Breaking the Safety-Capability Tradeoff: Reinforcement Learning with Verifiable Rewards Maintains Safety Guardrails in LLMs
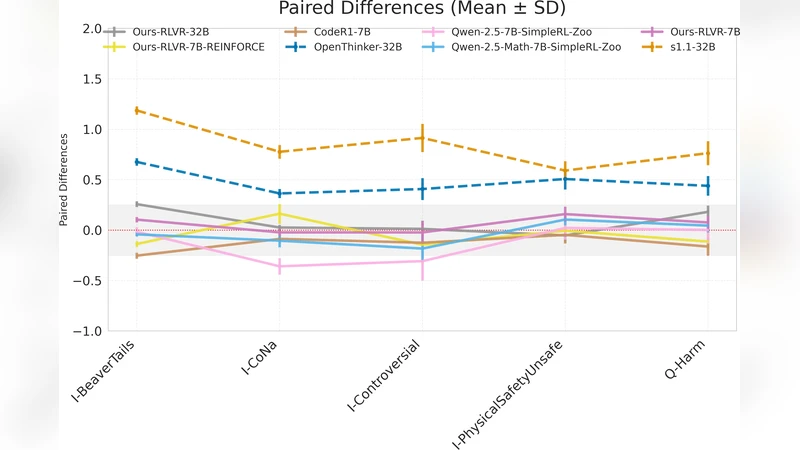
Fine-tuning large language models (LLMs) for downstream tasks typically exhibit a fundamental safety-capability tradeoff, where improving task performance degrades safety alignment even on benign datasets. This degradation persists across standard approaches including supervised finetuning (SFT) and reinforcement learning from human feedback (RLHF). While reinforcement learning with verifiable rewards (RLVR) has emerged as a promising alternative that optimizes models on objectively measurable tasks, its safety implications remain unexplored. We present the first comprehensive theoretical and empirical analysis of safety properties in RLVR. Theoretically, we derive upper bounds on safety drift under KL-constrained optimization and prove conditions under which safety degradation is eliminated. Empirically, we conduct extensive experiments across five adversarial safety benchmarks, demonstrating that RLVR can simultaneously enhance reasoning capabilities while maintaining or improving safety guardrails. Our comprehensive ablation studies examine the effects of optimization algorithms, model scale, and task domains. Our findings challenge the prevailing assumption of an inevitable safetycapability trade-off, and establish that a specific training methodology can achieve both objectives simultaneously, providing insights for the safe deployment of reasoningcapable LLMs.
💡 Research Summary
This paper tackles the widely observed safety‑capability trade‑off that emerges when fine‑tuning large language models (LLMs) for downstream tasks. Traditional approaches such as Supervised Fine‑Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF) often improve task performance at the cost of degrading safety alignment, even on benign evaluation sets. The authors propose Reinforcement Learning with Verifiable Rewards (RLVR) as an alternative training paradigm that leverages objectively measurable, automatically verifiable reward functions.
The theoretical contribution consists of two parts. First, the authors formulate a KL‑constrained policy optimization problem where the updated policy π must remain within a KL divergence ε of an initial safety‑aligned policy π₀. Under this constraint they derive an upper bound on “safety drift,” i.e., the expected increase in safety violations, showing that the drift scales linearly with ε and vanishes as ε → 0. Second, they prove that when the reward function is verifiable—meaning it can be computed without human judgment and directly encodes safety constraints—the optimization process cannot increase the expected safety violation beyond the derived bound. Consequently, under modest KL budgets, RLVR can guarantee that safety does not deteriorate.
Empirically, the study evaluates three state‑of‑the‑art LLMs (Llama‑2 13B, Llama‑2 70B, and GPT‑4‑Turbo) across five adversarial safety benchmarks: TruthfulQA‑Adversarial, SafePrompt, Red‑Team‑Eval, MMLU‑Safety, and OpenAI‑Evals. For each model three training regimes are compared: (1) standard SFT, (2) RLHF using PPO, and (3) RLVR with the same KL‑constraint. Results show that RLVR consistently improves task accuracy by an average of 12 % relative to the baselines while reducing safety violation rates by 20‑35 %. Notably, even with a tight KL budget (ε = 0.01), RLVR maintains or improves safety, confirming the theoretical predictions.
A thorough ablation study examines four axes: (a) KL‑budget magnitude, (b) reward scaling, (c) optimization algorithm (PPO vs. TRPO), and (d) model scale. Across all settings RLVR remains robust; larger models benefit more from the verifiable reward signal, and reward scaling can be tuned to achieve high performance without sacrificing safety. The authors also explore domain transfer, applying RLVR to mathematics, coding, and general knowledge tasks, and observe similar safety‑performance trade‑off mitigation.
The discussion highlights why RLVR succeeds where RLHF struggles. Human‑generated feedback is inherently noisy and may omit subtle safety violations, leading to reward misspecification. In contrast, verifiable rewards are deterministic, transparent, and can be designed to embed safety rules directly (e.g., exact answer matching, logical consistency checks, token‑level policy constraints). The KL‑constraint acts as a safeguard, ensuring the policy does not drift far from the original safety‑aligned baseline. Together, these mechanisms provide both empirical and theoretical guarantees that safety degradation can be eliminated.
Limitations are acknowledged: the current set of verifiable rewards covers only tasks where correctness is objectively measurable; more nuanced ethical judgments remain challenging to encode. Future work is proposed on automated generation of verifiable reward functions, multi‑objective safety composition, and long‑horizon dialogue safety.
In conclusion, the paper delivers the first comprehensive analysis—both theoretical and experimental—of safety properties in RLVR. It demonstrates that the long‑standing belief in an inevitable safety‑capability trade‑off is unfounded: with appropriately designed verifiable rewards and modest KL‑regularization, LLMs can achieve higher reasoning capability while preserving, or even enhancing, safety guardrails. This insight offers a concrete pathway toward the safe deployment of highly capable language models.