📝 Original Info
- Title: Efficient Multi-Adapter LLM Serving via Cross-Model KV-Cache Reuse with Activated LoRA
- ArXiv ID: 2512.17910
- Date: 2025-11-26
- Authors: Researchers from original ArXiv paper
📝 Abstract
Modern large language model (LLM) systems increasingly rely on multi-turn pipelines that are composed of multiple task-specific adapters, yet existing serving frameworks remain inefficient, incurring substantial recomputation overhead when switching between adapters. We present the first LLM serving engine that supports cross-model prefix cache reuse between base and adapted models via Activated LoRA (aLoRA), enabling efficient and fine-grained adapter switching during inference. Our design extends the vLLM framework by introducing base-aligned block hashing and activation-aware masking within the model execution path, permitting cache reuse across models while preserving compatibility with existing serving engine optimizations. Integrated into a production-grade inference stack, this approach supports dynamic adapter activation without excessive key-value tensor recomputation. Evaluation across representative multi-turn, multi-adapter pipelines demonstrates up to 58x end-to-end latency reduction and over 100x time-to-first-token improvement relative to standard LoRA baselines, with benefits that scale with model size and sequence length and manifest across all stages of the request lifecycle. This work bridges parameter-efficient model adaptation with high-performance serving, providing the first complete realization of cross-model KV-cache reuse in modern LLM inference engines.
💡 Deep Analysis
Deep Dive into Efficient Multi-Adapter LLM Serving via Cross-Model KV-Cache Reuse with Activated LoRA.
Modern large language model (LLM) systems increasingly rely on multi-turn pipelines that are composed of multiple task-specific adapters, yet existing serving frameworks remain inefficient, incurring substantial recomputation overhead when switching between adapters. We present the first LLM serving engine that supports cross-model prefix cache reuse between base and adapted models via Activated LoRA (aLoRA), enabling efficient and fine-grained adapter switching during inference. Our design