📝 Original Info
- Title: 대형 언어 모델을 활용한 동적 개인화 접근 제어 시스템
- ArXiv ID: 2511.20284
- Date: 2025-11-26
- Authors: Researchers from original ArXiv paper
📝 Abstract
Precise access control decisions are crucial to the security of both traditional applications and emerging agent-based systems. Typically, these decisions are made by users during app installation or at runtime. Due to the increasing complexity and automation of systems, making these access control decisions can add a significant cognitive load on users, often overloading them and leading to suboptimal or even arbitrary access control decisions. To address this problem, we propose to leverage the processing and reasoning capabilities of large language models (LLMs) to make dynamic, context-aware decisions aligned with the user's security preferences. For this purpose, we conducted a user study, which resulted in a dataset of 307 natural-language privacy statements and 14,682 access control decisions made by users. We then compare these decisions against those made by two versions of LLMs: a general and a personalized one, for which we also gathered user feedback on 1,446 of its decisions. Our results show that in general, LLMs can reflect users' preferences well, achieving up to 86\% accuracy when compared to the decision made by the majority of users. Our study also reveals a crucial trade-off in personalizing such a system: while providing user-specific privacy preferences to the LLM generally improves agreement with individual user decisions, adhering to those preferences can also violate some security best practices. Based on our findings, we discuss design and risk considerations for implementing a practical natural-language-based access control system that balances personalization, security, and utility.
💡 Deep Analysis
Deep Dive into 대형 언어 모델을 활용한 동적 개인화 접근 제어 시스템.
Precise access control decisions are crucial to the security of both traditional applications and emerging agent-based systems. Typically, these decisions are made by users during app installation or at runtime. Due to the increasing complexity and automation of systems, making these access control decisions can add a significant cognitive load on users, often overloading them and leading to suboptimal or even arbitrary access control decisions. To address this problem, we propose to leverage the processing and reasoning capabilities of large language models (LLMs) to make dynamic, context-aware decisions aligned with the user’s security preferences. For this purpose, we conducted a user study, which resulted in a dataset of 307 natural-language privacy statements and 14,682 access control decisions made by users. We then compare these decisions against those made by two versions of LLMs: a general and a personalized one, for which we also gathered user feedback on 1,446 of its decisio
📄 Full Content
Can LLMs Make (Personalized) Access Control Decisions?
Friederike Groschupp∗, Daniele Lain∗, Aritra Dhar†, Lara Magdalena Lazier†, Srdjan ˇCapkun∗
∗Department of Computer Science, ETH Zurich, Switzerland,
{friederike.groschupp, daniele.lain, srdjan.capkun}@inf.ethz.ch
†Computing Systems Lab, Huawei Technologies Switzerland AG
{aritra.dhar, lara.magdalena.lazier2}@huawei.com
Abstract—Precise access control decisions are crucial to the
security of both traditional applications and emerging agent-
based systems. Typically, these decisions are made by users
during app installation or at runtime. Due to the increasing
complexity and automation of systems, making these access
control decisions can add a significant cognitive load on users,
often overloading them and leading to suboptimal or even
arbitrary access control decisions. To address this problem, we
propose to leverage the processing and reasoning capabilities
of large language models (LLMs) to make dynamic, context-
aware decisions aligned with the user’s security preferences.
For this purpose, we conducted a user study, which resulted in
a dataset of 307 natural-language privacy statements and 14,682
access control decisions made by users. We then compare these
decisions against those made by two versions of LLMs: a
general and a personalized one, for which we also gathered
user feedback on 1,446 of its decisions.
