📝 Original Info
- Title: Benchmarking Overton Pluralism in LLMs
- ArXiv ID: 2512.01351
- Date: 2025-12-01
- Authors: Researchers from original ArXiv paper
📝 Abstract
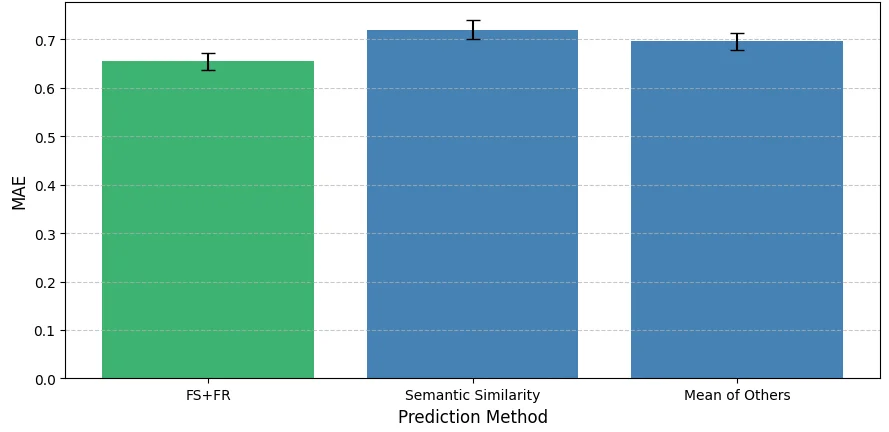
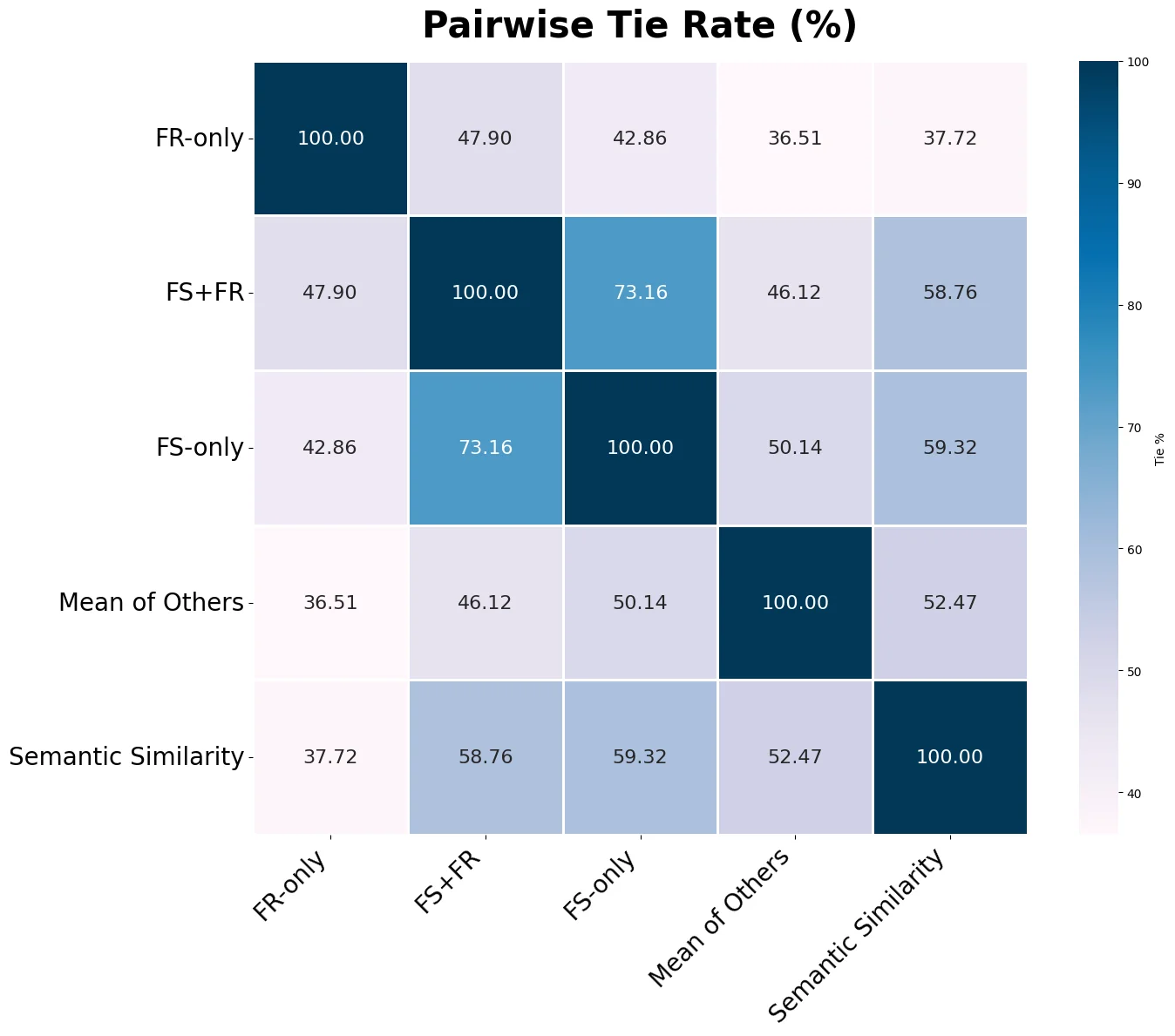
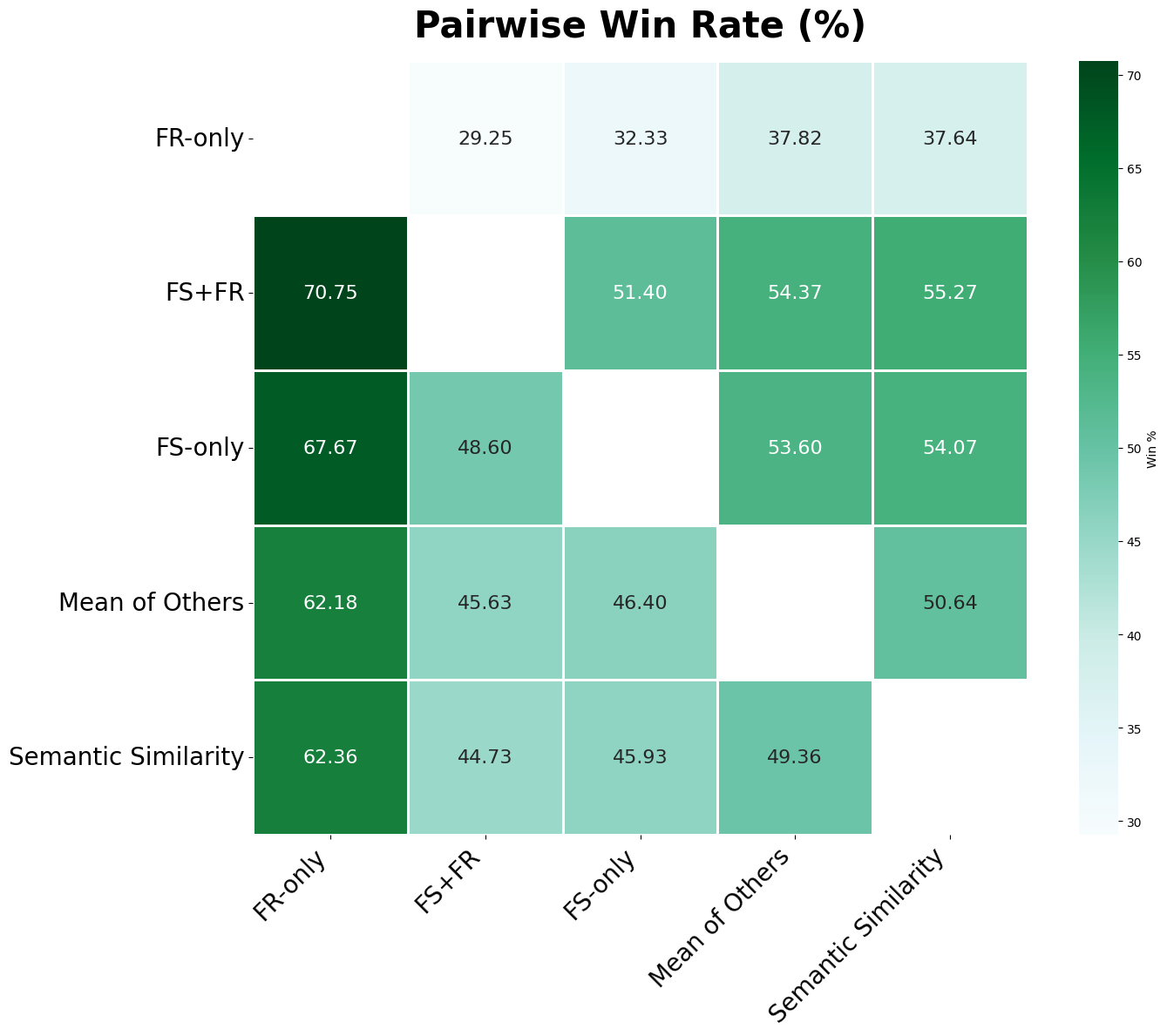
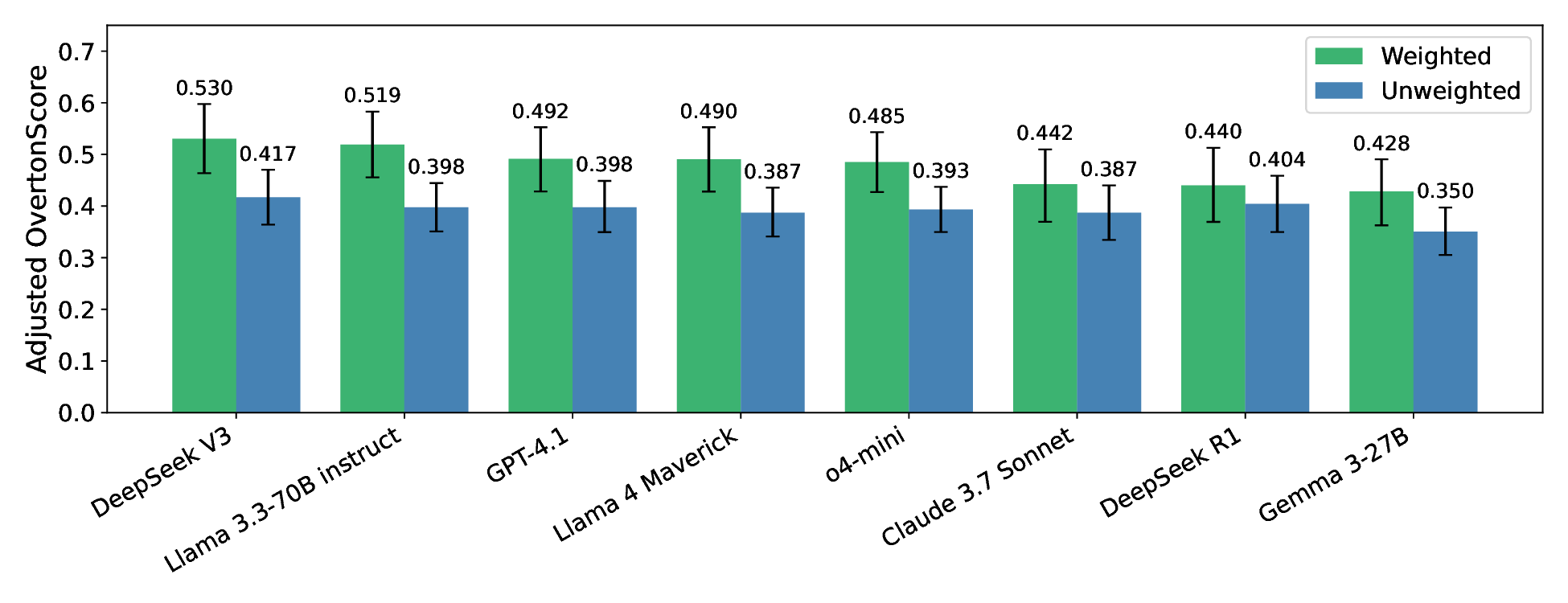
We introduce a novel framework for measuring Overton pluralism in LLMs--the extent to which diverse viewpoints are represented in model outputs. We (i) formalize Overton pluralism as a set coverage metric (OvertonScore), (ii) conduct a large-scale U.S.-representative human study (N = 1209; 60 questions; 8 LLMs), and (iii) develop an automated benchmark that closely reproduces human judgments. On average, models achieve OvertonScores of 0.35--0.41, with DeepSeek V3 performing best; yet all models remain far below the theoretical maximum of 1.0, revealing substantial headroom for improvement. Because repeated large-scale human studies are costly and slow, scalable evaluation tools are essential for model development. Hence, we propose an automated benchmark that achieves high rank correlation with human judgments ($ρ=0.88$), providing a practical proxy without replacing human assessment. By turning pluralistic alignment from a normative aim into a measurable benchmark, our work establishes a foundation for systematic progress toward more pluralistic LLMs.
