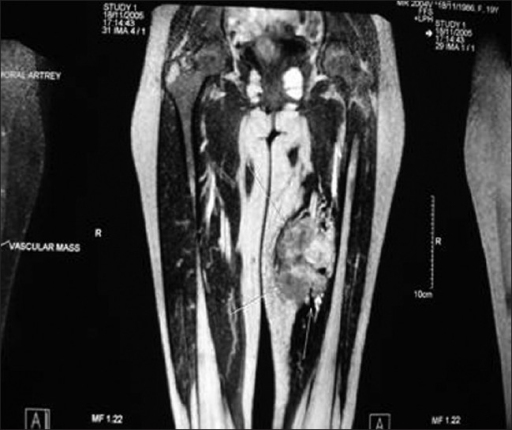
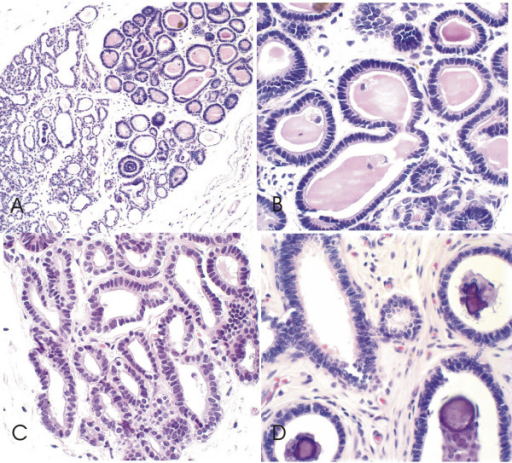
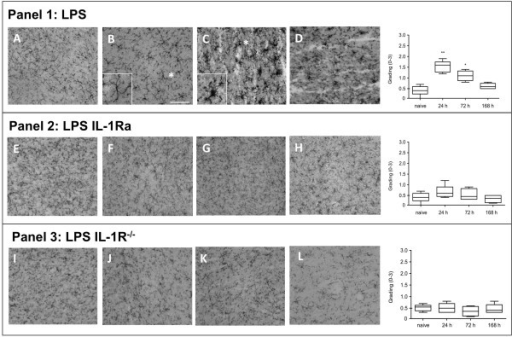
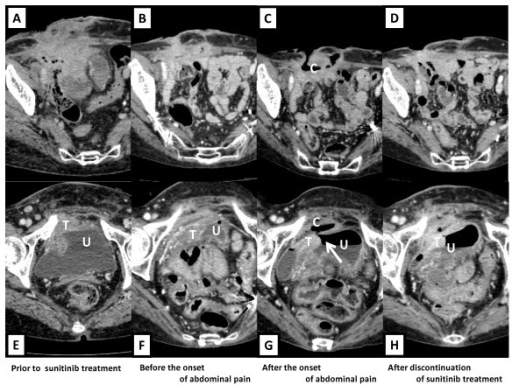
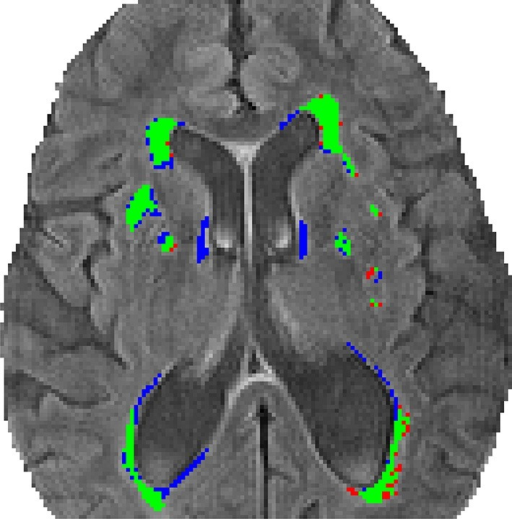
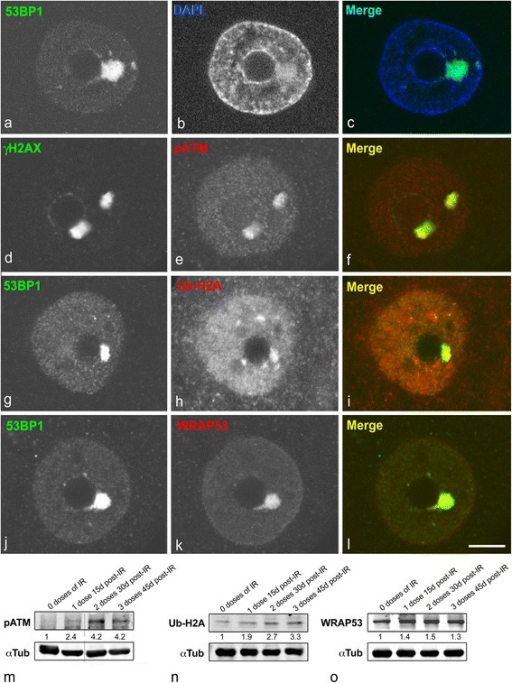
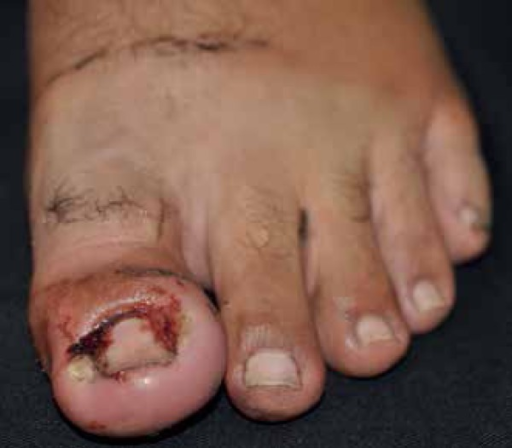
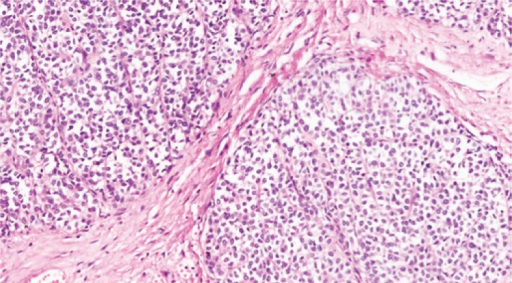
📝 Original Info
- Title: Med-CMR: A Fine-Grained Benchmark Integrating Visual Evidence and Clinical Logic for Medical Complex Multimodal Reasoning
- ArXiv ID: 2512.00818
- Date: 2025-11-30
