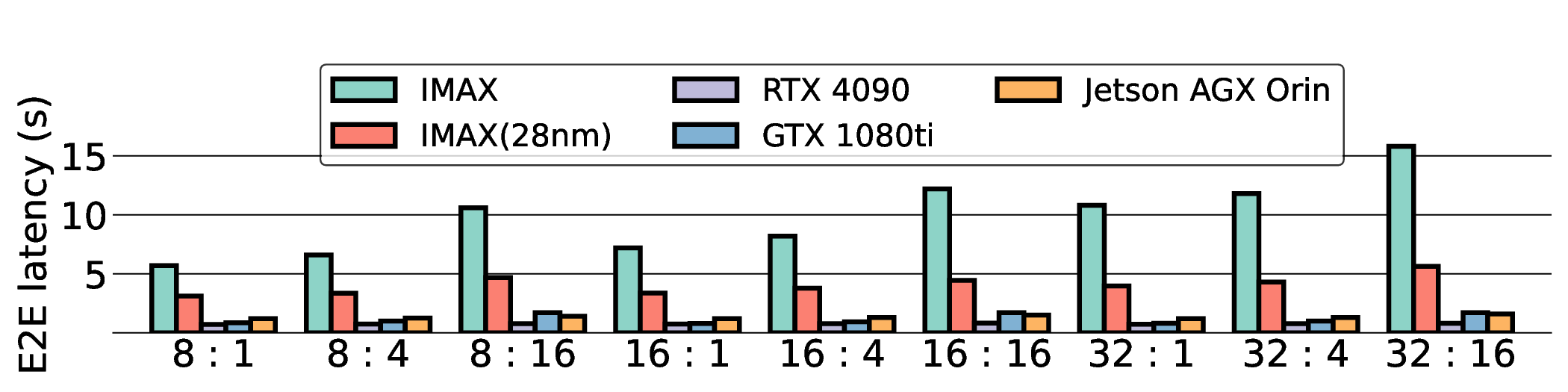
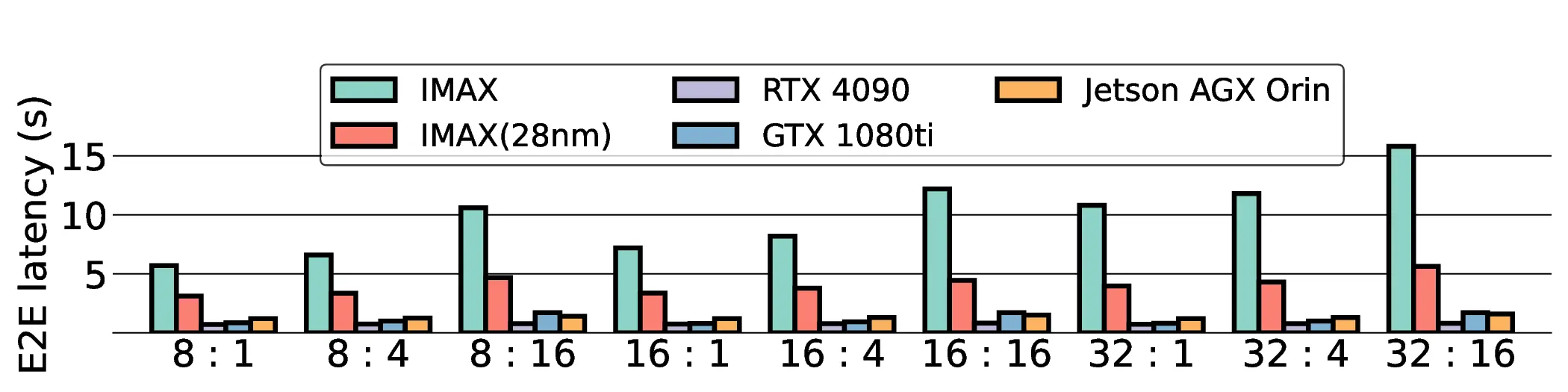
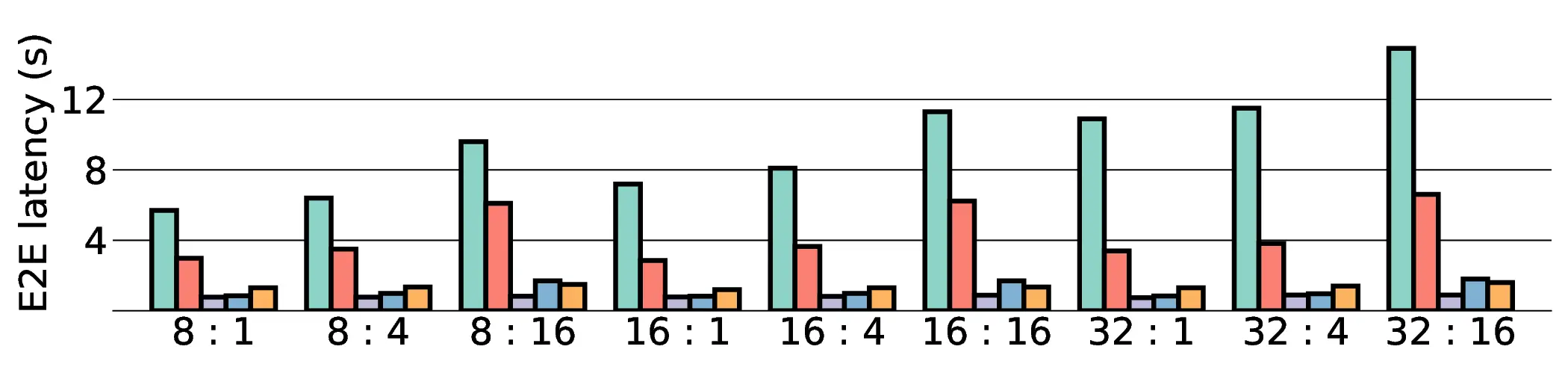
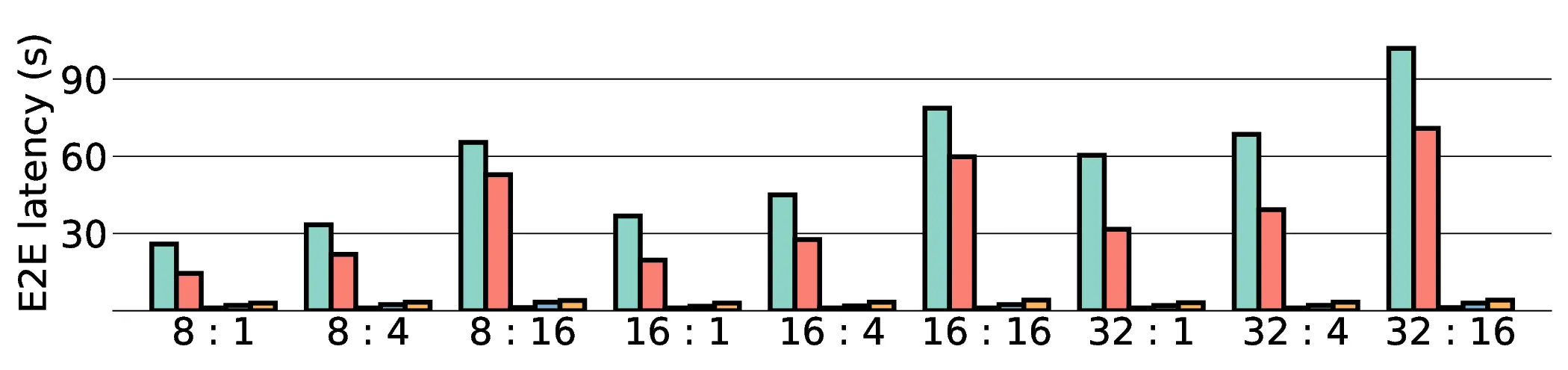
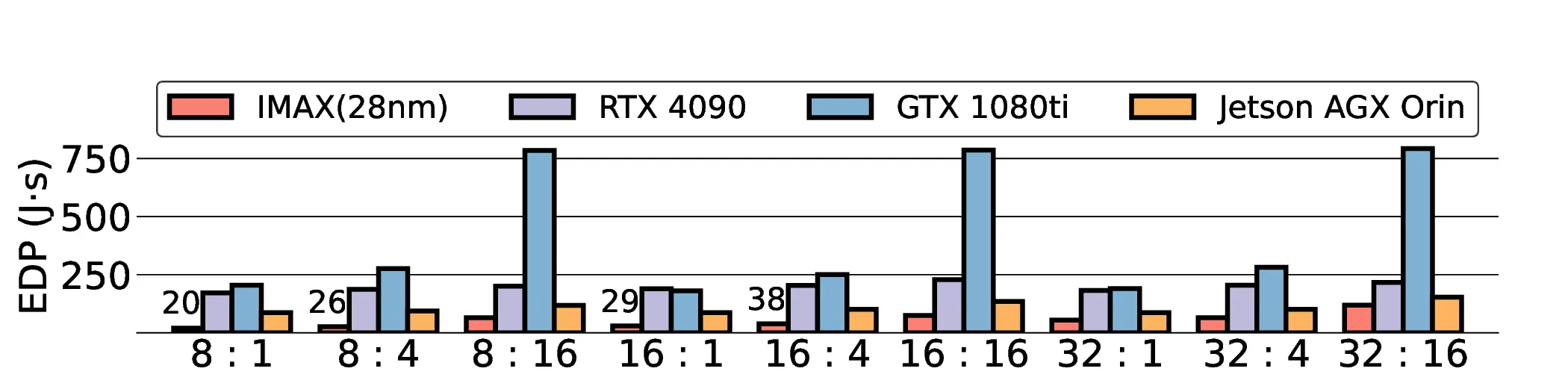
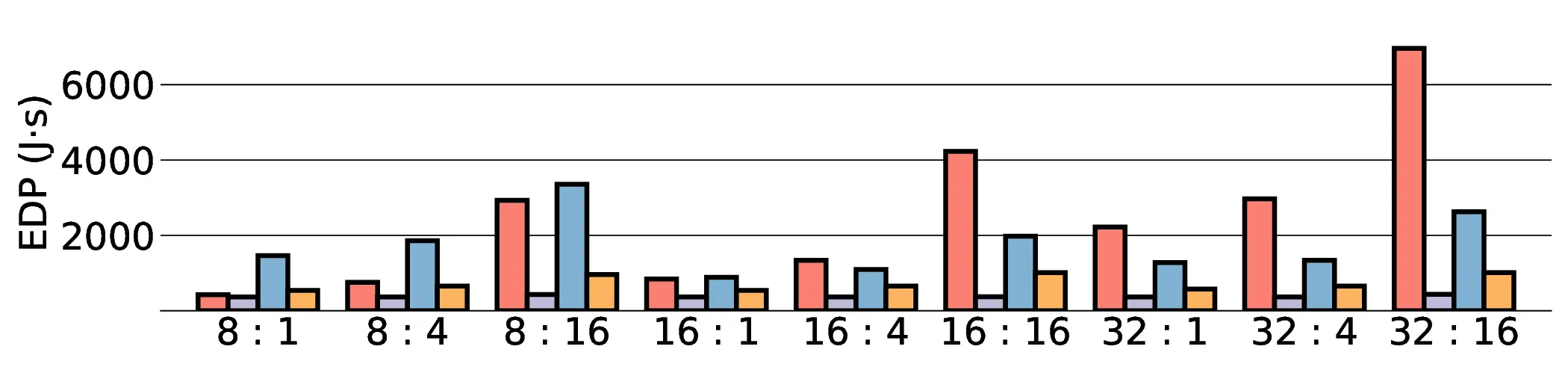
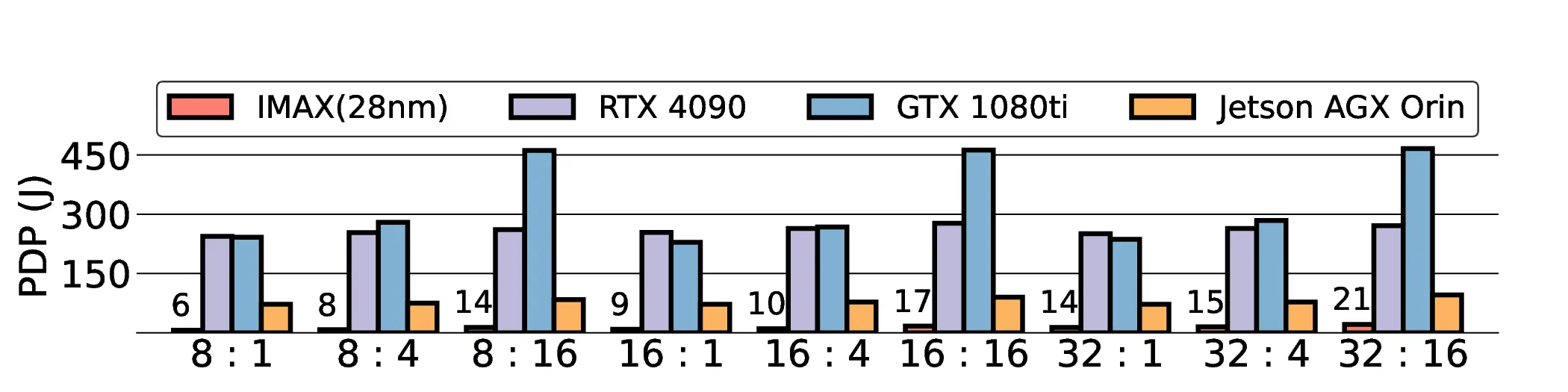
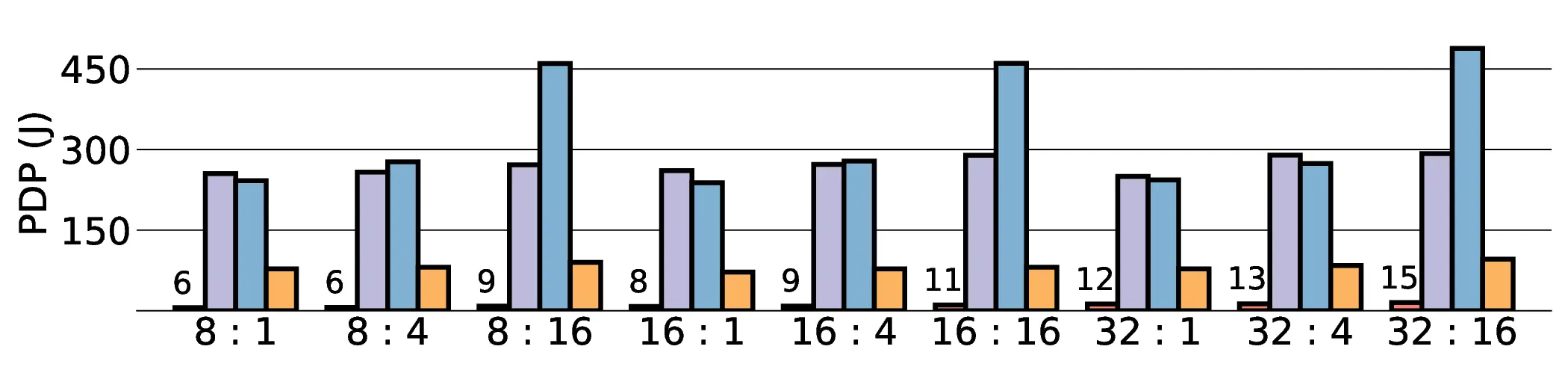
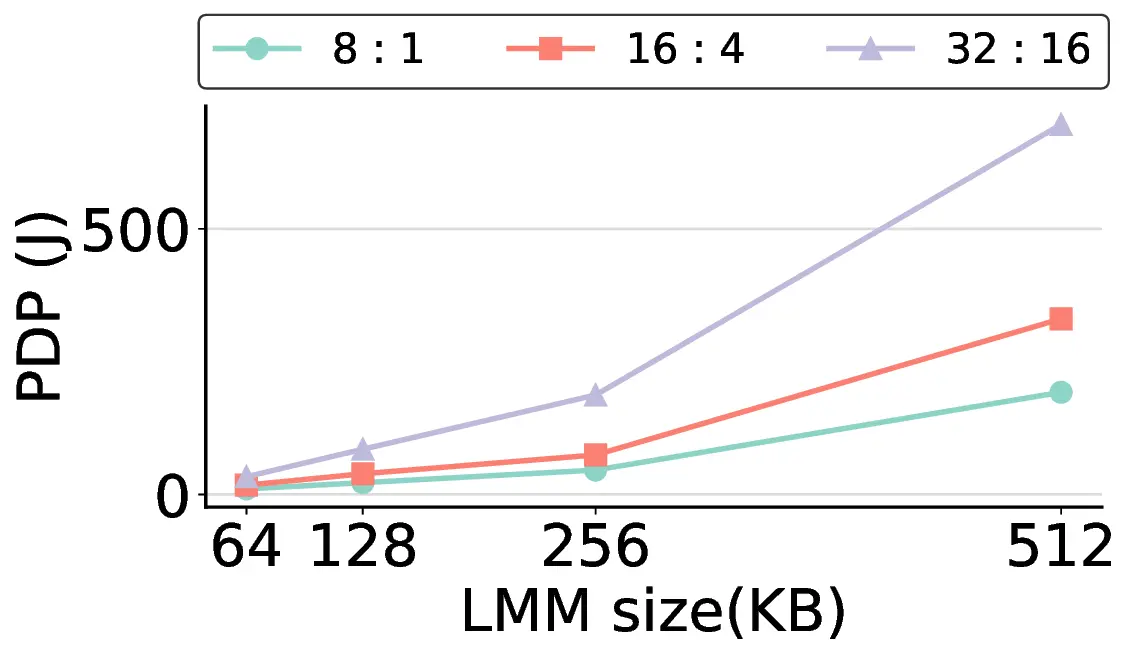
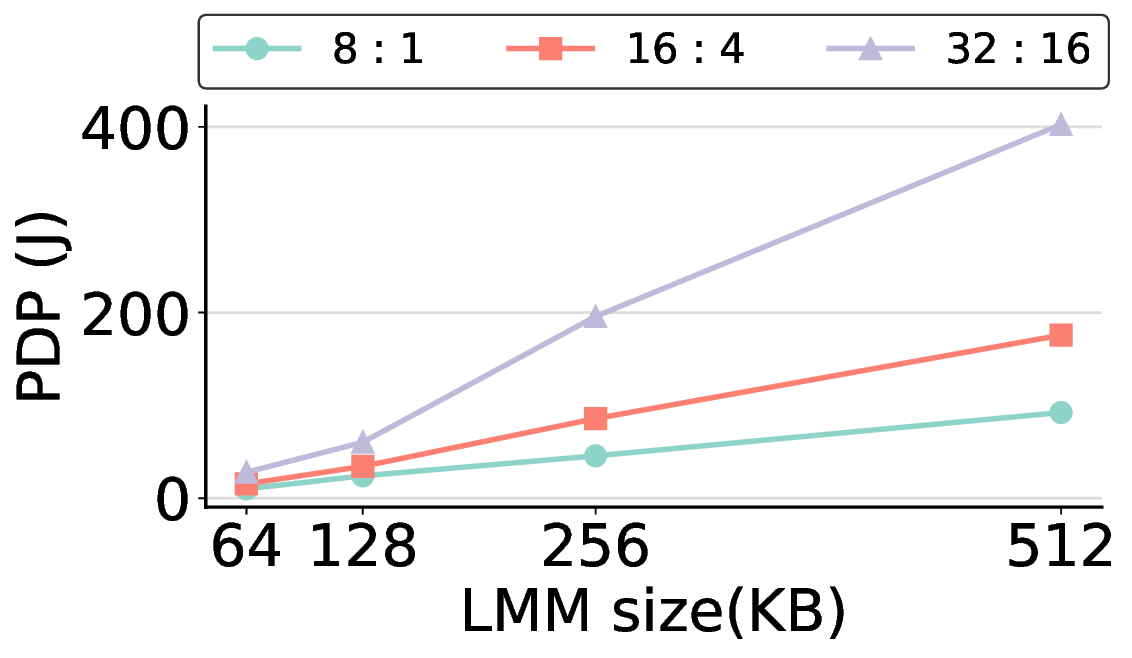
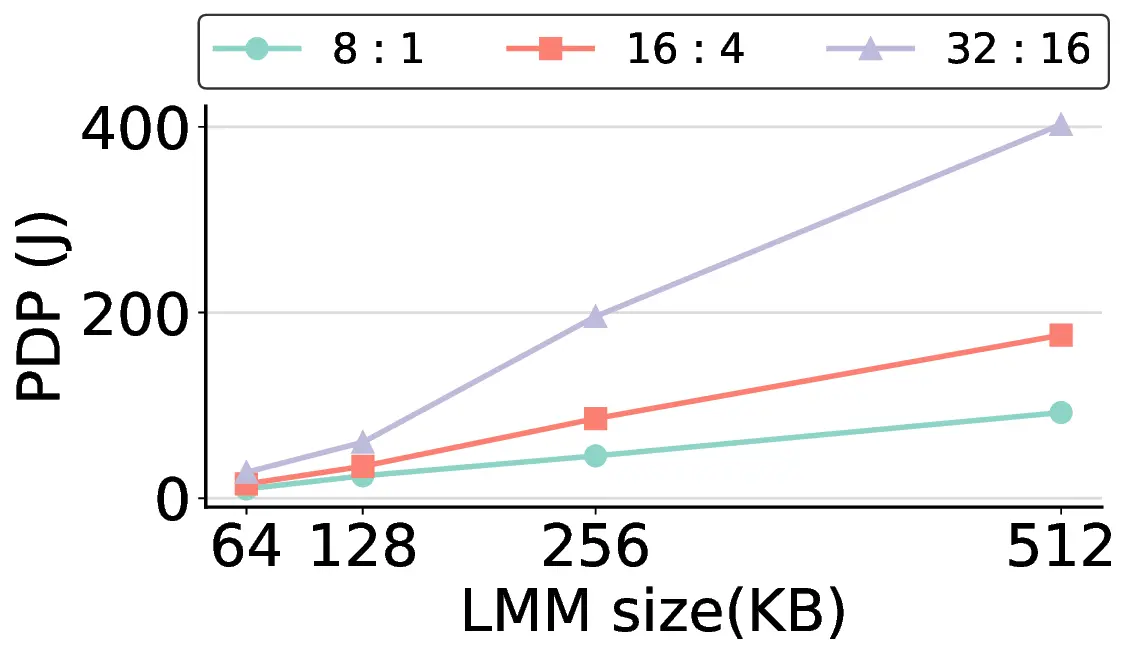
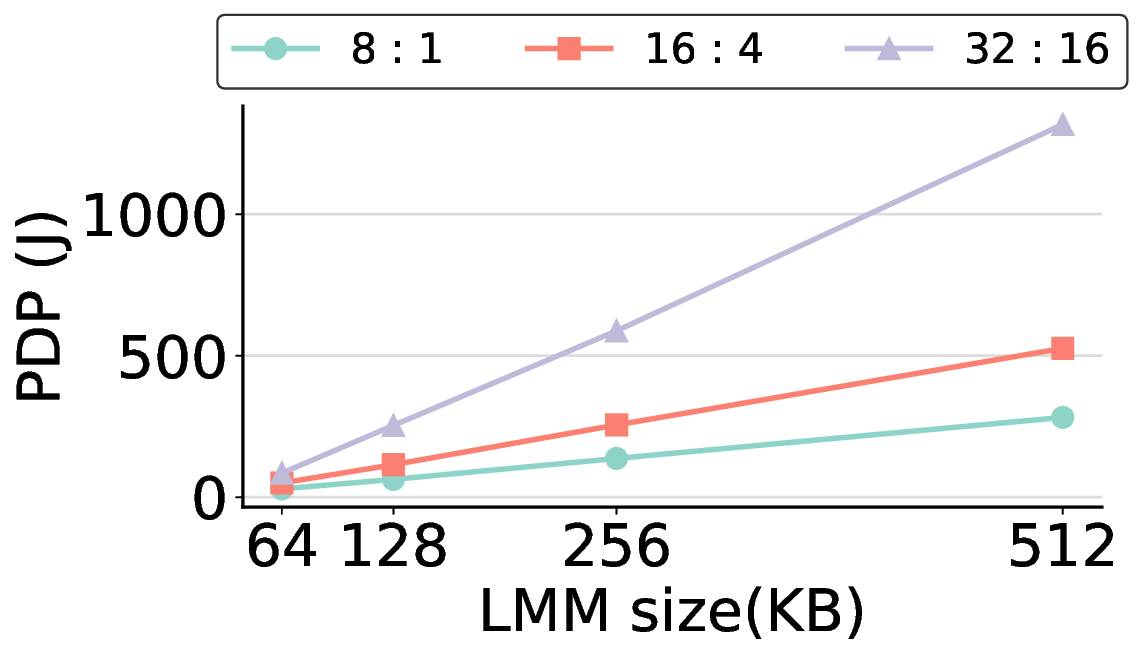
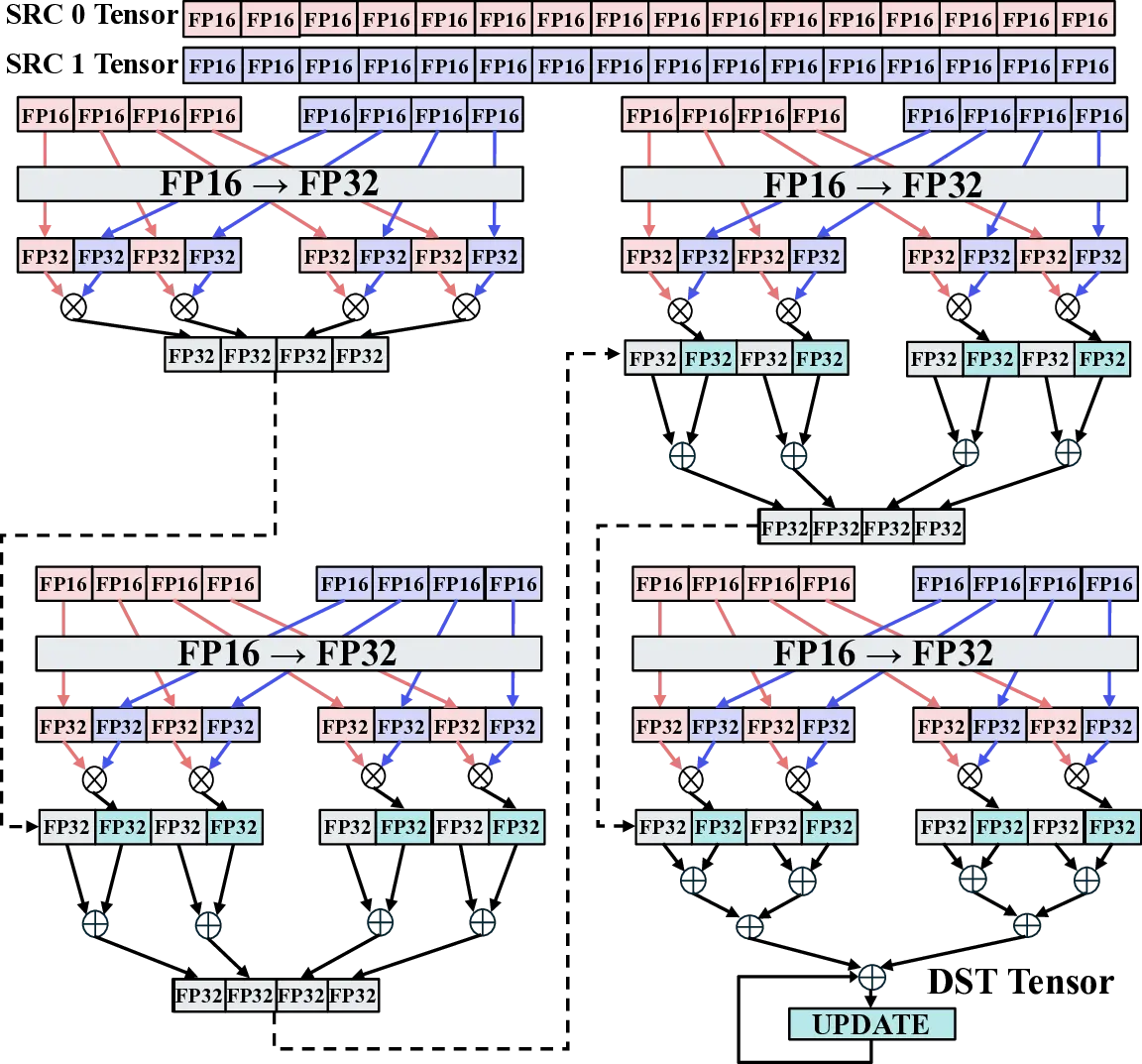
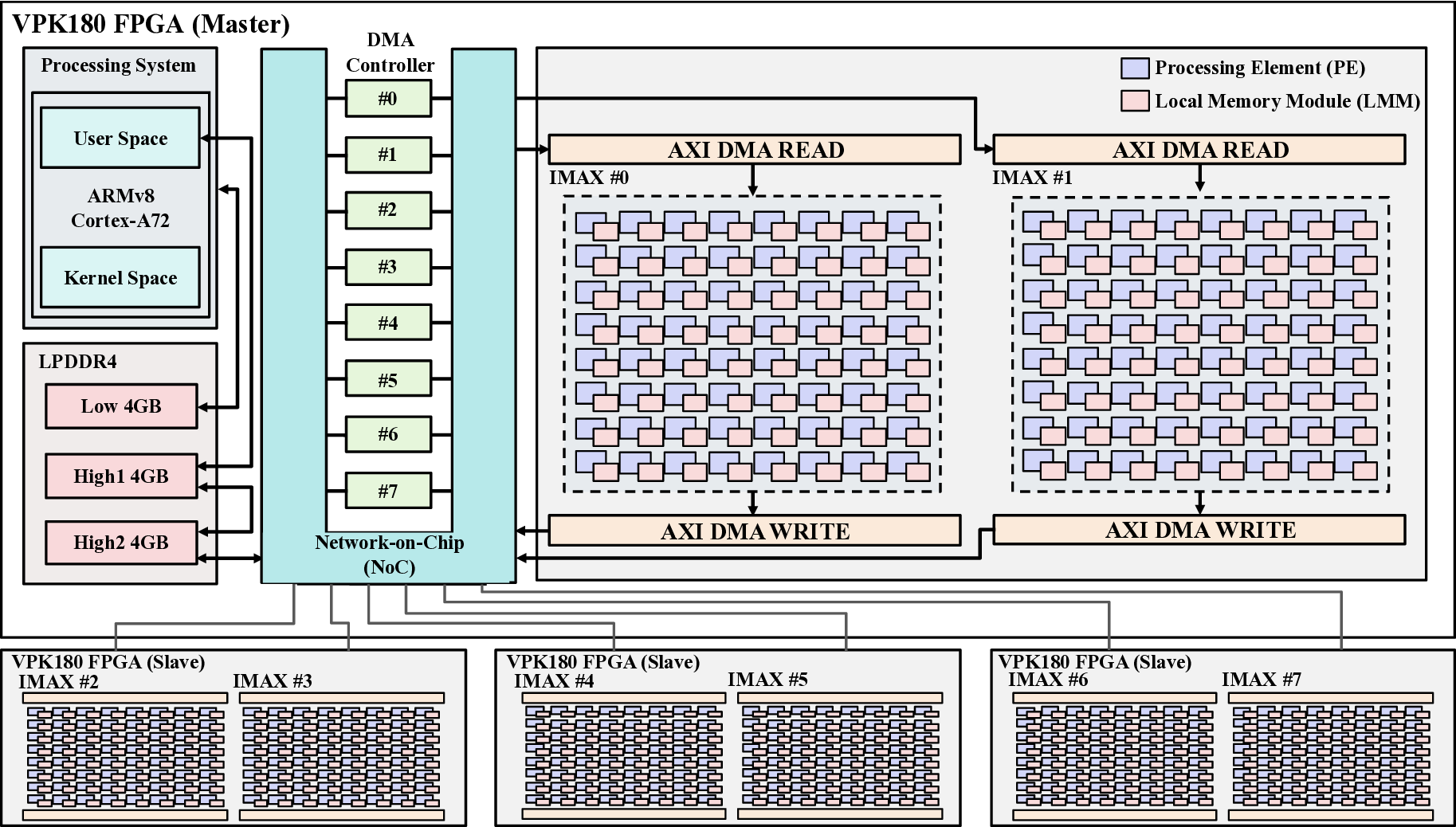
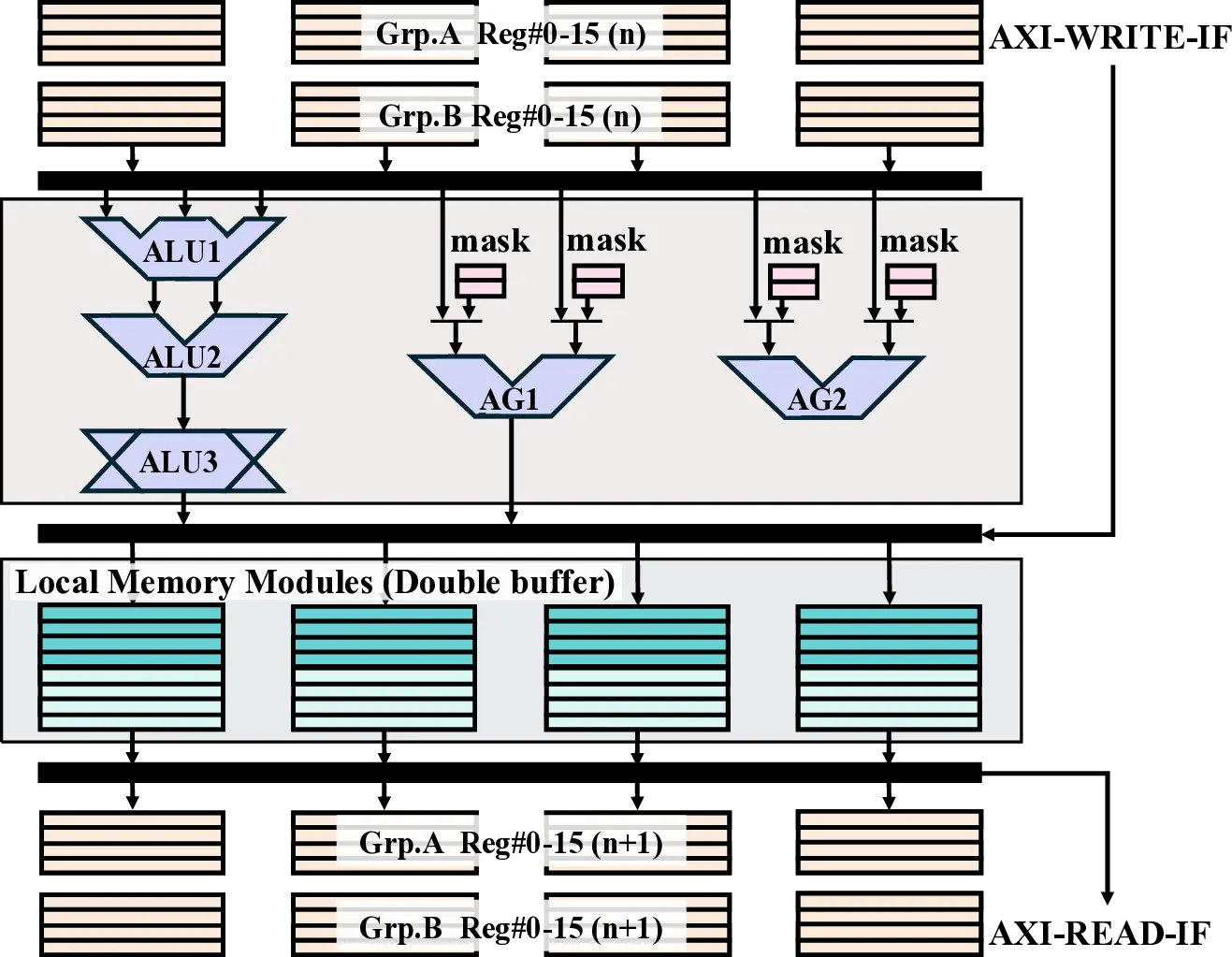
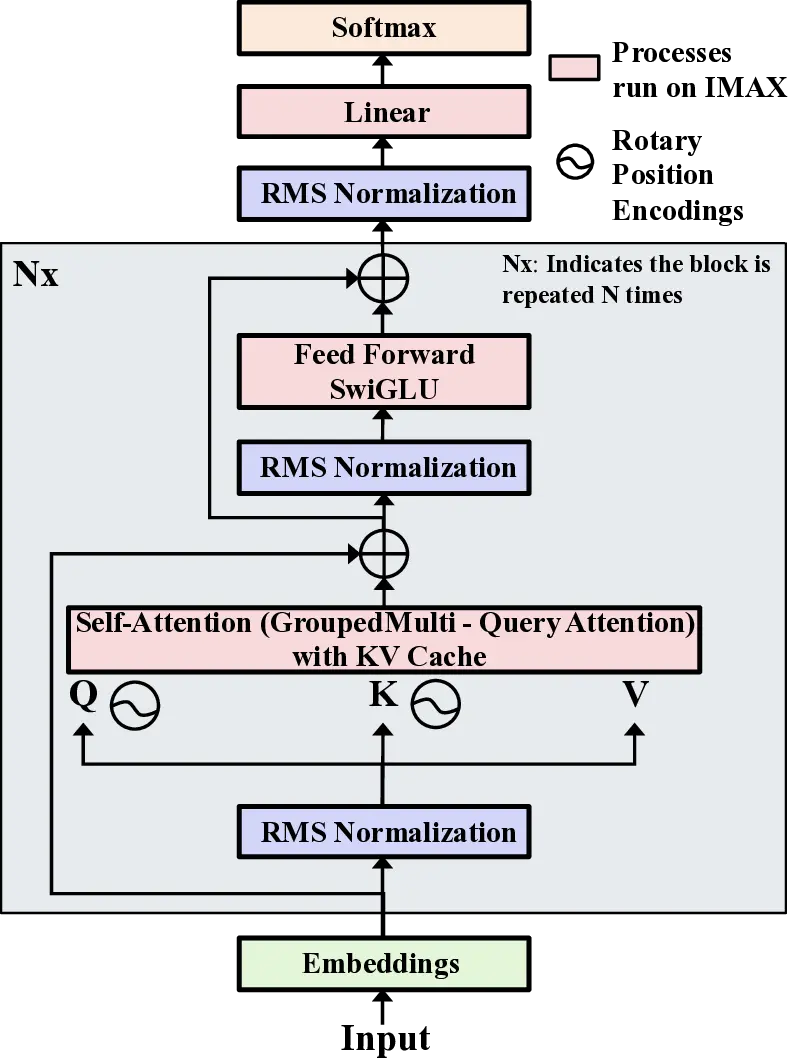
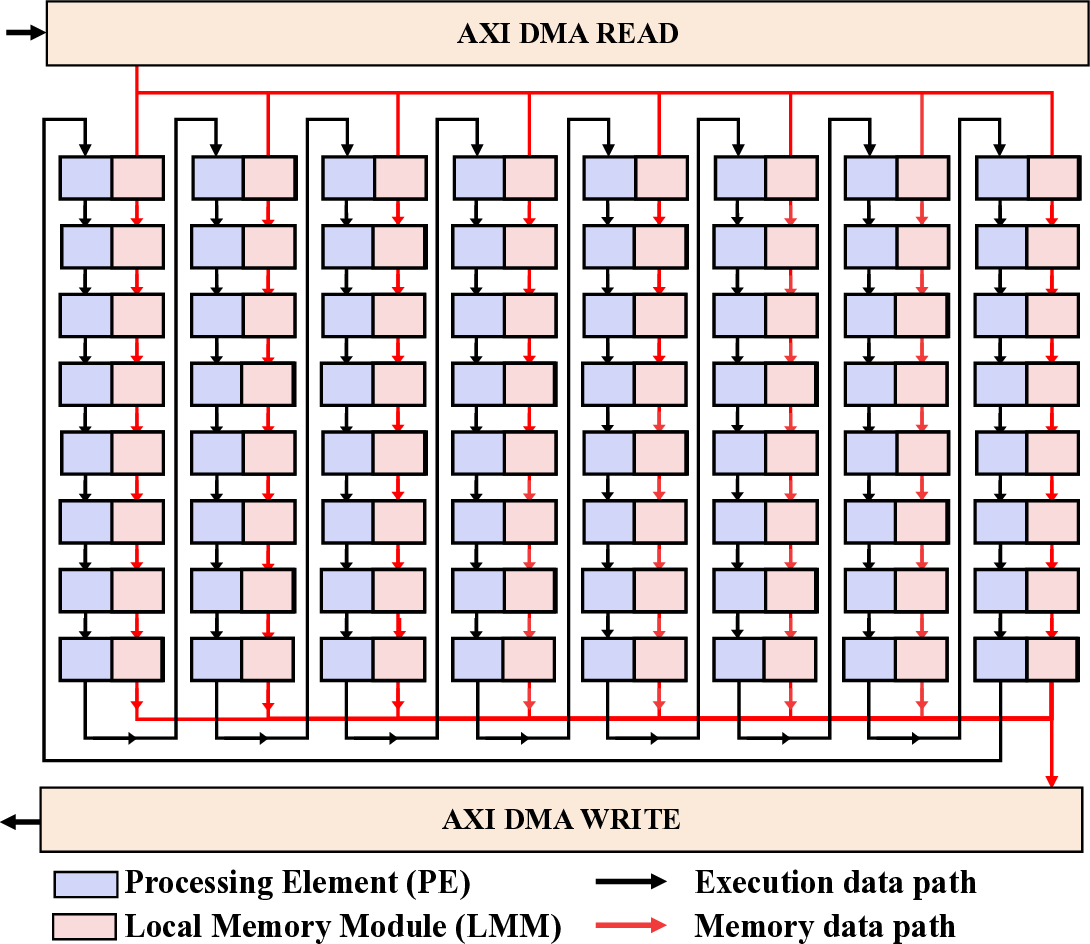
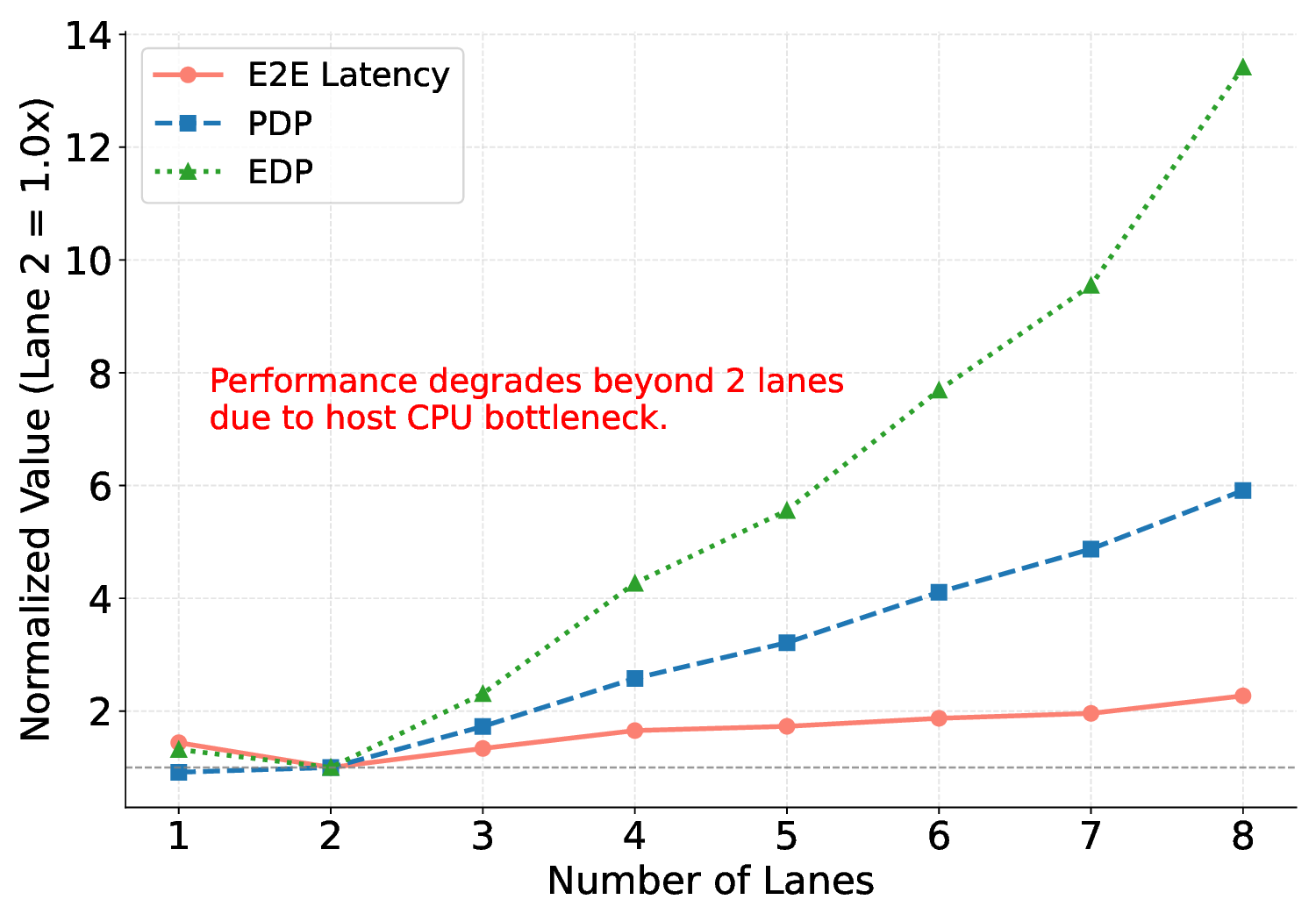
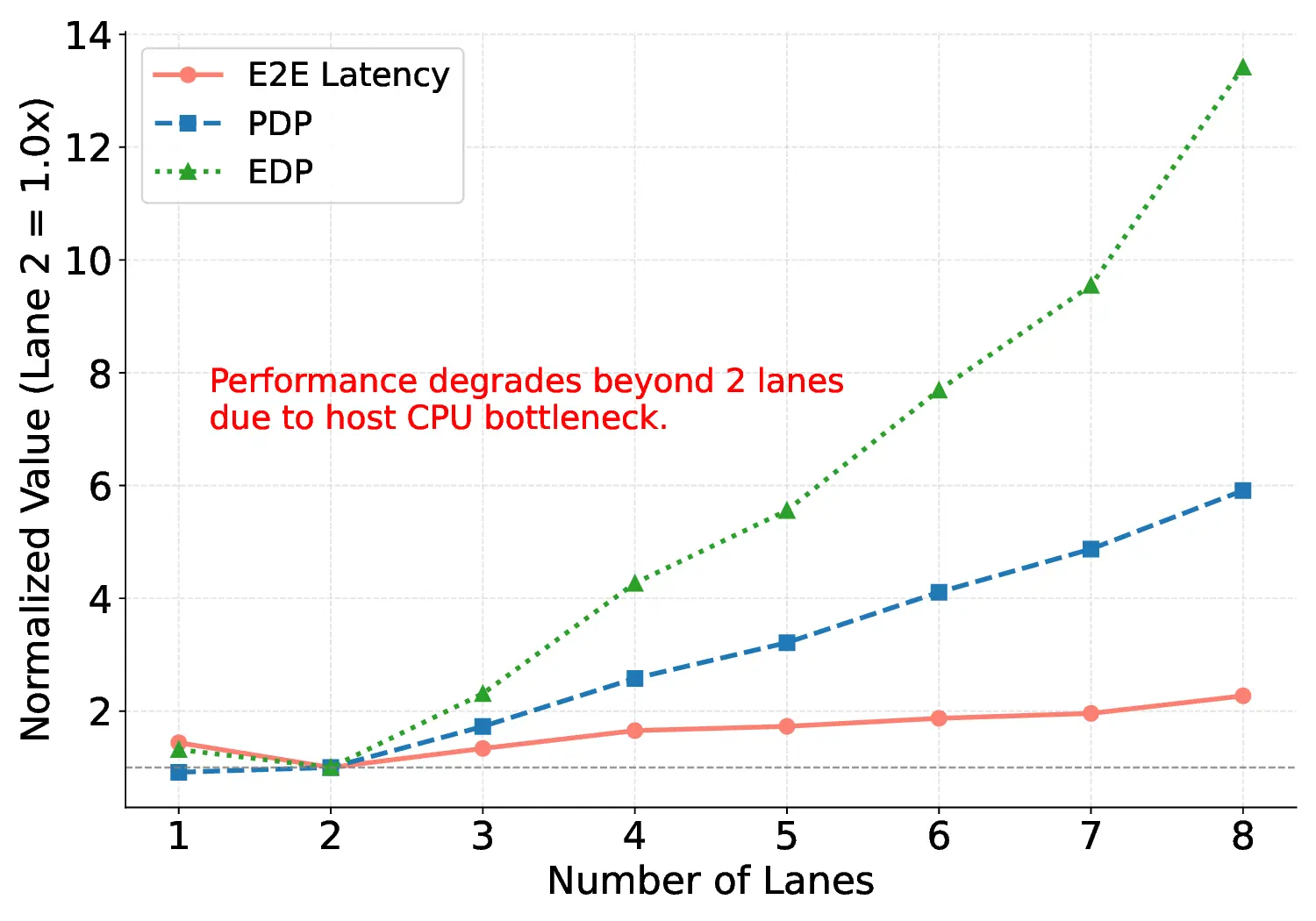
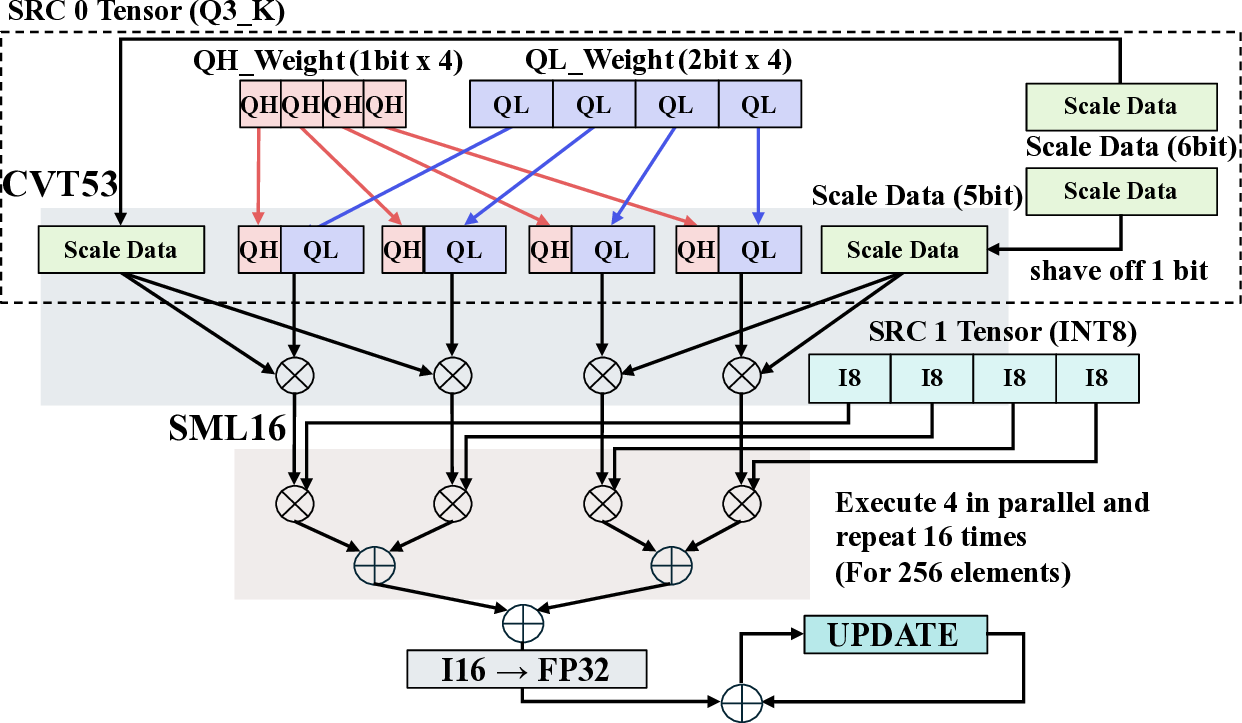
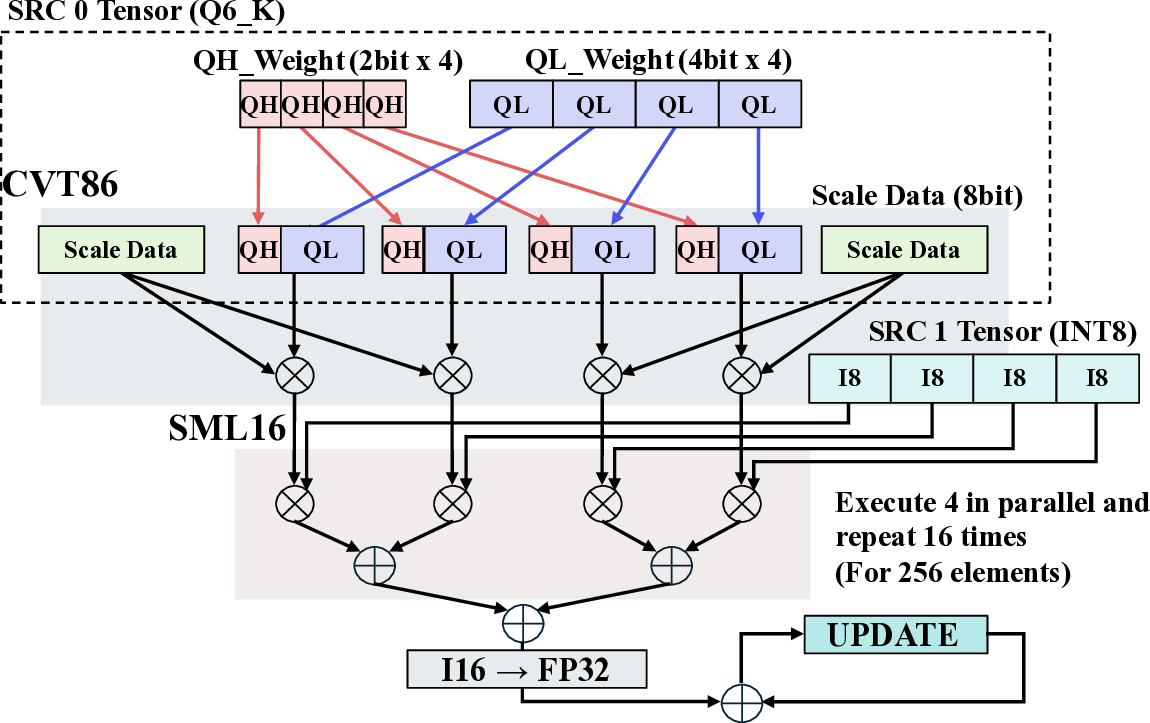
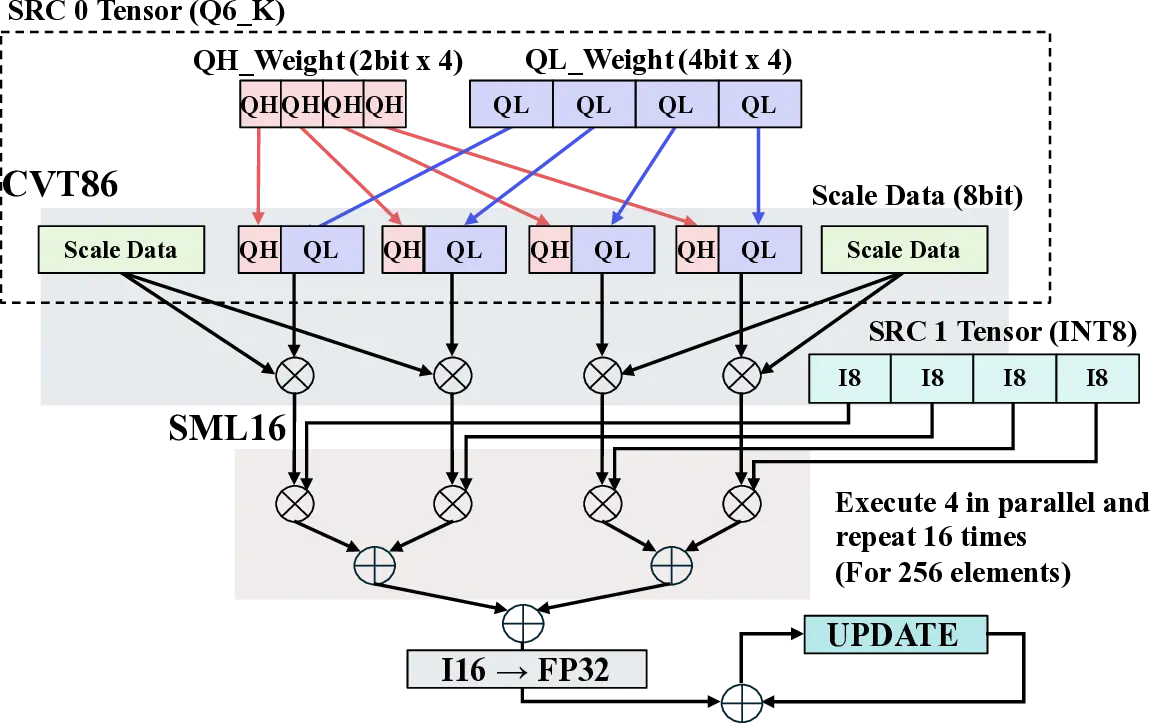
