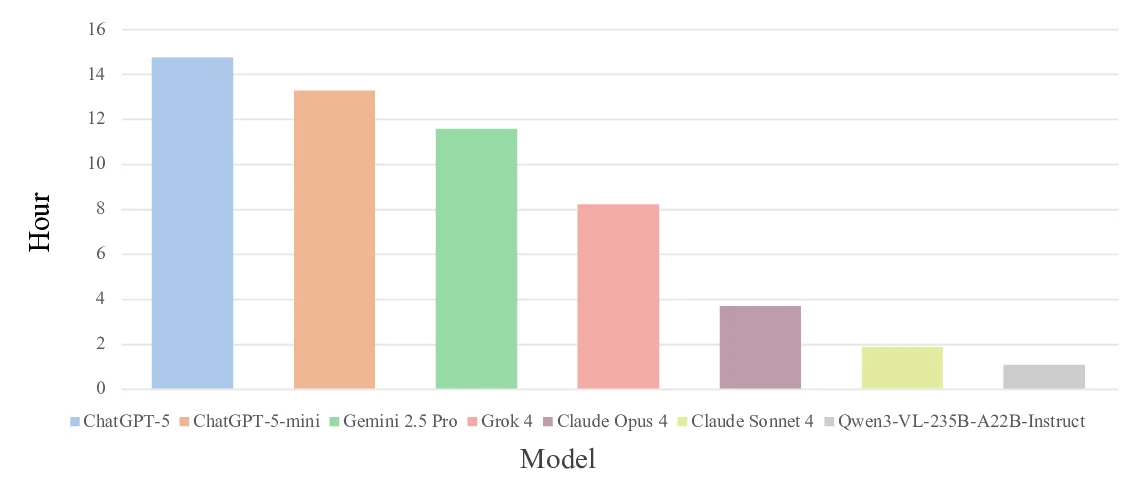
음악 악보 이해를 위한 대규모 멀티모달 벤치마크
📝 Original Info
- Title: 음악 악보 이해를 위한 대규모 멀티모달 벤치마크
- ArXiv ID: 2511.20697
- Date: 2025-11-27
- Authors: Researchers from original ArXiv paper
📝 Abstract
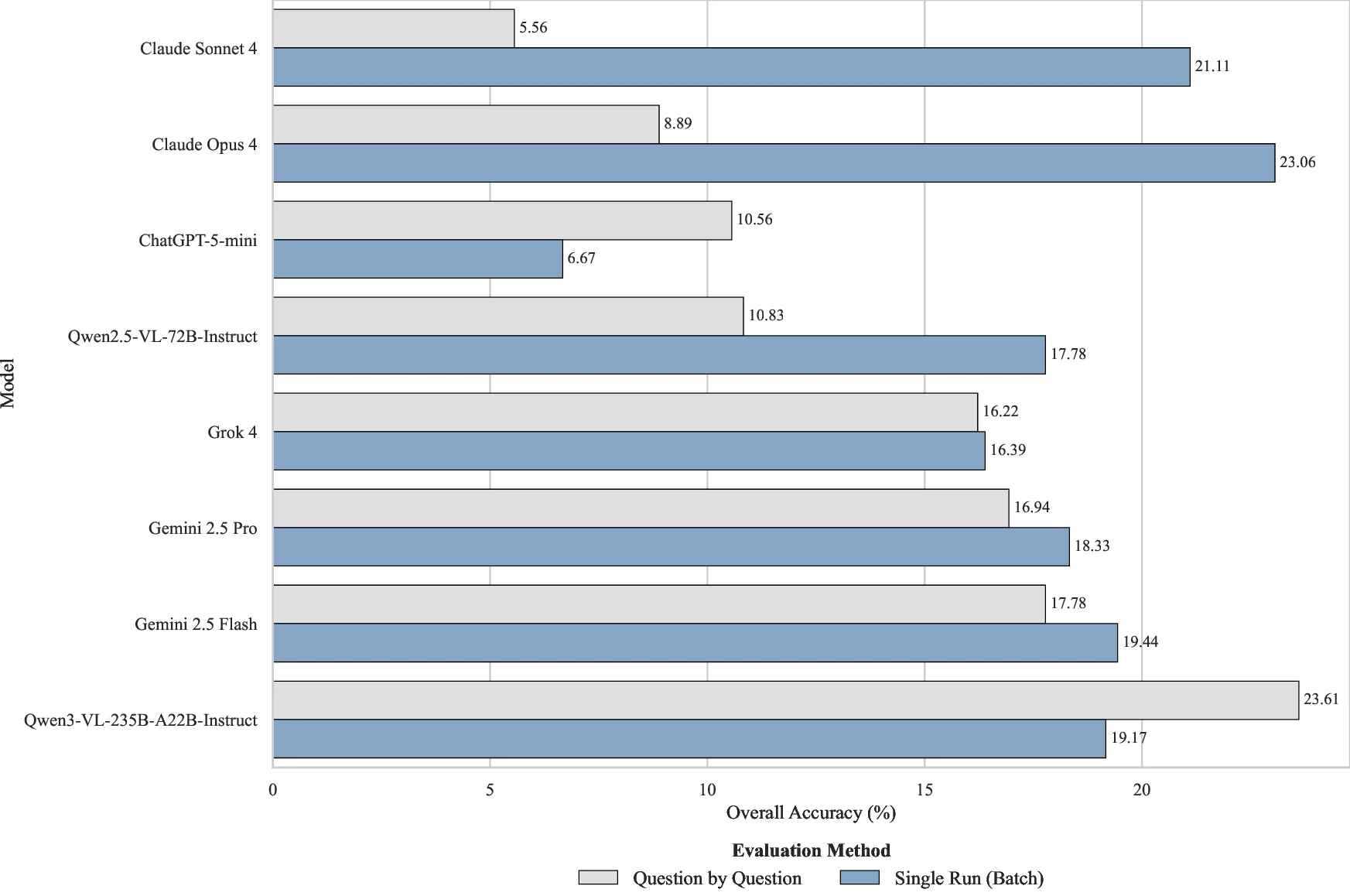
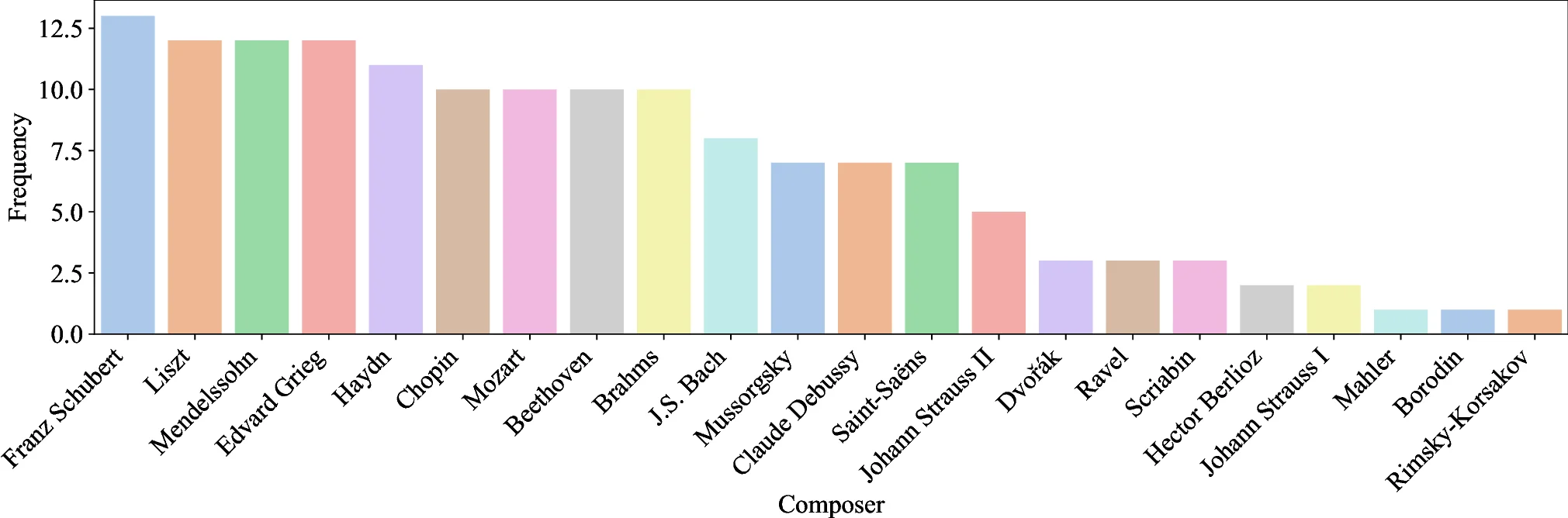
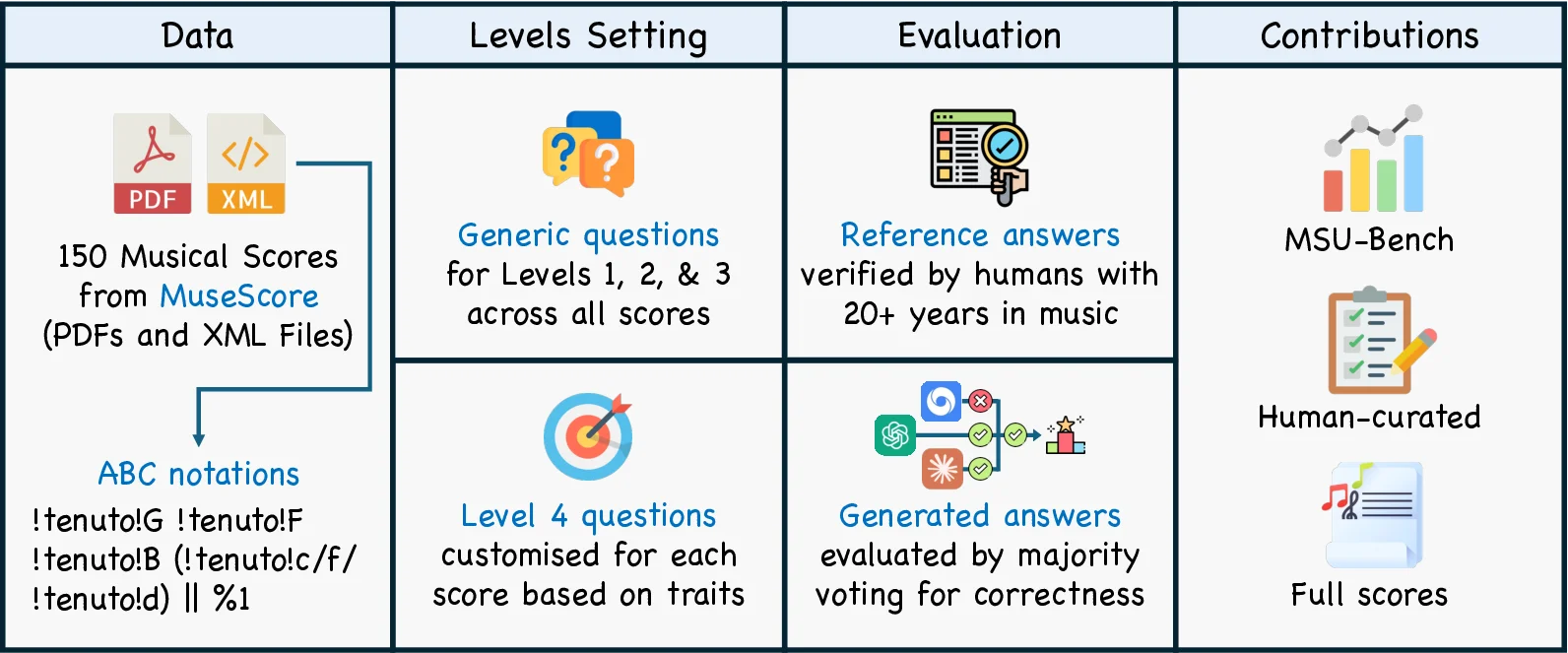
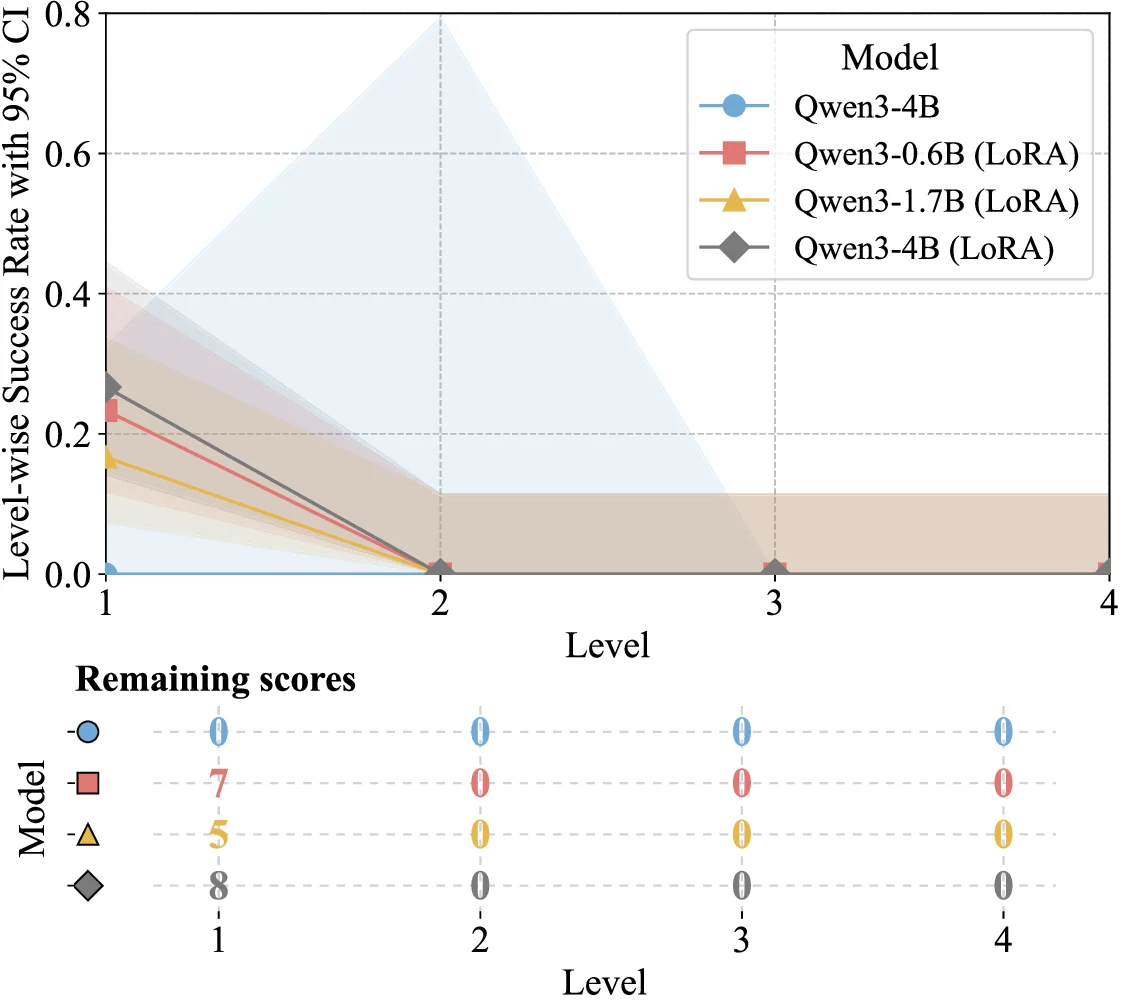
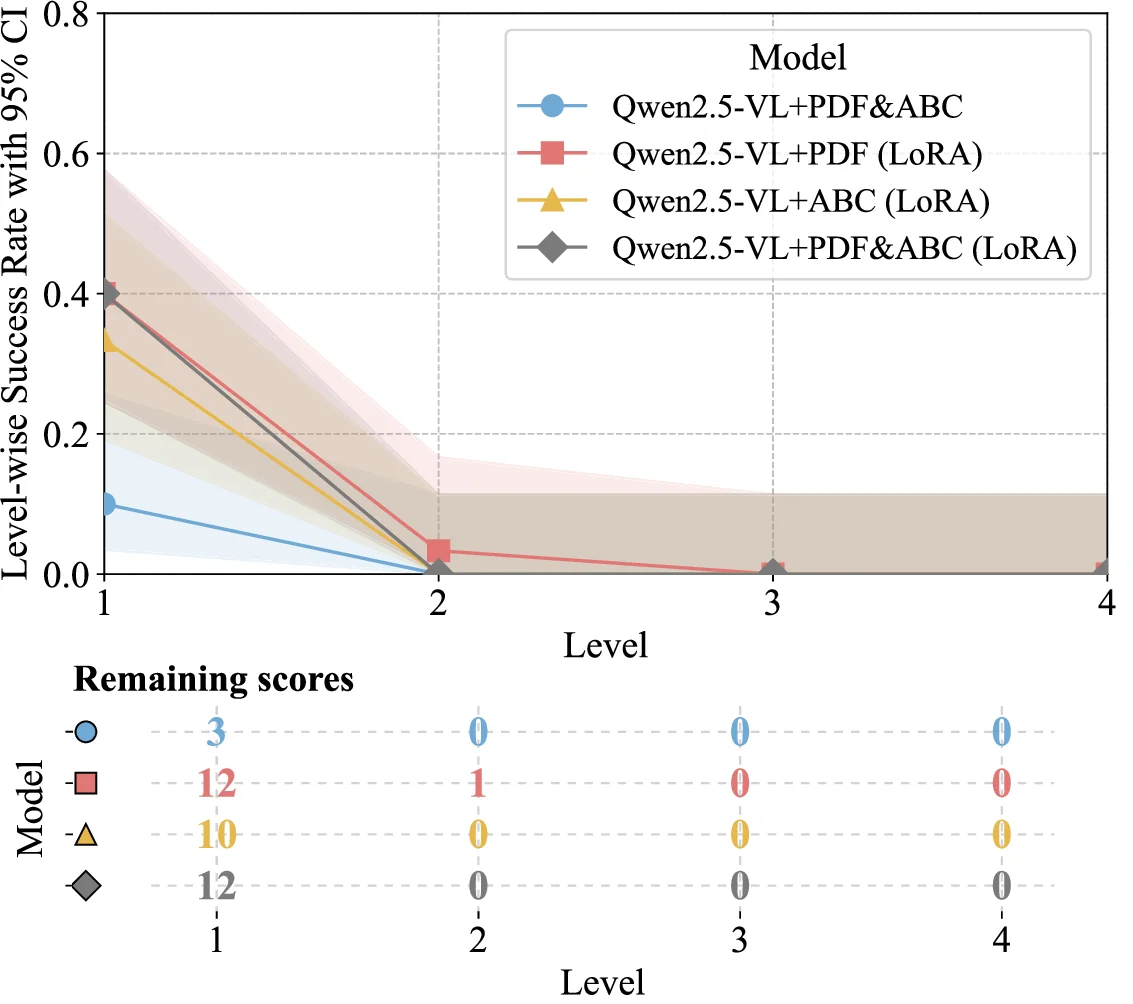
