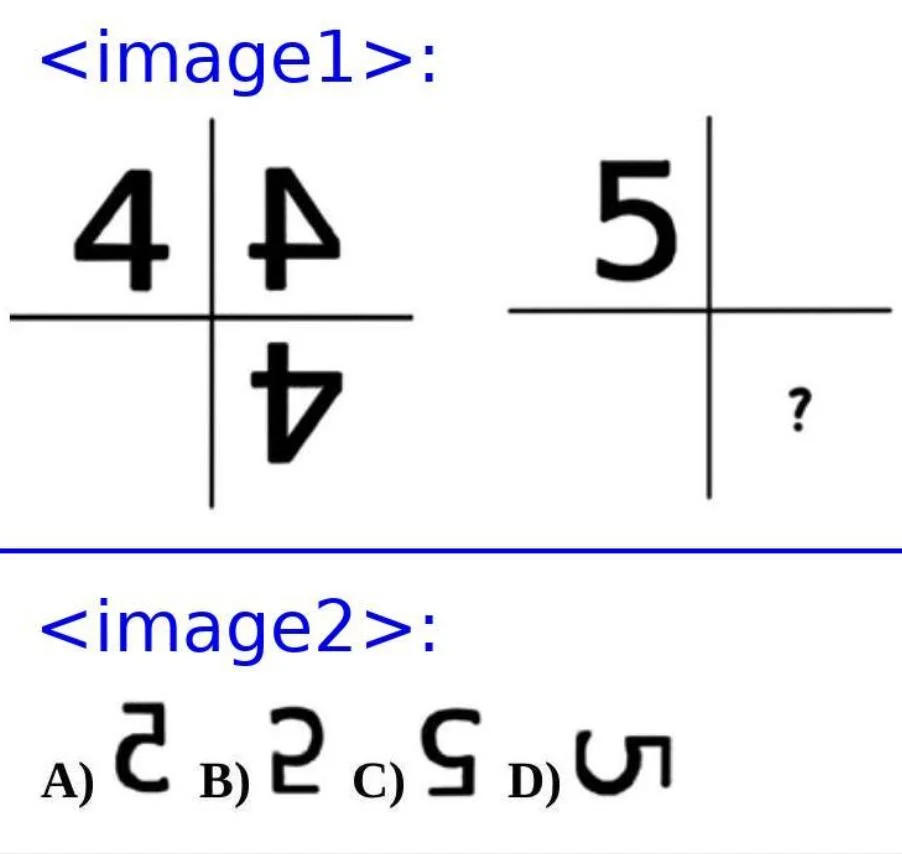
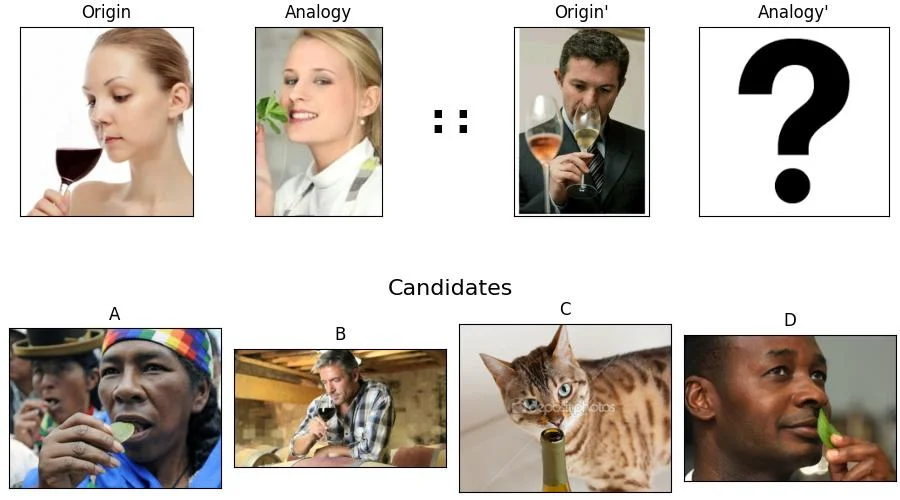
Thinking with images" has emerged as an effective paradigm for advancing visual reasoning, extending beyond text-only chains of thought by injecting visual evidence into intermediate reasoning steps. However, existing methods fall short of human-like abstract visual thinking, as their flexibility is fundamentally limited by external tools. In this work, we introduce Monet, a training framework that enables multimodal large language models (MLLMs) to reason directly within the latent visual space by generating continuous embeddings that function as intermediate visual thoughts. We identify two core challenges in training MLLMs for latent visual reasoning-high computational cost in latent-vision alignment and insufficient supervision over latent embeddings, and address them with a three-stage distillation-based supervised fine-tuning (SFT) pipeline. We further reveal a limitation of applying GRPO to latent reasoning: it primarily enhances text-based reasoning rather than latent reasoning. To overcome this, we propose VLPO (Visual-latent Policy Optimization), a reinforcement learning method that explicitly incorporates latent embeddings into policy gradient updates. To support SFT, we construct Monet-SFT-125K, a high-quality text-image interleaved CoT dataset containing 125K realworld, chart, OCR, and geometry CoTs. Our model, Monet-7B, shows consistent gains across real-world perception and reasoning benchmarks and exhibits strong outof-distribution generalization on challenging abstract visual reasoning tasks. We also empirically analyze the role of each training component and discuss our early unsuccessful attempts, providing insights for future developments in visual latent reasoning. Our model, data, and code are available at https://github.com/NOVAglow646/ Monet.
Deep Dive into Monet: Reasoning in Latent Visual Space Beyond Images and Language.
Thinking with images" has emerged as an effective paradigm for advancing visual reasoning, extending beyond text-only chains of thought by injecting visual evidence into intermediate reasoning steps. However, existing methods fall short of human-like abstract visual thinking, as their flexibility is fundamentally limited by external tools. In this work, we introduce Monet, a training framework that enables multimodal large language models (MLLMs) to reason directly within the latent visual space by generating continuous embeddings that function as intermediate visual thoughts. We identify two core challenges in training MLLMs for latent visual reasoning-high computational cost in latent-vision alignment and insufficient supervision over latent embeddings, and address them with a three-stage distillation-based supervised fine-tuning (SFT) pipeline. We further reveal a limitation of applying GRPO to latent reasoning: it primarily enhances text-based reasoning rather than latent reasoning