extends the vLLM framework by introducing base-aligned block hashing and activation-aware masking within the model execution path, permitting cache reuse across models while preserving compatibility with existing serving engine optimizations. Integrated into a production-grade inference stack, this approach supports dynamic adapter activation without excessive key-value tensor recomputation. Evaluation across representative multi-turn, multi-adapter pipelines demonstrates up to 58x end-to-end latenc
📄 Full Content
EFFICIENT MULTI-ADAPTER LLM SERVING VIA CROSS-MODEL
KV-CACHE REUSE WITH ACTIVATED LORA
Allison Li 1
Kristjan Greenewald 2
Thomas Parnell 2
Navid Azizan 1
1Massachusetts Institute of Technology
2IBM Research
ABSTRACT
Modern large language model (LLM) systems increasingly rely on multi-turn pipelines that are composed
of multiple task-specific adapters, yet existing serving frameworks remain inefficient, incurring substantial
recomputation overhead when switching between adapters. We present the first LLM serving engine that supports
cross-model prefix cache reuse between base and adapted models via Activated LoRA (aLoRA), enabling efficient
and fine-grained adapter switching during inference. Our design extends the vLLM framework by introducing
base-aligned block hashing and activation-aware masking within the model execution path, permitting cache
reuse across models while preserving compatibility with existing serving engine optimizations1. Integrated into a
production-grade inference stack, this approach supports dynamic adapter activation without excessive key-value
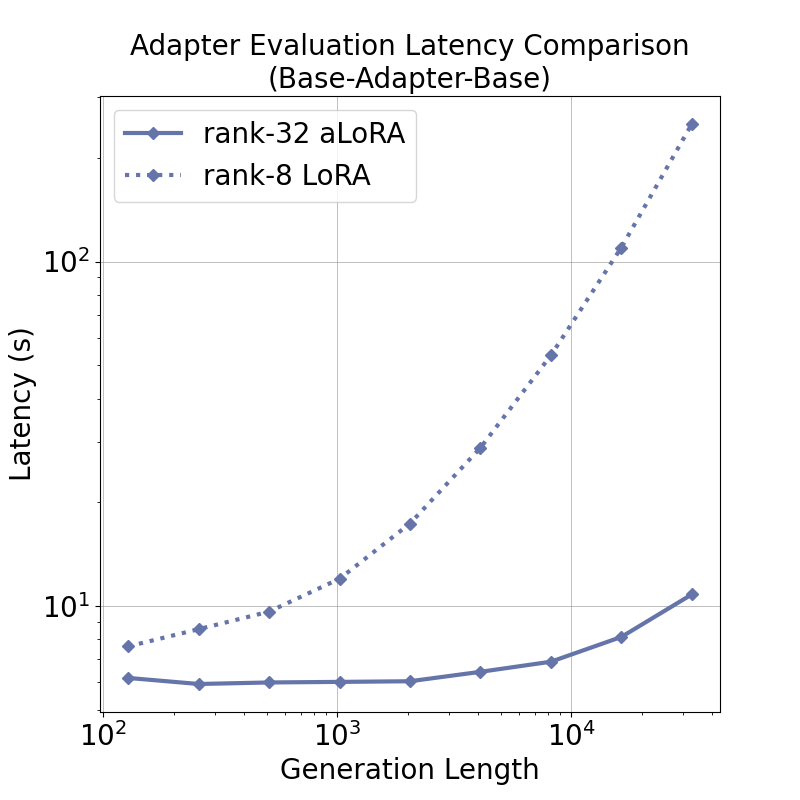
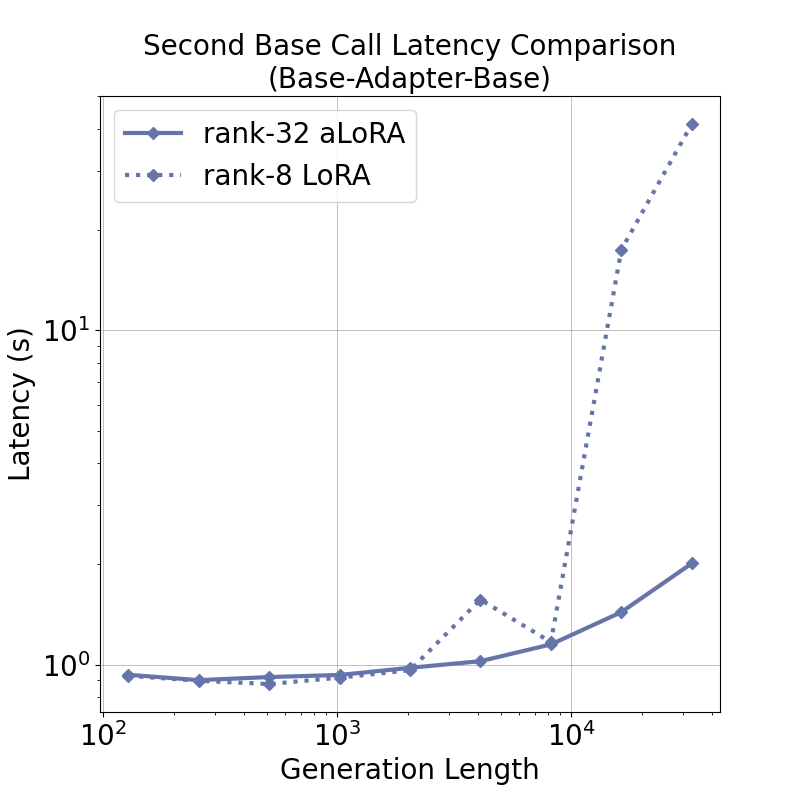
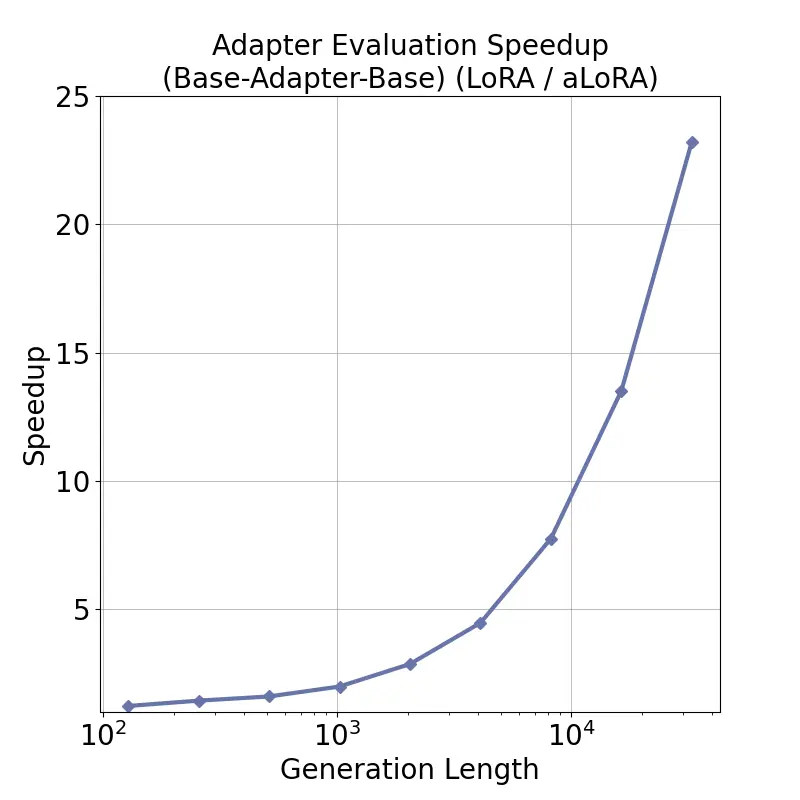
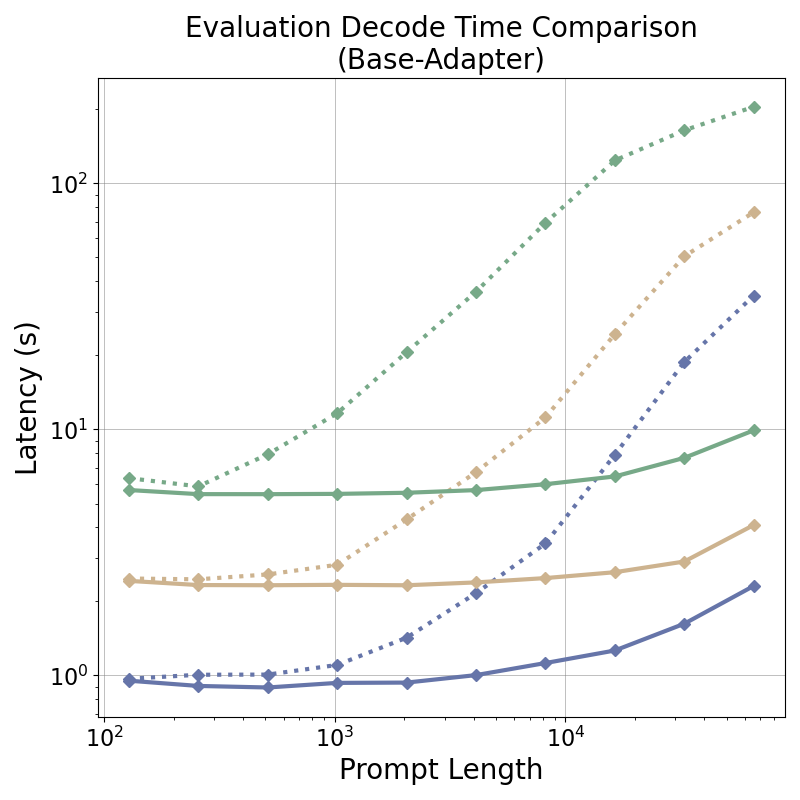
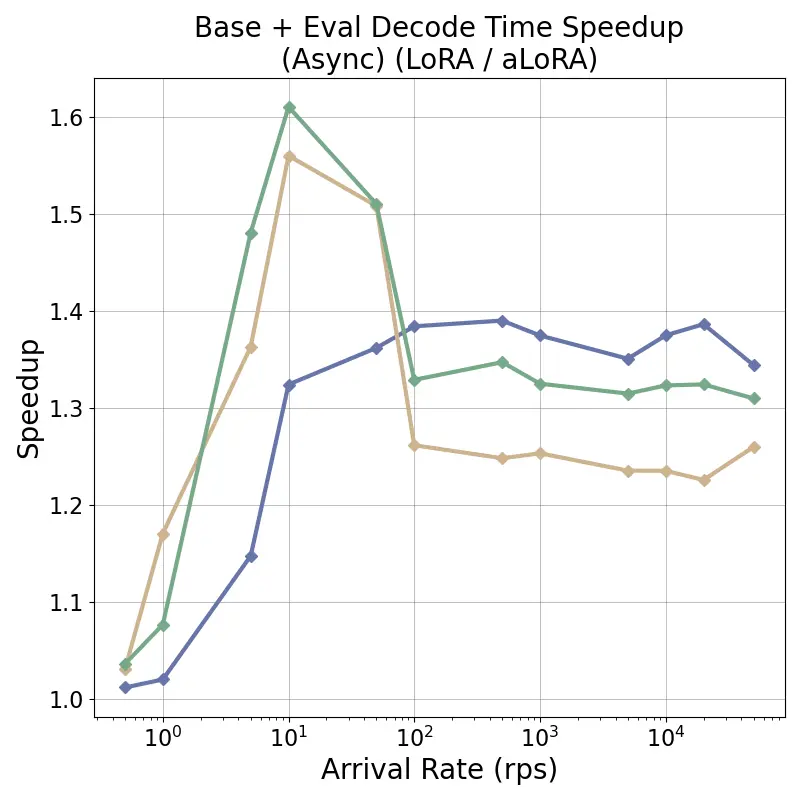
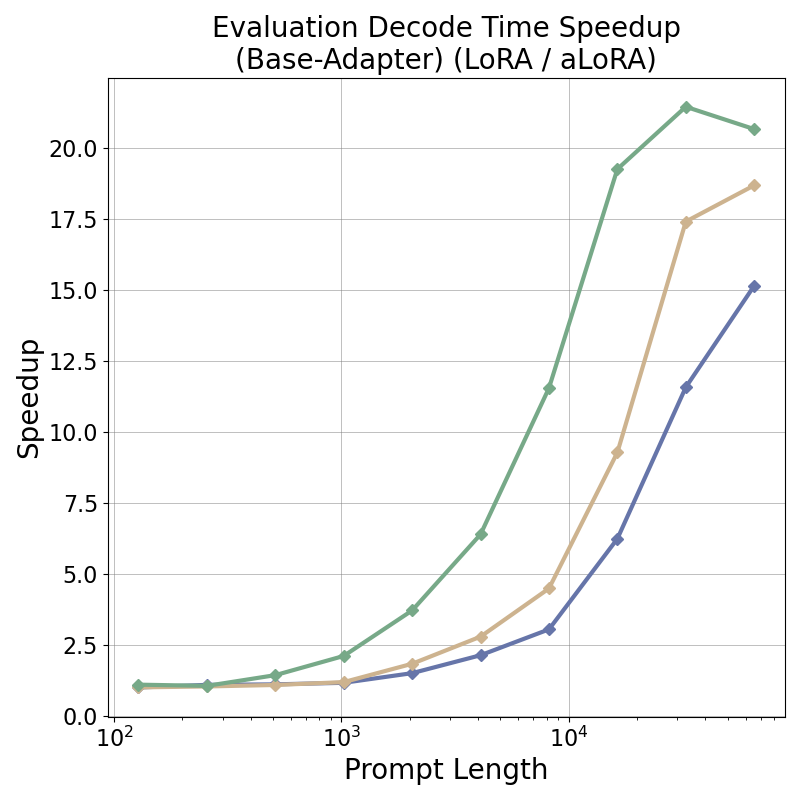
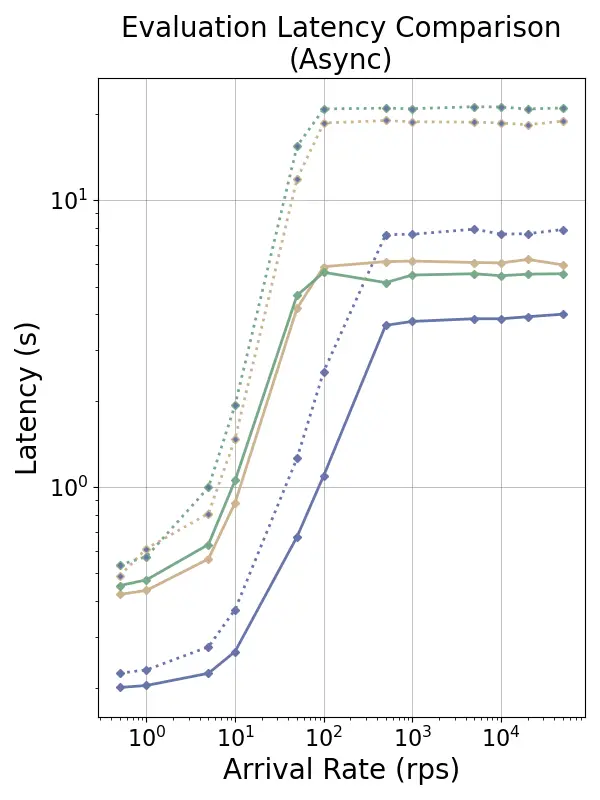
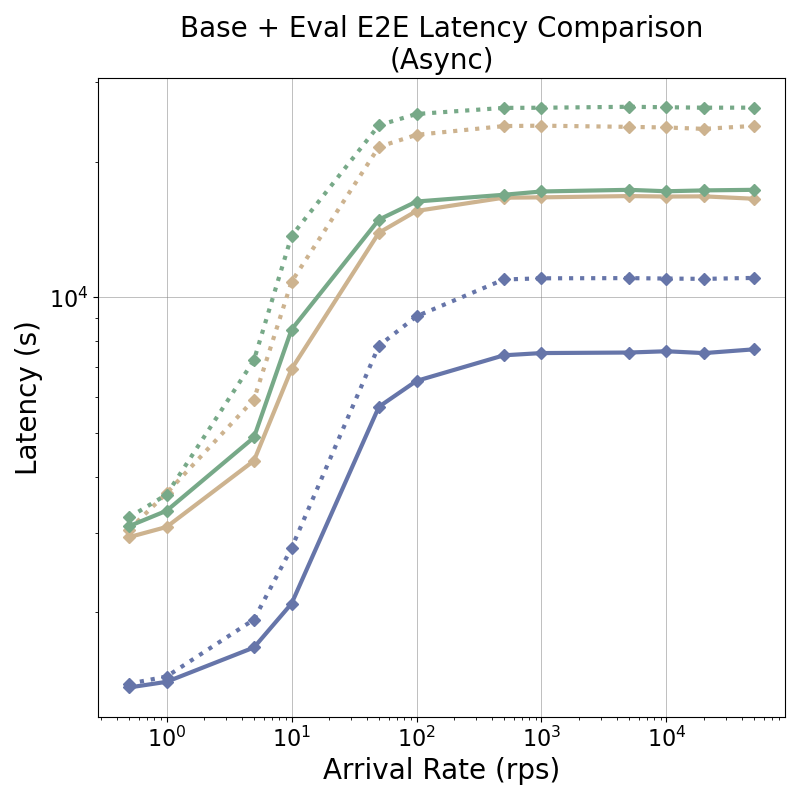
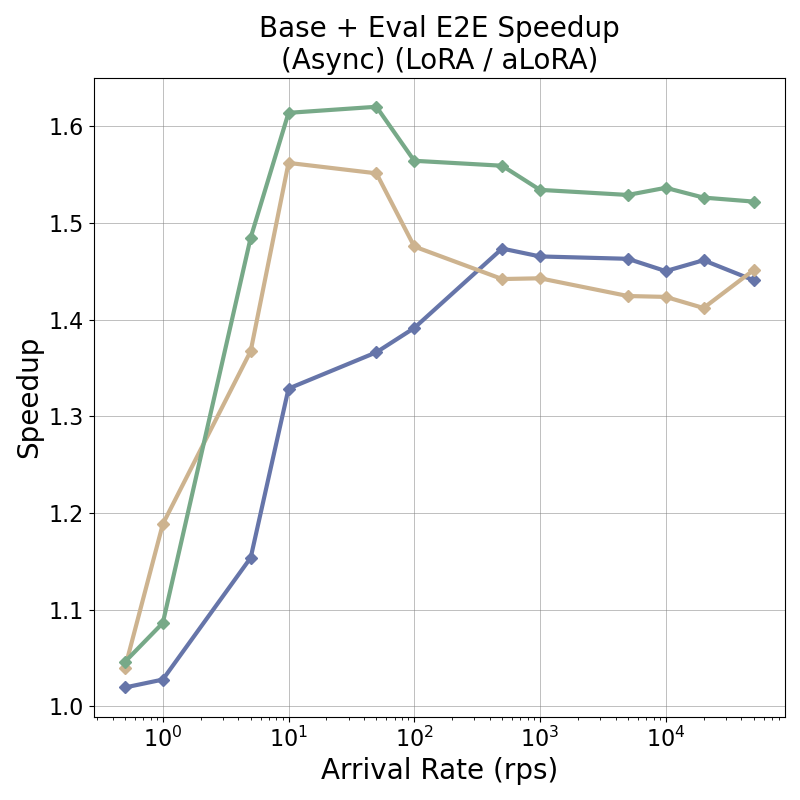
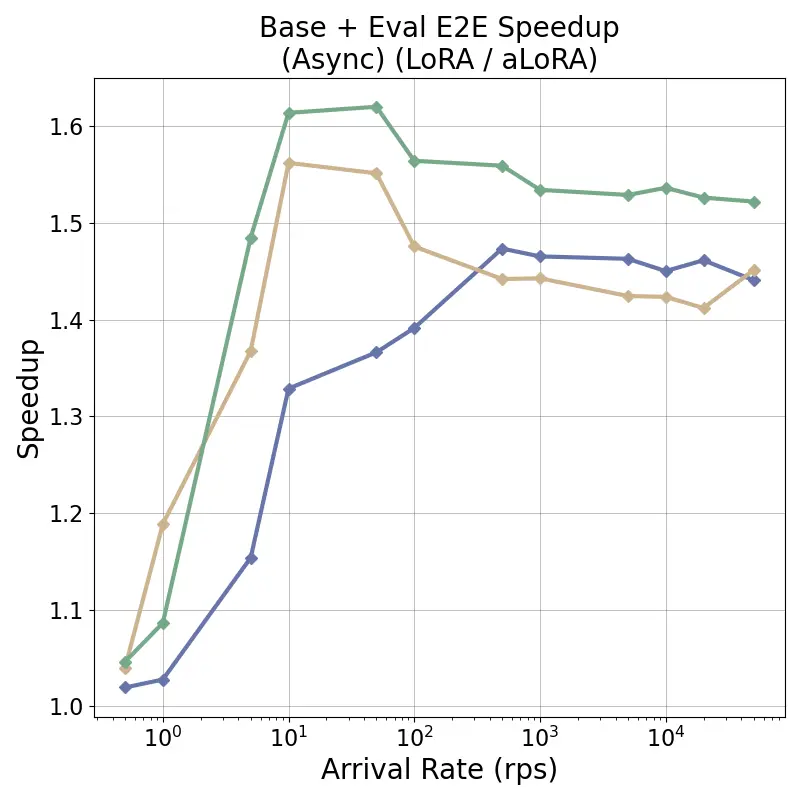
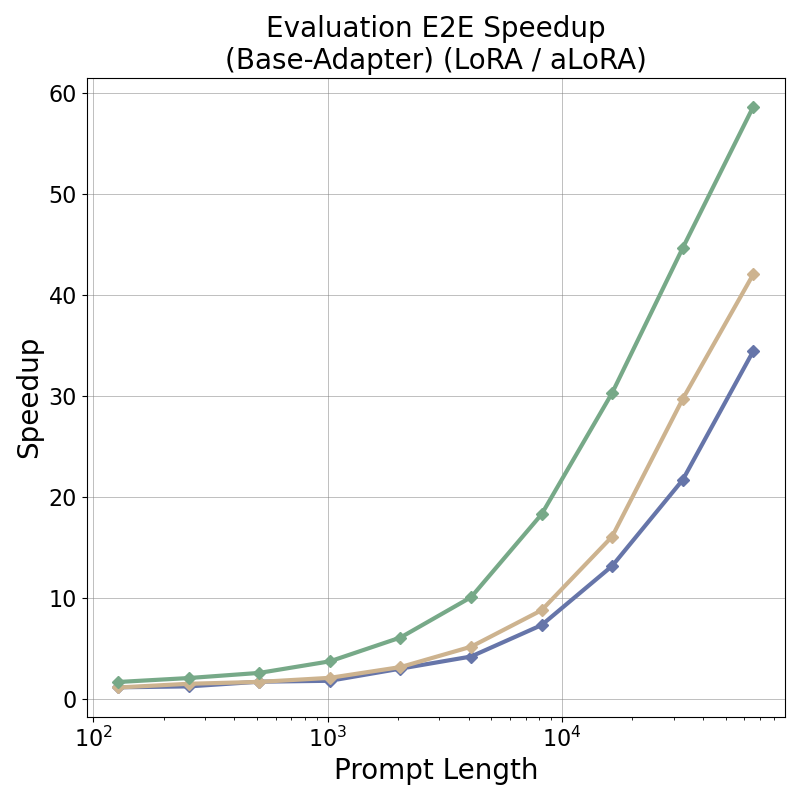
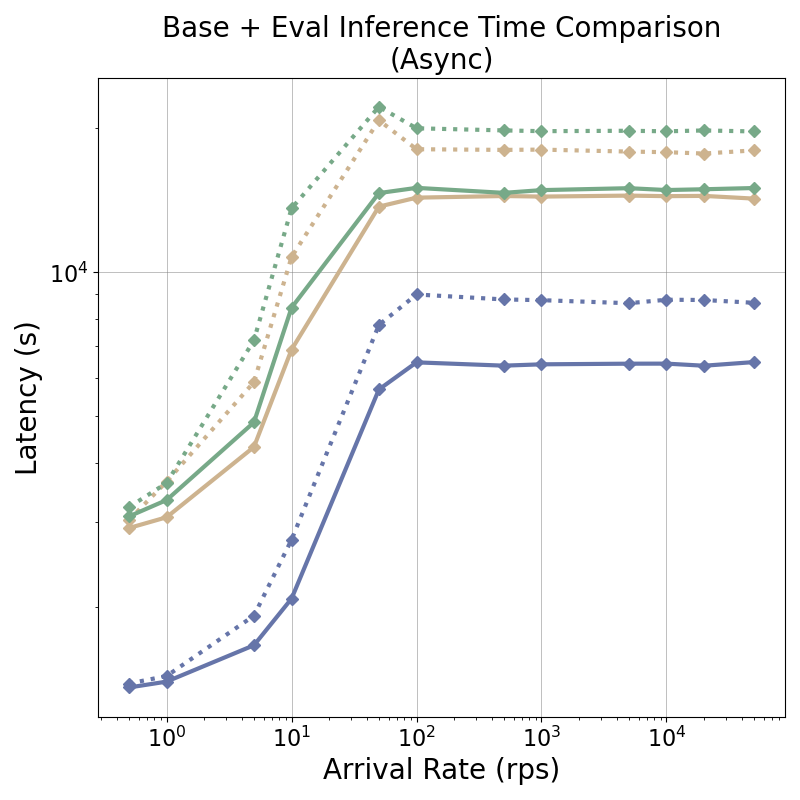
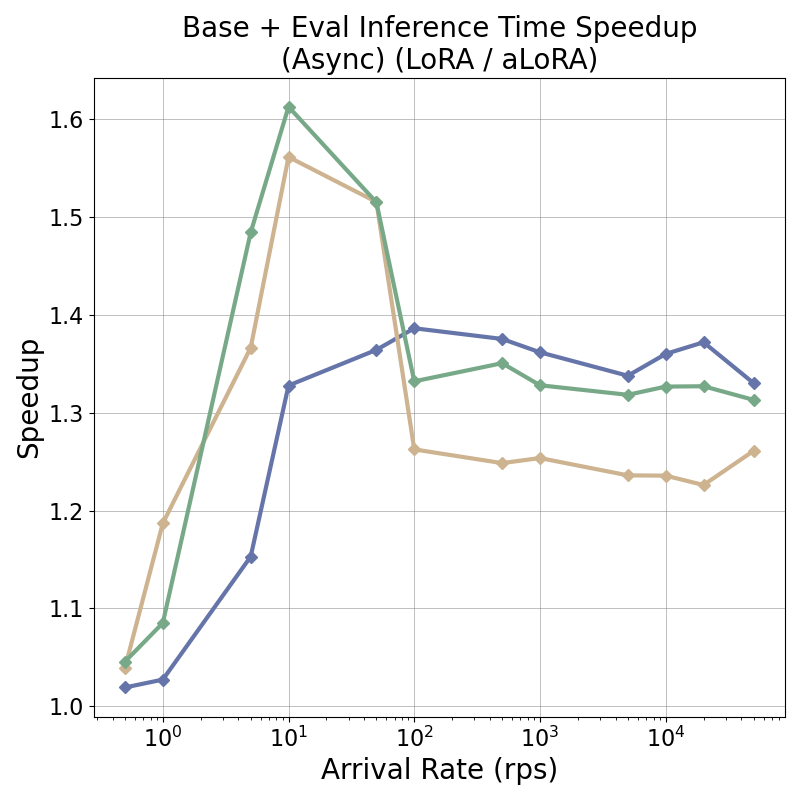
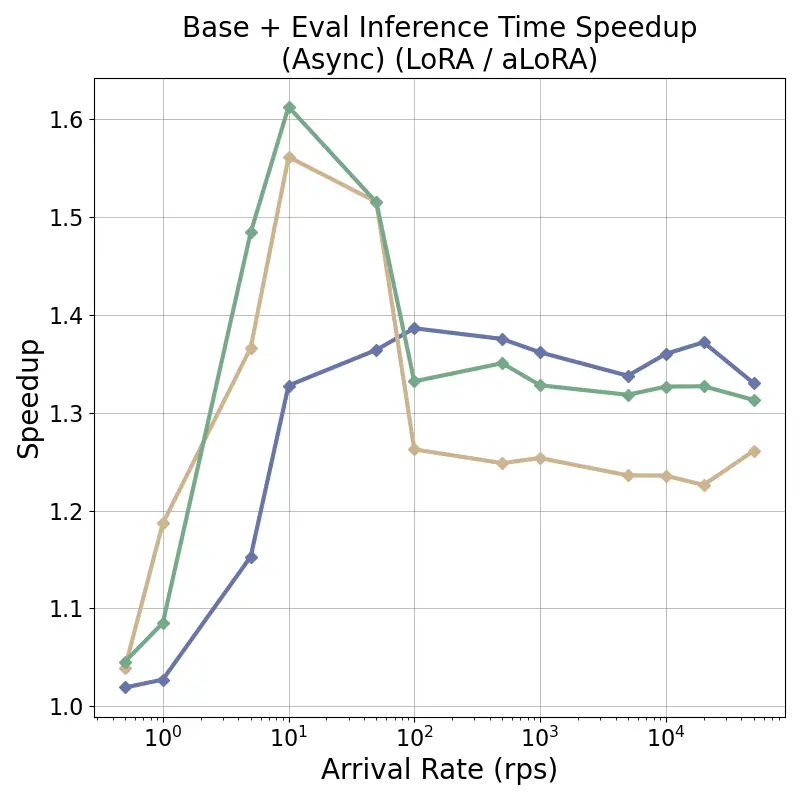
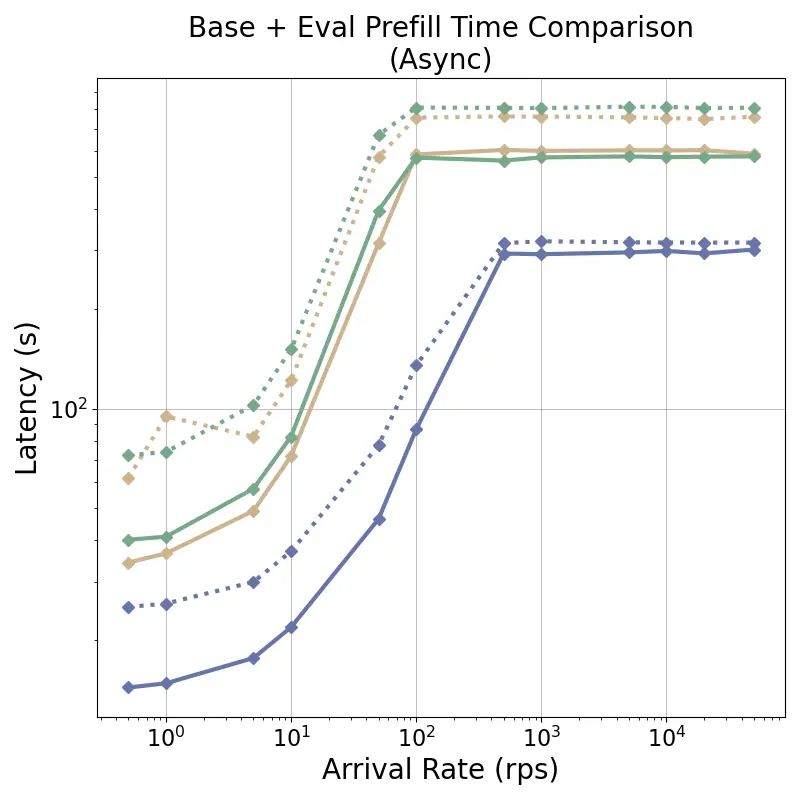
