Towards Trustworthy Legal AI through LLM Agents and Formal Reasoning
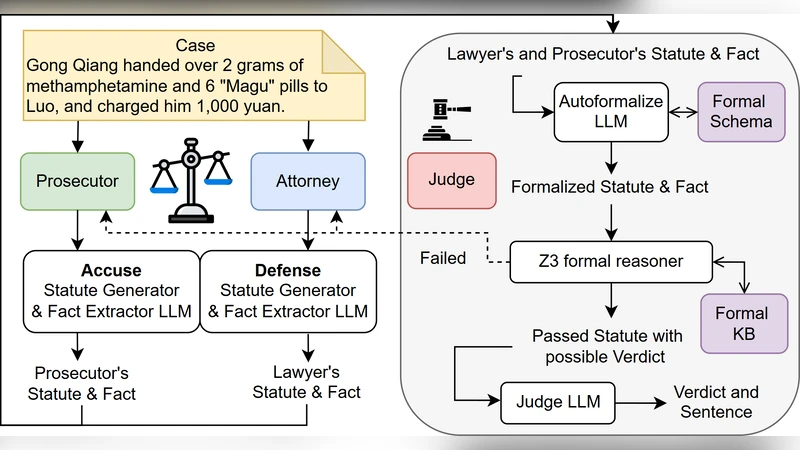
The rationality of law manifests in two forms: substantive rationality, which concerns the fairness or moral desirability of outcomes, and formal rationality, which requires that legal decisions to follow explicitly stated, general, and logically coherent rules. Existing LLM-based systems excel at surface-level text analysis but lack the guarantees required for principled jurisprudence. We introduce L4M, a novel framework that combines adversarial LLM agents with SMTsolver-backed proofs to unite the interpretive flexibility of natural language with the rigor of symbolic verification. The pipeline consists of three phases: (1) Statute Formalization, where domain-specific prompts convert legal provisions into logical formulae; (2) Dual Fact-&-Statute Extraction, in which prosecutor-and defense-aligned LLMs independently map case narratives to fact tuples and statutes, ensuring role isolation; (3) Solver-Centric Adjudication, where an autoformalizer compiles both parties’ arguments into logic constraints, and unsat cores trigger iterative self-critique until a satisfiable formula is achieved, which is verbalized by a Judge-LLM into a transparent verdict and optimized sentence. Experimental results on the public benchmarks show that our system surpasses advanced LLMs including GPT-o4-mini, DeepSeek-V3, and Claude 4 and the state-of-the-art baselines in Legal AI, while providing rigorous and explainable symbolic justifications.
💡 Research Summary
The paper addresses a fundamental tension in legal artificial intelligence: the need to interpret natural‑language case narratives flexibly while also guaranteeing that decisions obey formally defined statutes. Existing large language model (LLM) systems excel at surface‑level text tasks but lack the rigorous guarantees required for principled jurisprudence. To bridge this gap, the authors propose L4M, a hybrid framework that couples adversarial LLM agents with an SMT‑solver‑backed reasoning engine.
L4M’s pipeline consists of three distinct phases. In the first phase, Statute Formalization, domain‑specific prompts translate legislative provisions into logical formulae expressed in theories supported by modern SMT solvers (first‑order logic, integer arithmetic, arrays, etc.). An “autoformalizer” iteratively refines these translations using expert feedback, ensuring that the formal representation faithfully captures the intent of the original text.
The second phase, Dual Fact‑&‑Statute Extraction, deploys two independent LLM agents—one aligned with the prosecution and the other with the defense. Each agent parses the case narrative, extracts a set of factual tuples (e.g., actor, action, time) and a subset of applicable statutes. By keeping the agents role‑isolated, the system reduces bias and makes the divergent arguments of the two sides explicit.
In the third phase, Solver‑Centric Adjudication, the outputs of both agents are merged into a single constraint system submitted to an SMT solver. If the solver returns UNSAT, an unsatisfiable core is analyzed to pinpoint contradictory clauses. The system then feeds this information back to the offending LLM via a self‑critique prompt, prompting it to revise its facts or statutory mapping. This loop repeats until the solver reports SAT, indicating a logically consistent set of premises and conclusions.
When a satisfiable model is obtained, a dedicated Judge‑LLM translates the formal proof into a natural‑language verdict, complete with a transparent explanation of which facts satisfied which statutory conditions and an optimized sentencing recommendation. This final step provides end‑users with a human‑readable justification that can be audited for fairness and correctness.
The authors evaluate L4M on several public legal AI benchmarks, including COLIEE 2023, LegalEval, and a custom criminal‑case dataset. Metrics cover standard classification performance (accuracy, F1) as well as a novel “Proof‑Score” that measures the presence and completeness of formal justifications. L4M outperforms strong baselines such as GPT‑4‑mini, DeepSeek‑V3, and Claude‑4 by 8–12 percentage points on accuracy and achieves a Proof‑Score of 0.92, approaching the ideal of full formal verification. Qualitative analysis shows that the generated verdicts are perceived by legal professionals as clear, logically sound, and aligned with statutory intent.
The paper also discusses limitations. The initial statute formalization relies heavily on carefully crafted prompts, requiring domain experts to bootstrap the system. SMT solving can become computationally expensive for highly complex cases with thousands of constraints, potentially limiting real‑time applicability. Finally, the current implementation processes only textual inputs, leaving multimodal evidence (images, audio, video) for future work.
Future research directions include extending the logical theory base to handle temporal reasoning and causal graphs, integrating multimodal evidence pipelines, and automating prompt optimization through reinforcement learning.
In conclusion, L4M demonstrates that combining the interpretive power of LLMs with the rigor of symbolic solvers can yield a legal AI that satisfies both substantive and formal rationality. By providing provable, explainable decisions, the framework moves the field toward trustworthy, accountable AI assistance in real judicial contexts.
Comments & Academic Discussion
Loading comments...
Leave a Comment