Recent work [10,15,25,29,49] has demonstrated that the incorporation of auxiliary images in the intermediate steps of chain-of-thought (CoT) can improve the visual reasoning of multimodal large language models (MLLMs) [1,5,8,17,30,38]. A recent trend is to acquire auxiliary images by training MLLMs to predict key region coordinates [10,12,32,49], invoking visual tools such as grounding or depth estimation models [15,25,33], or generating executable codes [46,47] to modify the input image. While promising, these methods are constrained by a limited set of external tools, lacking the flexible, human-like visual reasoning that arises within an internal perceptual space.
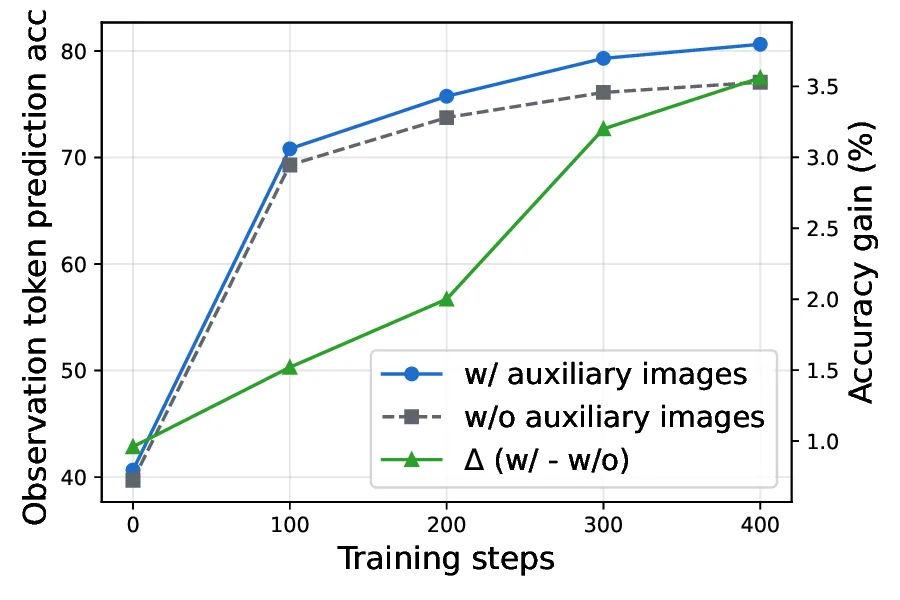
To emulate the flexible visual reasoning of humans, we investigate training MLLMs to reason directly in the continuous latent space. Specifically, we enable MLLMs to generate latent embeddings that serve as intermediate visual thoughts beyond textual descriptions and image embeddings, thus eliminating the need for explicit auxiliary images and overcoming the rigidity of external tools. Recent studies have begun exploring latent visual reasoning strategies [20,23,42]. Most existing methods simply align the generated embeddings with those of auxiliary images while applying a next-token prediction (NTP) loss on text tokens during supervised fine-tuning (SFT), and directly apply GRPO [27] for reinforcement learning (RL), which leads to two key limitations: (1) poor scalability, as alignment over thousands of image tokens incurs high computational and memory costs, and using mean pooling to compress the image tokens [42] will distort detailed visual features; (2) insufficient optimization of latent embeddings, since the NTP objective in SFT can be easily overfit and the GRPO loss can only be computed for text tokens, the optimization of latent embeddings are ignored; Consequently, their improvements remain limited and task-specific.
Motivated by these observations, we propose Monet1 , a novel training framework for multimodal latent reasoning that trains a text-output MLLM (Qwen2.5-VL-7B [1]) to perform latent reasoning through SFT and RL. The SFT stage aims at equipping the model with the fundamental ability to generate and reason with latent embeddings. To tackle limitation (1), instead of directly aligning latent embeddings with those of auxiliary images, we introduce dual