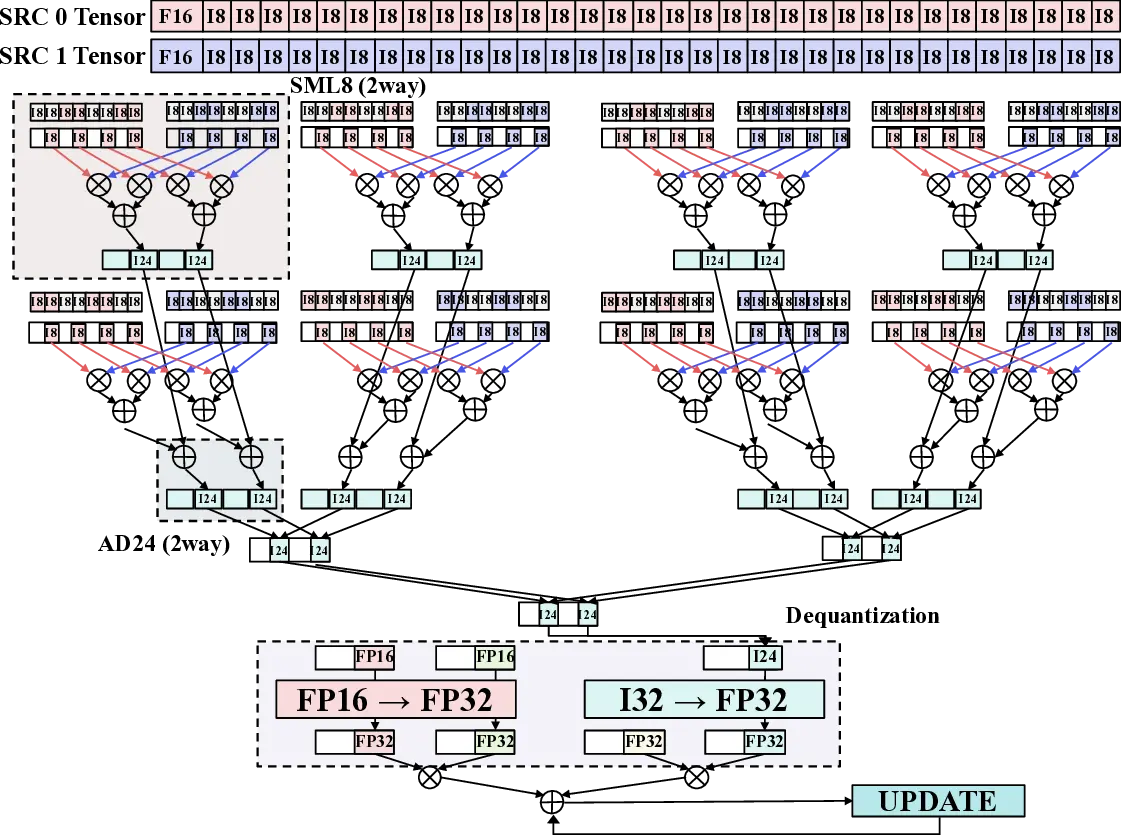
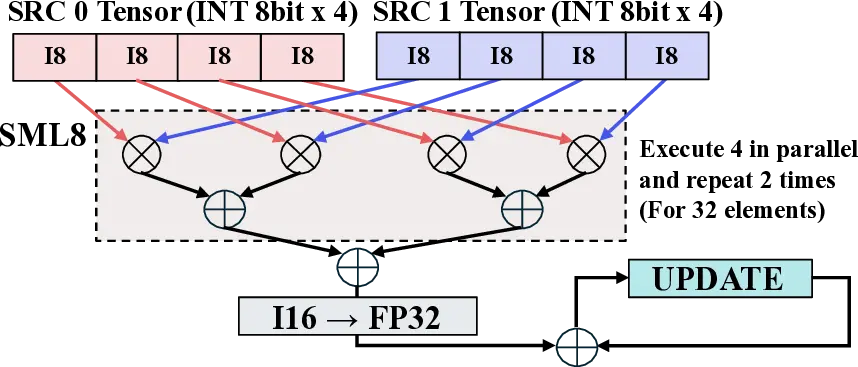
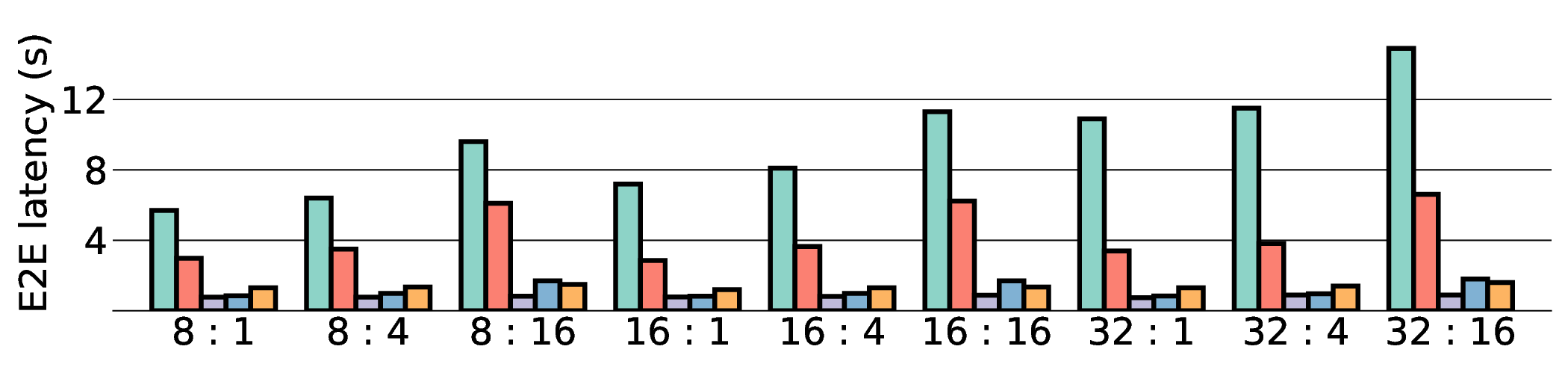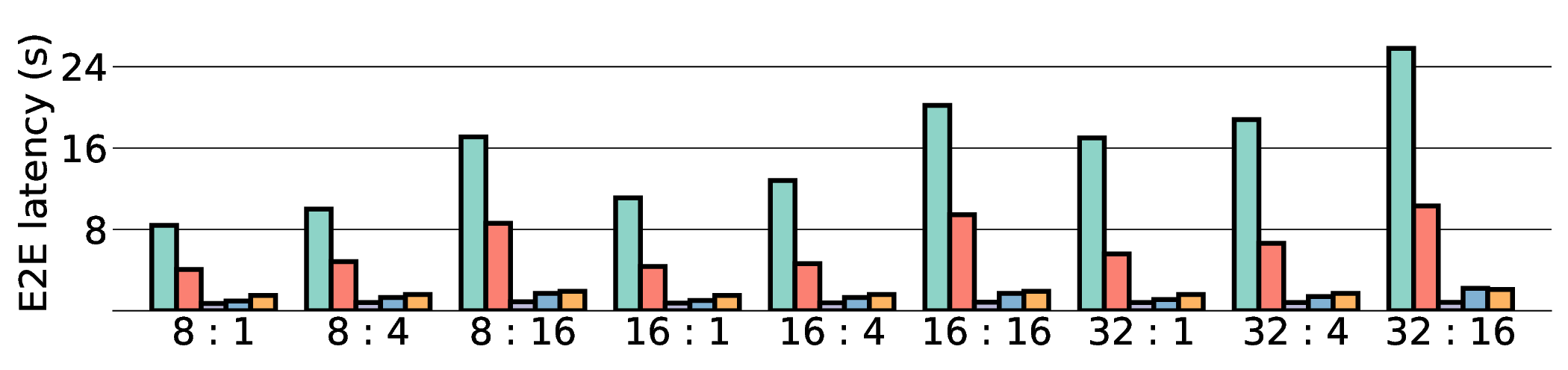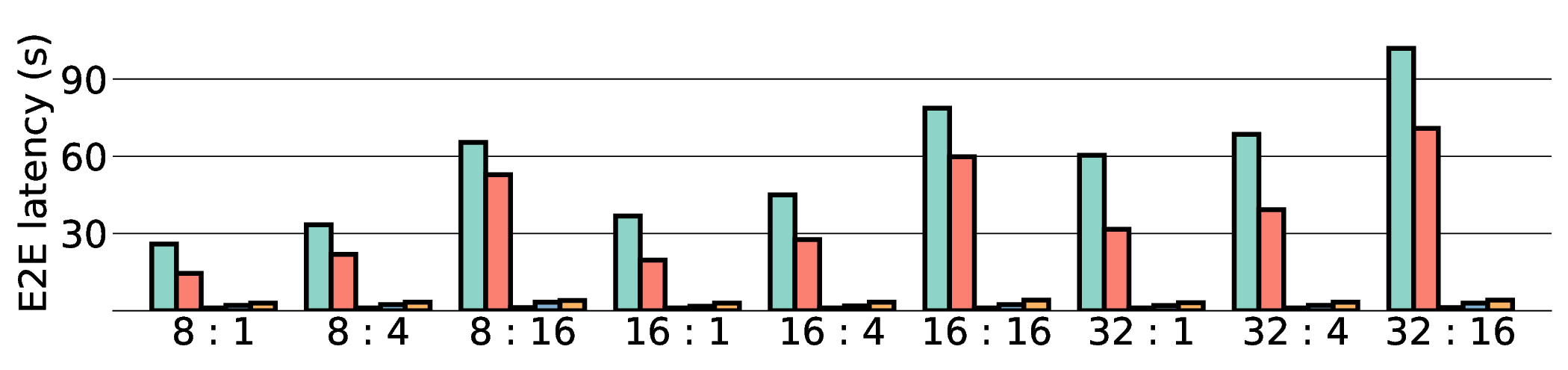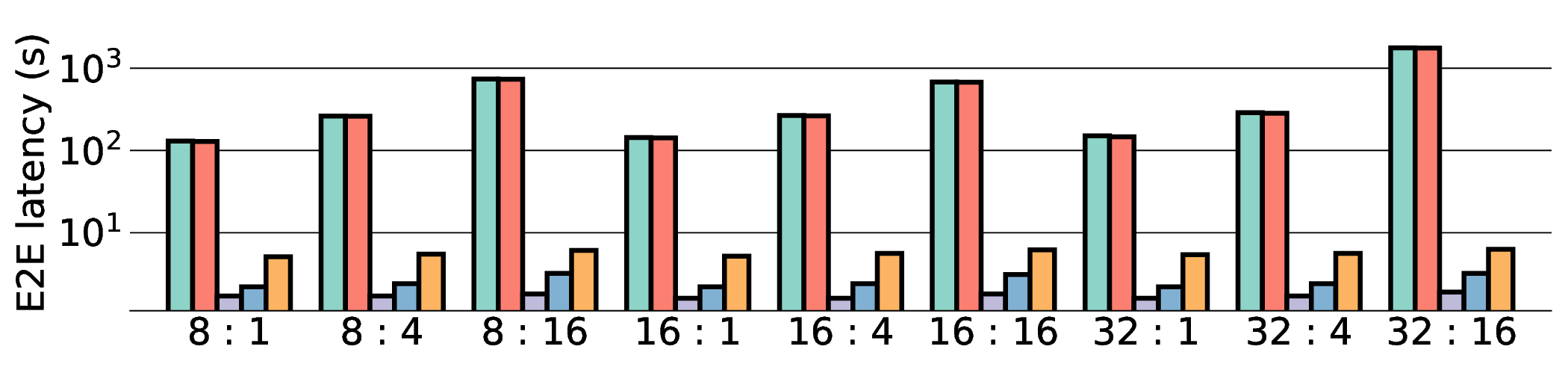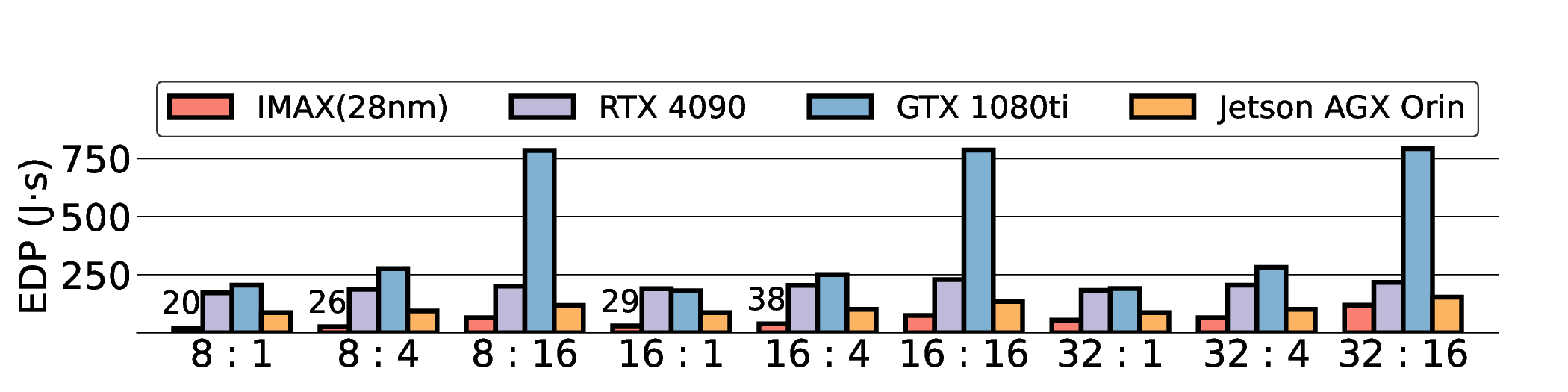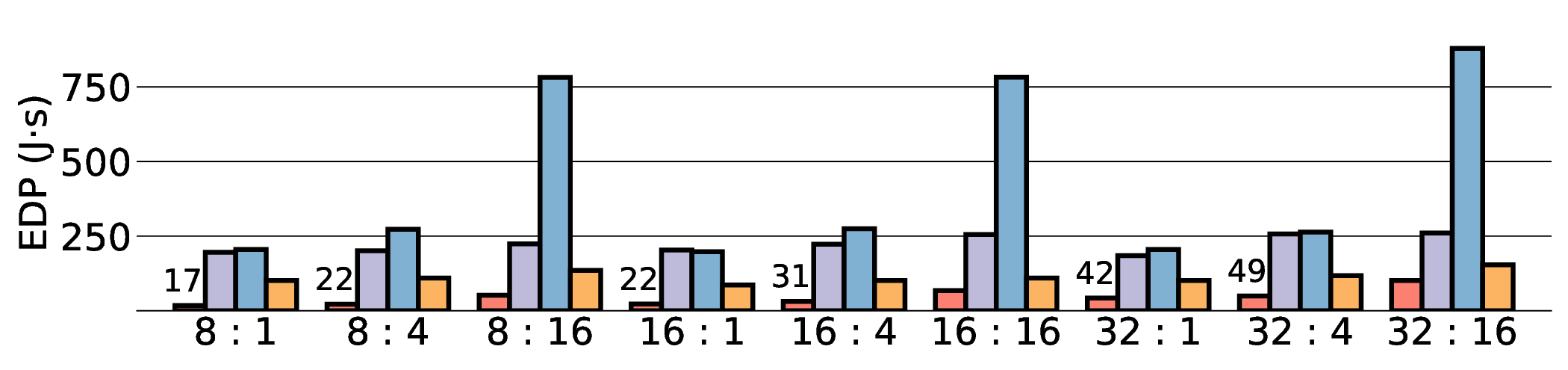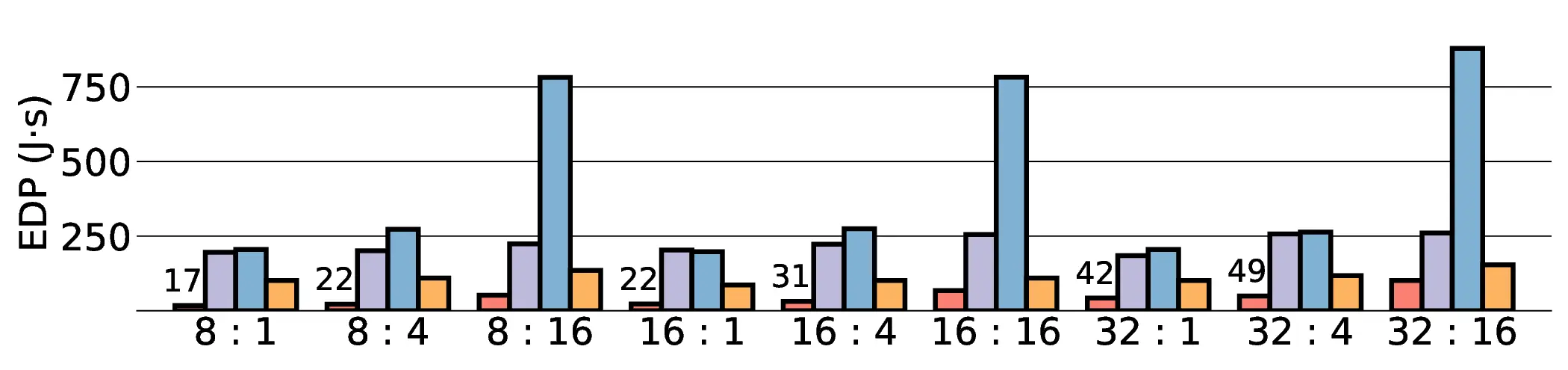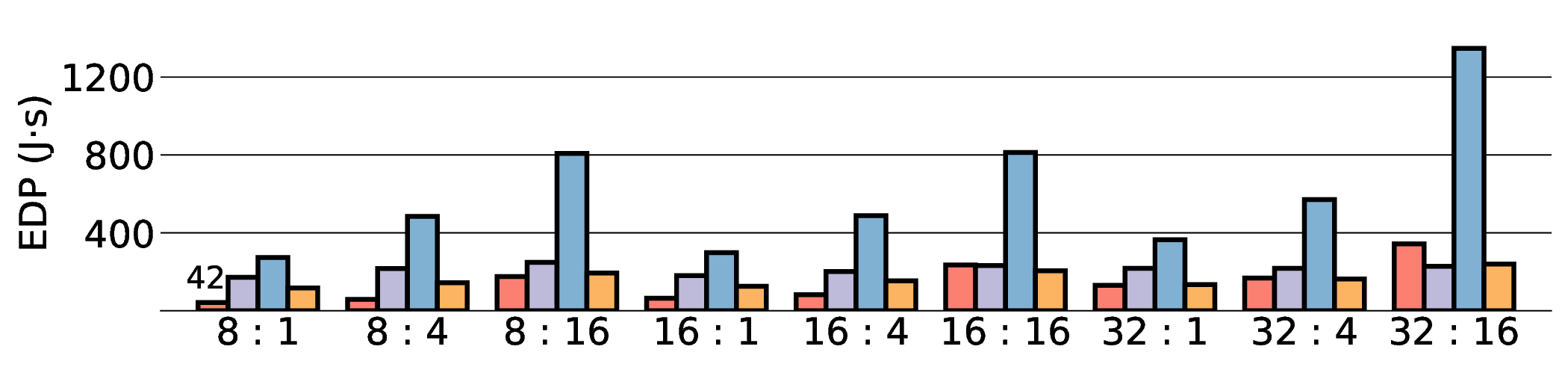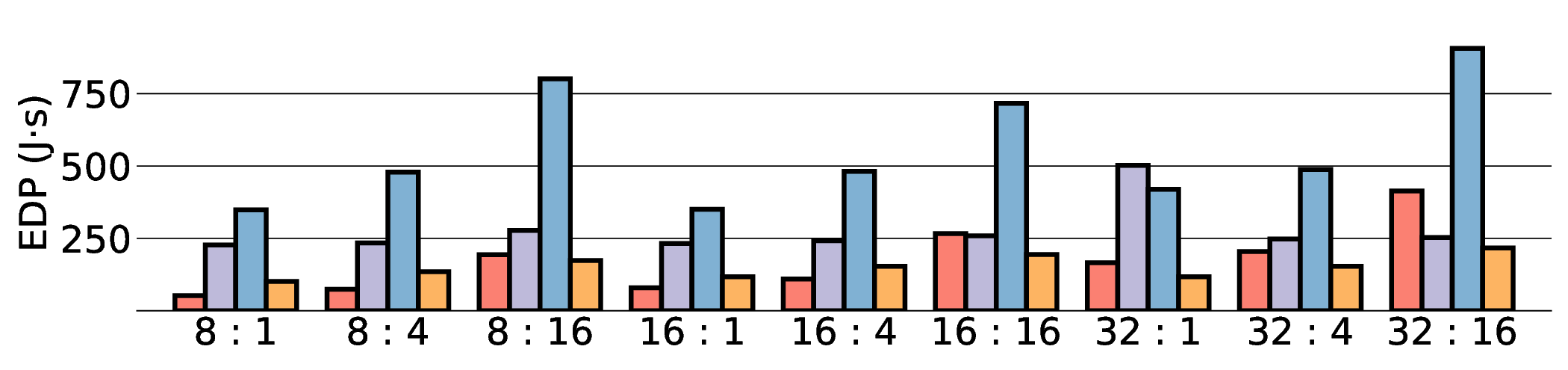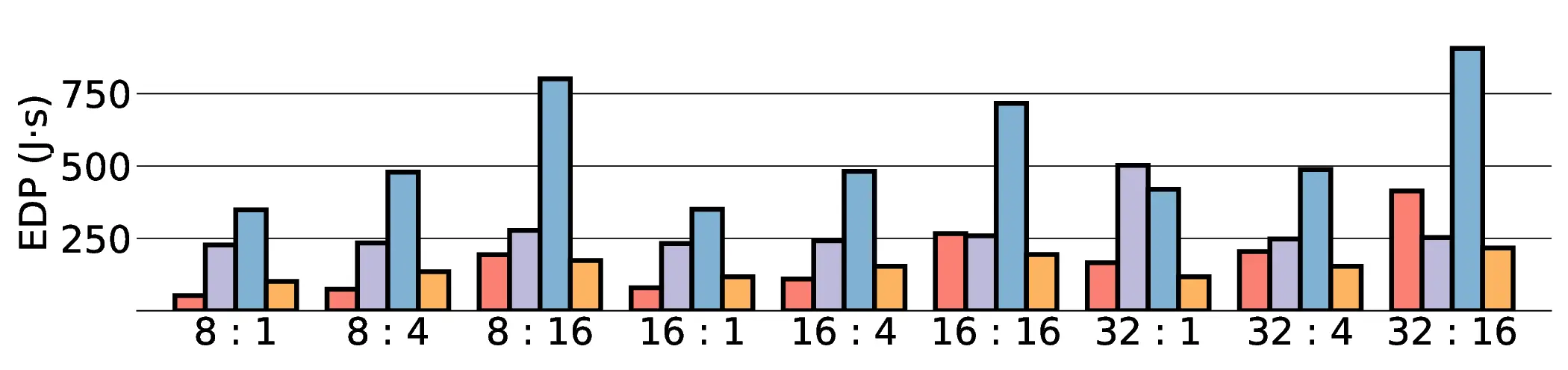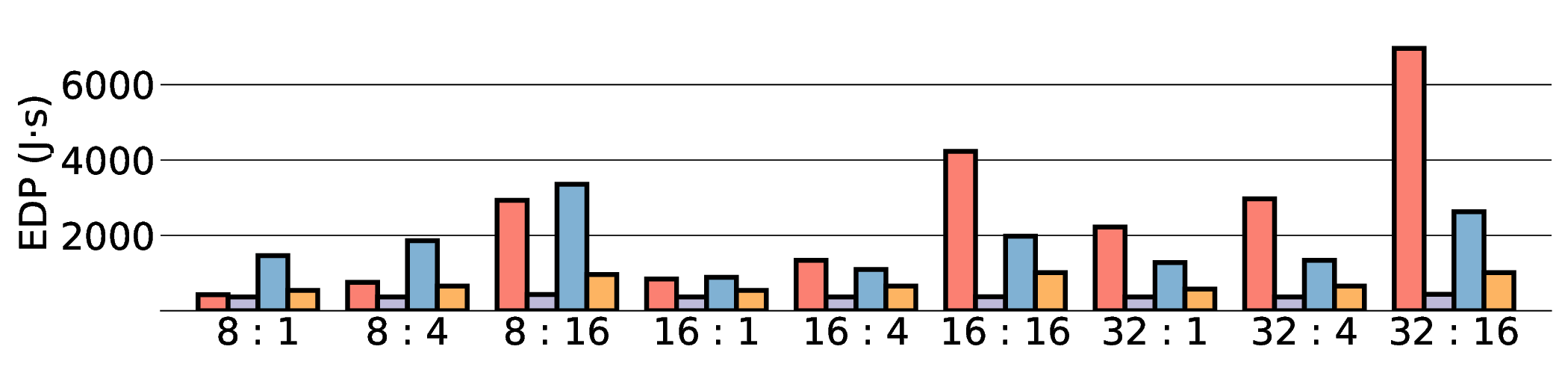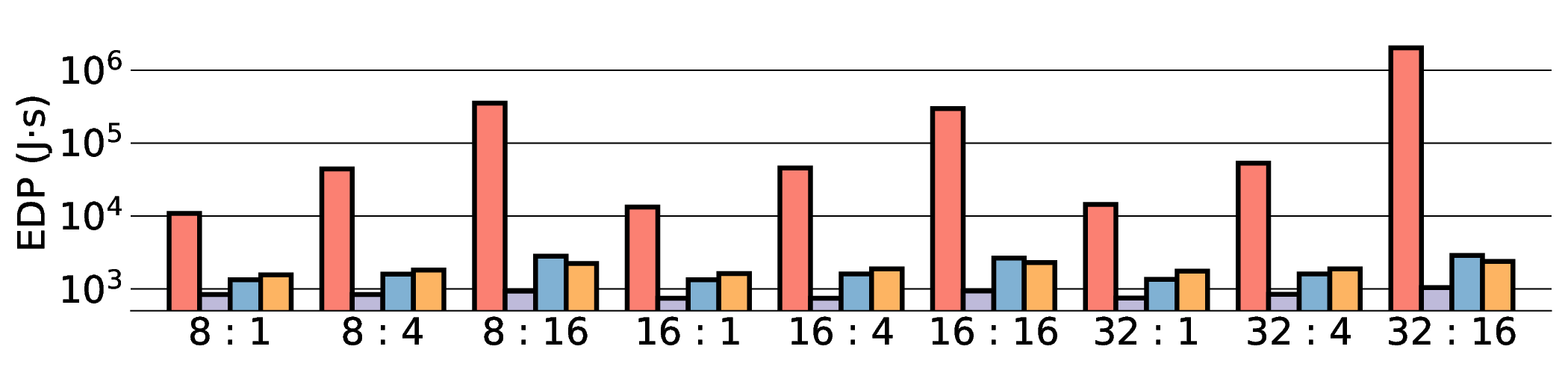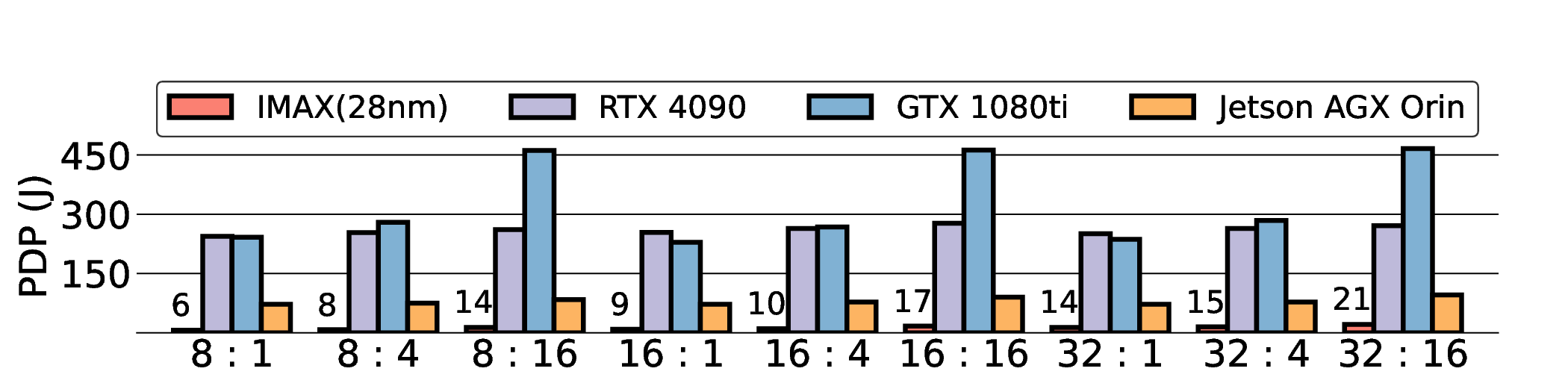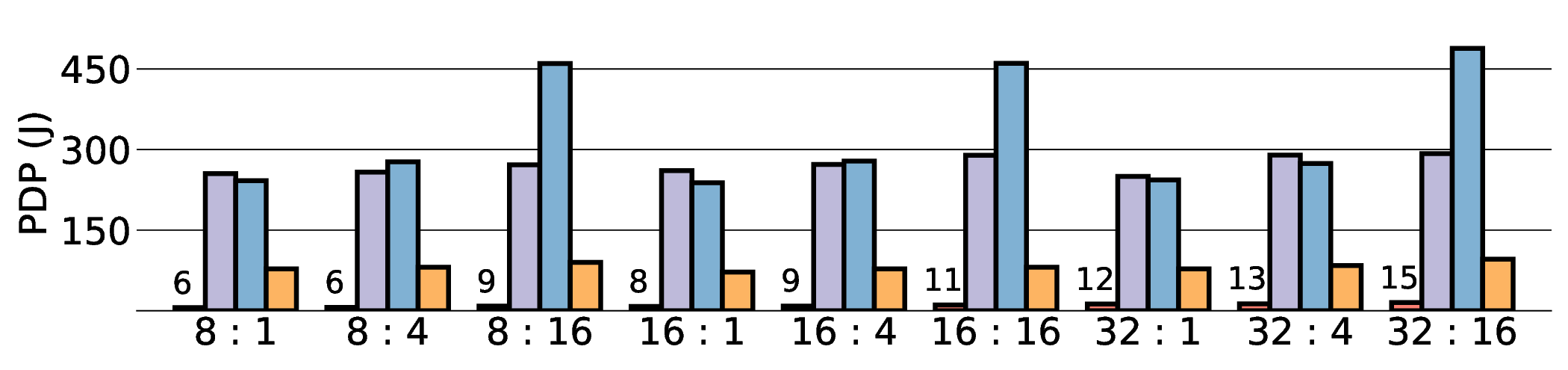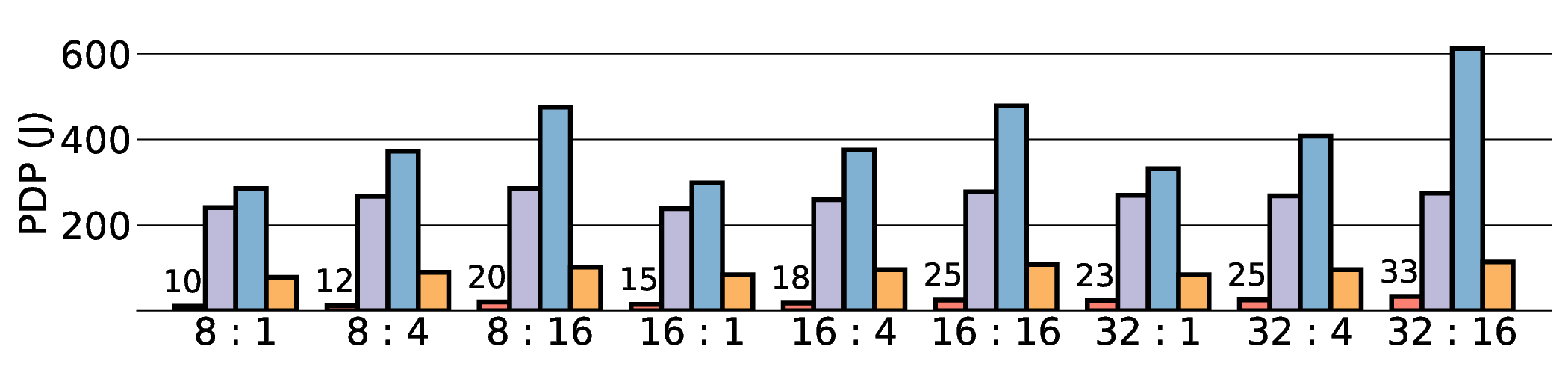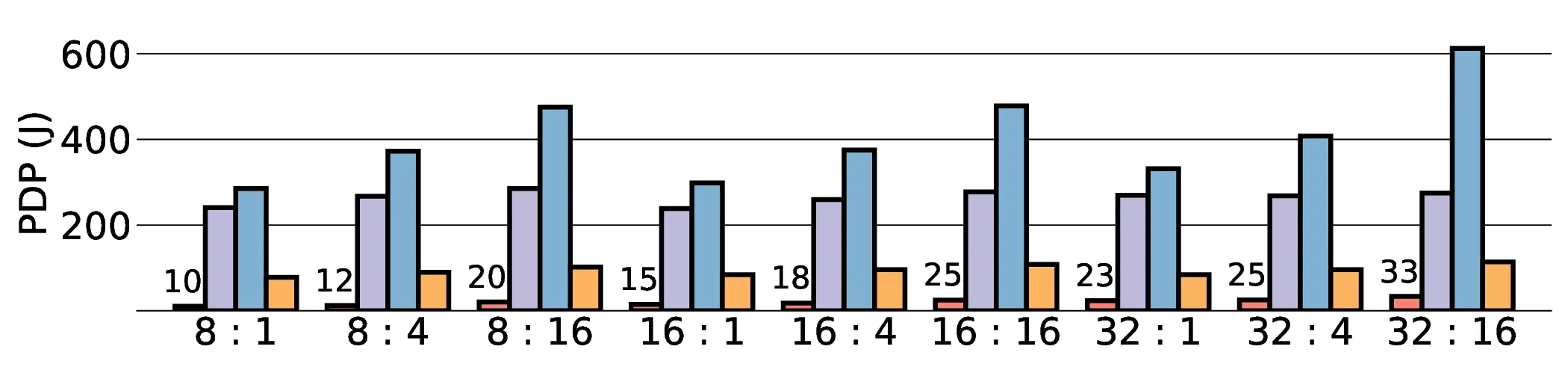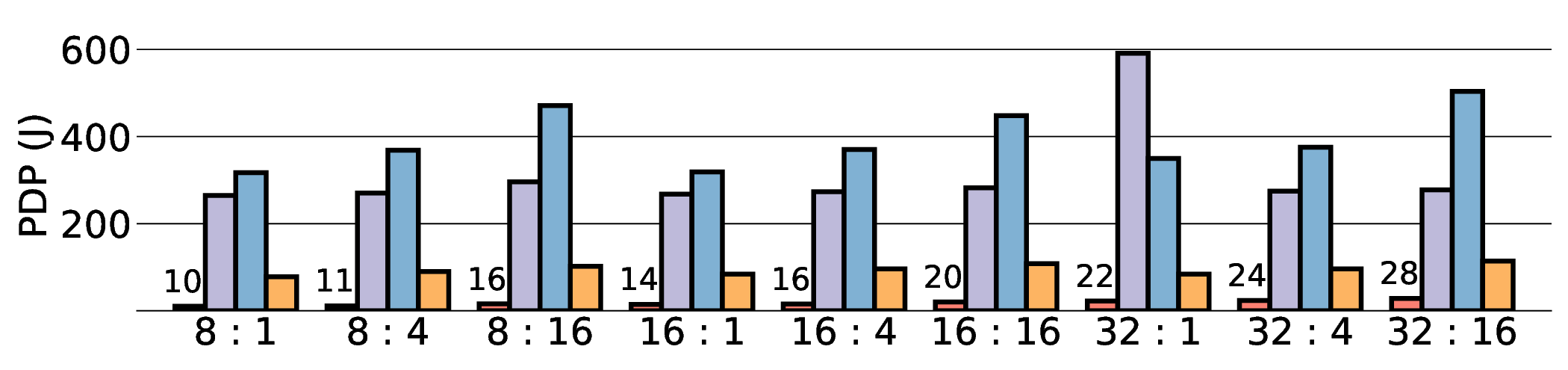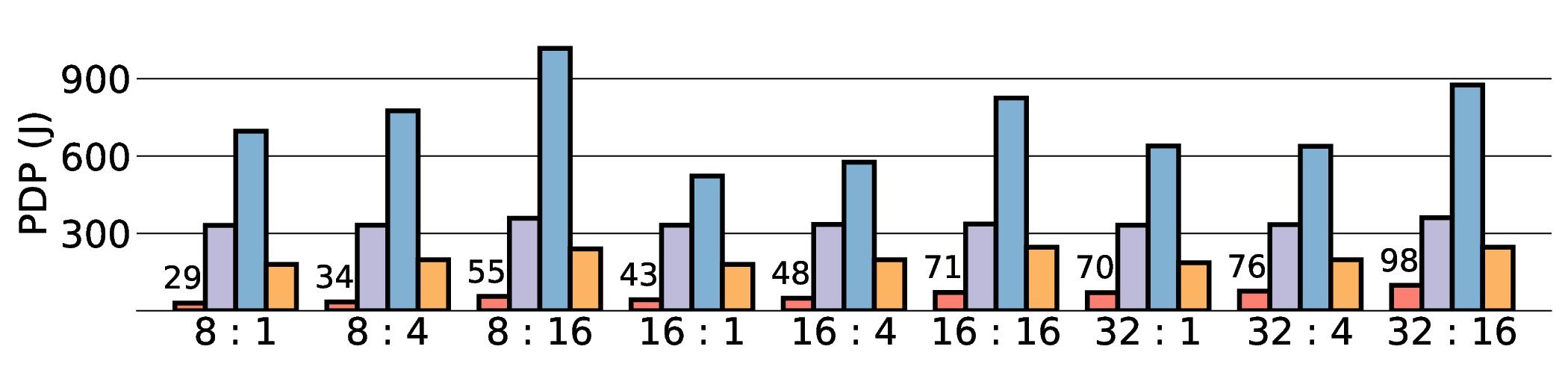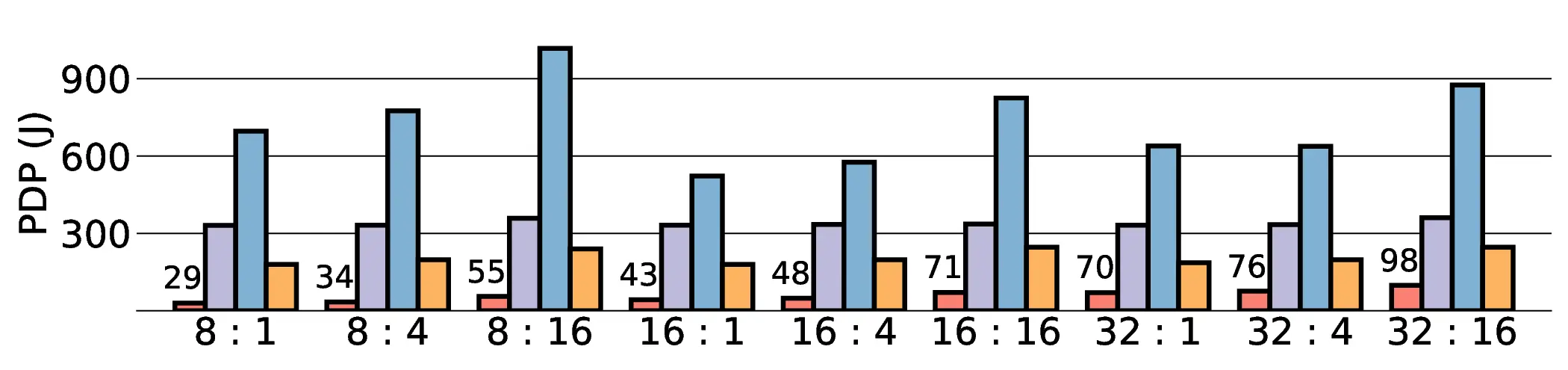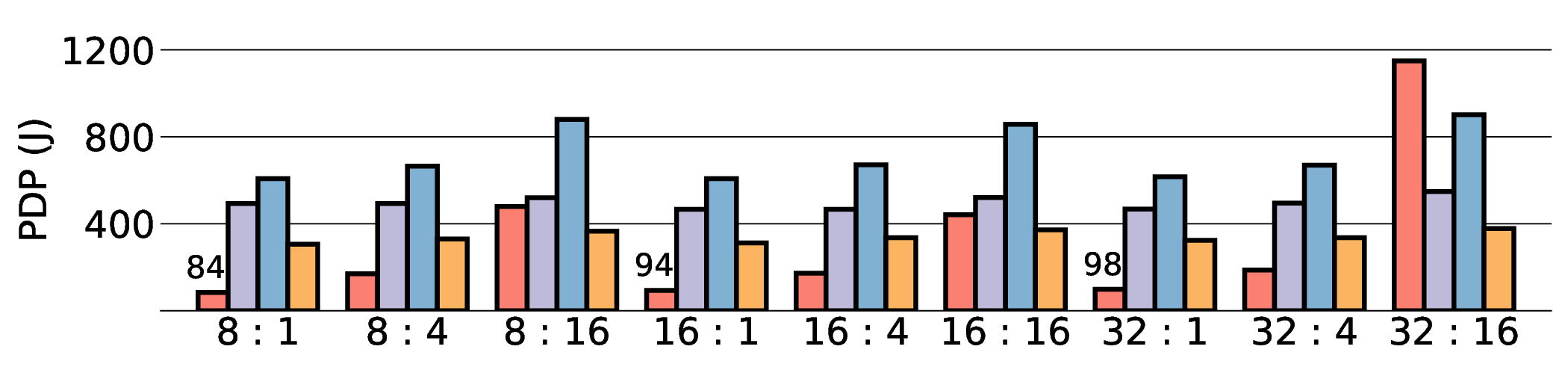Large