📝 Original Info
- Title: 생성 평가 일관성을 활용한 대형 언어 모델 정렬 벤치마크
- ArXiv ID: 2511.20604
- Date: 2025-11-26
- Authors: ** - Yixin Liu (Yale University) - Pengfei Liu (Shanghai Jiao Tong University) - Arman Cohan (Yale University) **
📝 Abstract
Alignment with human preferences is an important evaluation aspect of LLMs, requiring them to be helpful, honest, safe, and to precisely follow human instructions. Evaluating large language models' (LLMs) alignment typically involves directly assessing their open-ended responses, requiring human annotators or strong LLM judges. Conversely, LLMs themselves have also been extensively evaluated as judges for assessing alignment. In this work, we examine the relationship between LLMs' generation and evaluation capabilities in aligning with human preferences. To this end, we first conduct a comprehensive analysis of the generation-evaluation consistency (GE-consistency) among various LLMs, revealing a strong correlation between their generation and evaluation capabilities when evaluated by a strong LLM preference oracle. Utilizing this finding, we propose a benchmarking paradigm that measures LLM alignment with human preferences without directly evaluating their generated outputs, instead assessing LLMs in their role as evaluators. Our evaluation shows that our proposed benchmark, AlignEval, matches or surpasses widely used automatic LLM evaluation benchmarks, such as AlpacaEval and Arena-Hard, in capturing human preferences when ranking LLMs. Our study offers valuable insights into the connection between LLMs' generation and evaluation capabilities, and introduces a benchmark that assesses alignment without directly evaluating model outputs.
💡 Deep Analysis
Deep Dive into 생성 평가 일관성을 활용한 대형 언어 모델 정렬 벤치마크.
Alignment with human preferences is an important evaluation aspect of LLMs, requiring them to be helpful, honest, safe, and to precisely follow human instructions. Evaluating large language models’ (LLMs) alignment typically involves directly assessing their open-ended responses, requiring human annotators or strong LLM judges. Conversely, LLMs themselves have also been extensively evaluated as judges for assessing alignment. In this work, we examine the relationship between LLMs’ generation and evaluation capabilities in aligning with human preferences. To this end, we first conduct a comprehensive analysis of the generation-evaluation consistency (GE-consistency) among various LLMs, revealing a strong correlation between their generation and evaluation capabilities when evaluated by a strong LLM preference oracle. Utilizing this finding, we propose a benchmarking paradigm that measures LLM alignment with human preferences without directly evaluating their generated outputs, instead a
📄 Full Content
On Evaluating LLM Alignment by Evaluating
LLMs as Judges
Yixin Liu1
Pengfei Liu2
Arman Cohan1
1Yale University
2Shanghai Jiao Tong University
{yixin.liu, arman.cohan}@yale.edu
Abstract
Alignment with human preferences is an important evaluation aspect of LLMs, re-
quiring them to be helpful, honest, safe, and to precisely follow human instructions.
Evaluating large language models’ (LLMs) alignment typically involves directly
assessing their open-ended responses, requiring human annotators or strong LLM
judges. Conversely, LLMs themselves have also been extensively evaluated as
judges for assessing alignment. In this work, we examine the relationship between
LLMs’ generation and evaluation capabilities in aligning with human preferences.
To this end, we first conduct a comprehensive analysis of the generation-evaluation
consistency (GE-consistency) among various LLMs, revealing a strong correla-
tion between their generation and evaluation capabilities when evaluated by a
strong LLM preference oracle. Utilizing this finding, we propose a benchmarking
paradigm that measures LLM alignment with human preferences without directly
evaluating their generated outputs, instead assessing LLMs in their role as evalua-
tors. Our evaluation shows that our proposed benchmark, ALIGNEVAL, matches or
surpasses widely used automatic LLM evaluation benchmarks, such as AlpacaEval
and Arena-Hard, in capturing human preferences when ranking LLMs. Our study
offers valuable insights into the connection between LLMs’ generation and eval-
uation capabilities, and introduces a benchmark that assesses alignment without
directly evaluating model outputs.1
1
Introduction
Alignment with human preferences is a key property of LLMs, requiring them to accurately follow
user instructions, generate responses that meet user needs, and reflect human values [29, 4]. Evaluating
LLM alignment2 typically involves human evaluations of model outputs in response to various user
queries, since it requires assessing LLMs’ capabilities in various open-ended tasks. However, such
large-scale and reliable human evaluations are often complex, expensive, and time-consuming [46].
