📝 Original Info
- Title: 확산 모델을 활용한 노래 음성 분리 라티스 디퓨전 기반 효율적 생성 접근
- ArXiv ID: 2511.20470
- Date: 2025-11-26
- Authors: Researchers from original ArXiv paper
📝 Abstract
Extracting individual elements from music mixtures is a valuable tool for music production and practice. While neural networks optimized to mask or transform mixture spectrograms into the individual source(s) have been the leading approach, the source overlap and correlation in music signals poses an inherent challenge. Also, accessing all sources in the mixture is crucial to train these systems, while complicated. Attempts to address these challenges in a generative fashion exist, however, the separation performance and inference efficiency remain limited. In this work, we study the potential of diffusion models to advance toward bridging this gap, focusing on generative singing voice separation relying only on corresponding pairs of isolated vocals and mixtures for training. To align with creative workflows, we leverage latent diffusion: the system generates samples encoded in a compact latent space, and subsequently decodes these into audio. This enables efficient optimization and faster inference. Our system is trained using only open data. We outperform existing generative separation systems, and level the compared non-generative systems on a list of signal quality measures and on interference removal. We provide a noise robustness study on the latent encoder, providing insights on its potential for the task. We release a modular toolkit for further research on the topic.
💡 Deep Analysis
Deep Dive into 확산 모델을 활용한 노래 음성 분리 라티스 디퓨전 기반 효율적 생성 접근.
Extracting individual elements from music mixtures is a valuable tool for music production and practice. While neural networks optimized to mask or transform mixture spectrograms into the individual source(s) have been the leading approach, the source overlap and correlation in music signals poses an inherent challenge. Also, accessing all sources in the mixture is crucial to train these systems, while complicated. Attempts to address these challenges in a generative fashion exist, however, the separation performance and inference efficiency remain limited. In this work, we study the potential of diffusion models to advance toward bridging this gap, focusing on generative singing voice separation relying only on corresponding pairs of isolated vocals and mixtures for training. To align with creative workflows, we leverage latent diffusion: the system generates samples encoded in a compact latent space, and subsequently decodes these into audio. This enables efficient optimization and f
📄 Full Content
Efficient and Fast Generative-Based Singing Voice
Separation using a Latent Diffusion Model
Gen´ıs Plaja-Roglans∗†, Yun-Ning Hung∗, Xavier Serra†, and Igor Pereira∗
∗Music.AI, Salt Lake City, Utah, United States
†Music Technology Group, Universitat Pompeu Fabra. Barcelona, Spain
Abstract—Extracting individual elements from music mixtures
is a valuable tool for music production and practice. While neural
networks optimized to mask or transform mixture spectrograms
into the individual source(s) have been the leading approach, the
source overlap and correlation in music signals poses an inherent
challenge. Also, accessing all sources in the mixture is crucial to
train these systems, while complicated. Attempts to address these
challenges in a generative fashion exist, however, the separation
performance and inference efficiency remain limited. In this
work, we study the potential of diffusion models to advance
toward bridging this gap, focusing on generative singing voice
separation relying only on corresponding pairs of isolated vocals
and mixtures for training. To align with creative workflows, we
leverage latent diffusion: the system generates samples encoded
in a compact latent space, and subsequently decodes these into
audio. This enables efficient optimization and faster inference.
Our system is trained using only open data. We outperform
existing generative separation systems, and level the compared
non-generative systems on a list of signal quality measures and
on interference removal. We provide a noise robustness study on
the latent encoder, providing insights on its potential for the task.
We release a modular toolkit for further research on the topic.1
Index Terms—Denoising Diffusion Probabilistic Models, Music
Source Separation, Generative Modeling.
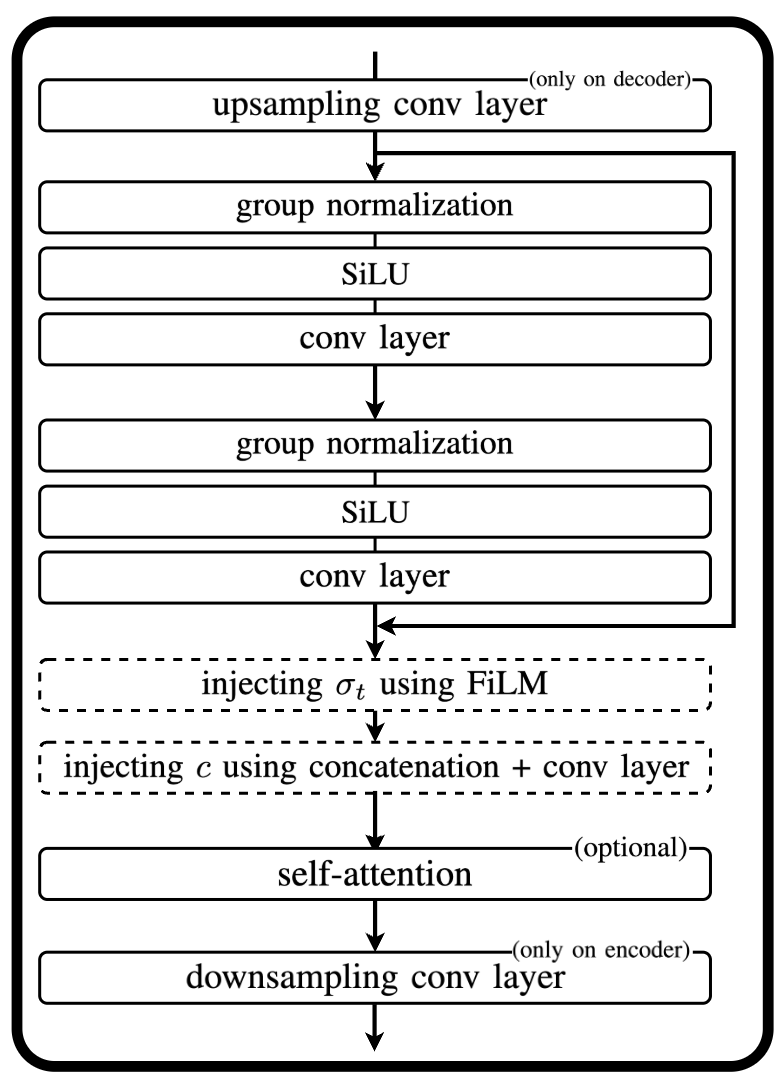
I. INTRODUCTION
Deep generative audio modeling has emerged as a widely
explored topic, with important advances specially attributed to
denoising diffusion probabilistic models (DDPM) [1]. These
generative systems have demonstrated impressive performance
for creative purposes [2, 3]. By introducing stringent condi-
tioning techniques [4, 5], the generative potential of DDPM
may be used to address audio inverse problems [4, 6, 7],
showing promise for multiple applications crucial to music
creation. Few examples are audio or speech enhancement [4],
upsampling [8], and more recently source separation [7, 9].