Language Models (LLMs) demand substantial computational resources, resulting in high energy consumption on GPUs. To address this challenge, we focus on Coarse-Grained Reconfigurable Arrays (CGRAs) as an effective alternative that provides a trade-off between energy efficiency and programmability. This paper presents the first comprehensive, end-to-end evaluation of a non-AI-specialized Coarse-Grained Linear Array (CGLA) accelerator for the state-of-the-art Qwen3 LLM family. The architecture has a general-purpose, task-agnostic design, yet its flexible instruction set allows for domain-specific adaptations. This flexibility enables the architecture to achieve high efficiency for sustainable LLM inference. We assess the performance of our architecture on an FPGA prototype using the widely adopted llama.cpp framework. We then project its potential as a 28 nm ASIC and compare it against a high-performance GPU (NVIDIA RTX 4090) and an edge AI device (NVIDIA Jetson AGX Orin). While GPUs exhibit lower latency, our non-AI-specific accelerator achieves higher energy efficiency, improving the Power-Delay Product (PDP) by up to 44.4× and 13.6× compared with the RTX 4090 and Jetson, respectively. Similarly, it reduces the Energy-Delay Product (EDP) by up to 11.5× compared to the high-performance GPU, demonstrating a favorable performance-energy trade-off. Critically, our system-level analysis identifies host-accelerator data transfer as the primary performance bottleneck, a factor often overlooked in kernel-level studies. These findings provide design guidance for next-generation LLM accelerators. This work validates CGRAs as a suitable platform for LLM inference in power-constrained environments, without being confined to specific algorithms.