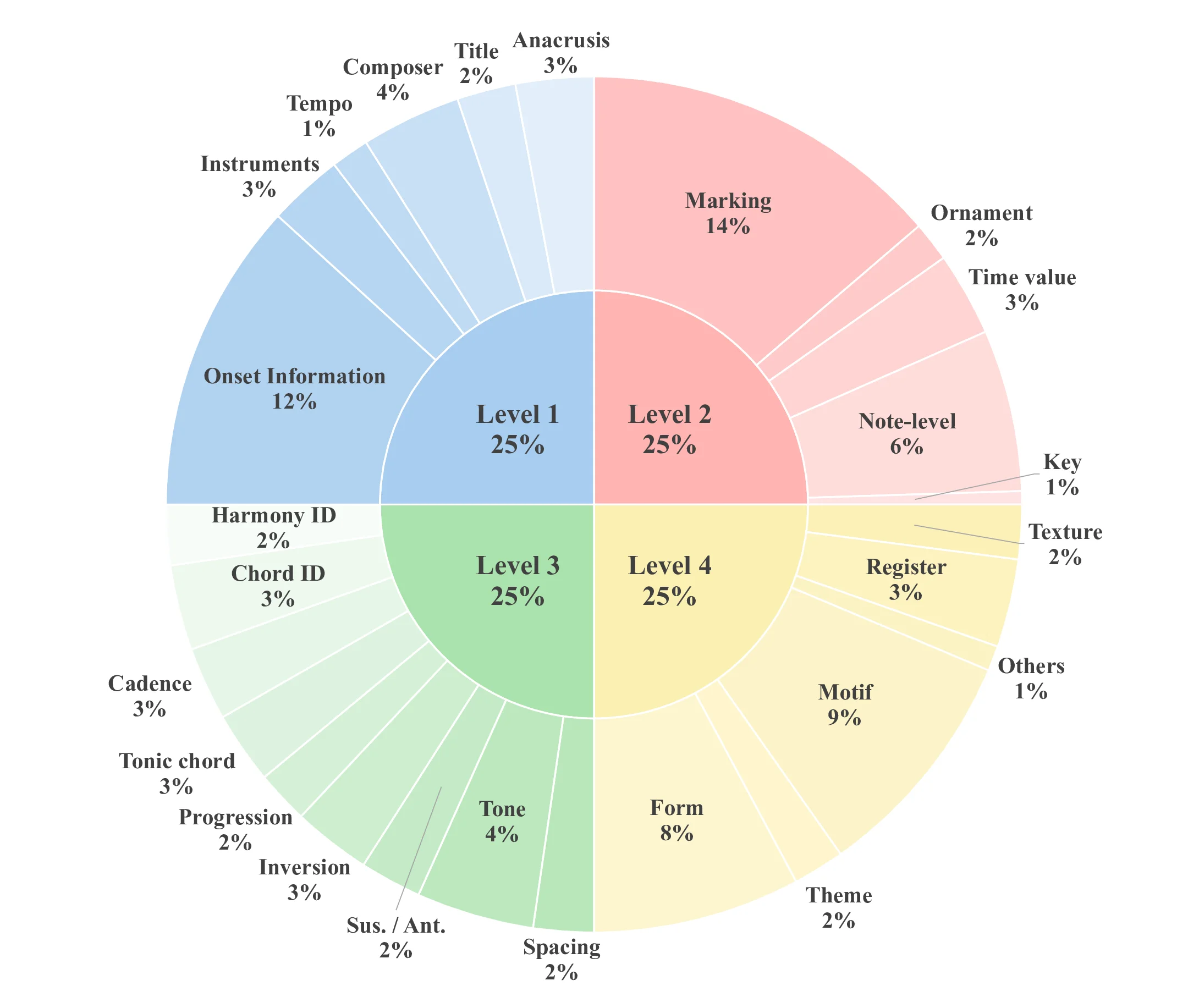
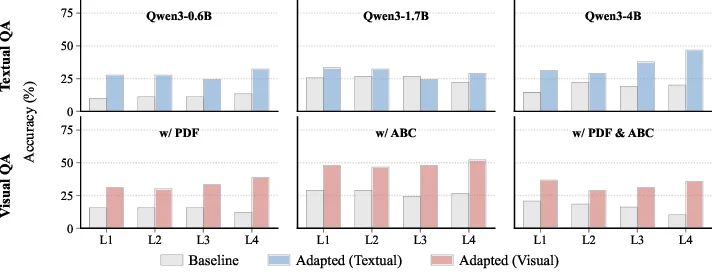
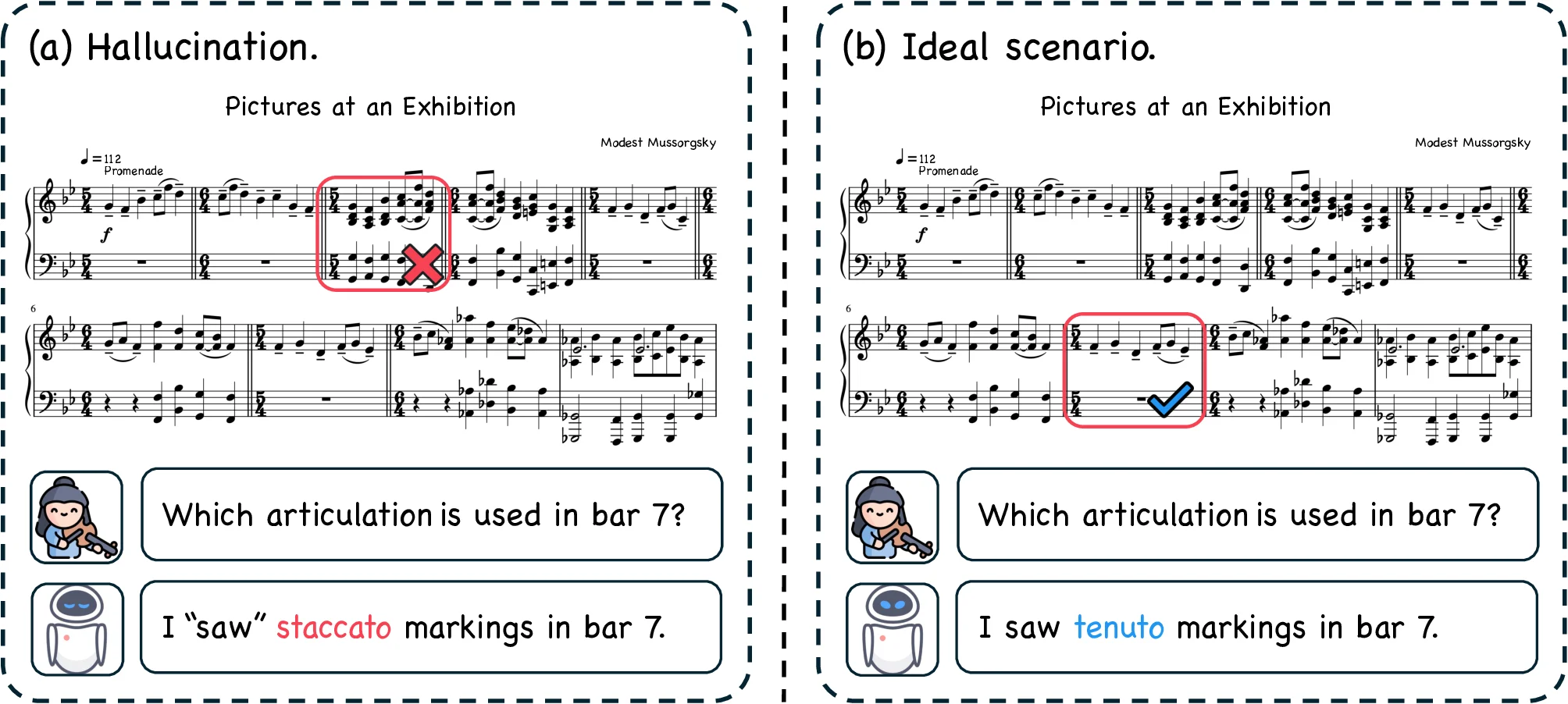
Understanding complete musical scores requires reasoning over symbolic structures such as pitch, rhythm, harmony, and form. Despite the rapid progress of Large Language Models (LLMs) and Vision-Language Models (VLMs) in natural language and multimodal tasks, their ability to comprehend