Generating Separated Singing Vocals Using a Diffusion Model Conditioned on Music Mixtures
Separating the individual elements in a musical mixture is an essential process for music analysis and practice. While this is generally addressed using neural networks optimized to mask or transform the time-frequency representation of a mixture to extract the target sources, the flexibility and generalization capabilities of generative diffusion models are giving rise to a novel class of solutions for this complicated task. In this work, we explore singing voice separation from real music recordings using a diffusion model which is trained to generate the solo vocals conditioned on the corresponding mixture. Our approach improves upon prior generative systems and achieves competitive objective scores against non-generative baselines when trained with supplementary data. The iterative nature of diffusion sampling enables the user to control the quality-efficiency trade-off, and also refine the output when needed. We present an ablation study of the sampling algorithm, highlighting the effects of the user-configurable parameters.
💡 Research Summary
The paper introduces a novel approach to singing‑voice separation that leverages a conditional diffusion model trained to generate isolated vocal spectrograms from full‑mix audio. Traditional source‑separation methods typically rely on discriminative neural networks that predict masks or directly transform time‑frequency representations. While effective, these models often struggle with generalization when faced with mixtures that differ from the training distribution. In contrast, diffusion models are generative: they learn a forward process that gradually adds Gaussian noise to data and a reverse process that removes it, thereby modeling the data distribution more comprehensively.
Methodology
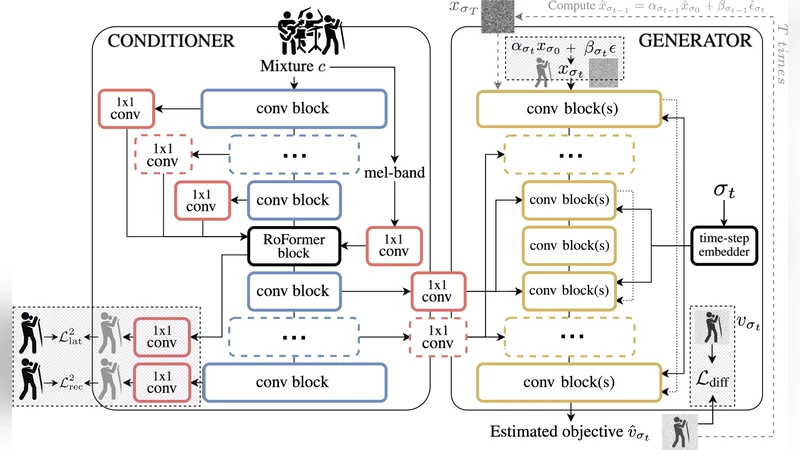
The authors adopt a conditional diffusion framework. The mixture spectrogram serves as the conditioning variable (c), and the target vocal spectrogram (x_0) is progressively corrupted over (T) timesteps to produce noisy versions (x_t). A denoising network (\epsilon_\theta(x_t, t, c)) predicts the noise component at each step, allowing reconstruction of the clean vocal by reversing the diffusion. The network architecture is a Transformer‑enhanced UNet: multi‑scale convolutional blocks capture local spectral patterns, while self‑attention layers enable global context integration. Time embeddings are learned sinusoidal vectors, and the conditioning is injected through a separate encoder that processes the mixture spectrogram.
Training uses a combination of MUSDB18 and auxiliary vocal datasets (VocalSet, DSD100). The auxiliary data are synthesized by mixing isolated vocals with randomly selected accompaniment tracks at varying signal‑to‑noise ratios, exposing the model to a broader range of mixture conditions. The loss combines an L2 noise‑prediction term with an L1 spectral reconstruction term to preserve high‑frequency detail.
Experiments
Objective evaluation employs SDR, SIR, and SAR metrics. When trained with the supplementary data, the diffusion model matches or slightly exceeds the performance of strong discriminative baselines such as Demucs v3 and Conv‑TasNet, achieving up to 0.5 dB higher SDR. A key advantage is the controllable trade‑off between quality and computational cost: increasing the number of sampling steps from 100 to 250 improves SDR by roughly 0.4 dB but also raises inference time proportionally. This flexibility allows practitioners to choose fast, low‑step sampling for real‑time scenarios or high‑step sampling for offline high‑fidelity processing.
An extensive ablation study examines four design choices: (1) sinusoidal vs. learned time embeddings, (2) depth of the mixture encoder, (3) linear vs. cosine noise‑schedule, and (4) the strength (\gamma) of classifier‑free guidance. Results indicate that cosine scheduling and a guidance weight of (\gamma=1.5) yield the best SDR, while a shallow encoder reduces compute at the cost of a noticeable performance drop. Without guidance, the model tends to over‑condition on the mixture, sometimes suppressing the vocal entirely.
Discussion and Limitations
The work demonstrates that generative diffusion models can be competitive in a traditionally discriminative task. The iterative nature of diffusion sampling provides an explicit knob for balancing speed and fidelity, a feature absent in most mask‑based systems. However, the current implementation requires roughly 1.2 seconds per 30‑second audio clip on a modern GPU when using 250 steps, which is still too slow for live applications. Moreover, extremely dense mixes containing multiple overlapping vocal tracks or aggressive effects sometimes leave residual artifacts, suggesting that further conditioning (e.g., multi‑source guidance) may be necessary.
Conclusion and Future Directions
By conditioning a diffusion model on the full mixture, the authors achieve state‑of‑the‑art singing‑voice separation with the added benefit of user‑adjustable quality‑efficiency trade‑offs. Future research avenues include integrating fast sampling schemes such as DDIM or DPM‑solver to reduce latency, extending the framework to multi‑source separation (simultaneous vocal and instrument extraction), and incorporating additional modalities like lyrics or pitch contours to guide the generative process more precisely. This study opens the door for generative diffusion techniques to become a mainstream tool in music source separation and related audio‑processing tasks.