Deep Dive into Efficient Kernel Mapping and Comprehensive System Evaluation of LLM Acceleration on a CGLA.
Large Language Models (LLMs) demand substantial computational resources, resulting in high energy consumption on GPUs. To address this challenge, we focus on Coarse-Grained Reconfigurable Arrays (CGRAs) as an effective alternative that provides a trade-off between energy efficiency and programmability. This paper presents the first comprehensive, end-to-end evaluation of a non-AI-specialized Coarse-Grained Linear Array (CGLA) accelerator for the state-of-the-art Qwen3 LLM family. The architecture has a general-purpose, task-agnostic design, yet its flexible instruction set allows for domain-specific adaptations. This flexibility enables the architecture to achieve high efficiency for sustainable LLM inference. We assess the performance of our architecture on an FPGA prototype using the widely adopted llama.cpp framework. We then project its potential as a 28 nm ASIC and compare it against a high-performance GPU (NVIDIA RTX 4090) and an edge AI device (NVIDIA Jetson AGX Orin). While GPU
Received 8 October 2025, accepted 19 November 2025.
Digital Object Identifier 10.1109/ACCESS.2025.3636266
Efficient Kernel Mapping and
Comprehensive System Evaluation of
LLM Acceleration on a CGLA
TAKUTO ANDO
, (Member, IEEE), YU ETO
,
AYUMU TAKEUCHI
and YASUHIKO NAKASHIMA
, (Member, IEEE)
Nara Institute of Science and Technology (NAIST), Ikoma, Nara 630-0192, Japan
Corresponding author: Takuto ANDO (e-mail: antaku7585@gmail.com).
This work was supported by the JST-ALCA-Next Program (Grant Number JPMJAN23F4) and JSPS KAKENHI (Grant No. 22H00515).
We also acknowledge the activities of VDEC, The University of Tokyo, in collaboration with NIHON SYNOPSYS G.K.
