Neuromorphic accelerators offer promising platforms for machine learning (ML) inference by leveraging eventdriven, spatially-expanded architectures that naturally exploit unstructured sparsity through co-located memory and compute. However, their unique architectural characteristics create performance dynamics that differ fundamentally from conventional accelerators. Existing workload optimization approaches for neuromorphic accelerators rely on aggregate network-wide sparsity and operation counting, but the extent to which these metrics actually improve deployed performance remains unknown. This paper presents the first comprehensive performance bound and bottleneck analysis of neuromorphic accelerators, revealing the shortcomings of the conventional metrics and offering an understanding of what facets matter for workload performance. We present both theoretical analytical modeling and extensive empirical characterization of three real neuromorphic accelerators: Brainchip AKD1000, Synsense Speck, and Intel Loihi 2. From these, we establish three distinct accelerator bottleneck states, memory-bound, compute-bound, and trafficbound, and identify which workload configuration features are likely to exhibit these bottleneck states. We synthesize all of our insights into the floorline performance model, a visual model that identifies performance bounds and informs how to optimize a given workload, based on its position on the model. Finally, we present an optimization methodology that combines sparsity-aware training with floorline-informed partitioning. Our methodology achieves substantial performance improvements at iso-accuracy: up to 3.86× runtime improvement and 3.38× energy reduction compared to prior manually-tuned configurations. This work lays the groundwork for system-level optimization of neuromorphic accelerators, and it provides architectural insights and a systematic optimization framework that enables principled performance engineering for this class of architectures.
Deep Dive into Modeling and Optimizing Performance Bottlenecks for Neuromorphic Accelerators.
Neuromorphic accelerators offer promising platforms for machine learning (ML) inference by leveraging eventdriven, spatially-expanded architectures that naturally exploit unstructured sparsity through co-located memory and compute. However, their unique architectural characteristics create performance dynamics that differ fundamentally from conventional accelerators. Existing workload optimization approaches for neuromorphic accelerators rely on aggregate network-wide sparsity and operation counting, but the extent to which these metrics actually improve deployed performance remains unknown. This paper presents the first comprehensive performance bound and bottleneck analysis of neuromorphic accelerators, revealing the shortcomings of the conventional metrics and offering an understanding of what facets matter for workload performance. We present both theoretical analytical modeling and extensive empirical characterization of three real neuromorphic accelerators: Brainchip AKD1000, Syn
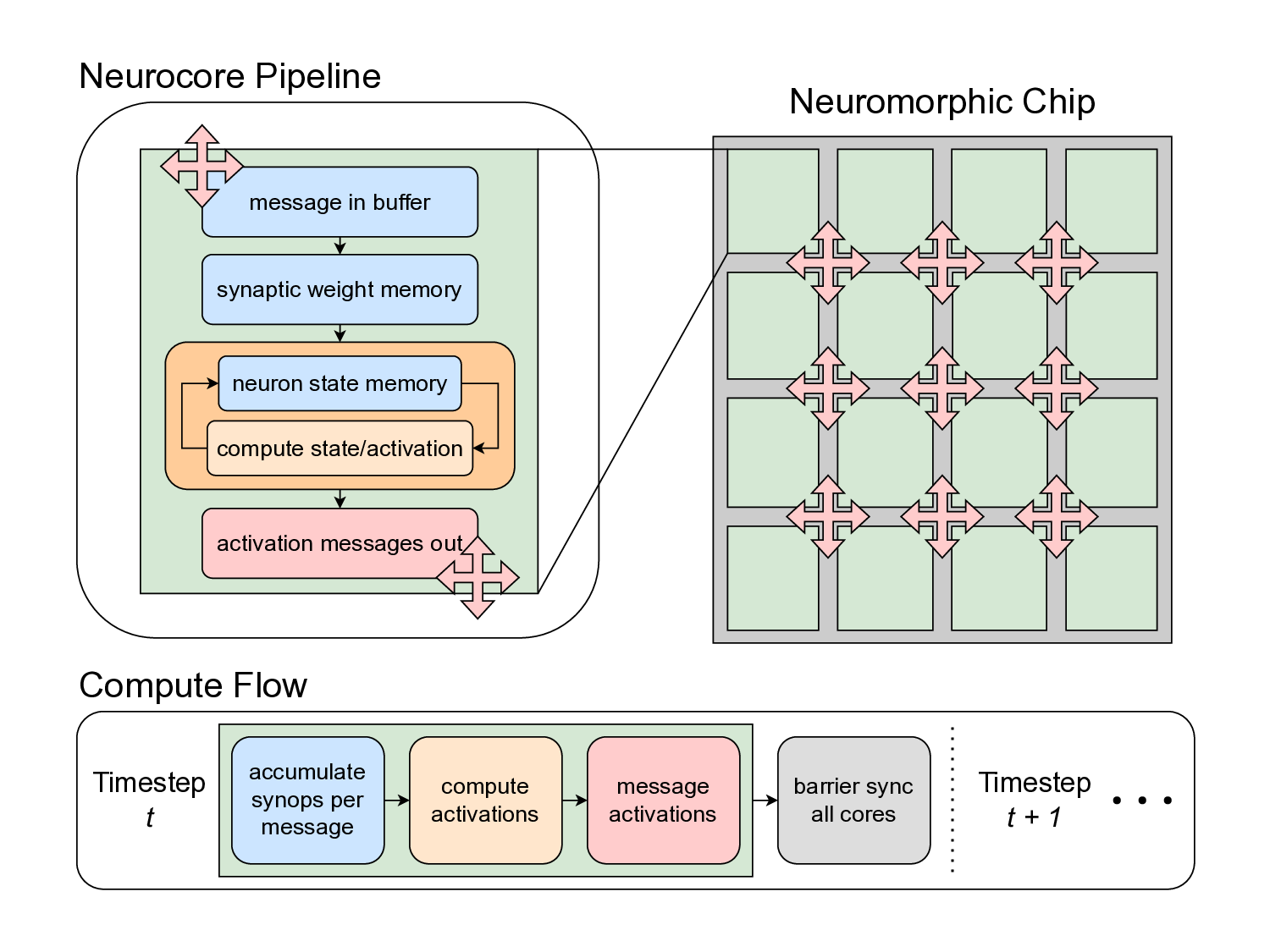
Neuromorphic accelerators employ a distinct architectural approach for executing sparse neural network inference, characterized by spatially-expanded designs where each logical neuron maps to a dedicated physical compute unit onchip. This contrasts with conventional accelerators that timemultiplex logical neurons across shared arithmetic units [4], [24], [40], [41]. The neuromorphic approach co-locates memory with processing units (neurocores) and leverages eventdriven execution to exploit activation sparsity without requiring structured sparsity patterns. Recent deployments have demonstrated substantial performance and energy benefits for specific sparse workloads compared to edge GPU baselines [1], [30], [38], [46], [62].
However, the unique architectural characteristics of neuromorphic accelerators create performance dynamics that are poorly understood. While recent algorithmic work has focused on optimizing neural networks for neuromorphic deployment [10], [32], [33], [38], [43], [44], [59], [60], these efforts rely on high-level performance proxies, primarily networkwide sparsity and aggregate operation counting, without testing how well such proxies actually inform deployed performance. This gap is critical: no systematic analysis has established which factors actually drive neuromorphic accelerator performance and how to optimize for them.