- Authors: Haozhen Gong, Xiaozhong Ji, Yuansen Liu, Wenbin Wu, Xiaoxiao Yan, Jingjing Liu, Kai Wu, Jiazhen Pan, Bailiang Jian, Jiangning Zhang, Xiaobin Hu, Hongwei Bran Li
📝 Abstract
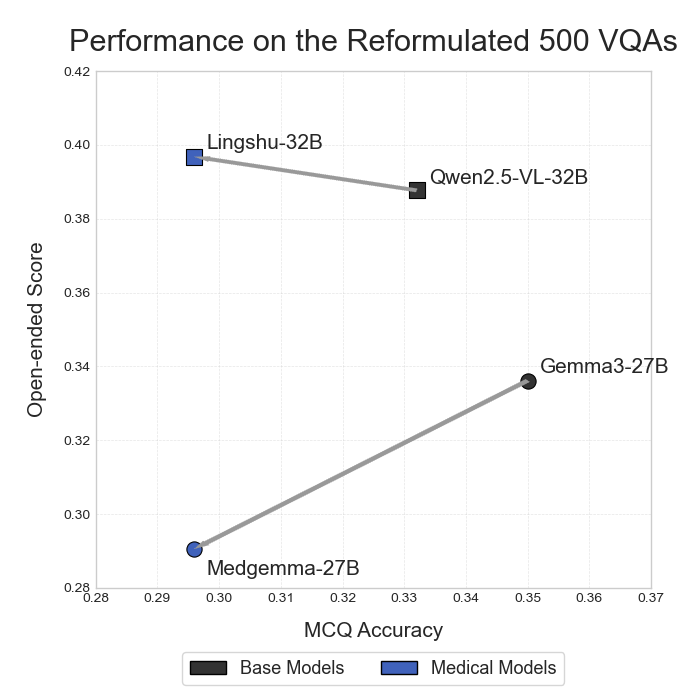
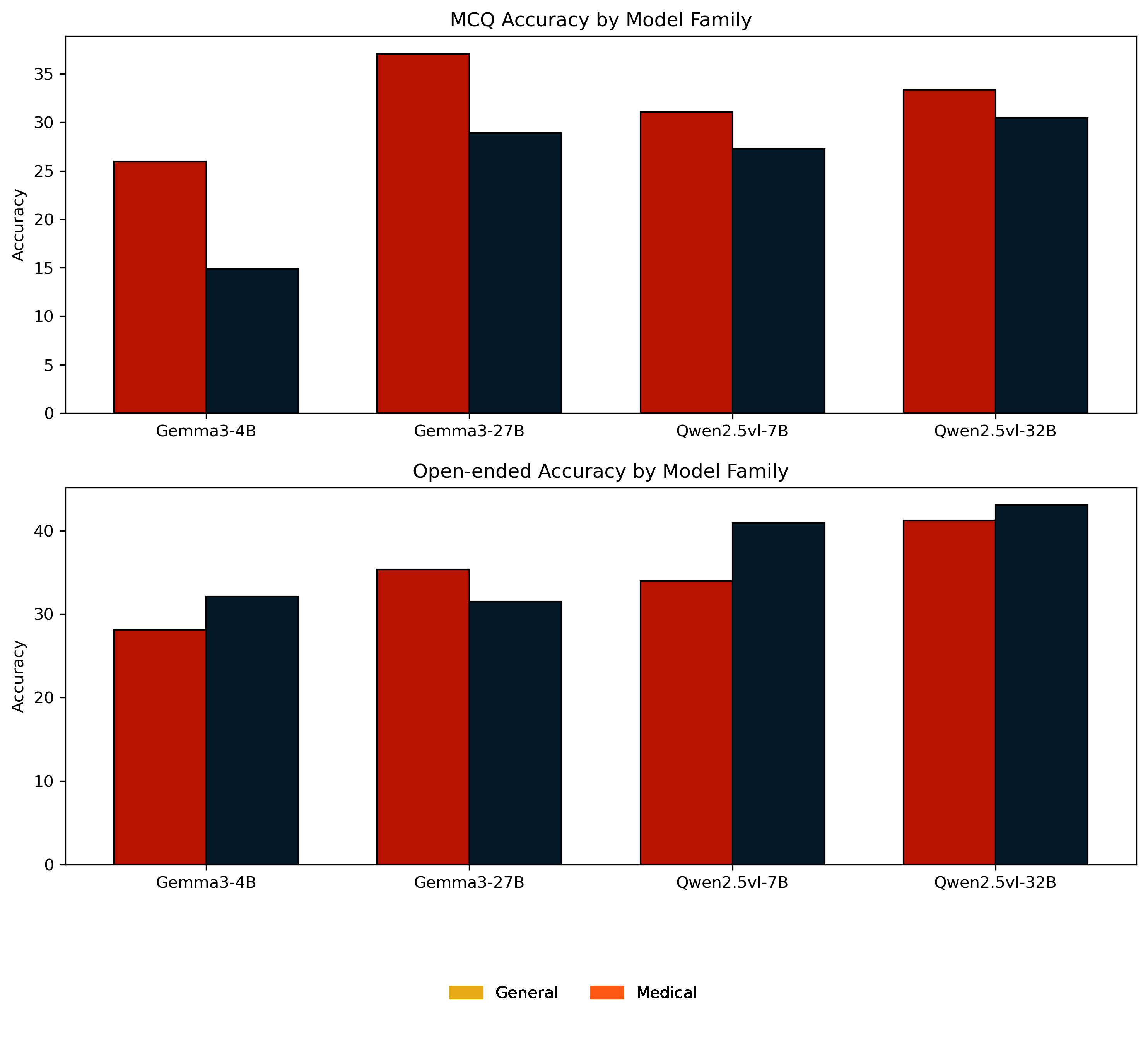
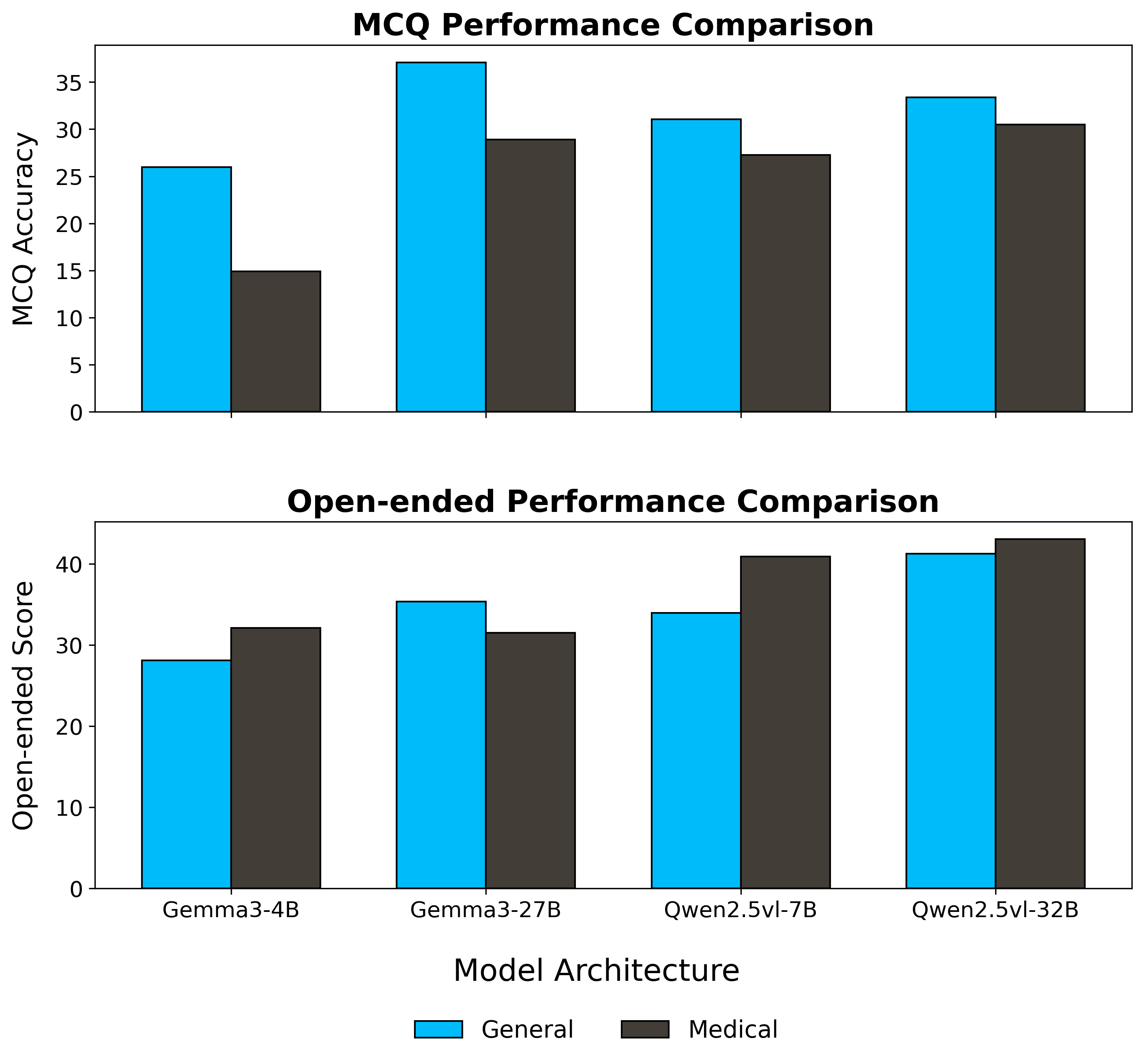
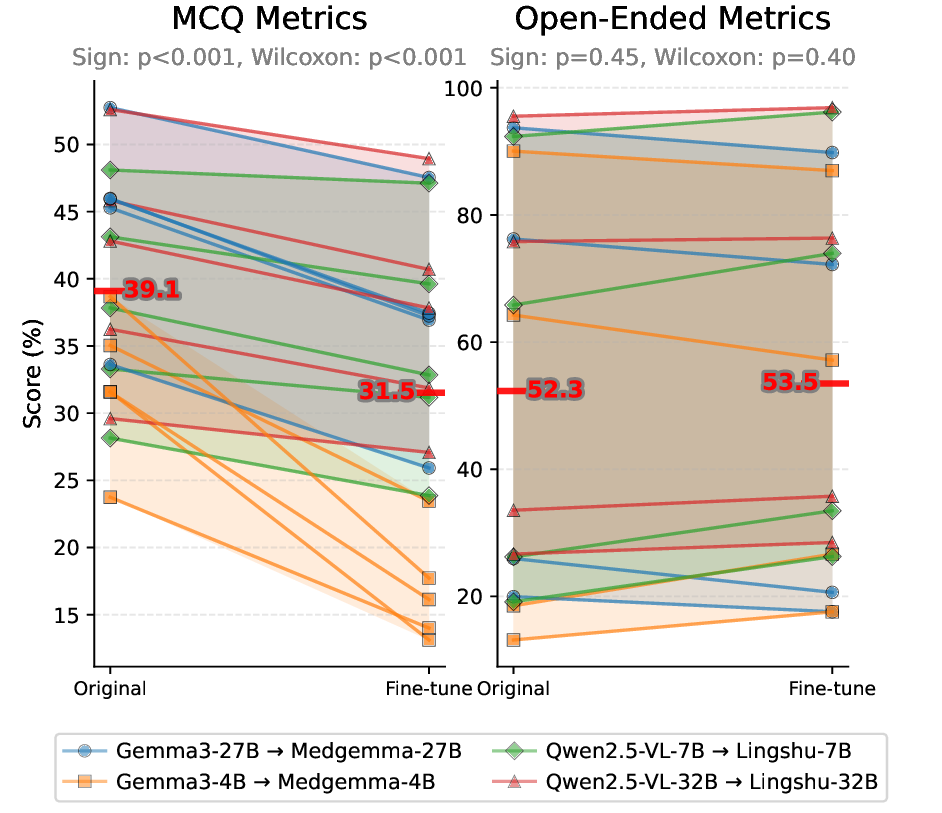
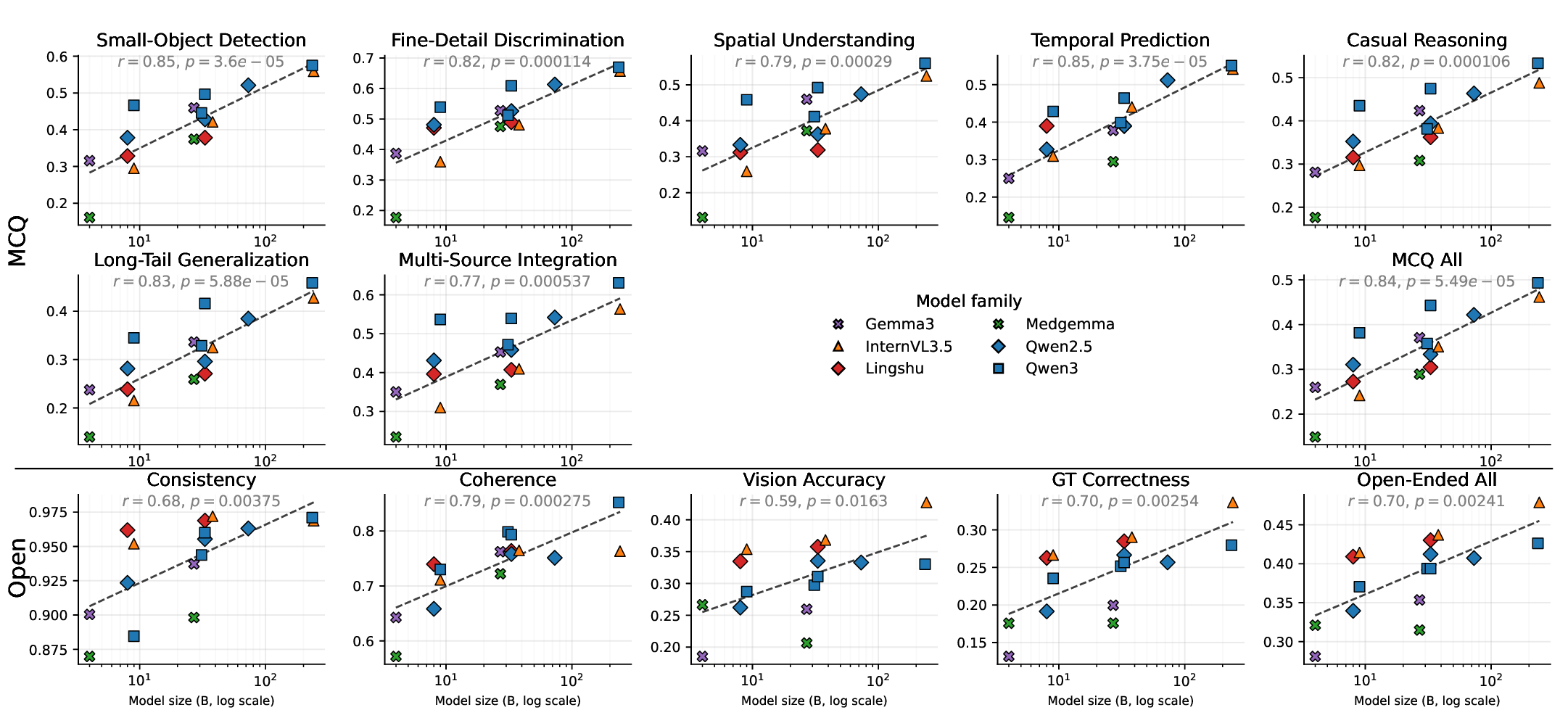
MLLMs MLLMs are beginning to appear in clinical workflows, but their ability to perform complex medical reasoning remains unclear. We