ABSTRACT
Large Language Models (LLMs) demand substantial computational resources, resulting in high energy con-
sumption on GPUs. To address this challenge, we focus on Coarse-Grained Reconfigurable Arrays (CGRAs)
as an effective alternative that provides a trade-off between energy efficiency and programmability. This
paper presents the first comprehensive, end-to-end evaluation of a non-AI-specialized Coarse-Grained
Linear Array (CGLA) accelerator for the state-of-the-art Qwen3 LLM family. The architecture has a
general-purpose, task-agnostic design, yet its flexible instruction set allows for domain-specific adaptations.
This flexibility enables the architecture to achieve high efficiency for sustainable LLM inference. We assess
the performance of our architecture on an FPGA prototype using the widely adopted llama.cpp framework.
We then project its potential as a 28 nm ASIC and compare it against a high-performance GPU (NVIDIA
RTX 4090) and an edge AI device (NVIDIA Jetson AGX Orin). While GPUs exhibit lower latency, our
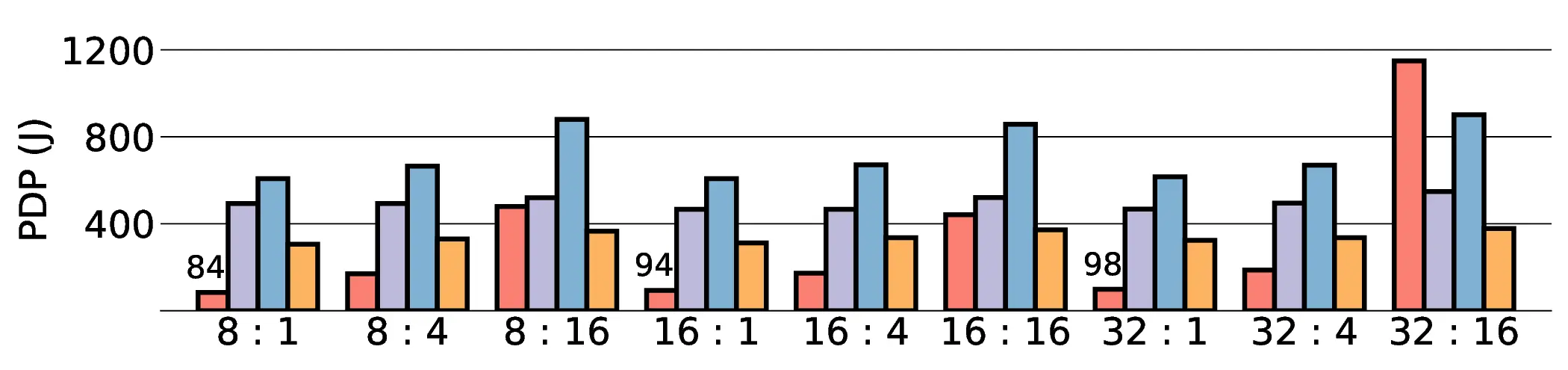
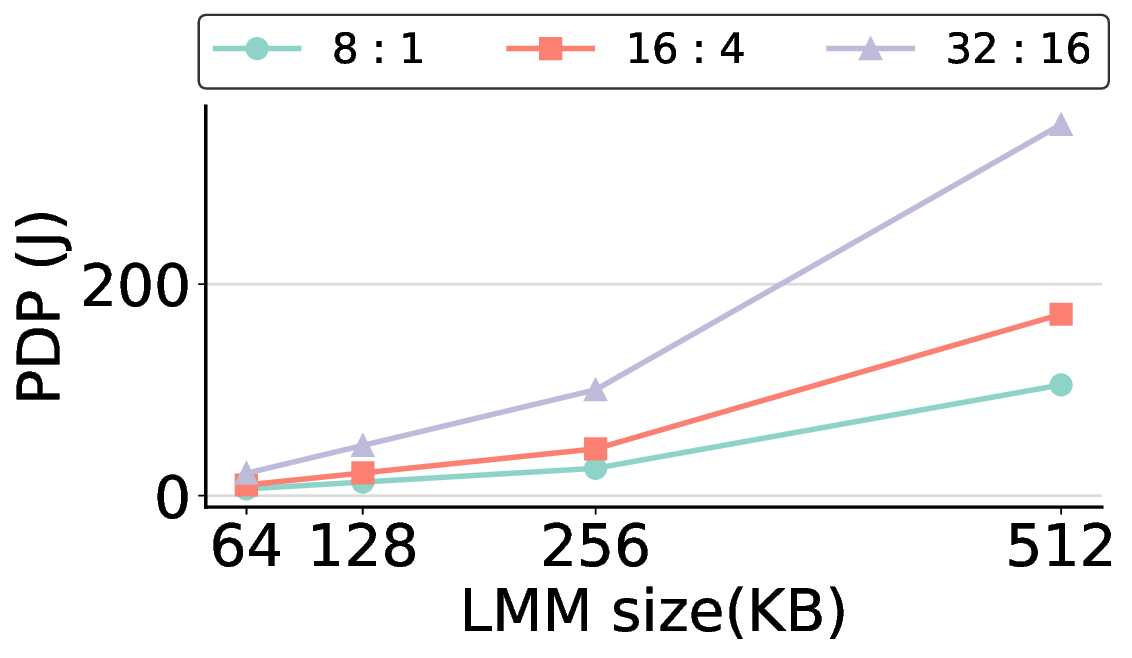
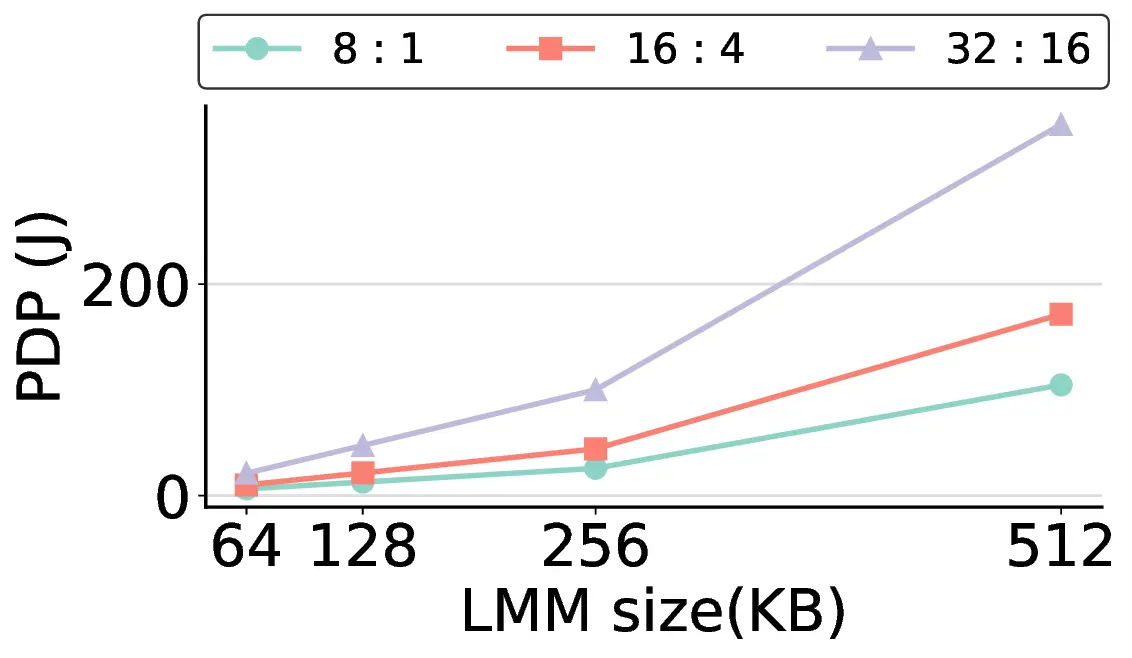
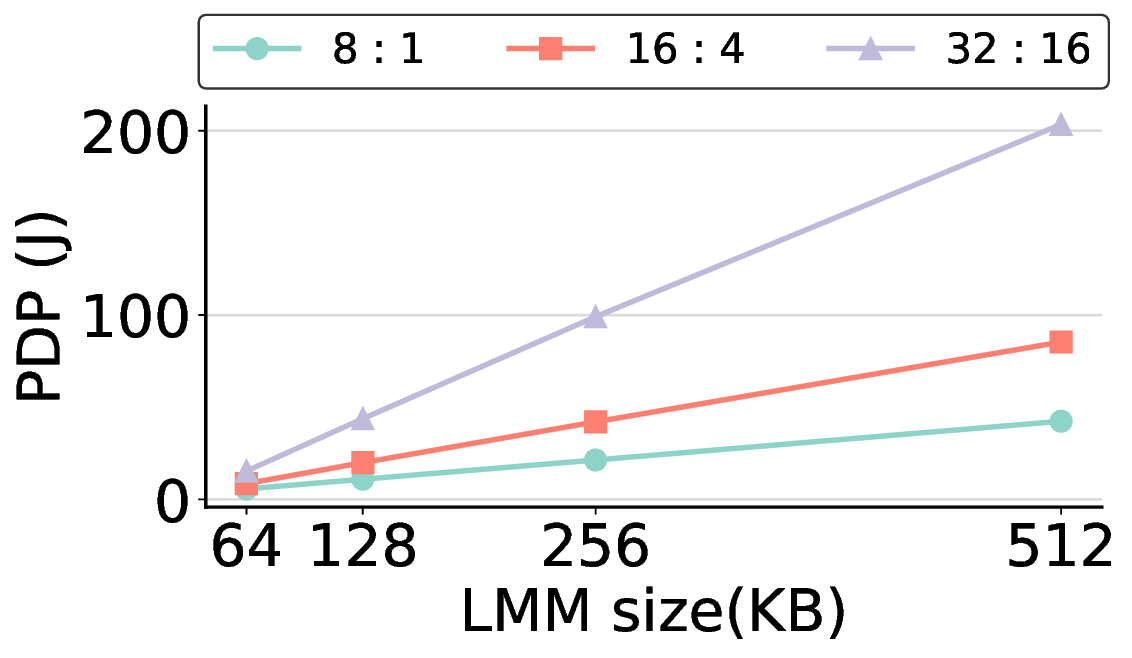
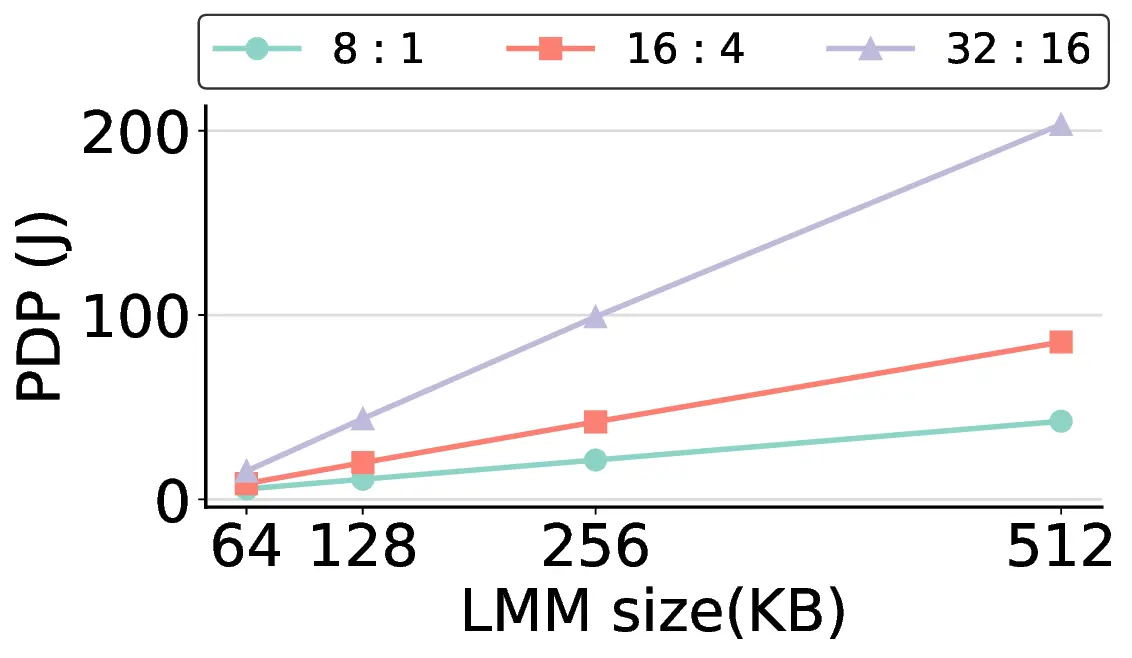
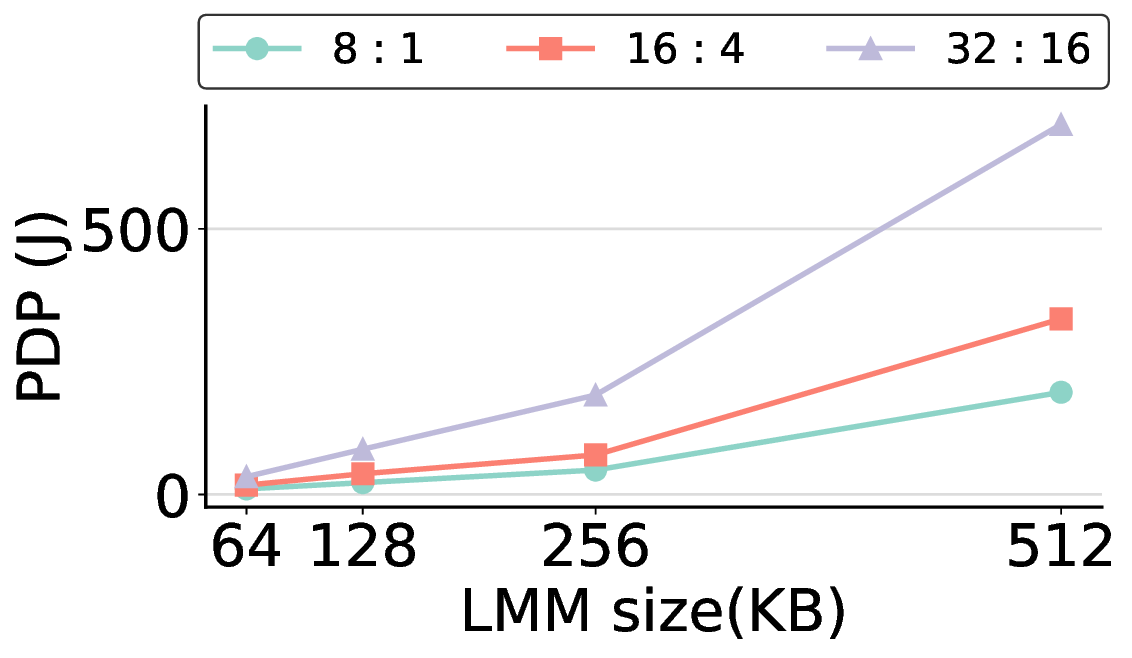
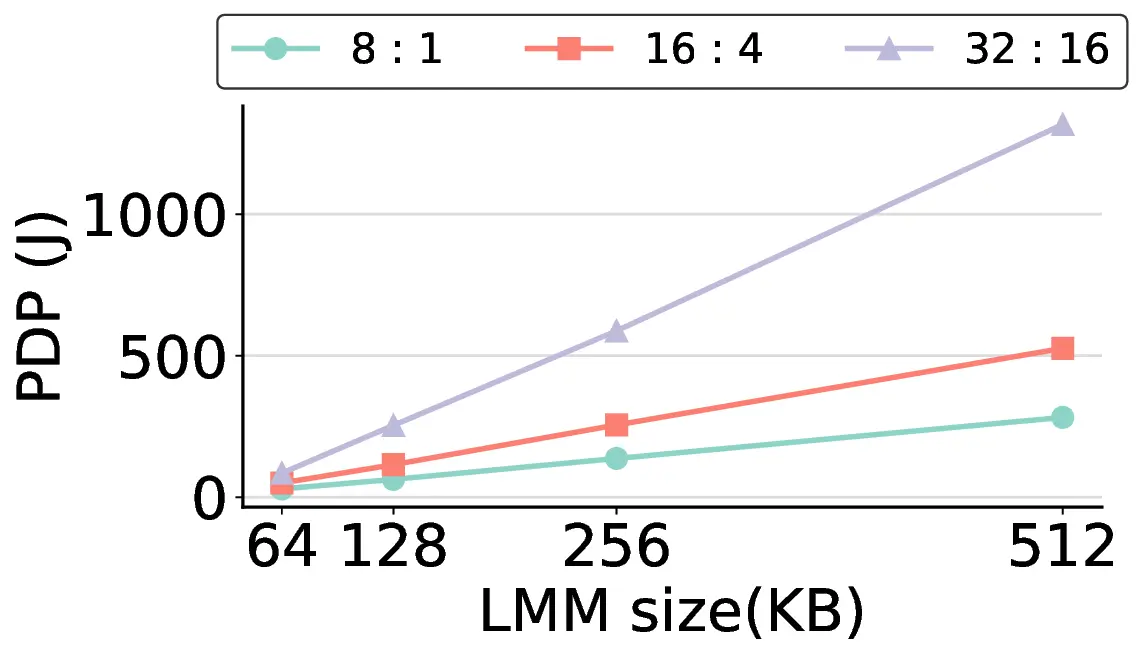
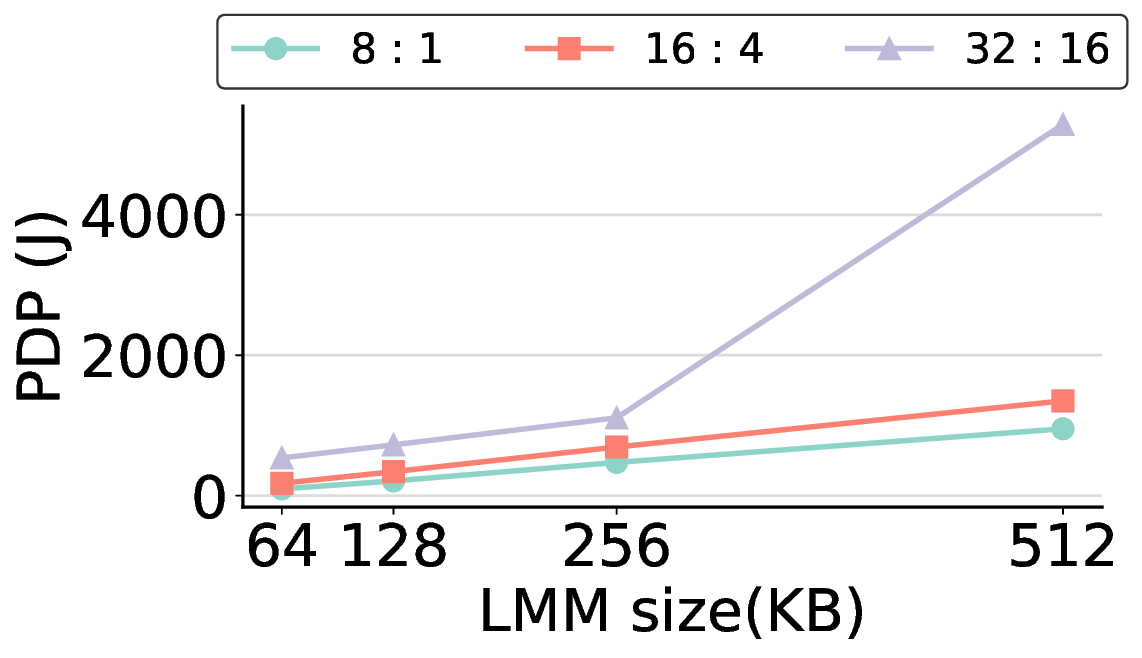
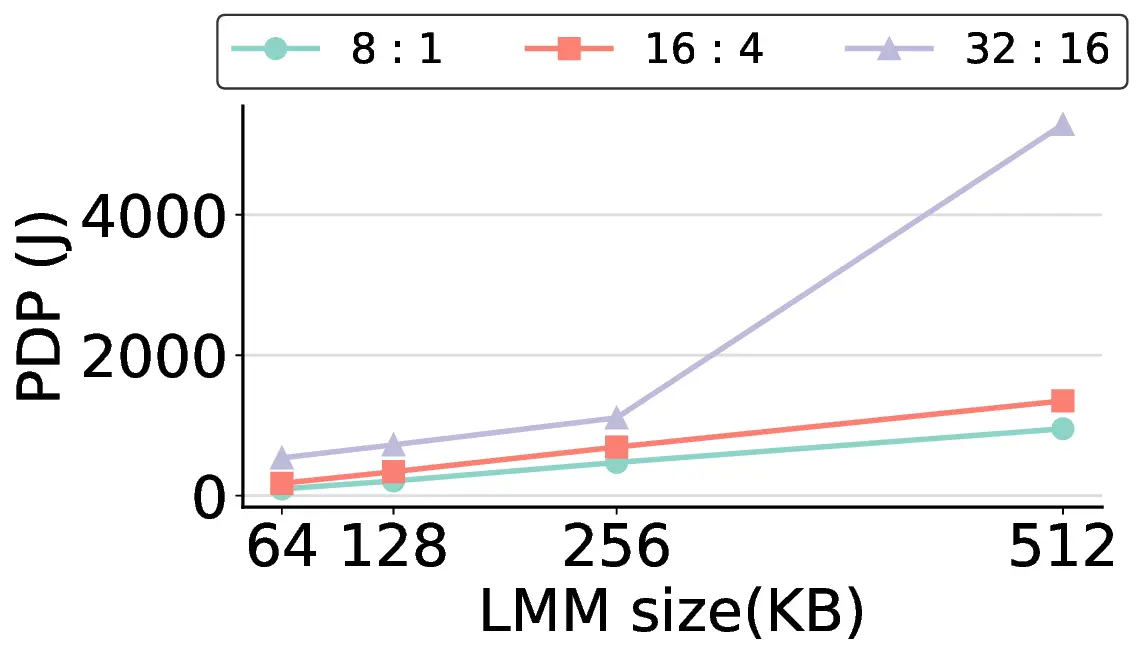
non-AI-specific accelerator achieves higher energy efficiency, improving the Power-Delay Product (PDP)
by up to 44.4× and 13.6× compared with the RTX 4090 and Jetson, respectively. Similarly, it reduces
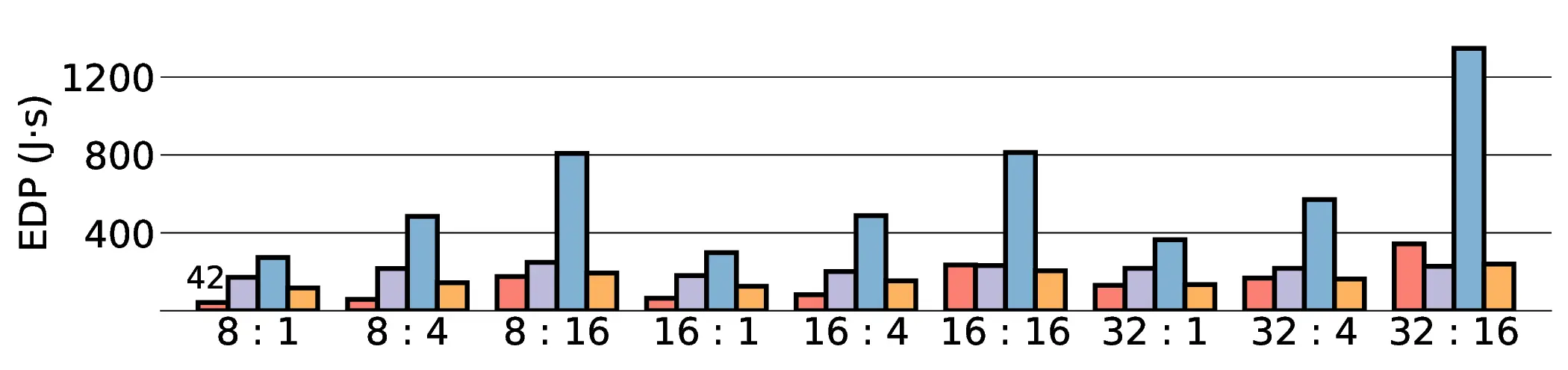
the Energy-Delay Product (EDP) by up to 11.5× compared to the high-performance GPU, demonstrating
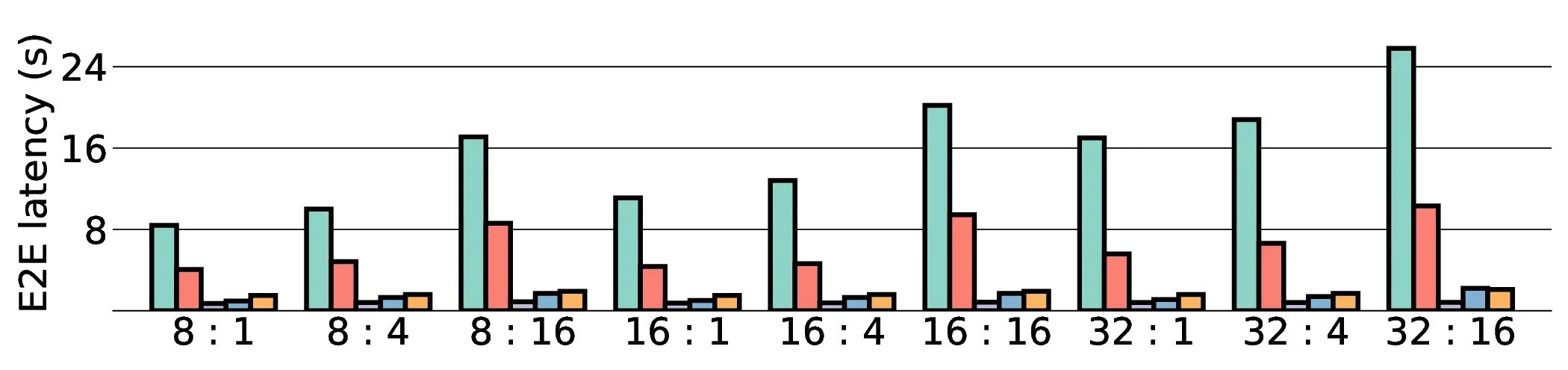
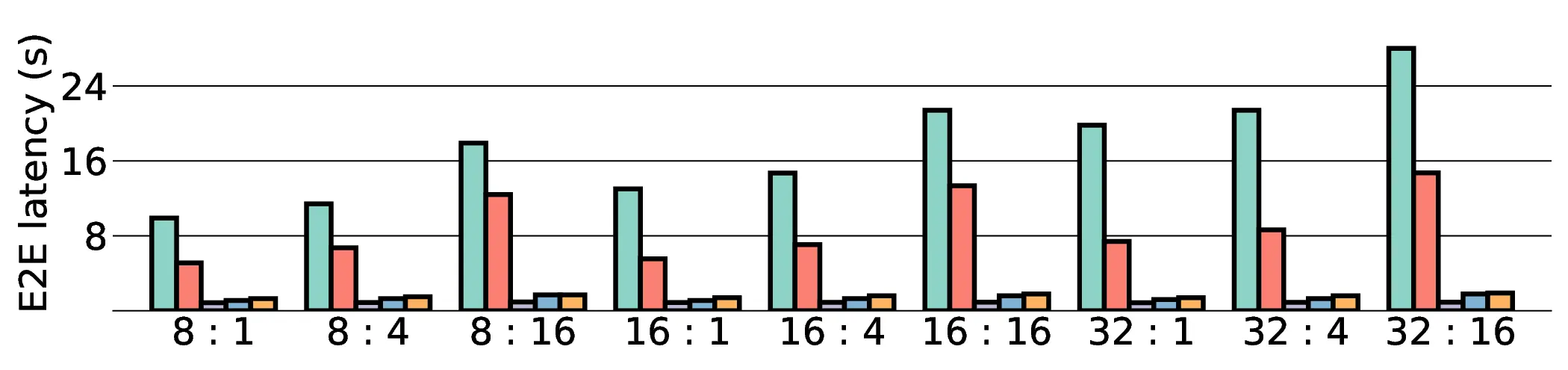
a favorable performance-energy trade-off. Critically, our system-level analysis identifies host-accelerator
data transfer as the primary performance bottleneck, a factor often overlooked in kernel-level studies. These
findings provide design guidance for next-generation LLM accelerators. This work validates CGRAs as a
suitable platform for LLM inference in power-constrained environments, without being confined to specific
algorithms.
INDEX TERMS Qwen, LLM, CGRA, CGLA, IMAX
I. INTRODUCTION
Large Language Models (LLMs) have evolved from spe-
cialized text processing tools into a widely applied tech-
nology in various fields [1], [2], [3], [4], [5]. They have