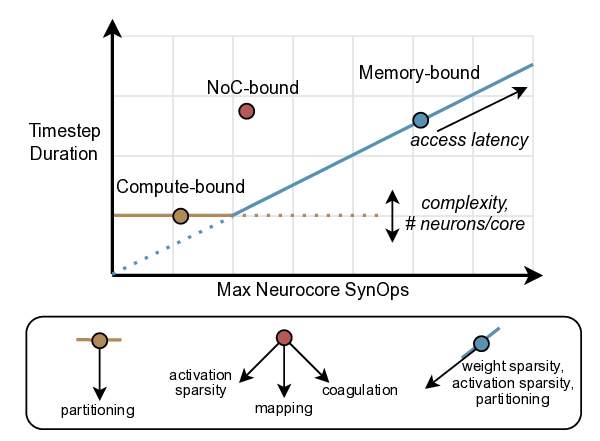
In this paper, we address this gap by presenting a “bound and bottleneck” analysis [25] of neuromorphic accelerator performance, mirroring methodology which produced the widelyused roofline performance model for conventional architectures [56]. Our analysis aims to answer three key questions about neuromorphic systems: (1) What core operations bound and bottleneck performance? (2) Which workload configurations result in different bounds and bottlenecks? (3) How does one optimize a given workload using an understanding of its bottleneck and performance bounds?
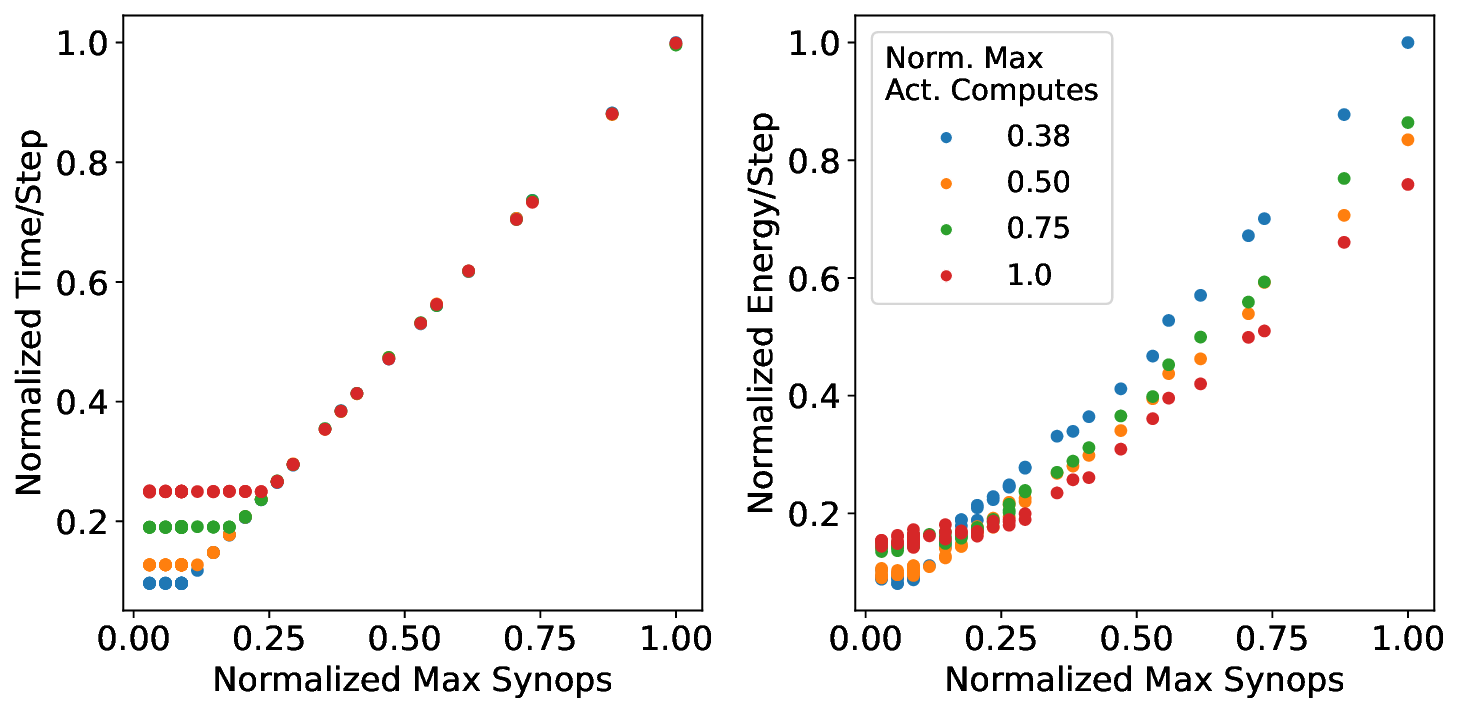
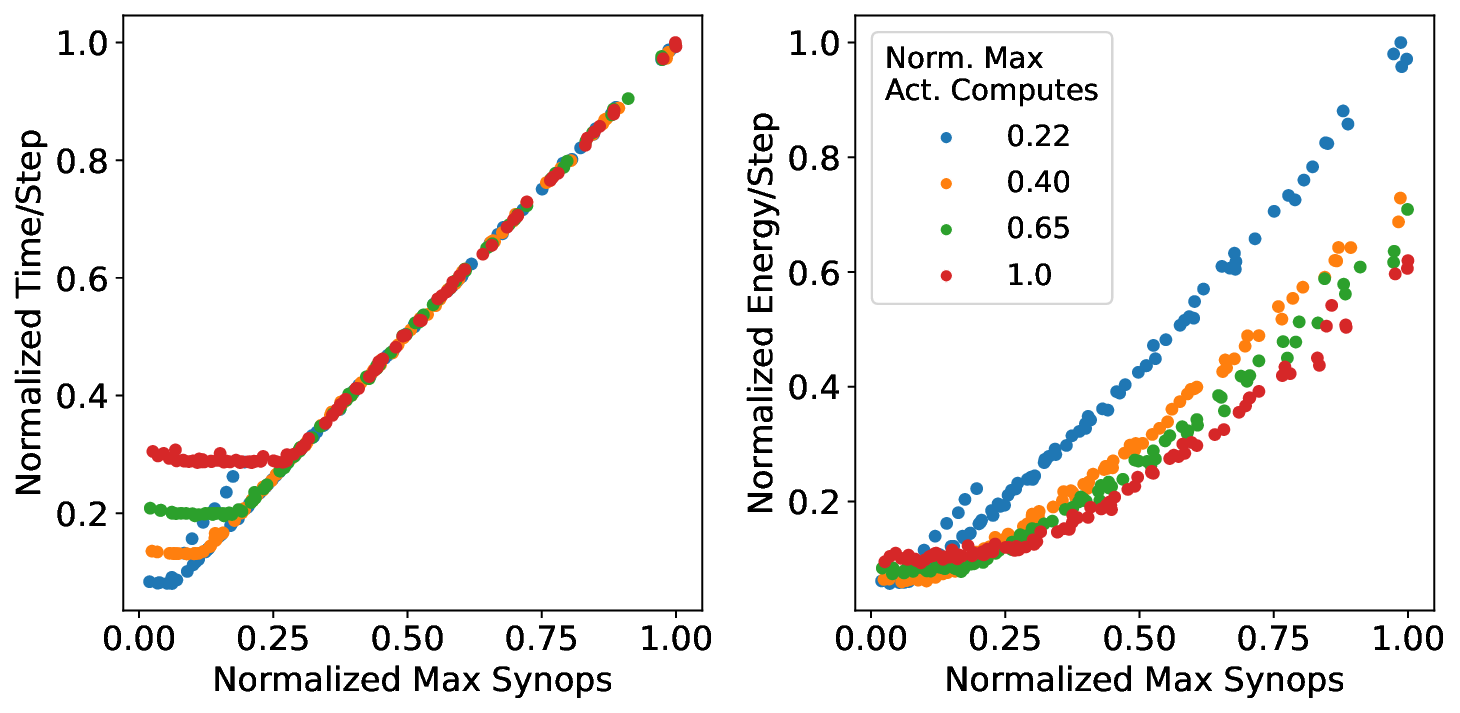
Our study proceeds by first using a simple analytical architecture and workload model to provide theoretical insights into how memory, compute, and traffic operations scale with workload sparsity and parallelization on a neuromorphic chip. Next, we verify and substantiate the insights by extensively profiling three real neuromorphic accelerators: the edge-focused Brainchip AKD1000 [7], the event-camera specialized Synsense Speck [28], and the research-oriented Intel Loihi 2 [20]. Based on the modeling and profiling insights, we synthesize the floorline model, an analog to the roofline model, which visually indicates the performance bounds of a neural network architecture and informs how to optimize any trained network instantiation.