present Med-CMR, a fine-grained Medical Complex Multimodal Reasoning benchmark. Med-CMR distinguishes from existing counterparts by three core features: 1) Systematic capability decomposition, splitting medical multimodal reasoning into fine-grained visual understanding and multi-step reasoning to enable targeted evaluation; 2) Challenging task design, with visual understanding across three key dimensions (small-object detection, fine-detail discrimination, spatial understanding) and reasoning covering four clinically relevant scenarios (temporal prediction, causal reasoning, long-tail generalization, multi-source integration); 3) Broad, high-quality data coverage, comprising 20,653 Visual Question Answering (VQA) pairs spanning 11 organ systems and 12 imaging modalities, validated via a rigorous two-stage (human expert + model-assisted) review to ensure clinical authenticity. We evaluate 18 state-of-the-art MLLMs with Med-CMR, revealing GPT-5 as the top-performing commercial model: 57.81 accuracy on multiple-choice questions (MCQs) and a 48.70 open-ended score, outperforming Gemini 2.5 Pro (49.87 MCQ accuracy, 45.98 open-ended score) and leading open-source model Qwen3-VL-235B-A22B (49.34 MCQ accuracy, 42.62 open-ended score). However, specialized medical MLLMs do not reliably outperform strong general models, and long-tail generalization emerges as the dominant failure mode. Med-CMR thus provides a stress test for visual-reasoning integration and rare-case robustness in medical MLLMs, and a rigorous yardstick for future clinical systems.
