Foundation models (FMs) have opened new avenues for machine learning applications due to their ability to adapt to new and unseen tasks with minimal or no further training. Time-series foundation models (TSFMs)-FMs trained on time-series data-have shown strong performance on classification, regression, and imputation tasks. Recent pipelines combine TSFMs with task-specific encoders, decoders, and adapters to improve performance; however, assembling such pipelines typically requires ad hoc, model-specific implementations that hinder modularity and reproducibility. We introduce FMTK, an open-source, lightweight and extensible toolkit for constructing and fine-tuning TSFM pipelines via standardized backbone and component abstractions. FMTK enables flexible composition across models and tasks, achieving correctness and performance with an average of seven lines of code. https://github.com/umassos/FMTK Although existing time series libraries such as sktime [10] , Darts [7], tsai [12] , and GluonTS [1] support classical and deep learning pipelines, they do not address the emerging need for composable, FM-centric evaluation. To this end, we introduce FMTK: an open-source, lightweight, and extensible Time Series Foundation Model Toolkit for constructing, fine-tuning and benchmarking modular TSFM pipelines. † Author holds concurrent appointments as a Professor at UCLA, and as an Amazon Scholar. This paper describes work performed at UCLA and is not associated with Amazon. NeurIPS 2025 Workshop on Recent Advances in Time Series Foundation Models (BERT 2 S).
💡 Deep Analysis
Deep Dive into 시간 시계열 기반 모델 툴킷으로 혁신적인 파이프라인 구축.
Foundation models (FMs) have opened new avenues for machine learning applications due to their ability to adapt to new and unseen tasks with minimal or no further training. Time-series foundation models (TSFMs)-FMs trained on time-series data-have shown strong performance on classification, regression, and imputation tasks. Recent pipelines combine TSFMs with task-specific encoders, decoders, and adapters to improve performance; however, assembling such pipelines typically requires ad hoc, model-specific implementations that hinder modularity and reproducibility. We introduce FMTK, an open-source, lightweight and extensible toolkit for constructing and fine-tuning TSFM pipelines via standardized backbone and component abstractions. FMTK enables flexible composition across models and tasks, achieving correctness and performance with an average of seven lines of code. https://github.com/umassos/FMTK
Although existing time series libraries such as sktime [10] , Darts [7], tsai [12] , an
📄 Full Content
FMTK: A Modular Toolkit for Composable Time
Series Foundation Model Pipelines
Hetvi Shastri1
Pragya Sharma2
Walid A. Hanafy1
Mani Srivastava2†
Prashant Shenoy1
1University of Massachusetts Amherst
2University of California Los Angeles
Abstract
Foundation models (FMs) have opened new avenues for machine learning applica-
tions due to their ability to adapt to new and unseen tasks with minimal or no further
training. Time-series foundation models (TSFMs)—FMs trained on time-series
data—have shown strong performance on classification, regression, and imputation
tasks. Recent pipelines combine TSFMs with task-specific encoders, decoders, and
adapters to improve performance; however, assembling such pipelines typically
requires ad hoc, model-specific implementations that hinder modularity and repro-
ducibility. We introduce FMTK, an open-source, lightweight and extensible toolkit
for constructing and fine-tuning TSFM pipelines via standardized backbone and
component abstractions. FMTK enables flexible composition across models and
tasks, achieving correctness and performance with an average of seven lines of
code. https://github.com/umassos/FMTK
1
Introduction
Time Series Foundation Models (TSFMs), such as MOMENT [6], Chronos [2], and TimesFM [4],
have emerged as powerful pre-trained architectures for a variety of downstream tasks, including
forecasting, classification, and imputation. While these models serve as fixed backbones trained
on large-scale temporal data, effective task specialization often requires integrating additional com-
ponents: input encoders to structure raw data, task-specific decoders to generate predictions, and
increasingly, parameter-efficient adapters (e.g., LoRA [8]) to enable lightweight fine-tuning.