To scale this process, the widely used ChatBot Arena benchmark [5] relies on crowd-sourced
annotations, where each instance consists of a pairwise comparison between two model outputs for
a given instruction. To reduce reliance on the expensive process of human evaluation, automatic
alignment benchmarks have been proposed [45, 22, 21, 24], where LLMs as judges are used in
place of human annotators, enabling faster evaluation while maintaining a reasonably high level
of agreement with human preferences. Consequently, this LLMs-as-Judges paradigm has been
commonly used for LLM evaluation in alignment and other open-ended tasks.
Understanding and evaluating how reliable LLMs are as judges has also become an important
topic [43, 19, 25]. As discussed earlier, LLMs-as-Judges is an important paradigm for LLM evaluation.
1ALIGNEVAL is available at https://github.com/yale-nlp/AlignEval.
2In this work, we use “LLM alignment” to refer to LLMs’ general capabilities in following human instructions
and providing helpful, high-quality responses, which goes beyond safety or harmlessness alignment.
39th Conference on Neural Information Processing Systems (NeurIPS 2025).
arXiv:2511.20604v1 [cs.CL] 25 Nov 2025
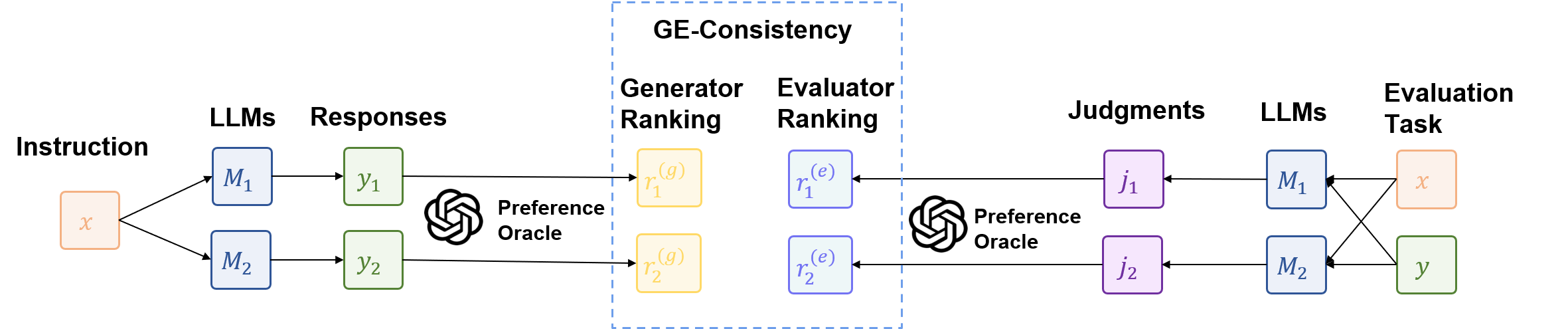
Figure 1: Illustration of Generation-Evaluation Consistency (GE-consistency), where LLMs’ genera-
tion and evaluation capability rankings are compared using a preference oracle.
Furthermore, LLMs can also be used as judges in model training with preference optimization
algorithms in place of fine-tuned reward models [35]. The evaluations of LLMs as judges are
typically conducted by comparing the predictions of LLMs against human annotations for the same
evaluation tasks. Recent studies [47, 19] have shown that frontier LLMs are strong judges for
alignment evaluation. In particular, they can serve as effective out-of-the-box generative reward
models [26], achieving performance competitive with fine-tuned discriminative reward models.
We argue that it is important to study the connection between these two related capabilities of LLMs:
generating responses that align with human preferences and evaluating whether responses are aligned
with human preferences. Understanding this connection has significant implications for both model
evaluation, by revealing the (in)consistency between these capabilities [41, 23], and model training,
particularly in exploring the feasibility of self-improvement where an LLM’s training is supervised
by its own judgments, which inherently requires a model to accurately assess its own outputs [32, 42].
Along this direction, prior work has examined the (in)consistency of individual LLMs when acting as
both generator and validator [32, 42]. However, a comprehensive study is still lacking on whether the
performance rankings among various LLMs are consistent between the gen
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.