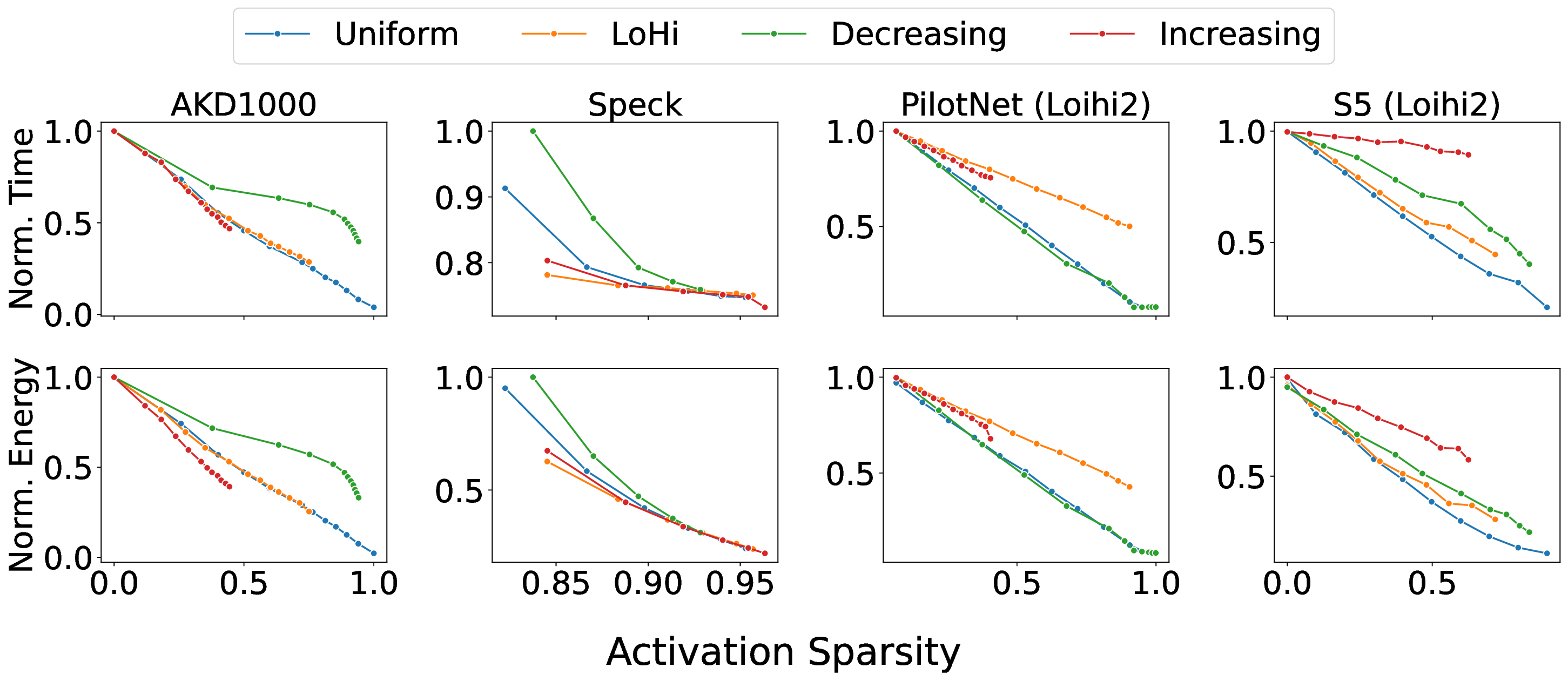
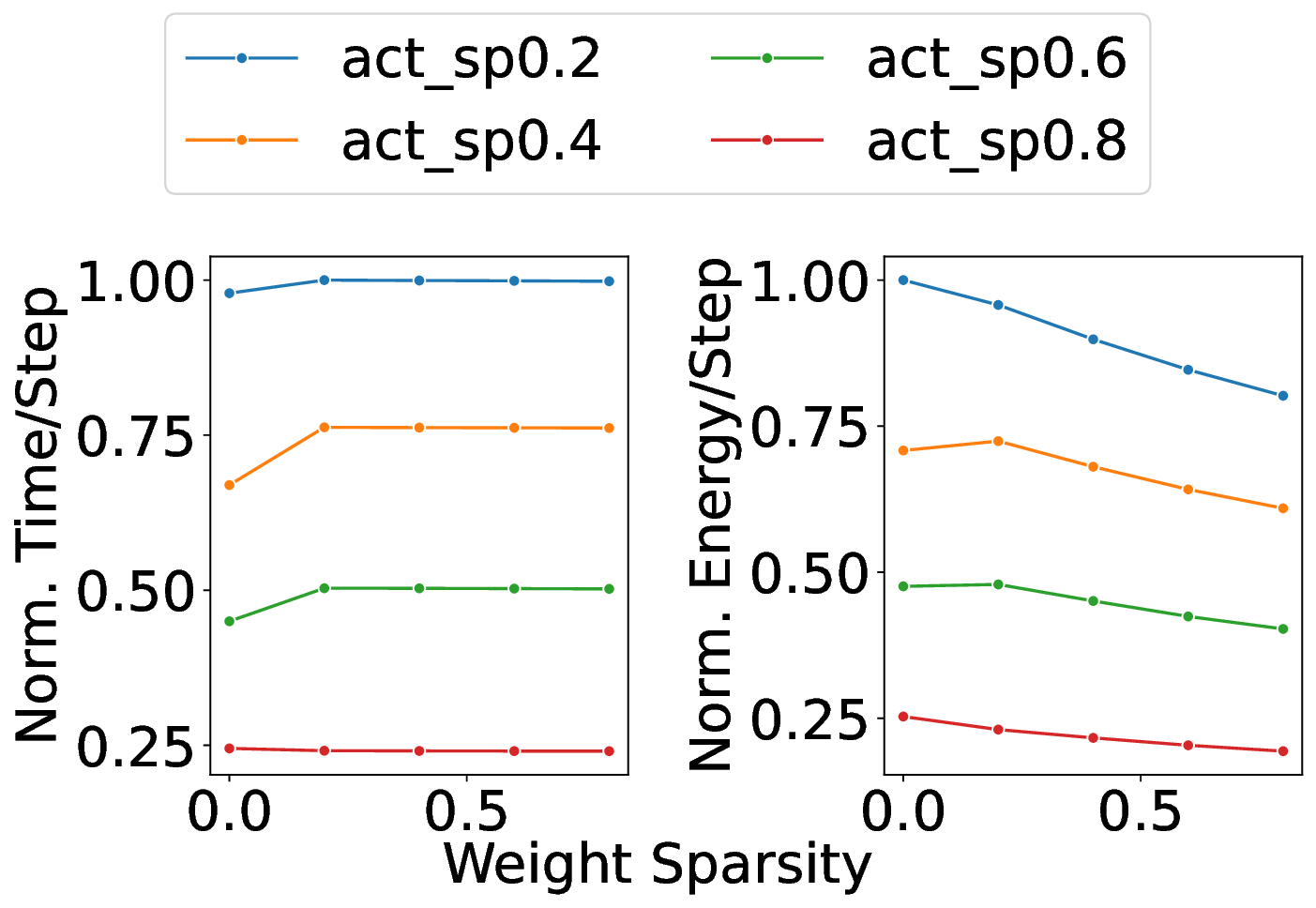
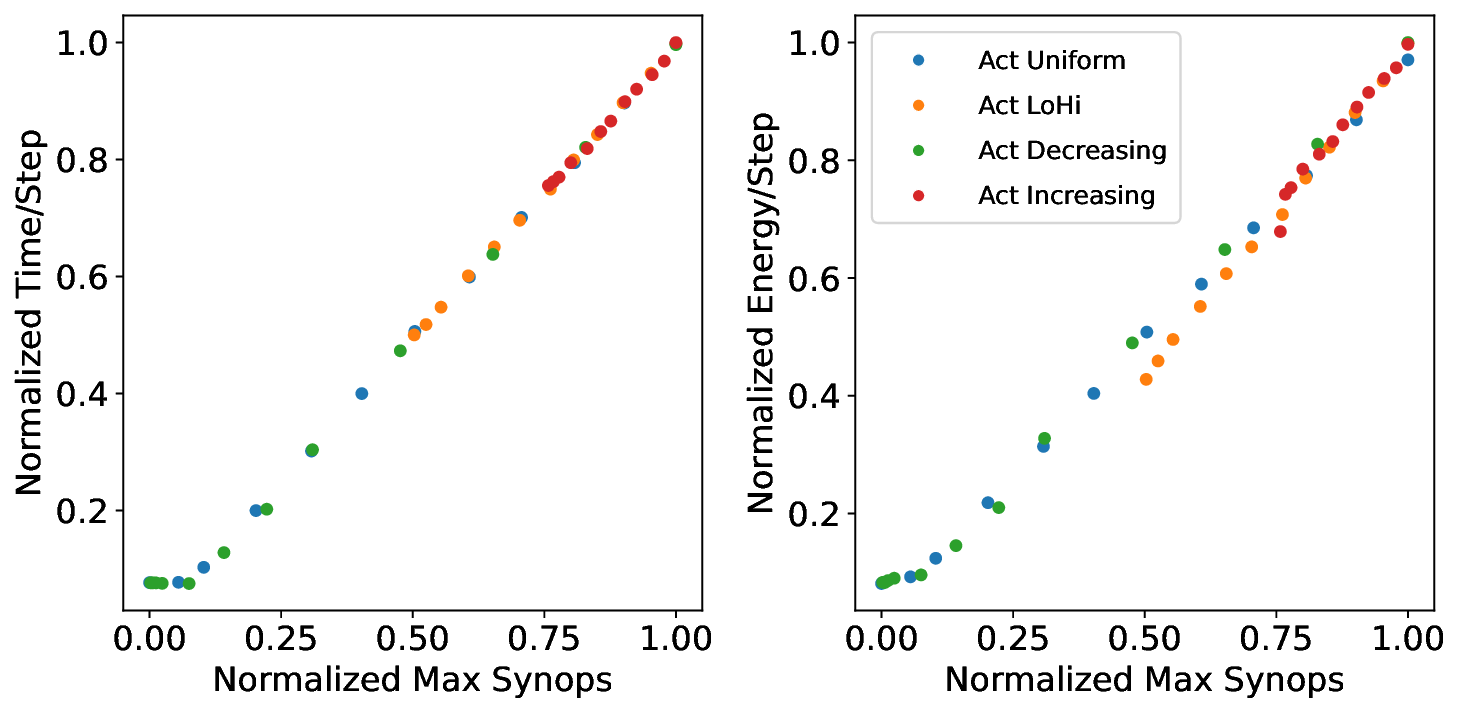
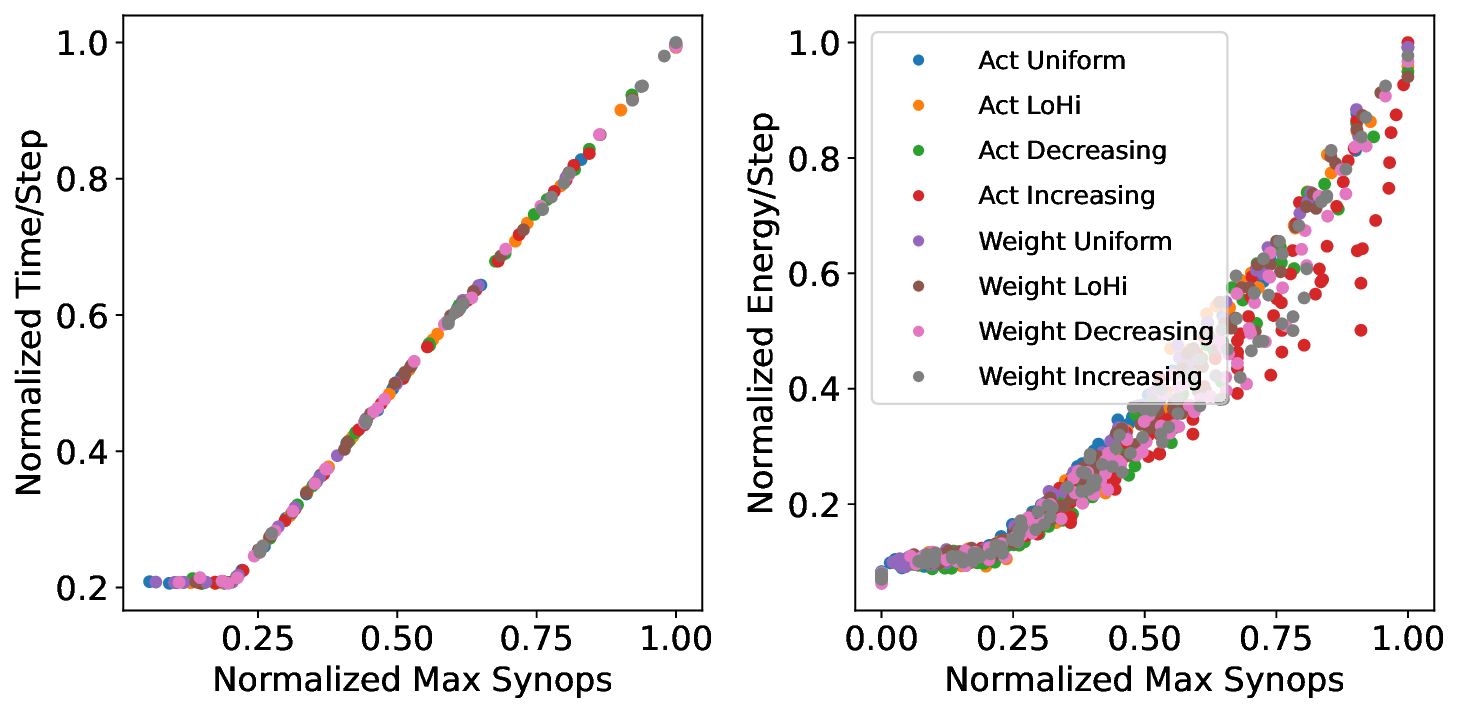
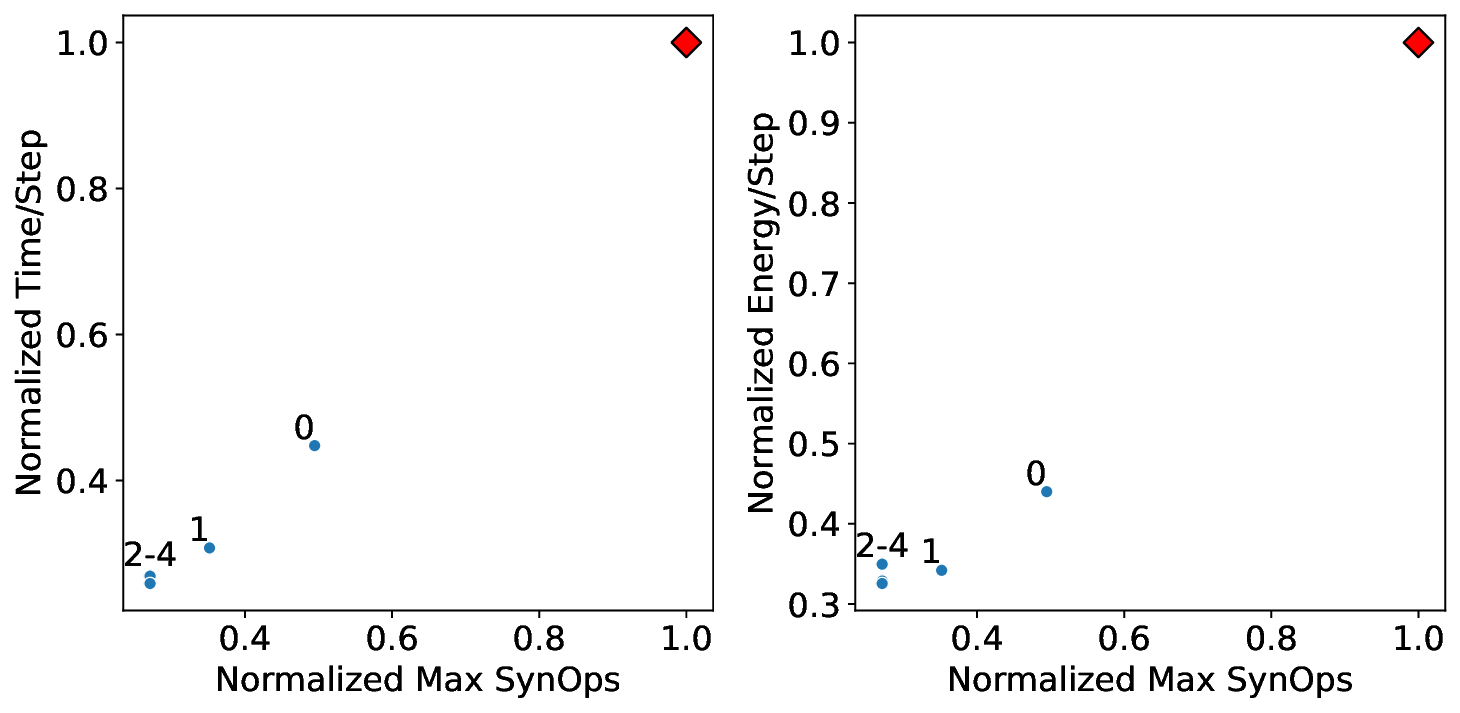
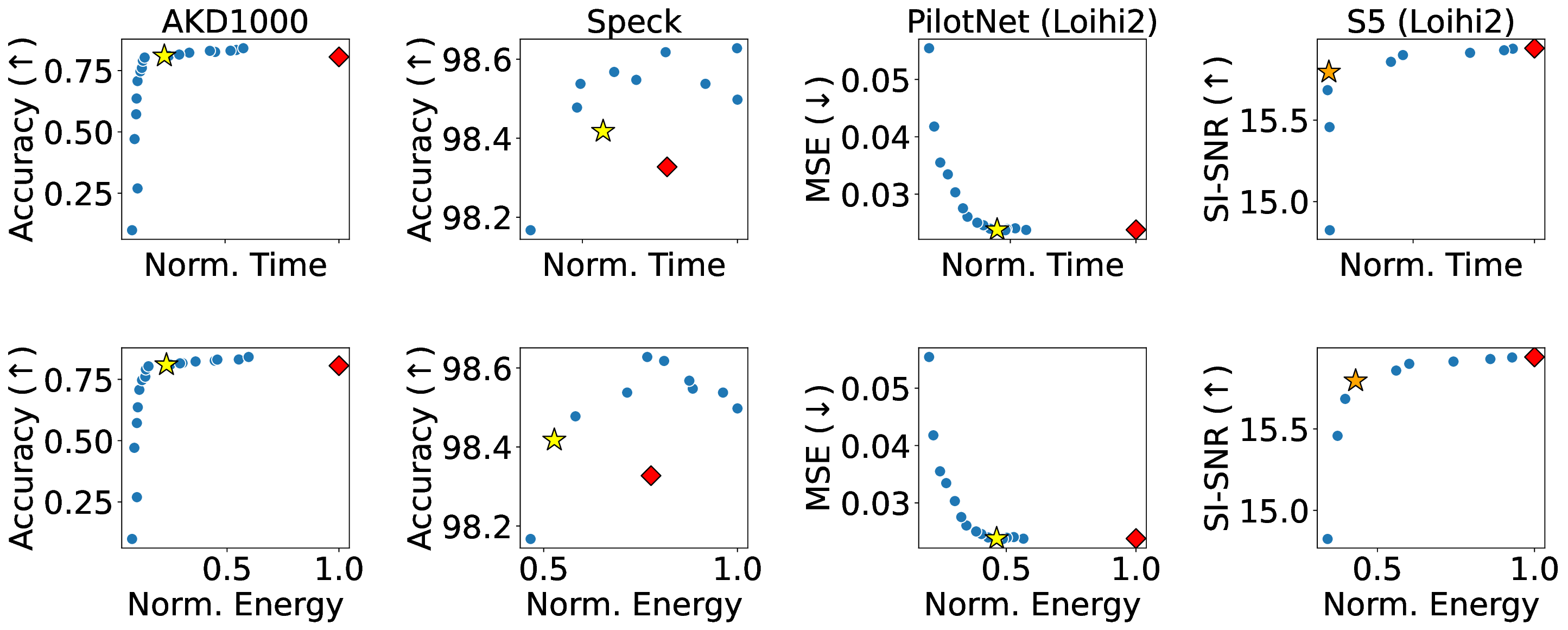
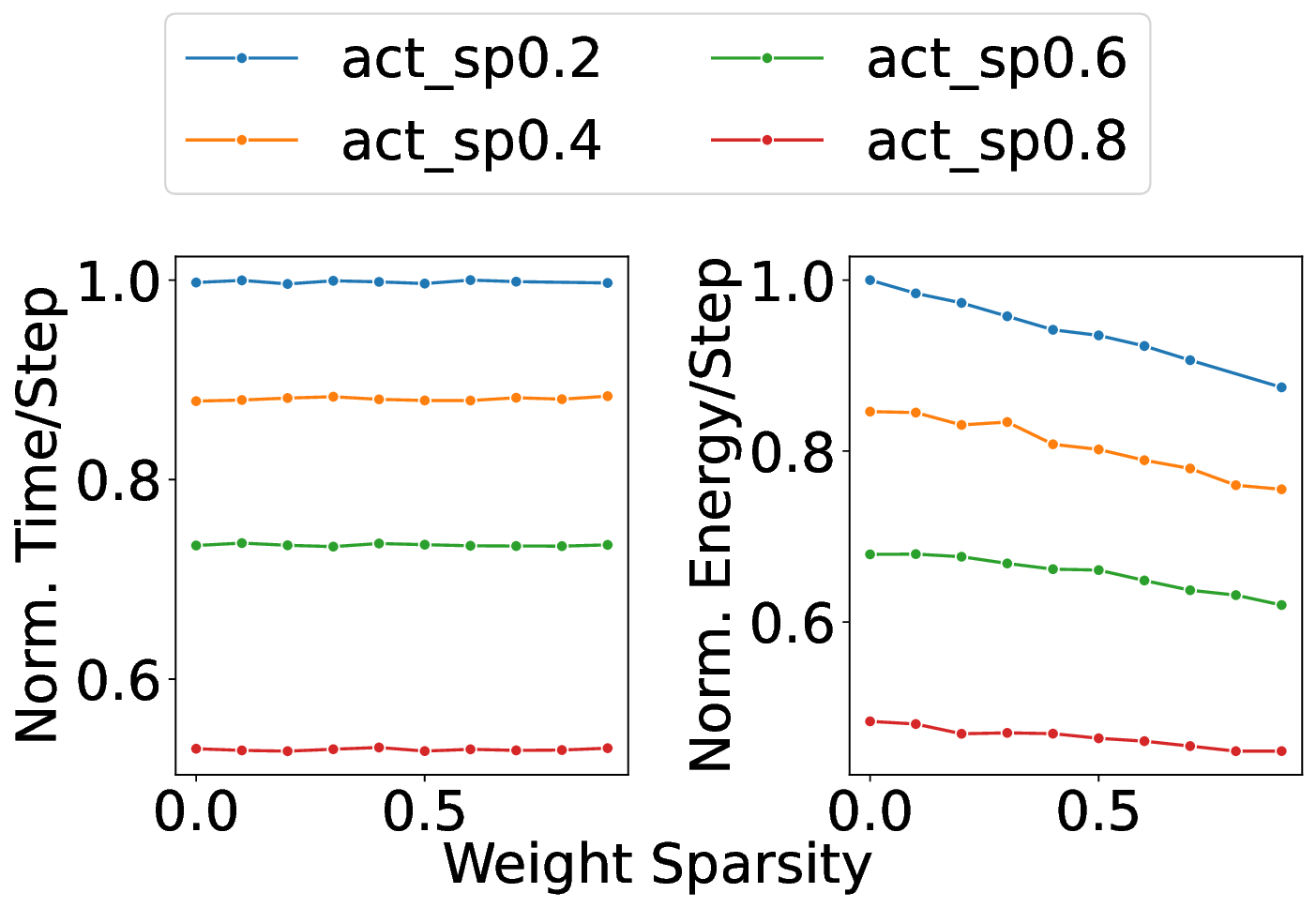
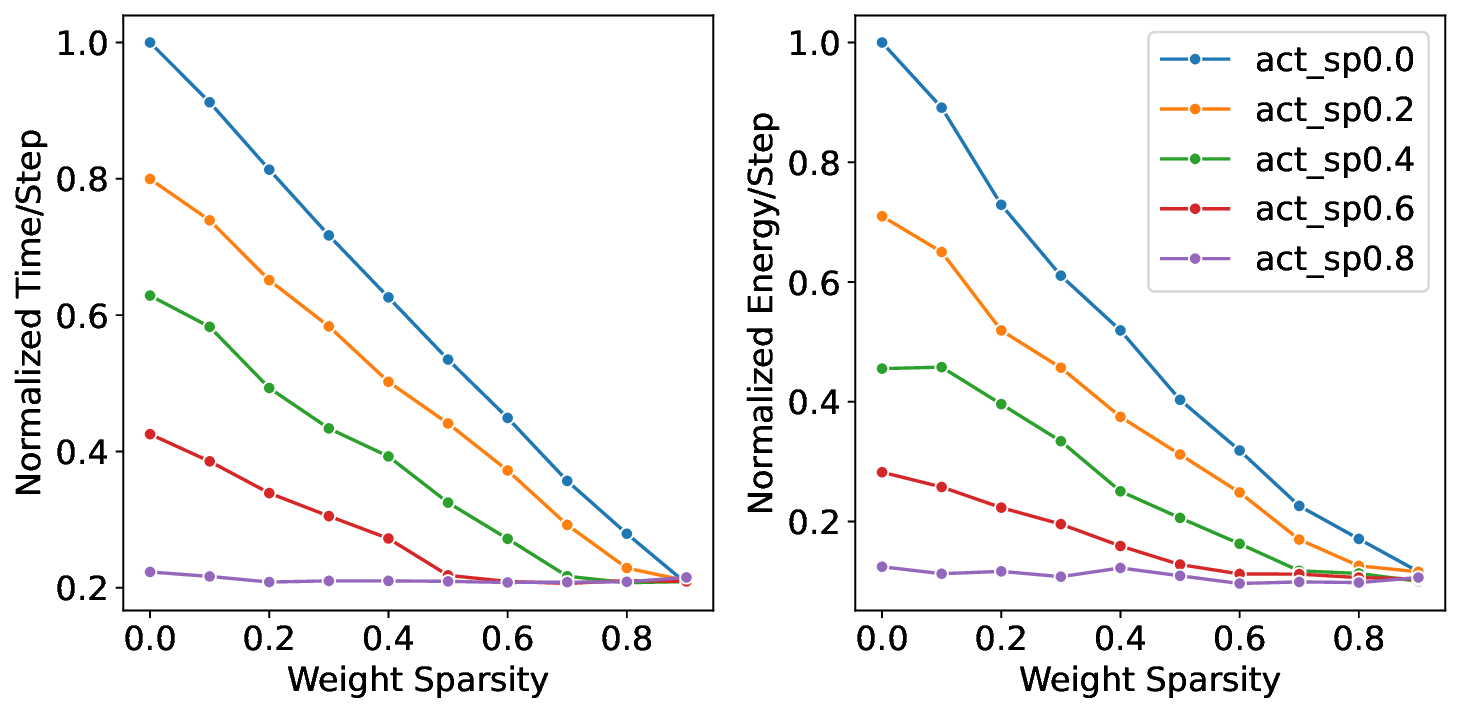
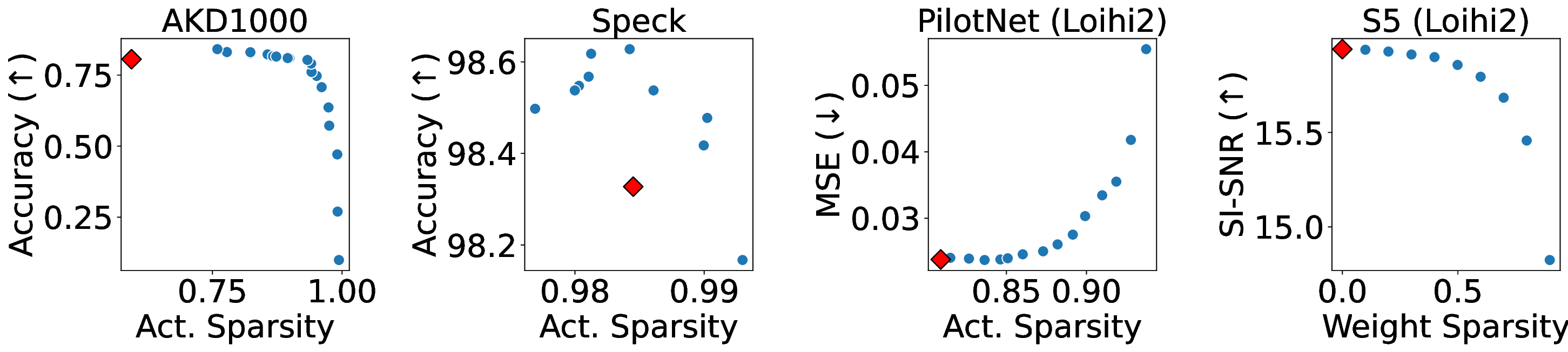
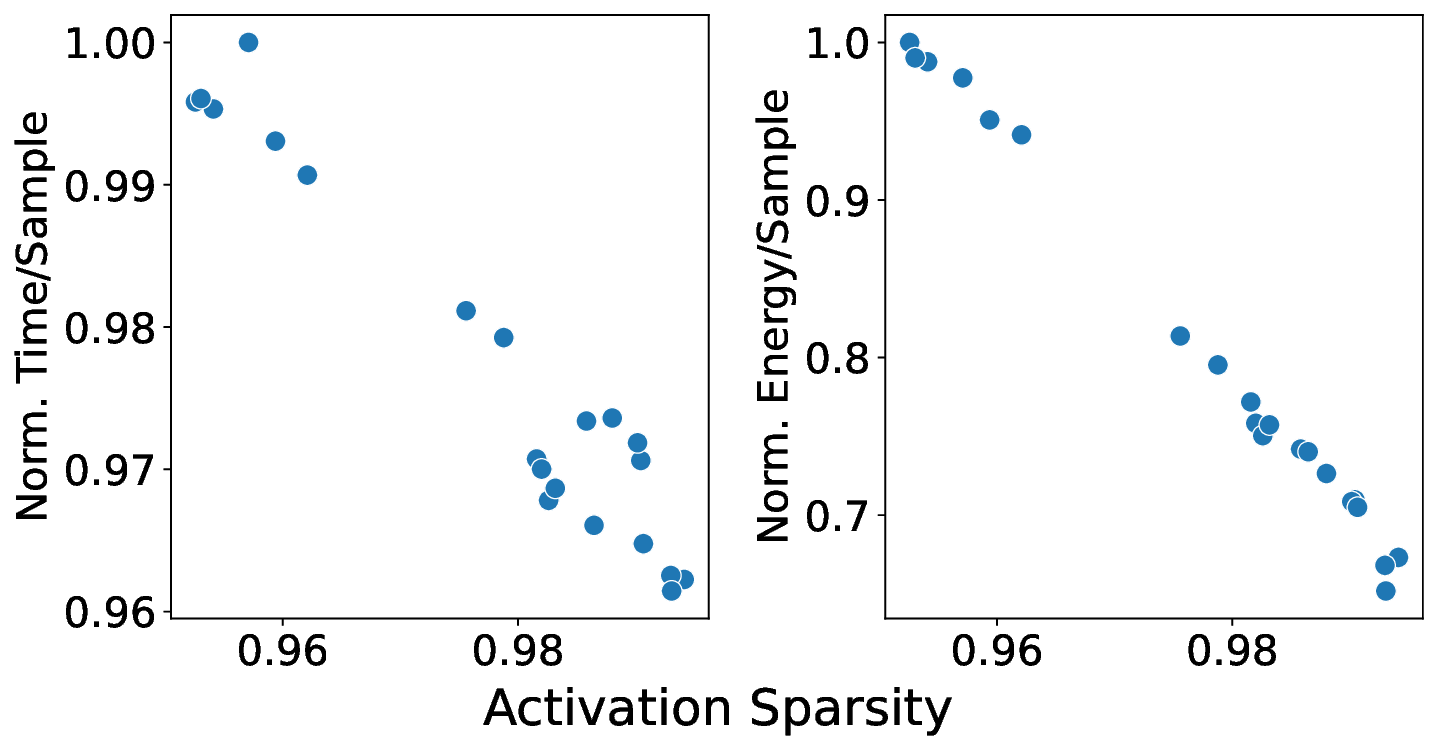
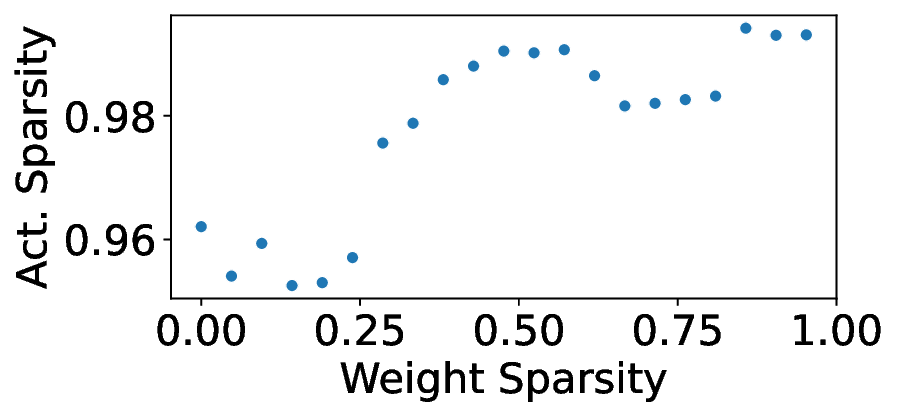
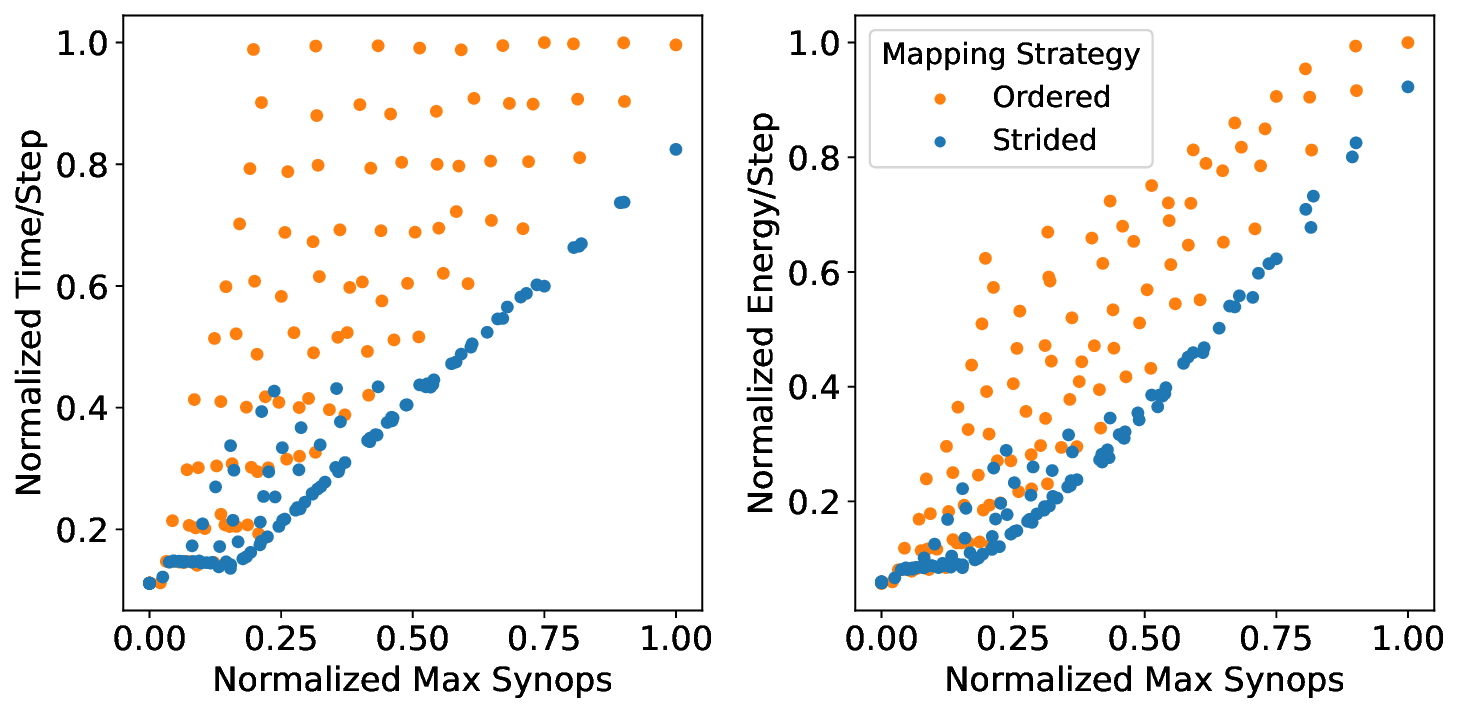