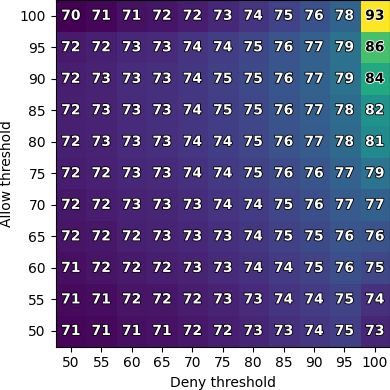
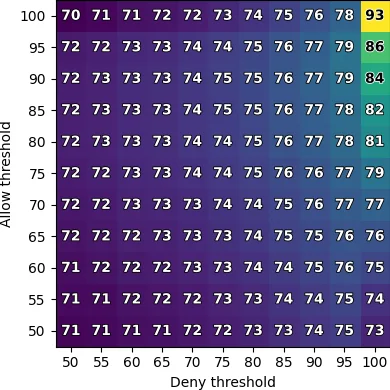
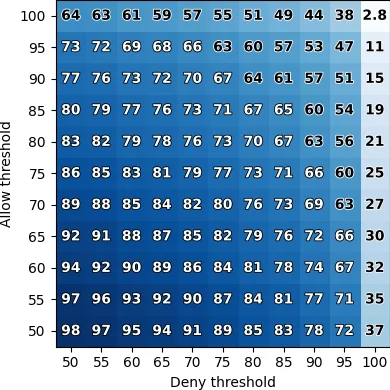
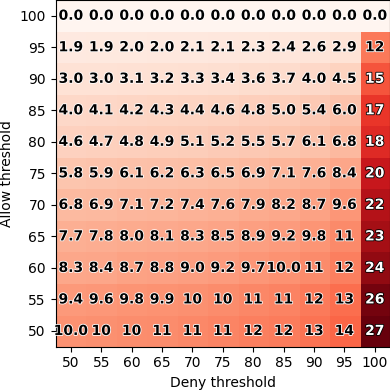
Our results show that in general, LLMs can reflect
users’ preferences well, achieving up to 86% accuracy when
compared to the decision made by the majority of users. Our
study also reveals a crucial trade-off in personalizing such
a system: while providing user-specific privacy preferences
to the LLM generally improves agreement with individual
user decisions, adhering to those preferences can also violate
some security best practices. Based on our findings, we discuss
design and risk considerations for implementing a practical
natural-language-based access control system that balances
personalization, security, and utility.
1. Introduction
With the rising capabilities of large language models
(LLMs), they are increasingly employed to solve classical
security problems, such as synthesizing firewall rules [1],
detecting security bugs [2], or formal verification [3], among
others. We turn our attention to access control, an area
known for imposing a high cognitive burden on users [4],
often resulting in suboptimal decisions [5], [6].
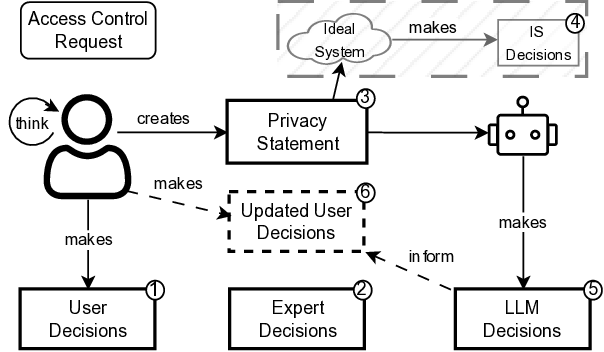
We investigate whether we can reduce this burden by
relying on a state-of-the-art LLM to make personalized
runtime decisions on behalf of the user. To reduce the setup
cost of such a system, we want to avoid approaches that
would require gathering a large set of data points from
the user or require retraining or fine-tuning the model to
learn the user’s preferences. Instead, we ask the user to
provide their privacy statement, a short natural-language
description of their access control preferences. The LLM
then makes decisions based on this statement and the
contextual factors surrounding an access request provided
in its context, balancing user requirements and security
considerations.
Using LLMs to accurately reflect users’ privacy prefer-
ences and make access control decisions is non-trivial and
poses several challenges. First, the quality of the LLM infer-
ence is often dependent on the input [7]. Therefore, poorly
expressed privacy preferences may result in less accurate
access control decisions. Second, it is well documented that
self-reported behavior, specifically in the context of security,
often suffers from bias [8] and the privacy paradox
[9],
[10], resulting in a divergence between reported preference
and actual actions [11]. Third, limitations of LLMs, such as
hallucinations [12] or biases [13] might lead to undesired
decision making. In this work, we therefore ask the fol-
lowing question: Can existing LLMs derive users’ privacy
preferences from a few user-provided instructions and take
access control decisions on behalf of the users?
To answer this question, we conducted a user study to
create a new dataset comprising users’ privacy preferences
in natural language, their access-control decisions in a
concrete scenario—permission requests from smartphone
applications—and users’ feedback on the LLM’s decisions.
To the best of our knowledge, this is the first dataset
comprising personal natural-language privacy statements
and corresponding access control decisions. This dataset
allows us to systematically evaluate LLM access-control
decision-making in terms of agreement with average user
judgment, individual user preferences, and general best
practices.