supervision signals. First, since latent embeddings are intended to facilitate reasoning, we align the hidden representations of text tokens corresponding to crucial visual features observed from the auxiliary images, when conditioned on either auxiliary images or generated latent embeddings. Second, to preserve visual information, we use a controlled attention mask so that latent embeddings can directly attend to auxiliary image embeddings. To overcome limitation (2), we optimize the alignment loss solely through latent embeddings by stopping gradients on non-latent representations. Furthermore, we propose Viusal-latent Policy Optimization (VLPO), which computes policy gradient directly for latent embeddings by estimating their output probability.
Our contributions are summarized as follows: 1. We propose Monet-SFT, a three-stage supervised finetuning framework that trains MLLMs to generate and reason with latent embeddings. 2. We propose VLPO, a novel RL algorithm tailored for latent reasoning. Unlike GRPO, which targets text reasoning, VLPO incorporates latent embeddings into the total loss by computing an approximate probability for the latent embeddings collected during rollout. 3. We identify the limitations of existing image-text interleaved datasets: the unnecessary usage and inaccuracy of auxiliary images. To address these limitations, we further propose a multi-stage data curation pipeline to construct Monet-SFT-152K, a high-quality dataset with image-text interleaved chain-of-thoughts (CoT) for SFT. 4. Extensive experiments on real-world perception and reasoning benchmarks show that Monet-SFT and VLPO outperform conventional SFT + GRPO, cropping-based methods, and prior latent visual reasoning approaches. VLPO further enhances out-of-distribution (OOD) generalization on unseen tasks.
These studies can be broadly divided into two categories based on how they obtain intermediate-step auxiliary images: (1) directly emphasizing visual content from the original image, such as grounding, cropping, or re-inputting selected image tokens [3,7,25,34,44,49]; and (2) creating new visual content beyond the original image, such as invoking external tools or code interpreters to edit the image (e.g., drawing lines, adding bounding boxes, computing depth maps) [4,12,15,24,33,46,47,50], or generating new images via text-to-image models [6,21,41].
While these approaches significantly enhance visual perception and reasoning, they also introduce key limitations. First, models trained for specific visual tools, such as bounding box prediction, struggle to generalize to tasks requiri
…(Full text truncated)…
This content is AI-processed based on ArXiv data.