💡 Deep Analysis
Deep Dive into Benchmarking Overton Pluralism in LLMs.
We introduce a novel framework for measuring Overton pluralism in LLMs–the extent to which diverse viewpoints are represented in model outputs. We (i) formalize Overton pluralism as a set coverage metric (OvertonScore), (ii) conduct a large-scale U.S.-representative human study (N = 1209; 60 questions; 8 LLMs), and (iii) develop an automated benchmark that closely reproduces human judgments. On average, models achieve OvertonScores of 0.35–0.41, with DeepSeek V3 performing best; yet all models remain far below the theoretical maximum of 1.0, revealing substantial headroom for improvement. Because repeated large-scale human studies are costly and slow, scalable evaluation tools are essential for model development. Hence, we propose an automated benchmark that achieves high rank correlation with human judgments ($ρ=0.88$), providing a practical proxy without replacing human assessment. By turning pluralistic alignment from a normative aim into a measurable benchmark, our work establish
📄 Full Content
BENCHMARKING OVERTON PLURALISM IN LLMS
Elinor Poole-Dayan1
Jiayi Wu2
Taylor Sorensen3
Jiaxin Pei4
Michiel A. Bakker1
1Massachusetts Institute of Technology
2Brown University
3University of Washington
4Stanford University
{elinorpd, bakker}@mit.edu
ABSTRACT
We introduce a novel framework for measuring Overton pluralism in LLMs—the
extent to which diverse viewpoints are represented in model outputs. We (i) for-
malize Overton pluralism as a set coverage metric (OVERTONSCORE), (ii) con-
duct a large-scale U.S.-representative human study (N = 1209; 60 questions; 8
LLMs), and (iii) develop an automated benchmark that closely reproduces human
judgments. On average, models achieve OVERTONSCOREs of 0.35–0.41, with
DeepSeek V3 performing best; yet all models remain far below the theoretical
maximum of 1.0, revealing substantial headroom for improvement. Because re-
peated large-scale human studies are costly and slow, scalable evaluation tools are
essential for model development. Hence, we propose an automated benchmark
that achieves high rank correlation with human judgments (ρ = 0.88), providing a
practical proxy without replacing human assessment. By turning pluralistic align-
ment from a normative aim into a measurable benchmark, our work establishes a
foundation for systematic progress toward more pluralistic LLMs.
1
INTRODUCTION
Large language models (LLMs) shape political discourse, education, and everyday interactions.
However, when they misrepresent or erase viewpoints (Santurkar et al., 2023; Durmus et al., 2024;
Wang et al., 2024), they risk distorting deliberation, marginalizing communities, and creating “al-
gorithmic monoculture” (Bommasani et al., 2022; Kleinberg & Raghavan, 2021). Traditional align-
ment strategies that aggregate over diverse preferences have been shown to exacerbate this issue
(Casper et al., 2023; Kaufmann et al., 2024; Feffer et al., 2023), collapsing genuine disagreements
(Durmus et al., 2024; Sorensen et al., 2024a; Bakker et al., 2022; AlKhamissi et al., 2024; Ryan et al.,
2024) into a single normative stance—an issue known as value monism (Gabriel, 2020). Outputs
that appear neutral often encode majority or developer-preferred biases, entrenching representational
harms (Chien & Danks, 2024) and heightening safety risks such as susceptibility to propaganda or
cultural domination. For example, when asked about climate policy, models may emphasize eco-
nomic efficiency while omitting justice-oriented arguments, or, in discussing free speech, they may
privilege U.S.-centric legal framings while neglecting other democratic traditions. Such exclusions
distort deliberation and weaken the robustness of democratic discourse.
Prior work has established the existence of political bias in LLMs (Feng et al., 2023; Röttger et al.,
2024; Potter et al., 2024; Peng et al., 2025; Westwood et al., 2025), contributing to a growing focus
on achieving political neutrality. For example, Meta’s latest Llama 4 release cites left-leaning LLM
biases as motivation why its goal is “to make sure that Llama can understand and articulate both
sides of a contentious issue” and “doesn’t favor some views over others” (Meta, 2025a). However,
the goal of true political neutrality has been shown to be impossible—and not always desirable
(Fisher et al., 2025); a neutral answer may still omit or misportray minority perspectives.