💡 Deep Analysis
Deep Dive into Med-CMR: A Fine-Grained Benchmark Integrating Visual Evidence and Clinical Logic for Medical Complex Multimodal Reasoning.
MLLMs MLLMs are beginning to appear in clinical workflows, but their ability to perform complex medical reasoning remains unclear. We present Med-CMR, a fine-grained Medical Complex Multimodal Reasoning benchmark. Med-CMR distinguishes from existing counterparts by three core features: 1) Systematic capability decomposition, splitting medical multimodal reasoning into fine-grained visual understanding and multi-step reasoning to enable targeted evaluation; 2) Challenging task design, with visual understanding across three key dimensions (small-object detection, fine-detail discrimination, spatial understanding) and reasoning covering four clinically relevant scenarios (temporal prediction, causal reasoning, long-tail generalization, multi-source integration); 3) Broad, high-quality data coverage, comprising 20,653 Visual Question Answering (VQA) pairs spanning 11 organ systems and 12 imaging modalities, validated via a rigorous two-stage (human expert + model-assisted) review to ensure
📄 Full Content
Med-CMR: A Fine-Grained Benchmark Integrating Visual Evidence and
Clinical Logic for Medical Complex Multimodal Reasoning
Haozhen Gong1,†
Xiaozhong Ji2,†
Yuansen Liu1,†
Wenbin Wu1
Xiaoxiao Yan4
Jingjing Liu1
Kai Wu3