been applied in fields such as natural language process-
ing [6], [7], [8], code generation [9], [10], [11], and con-
versational AI [12], [13]. The development of multimodal
LLMs, which integrate modalities such as text, images, and
audio, is further expanding their scope of application on
a large scale [14], [15], [16]. The interaction between al-
gorithmic development and computational architectures en-
ables these innovations. Therefore, improving this infrastruc-
ture is not merely a practical challenge but critical for the
broader societal integration of AI. Currently, this technolog-
ical progress primarily depends on the evolution of General-
Purpose Graphics Processing Units (GPGPUs). However,
despite these advances, achieving high performance with
LLMs requires substantial computational resources for both
training and inference. In particular, the high performance
of GPGPUs requires substantial power, which creates sig-
nificant environmental and economic concerns [17], [18].
The International Energy Agency (IEA) estimates that data
center electricity consumption could double by 2030, reach-
ing approximately 945 TWh [19]. This consumption level,
VOLUME 13, 2025
1
arXiv:2512.00335v1 [cs.AR] 29 Nov 2025
T. Ando et al.: Efficient Kernel Mapping and Comprehensive System Evaluation of LLM Acceleration on a CGLA
fueled primarily by the expanding demand for AI, slightly
exceeds Japan’s total annual electricity consumption. This
sustainability challenge presents a significant barrier to the
widespread adoption of LLM technology, making it nec-
essary to address this with improvements in computational
architecture.
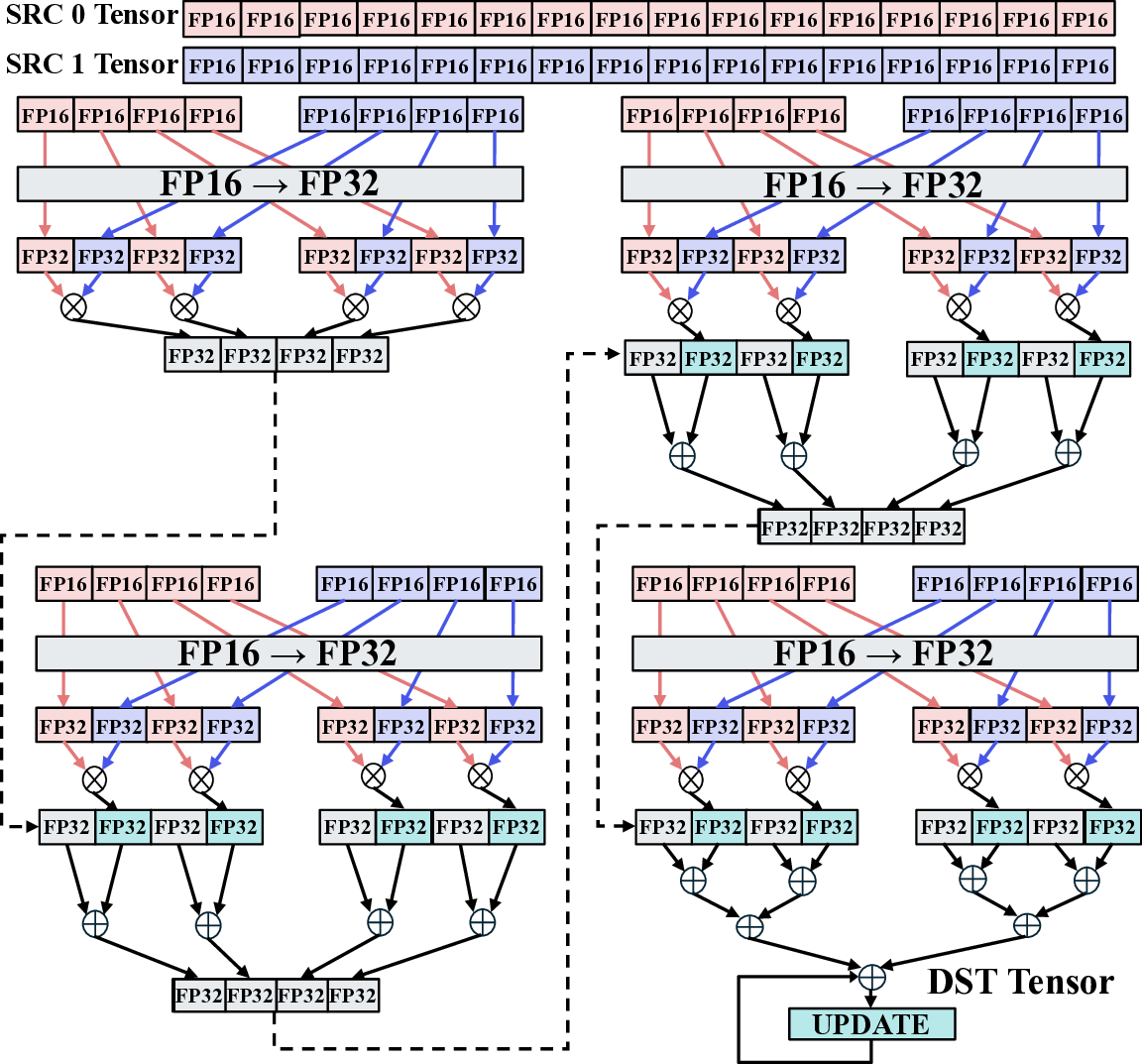
To address this challenge, specialized hardware such as
Application-Specific Integrated Circuits (ASICs) and Field-
Programmable Gate Arrays (FPGAs) have been widely in-
vestigated. While edge GPUs, such as the NVIDIA Jetson
series, demonstrate progress in reducing power consumption,
their general-purpose graphics pipelines inherently constrain
substantial gains in power efficiency. In contrast, ASICs
can potentially achieve orders of magnitude higher power
efficiency. ASICs specialize their circuits for the core com-
putational patterns of LLM inference, such as dot-product
operations. This allows them to remove all unnecessary func-
tionality and achieve maximum performanc
…(Full text truncated)…
This content is AI-processed based on ArXiv data.