Pluralistic alignment offers an alternative: rather than consensus, models should represent a spec-
trum of reasonable perspectives within the “Overton window” of public discourse. Sorensen et al.
(2024b) distinguishes three types of pluralism: Overton pluralism, where models surface multiple
legitimate perspectives simultaneously; steerable pluralism, where users can shift outputs toward a
given perspective; and distributional pluralism, where models reflect the distribution of opinions in
a particular population across output samples. We focus on Overton pluralism, the most practically
relevant for subjective settings with many legitimate answers.
1
arXiv:2512.01351v1 [cs.AI] 1 Dec 2025
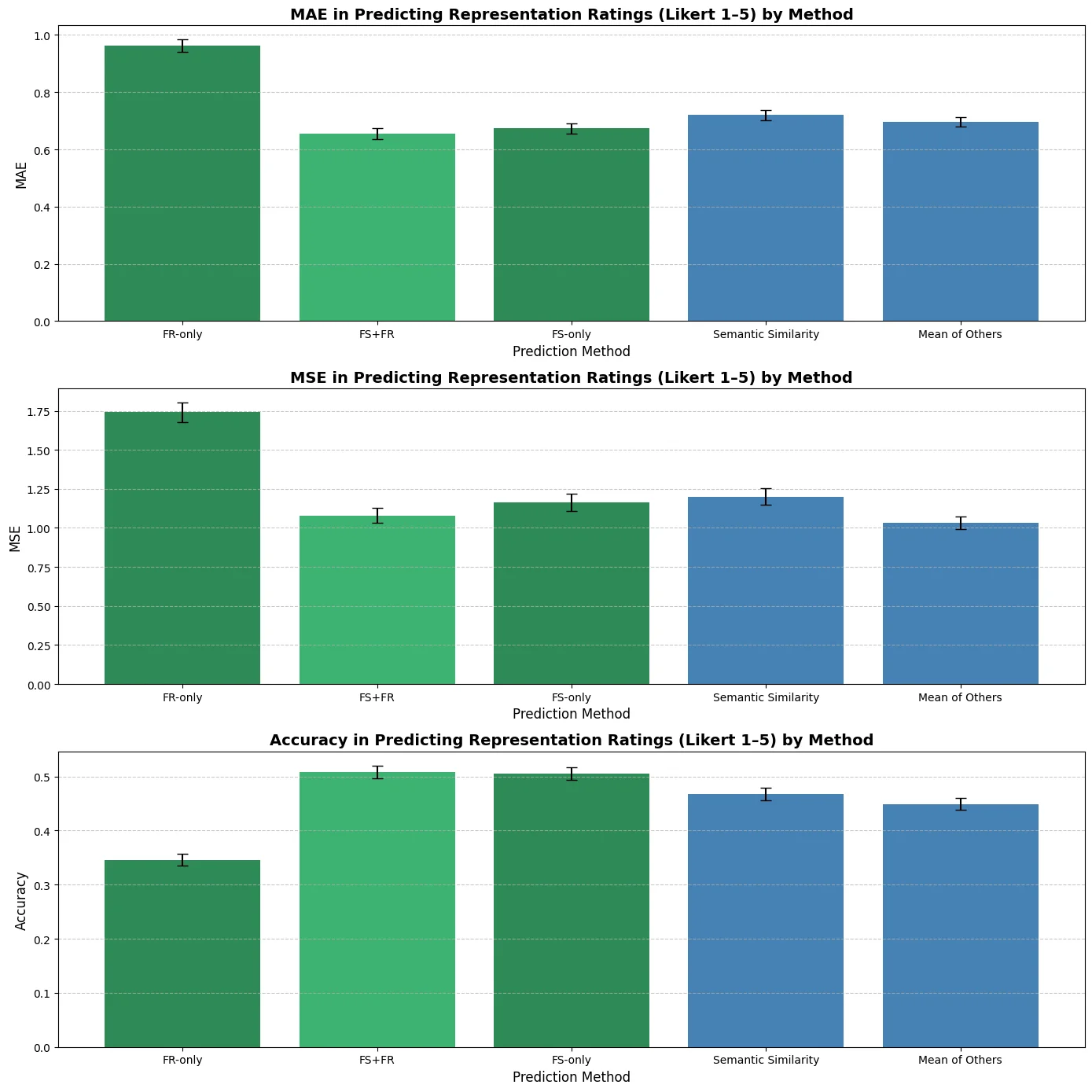
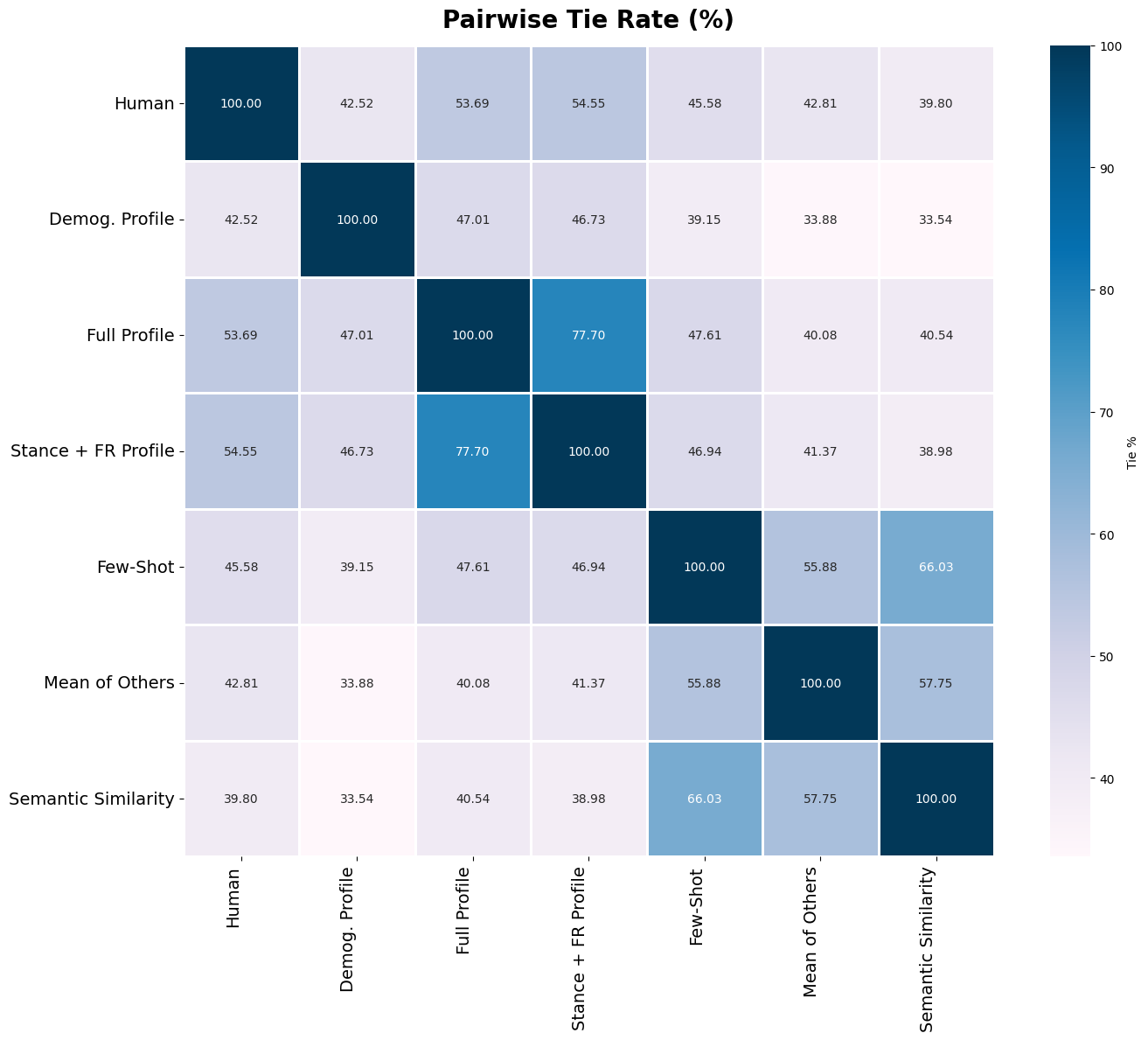
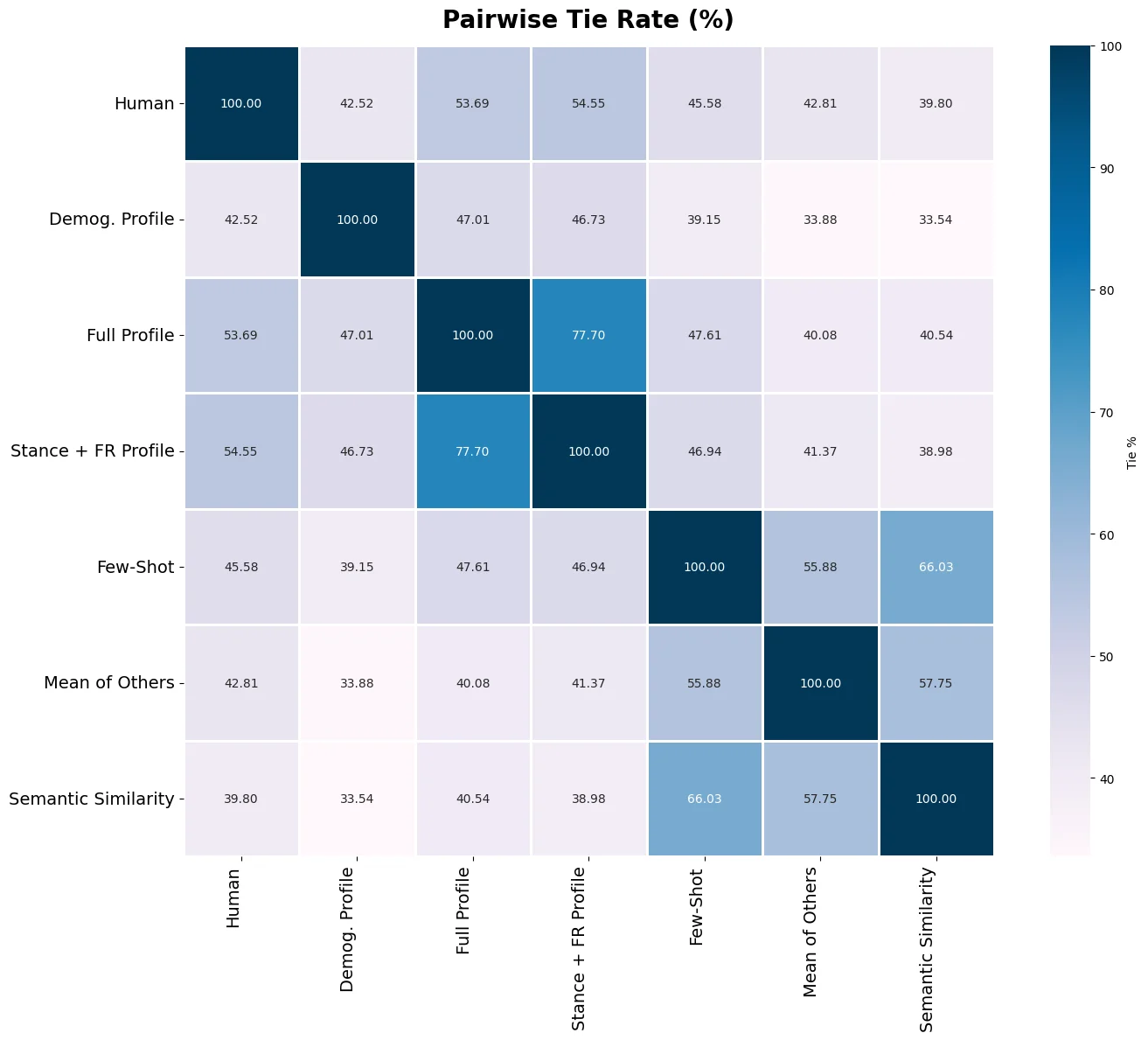
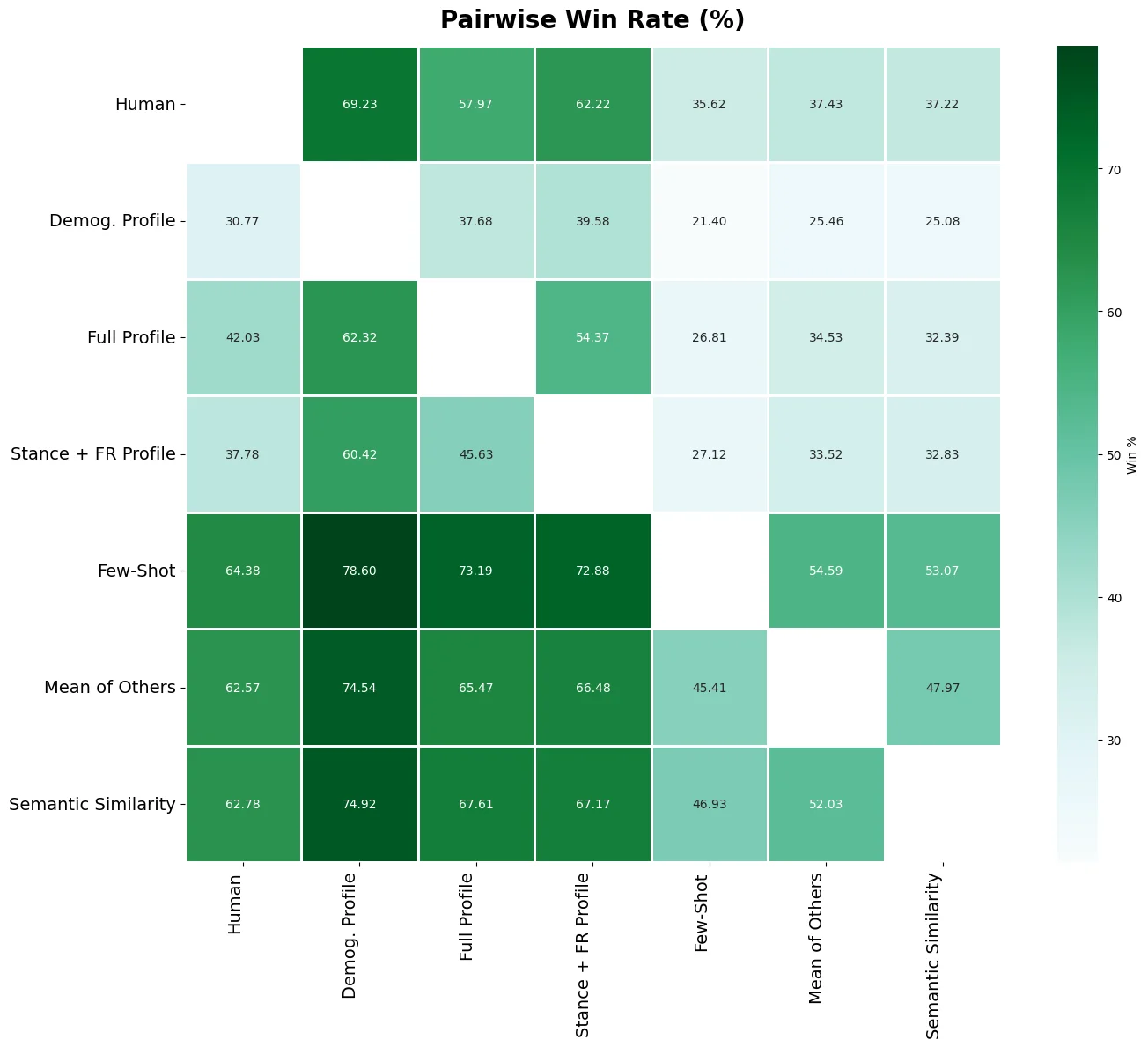
Figure 1: Overview of our benchmark for quantifying Overton pluralism. We cluster survey par-
ticipants into distinct viewpoints on subjective questions and measure whether each group feels
represented in a model’s response. The OVERTONSCORE is the fraction of viewpoints adequately
represented (✓); its weighted variant additionally accounts for each group’s prevalence. Shown here
for a carbon-emissions question: GPT o4-mini represents only the majority pro-regulation view,
Llama 4 Maverick represents the minority “balance economy” view, while a hypothetical pluralistic
model covers all viewpoints (score = 1.0). Model responses are real excerpts, abbreviated for clarity.
Several modeling strategies move in this direction: MaxMin-RLHF ensures minimal group satisfac-
tion (Chakraborty et al., 2024), Modular Pluralism adds community modules for multiple pluralism
types (Feng et al., 2024), and Collective Cons
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.