This modular design space, though conceptually flexible, has resulted in a fragmented and ad hoc
implementation landscape. For example, models such as PaPaGei [13] and Mantis [5] require the
development of extensive custom pipelines for simple comparison with state-of-the-art models.
Moreover, models like Moment [6] offer distinct modes for different tasks (e.g., forecasting versus
classification), which restricts the reuse of the same powerful backbone for a diverse set of downstream
tasks during runtime. As a result, three key challenges emerge. 1 First, the absence of a unifying
abstraction across encoders, backbones, adapters, and decoders significantly increases the engineering
burden and inhibits systematic exploration of architectural variants. 2 Second, the lack of modular
encapsulation complicates the attribution. It becomes difficult to isolate and measure the contribution
of individual components to the overall performance of the model. 3 Third, evaluation practices
vary widely across studies. Minor differences in data pre-processing, training regimes, or decoder
heads can lead to substantial discrepancies in reported results, thereby undermining reproducibility.
Although existing time series libraries such as sktime [10], Darts [7], tsai [12], and GluonTS [1]
support classical and deep learning pipelines, they do not address the emerging need for composable,
FM-centric evaluation. To this end, we introduce FMTK: an open-source, lightweight, and extensible
Time Series Foundation Model Toolkit for constructing, fine-tuning and benchmarking modular
TSFM pipelines.
†Author holds concurrent appointments as a Professor at UCLA, and as an Amazon Scholar. This paper
describes work performed at UCLA and is not associated with Amazon.
NeurIPS 2025 Workshop on Recent Advances in Time Series Foundation Models (BERT2S).
arXiv:2512.01038v1 [cs.LG] 30 Nov 2025
Foundation
Model (FM)
Encoders
Input
Output
+ Adapters
A1
A2
A3
P=Pipeline(backbone=FM)
Decoders
E3
E2
E1
D3
D2
D1
P.add_decoder(D2(...), load=True)
P.add_encoder(E1(...), load=True)
P.add_adapter(A1(), load=True)
train,test=Dataloader(..),Dataloader(..)
P.train(train,['adapter', 'encoder', 'decoder'])
y_test,y_pred=P.predict(test)
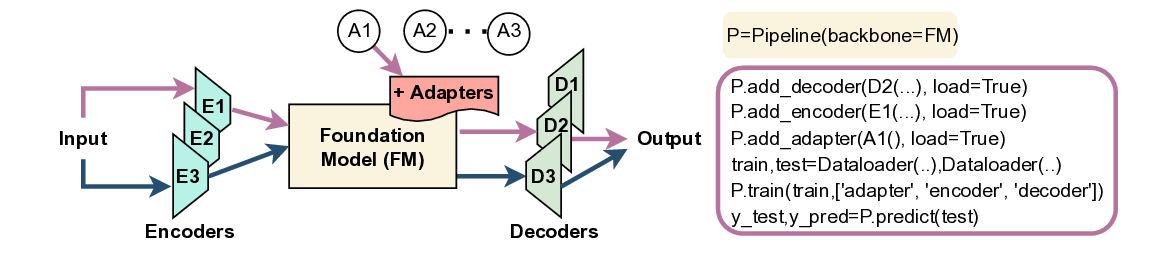
Figure 1: Modular abstraction of pipeline construction using FMTK: The framework allows
instantiating pipelines by pairing an FM with interchangeable components. Users can dynamically
select and load components, specify trainable parts (e.g., decoder), and benchmark pipelines in
a unified interface. We illustrate two example configurations using the same FM: (top) encoder-
decoder-adapter-tuned pipeline with E1, A1 and D2; (bottom) encoder-decoder tuned with E3 and
D3.
Contributions: Our contributions can be summarized as follows:
1. FMTK proposes a standardized API for TSFM pipelines that defines a common grammar for
connecting FM backbones with external encoders, fine-tuning adapters and decoders.
2. FMTK provides reference implementation of commonly used configurations and supports multiple
time series tasks under consistent evaluation settings.
3. By decoupling architectural components and enforcing standardized execution semantics, FMTK
facilitates reproducible experimentation and controlled compari