Our analytical modeling and profiling reveal several important insights about neuromorphic accelerator performance. Most critically, we find that conventional network-wide performance proxies are insufficient for neuromorphic architectures due to neurocore-level load imbalance; instead, neurocoreaware metrics are necessary for understanding whether performance will improve. We also observe that current neuromorphic implementations show limited ability to exploit weight sparsity for convolutional networks (CNNs), suggesting that recently proposed CNN weight pruning approaches [10], [43], [44] may require architectural modifications to be effective. For bounds and bottlenecks, we identify memory accesses during synaptic operations (synops) as the usual dominant workload cost, consistent with prior circuit-level analysis [11], [14], [52]. However, we importantly uncover that certain workloads can be bound by neuron computes or message traffic, necessitating different optimization approaches than the synops-bound state.
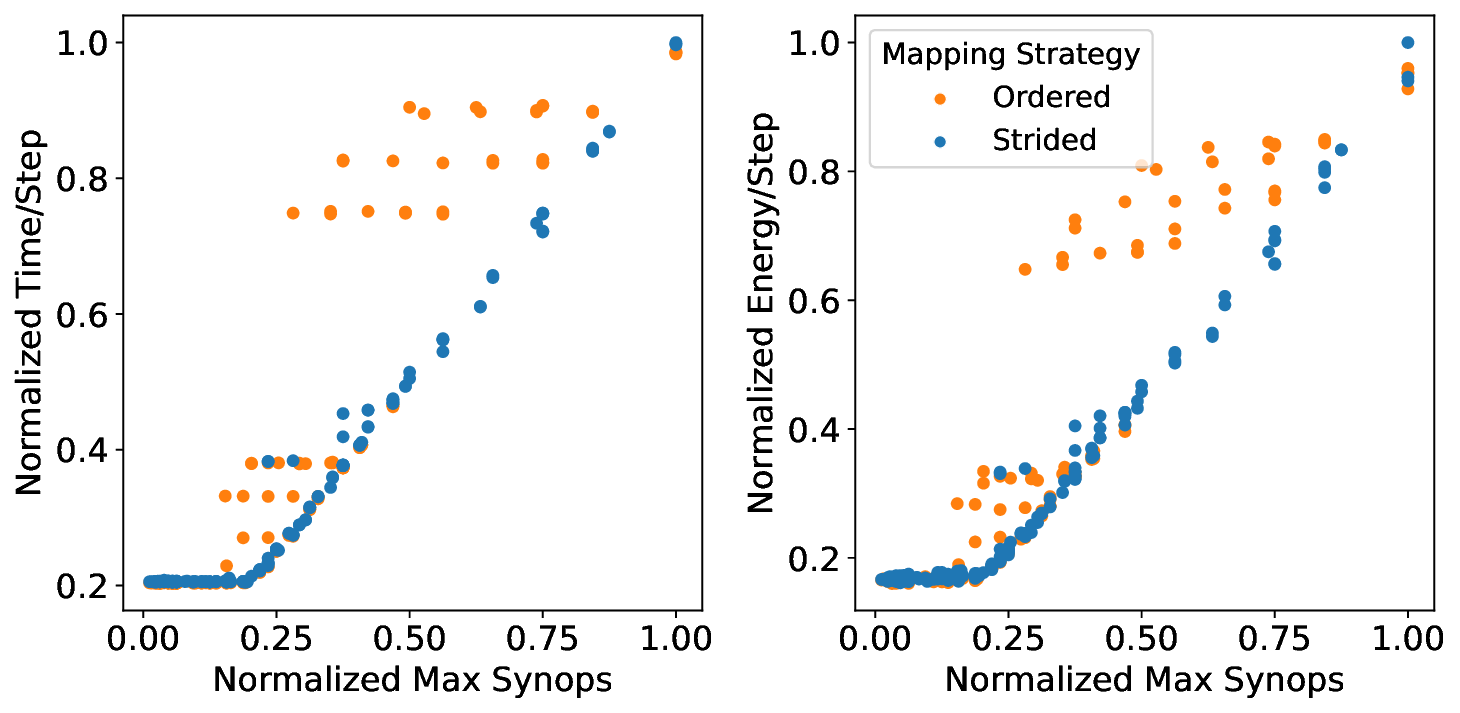
Based on these observations, we develop a two-stage optimization methodology that applies our performance model insights. The first stage co-optimizes network accuracy and sparsity during training to leverage the fundamental sparsity benefits in neuromorphic architectures. The second stage uses our architecture-aware floorline performance model to iteratively optimize neurocore partitioning and mapping. Applied to our three platforms at iso-accuracy operating points, this approach achieves notable performance improvements over baseline configurations: up to 4.29× runtime and 4.36× energy improvements from sparsity optimization, with additional gains of up to 1.83× runtime and 1.52× energy from architecture-aware optimization on Loihi 2. The combined two-stage optimization yields up to 3.86× runtime and 3.38× energy improvements compared to prior manually-tuned configurations for the studied workloads.
In summary, this work studies the performance bounds and bottlenecks of neuromorphic accelerators with the following contributions:
• We present analytical modeling to provide insights for how network sparsity and parallelization configurations affect memory, compute, and traffic bottlenecks.
This section provides the architectural background needed to understand n
…(Full text truncated)…
This content is AI-processed based on ArXiv data.