musical notation remains underexplored. We introduce Musical Score Understanding Benchmark (MSU-Bench), the first large-scale, human-curated benchmark for evaluating score-level musical understanding across both textual (ABC notation) and visual (PDF) modalities. MSU-Bench comprises 1,800 generative question-answer (QA) pairs drawn from works spanning Bach, Beethoven, Chopin, Debussy, and others, organised into four progressive levels of comprehension: Onset Information, Notation & Note, Chord & Harmony, and Texture & Form. Through extensive zero-shot and fine-tuned evaluations of over 15+ state-of-the-art (SOTA) models, we reveal sharp modality gaps, fragile level-wise success rates, and the difficulty of sustaining multilevel correctness. Fine-tuning markedly improves performance in both modalities while preserving general knowledge, establishing MSU-Bench as a rigorous foundation for future research at the intersection of Artificial Intelligence (AI), musicological, and multimodal reasoning.💡 Deep Analysis
Deep Dive into 음악 악보 이해를 위한 대규모 멀티모달 벤치마크.Understanding complete musical scores requires reasoning over symbolic structures such as pitch, rhythm, harmony, and form. Despite the rapid progress of Large Language Models (LLMs) and Vision-Language Models (VLMs) in natural language and multimodal tasks, their ability to comprehend musical notation remains underexplored. We introduce Musical Score Understanding Benchmark (MSU-Bench), the first large-scale, human-curated benchmark for evaluating score-level musical understanding across both textual (ABC notation) and visual (PDF) modalities. MSU-Bench comprises 1,800 generative question-answer (QA) pairs drawn from works spanning Bach, Beethoven, Chopin, Debussy, and others, organised into four progressive levels of comprehension: Onset Information, Notation & Note, Chord & Harmony, and Texture & Form. Through extensive zero-shot and fine-tuned evaluations of over 15+ state-of-the-art (SOTA) models, we reveal sharp modality gaps, fragile level-wise success rates, and the difficulty
📄 Full Content
📸 Image Gallery