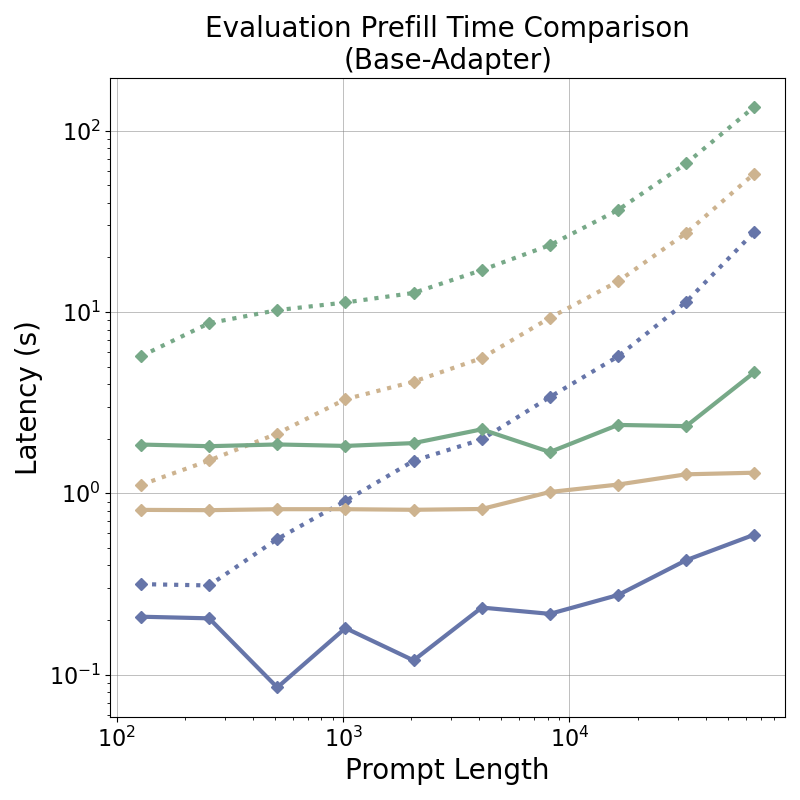
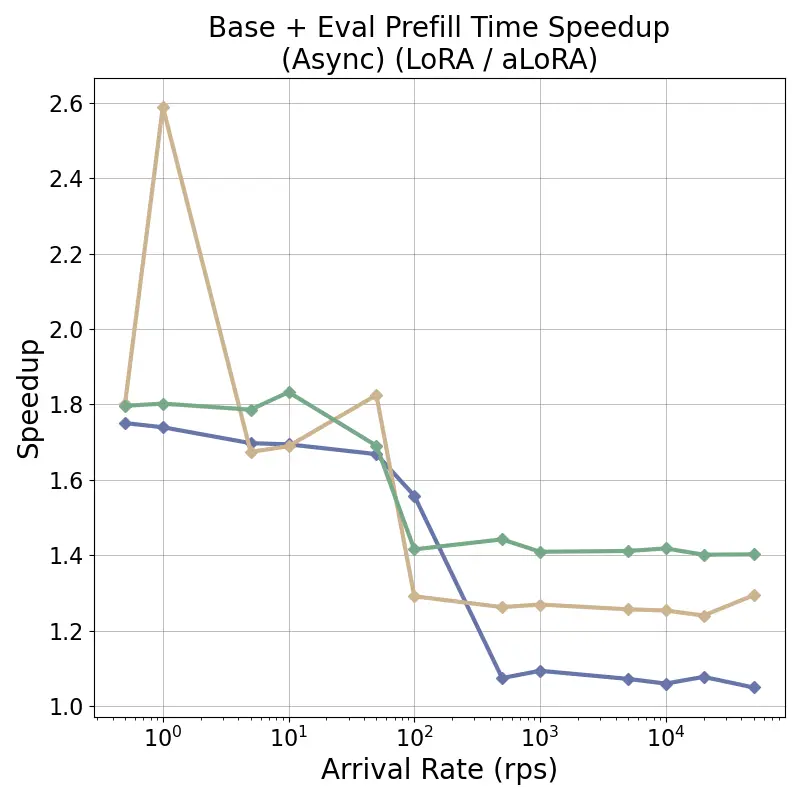
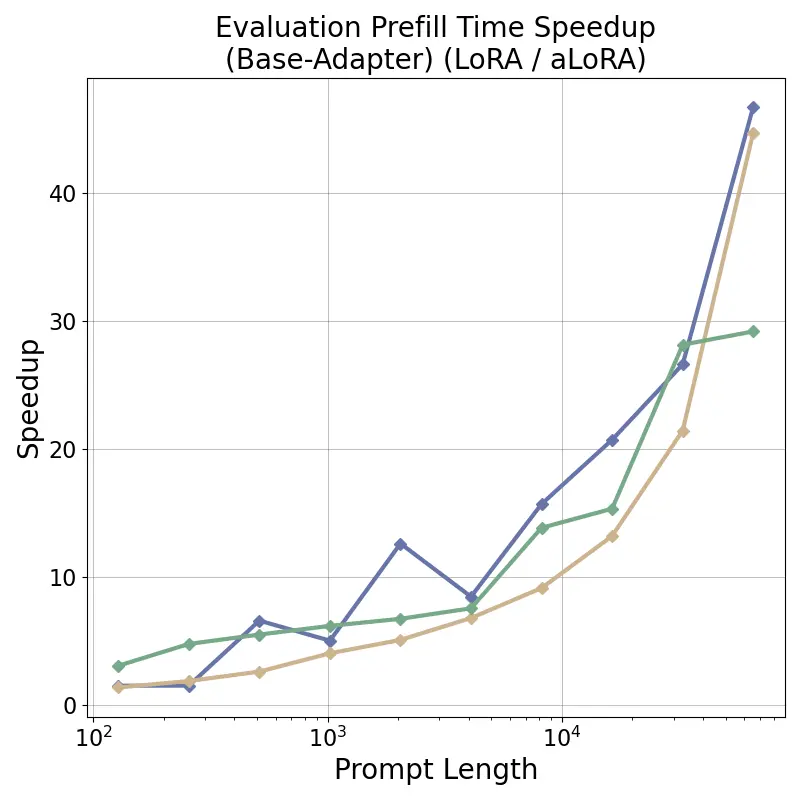
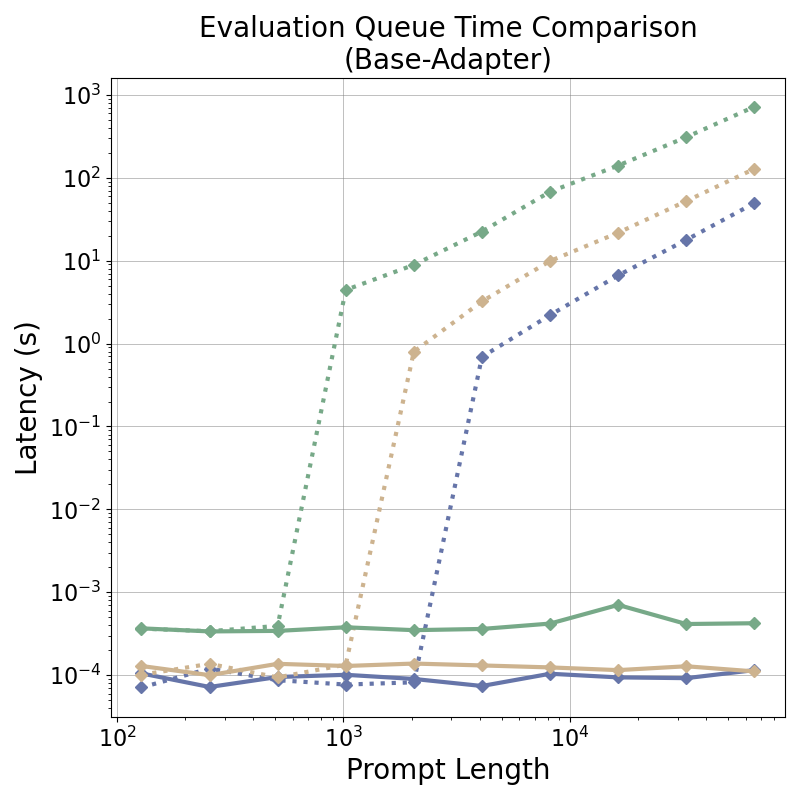
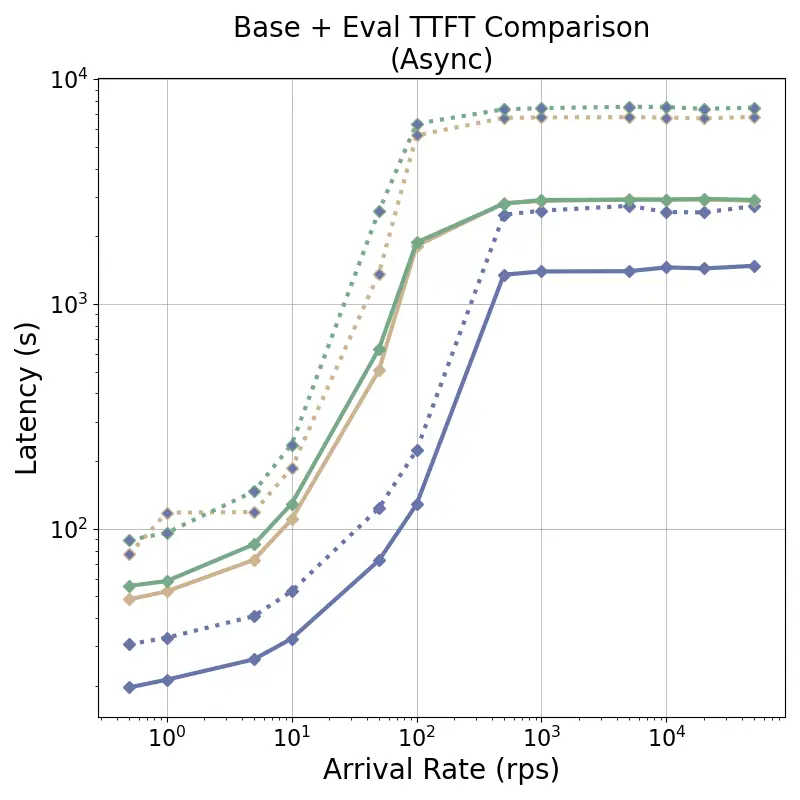
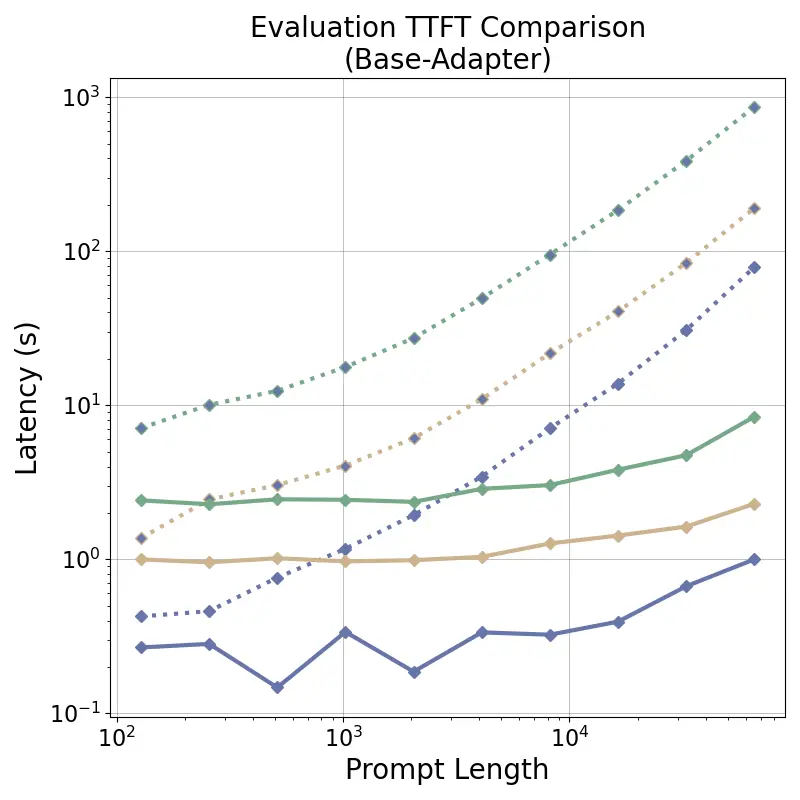
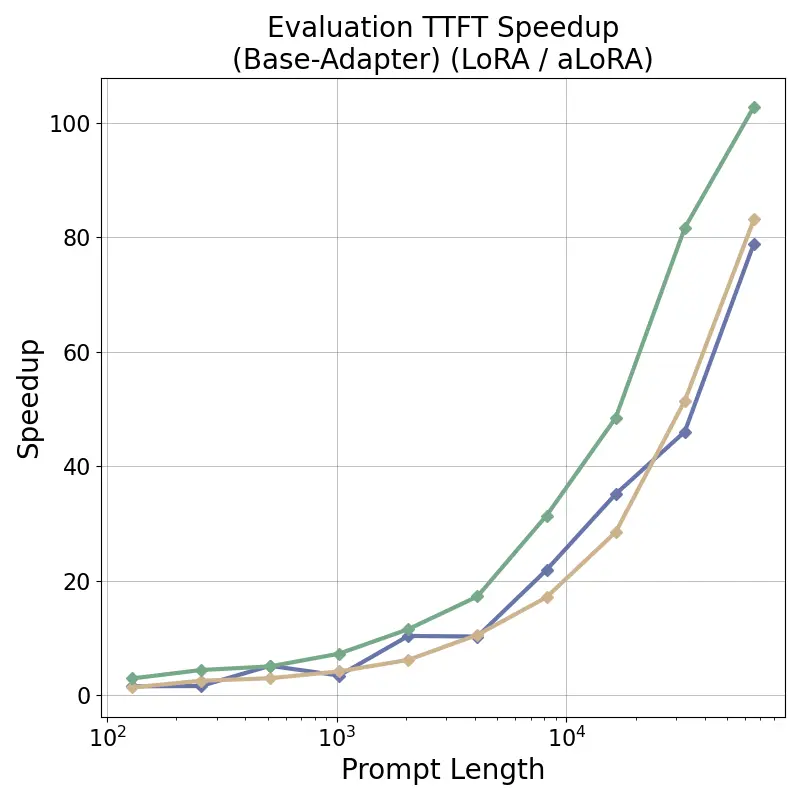
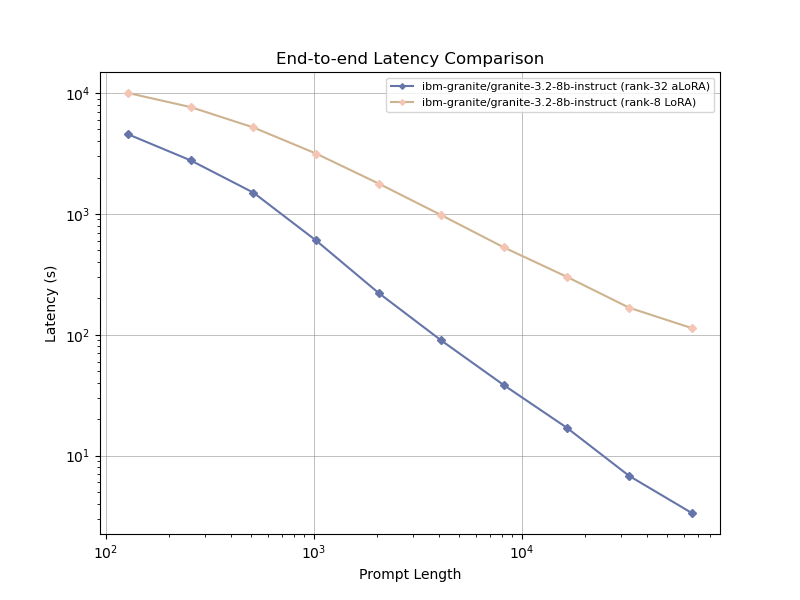
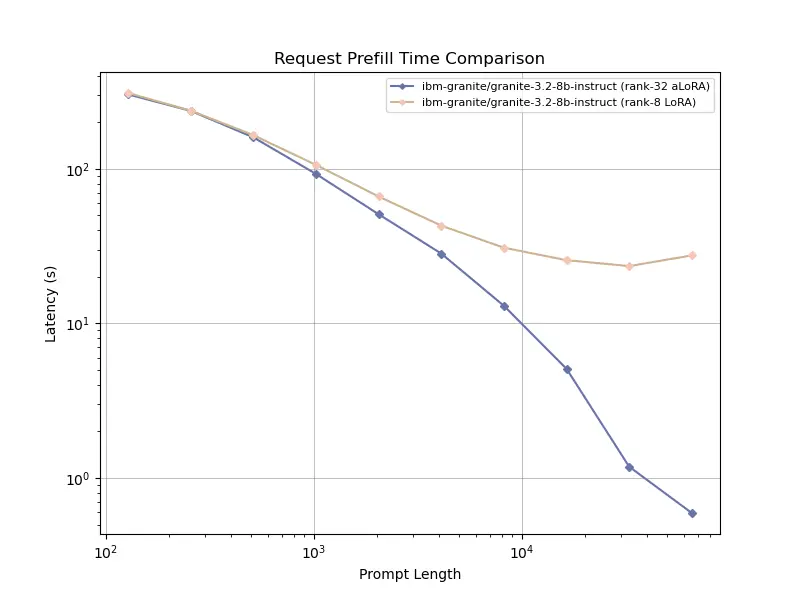
tensor recomputation. Evaluation across representative multi-turn, multi-adapter pipelines demonstrates up to
58× end-to-end latency reduction and over 100× time-to-first-token improvement relative to standard LoRA
baselines, with benefits that scale with model size and sequence length and manifest across all stages of the request
lifecycle. This work bridges parameter-efficient model adaptation with high-performance serving, providing the
first complete realization of cross-model KV-cache reuse in modern LLM inference engines.
1
INTRODUCTION
In recent years, the rise of large language models (LLMs)
has spurred growing demand for model specialization, a
trait essential for LLM adoption in narrow vertical mar-
kets requiring extensive domain-specific knowledge. LLM
