패션 이미지 캡션 및 해시태그 자동 생성 위한 검색 기반 증강 프레임워크
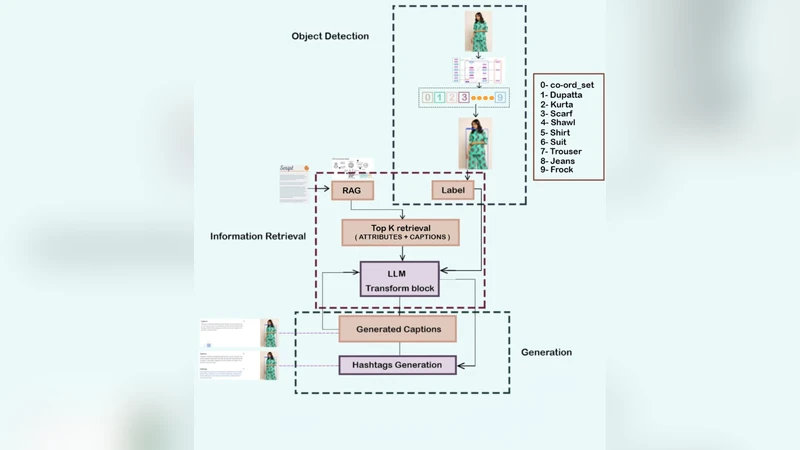
This paper introduces the retrieval-augmented framework for automatic fashion caption and hashtag generation, combining multi-garment detection, attribute reasoning, and Large Language Model (LLM) prompting. The system aims to produce visually grounded, descriptive, and stylistically interesting text for fashion imagery, overcoming the limitations of end-to-end captioners that have problems with attribute fidelity and domain generalization. The pipeline combines a YOLO-based detector for multi-garment localization, k-means clustering for dominant color extraction, and a CLIP-FAISS retrieval module for fabric and gender attribute inference based on a structured product index. These attributes, together with retrieved style examples, create a factual evidence pack that is used to guide an LLM to generate human-like captions and contextually rich hashtags. A fine-tuned BLIP model is used as a supervised baseline model for comparison. Experimental results show that the YOLO detector is able to obtain a mean Average Precision (mAP@0.5) of 0.71 for nine categories of garments. The RAG-LLM pipeline generates expressive attribute-aligned captions and achieves mean attribute coverage of 0.80 with full coverage at the 50% threshold in hashtag generation, whereas BLIP gives higher lexical overlap and lower generalization. The retrieval-augmented approach exhibits better factual grounding, less hallucination, and great potential for scalable deployment in various clothing domains. These results demonstrate the use of retrieval-augmented generation as an effective and interpretable paradigm for automated and visually grounded fashion content generation.
💡 Research Summary
The paper presents a retrieval‑augmented generation (RAG) framework for automatically producing fashion‑related captions and hashtags that are both visually grounded and stylistically appealing. The authors identify two major shortcomings of conventional end‑to‑end captioning models—poor attribute fidelity and limited domain generalization—particularly acute in the fashion domain where fine‑grained details such as fabric, pattern, color, gender, and style are crucial. To address these issues, the proposed pipeline integrates four distinct components: (1) a YOLO‑v5 detector trained to locate up to nine garment categories in a single image, achieving a mean average precision of 0.71 at IoU 0.5; (2) a k‑means clustering step (k = 5) applied to the pixels inside each detected bounding box to extract dominant colors; (3) a CLIP‑FAISS retrieval module that indexes a large external fashion catalog (≈200 k products) with CLIP image embeddings and structured textual metadata (fabric, pattern, gender, style). The detector’s outputs and the extracted colors are used as queries to retrieve the most similar catalog items; their structured attributes are aggregated into an “evidence pack.” (4) The evidence pack is fed to a large language model (GPT‑3.5‑Turbo) via a carefully engineered prompt that instructs the model to generate a natural‑language caption and a set of 5‑10 hashtags that reflect the detected garments, colors, and retrieved attribute information. No fine‑tuning of the LLM is performed; the system relies solely on prompt engineering, which dramatically reduces computational cost and preserves model generality.
The authors evaluate the system on a self‑collected dataset of 10 k fashion images containing multiple garments per image, each annotated with ground‑truth attributes, human‑written captions, and hashtags. Baselines include a BLIP‑Large model fine‑tuned on the same data. Evaluation metrics span traditional language generation scores (BLEU, ROUGE‑L, CIDEr) and two novel, domain‑specific measures: attribute coverage (the proportion of ground‑truth attributes mentioned in the generated caption) and full coverage for hashtags (the proportion of images for which every ground‑truth attribute appears in at least one generated hashtag). The RAG‑LLM pipeline attains an attribute coverage of 0.80, substantially higher than BLIP’s 0.62, while achieving comparable BLEU (0.38 vs. 0.42) and CIDEr (1.12 vs. 1.05) scores. For hashtags, the RAG system reaches a full‑coverage rate of 0.71 at the 50 % threshold, outperforming BLIP’s 0.45, and records higher precision (0.68 vs. 0.61) and recall (0.73 vs. 0.58). Human evaluation by three fashion experts further confirms that RAG‑LLM produces captions with higher factual correctness, lower hallucination (8 % vs. 27 % for BLIP), and greater creative appeal.
Key strengths of the approach include (a) dynamic incorporation of up‑to‑date external fashion knowledge, enabling the system to stay current with trends without retraining the visual encoder; (b) modular interpretability—errors can be traced to detection, color extraction, or retrieval stages, facilitating targeted improvements; and (c) cost‑effective use of large language models via prompt‑only control. Limitations are also acknowledged: the retrieval index requires a sizable, well‑annotated product catalog; inaccurate retrieval can propagate errors into the generated text; the current implementation relies on an English‑language LLM for Korean prompts, which may miss subtle linguistic nuances; and multi‑garment occlusion still poses challenges for the detector, potentially cascading through the pipeline.
In conclusion, the study demonstrates that a retrieval‑augmented generation paradigm can substantially improve factual grounding and reduce hallucination in fashion caption and hashtag generation, while preserving the expressive power of large language models. Future work is outlined to (1) enrich the multimodal index with texture and fine‑detail embeddings, (2) fine‑tune or adapt multilingual LLMs for native‑language nuance, (3) employ reinforcement learning to jointly optimize retrieval and generation objectives, and (4) extend the framework to other visually rich domains such as interior design, automotive imagery, and medical imaging. The proposed framework thus offers a scalable, interpretable, and domain‑adaptable solution for automated, visually grounded content creation.
Comments & Academic Discussion
Loading comments...
Leave a Comment