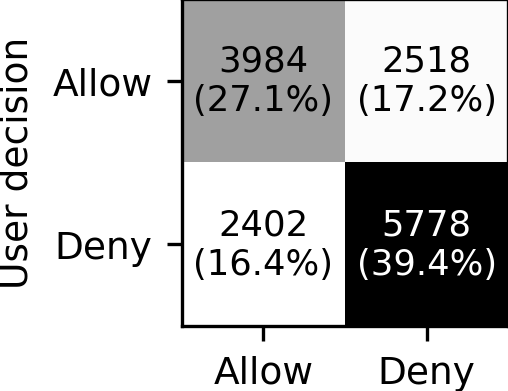
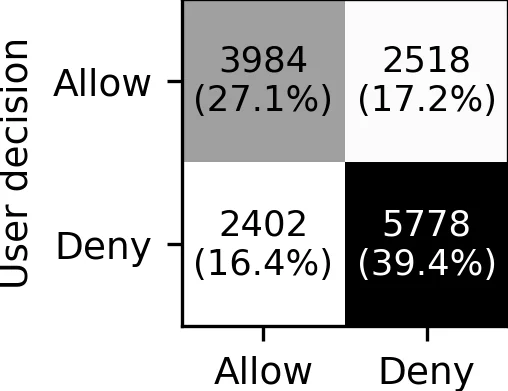
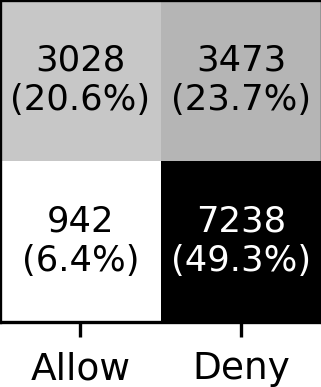
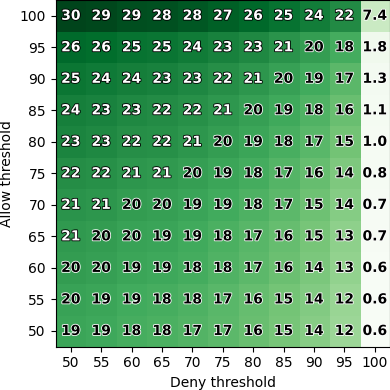
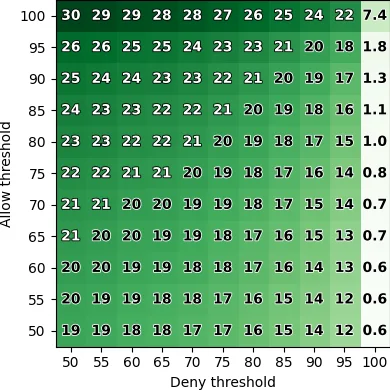
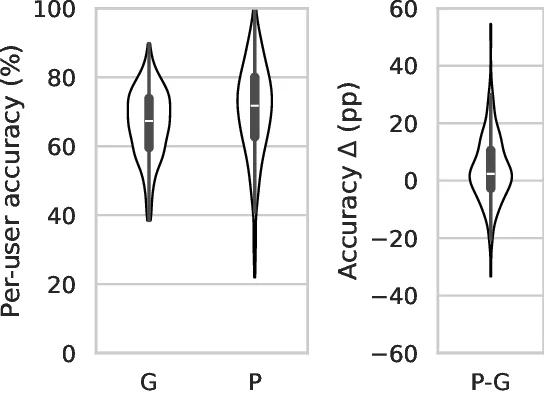
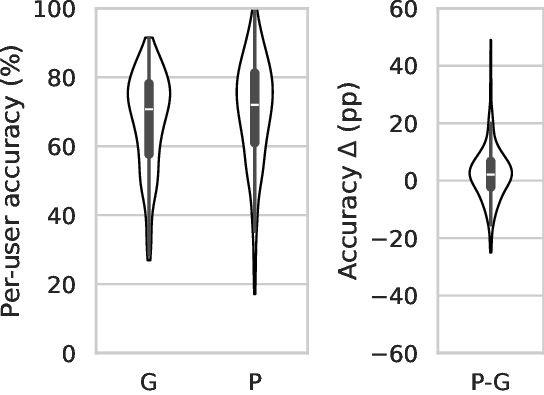
Our results show that LLMs can indeed reflect general
human judgment in access control decisions, achieving
up to 88% agreement with user majority decisions and
mostly agreeing with standard security practices. However,
individual personal differences lead to significant variation
in agreement, with some users having as low as 27%
agreement. Personaliz
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.