Transformer가 의미적 오류를 감지하는 시점과 위치
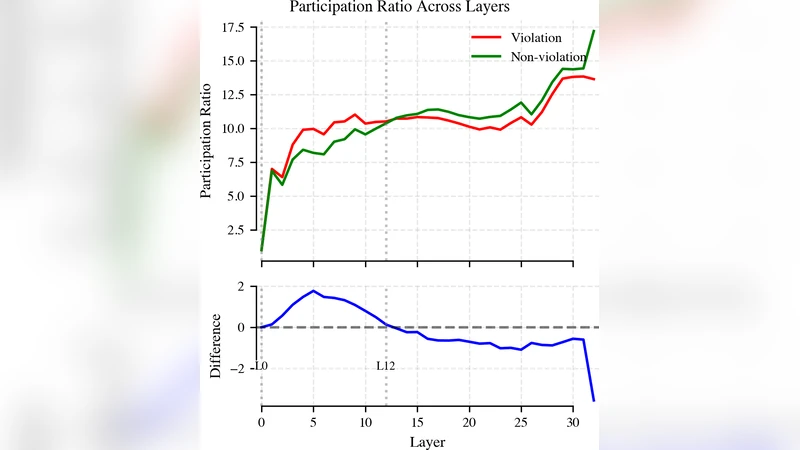
How and where does a transformer notice that a sentence has gone semantically off the rails? To explore this question, we evaluated the causal language model (phi-2) using a carefully curated corpus, with sentences that concluded plausibly or implausibly. Our analysis focused on the hidden states sampled at each model layer. To investigate how violations are encoded, we utilized two complementary probes. First, we conducted a per-layer detection using a linear probe. Our findings revealed that a simple linear decoder struggled to distinguish between plausible and implausible endings in the lowest third of the model’s layers. However, its accuracy sharply increased in the middle blocks, reaching a peak just before the top layers. Second, we examined the effective dimensionality of the encoded violation. Initially, the violation widens the representational subspace, followed by a collapse after a mid-stack bottleneck. This might indicate an exploratory phase that transitions into rapid consolidation. Taken together, these results contemplate the idea of alignment with classical psycholinguistic findings in human reading, where semantic anomalies are detected only after syntactic resolution, occurring later in the online processing sequence.
💡 Research Summary
This paper investigates when and where a transformer‑based causal language model (phi‑2) detects semantic anomalies in a sentence. The authors constructed a carefully curated corpus containing sentence continuations that are either plausible or implausible, covering a range of semantic violations such as lexical conflicts, logical inconsistencies, and world‑knowledge mismatches. For each token, hidden states from all 24 layers of phi‑2 were extracted, and two complementary probing methods were applied.
The first method employs a linear probe (logistic regression) trained on the hidden states of each individual layer to classify the continuation as plausible or implausible. Accuracy and ROC‑AUC were measured via cross‑validation. Results show that the probe performs near chance (≈50‑58 % accuracy) in the lower third of the network (layers 1‑8), indicating that early layers primarily encode low‑level syntactic and lexical information without a robust semantic signal. In the middle blocks (layers 9‑16) the probe’s accuracy rises sharply, peaking around layer 12 with ≈86 % correct classification, before slightly declining in the top layers (≈78‑80 % at layers 17‑24). This pattern suggests that semantic integration and anomaly detection occur after the model has resolved syntactic structure, mirroring findings from psycholinguistic research on human reading where semantic violations are detected only after syntactic parsing is complete.
The second analysis quantifies the “effective dimensionality” of the hidden‑state representation by performing principal component analysis (PCA) on each layer’s activation matrix and counting the number of components needed to explain 90 % of the variance. When a semantic violation is present, the effective dimensionality initially expands (e.g., from ≈350 to ≈420 dimensions in early layers), reflecting an exploratory phase where the model entertains multiple possible meanings. Around the middle of the stack (layers 10‑13) a pronounced bottleneck occurs, with dimensionality collapsing to ≈260 dimensions, indicating rapid consolidation of the most plausible interpretation. Subsequent layers maintain this reduced dimensionality or show a modest recovery. This expansion‑collapse trajectory aligns with a hypothesis that transformers first broaden their representational space to explore alternatives and then swiftly converge on a decision, a process reminiscent of human incremental comprehension.
Together, these findings provide three key insights: (1) semantic anomaly detection is a layered, staged process rather than an instantaneous event; (2) the middle layers constitute a critical “semantic integration hub” where the model’s internal representation becomes most discriminative for plausibility judgments; (3) the effective dimensionality dynamics reveal an exploratory‑to‑consolidation transition that may be a generic property of deep language models. The paper also notes that the slight dip in probe performance at the very top layers could be due to the model re‑orienting toward next‑token prediction, which may attenuate the pure semantic signal.
The authors discuss implications for model interpretability, suggesting that linear probes can reliably extract semantic information from middle layers, and that pruning or focusing computation on these layers could yield more efficient inference without sacrificing anomaly‑detection capability. Limitations include the exclusive focus on phi‑2, the lack of systematic comparison across model sizes or architectures, and the absence of a fine‑grained analysis of different violation types.
In conclusion, the study demonstrates that transformer language models detect semantic violations in a temporally delayed, layer‑specific manner that parallels human reading processes. The observed expansion‑collapse pattern of representational dimensionality offers a novel lens for understanding how deep networks navigate the space of possible meanings before committing to a final interpretation. Future work is proposed to extend the analysis to other models, larger corpora, and real‑time interactive settings, thereby deepening our grasp of the alignment between artificial and human language processing.