fine-tuning enhances pretrained LLMs by adapting their
knowledge to a specific domain or task without compro-
mising the model’s core language capabilities. In contrast
to full-finetuning methods, which face obstacles in compu-
tational resource constraints, long training times, overfit-
ting, and potentially “catastrophic forgetting” (Nobari et al.,
2025), parameter-efficient fine-tuning (PEFT) methods such
as low-rank adaptation (LoRA) adapters freeze most of the
foundation model’s weights during training and adjust only
rank r additive adapters to target weight matrices. LoRAs
have gained widespread adoption in practice due to their
low resource requirements, often comparable performance
to full finetuning, and the inference-time modular flexibility
that they offer since adapters can be easily and efficiently
switched in and out (Hu et al., 2021) on a single instance of
the served base model.
As LLMs are increasingly deployed in complex reasoning
and agentic pipelines (OpenAI et al., 2024; de Lamo Cas-
trillo et al., 2025; Yao et al., 2023; Song et al., 2023), in-
1Code for our design can be found at https://github.
com/tdoublep/vllm/tree/alora
ference workloads are no longer dominated by single-task
models. Instead, modern AI systems orchestrate multiple
components—each responsible for carrying out specialized
tasks such as safety checking and prompt rewriting, or in-
voking external tools such as APIs—within long multi-turn
interactions (Zeng et al., 2025; Feng et al., 2025; Chen et al.,
2025; Jin et al., 2025). This multi-adapter composition al-
lows systems to leverage finetuned expertise dynamically
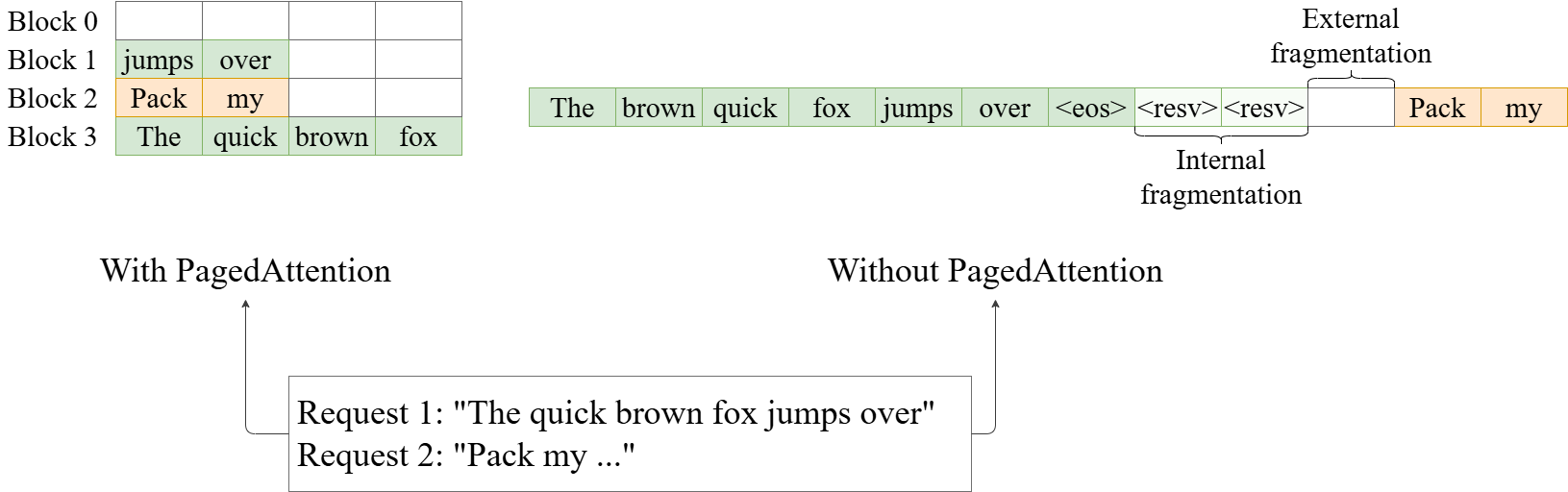
during inference. While current serving frameworks are
able to easily serve multiple LoRA adapters in heteroge-
neous batches, they still incur substantial overhead when
switching adapters mid-sequence: every adapter change in-
validates the model’s key-value (KV) cache and forces a full
recomputation of context representations before generation
can resume. This cache invalidation problem becomes a
bottleneck in multi-turn or long-context pipelines, where
the same input tokens may be repeatedly re-encoded for
different adapters.
