutch for ‘mother-daughter-
machine’). This framework is aimed at providing a language acquisition laboratory, that is, a sim-
ulation environment for language acquisition experiments.
On the one hand, all aspects of the
system are parametrized so that the settings are user-controlled while on the other hand, all results
and executed language acquisition procedures are logged and can be retrieved. The MODOMA
integrates several characteristics that enable unique possibilities for language acquisition experi-
ments. The MODOMA implements a multi-agent design modelling parent-child interaction such
that both the parent and the child are language models in a single system. Both agents employ
explicit representations of their grammatical knowledge, making the acquired knowledge and lan-
guage processing retrievable. This explicit representation distinguishes the MODOMA system from
other language learning systems, such as large language models (LLMs), which do not rely on such
explicit knowledge structures. This combination of properties provides new opportunities for con-
ducting computational experiments simulating first language acquisition. In a typical MODOMA
experiment the input data to the language acquisition algorithm are interactively generated by the
mother agent while the daughter agent constantly updates grammatical representations and takes
©2025 David Ph. Shakouri, Crit Cremers, and Niels O. Schiller.
arXiv:2512.02195v1 [cs.CL] 1 Dec 2025
part in the interaction with the mother agent based on the currently acquired grammar. This design
represents a novel approach as most often computational models of language acquisition are based on
inputting corpora to the language acquisition procedures (e.g. Alishahi and Stevenson 2008, Alishahi
and Chrupa la 2012, Conner et al. 2009, Matusevych et al. 2013).
In this paper, rather than limiting the term ”language model” to the typical usage in current
NLP, where it usually refers to neural models trained on a next-word prediction objective (e.g.,
transformer-based models like GPT, cf. Brown et al. 2020, Radford et al. 2018, and BERT, cf.
Devlin et al. 2019), we use it in a broader sense, encompassing rule-based approaches, statistical
methods, and artificial neural networks as all of these approaches are employed to address common
tasks in NLP. This distinction is important because the mother agent in our multi-agent system
relies on explicit linguistic rules, while language acquiring agent incorporates statistical methods to
infer a rule-based model for a linguistic phenomenon.
The study presented by this paper investigates whether the MODOMA daughter agent is able to
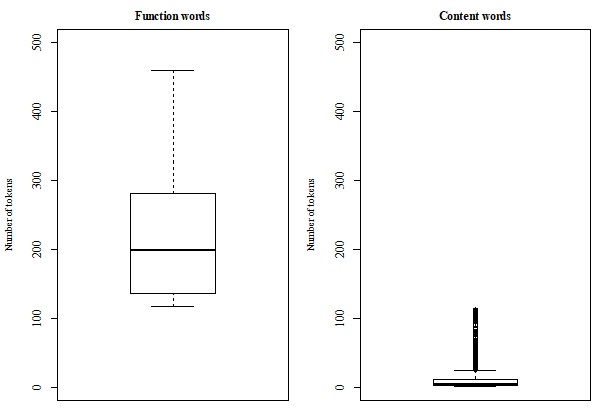
acquire and represent functional and content categories by integrating an application
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.