Jiazhen Pan5
Bailiang Jian5
Jiangning Zhang6
Xiaobin Hu1,∗
Hongwei Bran Li1
1National University of Singapore
2Nanjing University
3Tongji University
4Ruijin Hospital
5Technical University of Munich
6Zhejiang University
† Equal contribution
* Corresponding author
Abstract
MLLMs are beginning to appear in clinical workflows,
but their ability to perform complex medical reasoning
remains unclear.
We present Med-CMR, a fine-grained
Medical Complex Multimodal Reasoning benchmark. Med-
CMR distinguishes from existing counterparts by three core
features: 1) Systematic capability decomposition, splitting
medical multimodal reasoning into fine-grained visual un-
derstanding and multi-step reasoning to enable targeted
evaluation; 2) Challenging task design, with visual un-
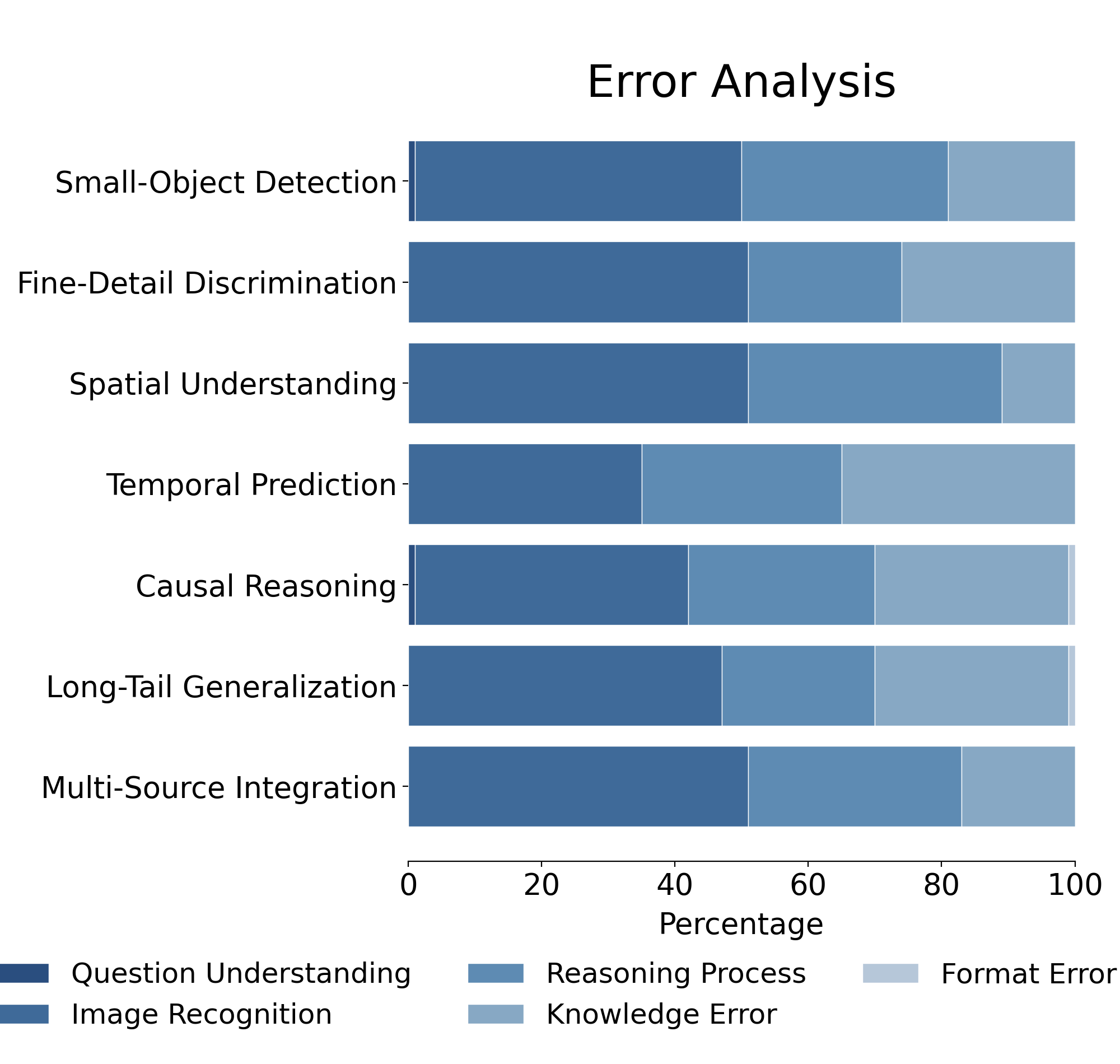
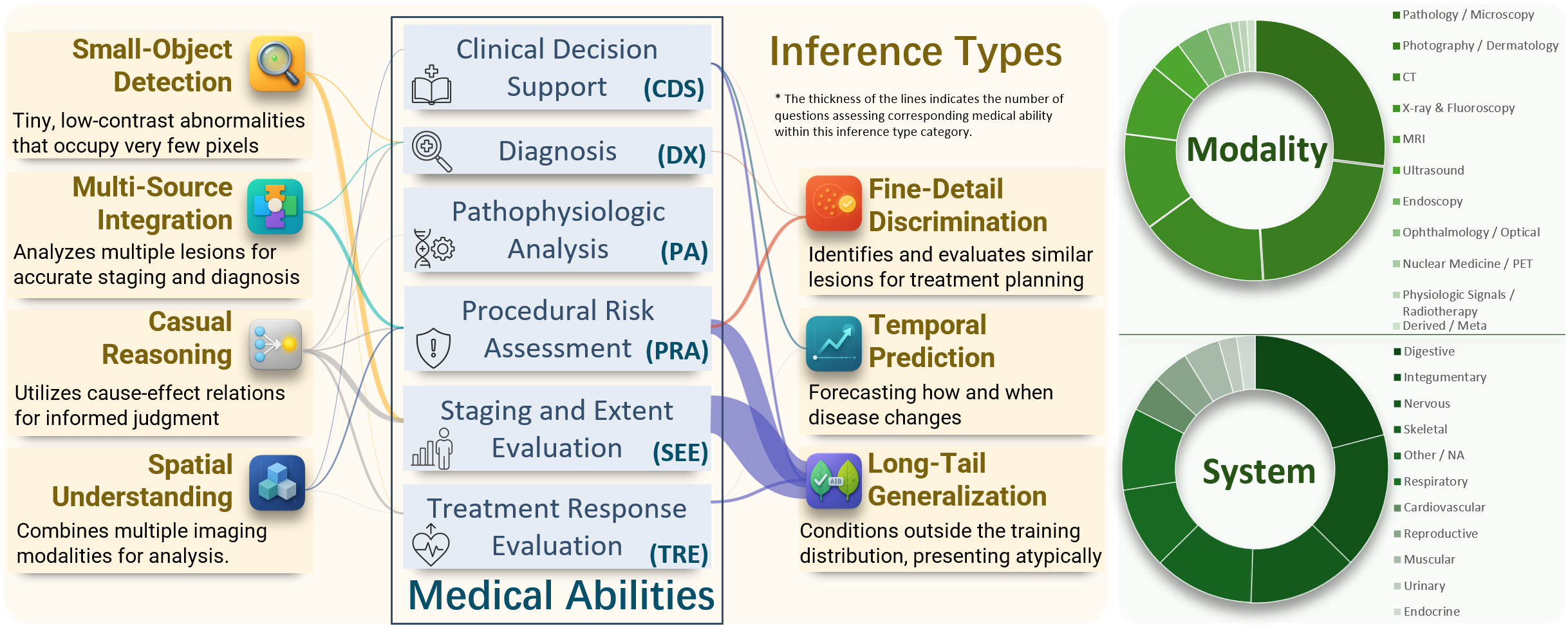
derstanding across three key dimensions (small-object de-
tection, fine-detail discrimination, spatial understanding)
and reasoning covering four clinically relevant scenarios
(temporal prediction, causal reasoning, long-tail general-
ization, multi-source integration); 3) Broad, high-quality
data coverage, comprising 20,653 Visual Question Answer-
ing (VQA) pairs spanning 11 organ systems and 12 imag-
ing modalities, validated via a rigorous two-stage (hu-
man expert + model-assisted) review to ensure clinical au-
thenticity.