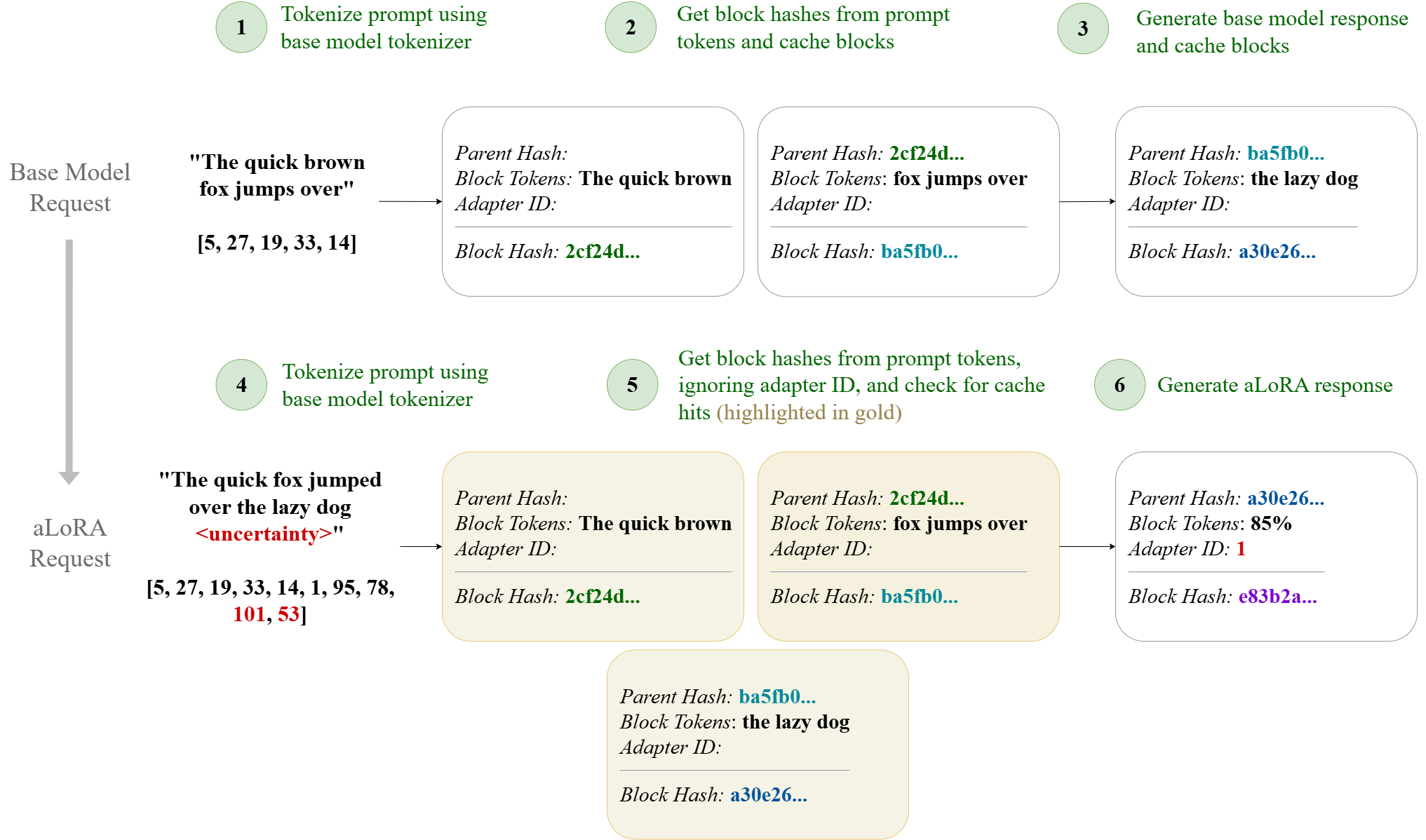
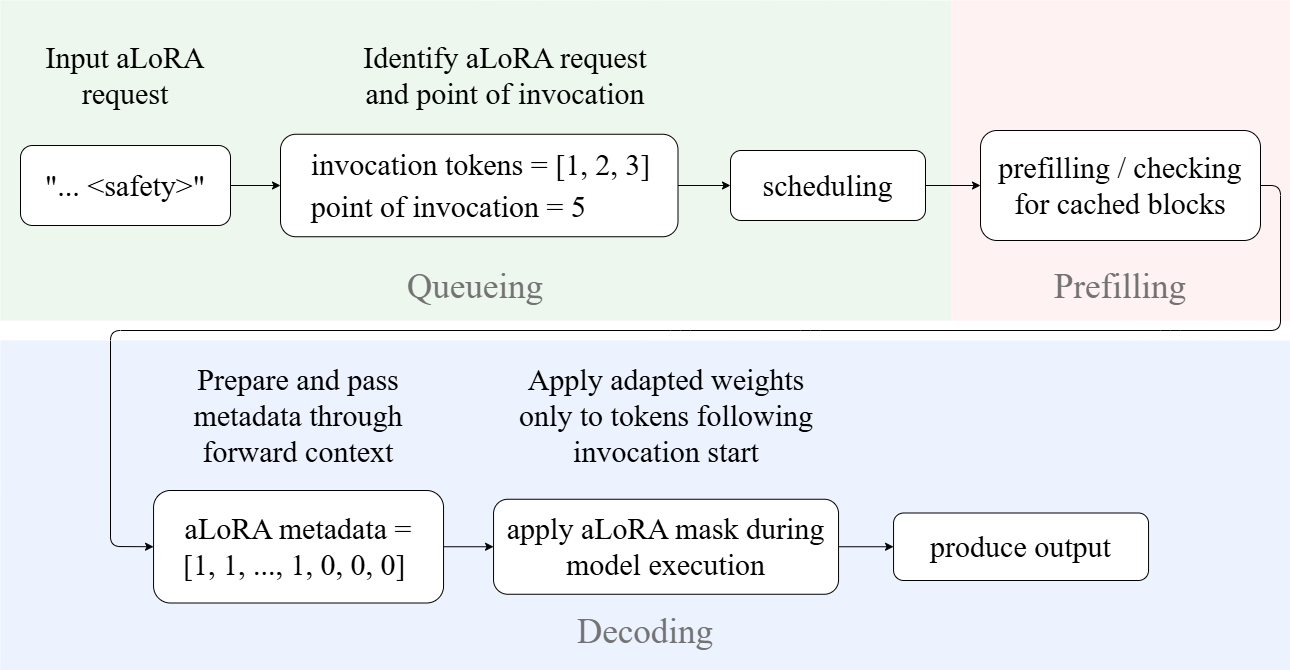
Activated LoRA (aLoRA) (Greenewald et al., 2025) intro-
duces a mechanism to mitigate this inefficiency by modify-
ing the model’s attention projections only after a predefined
activation sequence. Because the pre-activation attention
weights remain identical between the base model and the
adapter, the base model’s KV-cache can be reused up to
the activation point. This property makes aLoRA well-
suited for pipelines where multiple lightweight adapters
need to be invoked mid-generation with high frequency. In
arXiv:2512.17910v1 [cs.DC] 26 Nov 2025
Efficient Multi-Adapter Serving via Activated LoRA Cache Reuse
principle, aLoRA enables low-latency switching between
model adapters, but realizing such fine-grained cache reuse
in modern LLM serving systems presents nontrivial design
challenges.
In this work, we design, implement, and evaluate a serving
architecture that enables cross-model KV-cache reuse be-
tween base and aLoRA adapters, allowing models to
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.