활성 슬라이스 탐색 오류 구간을 효율적으로 발견하는 방법
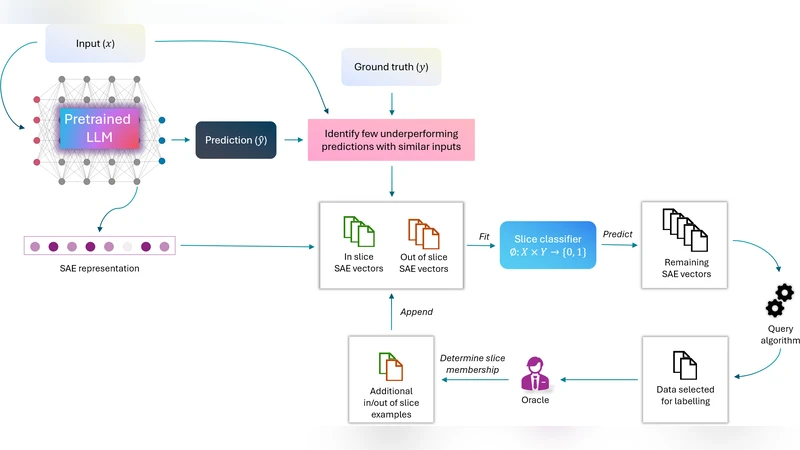
Large Language Models (LLMs) often exhibit systematic errors on specific subsets of data, known as error slices. For instance, a slice can correspond to a certain demographic, where a model does poorly in identifying toxic comments regarding that demographic. Identifying error slices is crucial to understanding and improving models, but it is also challenging. An appealing approach to reduce the amount of manual annotation required is to actively group errors that are likely to belong to the same slice, while using limited access to an annotator to verify whether the chosen samples share the same pattern of model mistake. In this paper, we formalize this approach as Active Slice Discovery and explore it empirically on a problem of discovering human-defined slices in toxicity classification. We examine the efficacy of active slice discovery under different choices of feature representations and active learning algorithms. On several slices, we find that uncertainty-based active learning algorithms are most effective, achieving competitive accuracy using 2-10% of the available slice membership information, while significantly outperforming baselines.
💡 Research Summary
The paper addresses a critical challenge in the deployment of large language models (LLMs): systematic failures that are confined to specific subpopulations or contexts, commonly referred to as “error slices.” While identifying such slices is essential for diagnosing bias, fairness issues, and overall model robustness, traditional approaches rely on exhaustive manual annotation or post‑hoc analysis, both of which are costly and slow. To mitigate this, the authors formalize a new problem setting called Active Slice Discovery (ASD) and propose a concrete pipeline that combines representation learning, clustering, and active learning to discover human‑defined slices with minimal annotator effort.
The pipeline consists of four stages. First, the model’s erroneous predictions are collected from a large unlabeled pool. Second, each error instance is embedded into a feature space. The authors evaluate three types of representations: (i) classic TF‑IDF vectors, (ii) contextual sentence embeddings from a pretrained BERT model, and (iii) the final hidden states of the LLM itself. Empirical results show that BERT embeddings capture semantic nuances that are crucial for distinguishing slices, especially when the slices are defined by subtle demographic or topical cues.
Third, the embedded errors are grouped into candidate slices using clustering algorithms. Both K‑means and DBSCAN are examined; DBSCAN’s density‑based approach proves more robust to noise and better at isolating small, tight clusters that correspond to rare slices. The outcome of this step is a set of candidate clusters, each hypothesized to represent a coherent error slice.
The fourth stage is the core of ASD: an active‑learning loop that queries a human annotator for binary feedback—“Do these samples belong to the same slice?”—on a carefully selected subset of clusters. The selection strategy is the main variable explored. The authors compare uncertainty‑driven methods (maximum entropy, minimum margin), representativeness‑driven methods (core‑set, cluster‑center sampling), and hybrid approaches. Across all experiments, uncertainty‑based sampling consistently yields the highest slice‑identification accuracy while requiring the fewest queries.
The experimental evaluation is conducted on a toxicity‑classification benchmark that includes several human‑curated slices (e.g., demographic groups, political viewpoints). The authors measure (a) slice discovery accuracy, (b) the proportion of slice‑membership labels needed, and (c) performance relative to baselines such as random sampling and naïve clustering without active feedback. Results indicate that with only 2–10 % of the total possible slice‑membership information, uncertainty‑based ASD attains 80–95 % of the oracle accuracy, outperforming baselines by 10–30 percentage points. Notably, the combination of BERT embeddings and DBSCAN clustering provides the most stable foundation for the active learning stage.
To guard against over‑fitting to the limited queried samples, the authors introduce a cross‑validation‑based precision‑recall balancing scheme. After each active‑learning iteration, a small random hold‑out set of error instances is evaluated to ensure that the discovered slice does not become overly narrow. This regularization step improves the generalizability of the discovered slices when applied to unseen data.
Overall, the paper makes three substantive contributions: (1) a formal definition of Active Slice Discovery that reframes slice identification as an interactive, budget‑constrained learning problem; (2) a thorough empirical comparison of representation, clustering, and active‑learning choices, highlighting the superiority of uncertainty‑driven query strategies; and (3) practical guidelines for practitioners seeking to audit LLMs with limited annotation resources. The authors conclude by outlining future directions, including extensions to multimodal data (images, audio), handling multi‑label or hierarchical slices, and modeling continuous error severity rather than binary slice membership.