We evaluate 18 state-of-the-art MLLMs with
Med-CMR, revealing GPT-5 as the top-performing com-
mercial model: 57.81 accuracy on multiple-choice ques-
tions (MCQs) and a 48.70 open-ended score, outperforming
Gemini 2.5 Pro (49.87 MCQ accuracy, 45.98 open-ended
score) and leading open-source model Qwen3-VL-235B-
A22B (49.34 MCQ accuracy, 42.62 open-ended score).
However, specialized medical MLLMs do not reliably out-
perform strong general models, and long-tail generaliza-
tion emerges as the dominant failure mode.
Med-CMR
thus provides a stress test for visual–reasoning integration
and rare-case robustness in medical MLLMs, and a rig-
orous yardstick for future clinical systems. Project page:
https://github.com/LsmnBmnc/Med-CMR.
1. Introduction
Multimodal large language models (MLLMs) [6, 7, 17, 23,
27, 28, 35, 41, 43, 45] are rapidly moving from proof-of-
concept demos into tools that clinicians can actually touch.
Before they are trusted in practice, we need to understand
not only how often they are right, but how they reach de-
cisions: can they detect subtle findings, integrate multiple
images, track disease evolution, and reason about rare but
critical scenarios? Concretely, we ask: to what extent can
current MLLMs integrate medical images and clinical con-
text to answer multi-step, reasoning-intensive questions, be-
yond basic VQA?
Most existing multimodal medical benchmarks answer
only a small part of this question
[5, 11, 12, 15, 16,
18, 21, 33, 34, 47, 50, 51, 55, 57]. They are dominated
by perception-level visual question answering, where the
model describes an image or retrieves an obvious fact from
a short context. This setup hides many of the hard cases that
shape clinical decisions: tiny, low-contrast lesions; cross-
modal comparisons; temporal change; causal chains linking
symptoms, imaging, and outcomes; and long-tailed distri-
bution in textbooks. As a result, today’s benchmarks pro-
vide limited visibility into the complex medical reasoning
capabilities that matter in real workflows.
Evaluating such capabilities requires three ingredients
that current benchmarks largely lack. First, systematic ca-
pability decomposition: instead of treating “medical mul-
timodal reasoning" as a single score, we must separate
fine-grained visual understanding from downstream reason-
ing, and further break both into clinically meaningful sub-
dimensions. Second, clinically aligned and deliberately
challenging tasks: questions should be built around real
cases and explicitly target difficult settings such as temporal
prediction, causal reasoning, long-tail generalization, and
integration of multiple sources. Third, broad and well-
curated coverage across organs, modalities, and disease
processes, with expert review to ensure that questions re-
main realistic and clinically interpretable.
To address these gaps, we introduce Med-CMR, a
comprehensive benchmark that systematically evaluates
MLLMs across multiple dimensions. Specifically, we cate-
arXiv:2512.00818v1 [cs.AI] 30 Nov 2025
gorizes reasoning complexity into three visual dimensions,
small-object detection, fine-detail discrimination, and spa-
tial understanding; and four reasoning complexity dimen-
sions, temporal prediction, causal reasoning, long-tail gen-
eralization, and multi-source integration. Each dimension
corresponds to a distinct capability of MLLMs, enabling de-
tailed diagnosis of model strengths and weaknesses. We
collect data from authentic jo
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.