Music source separation (MSS) involves isolating individual
elements from a musical mixture [10]. It plays an important
role in music creation, practice, and analysis [11]. This task
is generally addressed via neural networks that mask or trans-
form the spectrogram of a mixture to extract the individual
sources [12]. However, these face an inherent challenge due
to the significant overlap between musical sources, which may
limit performance. Additionally, synthesizing the estimated
spectrograms into the time domain introduces further complex-
ity [10], and predicting the phase of complex spectrograms is
a studied but challenging task [13]. Moreover, having access
1Please see https://github.com/WeAreMusicAI/dmx-diffusion
to all sources that linearly sum up to the mixture is crucial to
train these systems [14], but acquiring such data is costly [15].
These challenges are crucial as music practitioners value
high-quality, clean separations. While recent deterministic
models have achieved impressive performance on objective
separation metrics [16, 17], it remains unclear whether these
metrics fully-capture perceptual quality [18, 19]. This is more
pronounced for generative models, which inherently sample
from a modeled data distribution. This often results in out-
puts with minor, potentially imperceptible deviations from
the target when addressing inverse problems. These subtle
differences are disproportionately penalized by the separation
metrics [20, 21]. However, users may prioritize perceptual
quality and cleanliness over an exact copy of the target signal.
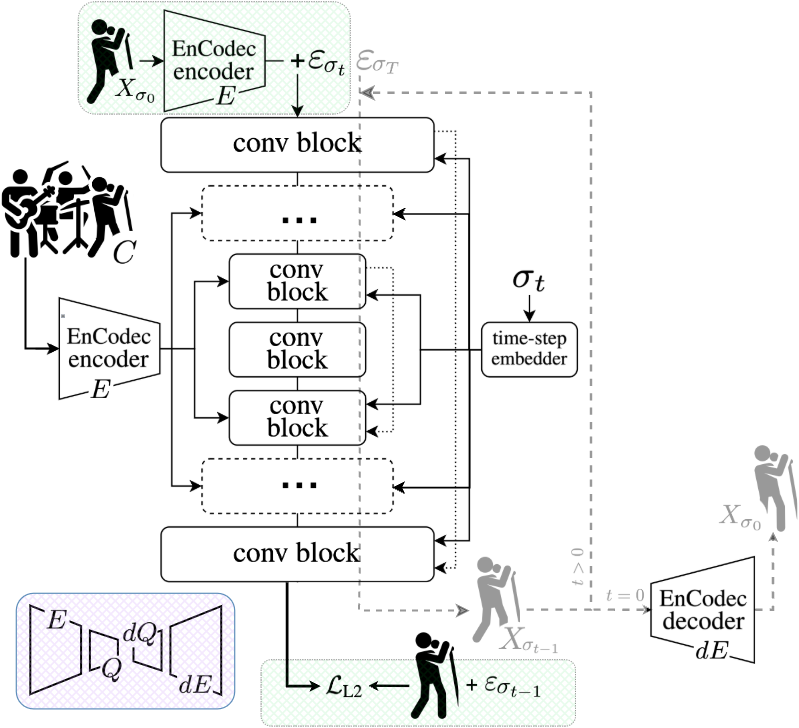
Despite their generation potential, the computational cost
of training DDPM remains a challenge, while large datasets
are normally required [1, 4]. To alleviate this, latent diffu-
sion models (LDM) were proposed [22]. These systems are
trained to generate samples encoded in a learned and compact
latent representation which is leveraged from an autoencoder
optimized for the target data. Thereby, latent diffusion enables
faster and more efficient optimization. More importantly, in-
ference can be run effectively with less computing resources,
which is crucial to bring these tools to music practitioners.
We explore the potential of latent diffusion to separate the
singing voice, a crucial but complex source, having solely
access to solo vocal tracks and the corresponding mixtures for
training. Recently, DDPM have been employed to separate mu-
sical sources both in the time [7] and latent domains [9]. How-
ever, these studies primarily focus on synthetic instrumental
mixtures and often exclude vocals
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.